- The Last Day

Содержание
- 2. Goals Take unmodified POSIX/Win32 applications . . . Run those applications in the cloud . .
- 3. Goals MapReduce Throughput > 1000 MB/s Scale-out architecture using commodity parts Take unmodified POSIX/Win32 applications .
- 4. Why Do I Want To Do This? Write POSIX/Win32 app once, automagically have fast cloud version
- 5. Naïve Solution: Network RAID
- 6. The naïve approach for implementing virtual disks does not maximize spindle parallelism for POSIX/Win32 applications which
- 7. LISTEN
- 8. Internet . . . Intermediate switch Intermediate switch Intermediate switch Intermediate switch Intermediate switch Intermediate switch
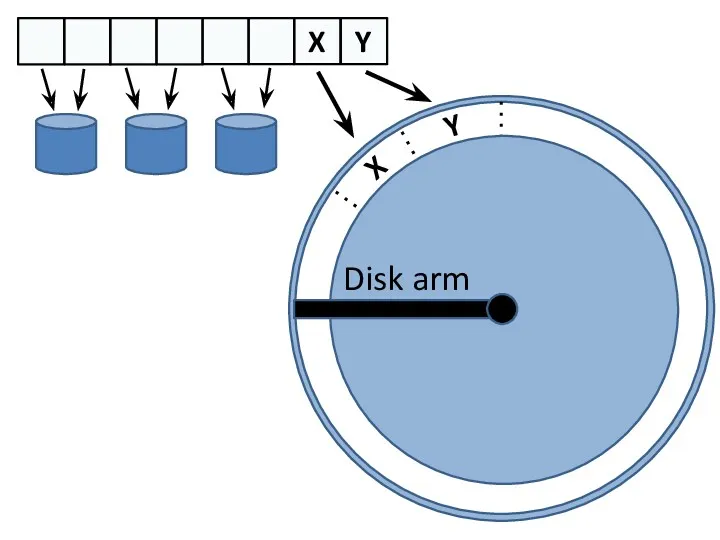
- 9. X Y Virtual disk Remote disks
- 10. X Y X Y Virtual disk Remote disks Disk arm
- 11. X Y Disk arm X Y
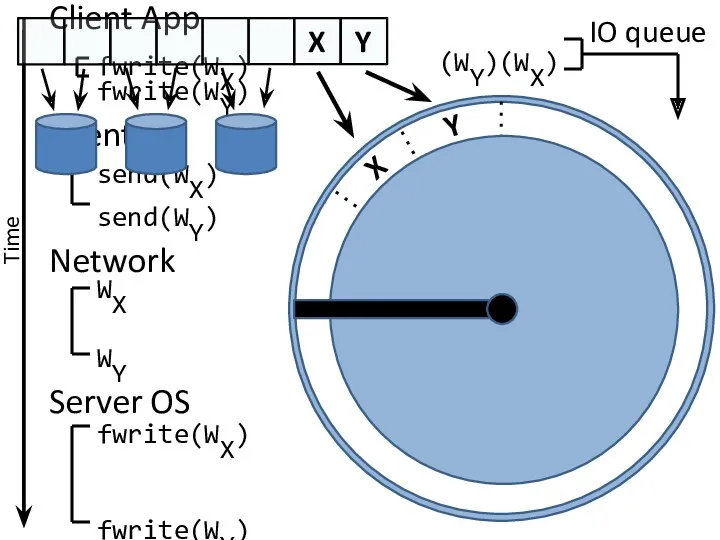
- 12. X Y (WX) (WY) X Y
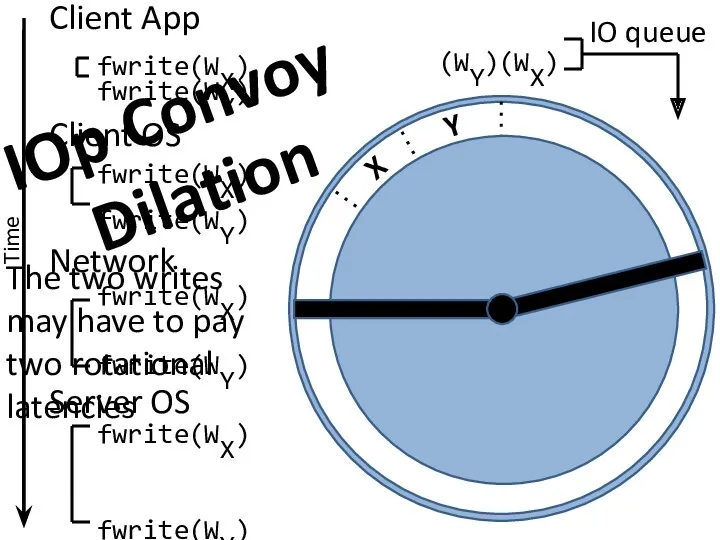
- 13. X Y (WX) (WY) IOp Convoy Dilation The two writes may have to pay two rotational
