- Программная реализация кода с повторением

Содержание
- 2. Вид сигнала кода с повторением
- 3. Перенос данных с листа 1 Sheets("Лист1").Select Период = Sheets("Лист1").Cells(2, 4).Value Длит = Sheets("Лист1").Cells(3, 4).Value ДлинаКода =
- 4. Формирование кода ШагВр = Период / ЧислТочНаПериод For i = 0 To ЧислТочНаПериод - 1 t
- 5. Построение графика периодической функции 'Число точек графика ЧислТочГраф = CInt(ЧислоПовт * ЧислТочНаПериод) ГрафШагВр = ЧислоПовт *
- 8. Подготовка к суммированию повторных сигналов 'Сумма сигналов (повтор) ReDim Sign(16) As Single 'Очистка листа 4 Sheets(4).Select
- 9. 'Перенос на лист 4 For j = 1 To ЧислоПовт - 1 For i = 0
- 10. Вычисление среднего значения по повторам For i = 0 To ЧислТочНаПериод - 1 SSign = 0
- 11. Сигнал + шум после усреднения 2-х выборок
- 12. КОД С ПОВТОРЕНИЕМ И ИНВЕРСИЕЙ Код с повторением и инверсией является систематическим разделимым нециклическим нелинейным (2k,k)-кодом.
- 13. Если, то есть, если число единиц в информационной части кода нечетно, то проверочные символы повторяют информационные
- 14. Процедура обнаружения ошибок Корректирующая способность кода: код позволяет обнаруживать ошибки любой кратности, за исключением таких, когда
- 15. В результате сравнения формируется синдром ошибки S=SrSr-1…Si…S1, Si=1 (i = r÷1), если соответствующие информационные и проверочные
- 16. Процедура обнаружения и формирования синдрома ошибки рассмотрим на следующих примерах: передавалась комбинация Vi=110110. В процессе передачи
- 17. Имеется ошибка четвертой кратности Передавалась комбинация Vi=110110. В процессе передачи искажены первые и третьи символы как
- 18. Вероятность появления ошибок комбинации на выходе устройства обнаружения ошибок при одноразовой передаче комбинации по двоичному симметричному
- 19. КОРРЕЛЯЦИОННЫЙ КОД - КОД С УДВОЕНИЕМ ЭЛЕМЕНТОВ Этот код является разделимым, не систематическим, длины n с
- 20. Процедура построения Строится первичный (обычный двоичный) код длины k. Затем производится его перекодирование по следующему правилу:
- 21. Процедура обнаружения Процедура обнаружения состоит в сравнении символов в парах и формирование по этим проверкам синдрома
- 22. Процедура обнаружения Процедура обнаружения состоит в сравнении символов в парах и формирование по этим проверкам синдрома
- 23. Относительная скорость передачи находится по формуле q = k / n, а избыточность кода И =
- 24. Процедура обнаружения и формирования синдрома ошибки 1) передавалась комбинация 100110. В процессе передачи искажен первый символ,
- 25. Ошибка есть, но она не обнаружена 2) передавалась комбинация Vi = 100110. В процессе передачи искажены
- 26. Вероятность появления ошибочной комбинации Вероятность появления ошибочной комбинации на выходе устройства обнаружения ошибок при одноразовой передаче
- 27. КОД С ПОСТОЯННЫМ ВЕСОМ Этот код является неразделимым, не систематическим, циклическим, нелинейным кодом длины n. Код
- 28. Процедура построения: используя соотношение N ≤ Cnl . Методом подбора для заданного N определяем n и
- 29. Вероятность появления ошибочной комбинации S1 =1, если число единиц nl принятой кодовой комбинации неравно то ошибка
- 30. ЛИНЕЙНЫЕ (n,k)-КОДЫ В классе блоковых разделимых корректирующих кодов различают коды систематические и несистематические. Систематическим называют такой
- 31. Систематический линейный код Двоичный (n,k) – код называется линейным, если его проверочные символы bj (j =
- 32. Закон построения линейного кода Закон построения линейного кода задается совокупностью коэффициентов Cji, число которых k⋅r .
- 33. Линейный систематический код Построить линейный систематический (7,4)-код, заданный следующей совокупностью коэффициентов Cji (всего таких коэффициентов должно
- 34. Проверочные символы находятся по формулам:
- 35. Строим первичный код с числом комбинаций N=2k = 16 и записываем его в таблицу графы 2,3,
- 36. Таблица 1 Таблица 1
- 37. В таблице представлены все N = 24=16 комбинаций первичного кода и одна комбинация корректирующего кода.
- 38. Для другой совокупности коэффициентов Cji был бы получен другой линейный код с тем же или иным
- 39. Характеристики систематического (n,k)-кода на примере (7,4)-кода с совокупностью коэффициентов Cji, приведенных выше, n = 7, k
- 40. По принятым информационным символам на приемной стороне вычисляются проверочные: Вычисленные значения сравниваются с принимаемыми символами bj*.
- 41. Пусть была передана комбинация кода Vi=1001001, а принята Vi* = 1001011, Vi* = a1*a2*a3*a4*b1*b2*b3*. Тогда Сравнение
- 42. Процесс исправления ошибок осуществляется аналогичным способом. Полученный ненулевой синдром, в виде трехзначного двоичного кода указывает позицию,
- 43. ЛИНЕЙНЫЙ НЕ СИСТЕМАТИЧЕКИЙ КОД (КОД ХЭМММИНГА НЕ СИСТЕМАТИЧЕСКИЙ) Этот код является разделимым не систематическим линейным кодом
- 44. Определение числа контрольных символов. Для этого можно воспользоваться следующими рассуждениями. При передаче по каналу с шумами
- 45. Число проверочных символов r в коде Хэмминга в зависимости от числа информационных символов k
- 46. Размещение проверочных символов В принципе место расположения проверочных символов может быть произвольным. Однако, произвольное расположение проверочных
- 47. Пример построения комбинации корректирующего кода. Пусть комбинация первичного кода будет 1001 тогда: a1=1, a2 =0, a3=0,
- 48. Характеристики не систематического (n,k)-кода на примере (7,4)-кода. Код разделимый, длины кода – n Число информационных символов
- 49. Обнаружение ошибок Обнаружение ошибки сводится к проверке выполнения соотношений и нахождению синдрома ошибки для каждой принимаемой
- 50. Пример: Передаваемая комбинация =0011001. Искажен четвертый символ, тогда принятая комбинация: 0010001=b1*b2*a1* b3*a2*a3*a4* Синдром определяется в соответствии
- 53. Скачать презентацию
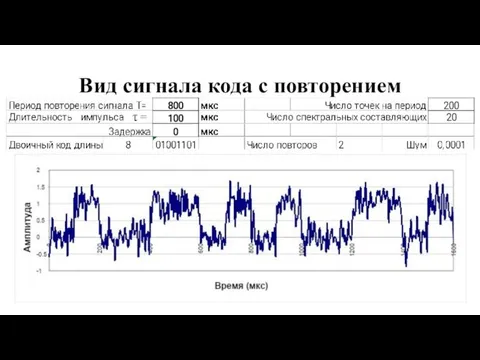
Вид сигнала кода с повторением
Вид сигнала кода с повторением

