- Ekonometria. Weryfikacja modelu ekonometrycznego

Содержание
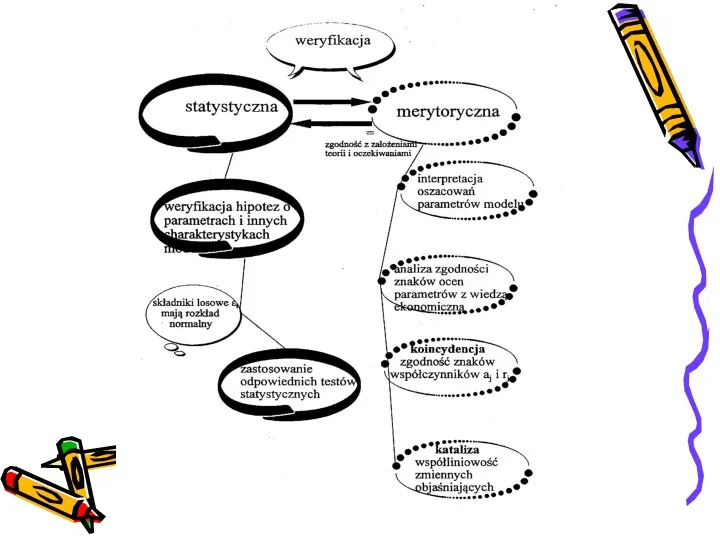
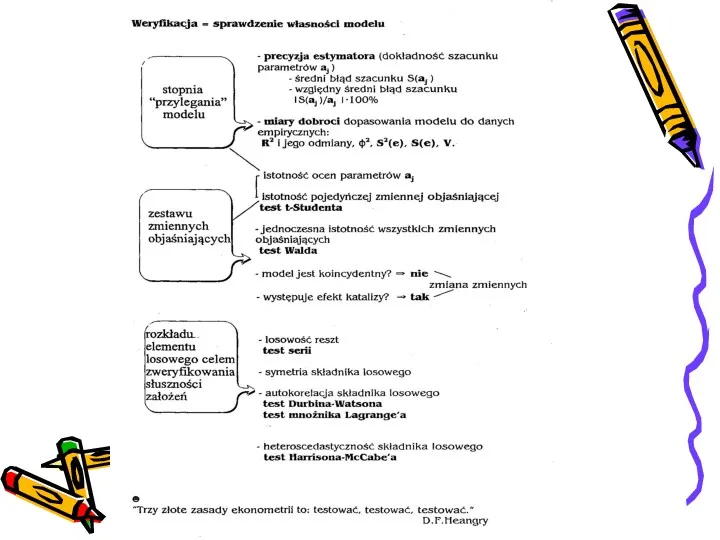
- 8. Weryfikacja modelu ekonometrycznego
- 13. Przykład. Do modelu wybrano zmienne objaśniające X1 oraz X2. Macierz obserwacji na zmiennych objaśniających modelu jest
- 14. Twierdzenie 1 (Gaussa-Markowa) Wektor ocen parametrów strukturalnych jest postaci:
- 15. Macierz odwrotna do macierzy XTX
- 16. Obliczamy wartości ocen parametrów strukturalnych modelu ekonometrycznego: Model ekonometryczny jest postaci:
- 17. Interpretacja: a0 = 7,941 to średnia wartość Y w przypadku, gdy zmienne objaśniające X1 i X2
- 20. Twierdzenie 2 (Gaussa-Markowa) Wariancja składnika resztowego (estymator wariancji składnika losowego) według wzoru: Do obliczenia wariancji potrzebne
- 21. Ile wynoszą reszty? Do oszacowanego modelu: podstawiamy kolejne wartości zmiennych X1 i X2
- 22. Wektor reszt równa się:
- 23. licznik wzoru to:
- 24. Odchylenie standardowe składnika resztowego (błąd estymacji): Interpretacja: Poszczególne obserwacje empiryczne Y odchylają się średnio od teoretycznych
- 25. Twierdzenie 3 (Gaussa-Markowa Wariancja estymatora parametrów strukturalnych według wzoru: wynosi: Obliczając wartości elementów diagonalnych macierzy D2(a)
- 26. Wnioskowanie o dokładności szacunku parametrów αi Błędy średnie szacunku parametrów strukturalnych: Interpretacja: O ile +- odchylają
- 27. Do interpretacji lepiej posługiwać się średnimi względnymi błędami szacunku parametrów wyznaczonymi ze wzoru: Błędy średnie stanowią
- 28. Współczynnik zbieżności dany wzorem: wynosi: bowiem:
- 29. Współczynnik zbieżności φ2 = 0,380 oznacza, iż 38% zmienności zmiennej objaśnianej Y nie zostało wyjaśnione przez
- 30. Współczynnik zmienności losowej: Interpretacja: Odchylenia losowe stanowią 23,7% wartości średniej zmiennej objaśnianej Y.
- 31. W ekonometrii przyjęta jest konwencja podawania średnich błędów szacunku parametrów strukturalnych łącznie z oszacowaniem modelu. Oszacowany
- 33. Weryfikujemy istotność parametrów strukturalnych oszacowanego modelu Stawiamy hipotezę: H0: αi = 0 (parametr αi nieistotnie różni
