- Лекция №3. Функции промышленных СУБД

Содержание
- 2. 1 Эффективное хранение данных и доступ к ним 2 Поддержка системного каталога 3 Обеспечение ссылочной целостности
- 3. 1 Эффективное хранение данных и доступ к ним Инструменты эффективной организации данных: Кластеризация - ЛОГИЧЕСКИ СВЯЗАННЫЕ
- 4. Кластеризация tab1 tab1 tab2 tab1 tab1 tab2 Блок 10 Блок 11 кластеры Каждому блоку устанавливается кластерный
- 5. Индексация Блок 260 Блок 300 Блок 301 Блок 260 Блок 300 Блок 301 Блок 260 Блок
- 6. Индексы в виде В+дерева целесообразно создавать для атрибутов, у которых значения являются уникальными. Если атрибут содержит
- 7. Хеширование данных Недостаток индексных схем – необходимость при поиске записи дважды обращаться к вспомогательному запоминающему устройству:
- 8. ПРИМЕР, ИЛЛЮСТРИРУЮЩИЙ ЭТОТ МЕТОД: Требуется записать на диск, позволяющий хранить в блоке до 2000 байт, 500
- 9. 3 Обеспечение целостности данных Tab_num INTEGER PRIMARY KEY NOT NULL – в таблице sotr Name_disp INTEGER
- 10. Описание таблиц на языке SQL CREATE TABLE sotr ( cod NUMBER (4) PRIMARY KEY NOT NULL,
- 11. CREATE TABLE sotr (tab_num INT PRIMARY KEY NOT NULL, name VARCHAR 2(200) UNIQUE, dol VARCHAR2 (200),
- 12. 4 Управление буферами Ориентировано на повторное использование элементов базы данных (результатов выполнения запросов). Приложение Буферный кэш
- 13. 5 Обеспечение транзакционной целостности – поддержка свойства изолированности транзакций Решение проблем: 1 потерянного обновления, 2 чернового
- 14. 6 Организация обмена данными Организация обмена данными предполагает дополнение СУБД компонентами, которые позволяют организовать работу СУБД
- 15. 7 Оптимизация запросов Синтаксический анализ Конструирование первоначального логического плана Перепроектирование логического плана на основе правил эквивалентного
- 16. Укрупненая схема СУБД
- 17. Основными компонентами СУБД являются: компилятор запросов – предназначен для формирования физического плана реализации запроса, включает выполнение
- 18. метод доступа – предназначен для организации страничного обмена информацией между дисковым накопителем и оперативной памятью; менеджер
- 19. ТЕМА. Традиционная концептуальная модель данных Чена. Классификация атрибутов, сущностей и связей. Степень и кардинальность связи. Сильные,
- 20. Атрибуты делятся на простые и составные, однозначные и многозначные, исходные и производные. Простой атрибут описывает элементарное
- 21. Классы сущностей соединяются между собой поименованными типами связей . Каждый уникально идентифицируемый экземпляр типа связи позиционируется
- 22. ТЕМА. Проектирование логической модели баз данных Разработанная концептуальная модель базы данных является исходной информацией для проектирования
- 23. Иерархическая модель данных является исторически первой логической структурой, которая впервые была предложена компанией North American Rockwell
- 24. Основными недостатками иерархической модели данных являются следующие: вход в базу данных производится, в основном, через экземпляры
- 25. Сетевая модель данных была специфицирована в 1969 году рабочей группой конференции по языкам систем данных Conference
- 26. Основной недостаток сетевых систем - сложность и значительная трудоемкость программирования приложений на встроенных языках, требующее высокой
- 27. Реляционная модель данных была предложена в 1969 году преподавателем математики Э.Коддом, который по совместительству работал в
- 28. Объектно-реляционная модель данных представляет собой сочетание преимуществ реляционной и объектной модели данных. Основные элементы этой модели
- 30. Скачать презентацию

1 Эффективное хранение данных и доступ к ним
2 Поддержка системного каталога
3
1 Эффективное хранение данных и доступ к ним
2 Поддержка системного каталога
3

