- Алгоритмизация и программирование. Язык C++. (§ 38 - § 45)

Содержание
- 2. Алгоритмизация и программирование. Язык C++ § 38. Целочисленные алгоритмы
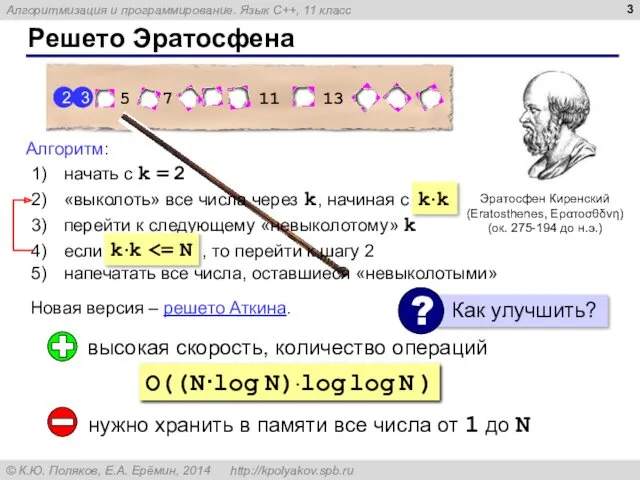
- 3. Решето Эратосфена Эратосфен Киренский (Eratosthenes, Ερατοσθδνη) (ок. 275-194 до н.э.) Новая версия – решето Аткина. 2
- 4. Решето Эратосфена Задача. Вывести все простые числа от 2 до N. Объявление переменных: const int N
- 5. Решето Эратосфена Вычёркивание непростых: k = 2; while ( k*k if ( A[k] ) { i
- 6. Решето Эратосфена Вывод результата: for ( i = 2; i if ( A[i] ) cout
- 7. «Длинные» числа Ключи для шифрования: ≥ 256 битов. Целочисленные типы данных: ≤ 64 битов. Длинное число
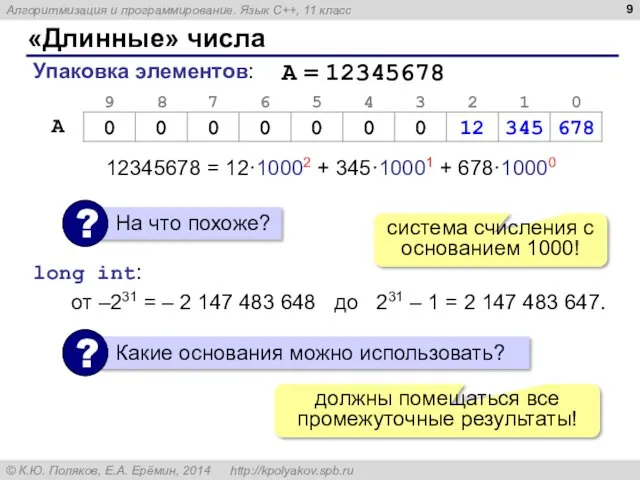
- 8. «Длинные» числа A = 12345678 нужно хранить длину числа неудобно вычислять (с младшего разряда!) неэкономное расходование
- 9. «Длинные» числа Упаковка элементов: 12345678 = 12·10002 + 345·10001 + 678·10000 система счисления с основанием 1000!
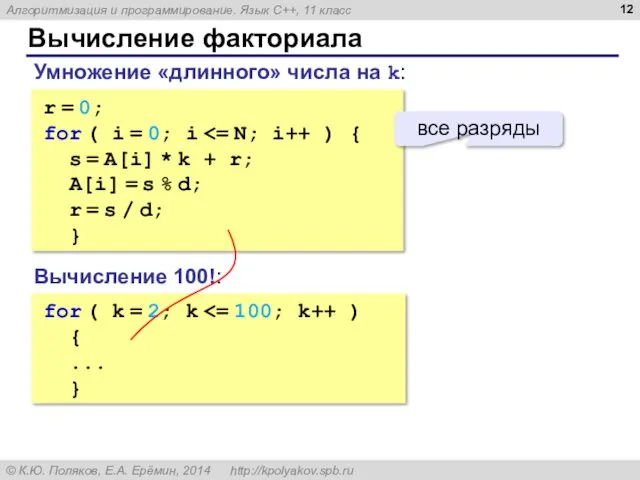
- 10. Вычисление факториала Задача 1. Вычислить точно значение факториала 100! = 1·2·3·…·99·100 1·2·3·…·99·100 201 цифра 6 цифр
- 11. Вычисление факториала основание d = 1 000 000 [A] = 12345678901734567 734 567·3 = 2 203
- 12. Вычисление факториала r = 0; for ( i = 0; i s = A[i] * k
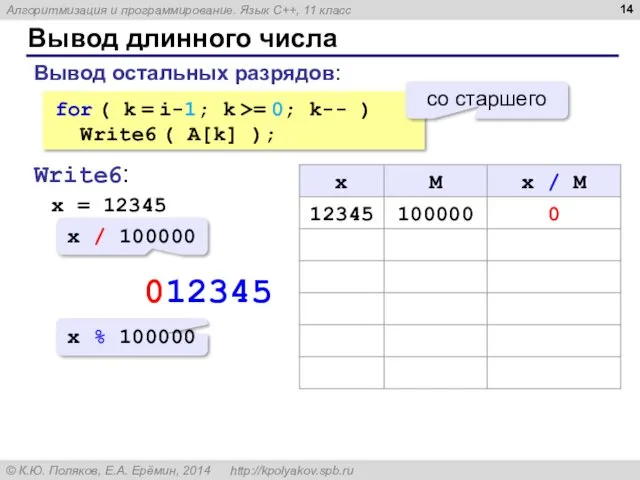
- 13. Вывод длинного числа [A] = 1000002000003 найти старший ненулевой разряд вывести этот разряд вывести все следующие
- 14. Вывод длинного числа for ( k = i-1; k >= 0; k-- ) Write6 ( A[k]
- 15. Вывод длинного числа Вывод числа с лидирующими нулями: void Write6 ( long int x ) {
- 16. Алгоритмизация и программирование. Язык C++ § 39. Структуры
- 17. Зачем нужны структуры? Книги в библиотеках: автор название количество экземпляров … символьные строки целое число Задачa:
- 18. Структуры Структура – это тип данных, который может включать в себя несколько полей – элементов разных
- 19. Объявление структур const int N = 100; TBook B; TBook Books[N]; cout cout cout typedef struct
- 20. Обращение к полям структур B.author // поле author структуры B Точечная нотация: Books[5].count // поле count
- 21. Обращение к полям структур B.author = "Пушкин А.С."; B.title = "Полтава"; B.count = 1; B.count --;
- 22. Запись структур в файлы 'Пушкин А.С.';'Полтава';12 'Лермонтов М.Ю.';'Мцыри';8 Текстовые файлы: символ-разделитель Двоичные файлы: ofstream Fout; Fout.open
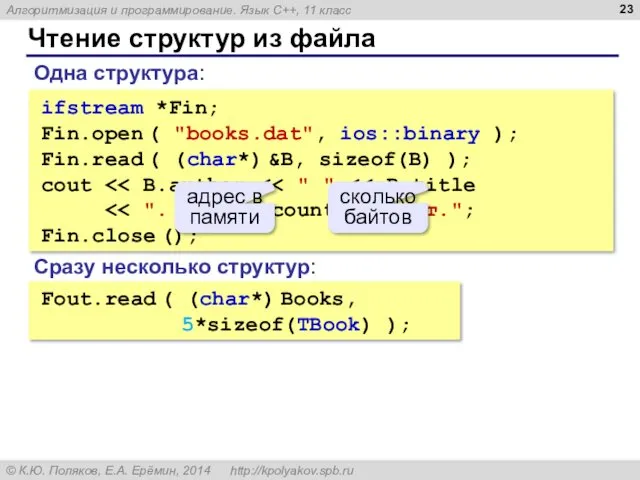
- 23. Чтение структур из файла ifstream *Fin; Fin.open ( "books.dat", ios::binary ); Fin.read ( (char*) &B, sizeof(B)
- 24. Чтение структур из файла const int N = 100; int M; ... Fin.read ( (char*) Books,
- 25. Сортировка структур Ключ – фамилия автора: for ( i = 0; i for ( j =
- 26. Указатели Указатель – это переменная, в которой можно сохранить адрес любой переменной заданного типа. TBook *p;
- 27. Сортировка по указателям TBook *p[N], *p1; for ( i = 0; i p[i] = &Books[i]; Задача
- 28. Сортировка по указателям for ( i = 0; i for ( j = M-2; j >=
- 29. Алгоритмизация и программирование. Язык C++ § 40. Динамические массивы
- 30. Чем плох обычный массив? const int N = 100; int A[N]; статический массив память выделяется при
- 31. Динамические структуры данных создавать новые объекты в памяти изменять их размер удалять из памяти, когда не
- 32. Динамические массивы Объявление: int *A; Выделение памяти: A = new int[N]; количество элементов
- 33. Динамические массивы Использование массива: for ( i = 0; i cin >> A[i]; ... for (
- 34. Тип vector (библиотека STL) Заголовочный файл: #include Объявление: vector A; пустой массив типа int Размер: cout
- 35. Тип vector (библиотека STL) Обработка : for ( i = 0; i cout
- 36. Динамические матрицы Указатель на матрицу: typedef int *pInt; pInt *A; Выделение памяти под массив указателей: A
- 37. Динамические матрицы массив указателей for ( i = 1; i A[i] = A[i-1] + M; Расстановка
- 38. Динамические матрицы массив указателей
- 39. Динамические матрицы for ( i = 0; i A[i] = new int[M]; Выделение памяти: for (
- 40. Динамические матрицы (vector) typedef vector vint; vector A; Объявление: A.resize ( N ); Изменение размера (число
- 41. Расширение массива Задача. С клавиатуры вводятся натуральные числа, ввод заканчивается числом 0. Нужно вывести на экран
- 42. Алгоритмизация и программирование. Язык C++ § 41. Списки
- 43. Зачем нужны списки? Задача. В файле находится список слов, среди которых есть повторяющиеся. Каждое слово записано
- 44. Алгоритм (псевдокод) пока есть слова в файле { прочитать очередное слово если оно есть в списке
- 45. Использование контейнера map (STL) #include ... map L; Объявление: Map («отображение») – это словарь (ассоциативный массив).
- 46. Использование контейнера map (STL) while ( Fin >> s ) { int p; p = L.count
- 47. Вывод результата map ::iterator it; Объявление: it = L.begin(); На первый элемент: Все элементы: for (
- 48. Связные списки (list) узлы могут размещаться в разных местах в памяти только последовательный доступ Рекурсивное определение:
- 49. Связные списки Head Циклический список: Двусвязный список: Head Tail «хвост» обход в двух направлениях сложнее вставка
- 50. Алгоритмизация и программирование. Язык C++ § 42. Стек, дек, очередь
- 51. Что такое стек? Стек (англ. stack – стопка) – это линейный список, в котором элементы добавляются
- 52. Реверс массива Задача. В файле записаны целые числа. Нужно вывести их в другой файл в обратном
- 53. Использование контейнера stack (STL) #include ... stack S; стек целых чисел Основные операции со стеком: push
- 54. Использование контейнера stack (STL) ifstream Fin; ofstream Fout; stack S; int x; Fin.open ( "input.dat" );
- 55. Использование контейнера stack (STL) Fout.open ( "output.dat" ); while ( ! S.empty() ) { Fout S.pop();
- 56. Вычисление арифметических выражений (5+15)/(4+7-1) инфиксная форма (знак операции между данными) первой стоит последняя операция (вычисляем с
- 57. Вычисление арифметических выражений (5+15)/(4+7-1) 1950-е: постфиксная форма (знак операции после данных) не нужны скобки вычисляем с
- 58. Использование стека 5 15 + 4 7 + 1 - / 5 15 + 4 7
- 59. Скобочные выражения Задача. Вводится символьная строка, в которой записано некоторое (арифметическое) выражение, использующее скобки трёх типов:
- 60. Скобочные выражения (стек) когда встретили закрывающую скобку, на вершине стека лежит соответствующая открывающая в конце работы
- 61. Скобочные выражения (стек) const string L = "([{", // открывающие R = ")]}"; // закрывающие string
- 62. Скобочные выражения (стек) for ( i = 0; i p = L.find ( str[i] ); if
- 63. Что такое очередь? Очередь – это линейный список, для которого введены две операции: • добавление элемента
- 64. Заливка области Задача. Рисунок задан в виде матрицы A, в которой элемент A[y][x] определяет цвет пикселя
- 65. Заливка: использование очереди добавить в очередь точку (x0,y0) запомнить цвет начальной точки пока очередь не пуста
- 66. Очередь queue (STL) typedef struct { int x, y; } TPoint; TPoint Point ( int x,
- 67. Очередь queue (STL) Основные операции: push – добавить элемент в конец очереди pop – удалить первый
- 68. Заливка const int XMAX = 5, YMAX = 5, NEW_COLOR = 2; // заполнить матрицу A
- 69. Заливка (основной цикл) while ( ! Q.empty() ) { pt = Q.front(); Q.pop(); if ( A[pt.y][pt.x]
- 70. Очередь: статический массив нужно знать размер не двигаем элементы голова хвост Удаление элемента: Добавление элемента:
- 71. Очередь: статический массив Замыкание в кольцо: Очередь заполнена: Очередь пуста:
- 72. Что такое дек? Дек – это линейный список, в котором можно добавлять и удалять элементы как
- 73. Алгоритмизация и программирование. Язык C++ § 43. Деревья
- 74. Что такое дерево? «Сыновья» А: B, C. «Родитель» B: A. «Потомки» А: B, C, D, E,
- 75. Рекурсивные определения пустая структура – это дерево дерево – это корень и несколько связанных с ним
- 76. Деревья поиска Ключ – это значение, связанное с узлом дерева, по которому выполняется поиск. слева от
- 77. Обход дерева Обойти дерево ⇔ «посетить» все узлы по одному разу. ⇒ список узлов КЛП –
- 78. Обход дерева ЛПК: КЛП: ЛКП: * + 1 4 – 9 5 1 + 4 *
- 79. Обход КЛП – обход «в глубину» записать в стек корень дерева пока стек не пуст {
- 80. Обход КЛП – обход «в глубину» * + 1 4 – 9 5
- 81. Обход «в ширину» записать в очередь корень дерева пока очередь не пуста { выбрать узел V
- 82. Обход «в ширину» (1+4)*(9-5) * + - 1 4 9 5 голова очереди
- 83. Вычисление арифметических выражений 40–2*3–4*5 В корень дерева нужно поместить последнюю из операций с наименьшим приоритетом.
- 84. Вычисление арифметических выражений найти последнюю выполняемую операцию если операций нет то { создать узел-лист выход }
- 85. Вычисление арифметических выражений n1 = значение левого поддерева n2 = значение правого поддерева результат = операция(n1,
- 86. Использование связанных структур Дерево – нелинейная структура ⇒ динамический массив неудобен! typedef struct TNode *PNode; typedef
- 87. Работа с памятью Выделить память для узла: PNode p; // указатель на узел p = new
- 88. Основная программа main() { PNode T; string s; // ввести строку s T = MakeTree (
- 89. Построение дерева PNode MakeTree ( string s ) { int k; PNode Tree; Tree = new
- 90. Построение дерева Tree->data = s.substr(k,1); Tree->left = MakeTree ( s.substr(0,k) ); Tree->right = MakeTree ( s.substr(k+1)
- 91. Вычисление по дереву int Calc ( PNode Tree ) { int n1, n2, res; if (
- 92. Приоритет операции int Priority ( char op ) { switch ( op ) { case '+':
- 93. Последняя выполняемая операция int LastOp ( string s ) { int i, minPrt, res; minPrt =
- 94. Двоичное дерево в массиве ? ?
- 95. Алгоритмизация и программирование. Язык C++ § 44. Графы
- 96. Что такое граф? Граф – это набор вершин и связей между ними (рёбер). петля Матрица смежности:
- 97. Связность графа Связный граф – это граф, между любыми вершинами которого существует путь.
- 98. Дерево – это граф? дерево ABC ABDC BCD CCC… Дерево – это связный граф без циклов
- 99. Взвешенные графы Весовая матрица: вес ребра
- 100. Ориентированные графы (орграфы) Рёбра имеют направление (начало и конец), рёбра называю дугами.
- 101. Жадные алгоритмы Жадный алгоритм – это многошаговый алгоритм, в котором на каждом шаге принимается решение, лучшее
- 102. Жадные алгоритмы Задача. Найти кратчайший маршрут из А в F.
- 103. Задача Прима-Крускала Задача. Между какими городами нужно проложить линии связи, чтобы все города были связаны в
- 104. Раскраска вершин 4 B 2 1 2 9 7 8 1 3 D E F A
- 105. Раскраска вершин const int N = 6; int W[N][N]; // весовая матрица int col[N]; // цвета
- 106. Раскраска вершин for ( k = 0; k // поиск ребра с минимальным весом minDist =
- 107. Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать ближайшая от A невыбранная вершина
- 108. Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать W[x,z] + W[z,y] может быть так, что
- 109. Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать W[x,z] + W[z,y] может быть так, что
- 110. Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать 7 E 8 E
- 111. Кратчайший маршрут длины кратчайших маршрутов из A в другие вершины A → C → E →
- 112. Алгоритм Дейкстры const int N = 6; int W[N][N]; // весовая матрица bool active[N]; // вершина
- 113. Алгоритм Дейкстры for ( i = 0; i minDist = 99999; for ( j = 0;
- 114. Алгоритм Дейкстры i = N-1; while ( i != -1 ) { cout i = P[i];
- 115. Алгоритм Флойда for ( k = 0; k for ( i = 0; i for (
- 116. Алгоритм Флойда + маршруты for ( i = 0; i for ( j = 0; j
- 117. Задача коммивояжера Коммивояжер (бродячий торговец) должен выйти из города 1 и, посетив по разу в неизвестном
- 118. Некоторые задачи Задача на минимум суммы. Имеется N населенных пунктов, в каждом из которых живет pi
- 119. Алгоритмизация и программирование. Язык C++ § 44. Динамическое программирование
- 120. Что такое динамическое программирование? Числа Фибоначчи: ; . F1 = F2 = 1 Fn = Fn-1
- 121. Динамическое программирование Объявление массива: const int N = 10; int F[N+1]; // чтобы начать с 1
- 122. Динамическое программирование Динамическое программирование – это способ решения сложных задач путем сведения их к более простым
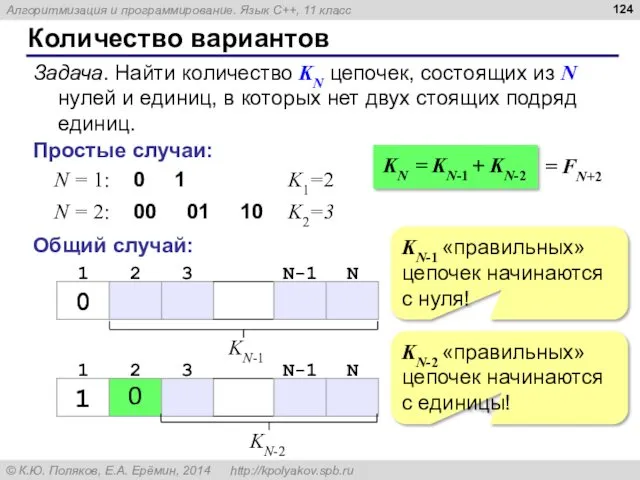
- 123. Количество вариантов Задача. Найти количество KN цепочек, состоящих из N нулей и единиц, в которых нет
- 124. Количество вариантов Задача. Найти количество KN цепочек, состоящих из N нулей и единиц, в которых нет
- 125. Оптимальное решение Задача. В цистерне N литров молока. Есть бидоны объемом 1, 5 и 6 литров.
- 126. Оптимальное решение Сначала выбрали бидон… KN – минимальное число бидонов для N литров KN = 1
- 127. Оптимальное решение (бидоны) 1 1 2 1 3 1 4 1 1 5 1 6 2
- 128. Задача о куче Задача. Из камней весом pi (i=1, …, N) набрать кучу весом ровно W
- 129. Задача о куче Задача. Из камней весом pi (i=1, …, N) набрать кучу весом ровно W
- 130. Задача о куче Добавляем камень с весом 4: для w 0 2 2 для w ≥
- 131. Задача о куче Добавляем камень с весом 5: для w 0 2 2 4 5 6
- 132. Задача о куче Добавляем камень с весом 7: для w 0 2 2 4 5 6
- 133. Задача о куче Добавляем камень с весом pi: для w Рекуррентная формула:
- 134. Задача о куче Оптимальный вес 7 5 + 2
- 135. Задача о куче Заполнение таблицы: W+1 N псевдополиномиальный
- 136. Количество программ Задача. У исполнителя Утроитель есть команды: 1. прибавь 1 2. умножь на 3 Сколько
- 137. Количество программ Как получить число N: N если делится на 3! последняя команда Рекуррентная формула: KN
- 138. Количество программ Заполнение таблицы: Рекуррентная формула: KN = KN-1 если N не делится на 3 KN
- 139. Количество программ Только точки изменения: 12 20 Программа: K[1] = 1; for ( i = 2;
- 140. Размен монет Задача. Сколькими различными способами можно выдать сдачу размером W рублей, если есть монеты достоинством
- 141. Размен монет Пример: W = 10, монеты 1, 2, 5 и 10 w pi базовые случаи
- 142. Размен монет Пример: W = 10, монеты 1, 2, 5 и 10 Рекуррентная формула (добавили монету
- 143. Конец фильма ПОЛЯКОВ Константин Юрьевич д.т.н., учитель информатики ГБОУ СОШ № 163, г. Санкт-Петербург kpolyakov@mail.ru ЕРЕМИН
- 145. Скачать презентацию