Перенос данных с листа 1
Sheets("Лист1").Select
Период = Sheets("Лист1").Cells(2, 4).Value
Длит = Sheets("Лист1").Cells(3, 4).Value
Перенос данных с листа 1
Sheets("Лист1").Select
Период = Sheets("Лист1").Cells(2, 4).Value
Длит = Sheets("Лист1").Cells(3, 4).Value

Формирование кода
ШагВр = Период / ЧислТочНаПериод
For i = 0
Формирование кода
ШагВр = Период / ЧислТочНаПериод
For i = 0

Построение графика периодической функции
'Число точек графика
ЧислТочГраф = CInt(ЧислоПовт * ЧислТочНаПериод)
Построение графика периодической функции
'Число точек графика
ЧислТочГраф = CInt(ЧислоПовт * ЧислТочНаПериод)
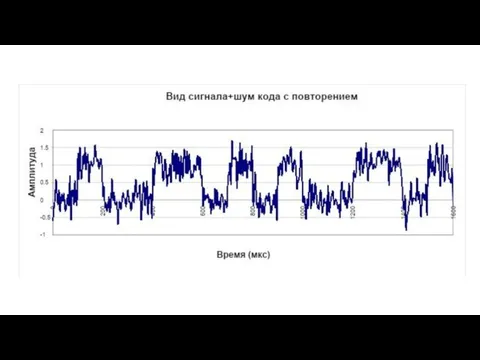
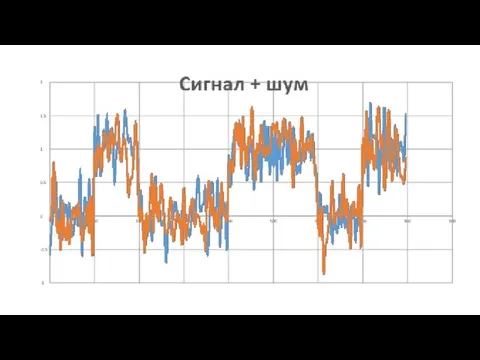

