- Администрирование баз данных

Содержание
- 2. Администрирование баз данных Типы и структура СУБД Запросы, индексы и эксплейны Администрирование MySQL Администрирование PostgreSQL Troubleshooting
- 3. Типы и структура СУБД
- 4. Типы и структура СУБД Типы БД, называемых также моделями БД или семействами БД, представляют собой шаблоны
- 5. Основные функции и компоненты СУБД Поддержка целостности файлов Восстановление согласованного состояния данных после сбоев Обеспечение параллельной
- 6. Управление данными во внешней памяти Для хранения данных и метаданных, входящих в БД Для служебных целей
- 7. Управление буферами оперативной памяти Управление буферами оперативной памяти (ОП) необходимо для увеличения скорости работы с данными.
- 8. Управление транзакциями Транзакция — это последовательность операций над БД, рассматриваемых СУБД как единое целое: либо все
- 9. Журнализация Журнализация необходима для восстановления БД в случае сбоев. Одним из основных требований к СУБД является
- 10. Пример WAL PostgreSQL postgres@s-pg13:~$ psql Timing is on. psql (13.3) Type "help" for help. postgres@postgres=# SELECT
- 11. Пример WAL PostgreSQL postgres@postgres=# SELECT pg_current_wal_lsn() AS pos1 \gset Time: 0,224 ms postgres@postgres=# CREATE TABLE t(n
- 12. Пример WAL PostgreSQL postgres@postgres=# SELECT * FROM pg_ls_waldir(); name | size | modification --------------------------+----------+------------------------ 000000010000000000000001 |
- 13. Пример WAL PostgreSQL postgres@postgres=# \q postgres@s-pg13:~$ ps -o pid,command --ppid `head -n 1 $PGDATA/postmaster.pid` PID COMMAND
- 14. Пример WAL PostgreSQL postgres@s-pg13:~$ rm /home/postgres/logfile postgres@s-pg13:~$ pg_ctl -w -l /home/postgres/logfile -D /usr/local/pgsql/data restart waiting for
- 15. Пример WAL PostgreSQL postgres@s-pg13:~$ rm /home/postgres/logfile postgres@s-pg13:~$ pg_ctl -w -D /usr/local/pgsql/data stop -m immediate waiting for
- 16. Пример WAL PostgreSQL postgres@s-pg13:~$ cat /home/postgres/logfile 2022-10-15 15:32:37.988 MSK [29389] LOG: starting PostgreSQL 13.3 on x86_64-pc-linux-gnu,
- 17. Типовая организация современной СУБД Основные функции СУБД Управление данными во внешней памяти Управление буферами оперативной памяти
- 18. Ядро СУБД Менеджер данных Менеджер буферов Менеджер транзакций Менеджер журнала
- 19. Утилиты БД загрузка и выгрузка БД сбор статистики глобальная проверка целостности БД
- 20. Классификация СУБД По модели данных Загрузка и выгрузка БД Сетевые Иерархические Реляционные (и sql-ориентированные) Объектно-ориентированные Xml-ориентированные
- 21. Универсальные и специализированные СУБД
- 22. Файл/клиент-серверные и встраиваемые СУБД СУБД Файл-серверные
- 23. Файл/клиент-серверные и встраиваемые СУБД СУБД Файл-серверные Клиент-серверные
- 24. Файл/клиент-серверные и встраиваемые СУБД СУБД Файл-серверные Клиент-серверные Встраиваемые
- 25. СУБД по месту хранения БД Внешняя память вообще не используется, а надёжность достигается за счёт хранения
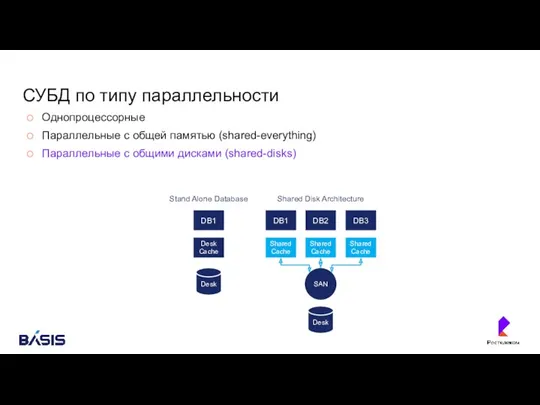
- 26. СУБД по типу параллельности Однопроцессорные
- 27. СУБД по типу параллельности Однопроцессорные Параллельные с общей памятью (shared-everything)
- 28. СУБД по типу параллельности Однопроцессорные Параллельные с общей памятью (shared-everything) Параллельные с общими дисками (shared-disks)
- 29. СУБД по типу параллельности Однопроцессорные Параллельные с общей памятью (shared-everything) Параллельные с общими дисками (shared-disks) Параллельные
- 30. Запросы, индексы и эксплейны
- 31. Что такое индексы? Индексы (indexes) – это особые таблицы, используемые поисковыми системами для поиска данных
- 32. Нельзя создать индекс Столбцов, которые используются для хранения данных объектов, имеющих большие размеры, (LOB): TEXT, IMAGE,
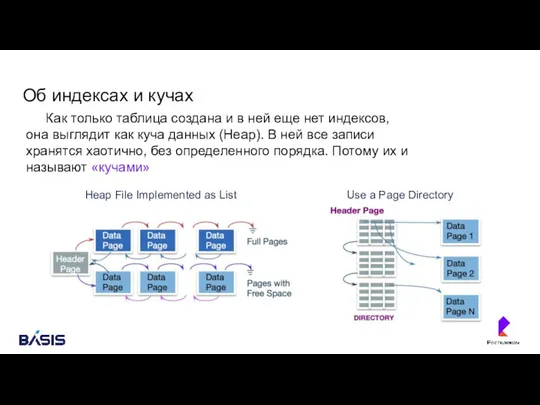
- 33. Об индексах и кучах Как только таблица создана и в ней еще нет индексов, она выглядит
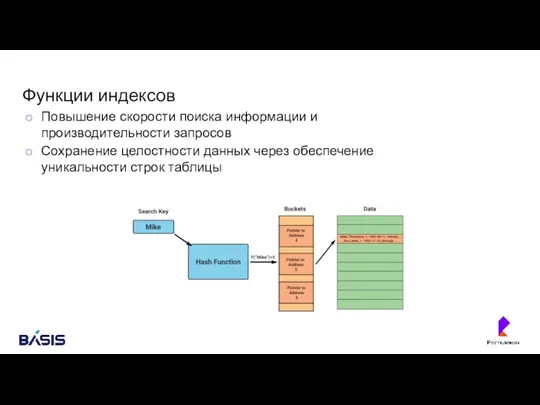
- 34. Функции индексов Повышение скорости поиска информации и производительности запросов Сохранение целостности данных через обеспечение уникальности строк
- 35. Структура индексов Наборов страниц Узлов, имеющих древовидную структуру, иерархическую по природе
- 36. Типы индексов. Кластерный индекс Задача — сохранение табличных данных в виде, отсортированном по значению ключа.
- 37. Типы индексов. Некластерный индекс Индекс содержит Значения ключей – ключевые столбцы, по которым они определены Указатели
- 38. Специальные типы индексов Фильтруемый (Filtered)
- 39. Специальные типы индексов Фильтруемый (filtered) Составной (composite)
- 40. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique)
- 41. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique) Колоночный (columnstore)
- 42. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique) Колоночный (columnstore) Пространственный (spatial)
- 43. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique) Колоночный (columnstore) Пространственный (spatial) Полнотекстовый (full-text)
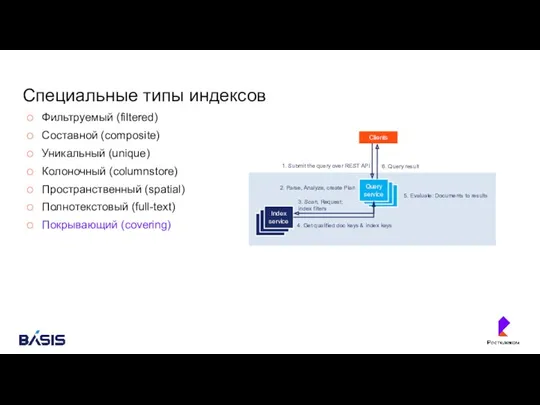
- 44. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique) Колоночный (columnstore) Пространственный (spatial) Полнотекстовый (full-text) Покрывающий
- 45. Специальные типы индексов Фильтруемый (filtered) Составной (composite) Уникальный (unique) Колоночный (columnstore) Пространственный (spatial) Полнотекстовый (full-text) Покрывающий
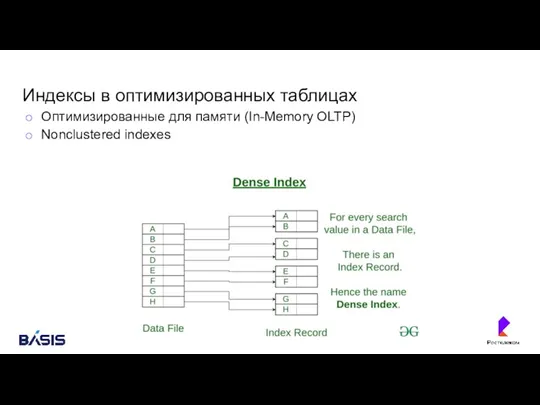
- 46. Индексы в оптимизированных таблицах Оптимизированные для памяти (In-Memory OLTP) Nonclustered indexes
- 47. Performance database Если предполагается частое обновление данных в таблице, то для нее нужно применять минимум индексов
- 48. Запросы к БД Предпочтительнее, чтобы один запрос содержал наибольшее число строк На столбцах, используемых в запросах
- 49. Способы создания индексов ms sql server SSMS (MSSQL Management Studio) Специальный язык Transact-SQL
- 50. Создать кластерный индекс в Management Studio Открыть SSMS Выбрать соответствующую таблицу Остановившись на пункте «Индексы» Выбрать
- 51. Создать некластерный индекс в Management Studio Открыть SSMS Выбрать требуемую таблицу и щелкнуть по пункту «Индексы»