Алгоритмизация и программирование. Язык C++
§ 38. Целочисленные алгоритмы
Алгоритмизация и программирование. Язык C++
§ 38. Целочисленные алгоритмы
Решето Эратосфена
Эратосфен Киренский
(Eratosthenes, Ερατοσθδνη)
(ок. 275-194 до н.э.)
Новая версия – решето
Решето Эратосфена
Эратосфен Киренский
(Eratosthenes, Ερατοσθδνη)
(ок. 275-194 до н.э.)
Новая версия – решето

Решето Эратосфена
Задача. Вывести все простые числа от 2 до N.
Объявление переменных:
const
Решето Эратосфена
Задача. Вывести все простые числа от 2 до N.
Объявление переменных:
const

Решето Эратосфена
Вычёркивание непростых:
k = 2;
while ( k*k <= N ) {
Решето Эратосфена
Вычёркивание непростых:
k = 2;
while ( k*k <= N ) {
![Решето Эратосфена Вывод результата: for ( i = 2; i if ( A[i] ) cout](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-5.jpg)
Решето Эратосфена
Вывод результата:
for ( i = 2; i <= N; i++
Решето Эратосфена
Вывод результата:
for ( i = 2; i <= N; i++

«Длинные» числа
Ключи для шифрования: ≥ 256 битов.
Целочисленные типы данных: ≤ 64
«Длинные» числа
Ключи для шифрования: ≥ 256 битов.
Целочисленные типы данных: ≤ 64

«Длинные» числа
A = 12345678
нужно хранить длину числа
неудобно вычислять (с младшего разряда!)
неэкономное
«Длинные» числа
A = 12345678
нужно хранить длину числа
неудобно вычислять (с младшего разряда!)
неэкономное
«Длинные» числа
Упаковка элементов:
12345678 = 12·10002 + 345·10001 + 678·10000
система счисления с
«Длинные» числа
Упаковка элементов:
12345678 = 12·10002 + 345·10001 + 678·10000
система счисления с

Вычисление факториала
Задача 1. Вычислить точно значение факториала
100! = 1·2·3·…·99·100
1·2·3·…·99·100
Вычисление факториала
Задача 1. Вычислить точно значение факториала
100! = 1·2·3·…·99·100
1·2·3·…·99·100
![Вычисление факториала основание d = 1 000 000 [A] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-10.jpg)
Вычисление факториала
основание d = 1 000 000
[A] = 12345678901734567
734 567·3 = 2 203 701
*3
остаётся
Вычисление факториала
основание d = 1 000 000
[A] = 12345678901734567
734 567·3 = 2 203 701
*3
остаётся
Вычисление факториала
r = 0;
for ( i = 0; i <= N;
Вычисление факториала
r = 0;
for ( i = 0; i <= N;
![Вывод длинного числа [A] = 1000002000003 найти старший ненулевой разряд](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-12.jpg)
Вывод длинного числа
[A] = 1000002000003
найти старший ненулевой разряд
вывести этот разряд
вывести все
Вывод длинного числа
[A] = 1000002000003
найти старший ненулевой разряд
вывести этот разряд
вывести все
Вывод длинного числа
for ( k = i-1; k >= 0; k--
Вывод длинного числа
for ( k = i-1; k >= 0; k--
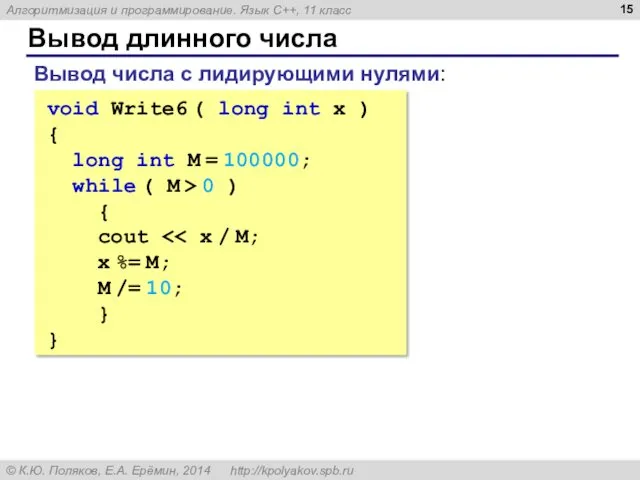
Вывод длинного числа
Вывод числа с лидирующими нулями:
void Write6 ( long int
Вывод длинного числа
Вывод числа с лидирующими нулями:
void Write6 ( long int

Алгоритмизация и программирование. Язык C++
§ 39. Структуры
Алгоритмизация и программирование. Язык C++
§ 39. Структуры