- 14. Fixing IOp Convoy Dilation Virtual drive Remote disks
- 15. Fixing IOp Convoy Dilation Random *and* sequential IOs hit multiple spindles in parallel—seeks and rotational latencies
- 16. Rack Locality 10 Gbps to all rack peers 10 Gbps to all rack peers 20 Gbps
- 17. Rack Locality In A Datacenter Remote disks
- 18. Flat Datacenter Storage (FDS) Idea 1: Build a datacenter network with full-bisection bandwidth (i.e., no oversubscription)
- 19. Blizzard as FDS Client Blizzard client handles: Nested striping Delayed durability semantics
- 20. The problem with fsync() Used by POSIX/Win32 file systems and applications to implement crash consistency On-disk
- 21. WRITE BARRIERS RUIN BIRTHDAYS Stalled operations limit parallelism!
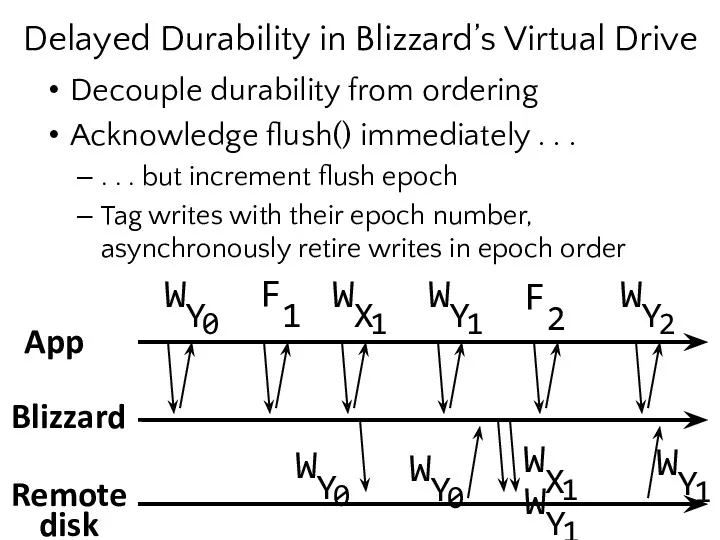
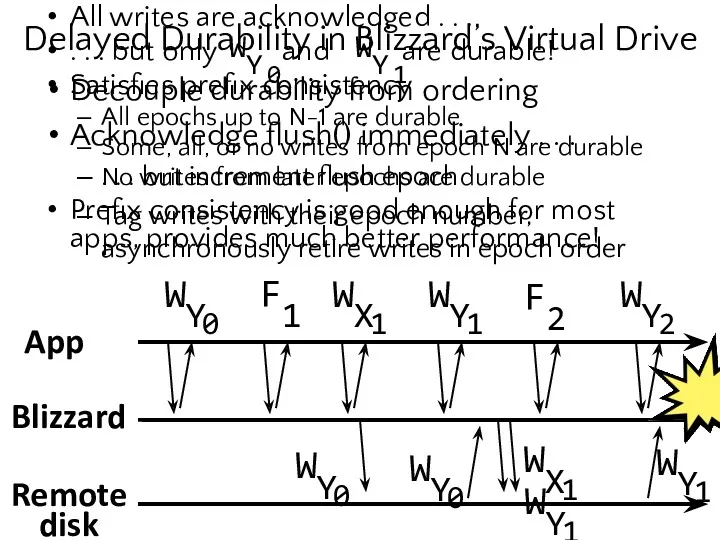
- 22. Delayed Durability in Blizzard’s Virtual Drive Decouple durability from ordering Acknowledge flush() immediately . . .