- 52. Удаление индекса в Management Studio Открыть SSMS Выбрать индекс, подлежащий удалению Щелкнуть мышкой по нему и
- 53. Оптимизация индексов Выполнить запрос: SELECT OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS
- 54. Реорганизация индексов Открыть SSMS На выбранном индексе следует щелкнуть мышкой, из списка выбрать и нажать «Реорганизовать»
- 55. Перестроение индексов Открыть SSMS: Выбрать нужный индекс, мышкой кликнуть по нему и выбрать «Перестроить» ALTER INDEX
- 56. Администрирование MySQL
- 57. База данных MySQL MySQL является ведущей системой управления базами данных с открытым исходным кодом. Разработка MySQL
- 58. Основные понятия и компоненты MySQL Каталог данных - содержит всю информацию, которая управляется сервером «mysqld» (базы
- 59. Основные понятия и компоненты MySQL База данных - каждая БД представляет собой подкаталог в каталоге «каталога
- 60. Основные понятия и компоненты MySQL Файлы состояний MySQL .pid PID процесса сервера --pid-file .err журнал ошибок
- 61. Основные программы и утилиты MySQL
- 62. Полезные команды/запросы клиента mysql Подключение к серверу MySQL с БД осуществляется с помощью клиента «mysql». Синтаксис
- 63. Полезные команды/запросы клиента mysql
- 64. Полезные команды/запросы клиента mysql
- 65. Полезные команды/запросы клиента mysql Чтобы найти все установленные файлы какого-либо пакета, можно воспользоваться командой: shell#> pkg_info
- 66. Полезные команды/запросы клиента mysql Чтобы найти справку по нужному оператору надо выполнить соответствующий запрос SELECT. Пример:
- 67. Методы запуска сервера Непосредственный вызов mysqld
- 68. Методы запуска сервера Непосредственный вызов mysqld Вызов сценария safemysqld(mysqld_safe)
- 69. Методы запуска сервера Непосредственный вызов mysqld Вызов сценария safemysqld(mysqld_safe) Вызов сценария mysql.server
- 70. Определение опций запуска Во-первых, можно изменить используемый сценарий запуска (safemysqld или mysql.server ) и задать параметры
- 71. Завершение работы сервера Для самостоятельного завершения работы сервера применяется команда mysqladmin: % mysqladmin shutdown
- 72. Работа с учетными записями пользователей MySQL Идентификация и права доступа Проверка прав доступа к данным осуществляется
- 73. Работа с учетными записями пользователей MySQL Четыре уровня привилегий Глобальный уровень: Глобальные привилегии применяются ко всем
- 74. Работа с учетными записями пользователей MySQL Два типа полей Поля контента Поля привилегий Поля контекста определяют
- 75. Создание MySQL пользователей и назначение прав Создавать/удалять пользователей MySQL можно используя, операторы CREATE USER, DROP USER:
- 76. Создание MySQL пользователей и назначение прав Назначать привилегии лучше используя, оператор GRANT: GRANT priv_type [(column_list)] [,
- 77. Создание MySQL пользователей и назначение прав Отнимать привилегии лучше используя, оператор REVOKE. REVOKE priv_type [(column_list)] [,
- 78. Поиск разрешения прав идет следующим образом: «use» => «db» & «host» => «tables_priv» => «columns_priv» или
- 79. Сменить пароль можно с помощью оператора SET PASSWORD SET PASSWORD = PASSWORD('some password') SET PASSWORD FOR
- 80. Создание резервной копии БД mysqldump «mysqldump» - консольный клиент для «бэкапа», создания «дампов» БД MySQL. «Дамп»
- 81. Восстановление БД из «дамп» файлов Восстанавливать информацию из «дампа»: shell#> cat / / | mysql Или
- 82. Обнаружение ошибок и восстановление БД после сбоя Процедура обнаружения и исправления ошибок состоит из этапов: Проверка
- 83. Проверка таблиц на наличие ошибок Проверять и восстанавливать MyISAM таблицы можно с помощью утилиты «myisamchk», а
- 84. Проверка таблиц на наличие ошибок Для определения нескольких таблиц каталога: shell#> myisamchk список_опций_проверки *.MYI Где «список_опций_проверки»:
- 85. Исправление таблиц, содержащих ошибки Для исправления ошибок можно: восстановление без модификации файла данных (.MYD) shell> myisamchk
- 86. Восстановление INDEX файла таблицы (*.MYI) Перейти в каталог БД, содержащий файлы поврежденной таблицы. Скопировать файл данных
- 87. Восстановление файла описания таблицы (*.frm) Чтобы воссоздать файл описаний таблицы, его можно восстановить из архива (если
- 88. Работа с блокировками таблиц во время ремонта Сервер MySQL использует два вида блокировок: внутренняя блокировка внешняя
- 89. Настройка основных параметров сервера --skip-name-resolve Эту опцию полезно использовать, когда в сети существуют «проблемы» с DNS,
- 90. Работа нескольких серверов mysql на ВМ Используется утилита «mysqld_safe» указав ей соответствующий конфигурационный файл в котором
- 91. Советы по повышению безопасности mysql Следить за последними обновлениями (заплатками) MySQL Ограничить с помощью брандмауэра, доступ
- 92. Советы по повышению безопасности mysql Привязать доступ пользователей MySQL к БД только заранее определенных хостов (поле
- 93. Советы по повышению безопасности mysql Установить для «каталога данных» и «журналов» MySQL разрешения на доступ и
- 94. Администрирование PostgreSQL
- 95. База данных PostgreSQL PostgreSQL является одной из наиболее популярных систем управления БД. Развитие postgresql началось еще
- 96. PostgreSQL. Утилита psql Для управления сервером баз данных PostgreSQL есть много разных инструментов, но при установке
- 97. Подключение к серверу баз данных Подключение выполняется таким способом: Таким образом если вы в системе находитесь
- 98. Получение информации об узле \conninfo
- 99. PostgreSQL. Утилита psql Все команды psql начинаются с символа обратного слеша “\”. Можно выполнять запросы SQL,
- 100. Файлы, которые использует psql .psqlrc Примеры настроек, которые можно ввести в ~/.psqlrc: \setenv PAGER 'less -XS'
- 101. Файлы, которые использует psql .psql_history Другой полезный файл это ~/.psql_history. В нем хранится история команд введенных
- 102. Формат выводимой информации Настроить формат выводимой информации: \a – с выравниванием/без выравнивания \t – отображение строки
- 103. Конфигурационный файл postgresql.conf Главный конфиг файл для кластера PostgreSQL – postgresql.conf По умолчанию он находится в
- 104. Информация о текущих настройках сервера В PostgreSQL есть 2 представления через которые можно посмотреть текущие настройки