Зачем нужны структуры?
Книги в библиотеках:
автор
название
количество экземпляров
…
символьные строки
целое число
Задачa: объединить разнотипные данные
Зачем нужны структуры?
Книги в библиотеках:
автор
название
количество экземпляров
…
символьные строки
целое число
Задачa: объединить разнотипные данные
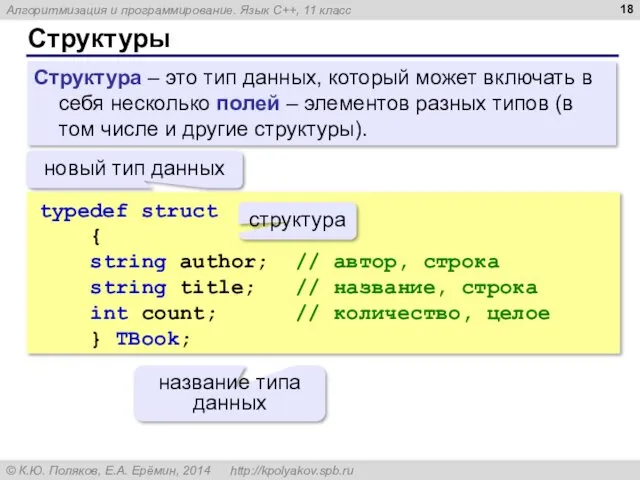
Структуры
Структура – это тип данных, который может включать в себя несколько
Структуры
Структура – это тип данных, который может включать в себя несколько
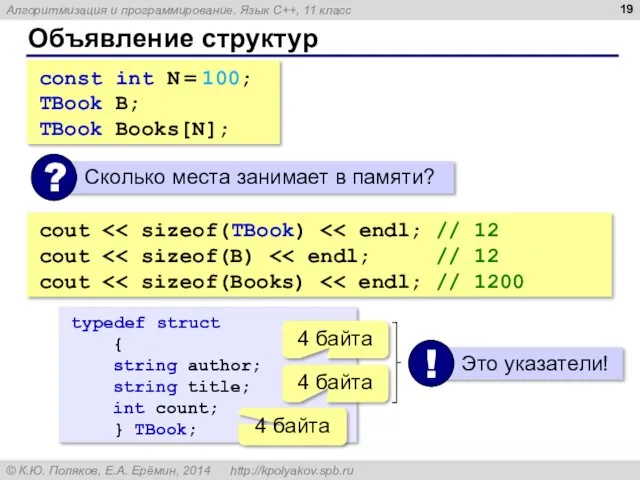
Объявление структур
const int N = 100;
TBook B;
TBook Books[N];
cout << sizeof(TBook) <<
Объявление структур
const int N = 100;
TBook B;
TBook Books[N];
cout << sizeof(TBook) <<
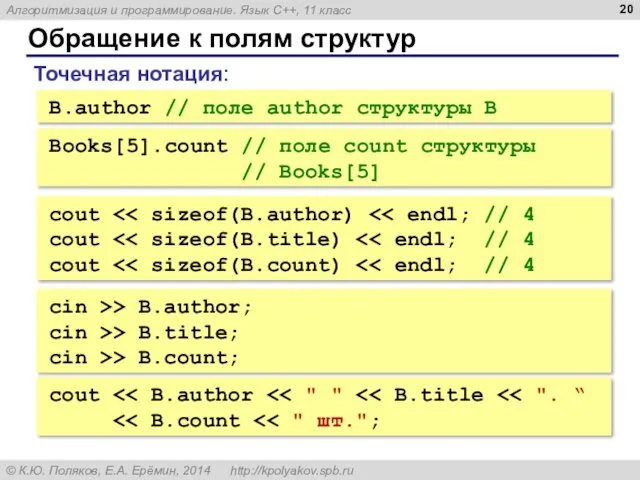
Обращение к полям структур
B.author // поле author структуры B
Точечная нотация:
Books[5].count
Обращение к полям структур
B.author // поле author структуры B
Точечная нотация:
Books[5].count

Обращение к полям структур
B.author = "Пушкин А.С.";
B.title = "Полтава";
B.count = 1;
B.count
Обращение к полям структур
B.author = "Пушкин А.С.";
B.title = "Полтава";
B.count = 1;
B.count

Запись структур в файлы
'Пушкин А.С.';'Полтава';12
'Лермонтов М.Ю.';'Мцыри';8
Текстовые файлы:
символ-разделитель
Двоичные файлы:
ofstream Fout;
Fout.open ( "books.dat",
Запись структур в файлы
'Пушкин А.С.';'Полтава';12
'Лермонтов М.Ю.';'Мцыри';8
Текстовые файлы:
символ-разделитель
Двоичные файлы:
ofstream Fout;
Fout.open ( "books.dat",
Чтение структур из файла
ifstream *Fin;
Fin.open ( "books.dat", ios::binary );
Fin.read ( (char*)
Чтение структур из файла
ifstream *Fin;
Fin.open ( "books.dat", ios::binary );
Fin.read ( (char*)
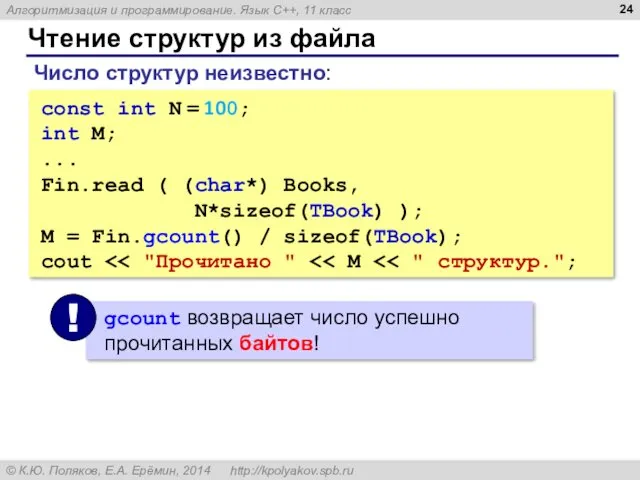
Чтение структур из файла
const int N = 100;
int M;
...
Fin.read ( (char*)
Чтение структур из файла
const int N = 100;
int M;
...
Fin.read ( (char*)

Сортировка структур
Ключ – фамилия автора:
for ( i = 0; i <
Сортировка структур
Ключ – фамилия автора:
for ( i = 0; i <

Указатели
Указатель – это переменная, в которой можно сохранить адрес любой переменной
Указатели
Указатель – это переменная, в которой можно сохранить адрес любой переменной
![Сортировка по указателям TBook *p[N], *p1; for ( i =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-26.jpg)
Сортировка по указателям
TBook *p[N], *p1;
for ( i = 0; i <
Сортировка по указателям
TBook *p[N], *p1;
for ( i = 0; i <

Сортировка по указателям
for ( i = 0; i < M-1; i++
Сортировка по указателям
for ( i = 0; i < M-1; i++

Алгоритмизация и программирование. Язык C++
§ 40. Динамические массивы
Алгоритмизация и программирование. Язык C++
§ 40. Динамические массивы

Чем плох обычный массив?
const int N = 100;
int A[N];
статический массив
память выделяется
Чем плох обычный массив?
const int N = 100;
int A[N];
статический массив
память выделяется

Динамические структуры данных
создавать новые объекты в памяти
изменять их размер
удалять из памяти,
Динамические структуры данных
создавать новые объекты в памяти
изменять их размер
удалять из памяти,
![Динамические массивы Объявление: int *A; Выделение памяти: A = new int[N]; количество элементов](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-31.jpg)
Динамические массивы
Объявление:
int *A;
Выделение памяти:
A = new int[N];
количество элементов
Динамические массивы
Объявление:
int *A;
Выделение памяти:
A = new int[N];
количество элементов

Динамические массивы
Использование массива:
for ( i = 0; i < N; i++
Динамические массивы
Использование массива:
for ( i = 0; i < N; i++

Тип vector (библиотека STL)
Заголовочный файл:
#include
Объявление:
vector A;
пустой массив типа int
Размер:
cout
Тип vector (библиотека STL)
Заголовочный файл:
#include Объявление: vector пустой массив типа int Размер: cout
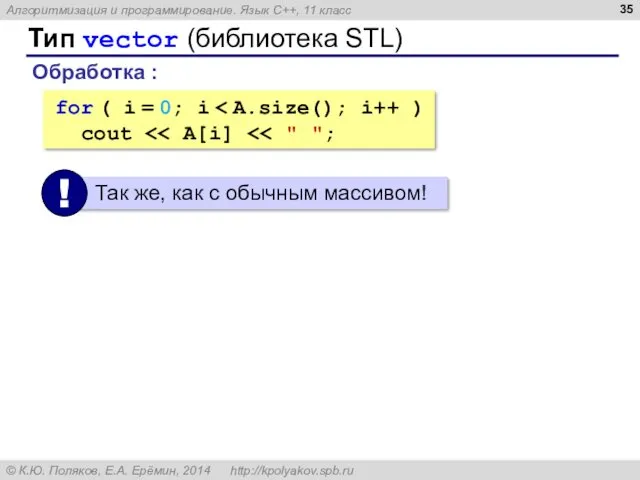
Тип vector (библиотека STL)
Обработка :
for ( i = 0; i <
Тип vector (библиотека STL)
Обработка :
for ( i = 0; i <

Динамические матрицы
Указатель на матрицу:
typedef int *pInt;
pInt *A;
Выделение памяти под массив указателей:
A
Динамические матрицы
Указатель на матрицу:
typedef int *pInt;
pInt *A;
Выделение памяти под массив указателей:
A

Динамические матрицы
массив указателей
for ( i = 1; i < N; i++
Динамические матрицы
массив указателей
for ( i = 1; i < N; i++

Динамические матрицы
массив указателей
Динамические матрицы
массив указателей
![Динамические матрицы for ( i = 0; i A[i] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-38.jpg)
Динамические матрицы
for ( i = 0; i < N; i++ )
Динамические матрицы
for ( i = 0; i < N; i++ )

Динамические матрицы (vector)
typedef vector vint;
vector A;
Объявление:
A.resize ( N );
Изменение размера
Динамические матрицы (vector)
typedef vector Объявление: A.resize ( N ); Изменение размера
vector

Расширение массива
Задача. С клавиатуры вводятся натуральные числа, ввод заканчивается числом 0.
Расширение массива
Задача. С клавиатуры вводятся натуральные числа, ввод заканчивается числом 0.

Алгоритмизация и программирование. Язык C++
§ 41. Списки
Алгоритмизация и программирование. Язык C++
§ 41. Списки

Зачем нужны списки?
Задача. В файле находится список слов, среди которых есть
Зачем нужны списки?
Задача. В файле находится список слов, среди которых есть

Алгоритм (псевдокод)
пока есть слова в файле
{
прочитать очередное слово
Алгоритм (псевдокод)
пока есть слова в файле
{
прочитать очередное слово

Использование контейнера map (STL)
#include
Использование контейнера map (STL)
#include
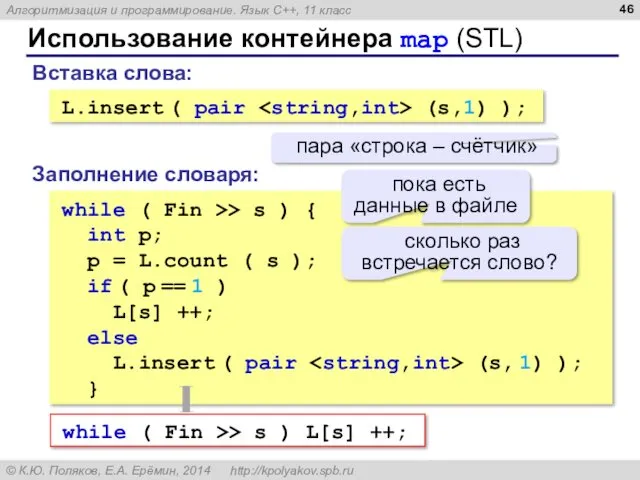
Использование контейнера map (STL)
while ( Fin >> s ) {
int
Использование контейнера map (STL)
while ( Fin >> s ) {
int
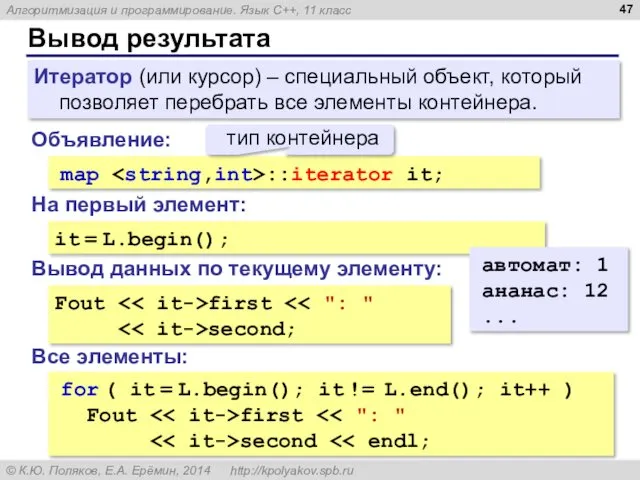
Вывод результата
map ::iterator it;
Объявление:
it = L.begin();
На первый элемент:
Все элементы:
for ( it
Вывод результата
map Объявление: it = L.begin(); На первый элемент: Все элементы: for ( it

