- Модели надежности ПС

Содержание
- 2. Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию. ПС без ошибок
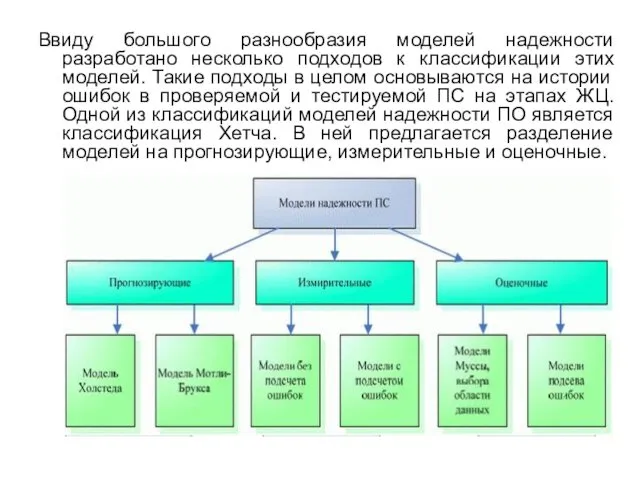
- 3. Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие подходы в целом
- 4. Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число циклов и степень
- 5. Измерительные модели предназначены для измерения надежности программного обеспечения, работающего с заданной внешней средой. Они имеют следующие
- 6. Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC. В тестовой среде
- 7. Другой вид классификации моделей предложил Гоэл, согласно которой модели надежности базируются на отказах и разбиваются на
- 8. Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют спрогнозировать количество ошибок,
- 9. Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в программу искусственных ошибок,
- 10. Классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы: модели, которые рассматривают
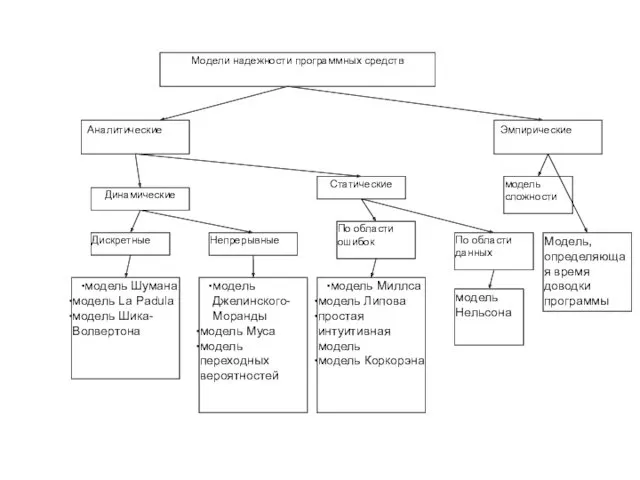
- 12. Аналитические модели дают возможность рассчитать количественные показатели надежности, основываясь на данных о поведении программы в процессе
- 13. Динамические модели Модель La Padula. По этой модели выполнение последовательности тестов производится в m этапов. Каждый
- 14. Модель Джелинского-Моранды. При тестировании фиксируется время до очередного отказа. Основное положение, на котором строится модель, заключается
- 15. Наиболее вероятные значения величин N и C можно определить на основе данных тестирования. Для этого фиксируют
- 16. Модель Шика-Волвертона. Модифицированная модель Джелинского-Моранды для случая возникновения на рассматриваемом интервале более одной ошибки. При этом
- 17. Модель Муса. Считается, что не всякая ошибка ПС может вызвать отказ, поэтому допускается обнаружение более одной
- 18. В модели Муса различают два вида времени: - суммарное время функционирования τ, которое учитывает чистое время
- 19. Один из основных показателей надежности, который рассчитывается по модели Муса, - средняя наработка на отказ. Средняя
- 20. Модель переходных вероятностей. Эта модель основана на марковском процессе. В начальный момент тестирования (t=0) в ПС
- 21. Статические модели надежности программных средств Модель Миллса Использование этой модели предполагает необходимость перед началом тестирования искусственно
- 22. где N – первоначальное число ошибок; S – количество искусственных ошибок; n – число найденных собственных
- 23. Модель Липова Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Вероятность
- 25. Скачать презентацию
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию.
Надежность является функцией от ошибок, оставшихся в ПС после ввода его в эксплуатацию.

Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие
Ввиду большого разнообразия моделей надежности разработано несколько подходов к классификации этих моделей. Такие
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число
Прогнозирующие модели надежности основаны на измерении технических характеристик создаваемой программы: длина, сложность, число

Измерительные модели предназначены для измерения надежности программного обеспечения, работающего с заданной внешней средой.
Измерительные модели предназначены для измерения надежности программного обеспечения, работающего с заданной внешней средой.

Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC.
Оценочные модели основываются на серии тестовых прогонов и проводятся на этапах тестирования ПC.