- 105. Статистика работы PostgreSQL Статистика PostgreSQL включается в файле postgresql.conf: track_counts – обращения к таблицам и индексам
- 106. Статистика работы PostgreSQL Каждый backend процесс собирает статистику в процессе своей работы Раз в полсекунды, статистика
- 107. Статистика работы PostgreSQL Статистику можно смотреть в следующих представлениях:
- 108. Утилита pgbench В PostgreSQL есть специальная утилита pgbench. С помощью, которой можно произвести нагрузочное тестирование (НТ).
- 109. Текущие активности в PostgreSQL Инструменты текущей активности: Посмотреть на текущие активности сервера PostgreSQL с помощью представления
- 110. Журнал PostgreSQL. Настройка и анализ В журнал PostgreSQL записывает некоторые из своих действий Настраивая журналирование мы
- 111. Журнал PostgreSQL. Настройка и анализ Опции настройки журнала: log_destination = можем указать один, или через запятую
- 112. Что можем записывать в журнал? log_min_messages – минимальный уровень логирования. Допустимые значения: DEBUG5 – DEBUG1, INFO,
- 113. Что можем записывать в журнал? log_(dis)connections – (on или off) записывать подключения к серверу и отключения
- 114. Ротация журналов Настроить ротацию, если мы используем log_destination=stderr: log_filename – может принять не просто имя файла,
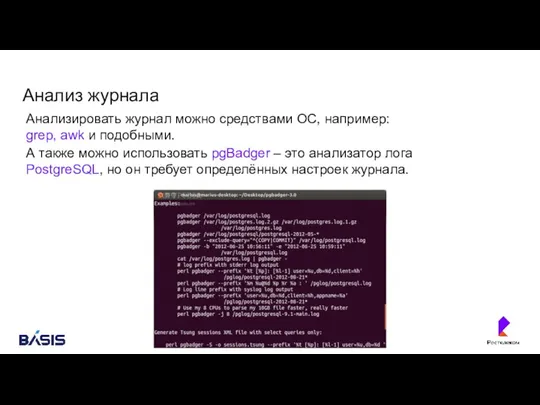
- 115. Анализ журнала Анализировать журнал можно средствами ОС, например: grep, awk и подобными. А также можно использовать
- 116. Роли и атрибуты в PostgreSQL В PostgreSQL пользователи и группы – это роли. Псевдороль public неявно
- 117. Управление ролями в PostgreSQL Создают роль следующим способом: Если при создании роли не указать атрибуты, то
- 118. Управление ролями в PostgreSQL Право включать роли в другие роли могут: Роль может включить в саму
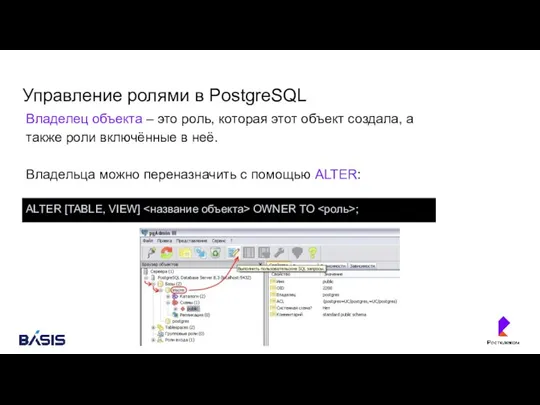
- 119. Управление ролями в PostgreSQL Владелец объекта – это роль, которая этот объект создала, а также роли
- 120. Процесс подключения Идентификация – определение имени роли БД. Аутентификация – проверка того, что пользователь тот за
- 121. Основные настройки аутентификации Конфигурационный файл отвечающий за настройки аутентификации – pg_hba.conf находится в каталоге PGDATA. Файл
- 122. Основные настройки аутентификации Если тип подключения, имя БД, имя пользователя и адрес сервера совпали, то применяется
- 123. Резервирование PostgreSQL Существует логическое и физическое резервирование PostgreSQL. Первый тип сохраняет SQL команды, выполнив которые можно
- 124. Логическое резервирование PostgreSQL Есть 3 инструмента для логического копирования: COPY – команда SQL для копирования данных
- 125. Физическое резервирование PostgreSQL Физическое резервное копирование разделяется на: Холодное резервирование (при выключенном сервере) – после корректного
- 126. Протокол репликации Протокол репликации – специальный протокол, который позволяет: Получать поток журнальных записей Выполнять команды управления
- 127. Протокол репликации Слот репликации – механизм для резервирования wal файлов. Подключившись по протоколу репликации, мы создаём
- 128. Архив журналов. Файловый архив. Сегменты WAL копируются в архив по мере заполнения; Механизм работает под управлением
- 129. Архив журналов. Потоковый архив. В архив постоянно записывается поток журнальных записей Требуются внешние средства Задержки минимальны
- 130. Репликация в PostgreSQL Репликация в PostgreSQL – это процесс синхронизации нескольких копий кластера БД на разных
- 131. Репликация в PostgreSQL Физическая – основной сервер передает поток wal записей на сервер репликации. Требования: Одинаковые
- 132. Физическая репликация PostgreSQL Алгоритм создания репликации: Делаем резервную копию с помощью pg_basebackup Разворачиваем полученную резервную копию
- 133. Сценарии использования физической репликации Обычная репликация – для создания резервного сервера Каскадная репликация – к основному
- 134. Логическая репликация PostgreSQL При репликации передаются wal записи, но для работы логической репликации нужно изменить формат
- 135. Сценарии использования логической репликации Собираем данные на центральном кластере. Распространяем данные с центрального кластера. Можно использовать
- 136. Troubleshooting
- 137. Что такое Troubleshooting Устранение неполадок сбоев базы данных и проблем с подключением - Troubleshooting
- 138. Подсказки из журналов приложений Успешно ли сервер приложений обрабатывает подключения? Запросы сервера приложений к базе данных
- 139. Проблемы с сетью К числу вопросов, связанных с сетевым взаимодействием, относятся: Проблемы с политикой VPC и
- 140. VPC При выделении облачных ресурсов, таких как базы данных на облачных платформах, они изолированы в виртуальном
- 141. Средства защиты правил брандмауэра Лучше развертывать приложение и базу данных в одном и том же VPC
- 142. Лимит исчерпанного соединения(timeout limit) Еще одна распространенная проблема с БД на основе подключений, такими как MySQL
- 143. Проблемы с объемом данных По мере роста приложения объем данных для этого приложения, скорее всего, также
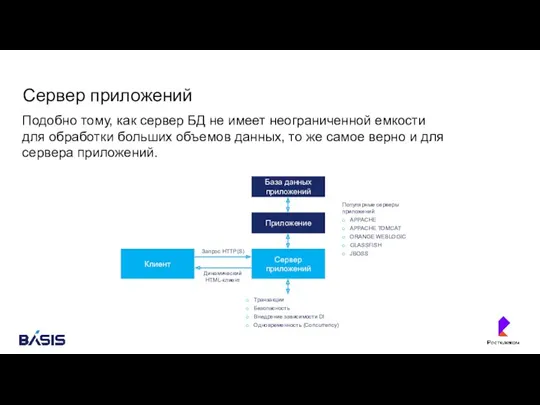
- 144. Сервер приложений Подобно тому, как сервер БД не имеет неограниченной емкости для обработки больших объемов данных,
- 145. Клиент Клиентские приложения могут быть наиболее подвержены узким местам, вызванным большими объемами данных. В отличие от
- 146. Средства защиты от размера данных Исправление снижения производительности и простоев, вызванных проблемами с объемом данных, почти
- 147. Разбиение данных на страницы LIMIT/OFFSET Разбиение на страницы — это шаблон проектирования, который ограничивает общее количество
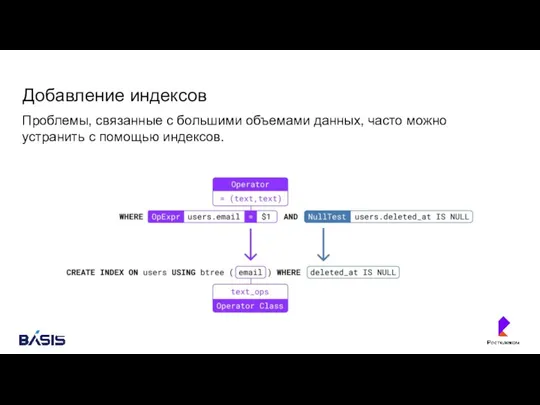
- 148. Добавление индексов Проблемы, связанные с большими объемами данных, часто можно устранить с помощью индексов.
- 149. Взлом изменений кода Предполагаемый сбой базы данных может быть прослежен до недавних критических изменений, внесенных в
- 150. Рекомендуемая литература
- 151. Using Postgres CREATE INDEX: Understanding operator classes, index types & more 10 способов сделать резервную копию
- 153. Скачать презентацию