Связные списки (list)
узлы могут размещаться в разных местах в памяти
только последовательный
Связные списки (list)
узлы могут размещаться в разных местах в памяти
только последовательный
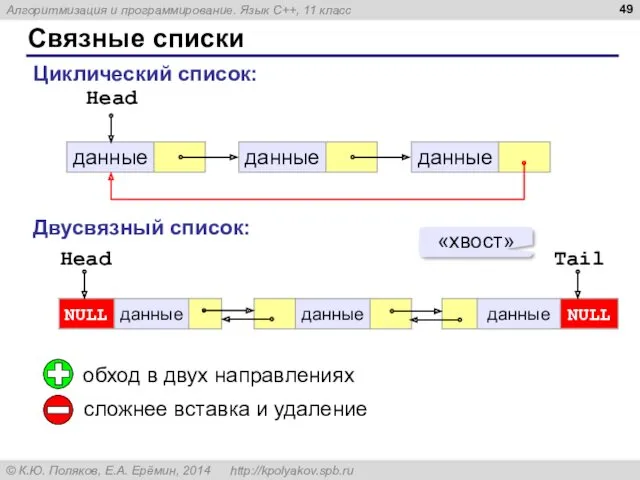
Связные списки
Head
Циклический список:
Двусвязный список:
Head
Tail
«хвост»
обход в двух направлениях
сложнее вставка и удаление
Связные списки
Head
Циклический список:
Двусвязный список:
Head
Tail
«хвост»
обход в двух направлениях
сложнее вставка и удаление

Алгоритмизация и программирование. Язык C++
§ 42. Стек, дек, очередь
Алгоритмизация и программирование. Язык C++
§ 42. Стек, дек, очередь

Что такое стек?
Стек (англ. stack – стопка) – это линейный список,
Что такое стек?
Стек (англ. stack – стопка) – это линейный список,
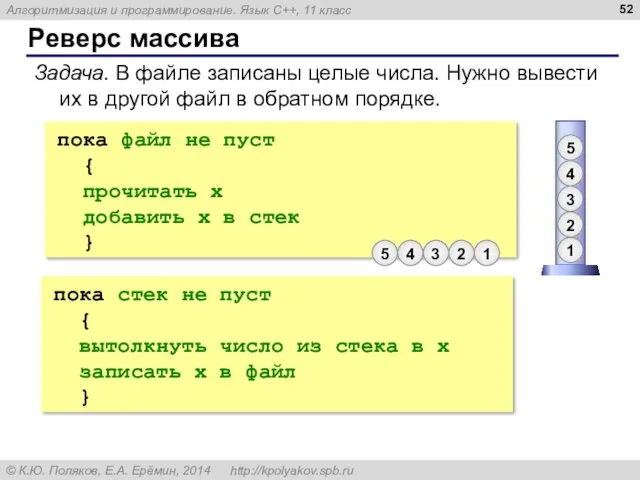
Реверс массива
Задача. В файле записаны целые числа. Нужно вывести их в
Реверс массива
Задача. В файле записаны целые числа. Нужно вывести их в

Использование контейнера stack (STL)
#include
...
stack S;
стек целых чисел
Основные операции со
Использование контейнера stack (STL)
#include стек целых чисел Основные операции со
...
stack

Использование контейнера stack (STL)
ifstream Fin;
ofstream Fout;
stack S;
int x;
Fin.open ( "input.dat"
Использование контейнера stack (STL)
ifstream Fin; Fin.open ( "input.dat"
ofstream Fout;
stack
int x;
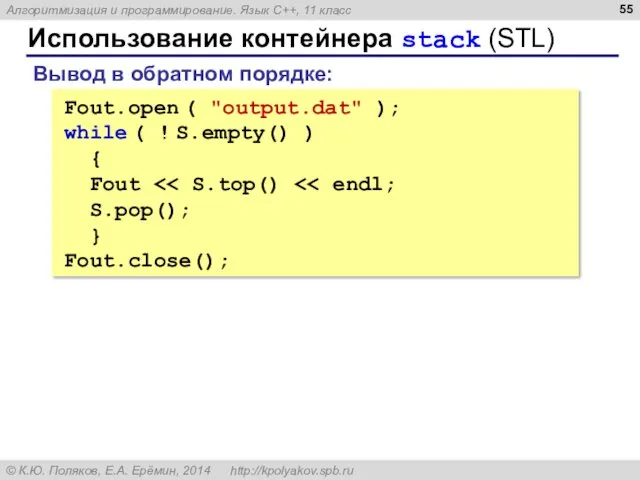
Использование контейнера stack (STL)
Fout.open ( "output.dat" );
while ( ! S.empty() )
Использование контейнера stack (STL)
Fout.open ( "output.dat" );
while ( ! S.empty() )

Вычисление арифметических выражений
(5+15)/(4+7-1)
инфиксная форма (знак операции между данными)
первой стоит последняя
Вычисление арифметических выражений
(5+15)/(4+7-1)
инфиксная форма (знак операции между данными)
первой стоит последняя

Вычисление арифметических выражений
(5+15)/(4+7-1)
1950-е: постфиксная форма
(знак операции после данных)
не нужны
Вычисление арифметических выражений
(5+15)/(4+7-1)
1950-е: постфиксная форма
(знак операции после данных)
не нужны
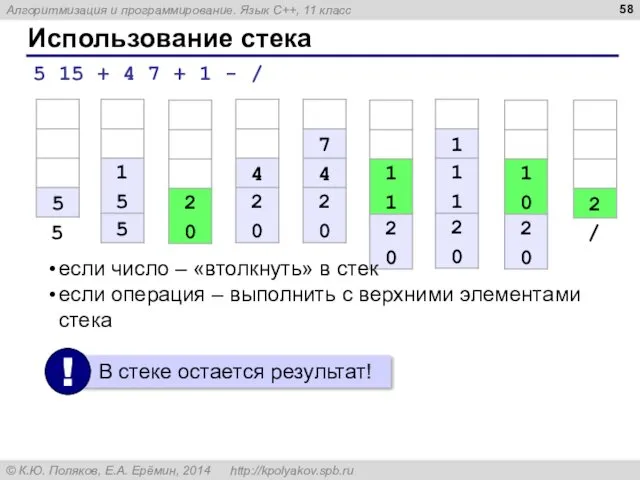
Использование стека
5
15
+
4
7
+
1
-
/
5 15 + 4 7 + 1 - /
если число
Использование стека
5
15
+
4
7
+
1
-
/
5 15 + 4 7 + 1 - /
если число

Скобочные выражения
Задача. Вводится символьная строка, в которой записано некоторое (арифметическое) выражение,
Скобочные выражения
Задача. Вводится символьная строка, в которой записано некоторое (арифметическое) выражение,
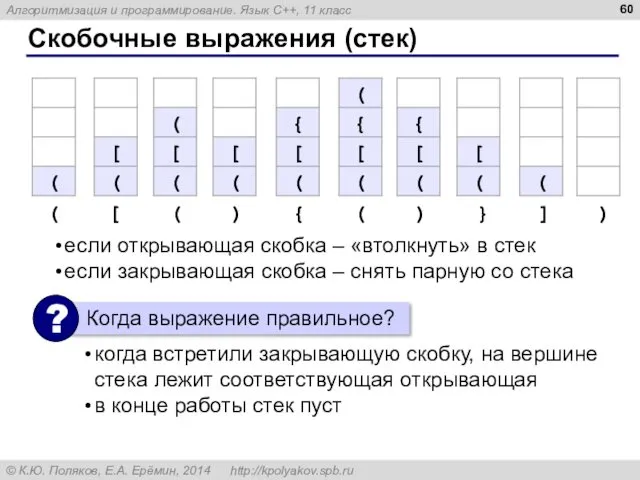
Скобочные выражения (стек)
когда встретили закрывающую скобку, на вершине стека лежит соответствующая
Скобочные выражения (стек)
когда встретили закрывающую скобку, на вершине стека лежит соответствующая

Скобочные выражения (стек)
const string L = "([{", // открывающие
R =
Скобочные выражения (стек)
const string L = "([{", // открывающие
R =

Скобочные выражения (стек)
for ( i = 0; i < str.size(); i++
Скобочные выражения (стек)
for ( i = 0; i < str.size(); i++
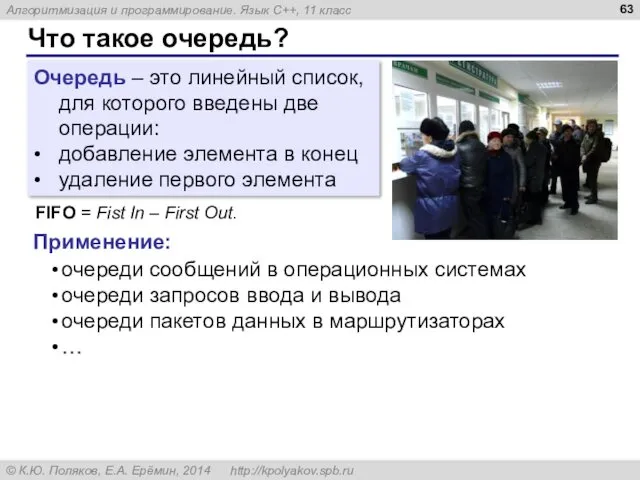
Что такое очередь?
Очередь – это линейный список, для которого введены две
Что такое очередь?
Очередь – это линейный список, для которого введены две

Заливка области
Задача. Рисунок задан в виде матрицы A, в которой элемент
Заливка области
Задача. Рисунок задан в виде матрицы A, в которой элемент

Заливка: использование очереди
добавить в очередь точку (x0,y0)
запомнить цвет начальной точки
пока очередь
Заливка: использование очереди
добавить в очередь точку (x0,y0)
запомнить цвет начальной точки
пока очередь

Очередь queue (STL)
typedef struct {
int x, y;
} TPoint;
TPoint Point
Очередь queue (STL)
typedef struct {
int x, y;
} TPoint;
TPoint Point

Очередь queue (STL)
Основные операции:
push – добавить элемент в конец очереди
pop –
Очередь queue (STL)
Основные операции:
push – добавить элемент в конец очереди
pop –
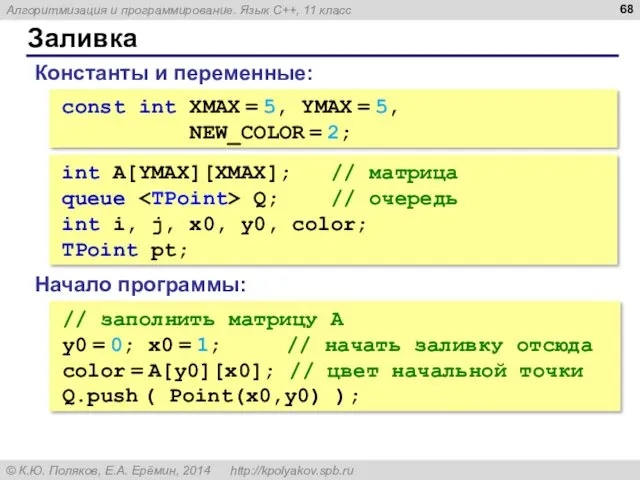
Заливка
const int XMAX = 5, YMAX = 5,
NEW_COLOR =
Заливка
const int XMAX = 5, YMAX = 5,
NEW_COLOR =
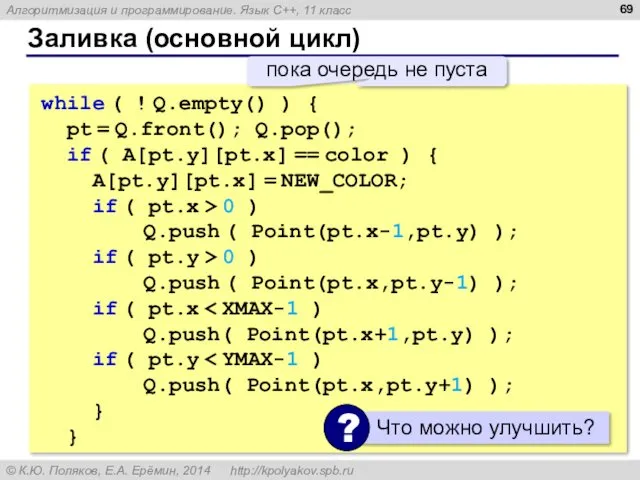
Заливка (основной цикл)
while ( ! Q.empty() ) {
pt = Q.front();
Заливка (основной цикл)
while ( ! Q.empty() ) {
pt = Q.front();
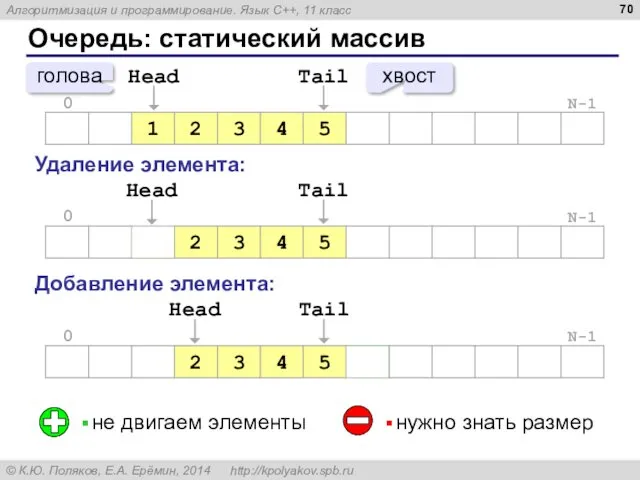
Очередь: статический массив
нужно знать размер
не двигаем элементы
голова
хвост
Удаление элемента:
Добавление элемента:
Очередь: статический массив
нужно знать размер
не двигаем элементы
голова
хвост
Удаление элемента:
Добавление элемента:
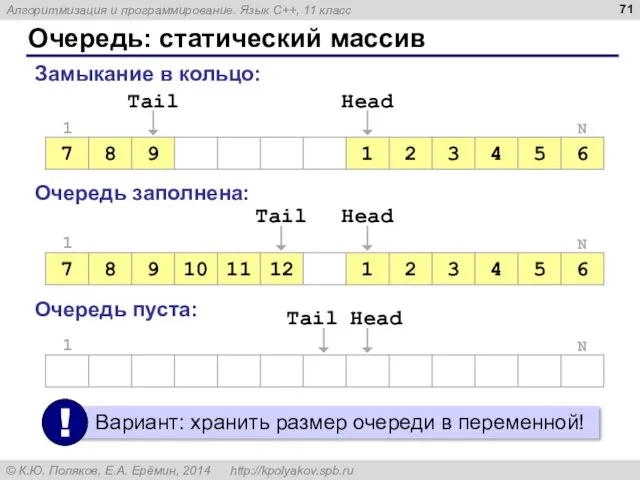
Очередь: статический массив
Замыкание в кольцо:
Очередь заполнена:
Очередь пуста:
Очередь: статический массив
Замыкание в кольцо:
Очередь заполнена:
Очередь пуста:

