Высокопроизводительные вычисления. Базовые методы ускорения вычислений, основные понятия распараллеливания презентация
- Высокопроизводительные вычисления. Базовые методы ускорения вычислений, основные понятия распараллеливания

Содержание
- 2. Факторы, определяющие время исполнения программных функций Свойства аппаратно-программной платформы Возможности программиста в полной мере использовать свойства
- 3. Наиболее важные свойства аппаратно-программных платформ, влияющие на быстродействие программ Параметры различных видов памяти и механизмы их
- 4. Два способа ускорения быстродействия машин Повышение частоты + Увеличение памяти: Увеличение частоты в к раз k*F
- 5. История параллельности: многоразрядность IBM 701 (1953), IBM 704 (1955): разрядно-параллельная память, разрядно-параллельная арифметика. Все самые первые
- 6. История параллельности: распараллеливание ввода-вывода IBM 709 (1958): независимые процессоры ввода/вывода. Процессоры первых компьютеров сами управляли вводом/выводом.
- 7. История параллельности: конвейер команд ATLAS (1963): конвейер команд. Впервые конвейерный принцип выполнения команд был использован в
- 8. История параллельности: независимые функциональные устройства CDC 6600 (1964): независимые функциональные устройства. Фирма Control Data Corporation (CDC)
- 9. История параллельности: независимые функциональные устройства CDC 6600 (1964): независимые функциональные устройства. Фирма Control Data Corporation (CDC)
- 10. История параллельности: конвейерные независимые функциональные устройства CDC 7600 (1969): конвейерные независимые функциональные устройства. CDC выпускает компьютер
- 11. История параллельности: матричные процессоры ILLIAC IV (1974): матричные процессоры. Проект: 256 процессорных элементов (ПЭ) = 4
- 12. История параллельности: векторно-конвейерные процессоры CRAY 1 (1976): векторно-конвейерные процессоры В 1972 году С.Крэй покидает CDC и
- 13. Основные понятия распараллеливания: уровни параллелизма и гранулярность Уровни параллелизма: Уровень заданий – несколько независимых заданий одновременно
- 14. Основные метрики параллелизма: профиль параллелизма Степень параллелизма (DOP – Degree of Parallelism) – это число участвующих
- 15. Основные понятия распараллеливания: общий объем вычислительной работы и средний параллелизм Общий объем вычислительной работы W в
- 16. Основные понятия распараллеливания: Степень ускорения - Speedup Ускорение (speedup) за счет параллельного выполнения: S(n) =T(1)/T(n), где
- 17. Основные понятия распараллеливания: эффективность и избыточность Эффективность (efficiency) n-процессорной системы – ускорение, приходящееся на один процессор:
- 18. Распараллеливание: Закон Амдала (1967)
- 19. Распараллеливание: Закон Амдала
- 20. Распараллеливание: Закон Амдала
- 21. Распараллеливание: Закон Амдала – зависимость ускорения от доли f и n
- 22. Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса
- 23. Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса
- 24. Распараллеливание: Сопоставление ускорения по Амдалу и по Густафсону-Барсису Пусть доля последовательной части f = 0,1 //
- 25. Классификация параллельных систем по Флинну Профессор Стенфорда Майкл Флинн в 1966 году предложил классифицировать параллельные системы
- 26. Архитектура базовых классов параллельных систем а) SIMD; б) MISD; в) SIMD; г) MIMD
- 27. Архитектура параллельных систем с общей памятью SM-MIMD
- 28. Архитектура параллельных систем с общей памятью DM-MIMD
- 30. Скачать презентацию

Факторы, определяющие время исполнения программных функций
Свойства аппаратно-программной платформы
Возможности программиста в полной
Факторы, определяющие время исполнения программных функций
Свойства аппаратно-программной платформы
Возможности программиста в полной

Наиболее важные свойства аппаратно-программных платформ, влияющие на быстродействие программ
Параметры различных видов
Наиболее важные свойства аппаратно-программных платформ, влияющие на быстродействие программ
Параметры различных видов

Два способа ускорения быстродействия машин
Повышение частоты + Увеличение памяти:
Увеличение
Два способа ускорения быстродействия машин
Повышение частоты + Увеличение памяти:
Увеличение

