- Структуры данных

Содержание
- 2. При решении любой задачи возникает необходимость работы с данными и выполнения операций над ними. Некоторый набор
- 3. Очередь Данные обрабатываются в порядке их поступления, принцип FIFO (First In, First Out)
- 4. Очередь поддерживает следующие операции: queue_init – инициализирует (создает пустую) очередь queue_push(x) – добавляет в очередь элемент
- 5. Реализация на базе массива Для хранения данных используется массив Q[0..N], где число N достаточно велико. Данные
- 6. Псевдокод операций, работающих с очередью: queue_init { Head=0 Tail=0 } queue_push(x) { Tail++ Q[Tail]=x } queue_empty
- 7. Все операции над очередью при такой реализации работают за O(1), следовательно, такая реализация эффективна по времени.
- 8. Стек Данные обрабатываются в обратном порядке их поступления, принцип FILO (First In, Last Out)
- 9. Стек поддерживает следующие операции: stack_init – инициализирует (создает пустой) стек stack_push(x) – добавляет в стек элемент
- 10. Реализация на базе массива Для хранения данных используется массив S[0..N], где число N достаточно велико. Данные
- 11. Псевдокод операций, работающих со стеком: stack_init { Top=-1 } stack_push(x) { Top++ S[Top]=x } stack_empty {
- 12. Все операции над стеком при такой реализации работают за O(1), следовательно, такая реализация эффективна по времени.
- 13. Список Список – это структура, в которой данные выписаны в некотором порядке. Порядок определяется указателями, связывающими
- 14. Обычно элемент списка представляет собой запись, содержащую ключ (идентификатор) хранящегося объекта, один или несколько указателей и
- 15. Список поддерживает следующие операции: list_init – инициализирует (создает пустой) список list_find(k) – возвращает true, если в
- 16. Реализация односвязного списка Каждый объект списка хранится как запись, содержащая следующие поля: Key – ключ объекта
- 17. Каждый объект может храниться в виде записи: struct myStruct { int Key; int Data; myStruct*Next; };
- 18. Поиск объекта по ключу: bool list_find(int k) { myStruct *x = Head; while(x != NULL){ if(x->Key
- 19. Вставка объекта в начало списка: void list_insert(myStruct x) { myStruct*new_el= new myStruct; new_el->Key = x->Key; new_el->Data
- 20. Операция list_delete выполняется за O(n), т.к. для ее выполнения нужно найти указатель на удаляемый объект списка,
- 21. Бинарная куча Будем считать, что объекты хранятся в вершинах двоичного дерева. Пронумеруем вершины этого дерева слева
- 22. Свойства: Высота двоичного дерева из N вершин (т.е. максимальное количество ребер на пути от корня к
- 23. Бинарная куча поддерживает следующие операции: heap_init – инициализирует бинарную кучу heap_minimum – возвращает объект с минимальным
- 24. Реализация на базе массива Для хранения данных используется массив H[0..N] Будем говорить что объекты, хранящиеся в
- 25. Рассмотрим операцию heap_insert. Сначала мы помещаем добавляемый объект на первое свободное место дерева. Если окажется, что
- 26. heap_insert(x) { N++, H[N] = x, i = N while (i > 1 && H[i].Key swap(H[i],
- 27. Теперь рассмотрим операцию heap_extract. Сначала перемещаем объект из листа с номером N в корень. Ставший свободным
- 28. heap_extract { res=H[1], H[1]=H[N], N- -, i=1 while(2i if(2i ind = 2i else ind = 2i+1
- 30. Скачать презентацию