- 23. Decouple durability from ordering Acknowledge flush() immediately . . . . . . but increment flush
- 24. App F1 F2 Blizzard Remote disk All writes are acknowledged . . . . . .
- 25. Isn’t Blizzard buffering a lot of data? Epoch 0 Epoch 1 Epoch 2 Epoch 3 In
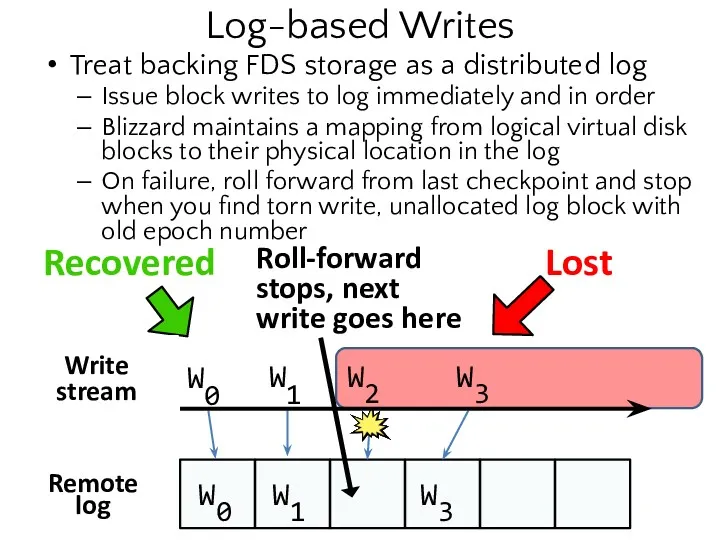
- 26. Log-based Writes Treat backing FDS storage as a distributed log Issue block writes to log immediately
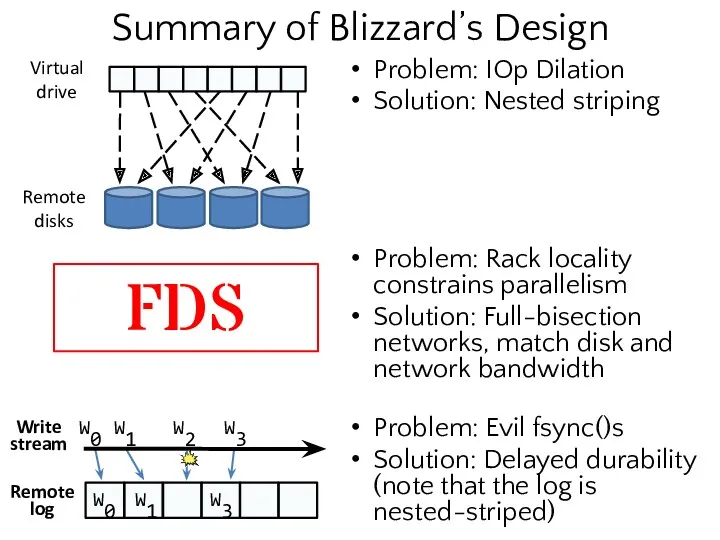
- 27. Summary of Blizzard’s Design Problem: IOp Dilation Solution: Nested striping Problem: Rack locality constrains parallelism Solution:
- 28. Throughput Microbenchmark Application issues a bunch of parallel reads or writes In this experiment, we use
- 29. Application Macrobenchmarks (Write-through, Single Replication)
- 31. Скачать презентацию

Goals
Take unmodified POSIX/Win32 applications . . .
Run those applications in the
Goals
Take unmodified POSIX/Win32 applications . . .