История параллельности:
многоразрядность
IBM 701 (1953), IBM 704 (1955): разрядно-параллельная память, разрядно-параллельная
История параллельности:
многоразрядность
IBM 701 (1953), IBM 704 (1955): разрядно-параллельная память, разрядно-параллельная

История параллельности:
распараллеливание ввода-вывода
IBM 709 (1958): независимые процессоры ввода/вывода.
Процессоры первых компьютеров
История параллельности:
распараллеливание ввода-вывода
IBM 709 (1958): независимые процессоры ввода/вывода. Процессоры первых компьютеров

История параллельности:
конвейер команд
ATLAS (1963): конвейер команд.
Впервые конвейерный принцип выполнения команд
История параллельности:
конвейер команд
ATLAS (1963): конвейер команд. Впервые конвейерный принцип выполнения команд

История параллельности:
независимые функциональные устройства
CDC 6600 (1964): независимые функциональные устройства.
Фирма
История параллельности:
независимые функциональные устройства
CDC 6600 (1964): независимые функциональные устройства. Фирма

История параллельности:
независимые функциональные устройства
CDC 6600 (1964): независимые функциональные устройства.
Фирма
История параллельности:
независимые функциональные устройства
CDC 6600 (1964): независимые функциональные устройства. Фирма

История параллельности:
конвейерные независимые функциональные устройства
CDC 7600 (1969): конвейерные независимые функциональные
История параллельности:
конвейерные независимые функциональные устройства
CDC 7600 (1969): конвейерные независимые функциональные

История параллельности:
матричные процессоры
ILLIAC IV (1974): матричные процессоры.
Проект: 256 процессорных элементов
История параллельности:
матричные процессоры
ILLIAC IV (1974): матричные процессоры.
Проект: 256 процессорных элементов

История параллельности:
векторно-конвейерные процессоры
CRAY 1 (1976): векторно-конвейерные процессоры
В 1972 году С.Крэй
История параллельности:
векторно-конвейерные процессоры
CRAY 1 (1976): векторно-конвейерные процессоры В 1972 году С.Крэй

Основные понятия распараллеливания:
уровни параллелизма и гранулярность
Уровни параллелизма:
Уровень заданий –
Основные понятия распараллеливания:
уровни параллелизма и гранулярность
Уровни параллелизма:
Уровень заданий –
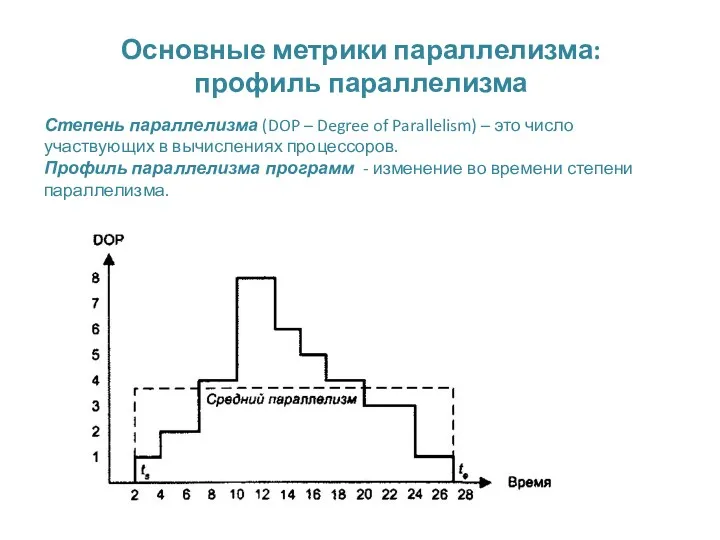
Основные метрики параллелизма:
профиль параллелизма
Степень параллелизма (DOP – Degree of Parallelism)
Основные метрики параллелизма:
профиль параллелизма
Степень параллелизма (DOP – Degree of Parallelism)

Основные понятия распараллеливания:
общий объем вычислительной работы и средний параллелизм
Общий объем
Основные понятия распараллеливания:
общий объем вычислительной работы и средний параллелизм
Общий объем