- 34. Dla każdego parametru obliczamy wartości empiryczne statystyki t: Z tablic t-Studenta dla przyjętego poziomu istotności α
- 35. Jeżeli spełniona jest nierówność: to hipoezę H0 należy odrzucić na korzyśćalternatywnej hipotezy H1, czyli dany parametr
- 36. Z naszych obliczeń wynika m.in., iż: więc hipotezę H1 odrzucamy, a parametr a0 jest statystycznie nieistotny.
- 38. Badanie koincydencji Model jest koincydentny, jeżeli dla każdej zmiennej objaśniającej model zachodzi: gdzie: ai – jest
- 39. Współliniowość – czy zmienne są katalizatorami? Zmienna Xi z pary zmiennych ( Xi, Xj) jest katalizatorem
- 41. Badanie losowości Badanie losowości ma związek z wyborem postaci analitycznej modelu. W standardowym modelu liniowym zmienna
- 43. Czy reszty są losowe? Wektor reszt Reguły testu (dla prób małych (n≤30) Przypisujemy resztom ek symbole
- 44. Wartości krytyczne testu serii
- 46. Czy rozkład reszt modelu jest symetryczny? W celu zweryfikowania hipotezy przyjęto poziom istotności testu a =
- 47. Czy występuje autokorelacja skladnika losowego? Jednym z założeń dotyczących modelu regresji jest niezależność błędów obserwacji, czyli
- 48. Sposobem określenia niezależności błędów obserwacji jest wyznaczenie autokorelacji składnika resztowego, czyli korelacji r-Pearsona pomiędzy kolejnymi resztami,
- 49. Współczynnik korelacji Pearsona rxy jest miernikiem związku liniowego między dwiema cechami (zmiennymi) mierzalnymi jest wyznaczany poprzez
- 50. Proces autokorelacji rzędu I Załóżmy, że składniki losowe εt związane są zależnością: gdzie: (t=1...,n-1) zmienne losowe
- 51. Test Durbina-Watsona Test Durbina-Watsona (statystyka) służy do oceny występowania korelacji pomiędzy resztami (błędami, składnikami resztowymi). Sprawdzamy,
- 53. Tablice testu Durbina-Watsona prezentują wartości krytyczne dL oraz dU dla odpowiedniej liczby obserwacji n oraz liczby
- 54. Czy występuje autokorelacja reszt? Statystyka d Obliczenia: Dla modelu wartość: d= 53,501/22,015=2,430
- 55. Zasadą jest, że wartości statystyk testowych w zakresie od 1,5 do 2,5 są stosunkowo normalne. Każda
- 60. Скачать презентацию







