- Основные сквозные технологии цифровой экономики. Большие данные

Содержание
- 2. Информация, море информации
- 3. Что говорят эксперты +25% p.a. 2009 2020 2015 2011 Почему это важно Более 90 % всех
- 4. Ежегодный рост данных 62% 22% 90% 10% Неструктурированные Структурированные
- 5. Физика информации Информация сама по себе является объективной физической величиной в ряду других величин, таких как
- 6. Датаизм — концепция, согласно которой большие данные и алгоритмы обработки этих данных являются высшей ценностью. 2013
- 7. «В наше время мы страдаем не столько из-за недостатка информации, сколько от избытка ненужной, бесполезной информации,
- 8. Негативные последствия перегруженности информацией
- 9. Источник: http://www.mirprognozov.ru/prognosis/society/informatsionnyiy-vzryiv-ugroza-buduschemu-tsivilizatsii/ Информационный взрыв Впервые об угрозе "информационного взрыва” ученые заговорили в 60-х годах XX века.
- 10. В мире проанализировано менее 1% всей информации, защищено менее 20% Основные прогнозы Объемы информации будут удваиваться
- 11. Определения и концепция больших данных (Big Data)
- 12. Термин и тренд Big Date 1998 Джон Мэши: ввёл в обиход термин Big Data. 2005 издание
- 13. Большие данные сравнивали с: минеральными ресурсами — the new oil (новая нефть), goldrush (золотая лихорадка), data
- 14. Существует ли проблема Больших Данных ? Большие Данные - red herring (букв. «копченая селедка» — ложный
- 15. – это «зонтичный» термин, объединяющий группу понятий, технологий и методов производительной обработки очень больших объёмов данных,
- 16. Разные взгляды на применение больших данных
- 17. Определение больших данных как технологии Большие данные – это: серия подходов, инструментов и методов обработки структурированных
- 18. Cloud of tags Вот как Интернет представляет понятие BigData Точнее – как Большие Данные представляют сами
- 19. Объем (Volume) 10% организаций обрабатывают 1+ Пб данных Социальные сети – миллионы транзакций в минуту Скорость
- 20. Отличия данных от больших данных
- 21. Таблица байтов: 1 байт = 8 бит 1 Кб (1 Килобайт) = 210 байт = 2*2*2*2*2*2*2*2*2*2
- 22. Классификация Больших Данных Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие данные на 3 группы:
- 23. Big Data Analytics Статистический анализ Технологии визуализации Технологии БД Технологии машинного обучения Технологии распознавания образов Искусственный
- 24. Источники данных Источник: McKinsey & Company
- 25. Методы анализа больших данных Описательные методы Прогнозные методы Директивные методы Описать взаимосвязи или составить выводы на
- 26. Эволюция статистических алгоритмов 1795 1810 1946 1957 1973 1906 Регрессии Байесовская статистика Цепь Маркова Нейронные сети
- 27. В результате этих преобразований подходы к анализу данных радикально изменились ИСТОЧНИК: McKinsey Analytics Многообразие: неструктурированные и
- 28. Упрощённая схема работы с большими массивами данных ___ ___ ___ Результат Машинное обучение Аналитики Системы и
- 29. Комплексный подход к большим данным 1. ДАННЫЕ 3. ОРГАНИЗАЦИОННАЯ СТРУКТУРА И БИЗНЕС-ПРОЦЕССЫ 2. АНАЛИТИКА 4. ИНФРАСТРУКТУРА
- 30. Джозеп Курто, управляющий независимой консалтинговой компанией Delfos Research, ассоциированный профессор IE Schoolof Social, Behavioral & Data
- 31. Профессии Big Date исследователь данных консультант в области больших данных инженер по большим данным архитектор больших
- 32. Игроки на рынке Big Date Поставщики инфраструктуры — решают задачи хранения и предобработки данных. Например: IBM,
- 33. Направления Big Date Сбор и обработка больших данных Аналитика Инженерия больших данных Архитектура больших данных и
- 34. Приоритетные направления для компаний Цели применения: Эффективность Удовлетворение клиентов Снижение риска Расширение бизнеса
- 35. Big Data не нужны, если сотрудники в состоянии обработать и автоматизировать данные по клиентам с помощью
- 36. Мэтт Слокум из O'Reilly Radar считает, что хотя большие данные и бизнес-аналитика имеют одинаковую цель (поиск
- 37. Факторы развития технологии https://netology.ru/blog/6-mif-bigdata
- 38. Машинное обучение и большие данные
- 39. Место машинного обучения среди других технологий https://vc.ru/future/59364-aimath https://studylib.ru/doc/1708570/mashinnoe-obuchenie-i-analiz-dannyh Pattern Recognition (распознавание образов) Pattern Recognition ≈ Machine
- 40. Типы обучения Дедуктивное или аналитическое обучение (экспертные системы). Имеются знания, сформулированные экспертом и как-то формализованные. Программа
- 41. Классификация задач машинного обучения Дедуктивное обучение (экспертные системы) Индуктивное обучение ( ≈ статистическое обучение) (определение Митчелла
- 42. Обучение с учителем: Классификация – это зависимость входных данных от дискретных выходных. https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84 Используют для: Спам-фильтры
- 43. Обучение с учителем: классификация: Наивный Байес https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
- 44. Обучение с учителем: классификация: дерево решений https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
- 45. Обучение с учителем: Регрессия - это зависимость между входными данными и непрерывными выходными. https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84 Используют для:
- 46. Обучение без учителя: Кластеризация - это группировка данных руководствуясь свойствами этих данных. Данные внутри кластера должны
- 47. Обучение без учителя: Кластеризация: метод k-средних https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
- 48. Обучение без учителя: Ассоциация – поиск закономерностей между связанными событиями. К примеру, можно привести следующее правило,
- 49. Последовательные шаблоны – установление закономерностей между связанными во времени событиями, т.е. обнаружение зависимости, что если произойдёт
- 50. Обучение без учителя: Уменьшение размерности – собирает конкретные признаки в абстракции более высокого уровня. Используют для:
- 51. Обучение без учителя: Уменьшение размерности: LSA https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
- 52. https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
- 53. Связь задач, методов ML с бизнес-задачами https://blog.zverit.com/machine-learning/2017/11/11/ml-bd-mining-business/
- 54. Инструменты больших данных
- 55. http://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D0%B5_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5_(Big_Data)
- 56. Платформа Hadoop Hadoop – это это свободно распространяемый набор программных средств (Software Framework) для разработки и
- 57. Экосистема Hadoop
- 58. Примеры кейсов с большими данными
- 59. Командообразование 2002, бейсбольная команда «Oakland Athletics» генеральный менеджер Билли Бин, выпускник экономического факультета Йельского университета Питер
- 60. Таргетированный маркетинг ВОЗМОЖНОСТИ Воздействие на клиента в нужное время В нужном месте (определение локаций) Распознавание интересов
- 61. Американская сеть магазинов Target и беременная девочка Target ежегодно тратит около 4 миллионов долларов на содержание
- 62. Классификация пользователя Психологи Кембриджского университета изучали, как ставят «лайки» 58 тысяч пользователей фейсбука и на основании
- 63. Данные для таргетирования – все действия в сети Компания Bombora (США) отслеживает поисковые запросы, загрузки документов,
- 64. Дискриминация в ценообразование или… «Некоторые онлайн-ресурсы показывают разные цены на товары в зависимости от того, с
- 65. Анализ социальных графов Задачи: выделение лидеров мнений, влияние в группах и из вне; выделение сообществ; определения
- 68. Методы NLP, Text Mining О чем говорят? Кто говорит? Как говорят? Обработка естественного языка (Natural Language
- 69. PolyAnalyst: Примеры Аналитических Решений Структуризация и контроль за содержанием учебных программ Автоматизация извлечения информации о контрагентах
- 70. Примеры (зарубежные кейсы) HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает, что в 10 раз улучшила
- 71. Примеры (отечественные кейсы) Яндекс. Это корпорация, которая управляет одним из самых популярных поисковиков и делает цифровые
- 72. «Анонимности в сети нет» Российская компания SocialDataHub в считанные часы смогла опознать террориста-смертника, подорвавшего в апреле
- 73. Насколько законно собирать данные о людях? Федеральный закон "О персональных данных" эксперты оценивают как "размытый". Например,
- 74. О чем спорят «ВКонтакте» и Double Data https://www.rbc.ru/technology_and_media/04/09/2019/5d6e5f6d9a794784dea7c2e2 2017 ВКонтакте судится с ООО «Дабл», требуя запрета
- 75. Кто владеет информацией, тот владеет миром. Натан Ротшильд Именно то, как вы собираете, организуете и используете
- 76. Не забывай: информация не есть знание, знание не есть мудрость, мудрость не есть истина, истина не
- 78. Скачать презентацию