Run those applications in the
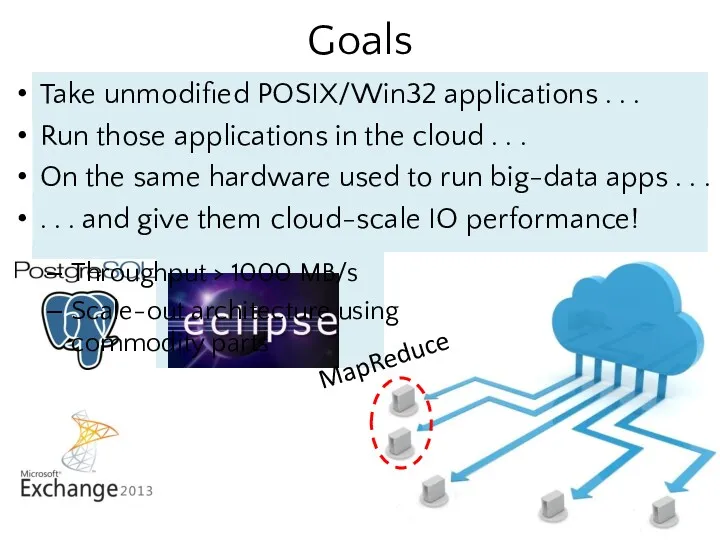
Goals
MapReduce
Throughput > 1000 MB/s
Scale-out architecture using commodity parts
Take unmodified POSIX/Win32 applications
Goals
MapReduce
Throughput > 1000 MB/s
Scale-out architecture using commodity parts
Take unmodified POSIX/Win32 applications

Why Do I Want To Do This?
Write POSIX/Win32 app once, automagically
Why Do I Want To Do This?
Write POSIX/Win32 app once, automagically
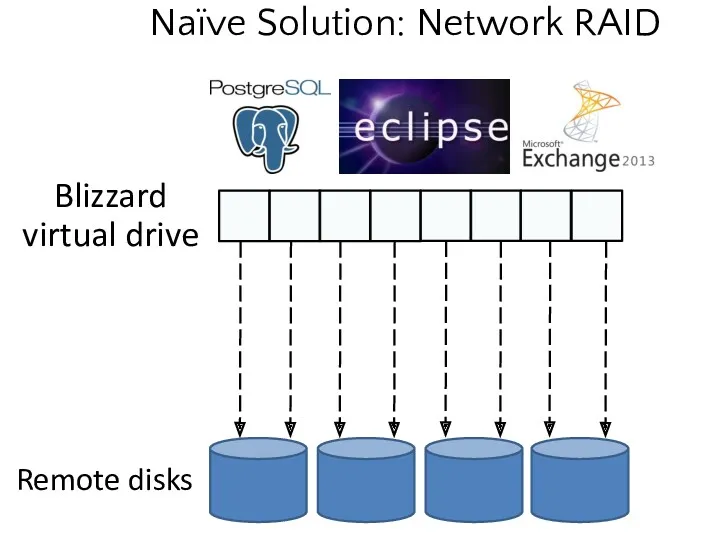
Naïve Solution: Network RAID
Naïve Solution: Network RAID

The naïve approach for implementing virtual disks does not maximize spindle
The naïve approach for implementing virtual disks does not maximize spindle

LISTEN
LISTEN

Internet
. . .
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
IP router
IP router
Datacenter
boundary
Internet
. . .