Подготовка к суммированию повторных сигналов
'Сумма сигналов (повтор)
ReDim Sign(16) As Single
'Очистка
Подготовка к суммированию повторных сигналов
'Сумма сигналов (повтор)
ReDim Sign(16) As Single
'Очистка

'Перенос на лист 4
For j = 1 To ЧислоПовт -
'Перенос на лист 4
For j = 1 To ЧислоПовт -

Вычисление среднего значения по повторам
For i = 0 To ЧислТочНаПериод
Вычисление среднего значения по повторам
For i = 0 To ЧислТочНаПериод
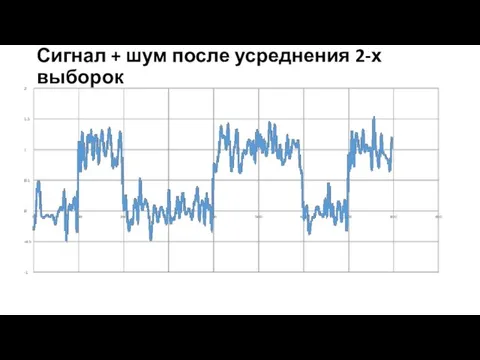
Сигнал + шум после усреднения 2-х выборок
Сигнал + шум после усреднения 2-х выборок

КОД С ПОВТОРЕНИЕМ И ИНВЕРСИЕЙ
Код с повторением и инверсией является систематическим
КОД С ПОВТОРЕНИЕМ И ИНВЕРСИЕЙ
Код с повторением и инверсией является систематическим

Если, то есть, если число единиц в информационной
части кода нечетно,
части кода нечетно,

Процедура обнаружения ошибок
Корректирующая способность кода: код позволяет обнаруживать ошибки любой кратности,
Процедура обнаружения ошибок
Корректирующая способность кода: код позволяет обнаруживать ошибки любой кратности,

В результате сравнения формируется синдром ошибки
S=SrSr-1…Si…S1, Si=1 (i = r÷1),
В результате сравнения формируется синдром ошибки
S=SrSr-1…Si…S1, Si=1 (i = r÷1),

Процедура обнаружения и формирования синдрома ошибки рассмотрим на следующих примерах: передавалась
Процедура обнаружения и формирования синдрома ошибки рассмотрим на следующих примерах: передавалась

Имеется ошибка четвертой кратности
Передавалась комбинация Vi=110110. В процессе передачи искажены первые
Имеется ошибка четвертой кратности
Передавалась комбинация Vi=110110. В процессе передачи искажены первые

Вероятность появления ошибок комбинации на выходе устройства обнаружения ошибок при одноразовой
Вероятность появления ошибок комбинации на выходе устройства обнаружения ошибок при одноразовой

КОРРЕЛЯЦИОННЫЙ КОД - КОД С УДВОЕНИЕМ ЭЛЕМЕНТОВ
Этот код является разделимым, не
КОРРЕЛЯЦИОННЫЙ КОД - КОД С УДВОЕНИЕМ ЭЛЕМЕНТОВ
Этот код является разделимым, не

Процедура построения
Строится первичный (обычный двоичный) код длины k. Затем производится его
Процедура построения
Строится первичный (обычный двоичный) код длины k. Затем производится его

Процедура обнаружения
Процедура обнаружения состоит в сравнении символов в парах и
Процедура обнаружения Процедура обнаружения состоит в сравнении символов в парах и

Процедура обнаружения
Процедура обнаружения состоит в сравнении символов в парах и
Процедура обнаружения
Процедура обнаружения состоит в сравнении символов в парах и

Относительная скорость передачи находится по формуле
q = k / n, а
Относительная скорость передачи находится по формуле
q = k / n, а

Процедура обнаружения и формирования синдрома ошибки
1) передавалась комбинация 100110. В
Процедура обнаружения и формирования синдрома ошибки
1) передавалась комбинация 100110. В

Ошибка есть, но она не обнаружена
2) передавалась комбинация Vi =
Ошибка есть, но она не обнаружена
2) передавалась комбинация Vi =

Вероятность появления ошибочной комбинации
Вероятность появления ошибочной комбинации на выходе устройства обнаружения
Вероятность появления ошибочной комбинации
Вероятность появления ошибочной комбинации на выходе устройства обнаружения