Информация, море информации
Информация, море информации

Что говорят эксперты
+25% p.a.
2009
2020
2015
2011
Почему это важно
Более 90 % всех данных было
Что говорят эксперты
+25% p.a.
2009
2020
2015
2011
Почему это важно
Более 90 % всех данных было

Ежегодный рост данных
62% 22%
90%
10%
Неструктурированные
Структурированные
Ежегодный рост данных
62% 22%
90%
10%
Неструктурированные
Структурированные

Физика информации
Информация сама по себе является объективной физической величиной в ряду
Физика информации
Информация сама по себе является объективной физической величиной в ряду

Датаизм
— концепция, согласно которой большие данные и алгоритмы обработки этих данных
Датаизм
— концепция, согласно которой большие данные и алгоритмы обработки этих данных
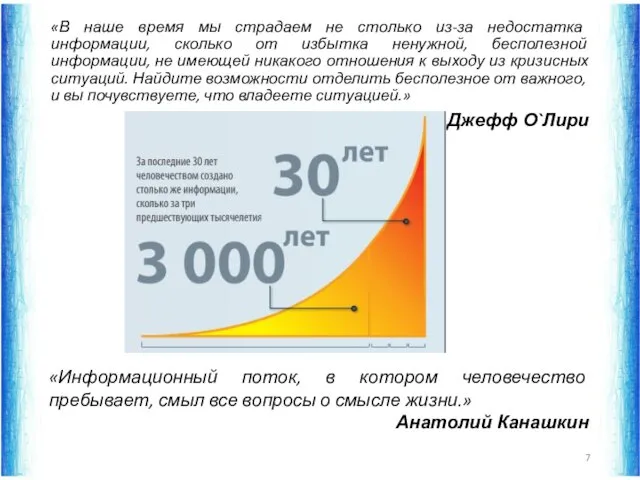
«В наше время мы страдаем не столько из-за недостатка информации, сколько
«В наше время мы страдаем не столько из-за недостатка информации, сколько
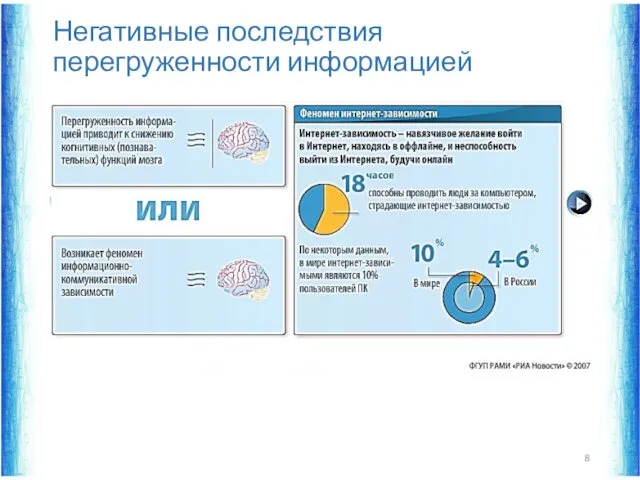
Негативные последствия перегруженности информацией
Негативные последствия перегруженности информацией

Источник: http://www.mirprognozov.ru/prognosis/society/informatsionnyiy-vzryiv-ugroza-buduschemu-tsivilizatsii/
Информационный взрыв
Впервые об угрозе "информационного взрыва” ученые заговорили в
Источник: http://www.mirprognozov.ru/prognosis/society/informatsionnyiy-vzryiv-ugroza-buduschemu-tsivilizatsii/
Информационный взрыв
Впервые об угрозе "информационного взрыва” ученые заговорили в

В мире проанализировано менее 1% всей информации, защищено менее 20%
Основные
В мире проанализировано менее 1% всей информации, защищено менее 20%
Основные

Определения и концепция больших данных
(Big Data)
Определения и концепция больших данных
(Big Data)

Термин и тренд Big Date
1998 Джон Мэши:
ввёл в обиход термин
Термин и тренд Big Date
1998 Джон Мэши:
ввёл в обиход термин

Большие данные сравнивали с:
минеральными ресурсами —
the new oil (новая
Большие данные сравнивали с:
минеральными ресурсами —
the new oil (новая