Основные понятия распараллеливания: Степень ускорения - Speedup
Ускорение (speedup) за счет параллельного
Основные понятия распараллеливания: Степень ускорения - Speedup
Ускорение (speedup) за счет параллельного

Основные понятия распараллеливания: эффективность и избыточность
Эффективность (efficiency) n-процессорной системы – ускорение,
Основные понятия распараллеливания: эффективность и избыточность
Эффективность (efficiency) n-процессорной системы – ускорение,
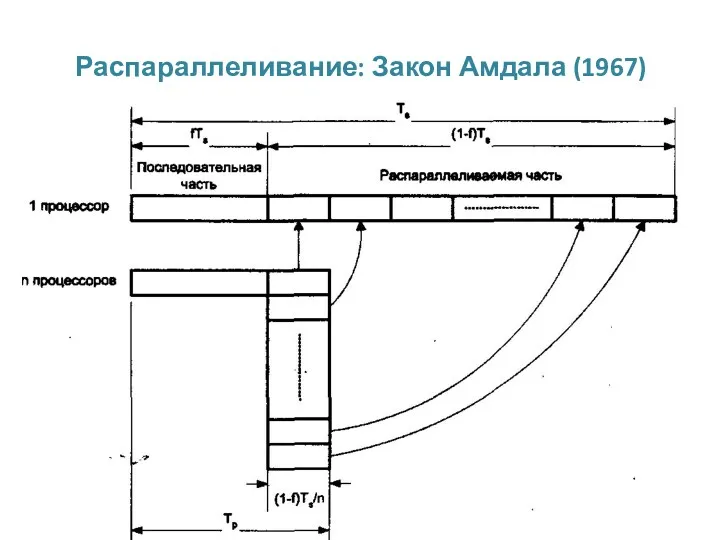
Распараллеливание: Закон Амдала (1967)
Распараллеливание: Закон Амдала (1967)

Распараллеливание: Закон Амдала
Распараллеливание: Закон Амдала
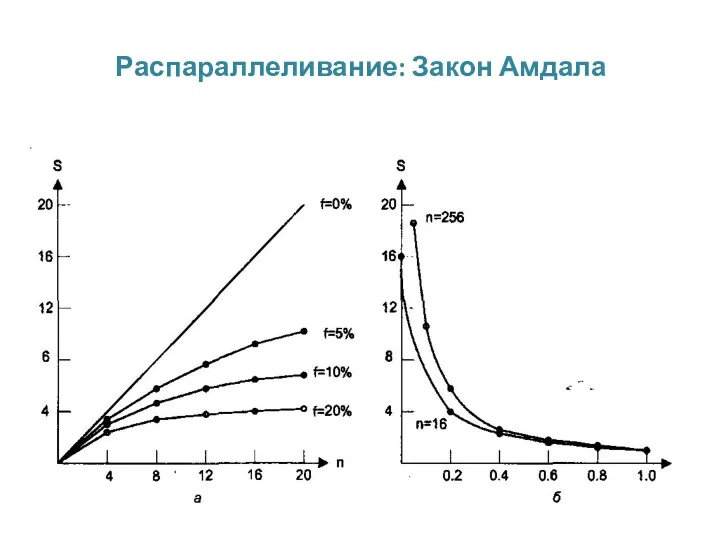
Распараллеливание: Закон Амдала
Распараллеливание: Закон Амдала

Распараллеливание: Закон Амдала – зависимость ускорения от доли f и n
Распараллеливание: Закон Амдала – зависимость ускорения от доли f и n
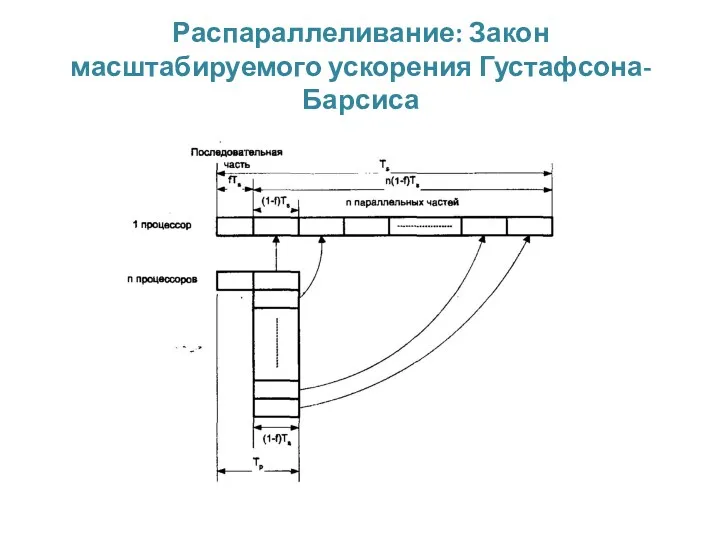
Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса
Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса

Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса
Распараллеливание: Закон масштабируемого ускорения Густафсона-Барсиса
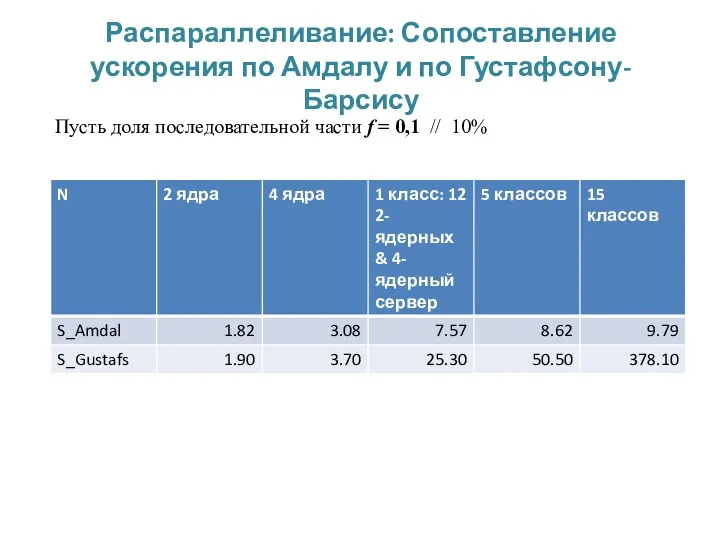
Распараллеливание: Сопоставление ускорения по Амдалу и по Густафсону-Барсису
Пусть доля последовательной части
Распараллеливание: Сопоставление ускорения по Амдалу и по Густафсону-Барсису
Пусть доля последовательной части

Классификация параллельных систем по Флинну
Профессор Стенфорда Майкл Флинн в 1966 году
Классификация параллельных систем по Флинну
Профессор Стенфорда Майкл Флинн в 1966 году
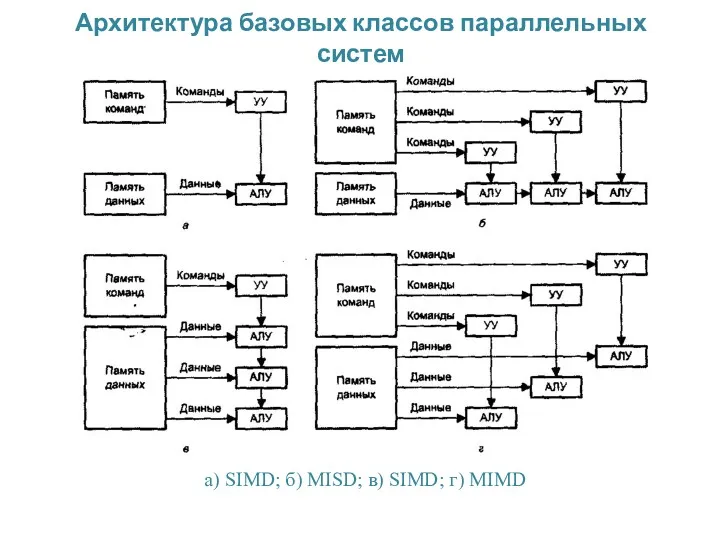
Архитектура базовых классов параллельных систем
а) SIMD; б) MISD; в) SIMD; г)
Архитектура базовых классов параллельных систем
а) SIMD; б) MISD; в) SIMD; г)