Weryfikacja modelu ekonometrycznego
Weryfikacja modelu ekonometrycznego




Przykład.
Do modelu wybrano zmienne objaśniające X1 oraz X2.
Macierz obserwacji na zmiennych
Przykład.
Do modelu wybrano zmienne objaśniające X1 oraz X2.
Macierz obserwacji na zmiennych
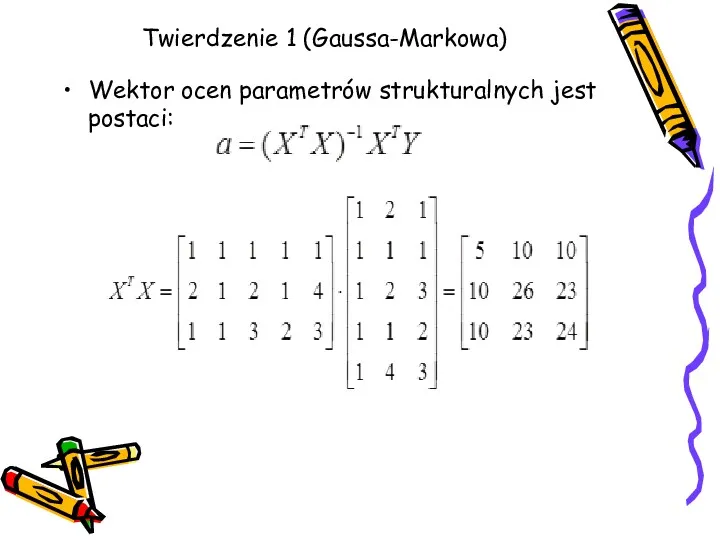
Twierdzenie 1 (Gaussa-Markowa)
Wektor ocen parametrów strukturalnych jest postaci:
Twierdzenie 1 (Gaussa-Markowa)
Wektor ocen parametrów strukturalnych jest postaci:

Macierz odwrotna do macierzy XTX
Macierz odwrotna do macierzy XTX

Obliczamy wartości ocen parametrów strukturalnych modelu ekonometrycznego:
Model ekonometryczny jest postaci:
Obliczamy wartości ocen parametrów strukturalnych modelu ekonometrycznego:
Model ekonometryczny jest postaci:

Interpretacja:
a0 = 7,941 to średnia wartość Y w przypadku, gdy zmienne
Interpretacja:
a0 = 7,941 to średnia wartość Y w przypadku, gdy zmienne


Twierdzenie 2 (Gaussa-Markowa)
Wariancja składnika resztowego (estymator wariancji składnika losowego) według wzoru:
Do
Twierdzenie 2 (Gaussa-Markowa)
Wariancja składnika resztowego (estymator wariancji składnika losowego) według wzoru:
Do

Ile wynoszą reszty?
Do oszacowanego modelu:
podstawiamy kolejne wartości zmiennych X1 i X2
Ile wynoszą reszty?
Do oszacowanego modelu:
podstawiamy kolejne wartości zmiennych X1 i X2

Wektor reszt równa się:
Wektor reszt równa się:
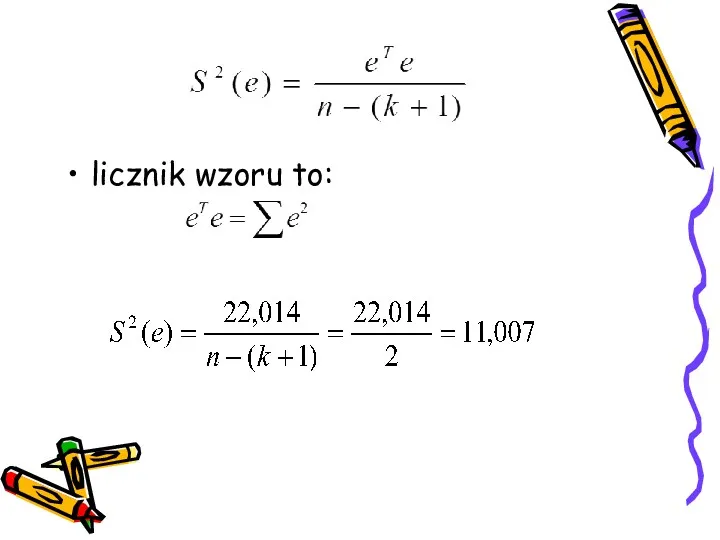
licznik wzoru to:
licznik wzoru to:

Odchylenie standardowe składnika resztowego (błąd estymacji):
Interpretacja:
Poszczególne obserwacje empiryczne Y odchylają się
Odchylenie standardowe składnika resztowego (błąd estymacji):
Interpretacja:
Poszczególne obserwacje empiryczne Y odchylają się

Twierdzenie 3 (Gaussa-Markowa
Wariancja estymatora parametrów strukturalnych według wzoru:
wynosi:
Obliczając wartości elementów diagonalnych
Twierdzenie 3 (Gaussa-Markowa
Wariancja estymatora parametrów strukturalnych według wzoru:
wynosi:
Obliczając wartości elementów diagonalnych