1 Эффективное хранение данных и доступ к ним
Инструменты эффективной организации данных:
Кластеризация
1 Эффективное хранение данных и доступ к ним
Инструменты эффективной организации данных:
Кластеризация
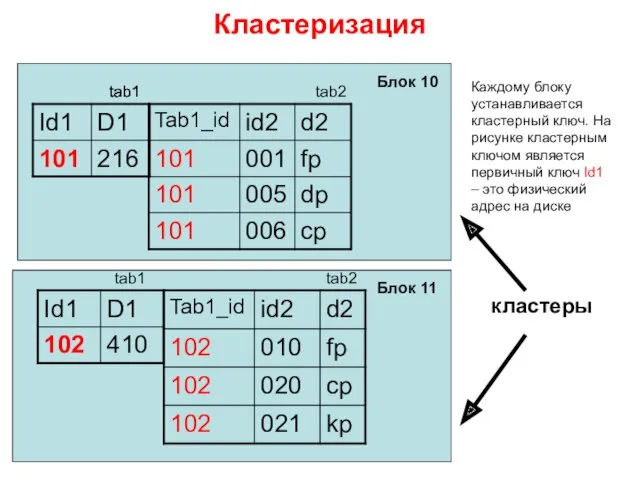
Кластеризация
tab1
tab1
tab2
tab1
tab1
tab2
Блок 10
Блок 11
кластеры
Каждому блоку устанавливается кластерный ключ. На рисунке кластерным ключом
Кластеризация
tab1
tab1
tab2
tab1
tab1
tab2
Блок 10
Блок 11
кластеры
Каждому блоку устанавливается кластерный ключ. На рисунке кластерным ключом
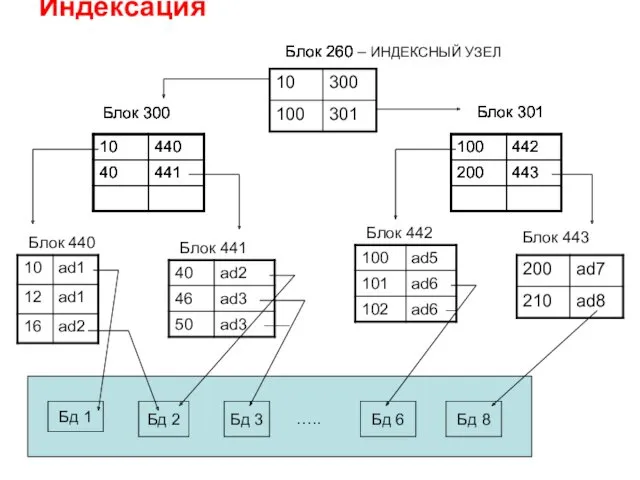
Индексация
Блок 260
Блок 300
Блок 301
Блок 260
Блок 300
Блок 301
Блок 260
Блок 300
Блок 301
Блок 260
Индексация
Блок 260
Блок 300
Блок 301
Блок 260
Блок 300
Блок 301
Блок 260
Блок 300
Блок 301
Блок 260
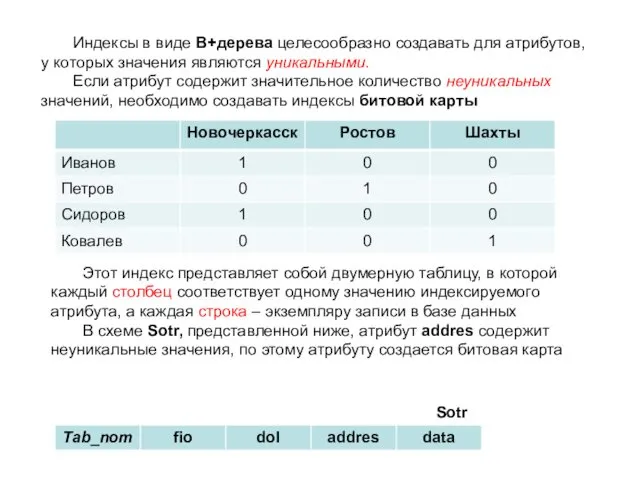
Индексы в виде В+дерева целесообразно создавать для атрибутов, у которых значения
Индексы в виде В+дерева целесообразно создавать для атрибутов, у которых значения
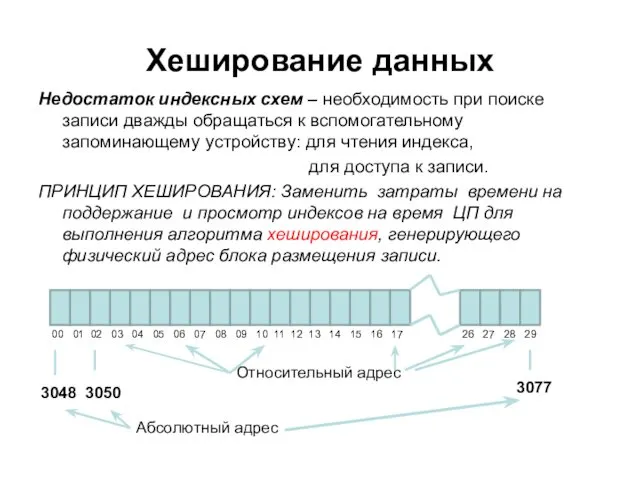
Хеширование данных
Недостаток индексных схем – необходимость при поиске записи дважды обращаться
Хеширование данных
Недостаток индексных схем – необходимость при поиске записи дважды обращаться