Архитектура параллельных систем с общей памятью
SM-MIMD
Архитектура параллельных систем с общей памятью
SM-MIMD
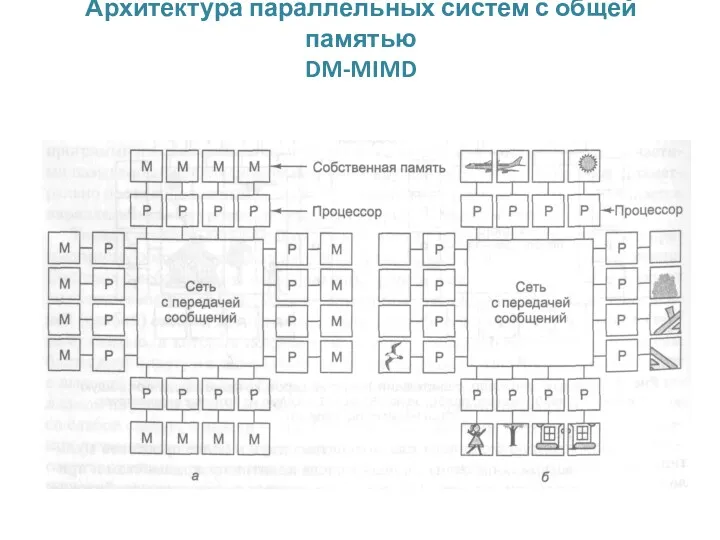
Архитектура параллельных систем с общей памятью
DM-MIMD
Архитектура параллельных систем с общей памятью
DM-MIMD
 Педагогическое общение
Педагогическое общение Презентация. Православные праздники русского народа.
Презентация. Православные праздники русского народа. Классный час Секреты Ромео и Джульетты
Классный час Секреты Ромео и Джульетты Векторная алгебра. Лекционно-практические занятия
Векторная алгебра. Лекционно-практические занятия Особенности коррозии в морской воде
Особенности коррозии в морской воде Строительные материалы и изделия
Строительные материалы и изделия Музейная педагогика
Музейная педагогика Встреча – медитация по сакральной геометрии
Встреча – медитация по сакральной геометрии Элементы внешней среды. АО Костромской завод автокомпонентов
Элементы внешней среды. АО Костромской завод автокомпонентов презентация к проекту Вагоны грузовогои пассажирского парков
презентация к проекту Вагоны грузовогои пассажирского парков Дөңгелек ауыздылар мен сүйекті балықтар кластарының систематикалық топтарын анықтаудын әдістері
Дөңгелек ауыздылар мен сүйекті балықтар кластарының систематикалық топтарын анықтаудын әдістері Техническое обслуживание железнодорожного пути
Техническое обслуживание железнодорожного пути Тема урока: Австралия – страна-материк
Тема урока: Австралия – страна-материк Судебно-психиатрическая экспертиза
Судебно-психиатрическая экспертиза Отрасли производства
Отрасли производства Автомобили
Автомобили Кольчурина А.С. СОШ №21
Кольчурина А.С. СОШ №21 Африка: рельеф, тектоническое строение, полезные ископаемые
Африка: рельеф, тектоническое строение, полезные ископаемые Клещевой сыпной тиф Северной Азии
Клещевой сыпной тиф Северной Азии Что такое дружба
Что такое дружба Влияние музыки на речевое развитие детей
Влияние музыки на речевое развитие детей Театрализованная деятельность в первой младшей группе
Театрализованная деятельность в первой младшей группе С днем рождения
С днем рождения Методическая разработка урока химии для 9 класса в соответствии с требованиями ФГОС второго поколения.Тема:Предельные углеводороды(мультимедийное сопровождение)
Методическая разработка урока химии для 9 класса в соответствии с требованиями ФГОС второго поколения.Тема:Предельные углеводороды(мультимедийное сопровождение) Welcome to the Zoo
Welcome to the Zoo Комплекс упражнений для разминки баскетболиста
Комплекс упражнений для разминки баскетболиста Методы экономического анализа
Методы экономического анализа Презентация Птицы перелетные в дорогу собираются… Диск
Презентация Птицы перелетные в дорогу собираются… Диск