Существует ли проблема Больших Данных ?
Большие Данные - red herring (букв.
Существует ли проблема Больших Данных ?
Большие Данные - red herring (букв.
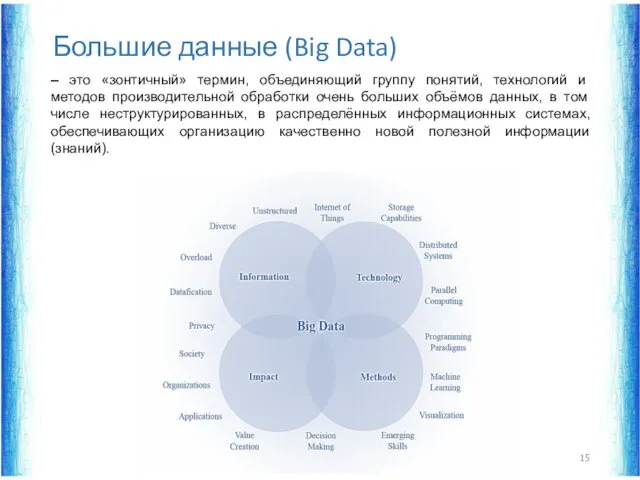
– это «зонтичный» термин, объединяющий группу понятий, технологий и методов производительной
– это «зонтичный» термин, объединяющий группу понятий, технологий и методов производительной
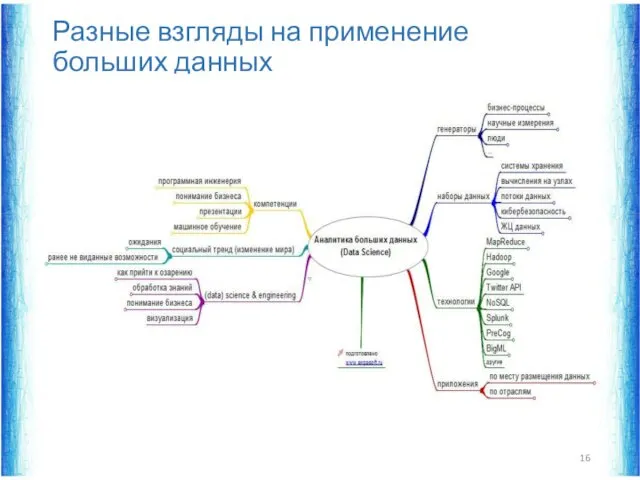
Разные взгляды на применение больших данных
Разные взгляды на применение больших данных

Определение больших данных как технологии
Большие данные – это:
серия подходов, инструментов и
Определение больших данных как технологии
Большие данные – это:
серия подходов, инструментов и

Cloud of tags
Вот как Интернет представляет понятие BigData
Точнее – как
Cloud of tags
Вот как Интернет представляет понятие BigData
Точнее – как

Объем (Volume)
10% организаций обрабатывают 1+ Пб данных
Социальные сети – миллионы транзакций
Объем (Volume)
10% организаций обрабатывают 1+ Пб данных
Социальные сети – миллионы транзакций
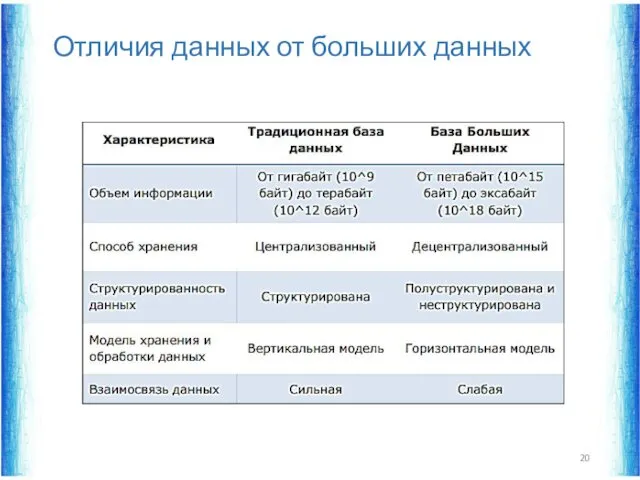
Отличия данных от больших данных
Отличия данных от больших данных

Таблица байтов:
1 байт = 8 бит
1 Кб (1 Килобайт) = 210
Таблица байтов:
1 байт = 8 бит
1 Кб (1 Килобайт) = 210