Что такое дек?
Дек – это линейный список, в котором можно добавлять
Что такое дек?
Дек – это линейный список, в котором можно добавлять

Алгоритмизация и программирование. Язык C++
§ 43. Деревья
Алгоритмизация и программирование. Язык C++
§ 43. Деревья
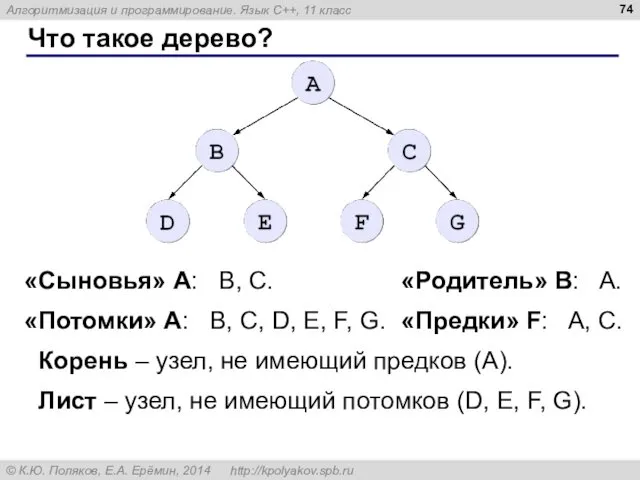
Что такое дерево?
«Сыновья» А: B, C.
«Родитель» B: A.
«Потомки» А: B, C,
Что такое дерево?
«Сыновья» А: B, C.
«Родитель» B: A.
«Потомки» А: B, C,

Рекурсивные определения
пустая структура – это дерево
дерево – это корень и несколько
Рекурсивные определения
пустая структура – это дерево
дерево – это корень и несколько
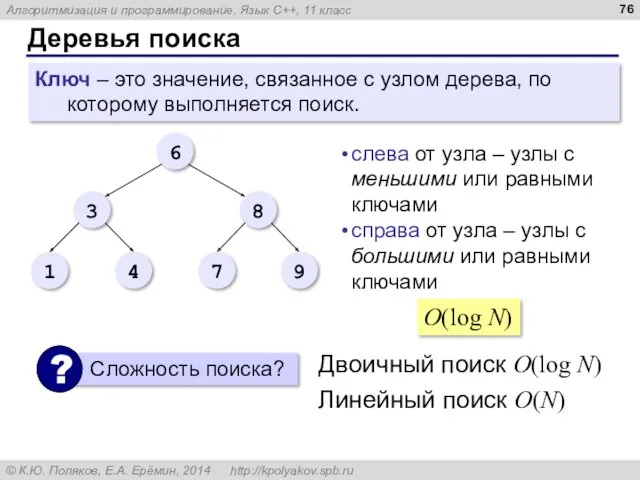
Деревья поиска
Ключ – это значение, связанное с узлом дерева, по которому
Деревья поиска
Ключ – это значение, связанное с узлом дерева, по которому

Обход дерева
Обойти дерево ⇔ «посетить» все узлы по одному разу.
⇒
Обход дерева
Обойти дерево ⇔ «посетить» все узлы по одному разу.
⇒
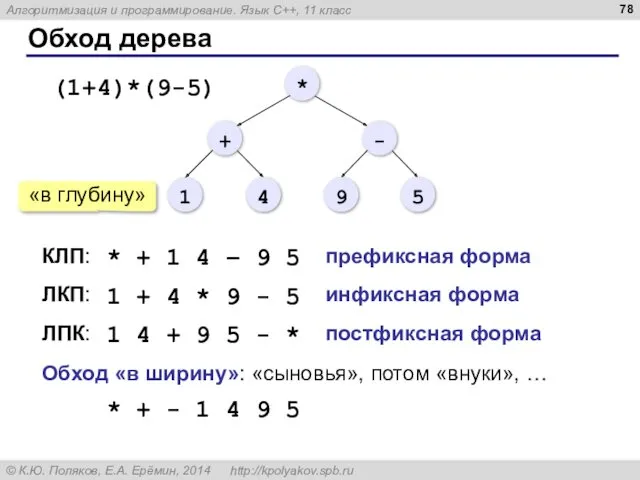
Обход дерева
ЛПК:
КЛП:
ЛКП:
* + 1 4 – 9 5
1 + 4 *
Обход дерева
ЛПК:
КЛП:
ЛКП:
* + 1 4 – 9 5
1 + 4 *

Обход КЛП – обход «в глубину»
записать в стек корень дерева
пока стек
Обход КЛП – обход «в глубину»
записать в стек корень дерева
пока стек
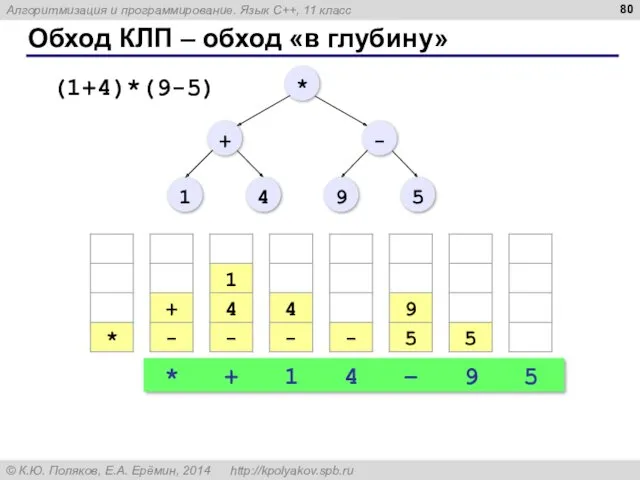
Обход КЛП – обход «в глубину»
*
+
1
4
–
9
5
Обход КЛП – обход «в глубину»
*
+
1
4
–
9
5
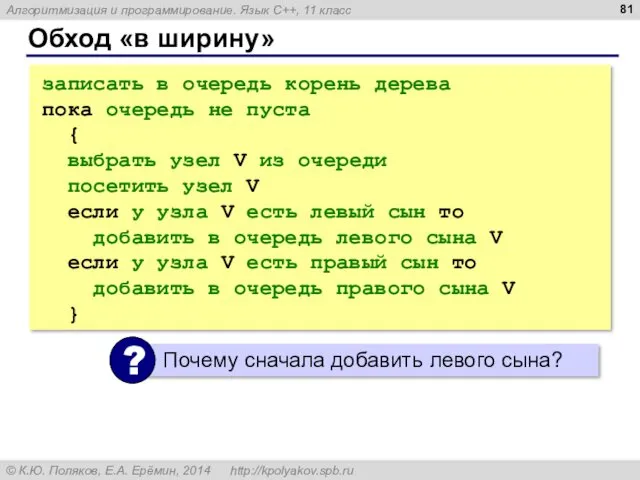
Обход «в ширину»
записать в очередь корень дерева
пока очередь не пуста
{
Обход «в ширину»
записать в очередь корень дерева
пока очередь не пуста
{
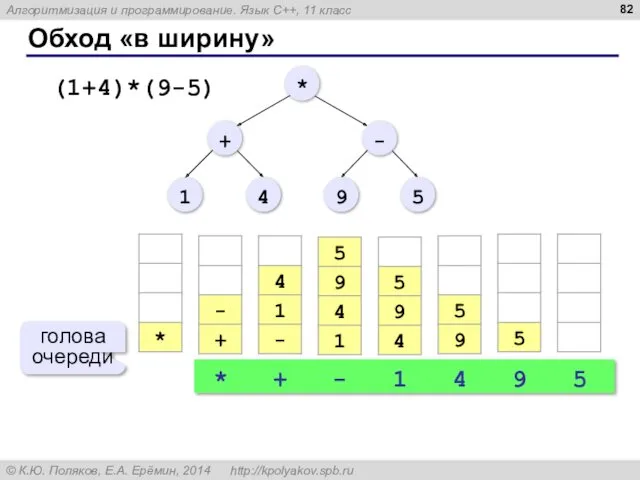
Обход «в ширину»
(1+4)*(9-5)
*
+
-
1
4
9
5
голова очереди
Обход «в ширину»
(1+4)*(9-5)
*
+
-
1
4
9
5
голова очереди
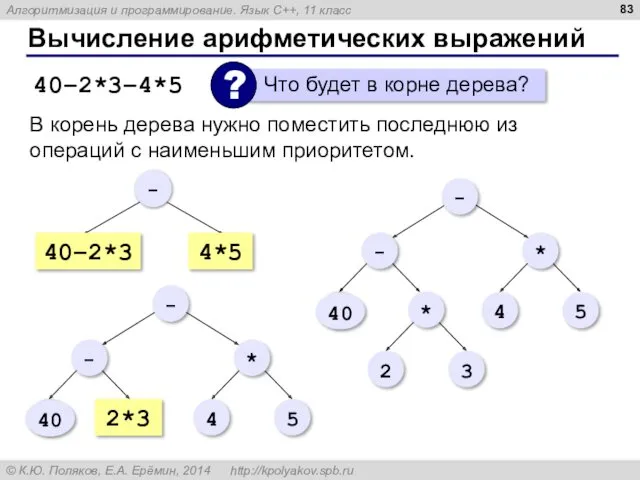
Вычисление арифметических выражений
40–2*3–4*5
В корень дерева нужно поместить последнюю из операций с
Вычисление арифметических выражений
40–2*3–4*5
В корень дерева нужно поместить последнюю из операций с

Вычисление арифметических выражений
найти последнюю выполняемую операцию
если операций нет то
{
создать
Вычисление арифметических выражений
найти последнюю выполняемую операцию
если операций нет то
{
создать
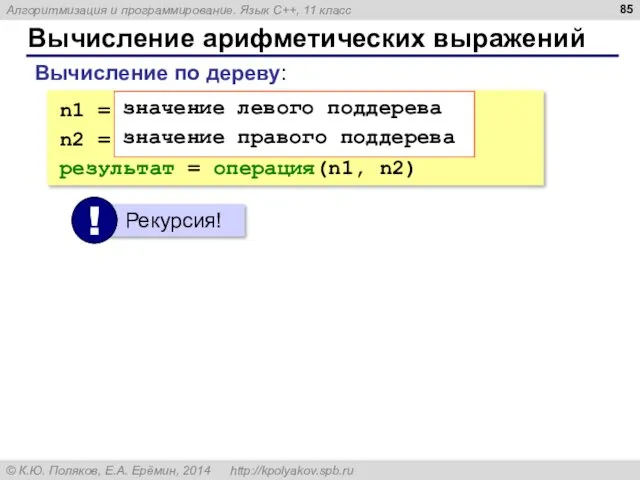
Вычисление арифметических выражений
n1 = значение левого поддерева
n2 = значение правого поддерева
результат
Вычисление арифметических выражений
n1 = значение левого поддерева
n2 = значение правого поддерева
результат