Администрирование баз данных
Типы и структура СУБД
Запросы, индексы и эксплейны
Администрирование MySQL
Администрирование PostgreSQL
Troubleshooting
Администрирование баз данных
Типы и структура СУБД
Запросы, индексы и эксплейны
Администрирование MySQL
Администрирование PostgreSQL
Troubleshooting

Типы и структура СУБД
Типы и структура СУБД

Типы и структура СУБД
Типы БД, называемых также моделями БД или семействами
Типы и структура СУБД
Типы БД, называемых также моделями БД или семействами
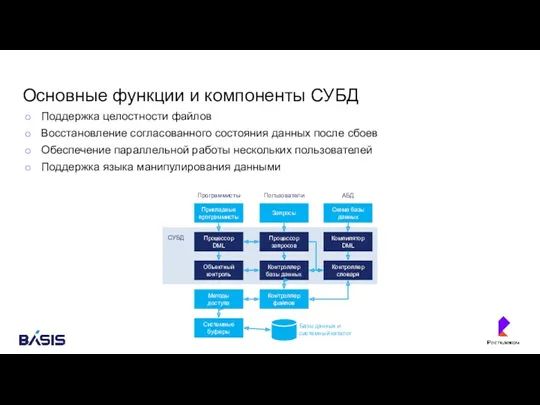
Основные функции и компоненты СУБД
Поддержка целостности файлов
Восстановление согласованного состояния данных после
Основные функции и компоненты СУБД
Поддержка целостности файлов
Восстановление согласованного состояния данных после
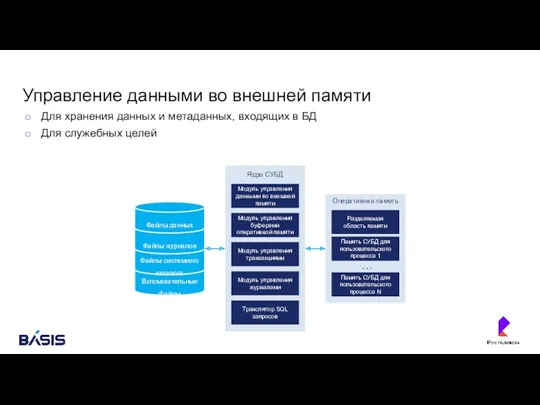
Управление данными во внешней памяти
Для хранения данных и метаданных, входящих в
Управление данными во внешней памяти
Для хранения данных и метаданных, входящих в
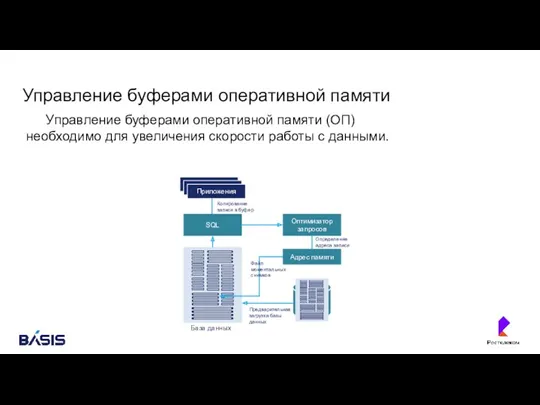
Управление буферами оперативной памяти
Управление буферами оперативной памяти (ОП) необходимо для увеличения
Управление буферами оперативной памяти
Управление буферами оперативной памяти (ОП) необходимо для увеличения
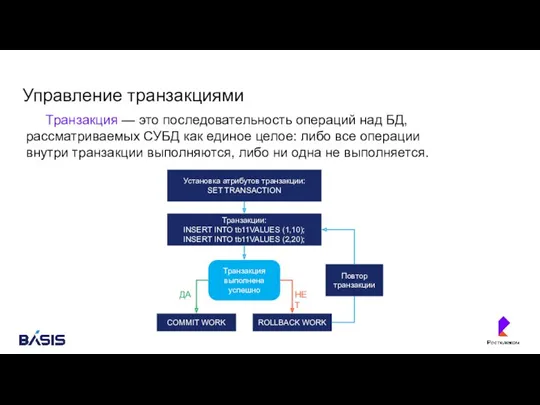
Управление транзакциями
Транзакция — это последовательность операций над БД, рассматриваемых СУБД как
Управление транзакциями
Транзакция — это последовательность операций над БД, рассматриваемых СУБД как
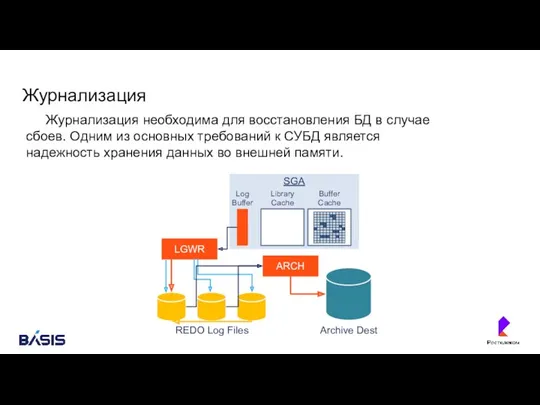
Журнализация
Журнализация необходима для восстановления БД в случае сбоев. Одним из основных
Журнализация
Журнализация необходима для восстановления БД в случае сбоев. Одним из основных
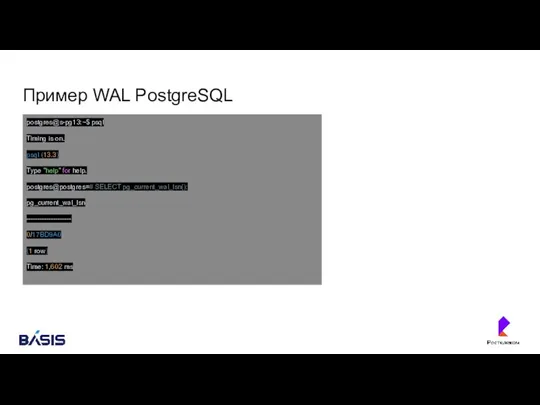
Пример WAL PostgreSQL
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SELECT
Пример WAL PostgreSQL
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SELECT
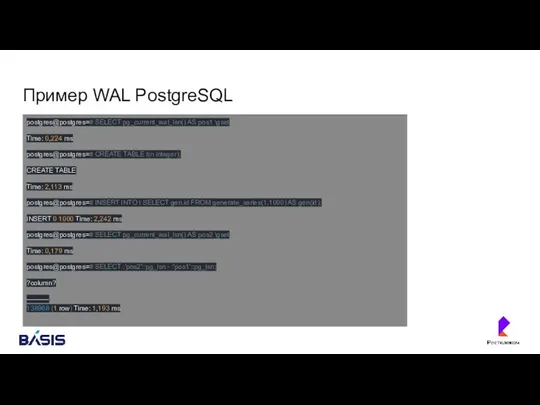
Пример WAL PostgreSQL
postgres@postgres=# SELECT pg_current_wal_lsn() AS pos1 \gset
Time: 0,224 ms
postgres@postgres=# CREATE
Пример WAL PostgreSQL
postgres@postgres=# SELECT pg_current_wal_lsn() AS pos1 \gset
Time: 0,224 ms
postgres@postgres=# CREATE

Пример WAL PostgreSQL
postgres@postgres=# SELECT * FROM pg_ls_waldir();
name | size | modification
--------------------------+----------+------------------------
000000010000000000000001
Пример WAL PostgreSQL
postgres@postgres=# SELECT * FROM pg_ls_waldir();
name | size | modification
--------------------------+----------+------------------------
000000010000000000000001

Пример WAL PostgreSQL
postgres@postgres=# \q
postgres@s-pg13:~$ ps -o pid,command --ppid `head -n 1
Пример WAL PostgreSQL
postgres@postgres=# \q
postgres@s-pg13:~$ ps -o pid,command --ppid `head -n 1

Пример WAL PostgreSQL
postgres@s-pg13:~$ rm /home/postgres/logfile
postgres@s-pg13:~$ pg_ctl -w -l /home/postgres/logfile -D /usr/local/pgsql/data
Пример WAL PostgreSQL
postgres@s-pg13:~$ rm /home/postgres/logfile
postgres@s-pg13:~$ pg_ctl -w -l /home/postgres/logfile -D /usr/local/pgsql/data

Пример WAL PostgreSQL
postgres@s-pg13:~$ rm /home/postgres/logfile
postgres@s-pg13:~$ pg_ctl -w -D /usr/local/pgsql/data stop -m
Пример WAL PostgreSQL
postgres@s-pg13:~$ rm /home/postgres/logfile
postgres@s-pg13:~$ pg_ctl -w -D /usr/local/pgsql/data stop -m
![Пример WAL PostgreSQL postgres@s-pg13:~$ cat /home/postgres/logfile 2022-10-15 15:32:37.988 MSK [29389]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/586090/slide-15.jpg)
Пример WAL PostgreSQL
postgres@s-pg13:~$ cat /home/postgres/logfile
2022-10-15 15:32:37.988 MSK [29389] LOG: starting PostgreSQL
Пример WAL PostgreSQL
postgres@s-pg13:~$ cat /home/postgres/logfile
2022-10-15 15:32:37.988 MSK [29389] LOG: starting PostgreSQL

Типовая организация современной СУБД
Основные функции СУБД
Управление данными во внешней памяти
Управление буферами
Типовая организация современной СУБД
Основные функции СУБД
Управление данными во внешней памяти
Управление буферами
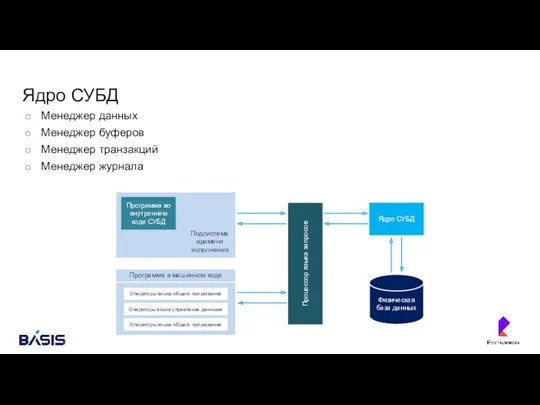
Ядро СУБД
Менеджер данных
Менеджер буферов
Менеджер транзакций
Менеджер журнала
Ядро СУБД
Менеджер данных
Менеджер буферов
Менеджер транзакций
Менеджер журнала

Утилиты БД
загрузка и выгрузка БД
сбор статистики
глобальная проверка целостности БД
Утилиты БД
загрузка и выгрузка БД
сбор статистики
глобальная проверка целостности БД

Классификация СУБД
По модели данных
Загрузка и выгрузка БД
Сетевые
Иерархические
Реляционные (и sql-ориентированные)
Объектно-ориентированные
Xml-ориентированные и другие
Классификация СУБД
По модели данных
Загрузка и выгрузка БД
Сетевые
Иерархические
Реляционные (и sql-ориентированные)
Объектно-ориентированные
Xml-ориентированные и другие
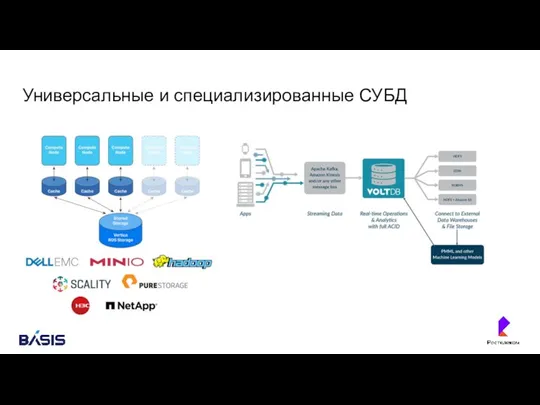
Универсальные и специализированные СУБД
Универсальные и специализированные СУБД
Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные
Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные

Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные
Клиент-серверные
Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные
Клиент-серверные

Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные
Клиент-серверные
Встраиваемые
Файл/клиент-серверные и встраиваемые СУБД
СУБД
Файл-серверные
Клиент-серверные
Встраиваемые