Классификация Больших Данных
Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие
Классификация Больших Данных
Дайон Хинчклиф, редактора журнала Web 2.0 Journal делит Большие
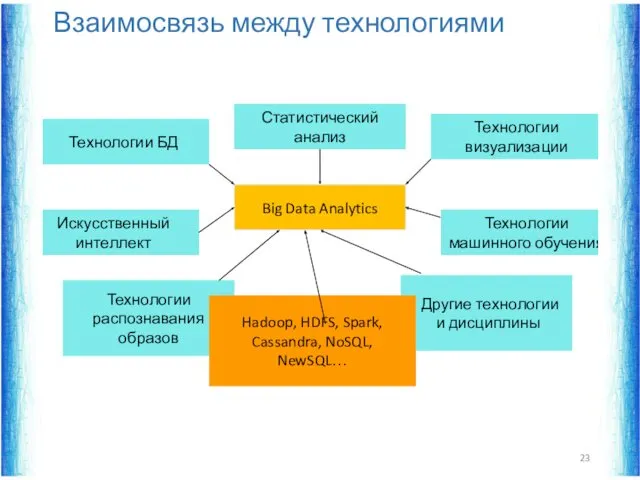
Big Data Analytics
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
Big Data Analytics
Статистический анализ
Технологии визуализации
Технологии БД
Технологии машинного обучения
Технологии распознавания образов
Искусственный интеллект
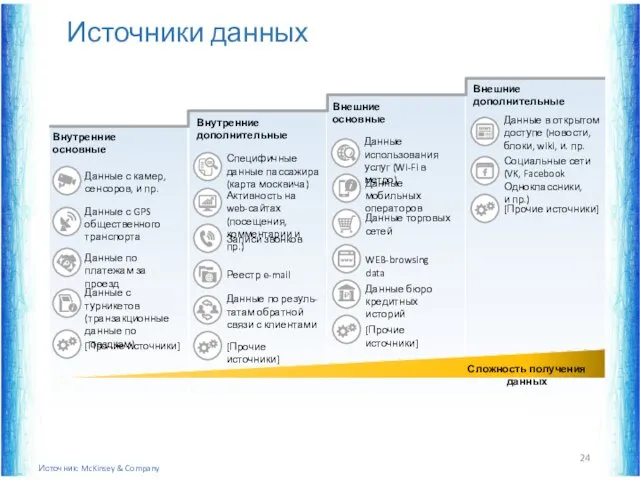
Источники данных
Источник: McKinsey & Company
Источники данных
Источник: McKinsey & Company
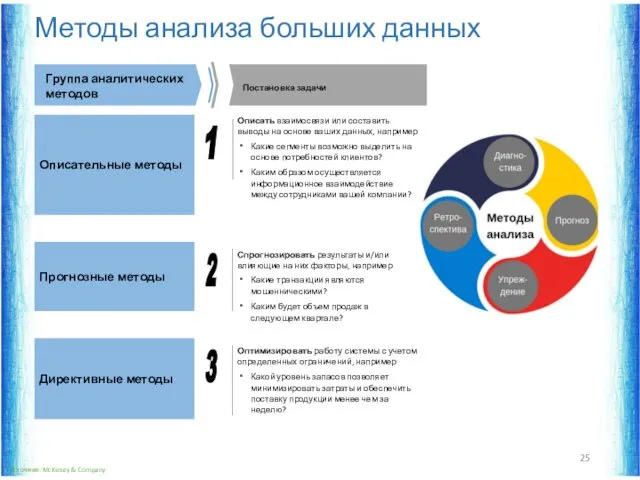
Методы анализа больших данных
Описательные методы
Прогнозные методы
Директивные методы
Описать взаимосвязи или составить выводы
Методы анализа больших данных
Описательные методы
Прогнозные методы
Директивные методы
Описать взаимосвязи или составить выводы
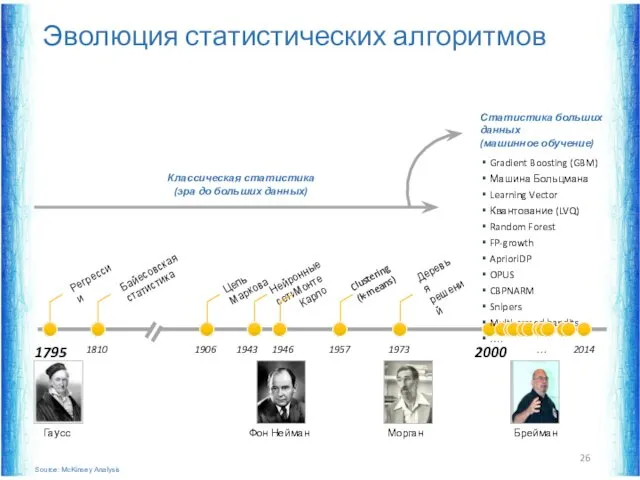
Эволюция статистических алгоритмов
1795
1810
1946
1957
1973
1906
Регрессии
Байесовская статистика
Цепь Маркова
Нейронные сети
1943
Монте Карло
Clustering
(k-means)
Деревья
решений
Классическая статистика
(эра до
Эволюция статистических алгоритмов
1795
1810
1946
1957
1973
1906
Регрессии
Байесовская статистика
Цепь Маркова
Нейронные сети
1943
Монте Карло
Clustering
(k-means)
Деревья
решений
Классическая статистика (эра до
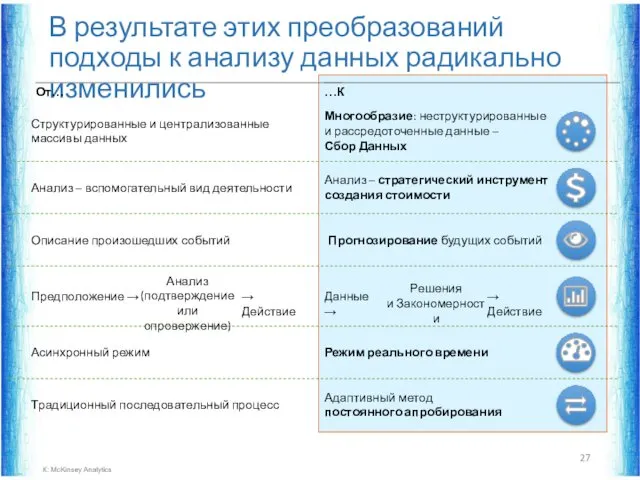
В результате этих преобразований подходы к анализу данных радикально изменились
ИСТОЧНИК: McKinsey
В результате этих преобразований подходы к анализу данных радикально изменились
ИСТОЧНИК: McKinsey
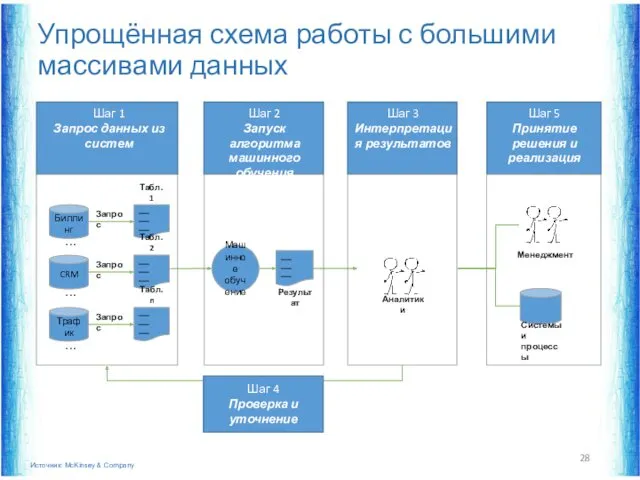
Упрощённая схема работы с большими массивами данных
___
___
___
Результат
Машинное
обучение
Аналитики
Системы и
процессы
Менеджмент
Шаг 4
Проверка и
Упрощённая схема работы с большими массивами данных
___
___
___
Результат
Машинное
обучение
Аналитики
Системы и
процессы
Менеджмент
Шаг 4 Проверка и

Комплексный подход к большим данным
1. ДАННЫЕ
3. ОРГАНИЗАЦИОННАЯ СТРУКТУРА И
БИЗНЕС-ПРОЦЕССЫ
2. АНАЛИТИКА
4.
Комплексный подход к большим данным
1. ДАННЫЕ
3. ОРГАНИЗАЦИОННАЯ СТРУКТУРА И
БИЗНЕС-ПРОЦЕССЫ
2. АНАЛИТИКА
4.

Джозеп Курто, управляющий независимой консалтинговой компанией Delfos Research, ассоциированный профессор IE
Джозеп Курто, управляющий независимой консалтинговой компанией Delfos Research, ассоциированный профессор IE
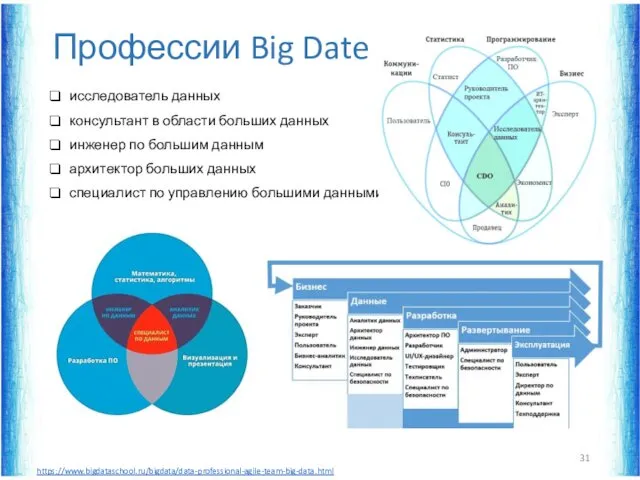
Профессии Big Date
исследователь данных
консультант в области больших данных
инженер по большим
Профессии Big Date
исследователь данных
консультант в области больших данных
инженер по большим

Игроки на рынке Big Date
Поставщики инфраструктуры — решают задачи хранения и предобработки
Игроки на рынке Big Date
Поставщики инфраструктуры — решают задачи хранения и предобработки

