Adaptive libraries for multicore architectures with explicitly-managed memory hierarchies презентация
- Adaptive libraries for multicore architectures with explicitly-managed memory hierarchies

Содержание
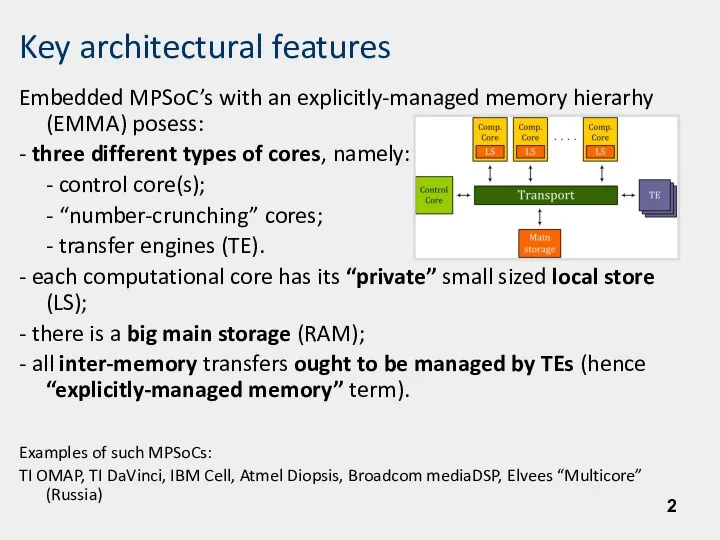
- 2. Key architectural features Embedded MPSoC’s with an explicitly-managed memory hierarhy (EMMA) posess: - three different types
- 3. Programming issues - workload distribution among computational cores; information transfers distribution among different channels: - trying
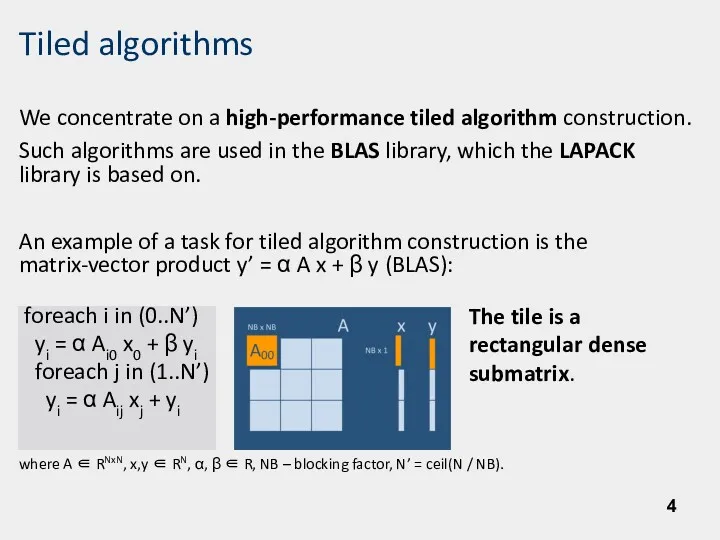
- 4. Tiled algorithms We concentrate on a high-performance tiled algorithm construction. Such algorithms are used in the
- 5. Program as a coarse-grained dataflow graph Each program could be represented as a macro-flow graph. Bigger
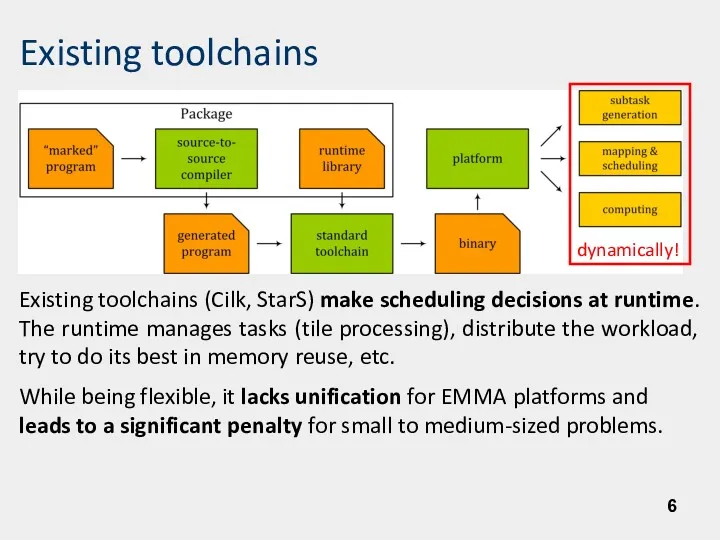
- 6. Existing toolchains Existing toolchains (Cilk, StarS) make scheduling decisions at runtime. The runtime manages tasks (tile
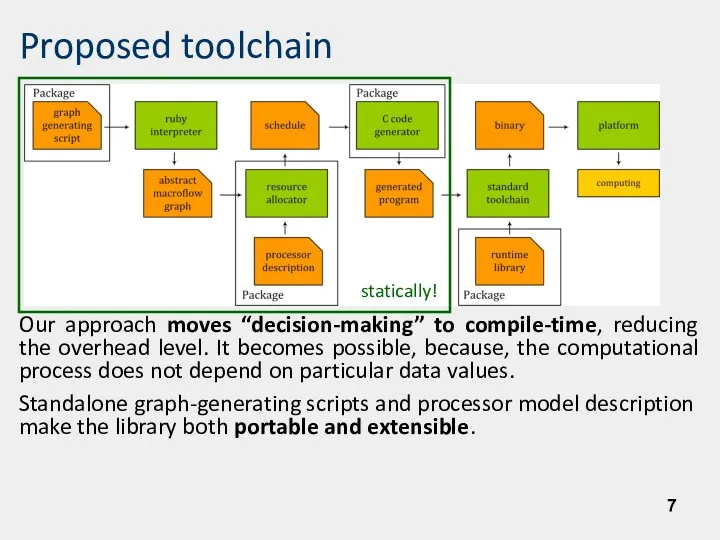
- 7. Proposed toolchain Our approach moves “decision-making” to compile-time, reducing the overhead level. It becomes possible, because,
- 8. How does it feel? User: 1. Wants to generate a parallel program. Runs single command, e.g.:
- 9. How fast is it? Scales almost linearly up to 16 cores of a synthetic multicore processor
- 11. Скачать презентацию
Key architectural features
Embedded MPSoC’s with an explicitly-managed memory hierarhy (EMMA) posess:
-
Key architectural features
Embedded MPSoC’s with an explicitly-managed memory hierarhy (EMMA) posess:
-