КОД С ПОСТОЯННЫМ ВЕСОМ
Этот код является неразделимым, не систематическим, циклическим, нелинейным
КОД С ПОСТОЯННЫМ ВЕСОМ
Этот код является неразделимым, не систематическим, циклическим, нелинейным

Процедура построения: используя соотношение N ≤ Cnl . Методом подбора для
Процедура построения: используя соотношение N ≤ Cnl . Методом подбора для

Вероятность появления ошибочной комбинации
S1 =1, если число единиц nl принятой
Вероятность появления ошибочной комбинации
S1 =1, если число единиц nl принятой

ЛИНЕЙНЫЕ (n,k)-КОДЫ
В классе блоковых разделимых корректирующих кодов различают коды систематические и
ЛИНЕЙНЫЕ (n,k)-КОДЫ
В классе блоковых разделимых корректирующих кодов различают коды систематические и

Систематический линейный код
Двоичный (n,k) – код называется линейным, если его проверочные
Систематический линейный код
Двоичный (n,k) – код называется линейным, если его проверочные

Закон построения линейного кода
Закон построения линейного кода задается совокупностью коэффициентов Cji,
Закон построения линейного кода
Закон построения линейного кода задается совокупностью коэффициентов Cji,

Линейный систематический код
Построить линейный систематический (7,4)-код, заданный следующей совокупностью коэффициентов Cji
Линейный систематический код
Построить линейный систематический (7,4)-код, заданный следующей совокупностью коэффициентов Cji

Проверочные символы находятся по формулам:
Проверочные символы находятся по формулам:

Строим первичный код с числом комбинаций N=2k = 16 и записываем
Строим первичный код с числом комбинаций N=2k = 16 и записываем
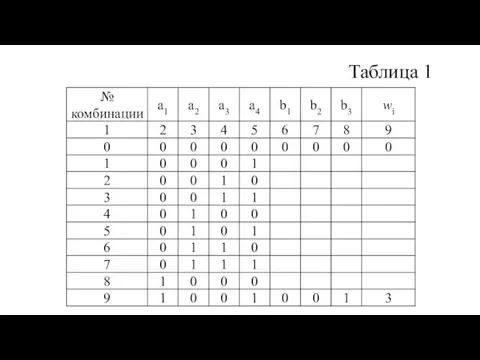
Таблица 1
Таблица 1
Таблица 1
Таблица 1
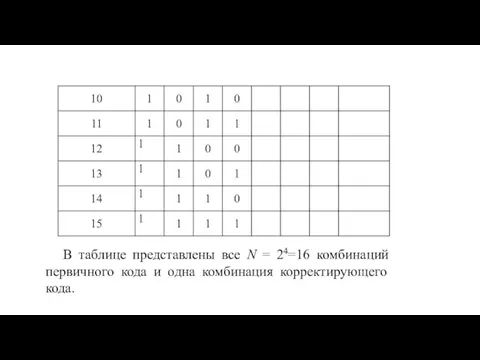
В таблице представлены все N = 24=16 комбинаций первичного кода и
В таблице представлены все N = 24=16 комбинаций первичного кода и

Для другой совокупности коэффициентов Cji был бы получен другой линейный код
Для другой совокупности коэффициентов Cji был бы получен другой линейный код

Характеристики систематического (n,k)-кода на примере (7,4)-кода с совокупностью коэффициентов Cji, приведенных
Характеристики систематического (n,k)-кода на примере (7,4)-кода с совокупностью коэффициентов Cji, приведенных

По принятым информационным символам на приемной стороне вычисляются проверочные:
Вычисленные значения сравниваются
По принятым информационным символам на приемной стороне вычисляются проверочные:
Вычисленные значения сравниваются

Пусть была передана комбинация кода Vi=1001001, а принята Vi* = 1001011,
Пусть была передана комбинация кода Vi=1001001, а принята Vi* = 1001011,

Процесс исправления ошибок осуществляется аналогичным способом. Полученный ненулевой синдром, в виде
Процесс исправления ошибок осуществляется аналогичным способом. Полученный ненулевой синдром, в виде

ЛИНЕЙНЫЙ НЕ СИСТЕМАТИЧЕКИЙ КОД
(КОД ХЭМММИНГА НЕ СИСТЕМАТИЧЕСКИЙ)
Этот код является разделимым не
ЛИНЕЙНЫЙ НЕ СИСТЕМАТИЧЕКИЙ КОД
(КОД ХЭМММИНГА НЕ СИСТЕМАТИЧЕСКИЙ)
Этот код является разделимым не