ПРИМЕР, ИЛЛЮСТРИРУЮЩИЙ ЭТОТ МЕТОД:
Требуется записать на диск, позволяющий хранить в блоке
ПРИМЕР, ИЛЛЮСТРИРУЮЩИЙ ЭТОТ МЕТОД:
Требуется записать на диск, позволяющий хранить в блоке
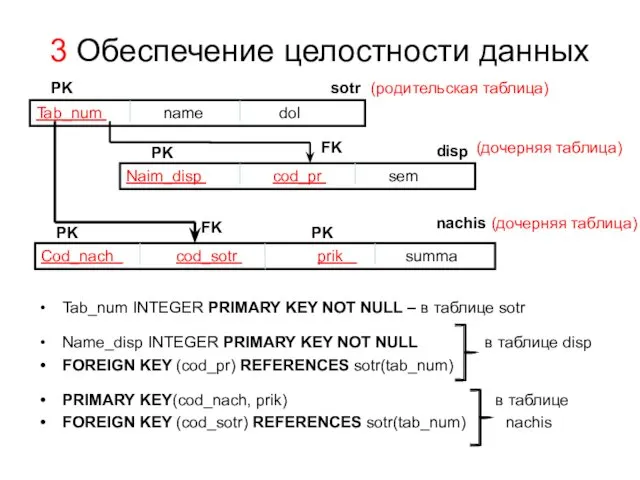
3 Обеспечение целостности данных
Tab_num INTEGER PRIMARY KEY NOT NULL – в
3 Обеспечение целостности данных
Tab_num INTEGER PRIMARY KEY NOT NULL – в

Описание таблиц на языке SQL
CREATE TABLE sotr (
cod NUMBER (4) PRIMARY
Описание таблиц на языке SQL
CREATE TABLE sotr ( cod NUMBER (4) PRIMARY
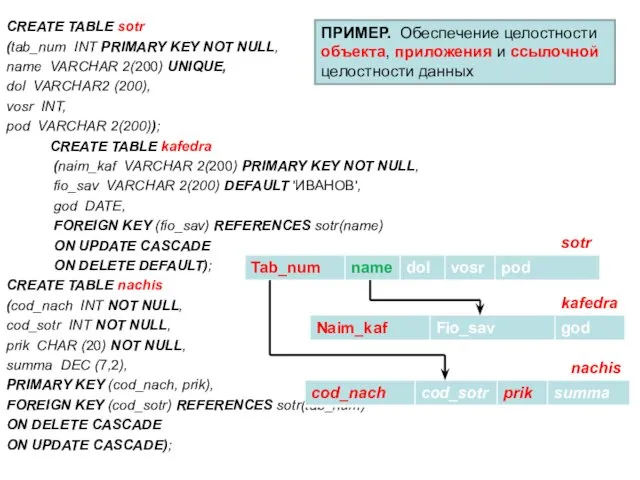
CREATE TABLE sotr
(tab_num INT PRIMARY KEY NOT NULL,
name VARCHAR 2(200) UNIQUE,
dol
CREATE TABLE sotr
(tab_num INT PRIMARY KEY NOT NULL,
name VARCHAR 2(200) UNIQUE,
dol
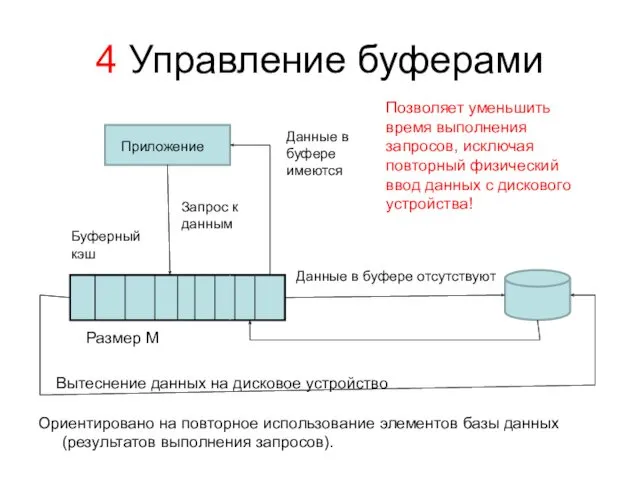
4 Управление буферами
Ориентировано на повторное использование элементов базы данных (результатов выполнения
4 Управление буферами
Ориентировано на повторное использование элементов базы данных (результатов выполнения
5 Обеспечение транзакционной целостности – поддержка свойства изолированности транзакций
Решение проблем:
1
5 Обеспечение транзакционной целостности – поддержка свойства изолированности транзакций
Решение проблем:
1