СУБД по месту хранения БД
Внешняя память вообще не используется, а надёжность
СУБД по месту хранения БД
Внешняя память вообще не используется, а надёжность
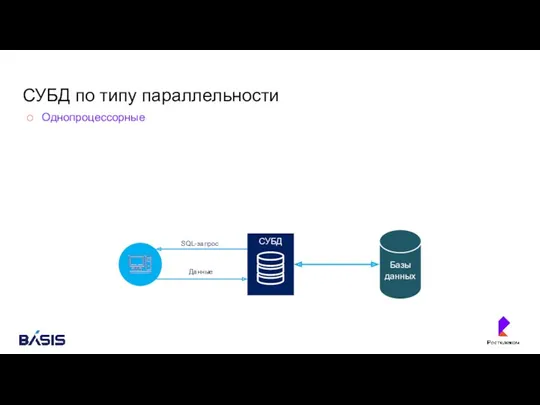
СУБД по типу параллельности
Однопроцессорные
СУБД по типу параллельности
Однопроцессорные
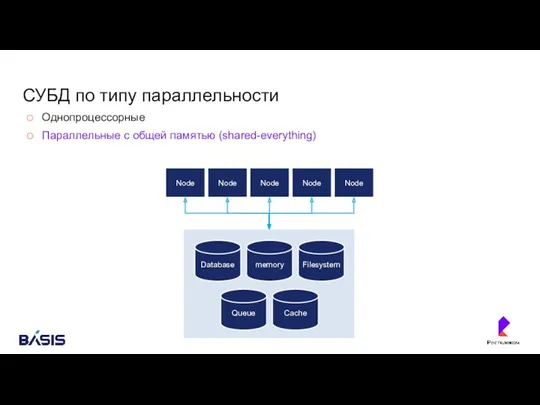
СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
Параллельные с общими дисками
СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
Параллельные с общими дисками

СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
Параллельные с общими дисками
СУБД по типу параллельности
Однопроцессорные
Параллельные с общей памятью (shared-everything)
Параллельные с общими дисками

Запросы, индексы и эксплейны
Запросы, индексы и эксплейны

Что такое индексы?
Индексы (indexes) – это особые таблицы, используемые поисковыми системами
Что такое индексы?
Индексы (indexes) – это особые таблицы, используемые поисковыми системами
Нельзя создать индекс
Столбцов, которые используются для хранения данных объектов, имеющих большие
Нельзя создать индекс
Столбцов, которые используются для хранения данных объектов, имеющих большие
Об индексах и кучах
Как только таблица создана и в ней еще
Об индексах и кучах
Как только таблица создана и в ней еще
Функции индексов
Повышение скорости поиска информации и производительности запросов
Сохранение целостности данных через
Функции индексов
Повышение скорости поиска информации и производительности запросов
Сохранение целостности данных через

Структура индексов
Наборов страниц
Узлов, имеющих древовидную структуру, иерархическую по природе
Структура индексов
Наборов страниц
Узлов, имеющих древовидную структуру, иерархическую по природе

Типы индексов. Кластерный индекс
Задача — сохранение табличных данных в виде, отсортированном
Типы индексов. Кластерный индекс
Задача — сохранение табличных данных в виде, отсортированном

Типы индексов. Некластерный индекс
Индекс содержит
Значения ключей – ключевые столбцы, по которым
Типы индексов. Некластерный индекс
Индекс содержит
Значения ключей – ключевые столбцы, по которым

Специальные типы индексов
Фильтруемый (Filtered)
Специальные типы индексов
Фильтруемый (Filtered)
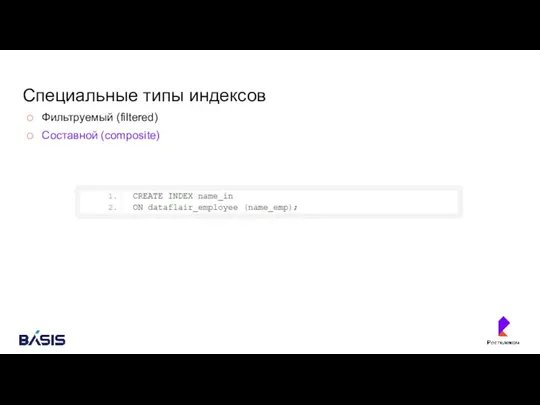
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
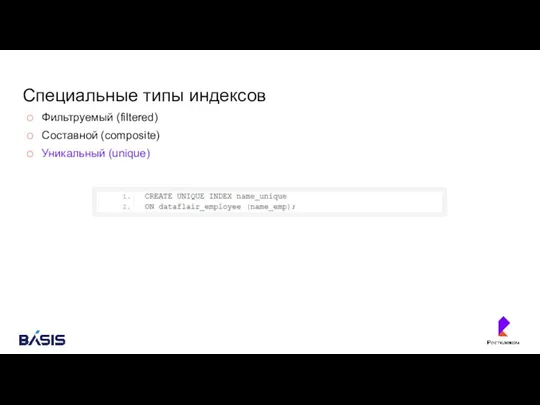
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
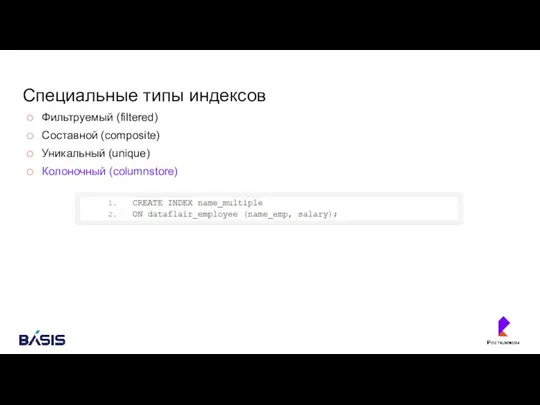
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
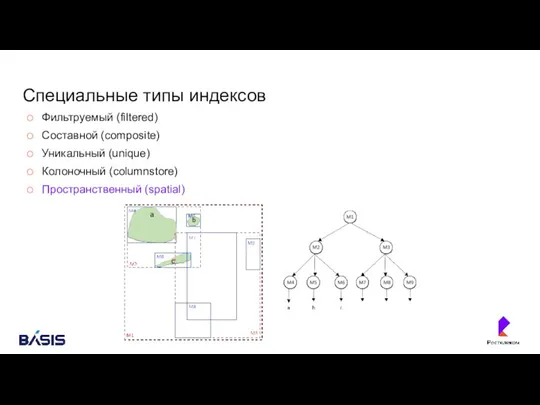
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Покрывающий (covering)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Покрывающий (covering)
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Покрывающий (covering)
Xml-индекс
Специальные типы индексов
Фильтруемый (filtered)
Составной (composite)
Уникальный (unique)
Колоночный (columnstore)
Пространственный (spatial)
Полнотекстовый (full-text)
Покрывающий (covering)
Xml-индекс
Индексы в оптимизированных таблицах
Оптимизированные для памяти (In-Memory OLTP)
Nonclustered indexes
Индексы в оптимизированных таблицах
Оптимизированные для памяти (In-Memory OLTP)
Nonclustered indexes

Performance database
Если предполагается частое обновление данных в таблице, то для нее
Performance database
Если предполагается частое обновление данных в таблице, то для нее

Запросы к БД
Предпочтительнее, чтобы один запрос содержал наибольшее число строк
На столбцах,
Запросы к БД
Предпочтительнее, чтобы один запрос содержал наибольшее число строк
На столбцах,
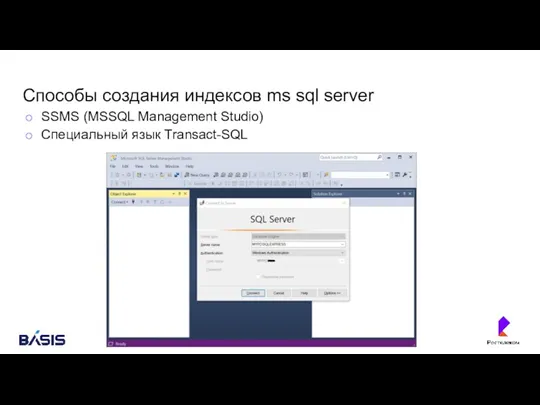
Способы создания индексов ms sql server
SSMS (MSSQL Management Studio)
Специальный язык Transact-SQL
Способы создания индексов ms sql server
SSMS (MSSQL Management Studio)
Специальный язык Transact-SQL

Создать кластерный индекс в Management Studio
Открыть SSMS
Выбрать соответствующую таблицу
Остановившись на
Создать кластерный индекс в Management Studio
Открыть SSMS
Выбрать соответствующую таблицу
Остановившись на
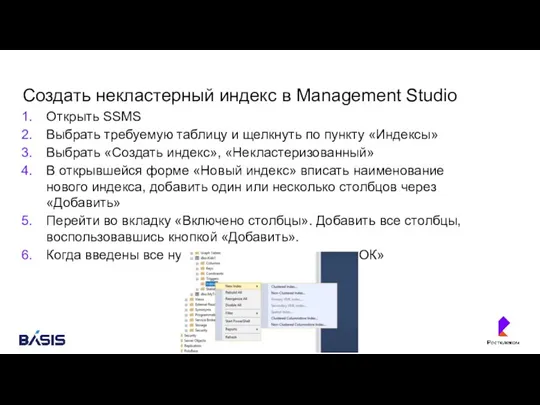
Создать некластерный индекс в Management Studio
Открыть SSMS
Выбрать требуемую таблицу и
Создать некластерный индекс в Management Studio
Открыть SSMS
Выбрать требуемую таблицу и
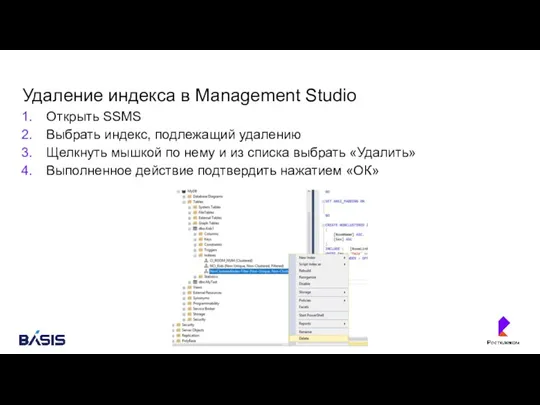
Удаление индекса в Management Studio
Открыть SSMS
Выбрать индекс, подлежащий удалению
Щелкнуть мышкой
Удаление индекса в Management Studio
Открыть SSMS
Выбрать индекс, подлежащий удалению
Щелкнуть мышкой