Wnioskowanie o dokładności szacunku parametrów αi
Błędy średnie szacunku parametrów strukturalnych:
Interpretacja:
O ile
Wnioskowanie o dokładności szacunku parametrów αi
Błędy średnie szacunku parametrów strukturalnych:
Interpretacja:
O ile

Do interpretacji lepiej posługiwać się średnimi względnymi błędami szacunku parametrów
Do interpretacji lepiej posługiwać się średnimi względnymi błędami szacunku parametrów

Współczynnik zbieżności dany wzorem:
wynosi:
bowiem:
Współczynnik zbieżności dany wzorem:
wynosi:
bowiem:

Współczynnik zbieżności φ2 = 0,380 oznacza, iż 38% zmienności zmiennej objaśnianej
Współczynnik zbieżności φ2 = 0,380 oznacza, iż 38% zmienności zmiennej objaśnianej

Współczynnik zmienności losowej:
Interpretacja:
Odchylenia losowe stanowią 23,7% wartości średniej zmiennej objaśnianej Y.
Współczynnik zmienności losowej:
Interpretacja:
Odchylenia losowe stanowią 23,7% wartości średniej zmiennej objaśnianej Y.

W ekonometrii przyjęta jest konwencja podawania średnich błędów szacunku parametrów strukturalnych
W ekonometrii przyjęta jest konwencja podawania średnich błędów szacunku parametrów strukturalnych


Weryfikujemy istotność parametrów strukturalnych oszacowanego modelu
Stawiamy hipotezę:
H0: αi = 0 (parametr
Weryfikujemy istotność parametrów strukturalnych oszacowanego modelu
Stawiamy hipotezę:
H0: αi = 0 (parametr

Dla każdego parametru obliczamy wartości empiryczne statystyki t:
Z tablic t-Studenta dla
Dla każdego parametru obliczamy wartości empiryczne statystyki t:
Z tablic t-Studenta dla

Jeżeli spełniona jest nierówność:
to hipoezę H0 należy odrzucić na korzyśćalternatywnej hipotezy
Jeżeli spełniona jest nierówność:
to hipoezę H0 należy odrzucić na korzyśćalternatywnej hipotezy

Z naszych obliczeń wynika m.in., iż:
więc hipotezę H1 odrzucamy, a parametr
Z naszych obliczeń wynika m.in., iż:
więc hipotezę H1 odrzucamy, a parametr


Badanie koincydencji
Model jest koincydentny, jeżeli dla każdej zmiennej objaśniającej model zachodzi:
gdzie:
ai
Badanie koincydencji
Model jest koincydentny, jeżeli dla każdej zmiennej objaśniającej model zachodzi:
gdzie:
ai

Współliniowość – czy zmienne są katalizatorami?
Zmienna Xi z pary zmiennych (
Współliniowość – czy zmienne są katalizatorami?
Zmienna Xi z pary zmiennych (


Badanie losowości
Badanie losowości ma związek z wyborem postaci analitycznej modelu.
W standardowym
Badanie losowości
Badanie losowości ma związek z wyborem postaci analitycznej modelu.
W standardowym


Czy reszty są losowe?
Wektor reszt
Reguły testu (dla prób małych (n≤30)
Przypisujemy resztom
Czy reszty są losowe?
Wektor reszt
Reguły testu (dla prób małych (n≤30)
Przypisujemy resztom

Wartości krytyczne testu serii
Wartości krytyczne testu serii


Czy rozkład reszt modelu jest symetryczny?
W celu zweryfikowania hipotezy
przyjęto poziom istotności
Czy rozkład reszt modelu jest symetryczny?
W celu zweryfikowania hipotezy
przyjęto poziom istotności

Czy występuje autokorelacja skladnika losowego?
Jednym z założeń dotyczących modelu regresji jest
Czy występuje autokorelacja skladnika losowego?
Jednym z założeń dotyczących modelu regresji jest

Sposobem określenia niezależności błędów obserwacji jest wyznaczenie autokorelacji składnika resztowego, czyli
Sposobem określenia niezależności błędów obserwacji jest wyznaczenie autokorelacji składnika resztowego, czyli

Współczynnik korelacji Pearsona
rxy jest miernikiem związku liniowego między dwiema cechami (zmiennymi)
Współczynnik korelacji Pearsona
rxy jest miernikiem związku liniowego między dwiema cechami (zmiennymi)