6 Организация обмена данными
Организация обмена данными предполагает дополнение СУБД компонентами, которые
6 Организация обмена данными
Организация обмена данными предполагает дополнение СУБД компонентами, которые
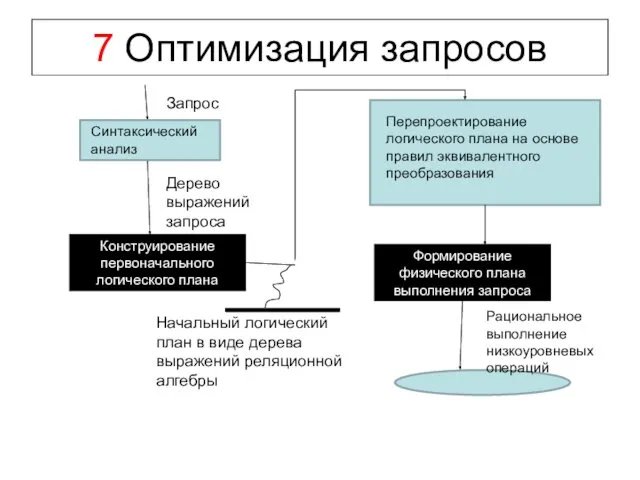
7 Оптимизация запросов
Синтаксический анализ
Конструирование первоначального логического плана
Перепроектирование логического плана на основе
7 Оптимизация запросов
Синтаксический анализ
Конструирование первоначального логического плана
Перепроектирование логического плана на основе
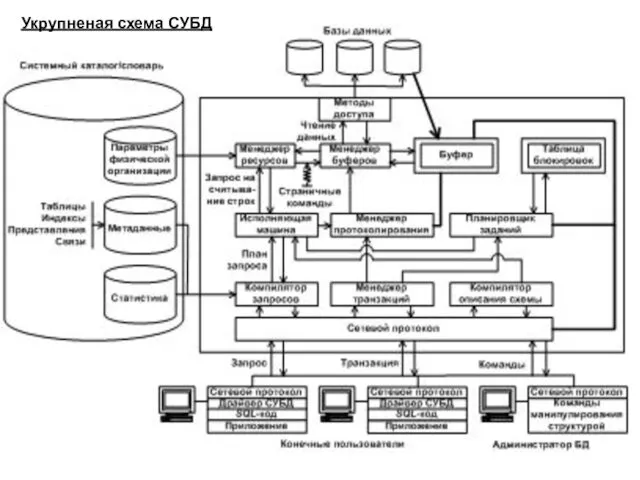
Укрупненая схема СУБД
Укрупненая схема СУБД

Основными компонентами СУБД являются:
компилятор запросов – предназначен для формирования физического плана
Основными компонентами СУБД являются:
компилятор запросов – предназначен для формирования физического плана

метод доступа – предназначен для организации страничного обмена информацией между дисковым
метод доступа – предназначен для организации страничного обмена информацией между дисковым

ТЕМА. Традиционная концептуальная модель данных Чена.
Классификация атрибутов, сущностей и связей. Степень
ТЕМА. Традиционная концептуальная модель данных Чена. Классификация атрибутов, сущностей и связей. Степень