Оптимизация индексов
Выполнить запрос:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name
Оптимизация индексов
Выполнить запрос:
SELECT OBJECT_NAME(T1.object_id) AS NameTable,
T1.index_id AS IndexId,
T2.name

Реорганизация индексов
Открыть SSMS
На выбранном индексе следует щелкнуть мышкой, из списка
Реорганизация индексов
Открыть SSMS
На выбранном индексе следует щелкнуть мышкой, из списка
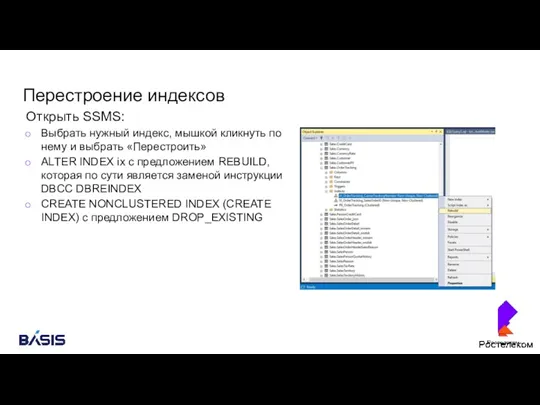
Перестроение индексов
Открыть SSMS:
Выбрать нужный индекс, мышкой кликнуть по нему и
Перестроение индексов
Открыть SSMS:
Выбрать нужный индекс, мышкой кликнуть по нему и

Администрирование MySQL
Администрирование MySQL

База данных MySQL
MySQL является ведущей системой управления базами данных с открытым
База данных MySQL
MySQL является ведущей системой управления базами данных с открытым

Основные понятия и компоненты MySQL
Каталог данных - содержит всю информацию, которая управляется
Основные понятия и компоненты MySQL
Каталог данных - содержит всю информацию, которая управляется

Основные понятия и компоненты MySQL
База данных - каждая БД представляет собой подкаталог
Основные понятия и компоненты MySQL
База данных - каждая БД представляет собой подкаталог
Основные понятия и компоненты MySQL
Файлы состояний MySQL
.pid PID процесса сервера --pid-file
.err журнал ошибок
.log общий
Основные понятия и компоненты MySQL
Файлы состояний MySQL
.pid PID процесса сервера --pid-file
.err журнал ошибок
.log общий

Основные программы и утилиты MySQL
Основные программы и утилиты MySQL

Полезные команды/запросы клиента mysql
Подключение к серверу MySQL с БД осуществляется с
Полезные команды/запросы клиента mysql
Подключение к серверу MySQL с БД осуществляется с

Полезные команды/запросы клиента mysql
Полезные команды/запросы клиента mysql

Полезные команды/запросы клиента mysql
Полезные команды/запросы клиента mysql

Полезные команды/запросы клиента mysql
Чтобы найти все установленные файлы какого-либо пакета, можно
Полезные команды/запросы клиента mysql
Чтобы найти все установленные файлы какого-либо пакета, можно

Полезные команды/запросы клиента mysql
Чтобы найти справку по нужному оператору надо выполнить
Полезные команды/запросы клиента mysql
Чтобы найти справку по нужному оператору надо выполнить
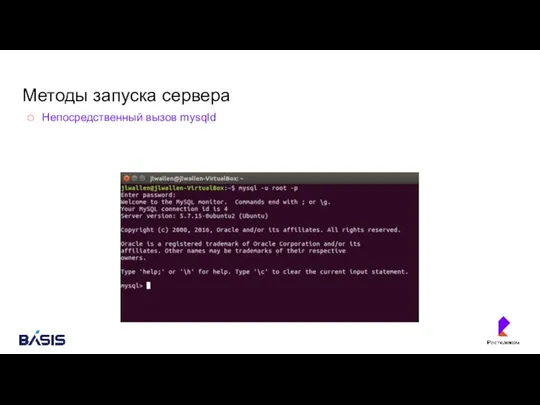
Методы запуска сервера
Непосредственный вызов mysqld
Методы запуска сервера
Непосредственный вызов mysqld
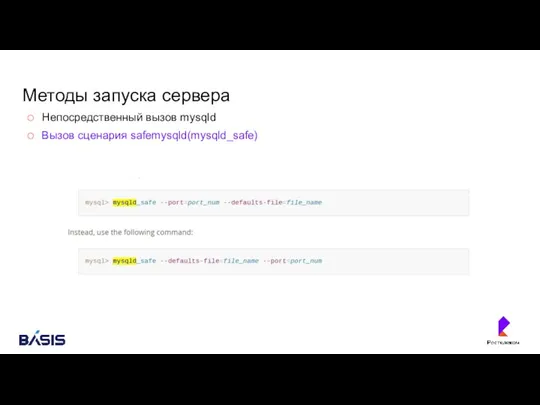
Методы запуска сервера
Непосредственный вызов mysqld
Вызов сценария safemysqld(mysqld_safe)
Методы запуска сервера
Непосредственный вызов mysqld
Вызов сценария safemysqld(mysqld_safe)
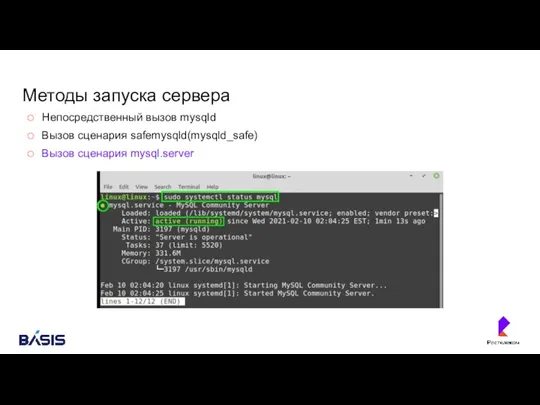
Методы запуска сервера
Непосредственный вызов mysqld
Вызов сценария safemysqld(mysqld_safe)
Вызов сценария mysql.server
Методы запуска сервера
Непосредственный вызов mysqld
Вызов сценария safemysqld(mysqld_safe)
Вызов сценария mysql.server

Определение опций запуска
Во-первых, можно изменить используемый сценарий запуска (safemysqld или mysql.server ) и задать параметры непосредственно
Определение опций запуска
Во-первых, можно изменить используемый сценарий запуска (safemysqld или mysql.server ) и задать параметры непосредственно

Завершение работы сервера
Для самостоятельного завершения работы сервера применяется команда mysqladmin:
% mysqladmin shutdown
Завершение работы сервера
Для самостоятельного завершения работы сервера применяется команда mysqladmin:
% mysqladmin shutdown
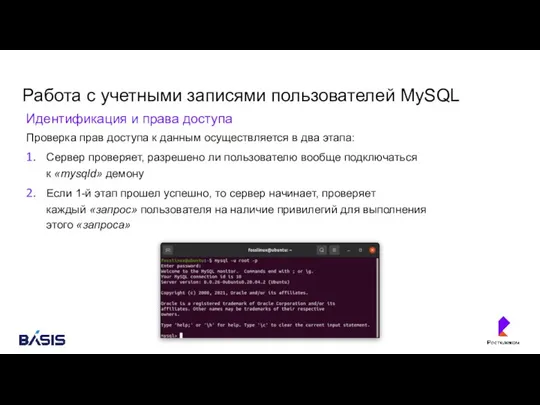
Работа с учетными записями пользователей MySQL
Идентификация и права доступа
Проверка прав доступа
Работа с учетными записями пользователей MySQL
Идентификация и права доступа
Проверка прав доступа

Работа с учетными записями пользователей MySQL
Четыре уровня привилегий
Глобальный уровень:
Глобальные привилегии применяются
Работа с учетными записями пользователей MySQL
Четыре уровня привилегий
Глобальный уровень:
Глобальные привилегии применяются

Работа с учетными записями пользователей MySQL
Два типа полей
Поля контента
Поля привилегий
Поля контекста определяют
Работа с учетными записями пользователей MySQL
Два типа полей
Поля контента
Поля привилегий
Поля контекста определяют

Создание MySQL пользователей и назначение прав
Создавать/удалять пользователей MySQL можно используя, операторы CREATE
Создание MySQL пользователей и назначение прав
Создавать/удалять пользователей MySQL можно используя, операторы CREATE

Создание MySQL пользователей и назначение прав
Назначать привилегии лучше используя, оператор GRANT:
GRANT priv_type
Создание MySQL пользователей и назначение прав
Назначать привилегии лучше используя, оператор GRANT:
GRANT priv_type

Создание MySQL пользователей и назначение прав
Отнимать привилегии лучше используя, оператор REVOKE.
REVOKE priv_type
Создание MySQL пользователей и назначение прав
Отнимать привилегии лучше используя, оператор REVOKE.
REVOKE priv_type