Направления Big Date
Сбор и обработка больших данных
Аналитика
Инженерия больших данных
Архитектура больших данных
Направления Big Date
Сбор и обработка больших данных
Аналитика
Инженерия больших данных
Архитектура больших данных
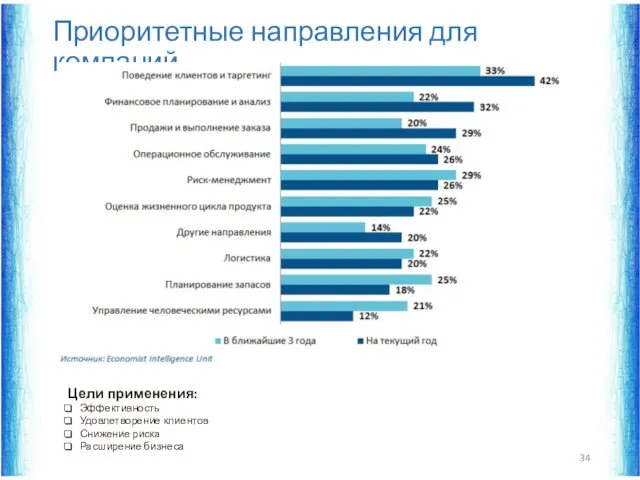
Приоритетные направления для компаний
Цели применения:
Эффективность
Удовлетворение клиентов
Снижение риска
Расширение бизнеса
Приоритетные направления для компаний
Цели применения:
Эффективность
Удовлетворение клиентов
Снижение риска
Расширение бизнеса
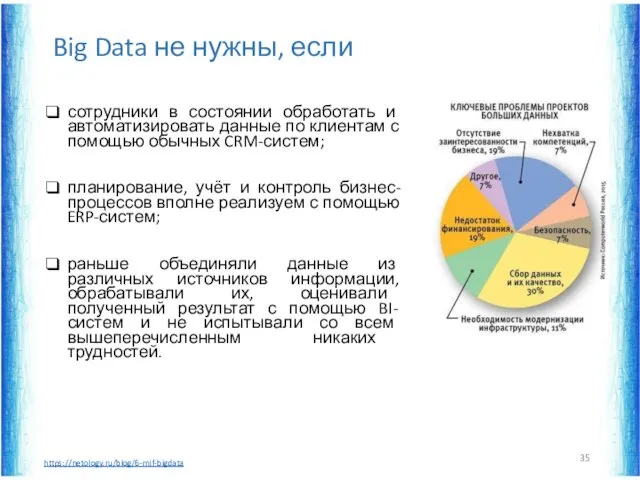
Big Data не нужны, если
сотрудники в состоянии обработать и автоматизировать данные
Big Data не нужны, если
сотрудники в состоянии обработать и автоматизировать данные

Мэтт Слокум из O'Reilly Radar считает, что хотя большие данные и
Мэтт Слокум из O'Reilly Radar считает, что хотя большие данные и
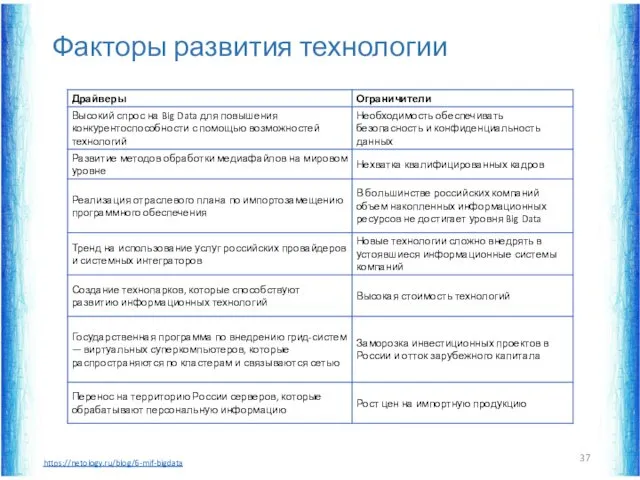
Факторы развития технологии
https://netology.ru/blog/6-mif-bigdata
Факторы развития технологии
https://netology.ru/blog/6-mif-bigdata
Машинное обучение и большие данные
Машинное обучение и большие данные
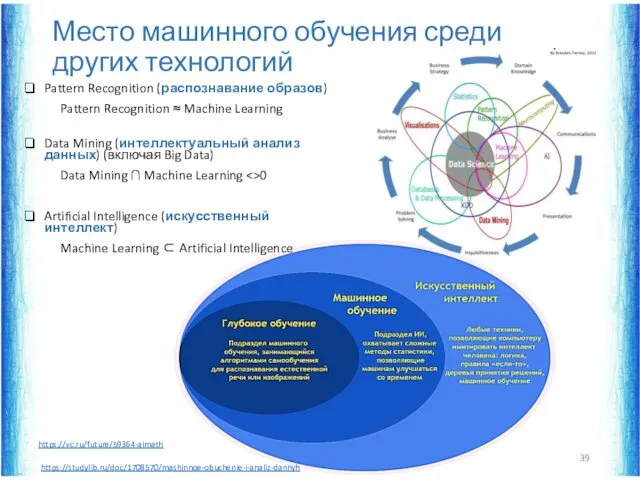
Место машинного обучения среди других технологий
https://vc.ru/future/59364-aimath
https://studylib.ru/doc/1708570/mashinnoe-obuchenie-i-analiz-dannyh
Pattern Recognition (распознавание образов)
Место машинного обучения среди других технологий
https://vc.ru/future/59364-aimath
https://studylib.ru/doc/1708570/mashinnoe-obuchenie-i-analiz-dannyh
Pattern Recognition (распознавание образов)