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
Intermediate switch
IP router
IP router
Datacenter
boundary
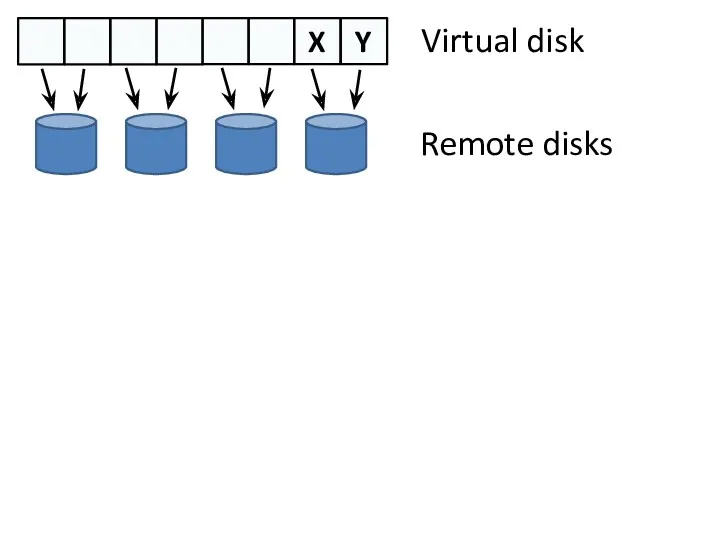
X
Y
Virtual disk
Remote disks
X
Y
Virtual disk
Remote disks
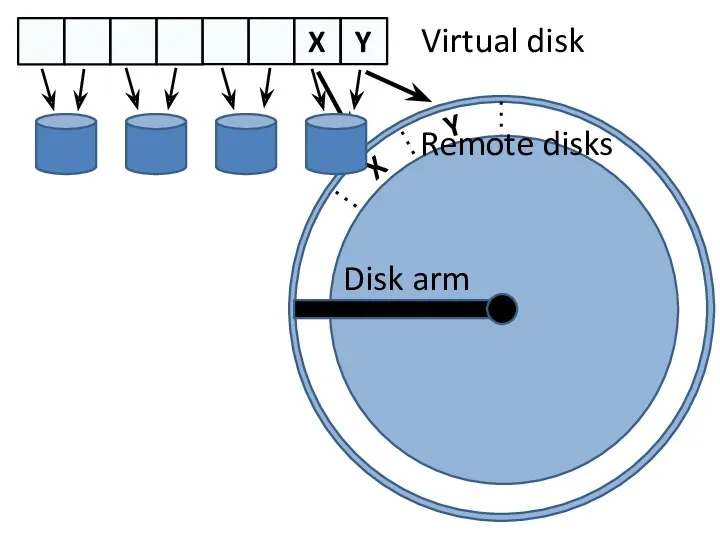
X
Y
X
Y
Virtual disk
Remote disks
Disk arm
X
Y
X
Y
Virtual disk
Remote disks
Disk arm
X
Y
Disk arm
X
Y
X
Y
Disk arm
X
Y
X
Y
(WX)
(WY)
X
Y
X
Y
(WX)
(WY)
X
Y
X
Y
(WX)
(WY)
IOp Convoy
Dilation
The two writes may have to pay two rotational
X
Y
(WX)
(WY)
IOp Convoy
Dilation
The two writes may have to pay two rotational
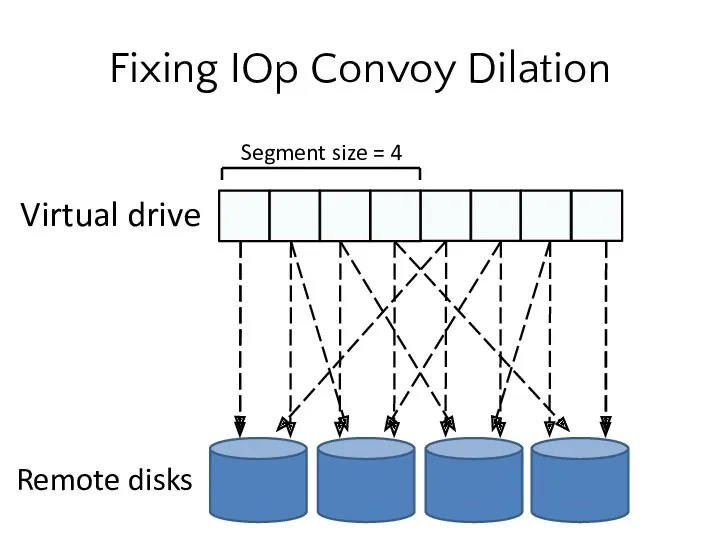
Fixing IOp Convoy Dilation
Virtual drive
Remote disks
Fixing IOp Convoy Dilation
Virtual drive
Remote disks
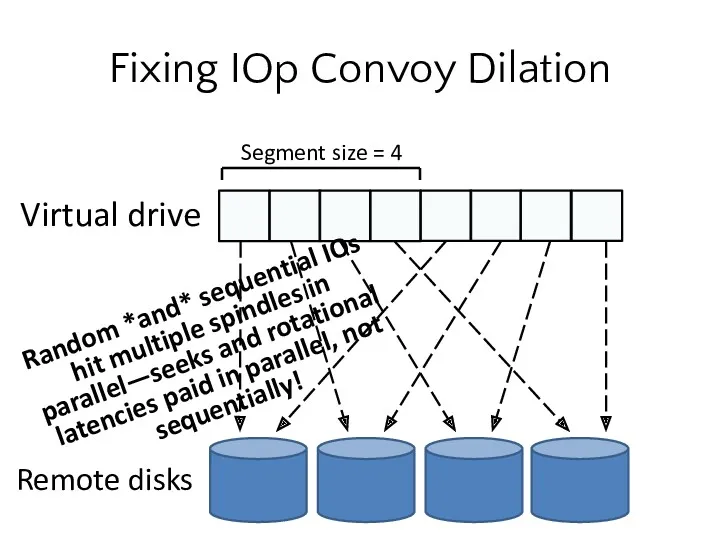
Fixing IOp Convoy Dilation
Random *and* sequential IOs hit multiple spindles in