Атрибуты делятся на простые и составные, однозначные и многозначные, исходные и
Атрибуты делятся на простые и составные, однозначные и многозначные, исходные и

Классы сущностей соединяются между собой поименованными типами связей
. Каждый уникально идентифицируемый
Классы сущностей соединяются между собой поименованными типами связей
. Каждый уникально идентифицируемый

ТЕМА. Проектирование логической модели баз данных
Разработанная концептуальная модель базы данных является
ТЕМА. Проектирование логической модели баз данных
Разработанная концептуальная модель базы данных является

Иерархическая модель данных является исторически первой логической структурой, которая впервые была
Иерархическая модель данных является исторически первой логической структурой, которая впервые была

Основными недостатками иерархической модели данных являются следующие:
вход в базу данных производится,
Основными недостатками иерархической модели данных являются следующие:
вход в базу данных производится,

Сетевая модель данных была специфицирована в 1969 году рабочей группой конференции
Сетевая модель данных была специфицирована в 1969 году рабочей группой конференции

Основной недостаток сетевых систем -
сложность и значительная трудоемкость программирования
Основной недостаток сетевых систем -
сложность и значительная трудоемкость программирования

Реляционная модель данных была предложена в 1969 году преподавателем математики Э.Коддом,

Объектно-реляционная модель данных представляет собой сочетание преимуществ реляционной и объектной модели
Объектно-реляционная модель данных представляет собой сочетание преимуществ реляционной и объектной модели
 Мнемотехника
Мнемотехника Фотоальбом. В память о любимой мамочке
Фотоальбом. В память о любимой мамочке Приобретенные пороки сердца
Приобретенные пороки сердца Конфликтные картинки
Конфликтные картинки Альтернативные источники энергии
Альтернативные источники энергии Биологическая очистка сточных вод
Биологическая очистка сточных вод Скважина, ее элементы и конструкции. Классификация скважин
Скважина, ее элементы и конструкции. Классификация скважин Семья. Традиции. Обычаи. Семейные ценности
Семья. Традиции. Обычаи. Семейные ценности : Лекарственные растения.
: Лекарственные растения. Анализ ситуации на рынке энергоресурсов
Анализ ситуации на рынке энергоресурсов Презентация ко дню матери Милая мама
Презентация ко дню матери Милая мама формирование вокально-хоровых навыков у дошкольников
формирование вокально-хоровых навыков у дошкольников Контроль технического состояния скважин. Лекция № 6
Контроль технического состояния скважин. Лекция № 6 Сенсорное развитие детей раннего возраста
Сенсорное развитие детей раннего возраста Карбонильные соединения - альдегиды
Карбонильные соединения - альдегиды Основы организации строительства и реконструкции железных дорог
Основы организации строительства и реконструкции железных дорог Картофель. Продукты из картофеля
Картофель. Продукты из картофеля Применение смазочно-охлаждающих жидкостей (СОЖ)
Применение смазочно-охлаждающих жидкостей (СОЖ) Технология формирования иноязычных грамматических навыков
Технология формирования иноязычных грамматических навыков Суицидальное поведение детей и подростков: определение, виды, причины, выявление
Суицидальное поведение детей и подростков: определение, виды, причины, выявление Современные методы инженерной защиты от оползней
Современные методы инженерной защиты от оползней Презентация Правила пожарной безопасности в лесу
Презентация Правила пожарной безопасности в лесу Предвыборная программа Шаровой Полины
Предвыборная программа Шаровой Полины Узор в полосе для косынки треугольной формы. 2 класс специальной коррекционной школы
Узор в полосе для косынки треугольной формы. 2 класс специальной коррекционной школы План -конспект урока по химии в 9 классе Ионные уравнения с презентацией
План -конспект урока по химии в 9 классе Ионные уравнения с презентацией Как вывести предприятие из финансового кризиса
Как вывести предприятие из финансового кризиса МЕТОДИЧЕСКИЙ ДОКЛАД и презентация на тему: Нетрадиционные методы обучения или о таинстве простых
МЕТОДИЧЕСКИЙ ДОКЛАД и презентация на тему: Нетрадиционные методы обучения или о таинстве простых Let’s make some pancakes
Let’s make some pancakes