Определение числа контрольных символов.
Для этого можно воспользоваться следующими рассуждениями. При передаче
Определение числа контрольных символов.
Для этого можно воспользоваться следующими рассуждениями. При передаче
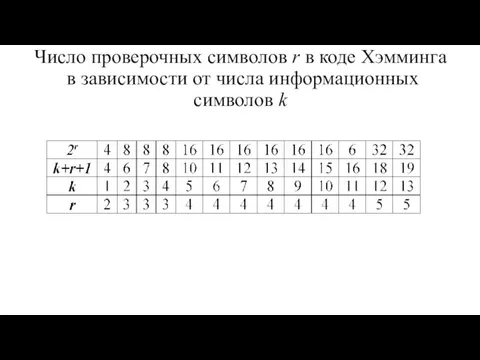
Число проверочных символов r в коде Хэмминга
в зависимости от числа
Число проверочных символов r в коде Хэмминга в зависимости от числа

Размещение проверочных символов
В принципе место расположения проверочных символов может быть произвольным.
Размещение проверочных символов
В принципе место расположения проверочных символов может быть произвольным.

Пример построения комбинации корректирующего кода.
Пусть комбинация первичного кода будет 1001
Пример построения комбинации корректирующего кода.
Пусть комбинация первичного кода будет 1001

Характеристики не систематического (n,k)-кода на примере (7,4)-кода.
Код разделимый, длины кода –
Характеристики не систематического (n,k)-кода на примере (7,4)-кода.
Код разделимый, длины кода –

Обнаружение ошибок
Обнаружение ошибки сводится к проверке выполнения соотношений и нахождению синдрома
Обнаружение ошибок
Обнаружение ошибки сводится к проверке выполнения соотношений и нахождению синдрома

Пример:
Передаваемая комбинация =0011001. Искажен четвертый символ, тогда принятая комбинация:
0010001=b1*b2*a1* b3*a2*a3*a4*
Синдром
Пример:
Передаваемая комбинация =0011001. Искажен четвертый символ, тогда принятая комбинация:
0010001=b1*b2*a1* b3*a2*a3*a4*
Синдром

 Пётр Великий
Пётр Великий Мультиинструмент Arhont. Информация о компании-производителе
Мультиинструмент Arhont. Информация о компании-производителе Холодильник
Холодильник Сельский зеленый туризм в Италии
Сельский зеленый туризм в Италии Акушериядағы жедел іш. Жедел панкреатит және жүктілік
Акушериядағы жедел іш. Жедел панкреатит және жүктілік Презентация Первая женщина-космонавт
Презентация Первая женщина-космонавт Вулканы
Вулканы Сквер Молодежный
Сквер Молодежный Предмет термодинамики
Предмет термодинамики Презентация к уроку окружающего мира Чтобы путь был счастливым 3 класс
Презентация к уроку окружающего мира Чтобы путь был счастливым 3 класс Микроклимат помещений
Микроклимат помещений Современная промышленная архитектура в России
Современная промышленная архитектура в России Умножение и деление натуральных чисел. Урок обобщения
Умножение и деление натуральных чисел. Урок обобщения Приглашение клиентов
Приглашение клиентов Религиозные организации в Российской Федерации
Религиозные организации в Российской Федерации Треугольники. Построение треугольника по трём сторонам. Периметр треугольника. 5 класс,
Треугольники. Построение треугольника по трём сторонам. Периметр треугольника. 5 класс, Проектная деятельность в начальной школе
Проектная деятельность в начальной школе Презентация к проекту Выше, дальше, быстрее
Презентация к проекту Выше, дальше, быстрее Растворы. Концентрация растворов
Растворы. Концентрация растворов iPhone X. Дизайн и дисплей
iPhone X. Дизайн и дисплей Осень-зима GABBI 2014-2015
Осень-зима GABBI 2014-2015 Инструкция по сборке для набора WEDO 2.0 Таракан
Инструкция по сборке для набора WEDO 2.0 Таракан Контроль качества строительной продукции. (Лекция 13)
Контроль качества строительной продукции. (Лекция 13) Учебный материал для подготовки классного часа День народного единства
Учебный материал для подготовки классного часа День народного единства Sergis General Information
Sergis General Information летние деньки
летние деньки Аппликация из ваты
Аппликация из ваты Несеп тасы ауруының қазіргі заманғы аспектілері
Несеп тасы ауруының қазіргі заманғы аспектілері