Другой вид классификации моделей предложил Гоэл, согласно которой модели надежности базируются на отказах
Другой вид классификации моделей предложил Гоэл, согласно которой модели надежности базируются на отказах

Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют
Модели без подсчета ошибок основаны на измерении интервала времени между отказами и позволяют

Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в
Модели с подсевом ошибок основаны на количестве устраненных ошибок и подсеве, внесенном в

Классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
модели,
Классификация моделей роста надежности относительно процесса выявления отказов, фактически разделена на две группы:
модели,

Аналитические модели дают возможность рассчитать количественные показатели надежности, основываясь на данных о поведении
Аналитические модели дают возможность рассчитать количественные показатели надежности, основываясь на данных о поведении

Динамические модели
Модель La Padula. По этой модели выполнение последовательности тестов производится в m
Динамические модели
Модель La Padula. По этой модели выполнение последовательности тестов производится в m

Модель Джелинского-Моранды. При тестировании фиксируется время до очередного отказа. Основное положение, на котором
Модель Джелинского-Моранды. При тестировании фиксируется время до очередного отказа. Основное положение, на котором

Наиболее вероятные значения величин N и C можно определить на основе данных тестирования.
Наиболее вероятные значения величин N и C можно определить на основе данных тестирования.

Модель Шика-Волвертона. Модифицированная модель Джелинского-Моранды для случая возникновения на рассматриваемом интервале более одной
Модель Шика-Волвертона. Модифицированная модель Джелинского-Моранды для случая возникновения на рассматриваемом интервале более одной

Модель Муса. Считается, что не всякая ошибка ПС может вызвать отказ, поэтому допускается
Модель Муса. Считается, что не всякая ошибка ПС может вызвать отказ, поэтому допускается

В модели Муса различают два вида времени:
- суммарное время функционирования τ, которое учитывает
В модели Муса различают два вида времени:
- суммарное время функционирования τ, которое учитывает

Один из основных показателей надежности, который рассчитывается по модели Муса, - средняя наработка
Один из основных показателей надежности, который рассчитывается по модели Муса, - средняя наработка

Модель переходных вероятностей. Эта модель основана на марковском процессе. В начальный момент тестирования
Модель переходных вероятностей. Эта модель основана на марковском процессе. В начальный момент тестирования

Статические модели надежности программных средств
Модель Миллса
Использование этой модели предполагает необходимость перед началом тестирования
Статические модели надежности программных средств
Модель Миллса
Использование этой модели предполагает необходимость перед началом тестирования

где N – первоначальное число ошибок;
S – количество искусственных ошибок;
n – число найденных
где N – первоначальное число ошибок;
S – количество искусственных ошибок;
n – число найденных

Модель Липова
Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа
Модель Липова
Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа

 Внутреннее устройство системного блока пк
Внутреннее устройство системного блока пк Сравнение десятичных дробей
Сравнение десятичных дробей Иммунохимические методы. Иммуноферментный анализ (ИФА )
Иммунохимические методы. Иммуноферментный анализ (ИФА ) Анемии и геморрагические диатезы
Анемии и геморрагические диатезы Бурение нефтяных и газовых скважин
Бурение нефтяных и газовых скважин Правила дорожного движения по сказкам.
Правила дорожного движения по сказкам. Общее имущество собственников помещений в многоквартирном доме. Состав общего имущества в многоквартирном доме
Общее имущество собственников помещений в многоквартирном доме. Состав общего имущества в многоквартирном доме Качественные газеты
Качественные газеты Игорь Иванович Сикорский
Игорь Иванович Сикорский чистые берега
чистые берега Разработка бизнес-плана дизайн-агентства RedGrаy
Разработка бизнес-плана дизайн-агентства RedGrаy Физическая культура, программа Управление и технологии в сфере физической культуры и спорта
Физическая культура, программа Управление и технологии в сфере физической культуры и спорта Комп'ютерний вірус
Комп'ютерний вірус Рискованное поведение подростков. причины, последствия, способы преодоления
Рискованное поведение подростков. причины, последствия, способы преодоления Предметно-развивающая среда в группе
Предметно-развивающая среда в группе Уравнения. Решение задач с помощью уравнений
Уравнения. Решение задач с помощью уравнений Monitorizarea calitatii. Energiei electrice
Monitorizarea calitatii. Energiei electrice Область познания-экспериментирование
Область познания-экспериментирование Портфолио учителя
Портфолио учителя Презентация к уроку географии - 7 класс. Тема: Открытие и исследование Арктики
Презентация к уроку географии - 7 класс. Тема: Открытие и исследование Арктики Физиология кровообращения
Физиология кровообращения Ответственность за нарушение законодательства
Ответственность за нарушение законодательства Логопедический кабинет
Логопедический кабинет Подпорные стенки: назначение и основные конструктивные решения
Подпорные стенки: назначение и основные конструктивные решения Приоритетный региональный проект Муниципальные дороги
Приоритетный региональный проект Муниципальные дороги Курыканы – народ тюркского происхождения
Курыканы – народ тюркского происхождения Геодезия. Топография
Геодезия. Топография Методы оптимизации. Методы последовательного поиска. Метод золотого сечения
Методы оптимизации. Методы последовательного поиска. Метод золотого сечения