Использование связанных структур
Дерево – нелинейная структура ⇒ динамический массив неудобен!
typedef struct
Использование связанных структур
Дерево – нелинейная структура ⇒ динамический массив неудобен!
typedef struct
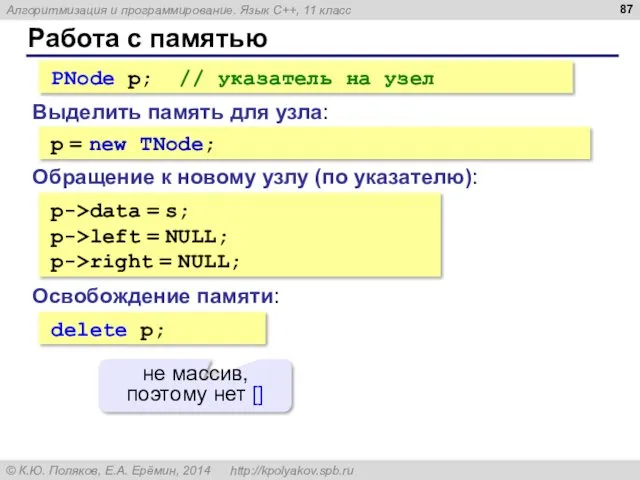
Работа с памятью
Выделить память для узла:
PNode p; // указатель на узел
Работа с памятью
Выделить память для узла:
PNode p; // указатель на узел
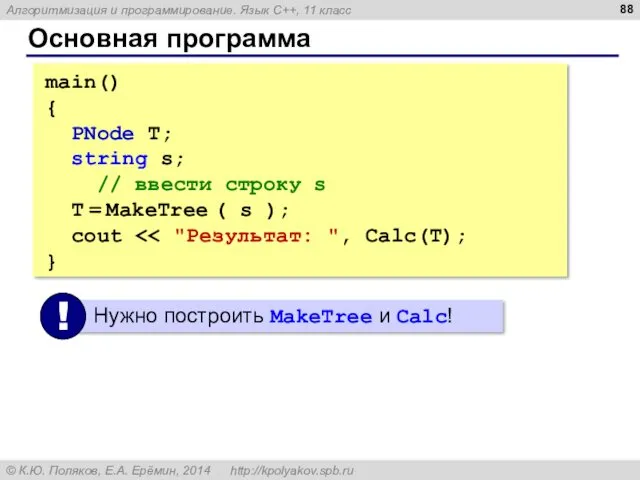
Основная программа
main()
{
PNode T;
string s;
// ввести строку s
T
Основная программа
main()
{
PNode T;
string s;
// ввести строку s
T
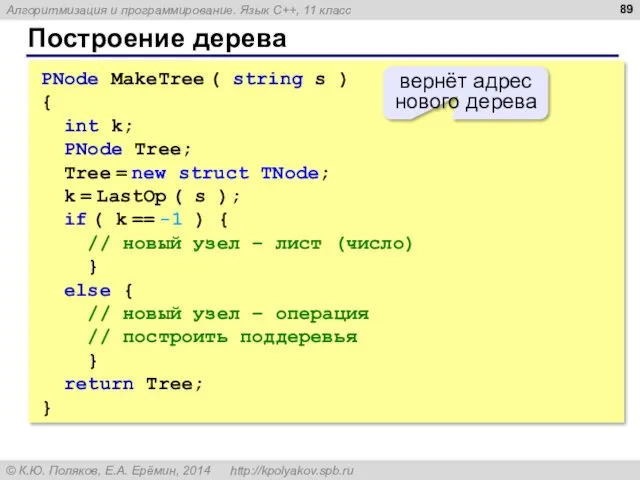
Построение дерева
PNode MakeTree ( string s )
{
int k;
PNode Tree;
Построение дерева
PNode MakeTree ( string s )
{
int k;
PNode Tree;

Построение дерева
Tree->data = s.substr(k,1);
Tree->left = MakeTree ( s.substr(0,k) );
Tree->right = MakeTree
Построение дерева
Tree->data = s.substr(k,1);
Tree->left = MakeTree ( s.substr(0,k) );
Tree->right = MakeTree
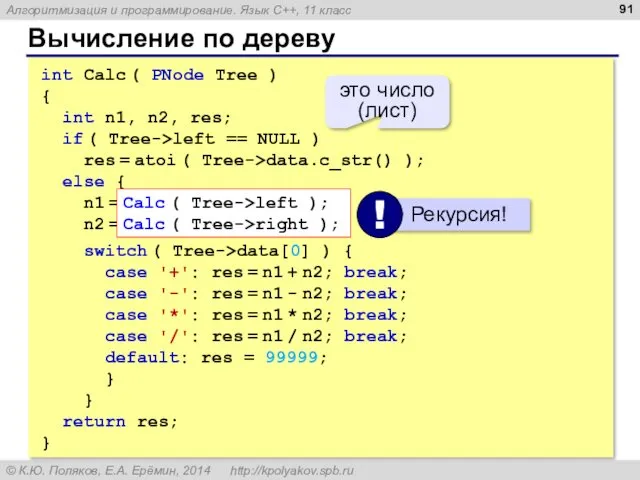
Вычисление по дереву
int Calc ( PNode Tree )
{
int n1, n2,
Вычисление по дереву
int Calc ( PNode Tree )
{
int n1, n2,

Приоритет операции
int Priority ( char op )
{
switch ( op )
Приоритет операции
int Priority ( char op )
{
switch ( op )
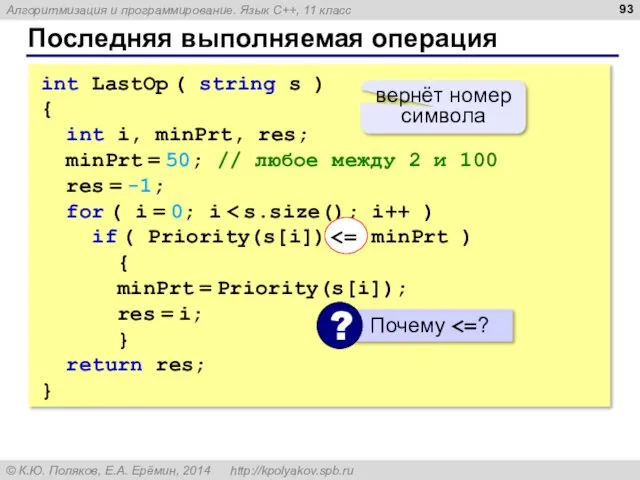
Последняя выполняемая операция
int LastOp ( string s )
{
int i, minPrt,
Последняя выполняемая операция
int LastOp ( string s )
{
int i, minPrt,
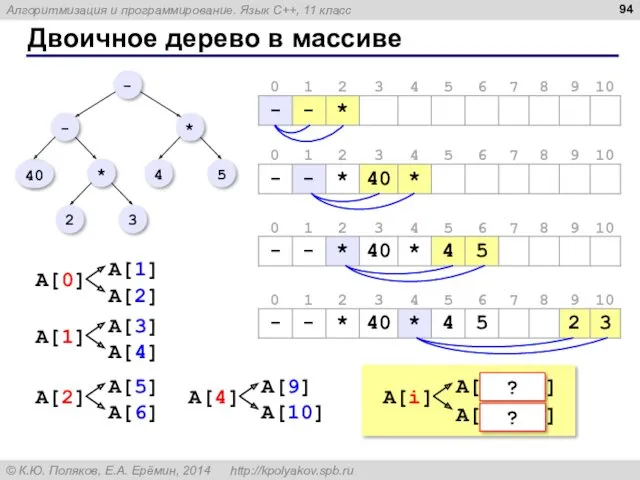
Двоичное дерево в массиве
?
?
Двоичное дерево в массиве
?
?

Алгоритмизация и программирование. Язык C++
§ 44. Графы
Алгоритмизация и программирование. Язык C++
§ 44. Графы
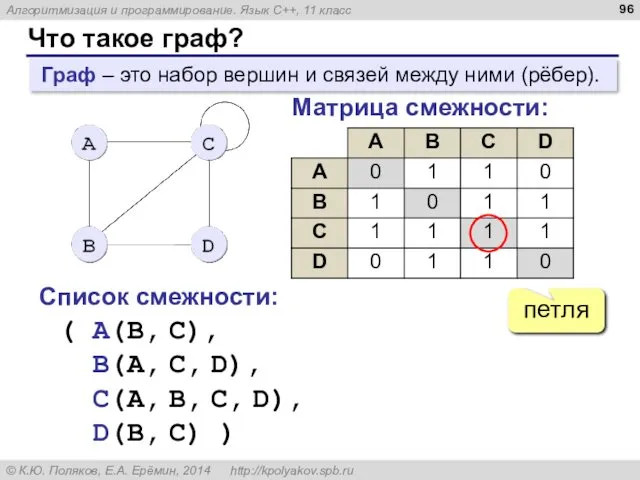
Что такое граф?
Граф – это набор вершин и связей между
Что такое граф?
Граф – это набор вершин и связей между
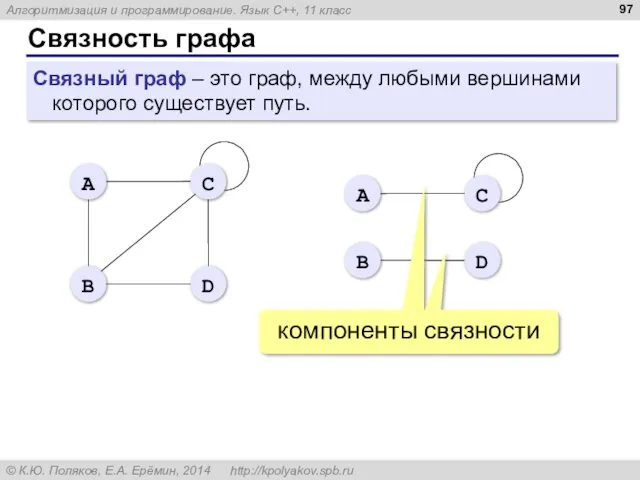
Связность графа
Связный граф – это граф, между любыми вершинами которого
Связность графа
Связный граф – это граф, между любыми вершинами которого
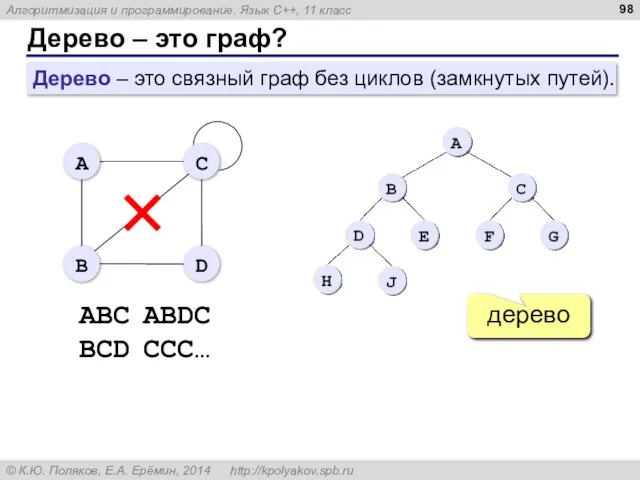
Дерево – это граф?
дерево
ABC ABDC
BCD CCC…
Дерево – это связный граф без циклов
Дерево – это граф?
дерево
ABC ABDC
BCD CCC…
Дерево – это связный граф без циклов
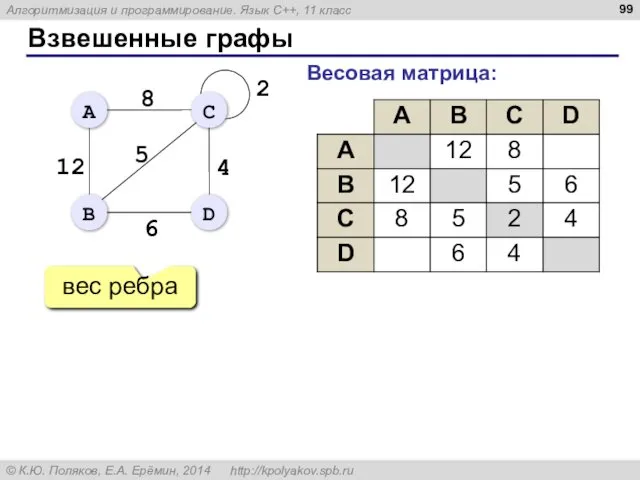
Взвешенные графы
Весовая матрица:
вес ребра
Взвешенные графы
Весовая матрица:
вес ребра
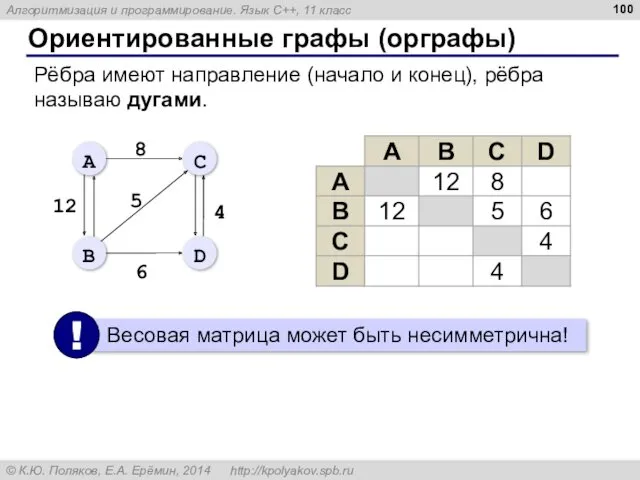
Ориентированные графы (орграфы)
Рёбра имеют направление (начало и конец), рёбра называю дугами.
Ориентированные графы (орграфы)
Рёбра имеют направление (начало и конец), рёбра называю дугами.
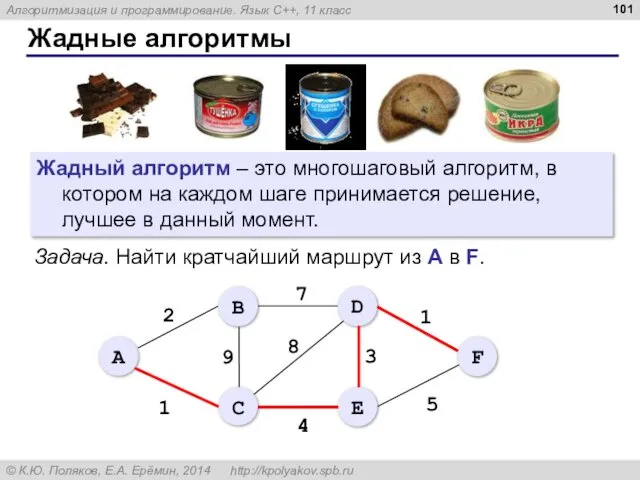
Жадные алгоритмы
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом
Жадные алгоритмы
Жадный алгоритм – это многошаговый алгоритм, в котором на каждом