Типы обучения
Дедуктивное или аналитическое обучение (экспертные системы).
Имеются знания, сформулированные экспертом и
Типы обучения
Дедуктивное или аналитическое обучение (экспертные системы).
Имеются знания, сформулированные экспертом и
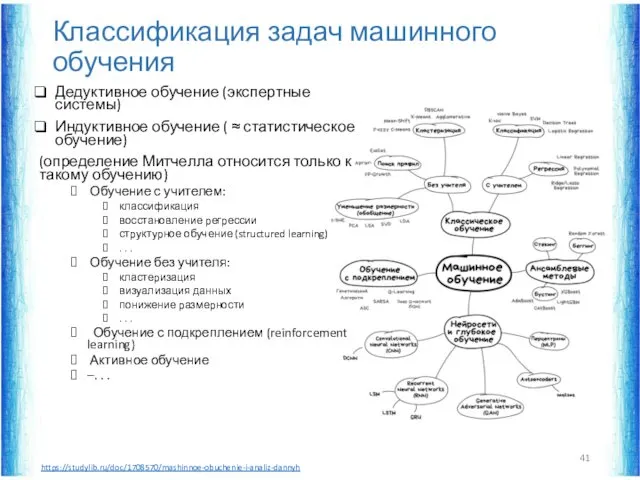
Классификация задач машинного обучения
Дедуктивное обучение (экспертные системы)
Индуктивное обучение ( ≈ статистическое
Классификация задач машинного обучения
Дедуктивное обучение (экспертные системы)
Индуктивное обучение ( ≈ статистическое
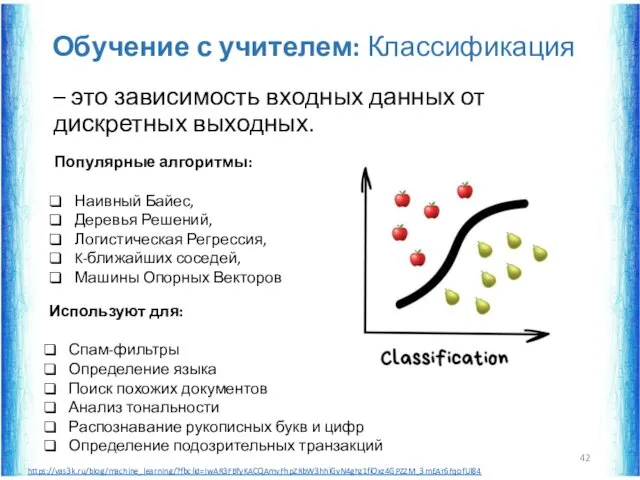
Обучение с учителем: Классификация
– это зависимость входных данных от дискретных выходных.
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
Обучение с учителем: Классификация
– это зависимость входных данных от дискретных выходных.
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
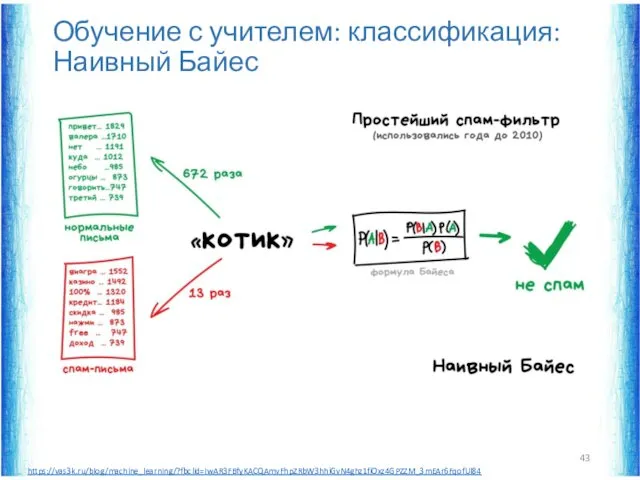
Обучение с учителем: классификация: Наивный Байес
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
Обучение с учителем: классификация: Наивный Байес
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
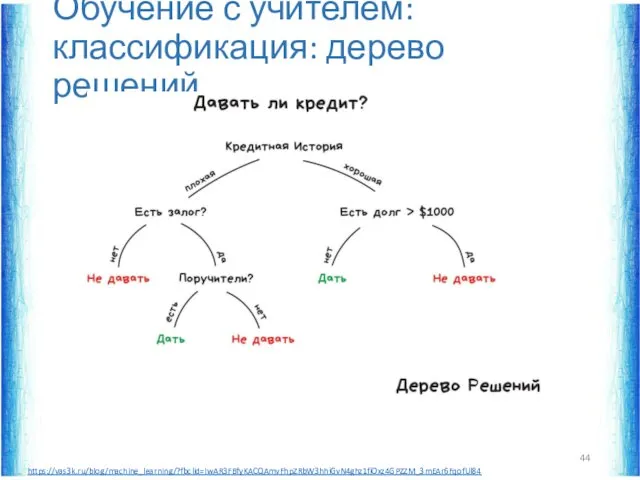
Обучение с учителем: классификация: дерево решений
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
Обучение с учителем: классификация: дерево решений
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
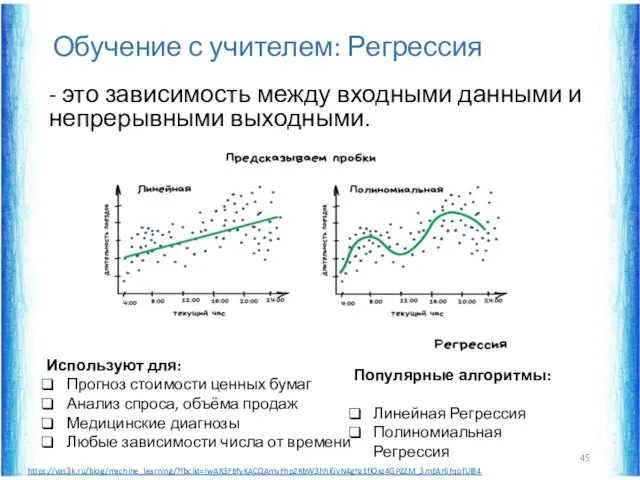
Обучение с учителем: Регрессия
- это зависимость между входными данными и непрерывными
Обучение с учителем: Регрессия
- это зависимость между входными данными и непрерывными

Обучение без учителя: Кластеризация
- это группировка данных руководствуясь свойствами этих данных.
Обучение без учителя: Кластеризация
- это группировка данных руководствуясь свойствами этих данных.
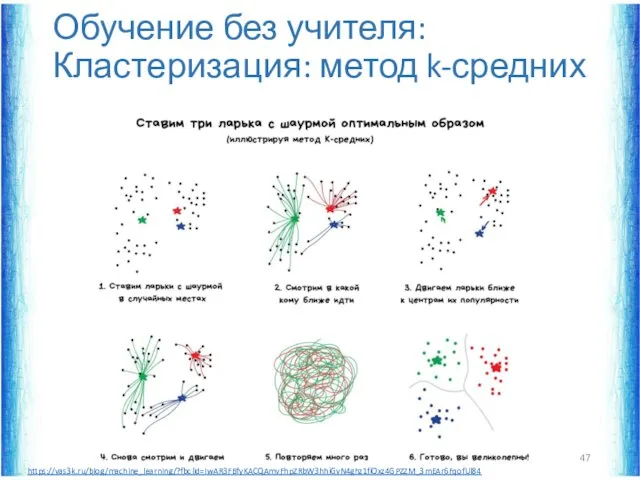
Обучение без учителя: Кластеризация: метод k-средних
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
Обучение без учителя: Кластеризация: метод k-средних
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84

Обучение без учителя: Ассоциация
– поиск закономерностей между связанными событиями. К примеру,
Обучение без учителя: Ассоциация
– поиск закономерностей между связанными событиями. К примеру,