Поиск разрешения прав идет следующим образом:
«use» => «db» & «host» =>
Поиск разрешения прав идет следующим образом:
«use» => «db» & «host» =>

Сменить пароль можно с помощью оператора
SET PASSWORD
SET PASSWORD = PASSWORD('some password')
SET PASSWORD FOR user = PASSWORD('some password')
Первая строчка меняет
Сменить пароль можно с помощью оператора
SET PASSWORD
SET PASSWORD = PASSWORD('some password')
SET PASSWORD FOR user = PASSWORD('some password')
Первая строчка меняет
Создание резервной копии БД
mysqldump
«mysqldump» - консольный клиент для «бэкапа», создания «дампов» БД MySQL. «Дамп» помещается в
Создание резервной копии БД
mysqldump
«mysqldump» - консольный клиент для «бэкапа», создания «дампов» БД MySQL. «Дамп» помещается в

Восстановление БД из «дамп» файлов
Восстанавливать информацию из «дампа»:
shell#> cat /<путь_до_дамп_файла>/<имя_дамп_файла> | mysql
Или когда «дамп» сделан
Восстановление БД из «дамп» файлов
Восстанавливать информацию из «дампа»:
shell#> cat /<путь_до_дамп_файла>/<имя_дамп_файла> | mysql
Или когда «дамп» сделан

Обнаружение ошибок и восстановление БД после сбоя
Процедура обнаружения и исправления ошибок
Обнаружение ошибок и восстановление БД после сбоя
Процедура обнаружения и исправления ошибок

Проверка таблиц на наличие ошибок
Проверять и восстанавливать MyISAM таблицы можно с
Проверка таблиц на наличие ошибок
Проверять и восстанавливать MyISAM таблицы можно с

Проверка таблиц на наличие ошибок
Для определения нескольких таблиц каталога:
shell#> myisamchk список_опций_проверки *.MYI
Где «список_опций_проверки»:
Можно проверить
Проверка таблиц на наличие ошибок
Для определения нескольких таблиц каталога:
shell#> myisamchk список_опций_проверки *.MYI
Где «список_опций_проверки»:
Можно проверить

Исправление таблиц, содержащих ошибки
Для исправления ошибок можно:
восстановление без модификации файла данных
Исправление таблиц, содержащих ошибки
Для исправления ошибок можно: восстановление без модификации файла данных

Восстановление INDEX файла таблицы (*.MYI)
Перейти в каталог БД, содержащий файлы поврежденной
Восстановление INDEX файла таблицы (*.MYI)
Перейти в каталог БД, содержащий файлы поврежденной

Восстановление файла описания таблицы (*.frm)
Чтобы воссоздать файл описаний таблицы, его можно
Восстановление файла описания таблицы (*.frm)
Чтобы воссоздать файл описаний таблицы, его можно

Работа с блокировками таблиц во время ремонта
Сервер MySQL использует два вида
Работа с блокировками таблиц во время ремонта
Сервер MySQL использует два вида

Настройка основных параметров сервера
--skip-name-resolve
Эту опцию полезно использовать, когда в сети существуют
Настройка основных параметров сервера
--skip-name-resolve Эту опцию полезно использовать, когда в сети существуют

Работа нескольких серверов mysql на ВМ
Используется утилита «mysqld_safe» указав ей соответствующий
Работа нескольких серверов mysql на ВМ
Используется утилита «mysqld_safe» указав ей соответствующий

Советы по повышению безопасности mysql
Следить за последними обновлениями (заплатками) MySQL
Ограничить с
Советы по повышению безопасности mysql
Следить за последними обновлениями (заплатками) MySQL
Ограничить с

Советы по повышению безопасности mysql
Привязать доступ пользователей MySQL к БД только
Советы по повышению безопасности mysql
Привязать доступ пользователей MySQL к БД только

Советы по повышению безопасности mysql
Установить для «каталога данных» и «журналов» MySQL разрешения на доступ и
Советы по повышению безопасности mysql
Установить для «каталога данных» и «журналов» MySQL разрешения на доступ и

Администрирование PostgreSQL
Администрирование PostgreSQL

База данных PostgreSQL
PostgreSQL является одной из наиболее популярных систем управления БД.
База данных PostgreSQL
PostgreSQL является одной из наиболее популярных систем управления БД.
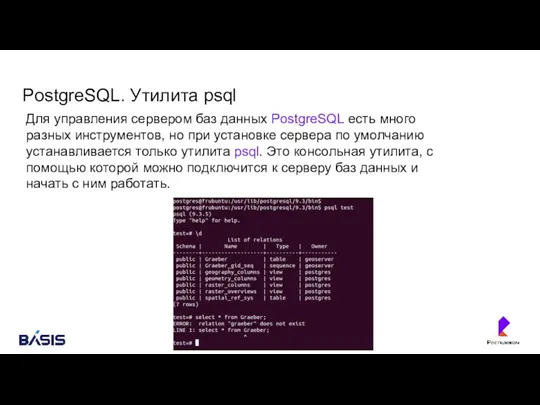
PostgreSQL. Утилита psql
Для управления сервером баз данных PostgreSQL есть много разных инструментов, но
PostgreSQL. Утилита psql
Для управления сервером баз данных PostgreSQL есть много разных инструментов, но

Подключение к серверу баз данных
Подключение выполняется таким способом:
Таким образом если вы
Подключение к серверу баз данных
Подключение выполняется таким способом:
Таким образом если вы

Получение информации об узле \conninfo
Получение информации об узле \conninfo

PostgreSQL. Утилита psql
Все команды psql начинаются с символа обратного слеша “\”.
Можно выполнять запросы SQL,
PostgreSQL. Утилита psql
Все команды psql начинаются с символа обратного слеша “\”.
Можно выполнять запросы SQL,

Файлы, которые использует psql
.psqlrc
Примеры настроек, которые можно ввести в ~/.psqlrc:
\setenv PAGER 'less
Файлы, которые использует psql
.psqlrc
Примеры настроек, которые можно ввести в ~/.psqlrc:
\setenv PAGER 'less
Файлы, которые использует psql
.psql_history
Другой полезный файл это ~/.psql_history. В нем хранится история
Файлы, которые использует psql
.psql_history
Другой полезный файл это ~/.psql_history. В нем хранится история

Формат выводимой информации
Настроить формат выводимой информации:
\a – с выравниванием/без выравнивания
\t – отображение
Формат выводимой информации
Настроить формат выводимой информации:
\a – с выравниванием/без выравнивания
\t – отображение

Конфигурационный файл postgresql.conf
Главный конфиг файл для кластера PostgreSQL – postgresql.conf
По умолчанию
Конфигурационный файл postgresql.conf
Главный конфиг файл для кластера PostgreSQL – postgresql.conf
По умолчанию

Информация о текущих настройках сервера
В PostgreSQL есть 2 представления через которые
Информация о текущих настройках сервера
В PostgreSQL есть 2 представления через которые

Статистика работы PostgreSQL
Статистика PostgreSQL включается в файле postgresql.conf:
track_counts – обращения к
Статистика работы PostgreSQL
Статистика PostgreSQL включается в файле postgresql.conf:
track_counts – обращения к

Статистика работы PostgreSQL
Каждый backend процесс собирает статистику в процессе своей работы
Раз
Статистика работы PostgreSQL
Каждый backend процесс собирает статистику в процессе своей работы
Раз

Статистика работы PostgreSQL
Статистику можно смотреть в следующих представлениях:
Статистика работы PostgreSQL
Статистику можно смотреть в следующих представлениях:

Утилита pgbench
В PostgreSQL есть специальная утилита pgbench. С помощью, которой можно
Утилита pgbench
В PostgreSQL есть специальная утилита pgbench. С помощью, которой можно

Текущие активности в PostgreSQL
Инструменты текущей активности:
Посмотреть на текущие активности сервера PostgreSQL
Текущие активности в PostgreSQL
Инструменты текущей активности:
Посмотреть на текущие активности сервера PostgreSQL
Журнал PostgreSQL. Настройка и анализ
В журнал PostgreSQL записывает некоторые из своих
Журнал PostgreSQL. Настройка и анализ
В журнал PostgreSQL записывает некоторые из своих

Журнал PostgreSQL. Настройка и анализ
Опции настройки журнала:
log_destination = можем указать один,
Журнал PostgreSQL. Настройка и анализ
Опции настройки журнала:
log_destination = можем указать один,

Что можем записывать в журнал?
log_min_messages – минимальный уровень логирования. Допустимые значения:
Что можем записывать в журнал?
log_min_messages – минимальный уровень логирования. Допустимые значения:

Что можем записывать в журнал?
log_(dis)connections – (on или off) записывать подключения
Что можем записывать в журнал?
log_(dis)connections – (on или off) записывать подключения

Ротация журналов
Настроить ротацию, если мы используем log_destination=stderr:
log_filename – может принять не
Ротация журналов
Настроить ротацию, если мы используем log_destination=stderr:
log_filename – может принять не
Анализ журнала
Анализировать журнал можно средствами ОС, например: grep, awk и подобными.
Анализ журнала
Анализировать журнал можно средствами ОС, например: grep, awk и подобными.