Programming issues
- workload distribution among computational cores;
information transfers distribution among
Programming issues
- workload distribution among computational cores;
information transfers distribution among
Tiled algorithms
We concentrate on a high-performance tiled algorithm construction.
Such algorithms are
Tiled algorithms
We concentrate on a high-performance tiled algorithm construction.
Such algorithms are

Program as a coarse-grained dataflow graph
Each program could be represented as
Program as a coarse-grained dataflow graph
Each program could be represented as
Existing toolchains
Existing toolchains (Cilk, StarS) make scheduling decisions at runtime. The
Existing toolchains
Existing toolchains (Cilk, StarS) make scheduling decisions at runtime. The
Proposed toolchain
Our approach moves “decision-making” to compile-time, reducing the overhead level.
Proposed toolchain
Our approach moves “decision-making” to compile-time, reducing the overhead level.

How does it feel?
User:
1. Wants to generate a parallel program.
Runs
How does it feel?
User:
1. Wants to generate a parallel program.
Runs
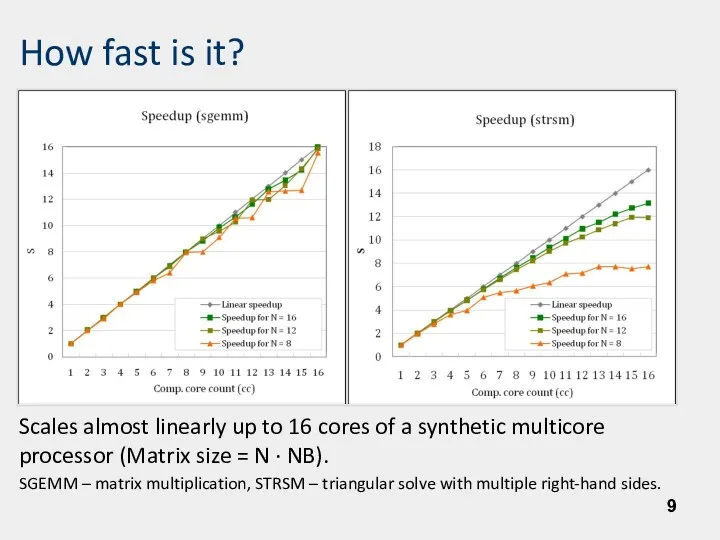
How fast is it?
Scales almost linearly up to 16 cores of
How fast is it?
Scales almost linearly up to 16 cores of
 Возможности ресурса Google Earth
Возможности ресурса Google Earth Delphi программасымен жұмыс жасау ерекшелігі және оны пайдалану тәсілдері
Delphi программасымен жұмыс жасау ерекшелігі және оны пайдалану тәсілдері Створення лінійних алгоритмів
Створення лінійних алгоритмів Теория информации. Построить код Хаффмана для букв русского алфавита
Теория информации. Построить код Хаффмана для букв русского алфавита Измерение информации. Единицы измерения информации
Измерение информации. Единицы измерения информации Коммерческое предложение. Комплексное размещение рекламы на всех платформах 2ГИС - в ПК
Коммерческое предложение. Комплексное размещение рекламы на всех платформах 2ГИС - в ПК Игра Какуро, 1 класс
Игра Какуро, 1 класс Учебный курс Сетевое программное обеспечение. Сеть Н.323
Учебный курс Сетевое программное обеспечение. Сеть Н.323 Представление информации в компьютере
Представление информации в компьютере Электронные таблицы. Табличный процессор Microsoft Excel
Электронные таблицы. Табличный процессор Microsoft Excel Ақылды қалам знаток
Ақылды қалам знаток Программное обеспечение. § 35. Введение
Программное обеспечение. § 35. Введение Устройство и система команд алгоритмической машины Поста
Устройство и система команд алгоритмической машины Поста Реляційні СУБД та тенденції їх розвитку
Реляційні СУБД та тенденції їх розвитку Универсальные информационные ресурсы
Универсальные информационные ресурсы Информационные технологии
Информационные технологии Электронные таблицы. Диаграммы
Электронные таблицы. Диаграммы Информатика и информатизация общества
Информатика и информатизация общества Елементи статистичної фізики у комп’ютерному моделюванні
Елементи статистичної фізики у комп’ютерному моделюванні Системы счисления. Математические основы информатики
Системы счисления. Математические основы информатики Характерные черты информационного общества
Характерные черты информационного общества История возникновения чисел и систем счисления
История возникновения чисел и систем счисления Основные виды обеспечения вычислительной системы
Основные виды обеспечения вычислительной системы Оцінка курсів у системі Moodle
Оцінка курсів у системі Moodle Методы искусственного интеллекта
Методы искусственного интеллекта DCL. Access Control. Lecture 5
DCL. Access Control. Lecture 5 Modeling and Solving Constraints. Basic Idea
Modeling and Solving Constraints. Basic Idea Разработка сайта преподавателя истории и философии
Разработка сайта преподавателя истории и философии