Последовательные шаблоны
– установление закономерностей между связанными во времени событиями, т.е. обнаружение
Последовательные шаблоны
– установление закономерностей между связанными во времени событиями, т.е. обнаружение
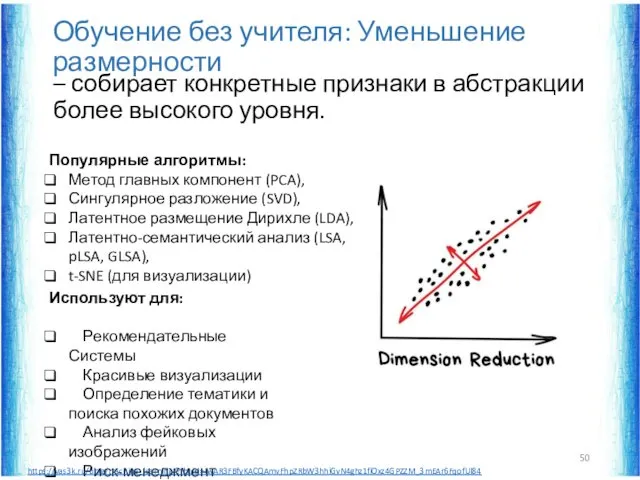
Обучение без учителя: Уменьшение размерности
– собирает конкретные признаки в абстракции более
Обучение без учителя: Уменьшение размерности
– собирает конкретные признаки в абстракции более
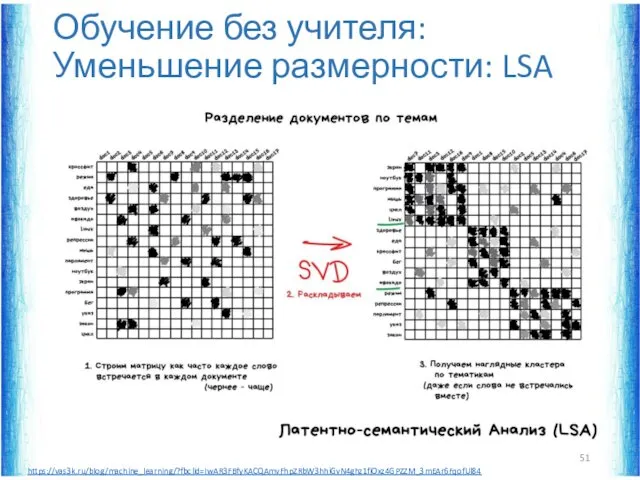
Обучение без учителя: Уменьшение размерности: LSA
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
Обучение без учителя: Уменьшение размерности: LSA
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
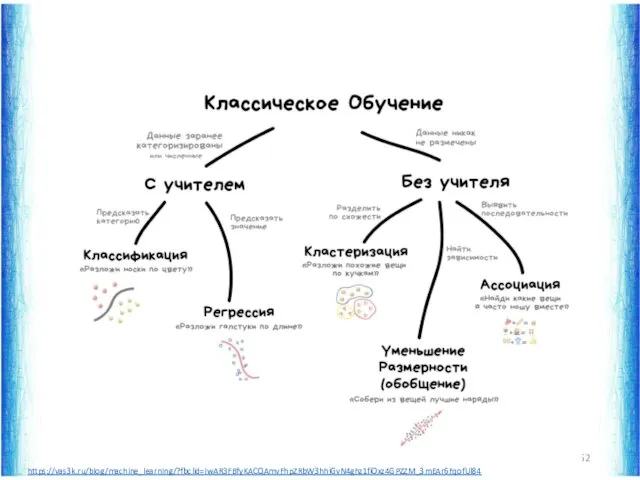
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
https://vas3k.ru/blog/machine_learning/?fbclid=IwAR3FBfyKACQAmvFhpZRbW3hhiGvN4ghz1fiOxz4GPZZM_3mEAr6FqofUl84
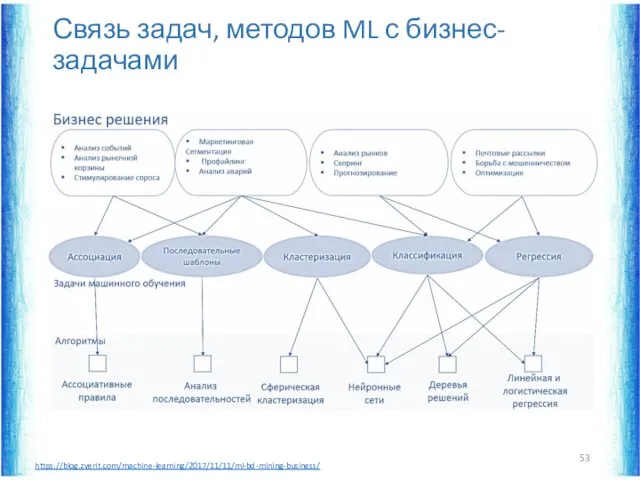
Связь задач, методов ML с бизнес-задачами
https://blog.zverit.com/machine-learning/2017/11/11/ml-bd-mining-business/
Связь задач, методов ML с бизнес-задачами
https://blog.zverit.com/machine-learning/2017/11/11/ml-bd-mining-business/

Инструменты больших данных
Инструменты больших данных

http://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D0%B5_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5_(Big_Data)
http://www.tadviser.ru/index.php/%D0%A1%D1%82%D0%B0%D1%82%D1%8C%D1%8F:%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%B8%D0%B5_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5_(Big_Data)

Платформа Hadoop
Hadoop – это это свободно распространяемый набор программных средств (Software
Платформа Hadoop
Hadoop – это это свободно распространяемый набор программных средств (Software
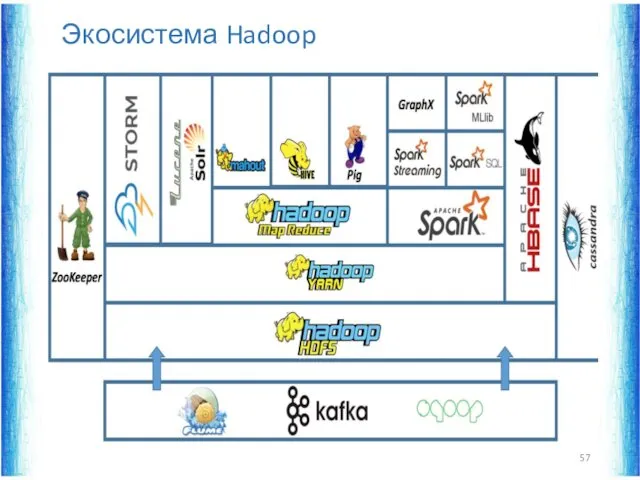
Экосистема Hadoop
Экосистема Hadoop

Примеры кейсов с большими данными
Примеры кейсов с большими данными

Командообразование
2002, бейсбольная команда «Oakland Athletics» генеральный менеджер Билли Бин, выпускник экономического
Командообразование
2002, бейсбольная команда «Oakland Athletics» генеральный менеджер Билли Бин, выпускник экономического

Таргетированный маркетинг
ВОЗМОЖНОСТИ
Воздействие на клиента в нужное время
В нужном месте (определение локаций)
Распознавание
Таргетированный маркетинг
ВОЗМОЖНОСТИ
Воздействие на клиента в нужное время
В нужном месте (определение локаций)
Распознавание

Американская сеть магазинов Target и беременная девочка
Target ежегодно тратит около 4 миллионов долларов
Американская сеть магазинов Target и беременная девочка
Target ежегодно тратит около 4 миллионов долларов

Классификация пользователя
Психологи Кембриджского университета изучали, как ставят «лайки» 58 тысяч пользователей
Классификация пользователя
Психологи Кембриджского университета изучали, как ставят «лайки» 58 тысяч пользователей

Данные для таргетирования – все действия в сети
Компания Bombora (США)
Данные для таргетирования – все действия в сети
Компания Bombora (США)