Роли и атрибуты в PostgreSQL
В PostgreSQL пользователи и группы – это
Роли и атрибуты в PostgreSQL
В PostgreSQL пользователи и группы – это

Управление ролями в PostgreSQL
Создают роль следующим способом:
Если при создании роли не
Управление ролями в PostgreSQL
Создают роль следующим способом:
Если при создании роли не

Управление ролями в PostgreSQL
Право включать роли в другие роли могут:
Роль может
Управление ролями в PostgreSQL
Право включать роли в другие роли могут:
Роль может
Управление ролями в PostgreSQL
Владелец объекта – это роль, которая этот объект
Управление ролями в PostgreSQL
Владелец объекта – это роль, которая этот объект

Процесс подключения
Идентификация – определение имени роли БД.
Аутентификация – проверка того, что пользователь тот
Процесс подключения
Идентификация – определение имени роли БД.
Аутентификация – проверка того, что пользователь тот

Основные настройки аутентификации
Конфигурационный файл отвечающий за настройки аутентификации – pg_hba.conf находится в
Основные настройки аутентификации
Конфигурационный файл отвечающий за настройки аутентификации – pg_hba.conf находится в

Основные настройки аутентификации
Если тип подключения, имя БД, имя пользователя и адрес сервера совпали, то применяется определённый метод аутентификации
При подключении выполняется
Основные настройки аутентификации
Если тип подключения, имя БД, имя пользователя и адрес сервера совпали, то применяется определённый метод аутентификации
При подключении выполняется

Резервирование PostgreSQL
Существует логическое и физическое резервирование PostgreSQL. Первый тип сохраняет SQL команды, выполнив которые можно
Резервирование PostgreSQL
Существует логическое и физическое резервирование PostgreSQL. Первый тип сохраняет SQL команды, выполнив которые можно

Логическое резервирование PostgreSQL
Есть 3 инструмента для логического копирования:
COPY – команда SQL для
Логическое резервирование PostgreSQL
Есть 3 инструмента для логического копирования:
COPY – команда SQL для

Физическое резервирование PostgreSQL
Физическое резервное копирование разделяется на:
Холодное резервирование (при выключенном сервере) –
Физическое резервирование PostgreSQL
Физическое резервное копирование разделяется на:
Холодное резервирование (при выключенном сервере) –

Протокол репликации
Протокол репликации – специальный протокол, который позволяет:
Получать поток журнальных записей
Выполнять команды
Протокол репликации
Протокол репликации – специальный протокол, который позволяет:
Получать поток журнальных записей
Выполнять команды

Протокол репликации
Слот репликации – механизм для резервирования wal файлов. Подключившись по протоколу
Протокол репликации
Слот репликации – механизм для резервирования wal файлов. Подключившись по протоколу

Архив журналов. Файловый архив.
Сегменты WAL копируются в архив по мере заполнения;
Механизм
Архив журналов. Файловый архив.
Сегменты WAL копируются в архив по мере заполнения;
Механизм

Архив журналов. Потоковый архив.
В архив постоянно записывается поток журнальных записей
Требуются внешние
Архив журналов. Потоковый архив.
В архив постоянно записывается поток журнальных записей
Требуются внешние

Репликация в PostgreSQL
Репликация в PostgreSQL – это процесс синхронизации нескольких копий кластера
Репликация в PostgreSQL
Репликация в PostgreSQL – это процесс синхронизации нескольких копий кластера

Репликация в PostgreSQL
Физическая – основной сервер передает поток wal записей на сервер
Репликация в PostgreSQL
Физическая – основной сервер передает поток wal записей на сервер

Физическая репликация PostgreSQL
Алгоритм создания репликации:
Делаем резервную копию с помощью pg_basebackup
Разворачиваем полученную резервную
Физическая репликация PostgreSQL
Алгоритм создания репликации:
Делаем резервную копию с помощью pg_basebackup
Разворачиваем полученную резервную

Сценарии использования физической репликации
Обычная репликация – для создания резервного сервера
Каскадная репликация – к
Сценарии использования физической репликации
Обычная репликация – для создания резервного сервера
Каскадная репликация – к

Логическая репликация PostgreSQL
При репликации передаются wal записи, но для работы логической
Логическая репликация PostgreSQL
При репликации передаются wal записи, но для работы логической

Сценарии использования логической репликации
Собираем данные на центральном кластере.
Распространяем данные с центрального кластера.
Можно
Сценарии использования логической репликации
Собираем данные на центральном кластере.
Распространяем данные с центрального кластера.
Можно

Troubleshooting
Troubleshooting

Что такое Troubleshooting
Устранение неполадок сбоев базы данных и проблем с
Что такое Troubleshooting
Устранение неполадок сбоев базы данных и проблем с

Подсказки из журналов приложений
Успешно ли сервер приложений обрабатывает подключения?
Запросы сервера приложений
Подсказки из журналов приложений
Успешно ли сервер приложений обрабатывает подключения?
Запросы сервера приложений

Проблемы с сетью
К числу вопросов, связанных с сетевым взаимодействием, относятся:
Проблемы с
Проблемы с сетью
К числу вопросов, связанных с сетевым взаимодействием, относятся:
Проблемы с

VPC
При выделении облачных ресурсов, таких как базы данных на облачных платформах,
VPC
При выделении облачных ресурсов, таких как базы данных на облачных платформах,

Средства защиты правил брандмауэра
Лучше развертывать приложение и базу данных в одном
Средства защиты правил брандмауэра
Лучше развертывать приложение и базу данных в одном
Лимит исчерпанного соединения(timeout limit)
Еще одна распространенная проблема с БД на основе
Лимит исчерпанного соединения(timeout limit)
Еще одна распространенная проблема с БД на основе

Проблемы с объемом данных
По мере роста приложения объем данных для этого
Проблемы с объемом данных
По мере роста приложения объем данных для этого
Сервер приложений
Подобно тому, как сервер БД не имеет неограниченной емкости для
Сервер приложений
Подобно тому, как сервер БД не имеет неограниченной емкости для

Клиент
Клиентские приложения могут быть наиболее подвержены узким местам, вызванным большими объемами
Клиент
Клиентские приложения могут быть наиболее подвержены узким местам, вызванным большими объемами

Средства защиты от размера данных
Исправление снижения производительности и простоев, вызванных проблемами
Средства защиты от размера данных
Исправление снижения производительности и простоев, вызванных проблемами

Разбиение данных на страницы LIMIT/OFFSET
Разбиение на страницы — это шаблон проектирования,
Разбиение данных на страницы LIMIT/OFFSET
Разбиение на страницы — это шаблон проектирования,
Добавление индексов
Проблемы, связанные с большими объемами данных, часто можно устранить с
Добавление индексов
Проблемы, связанные с большими объемами данных, часто можно устранить с

Взлом изменений кода
Предполагаемый сбой базы данных может быть прослежен до недавних
Взлом изменений кода
Предполагаемый сбой базы данных может быть прослежен до недавних

Рекомендуемая литература
Рекомендуемая литература

Using Postgres CREATE INDEX: Understanding operator classes, index types & more
10
Using Postgres CREATE INDEX: Understanding operator classes, index types & more
10
 Онлайн-сервисы и пространство в сети Интернет
Онлайн-сервисы и пространство в сети Интернет Создание Web-сайта. Структура Web-сайта
Создание Web-сайта. Структура Web-сайта Резиденция Деда Мороза в Великом Устюге
Резиденция Деда Мороза в Великом Устюге Работа с чёрным ящиком
Работа с чёрным ящиком Принципы организации вычислительных сетей
Принципы организации вычислительных сетей БИТ.CRM 3. Удобный инструмент для контроля и анализа взаимодействий с клиентом
БИТ.CRM 3. Удобный инструмент для контроля и анализа взаимодействий с клиентом Мультисервисные сети
Мультисервисные сети Создание видеороликов. Мастер-класс
Создание видеороликов. Мастер-класс ЛГОК. Выбор профессии
ЛГОК. Выбор профессии Правовая защита коммерческой тайны. Правовое регулирование отношений по защите КТ на предприятии (ОПОИБ, лекция 4.2)
Правовая защита коммерческой тайны. Правовое регулирование отношений по защите КТ на предприятии (ОПОИБ, лекция 4.2) Классификация СУБД. Лекция 3
Классификация СУБД. Лекция 3 Операційні системи
Операційні системи Створення програмних обєктів
Створення програмних обєктів Информация, ее измерение и представление в компьютере
Информация, ее измерение и представление в компьютере Оперативная информация
Оперативная информация Программирование на языке Python. Алгоритм и его свойства
Программирование на языке Python. Алгоритм и его свойства Анимация и анимационные средства. 2D и 3D анимация. (Лекция 7)
Анимация и анимационные средства. 2D и 3D анимация. (Лекция 7) Systemy informacyjne w zarządzaniu
Systemy informacyjne w zarządzaniu Управление исполнителем Чертёжник
Управление исполнителем Чертёжник Первое знакомство с языком программирования Ассемблер
Первое знакомство с языком программирования Ассемблер Перевод целых чисел из десятичной системы счисления в любую другую
Перевод целых чисел из десятичной системы счисления в любую другую Специальные информационные технологии в правоохранительной деятельности
Специальные информационные технологии в правоохранительной деятельности Информатика. Теоретическая информатика
Информатика. Теоретическая информатика Работа со временем pulsein(), millis(), micros(), delay(), delaymicroseconds()
Работа со временем pulsein(), millis(), micros(), delay(), delaymicroseconds() С++ тіліндегі функция. Дәріс-6
С++ тіліндегі функция. Дәріс-6 Обзор проблем информационной безопасности Омского региона
Обзор проблем информационной безопасности Омского региона Принципы маршрутизации. Основные функции и свойства маршрутизатора
Принципы маршрутизации. Основные функции и свойства маршрутизатора Создание таблиц баз данных
Создание таблиц баз данных