При решении любой задачи возникает необходимость работы с данными и выполнения
При решении любой задачи возникает необходимость работы с данными и выполнения
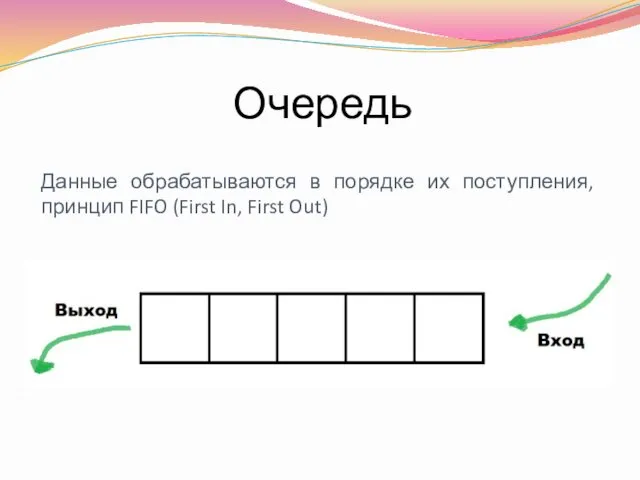
Очередь
Данные обрабатываются в порядке их поступления, принцип FIFO (First In, First
Очередь
Данные обрабатываются в порядке их поступления, принцип FIFO (First In, First

Очередь поддерживает следующие операции:
queue_init – инициализирует (создает пустую) очередь
queue_push(x)
Очередь поддерживает следующие операции:
queue_init – инициализирует (создает пустую) очередь
queue_push(x)
![Реализация на базе массива Для хранения данных используется массив Q[0..N],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/69253/slide-4.jpg)
Реализация на базе массива
Для хранения данных используется массив Q[0..N], где
Реализация на базе массива
Для хранения данных используется массив Q[0..N], где

Псевдокод операций, работающих с очередью:
queue_init {
Head=0
Tail=0
}
queue_push(x) {
Tail++
Q[Tail]=x
}
queue_empty
Псевдокод операций, работающих с очередью:
queue_init {
Head=0
Tail=0
}
queue_push(x) {
Tail++
Q[Tail]=x
}
queue_empty

Все операции над очередью при такой реализации работают за O(1), следовательно,
Все операции над очередью при такой реализации работают за O(1), следовательно,
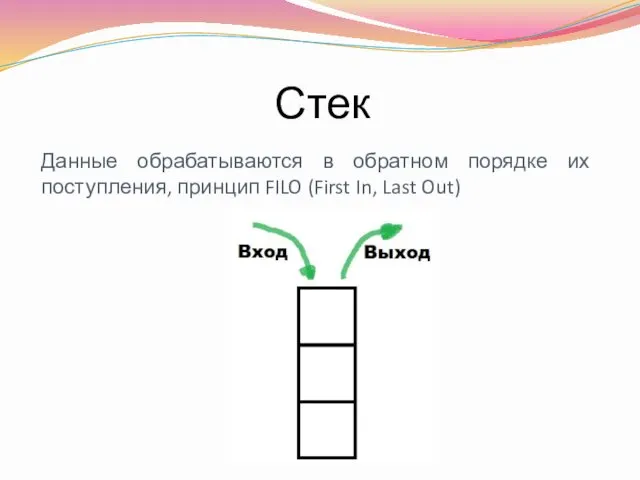
Стек
Данные обрабатываются в обратном порядке их поступления, принцип FILO (First In,
Стек
Данные обрабатываются в обратном порядке их поступления, принцип FILO (First In,

Стек поддерживает следующие операции:
stack_init – инициализирует (создает пустой) стек
stack_push(x)
Стек поддерживает следующие операции:
stack_init – инициализирует (создает пустой) стек
stack_push(x)
![Реализация на базе массива Для хранения данных используется массив S[0..N],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/69253/slide-9.jpg)
Реализация на базе массива
Для хранения данных используется массив S[0..N], где
Реализация на базе массива
Для хранения данных используется массив S[0..N], где

Псевдокод операций, работающих со стеком:
stack_init {
Top=-1
}
stack_push(x) {
Top++
S[Top]=x
}
stack_empty {
Псевдокод операций, работающих со стеком:
stack_init {
Top=-1
}
stack_push(x) {
Top++
S[Top]=x
}
stack_empty {