Дискриминация в ценообразование или…
«Некоторые онлайн-ресурсы показывают разные цены на товары
Дискриминация в ценообразование или…
«Некоторые онлайн-ресурсы показывают разные цены на товары
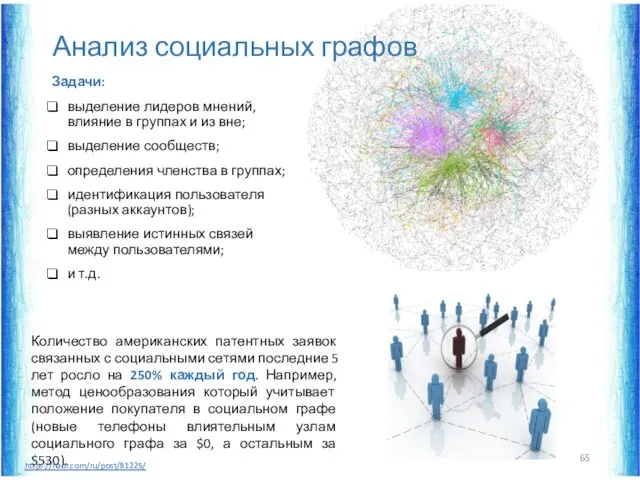
Анализ социальных графов
Задачи:
выделение лидеров мнений, влияние в группах и из вне;
выделение
Анализ социальных графов
Задачи:
выделение лидеров мнений, влияние в группах и из вне;
выделение

Методы NLP, Text Mining
О чем говорят?
Кто говорит?
Как говорят?
Обработка естественного языка (Natural
Методы NLP, Text Mining
О чем говорят?
Кто говорит?
Как говорят?
Обработка естественного языка (Natural
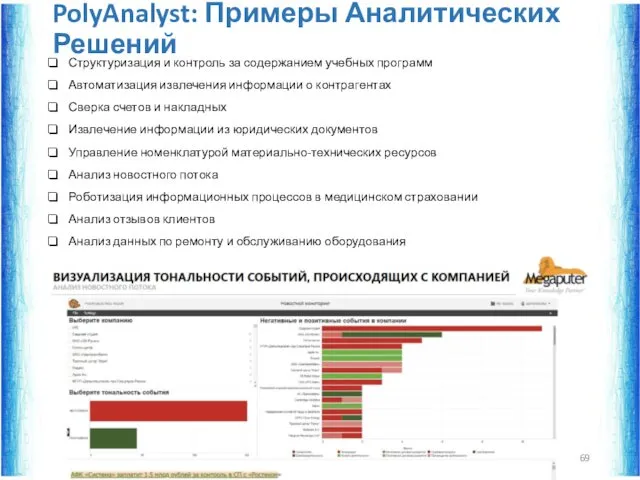
PolyAnalyst: Примеры Аналитических Решений
Структуризация и контроль за содержанием учебных программ
Автоматизация извлечения
PolyAnalyst: Примеры Аналитических Решений
Структуризация и контроль за содержанием учебных программ
Автоматизация извлечения

Примеры (зарубежные кейсы)
HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает,
Примеры (зарубежные кейсы)
HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает,

Примеры (отечественные кейсы)
Яндекс. Это корпорация, которая управляет одним из самых
Примеры (отечественные кейсы)
Яндекс. Это корпорация, которая управляет одним из самых

«Анонимности в сети нет»
Российская компания SocialDataHub
в считанные часы смогла опознать
«Анонимности в сети нет»
Российская компания SocialDataHub
в считанные часы смогла опознать

Насколько законно собирать данные о людях?
Федеральный закон "О персональных данных" эксперты оценивают как
Насколько законно собирать данные о людях?
Федеральный закон "О персональных данных" эксперты оценивают как

О чем спорят «ВКонтакте» и Double Data
https://www.rbc.ru/technology_and_media/04/09/2019/5d6e5f6d9a794784dea7c2e2
2017 ВКонтакте судится с
О чем спорят «ВКонтакте» и Double Data
https://www.rbc.ru/technology_and_media/04/09/2019/5d6e5f6d9a794784dea7c2e2
2017 ВКонтакте судится с

Кто владеет информацией, тот владеет миром.
Натан Ротшильд
Именно то, как вы
Натан Ротшильд
Именно то, как вы

Не забывай: информация не есть знание, знание не есть мудрость, мудрость
Не забывай: информация не есть знание, знание не есть мудрость, мудрость
 Проблема терроризма в России. Бесланская трагедия
Проблема терроризма в России. Бесланская трагедия Организация планирования на предприятии
Организация планирования на предприятии Дальневосточный центр судостроения и судоремонта
Дальневосточный центр судостроения и судоремонта Процесс систематизации экономических знаний. (Лекция 2)
Процесс систематизации экономических знаний. (Лекция 2) Индикативный метод оценки экономической безопасности
Индикативный метод оценки экономической безопасности Планирование и прогнозирование в экономике
Планирование и прогнозирование в экономике Topics in Macroeconomics
Topics in Macroeconomics Источники инвестирования развития электроэнергетики. Лекция 1
Источники инвестирования развития электроэнергетики. Лекция 1 Россия в процессах международной миграции рабочей силы
Россия в процессах международной миграции рабочей силы Теория организации. Науки, изучающие организации. (Часть 1)
Теория организации. Науки, изучающие организации. (Часть 1) Экономика и государство
Экономика и государство Трансакционные издержки
Трансакционные издержки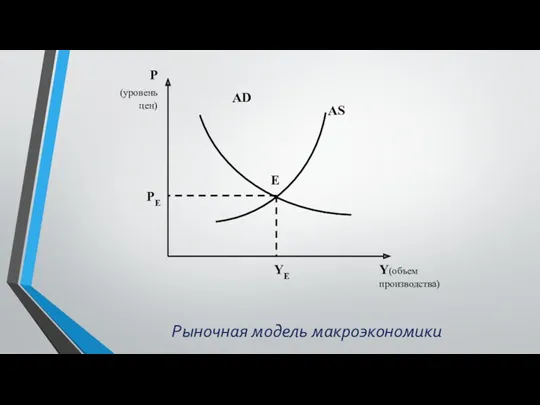 Циклические колебания развития экономики. Рыночная модель макроэкономики
Циклические колебания развития экономики. Рыночная модель макроэкономики Инвестиции и инвестиционная деятельность в рыночной экономике
Инвестиции и инвестиционная деятельность в рыночной экономике Mergers and Acquisition deals
Mergers and Acquisition deals Мировой рынок газа
Мировой рынок газа Система национальных счетов. Основные макроэкономические показатели
Система национальных счетов. Основные макроэкономические показатели Экономика: наука и хозяйство
Экономика: наука и хозяйство Системный анализ в экономике. Технология прикладного системного анализа (ПСА)
Системный анализ в экономике. Технология прикладного системного анализа (ПСА) Государственное регулирование предпринимательства
Государственное регулирование предпринимательства Что такое деньги (окружающий мир)
Что такое деньги (окружающий мир) Инфрақұрылымды дамытудың Нұрлы жол мемлекеттік бағдарламасын іске асыру туралы
Инфрақұрылымды дамытудың Нұрлы жол мемлекеттік бағдарламасын іске асыру туралы Национальная экономика и общественное воспроизводство
Национальная экономика и общественное воспроизводство Экономические взгляды Уильяма Петти
Экономические взгляды Уильяма Петти Казахстан и ВТО
Казахстан и ВТО Микроэкономика (1)
Микроэкономика (1) Проблема ограниченности экономических ресурсов и ее последствия
Проблема ограниченности экономических ресурсов и ее последствия Фирмы в экономике
Фирмы в экономике