Fixing IOp Convoy Dilation
Random *and* sequential IOs hit multiple spindles in
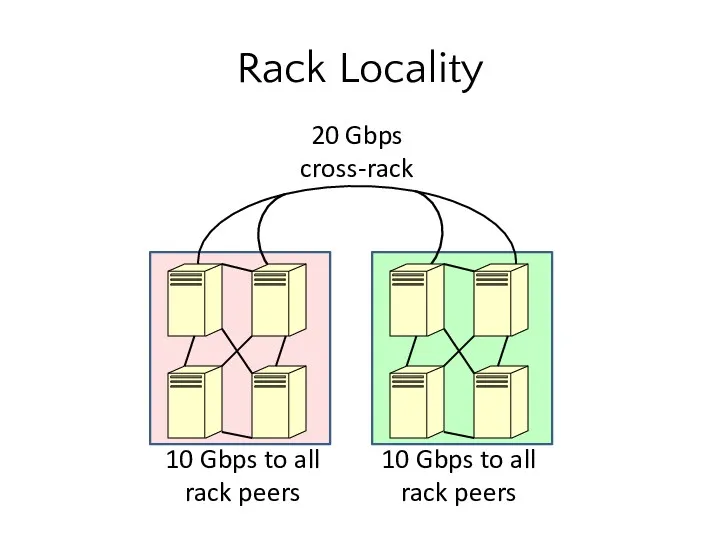
Rack Locality
10 Gbps to all rack peers
10 Gbps to all rack
Rack Locality
10 Gbps to all rack peers
10 Gbps to all rack
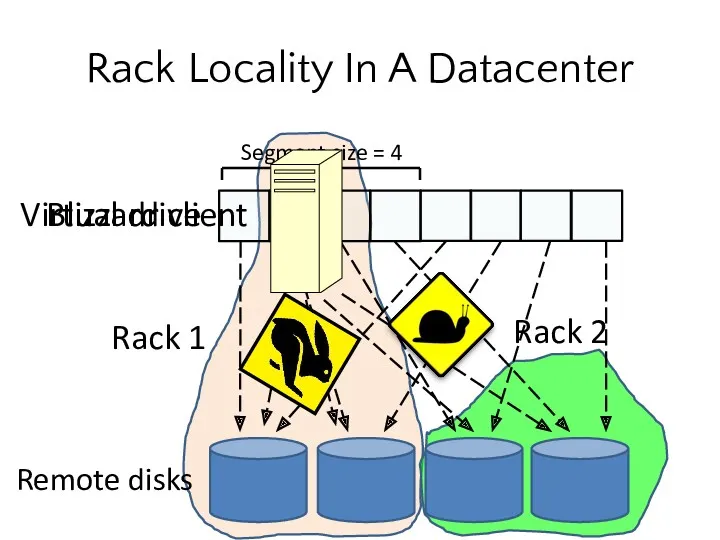
Rack Locality In A Datacenter
Remote disks
Rack Locality In A Datacenter
Remote disks

Flat Datacenter Storage (FDS)
Idea 1: Build a datacenter network with full-bisection
Flat Datacenter Storage (FDS)
Idea 1: Build a datacenter network with full-bisection
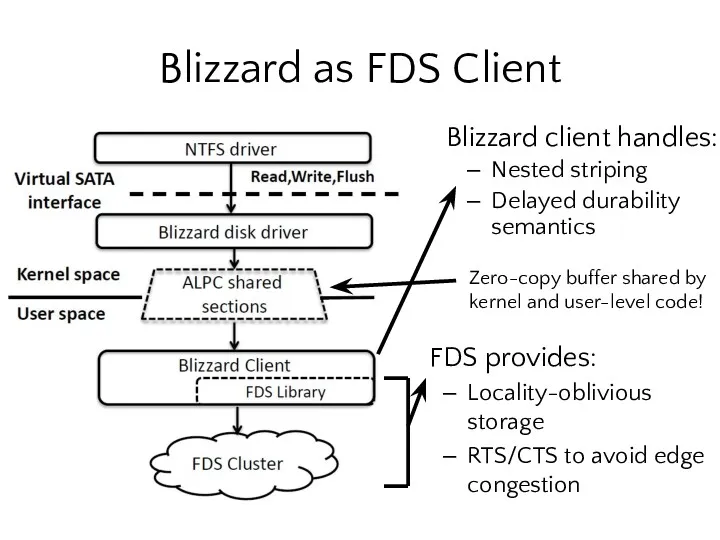
Blizzard as FDS Client
Blizzard client handles:
Nested striping
Delayed durability semantics
Blizzard as FDS Client
Blizzard client handles:
Nested striping
Delayed durability semantics

The problem with fsync()
Used by POSIX/Win32 file systems and applications to
The problem with fsync()
Used by POSIX/Win32 file systems and applications to

WRITE BARRIERS RUIN BIRTHDAYS
Stalled operations limit parallelism!
WRITE BARRIERS RUIN BIRTHDAYS
Stalled operations limit parallelism!

Delayed Durability in Blizzard’s Virtual Drive
Decouple durability from ordering
Acknowledge flush() immediately
Delayed Durability in Blizzard’s Virtual Drive
Decouple durability from ordering
Acknowledge flush() immediately
Decouple durability from ordering
Acknowledge flush() immediately . . .
. . .
Decouple durability from ordering
Acknowledge flush() immediately . . .
. . .
App
F1
F2
Blizzard
Remote
disk
All writes are acknowledged . . .
. . . but only
App
F1
F2
Blizzard
Remote
disk
All writes are acknowledged . . .
. . . but only

Isn’t Blizzard buffering a lot of data?
Epoch 0
Epoch 1
Epoch 2
Epoch 3
In
Isn’t Blizzard buffering a lot of data?