Все операции над стеком при такой реализации работают за O(1), следовательно,
Все операции над стеком при такой реализации работают за O(1), следовательно,
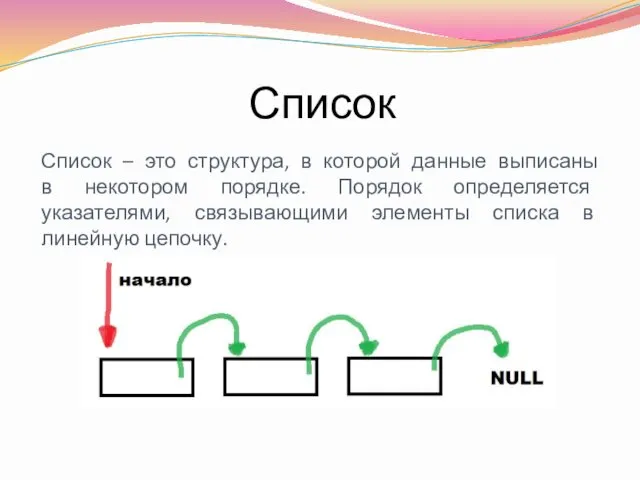
Список
Список – это структура, в которой данные выписаны в некотором порядке.
Список
Список – это структура, в которой данные выписаны в некотором порядке.

Обычно элемент списка представляет собой запись, содержащую ключ (идентификатор) хранящегося объекта,
Обычно элемент списка представляет собой запись, содержащую ключ (идентификатор) хранящегося объекта,

Список поддерживает следующие операции:
list_init – инициализирует (создает пустой) список
list_find(k)
Список поддерживает следующие операции:
list_init – инициализирует (создает пустой) список
list_find(k)

Реализация односвязного списка
Каждый объект списка хранится как запись, содержащая следующие
Реализация односвязного списка
Каждый объект списка хранится как запись, содержащая следующие

Каждый объект может храниться в виде записи:
struct myStruct {
int Key;
Каждый объект может храниться в виде записи:
struct myStruct {
int Key;

Поиск объекта по ключу:
bool list_find(int k) {
myStruct *x = Head;
Поиск объекта по ключу:
bool list_find(int k) {
myStruct *x = Head;

Вставка объекта в начало списка:
void list_insert(myStruct x) {
myStruct*new_el= new myStruct;
Вставка объекта в начало списка:
void list_insert(myStruct x) {
myStruct*new_el= new myStruct;

Операция list_delete выполняется за O(n), т.к. для ее выполнения нужно найти
Операция list_delete выполняется за O(n), т.к. для ее выполнения нужно найти
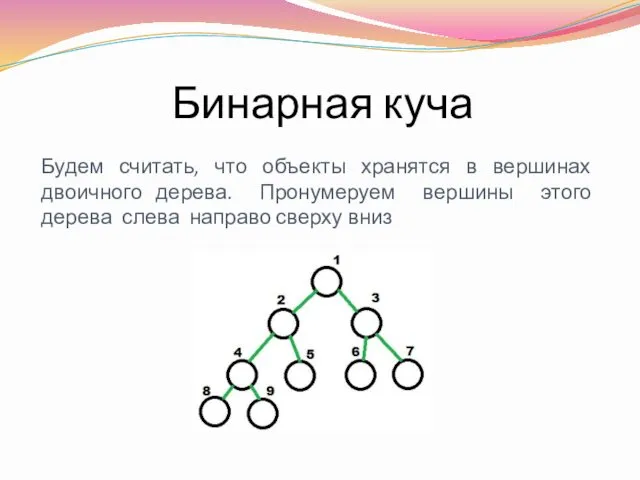
Бинарная куча
Будем считать, что объекты хранятся в вершинах двоичного дерева. Пронумеруем
Бинарная куча
Будем считать, что объекты хранятся в вершинах двоичного дерева. Пронумеруем

Свойства:
Высота двоичного дерева из N вершин (т.е. максимальное количество ребер
Свойства:
Высота двоичного дерева из N вершин (т.е. максимальное количество ребер

Бинарная куча поддерживает следующие операции:
heap_init – инициализирует бинарную кучу
heap_minimum
Бинарная куча поддерживает следующие операции:
heap_init – инициализирует бинарную кучу
heap_minimum
![Реализация на базе массива Для хранения данных используется массив H[0..N]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/69253/slide-23.jpg)
Реализация на базе массива
Для хранения данных используется массив H[0..N]
Будем
Реализация на базе массива
Для хранения данных используется массив H[0..N]
Будем