Жадные алгоритмы
Задача. Найти кратчайший маршрут из А в F.
Жадные алгоритмы
Задача. Найти кратчайший маршрут из А в F.
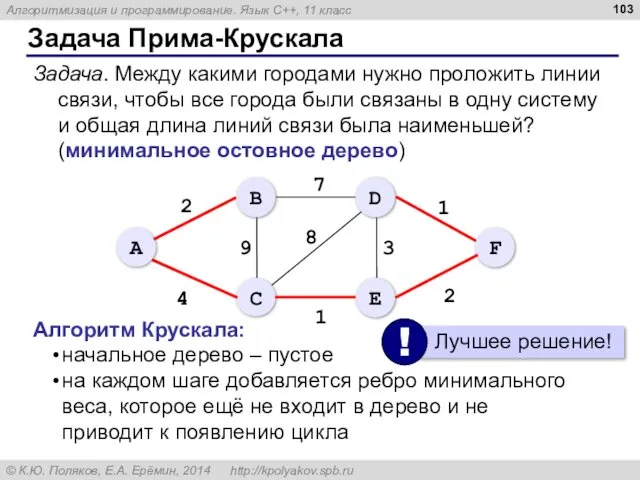
Задача Прима-Крускала
Задача. Между какими городами нужно проложить линии связи, чтобы все
Задача Прима-Крускала
Задача. Между какими городами нужно проложить линии связи, чтобы все
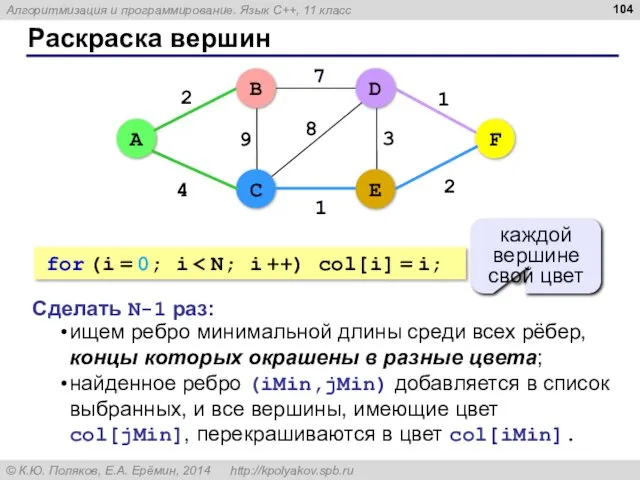
Раскраска вершин
4
B
2
1
2
9
7
8
1
3
D
E
F
A
C
ищем ребро минимальной длины среди всех рёбер, концы которых окрашены
Раскраска вершин
4
B
2
1
2
9
7
8
1
3
D
E
F
A
C
ищем ребро минимальной длины среди всех рёбер, концы которых окрашены
![Раскраска вершин const int N = 6; int W[N][N]; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-104.jpg)
Раскраска вершин
const int N = 6;
int W[N][N]; // весовая матрица
Раскраска вершин
const int N = 6;
int W[N][N]; // весовая матрица
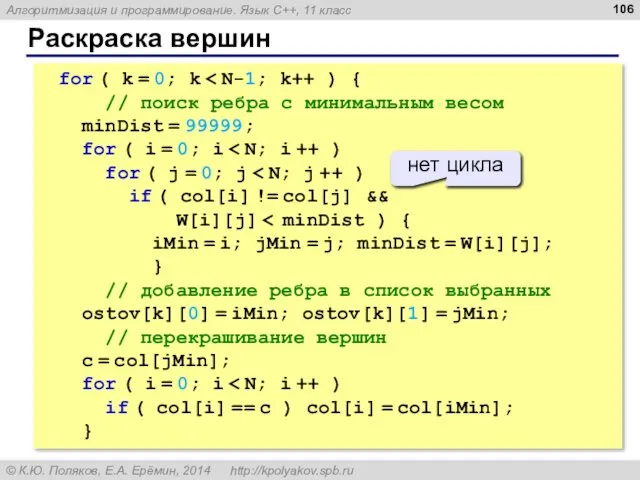
Раскраска вершин
for ( k = 0; k < N-1; k++ )
Раскраска вершин
for ( k = 0; k < N-1; k++ )
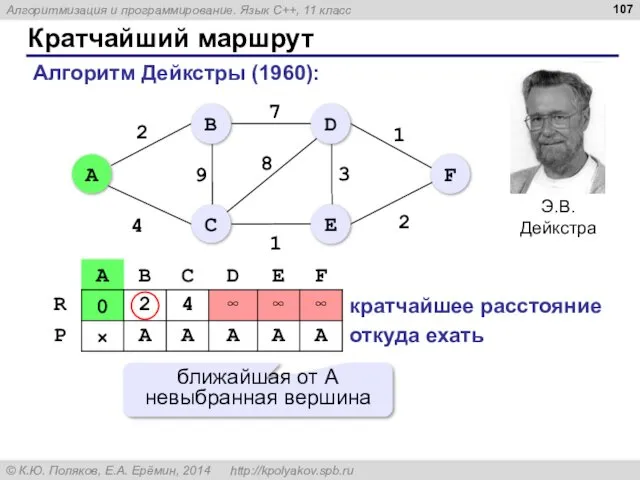
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
ближайшая от A невыбранная вершина
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
ближайшая от A невыбранная вершина
![Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать W[x,z]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-107.jpg)
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
W[x,z] + W[z,y] < W[x,y]
может быть
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
W[x,z] + W[z,y] < W[x,y]
может быть
![Кратчайший маршрут Алгоритм Дейкстры (1960): кратчайшее расстояние откуда ехать W[x,z]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-108.jpg)
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
W[x,z] + W[z,y] < W[x,y]
может быть
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
W[x,z] + W[z,y] < W[x,y]
может быть
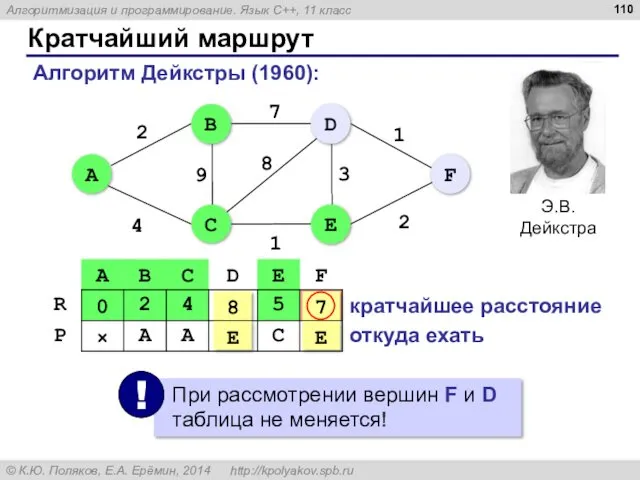
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
7
E
8
E
Кратчайший маршрут
Алгоритм Дейкстры (1960):
кратчайшее расстояние
откуда ехать
7
E
8
E

Кратчайший маршрут
длины кратчайших маршрутов из A в другие вершины
A → C
Кратчайший маршрут
длины кратчайших маршрутов из A в другие вершины
A → C
![Алгоритм Дейкстры const int N = 6; int W[N][N]; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-111.jpg)
Алгоритм Дейкстры
const int N = 6;
int W[N][N]; // весовая матрица
bool active[N];
Алгоритм Дейкстры
const int N = 6;
int W[N][N]; // весовая матрица
bool active[N];
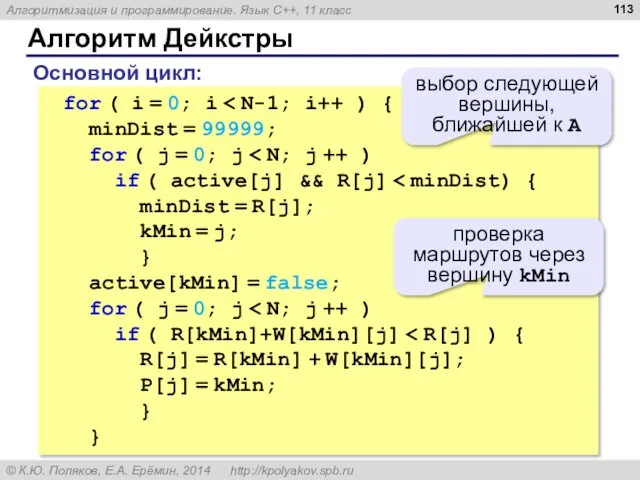
Алгоритм Дейкстры
for ( i = 0; i < N-1; i++ )
Алгоритм Дейкстры
for ( i = 0; i < N-1; i++ )

Алгоритм Дейкстры
i = N-1;
while ( i != -1 )
{
Алгоритм Дейкстры
i = N-1;
while ( i != -1 )
{

Алгоритм Флойда
for ( k = 0; k < N; k++ )
Алгоритм Флойда
for ( k = 0; k < N; k++ )
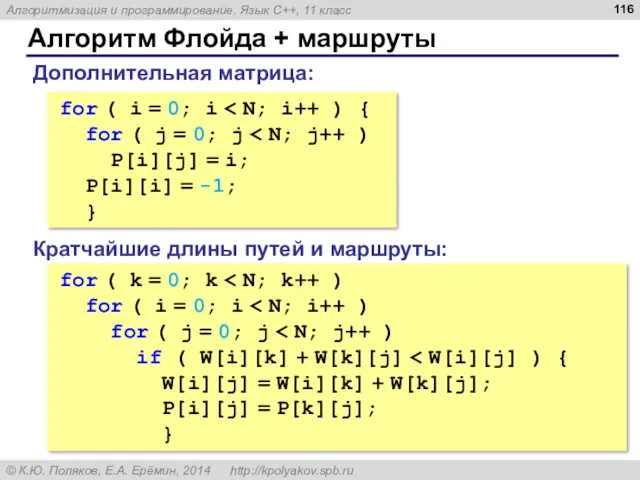
Алгоритм Флойда + маршруты
for ( i = 0; i < N;
Алгоритм Флойда + маршруты
for ( i = 0; i < N;

Задача коммивояжера
Коммивояжер (бродячий торговец) должен выйти из города 1 и, посетив
Задача коммивояжера
Коммивояжер (бродячий торговец) должен выйти из города 1 и, посетив

Некоторые задачи
Задача на минимум суммы. Имеется N населенных пунктов, в каждом
Некоторые задачи
Задача на минимум суммы. Имеется N населенных пунктов, в каждом

Алгоритмизация и программирование. Язык C++
§ 44. Динамическое программирование
Алгоритмизация и программирование. Язык C++
§ 44. Динамическое программирование
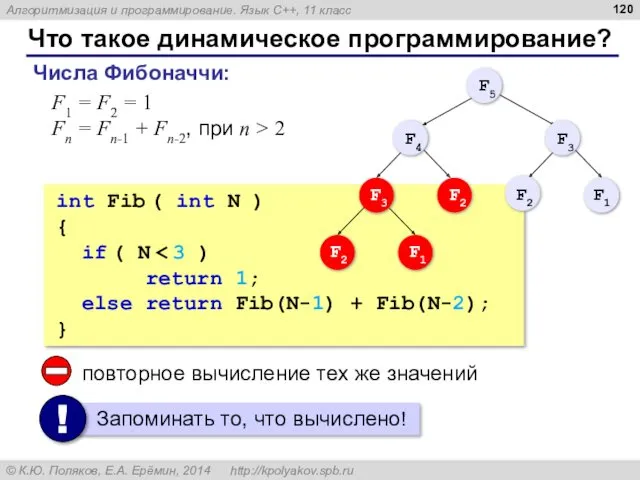
Что такое динамическое программирование?
Числа Фибоначчи:
;
.
F1 = F2 = 1
Fn =
Что такое динамическое программирование?
Числа Фибоначчи:
;
.
F1 = F2 = 1
Fn =
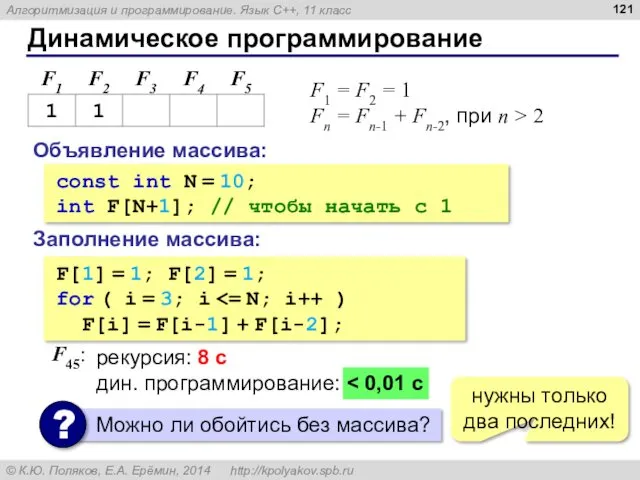
Динамическое программирование
Объявление массива:
const int N = 10;
int F[N+1]; // чтобы начать
Динамическое программирование
Объявление массива:
const int N = 10;
int F[N+1]; // чтобы начать