Proces autokorelacji rzędu I
Załóżmy, że składniki losowe εt związane są zależnością:
gdzie: (t=1...,n-1)
zmienne losowe
Proces autokorelacji rzędu I
Załóżmy, że składniki losowe εt związane są zależnością:
gdzie: (t=1...,n-1)
zmienne losowe

Test Durbina-Watsona
Test Durbina-Watsona (statystyka) służy do oceny występowania korelacji pomiędzy resztami
Test Durbina-Watsona
Test Durbina-Watsona (statystyka) służy do oceny występowania korelacji pomiędzy resztami


Tablice testu Durbina-Watsona prezentują wartości krytyczne dL oraz dU dla odpowiedniej
Tablice testu Durbina-Watsona prezentują wartości krytyczne dL oraz dU dla odpowiedniej

Czy występuje autokorelacja reszt?
Statystyka d
Obliczenia:
Dla modelu wartość:
d= 53,501/22,015=2,430
Czy występuje autokorelacja reszt?
Statystyka d
Obliczenia:
Dla modelu wartość:
d= 53,501/22,015=2,430

Zasadą jest, że wartości statystyk testowych w zakresie od 1,5 do
Zasadą jest, że wartości statystyk testowych w zakresie od 1,5 do



 Безработица, ее основные виды. Закон Оукена. Последствия безработицы
Безработица, ее основные виды. Закон Оукена. Последствия безработицы Неравенство. 1% самых богатых - 60% общего прироста НД США. Для остальных темпы роста 0,5% ежегодно
Неравенство. 1% самых богатых - 60% общего прироста НД США. Для остальных темпы роста 0,5% ежегодно ЭКСПО 2017 көрмесі – Қазақстанның әлеуетін көрсетуге зор мүмкіндік
ЭКСПО 2017 көрмесі – Қазақстанның әлеуетін көрсетуге зор мүмкіндік Митна політика україни. Сучасність і перспективи розвитку
Митна політика україни. Сучасність і перспективи розвитку Бюджетное ограничение. Равновесие потребителя
Бюджетное ограничение. Равновесие потребителя Макроэкономика. Введение в макроэкономику
Макроэкономика. Введение в макроэкономику Трудовая миграция в Чехии
Трудовая миграция в Чехии Рынок труда в сфере юриспруденции
Рынок труда в сфере юриспруденции Место США в мировой экономике
Место США в мировой экономике Капитал. Кругооборот и оборот капитала. Виды капитала
Капитал. Кругооборот и оборот капитала. Виды капитала Социальные нормы и их роль в экономике
Социальные нормы и их роль в экономике Государственный бюджет. Бюджетный дефицит и государственный долг
Государственный бюджет. Бюджетный дефицит и государственный долг Способы продвижения продукта на рынке. Сегментация рынка. Позиционирование продукта
Способы продвижения продукта на рынке. Сегментация рынка. Позиционирование продукта Дефицит/профицит госбюджета
Дефицит/профицит госбюджета Школа как пространство развития и применения компетенций
Школа как пространство развития и применения компетенций Система отношений собственности в современной экономике. Тема 8
Система отношений собственности в современной экономике. Тема 8 Management of bulls for reproductive and economic success
Management of bulls for reproductive and economic success Понятие ценовой дискриминации
Понятие ценовой дискриминации Меркантилизм. (Занятие 4)
Меркантилизм. (Занятие 4) Рыночная экономика
Рыночная экономика Издержки предприятия
Издержки предприятия Алгоритм определения инвестиционного потенциала региона (субъекта РФ) и его конкурентоспособности
Алгоритм определения инвестиционного потенциала региона (субъекта РФ) и его конкурентоспособности Основы поведения субъектов рыночной экономики. Фирма как хозяйствующий субъект. Производственная функция. Производственный выбор
Основы поведения субъектов рыночной экономики. Фирма как хозяйствующий субъект. Производственная функция. Производственный выбор Теория полезности и поведения потребителя
Теория полезности и поведения потребителя Поведение потребителя
Поведение потребителя Характеристика и особенности экономического развития Беларуси в 2016 году: глобальные вызовы и угрозы
Характеристика и особенности экономического развития Беларуси в 2016 году: глобальные вызовы и угрозы Состояние и перспективы развития агропромышленного комплекса государств-членов ЕАЭС
Состояние и перспективы развития агропромышленного комплекса государств-членов ЕАЭС Supply and demand: how markets work
Supply and demand: how markets work