Рассмотрим операцию heap_insert.
Сначала мы помещаем добавляемый объект на первое свободное
Рассмотрим операцию heap_insert.
Сначала мы помещаем добавляемый объект на первое свободное
![heap_insert(x) { N++, H[N] = x, i = N while](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/69253/slide-25.jpg)
heap_insert(x) {
N++, H[N] = x, i = N
while (i
heap_insert(x) {
N++, H[N] = x, i = N
while (i

Теперь рассмотрим операцию heap_extract.
Сначала перемещаем объект из листа с номером N
Теперь рассмотрим операцию heap_extract.
Сначала перемещаем объект из листа с номером N
![heap_extract { res=H[1], H[1]=H[N], N- -, i=1 while(2i if(2i ind](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/69253/slide-27.jpg)
heap_extract {
res=H[1], H[1]=H[N], N- -, i=1
while(2i if(2i
heap_extract {
res=H[1], H[1]=H[N], N- -, i=1
while(2i
 Алкогольное отравление. Токсичность этанола
Алкогольное отравление. Токсичность этанола Уральский экономический район. 9класс
Уральский экономический район. 9класс Хобби игра в футбол
Хобби игра в футбол ВКР: Ремонт тормозной системы автомобиля Chevrolet Niva
ВКР: Ремонт тормозной системы автомобиля Chevrolet Niva Современное состояние и перспективы развития скоростных и особо грузонапряженных линий на сети ОАО РЖД
Современное состояние и перспективы развития скоростных и особо грузонапряженных линий на сети ОАО РЖД Структурная схема ДЗ (эсэ)
Структурная схема ДЗ (эсэ) Антифриз и тосол. Технические жидкости системы охлаждения двигателя
Антифриз и тосол. Технические жидкости системы охлаждения двигателя Memory Game 05 (Things at home)
Memory Game 05 (Things at home) Экспертные системы в области права
Экспертные системы в области права Формы и виды гнутоклееных заготовок для мебели
Формы и виды гнутоклееных заготовок для мебели Некоммерческая общественная организация Санкт-Петербургский благотворительный фонд для инвалидов имени Марка Тайманова
Некоммерческая общественная организация Санкт-Петербургский благотворительный фонд для инвалидов имени Марка Тайманова Бойове застосування КЗА 86Ж6. Організація обчислювального процесу. (Тема 8.2)
Бойове застосування КЗА 86Ж6. Організація обчислювального процесу. (Тема 8.2) ФГОС ДО как основной ориентир обеспечения развития системы качества дошкольного образования в РФ.
ФГОС ДО как основной ориентир обеспечения развития системы качества дошкольного образования в РФ. Федеральный закон Об образовании в Российской Федерацииот 29 декабря 2012 года.
Федеральный закон Об образовании в Российской Федерацииот 29 декабря 2012 года. Основы написания и публикации научных статей
Основы написания и публикации научных статей Визуальный ряд Ромео и Джульетта
Визуальный ряд Ромео и Джульетта Целостный педагогический процесс
Целостный педагогический процесс Театр для всех
Театр для всех Пампа
Пампа Материаловедение. Теория сплавов. (Тема 6)
Материаловедение. Теория сплавов. (Тема 6) Кафе быстрого обслуживания Dio Cafe
Кафе быстрого обслуживания Dio Cafe Дифференцирование функции одного аргумента. Производная
Дифференцирование функции одного аргумента. Производная Животный мир Северной Америки
Животный мир Северной Америки Использование интерактивной доски на уроках химии.
Использование интерактивной доски на уроках химии. Расы и этносы
Расы и этносы Государственный исторический музей
Государственный исторический музей Конкурс 3D БУМ. Путь инженера начинается в школе
Конкурс 3D БУМ. Путь инженера начинается в школе Линейная перспектива. Правила построения фронтальной и угловой перспективы. 6 класс
Линейная перспектива. Правила построения фронтальной и угловой перспективы. 6 класс