Динамическое программирование
Динамическое программирование – это способ решения сложных задач путем сведения
Динамическое программирование
Динамическое программирование – это способ решения сложных задач путем сведения

Количество вариантов
Задача. Найти количество KN цепочек, состоящих из N нулей и
Количество вариантов
Задача. Найти количество KN цепочек, состоящих из N нулей и
Количество вариантов
Задача. Найти количество KN цепочек, состоящих из N нулей и
Количество вариантов
Задача. Найти количество KN цепочек, состоящих из N нулей и

Оптимальное решение
Задача. В цистерне N литров молока. Есть бидоны объемом 1,
Оптимальное решение
Задача. В цистерне N литров молока. Есть бидоны объемом 1,

Оптимальное решение
Сначала выбрали бидон…
KN – минимальное число бидонов для N литров
KN
Оптимальное решение
Сначала выбрали бидон…
KN – минимальное число бидонов для N литров
KN

Оптимальное решение (бидоны)
1
1
2
1
3
1
4
1
1
5
1
6
2
1
3
1
4
1
2
5
KN = 1 + min (KN-1 , KN-5 ,
Оптимальное решение (бидоны)
1
1
2
1
3
1
4
1
1
5
1
6
2
1
3
1
4
1
2
5
KN = 1 + min (KN-1 , KN-5 ,

Задача о куче
Задача. Из камней весом pi (i=1, …, N) набрать
Задача о куче
Задача. Из камней весом pi (i=1, …, N) набрать

Задача о куче
Задача. Из камней весом pi (i=1, …, N) набрать
Задача о куче
Задача. Из камней весом pi (i=1, …, N) набрать
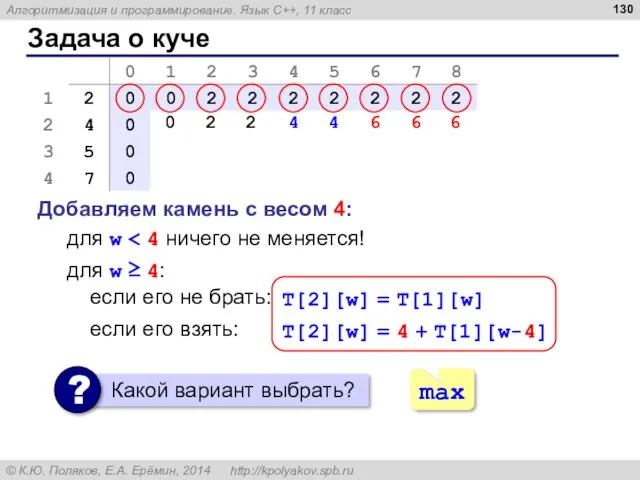
Задача о куче
Добавляем камень с весом 4:
для w < 4 ничего
Задача о куче
Добавляем камень с весом 4:
для w < 4 ничего
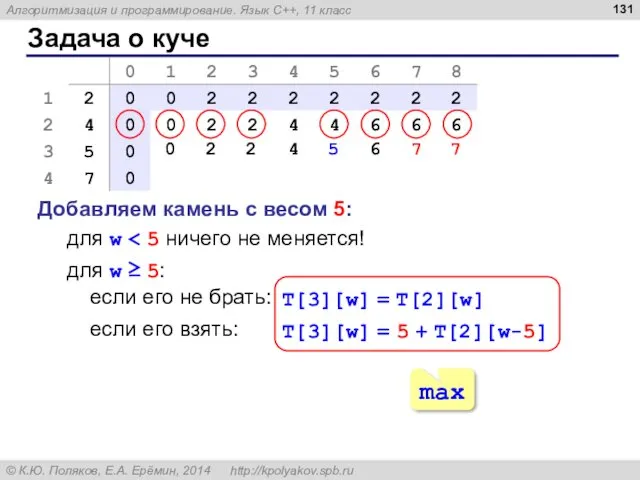
Задача о куче
Добавляем камень с весом 5:
для w < 5 ничего
Задача о куче
Добавляем камень с весом 5:
для w < 5 ничего
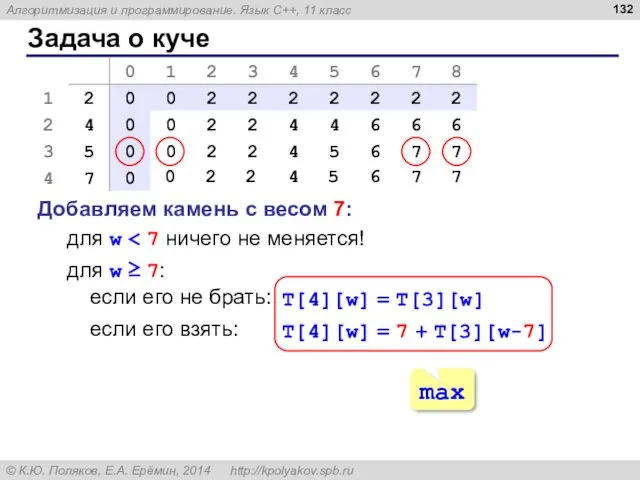
Задача о куче
Добавляем камень с весом 7:
для w < 7 ничего
Задача о куче
Добавляем камень с весом 7:
для w < 7 ничего
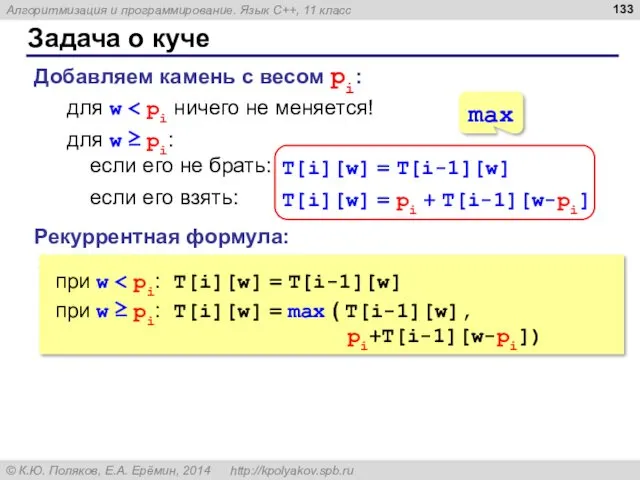
Задача о куче
Добавляем камень с весом pi:
для w < pi ничего
Задача о куче
Добавляем камень с весом pi:
для w < pi ничего
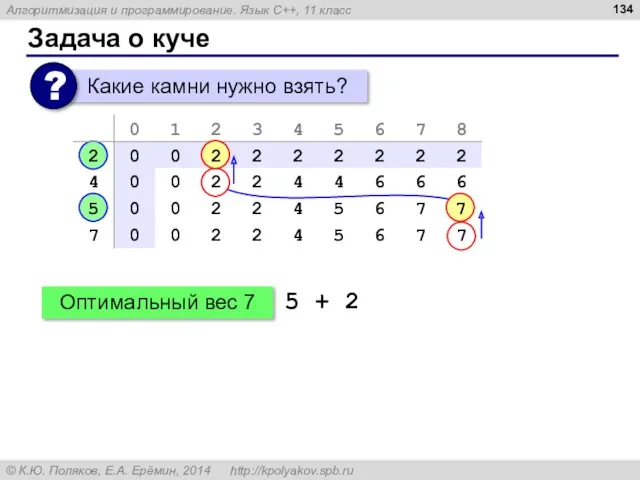
Задача о куче
Оптимальный вес 7
5 + 2
Задача о куче
Оптимальный вес 7
5 + 2

Задача о куче
Заполнение таблицы:
W+1
N
псевдополиномиальный
Задача о куче
Заполнение таблицы:
W+1
N
псевдополиномиальный

Количество программ
Задача. У исполнителя Утроитель есть команды:
1. прибавь 1
2.
Количество программ
Задача. У исполнителя Утроитель есть команды:
1. прибавь 1
2.

Количество программ
Как получить число N:
N
если делится на 3!
последняя команда
Рекуррентная формула:
KN =
Количество программ
Как получить число N:
N
если делится на 3!
последняя команда
Рекуррентная формула:
KN =

Количество программ
Заполнение таблицы:
Рекуррентная формула:
KN = KN-1 если N не делится на
Количество программ
Заполнение таблицы:
Рекуррентная формула:
KN = KN-1 если N не делится на
![Количество программ Только точки изменения: 12 20 Программа: K[1] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7368/slide-138.jpg)
Количество программ
Только точки изменения:
12
20
Программа:
K[1] = 1;
for ( i = 2; i
Количество программ
Только точки изменения:
12
20
Программа:
K[1] = 1;
for ( i = 2; i

Размен монет
Задача. Сколькими различными способами можно выдать сдачу размером W рублей,
Размен монет
Задача. Сколькими различными способами можно выдать сдачу размером W рублей,

Размен монет
Пример: W = 10, монеты 1, 2, 5 и 10
w
pi
базовые
Размен монет
Пример: W = 10, монеты 1, 2, 5 и 10
w
pi
базовые

Размен монет
Пример: W = 10, монеты 1, 2, 5 и 10
Рекуррентная
Размен монет
Пример: W = 10, монеты 1, 2, 5 и 10
Рекуррентная

Конец фильма
ПОЛЯКОВ Константин Юрьевич
д.т.н., учитель информатики
ГБОУ СОШ № 163, г. Санкт-Петербург
kpolyakov@mail.ru
Конец фильма
ПОЛЯКОВ Константин Юрьевич
д.т.н., учитель информатики
ГБОУ СОШ № 163, г. Санкт-Петербург
kpolyakov@mail.ru
 Наука і техніка в інформаційному суспільстві
Наука і техніка в інформаційному суспільстві Организация ввода и вывода данных. Начала программирования
Организация ввода и вывода данных. Начала программирования Моделирование и формализация. Моделирование как метод познания
Моделирование и формализация. Моделирование как метод познания Бит чётности
Бит чётности WIC Основной рабочий инструмент
WIC Основной рабочий инструмент Графический редактор Paint
Графический редактор Paint Одна распределённая станция Avaya, все сервисы через SIP. Миграция сервисов NEC и Asterisk на Avaya Aura
Одна распределённая станция Avaya, все сервисы через SIP. Миграция сервисов NEC и Asterisk на Avaya Aura Технология поиска информации в сети Интернет
Технология поиска информации в сети Интернет Построение диаграмм с использованием Мастера диаграмм при изучении текстового процессора Microsoft Word
Построение диаграмм с использованием Мастера диаграмм при изучении текстового процессора Microsoft Word Главные тренды
Главные тренды Основи Turtle. (Лекция 2)
Основи Turtle. (Лекция 2) Tег DIV и SPAN. CSS. (Тема 9)
Tег DIV и SPAN. CSS. (Тема 9) Cover title. Cover subtitile. Footer department
Cover title. Cover subtitile. Footer department Файл - серверные и клиент - серверные технологии в современных информационных технологиях
Файл - серверные и клиент - серверные технологии в современных информационных технологиях Программное обеспечение ГИС. Лекция 18
Программное обеспечение ГИС. Лекция 18 Электронные платежные системы. Лекция 9
Электронные платежные системы. Лекция 9 Мистерия Игры Богов – IV. Квадрант Мутации
Мистерия Игры Богов – IV. Квадрант Мутации Системы счисления. Двоичная, восьмеричная, шестнадцатеричная
Системы счисления. Двоичная, восьмеричная, шестнадцатеричная Информационная безопасность. Криптографические средства защиты данных. Шифрование
Информационная безопасность. Криптографические средства защиты данных. Шифрование Презентация урока по теме Двоичное кодирование информации в компьютере
Презентация урока по теме Двоичное кодирование информации в компьютере Типы алгоритмов
Типы алгоритмов Монтаж видеороликов в Windows Movie Maker
Монтаж видеороликов в Windows Movie Maker Инструкция по обеспечению актуальности данных при формировании и ведении ведомственных перечней государственных услуг и работ
Инструкция по обеспечению актуальности данных при формировании и ведении ведомственных перечней государственных услуг и работ Организация работы с одаренными и мотивированными детьми на уроке информатики
Организация работы с одаренными и мотивированными детьми на уроке информатики 8. Java Databases and JDBC 1. Introduction to Databases
8. Java Databases and JDBC 1. Introduction to Databases Как понять когда можно бросать работу и уходить в стартап
Как понять когда можно бросать работу и уходить в стартап Управление насосной станцией. Программирование в LOGO! Soft Comfort
Управление насосной станцией. Программирование в LOGO! Soft Comfort База данных магазина велозапчастей
База данных магазина велозапчастей