Epoch 0
Epoch 1
Epoch 2
Epoch 3
In
Log-based Writes
Treat backing FDS storage as a distributed log
Issue block writes
Log-based Writes
Treat backing FDS storage as a distributed log
Issue block writes
Summary of Blizzard’s Design
Problem: IOp Dilation
Solution: Nested striping
Problem: Rack locality constrains
Summary of Blizzard’s Design
Problem: IOp Dilation
Solution: Nested striping
Problem: Rack locality constrains
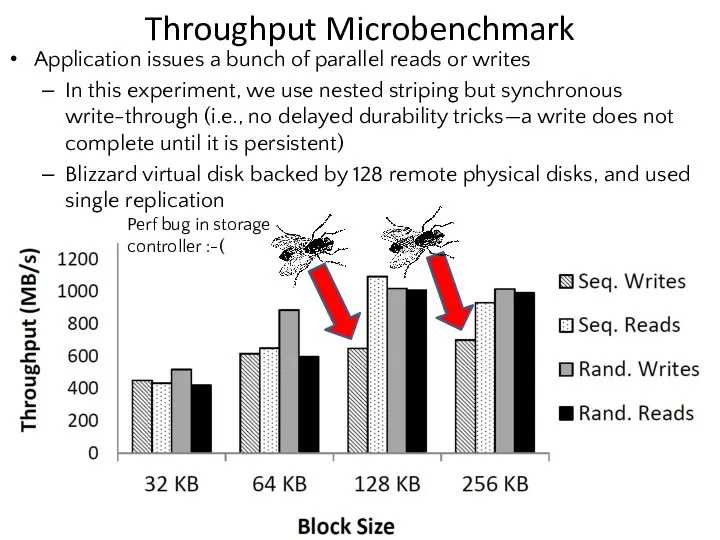
Throughput Microbenchmark
Application issues a bunch of parallel reads or writes
In this
Throughput Microbenchmark
Application issues a bunch of parallel reads or writes
In this
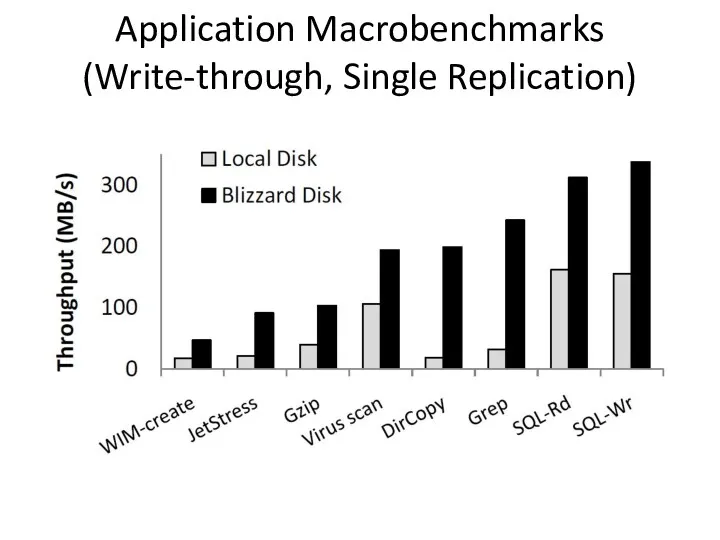
Application Macrobenchmarks
(Write-through, Single Replication)
Application Macrobenchmarks
(Write-through, Single Replication)
 Methods in behavioral genetics
Methods in behavioral genetics Глагол have to и must
Глагол have to и must Структура письма
Структура письма My family
My family Cardinal numbers. Ordinal numbers
Cardinal numbers. Ordinal numbers The law of property
The law of property Phrasal Verbs
Phrasal Verbs Composite sentence. Complex sentence
Composite sentence. Complex sentence The past continuous tense
The past continuous tense The Past Perfect Tense
The Past Perfect Tense Edinburgh the capital of Scotland. Interesting places of Edinburgh
Edinburgh the capital of Scotland. Interesting places of Edinburgh Halloween vocabulary
Halloween vocabulary Дискриминация. Discrimination
Дискриминация. Discrimination Purposes and problems of drawing up business plan
Purposes and problems of drawing up business plan Modern building materials
Modern building materials Names of the seasons
Names of the seasons Expressive means and stylistic devices
Expressive means and stylistic devices Democratic and authoritarian political systems
Democratic and authoritarian political systems Тренажёр There is / There are. Level A1 – A2
Тренажёр There is / There are. Level A1 – A2 Поставьте глаголы в следующих предложениях в утвердительную, вопросительную и отрицательную формы Present Simple
Поставьте глаголы в следующих предложениях в утвердительную, вопросительную и отрицательную формы Present Simple Newspaper Articles Features
Newspaper Articles Features The future continuous tense
The future continuous tense British police
British police Personal pronouns
Personal pronouns Where are the toys. Grammar drills
Where are the toys. Grammar drills Food and drinks
Food and drinks Module 6. Reported Speech
Module 6. Reported Speech What’s the weather like?
What’s the weather like?