- Алгоритмы и структуры данных. Скорость поиска

Содержание
- 2. Для многих приложений необходимо и достаточно реализовывать динамические множества, поддерживающие только стандартные операции : вставка поиск
- 3. Скорость поиска Линейный поиск - Tprepare = О(n),Tfind = O(n) Бинарный поиск и деревья поиска -
- 4. Прямая адресация применяется для небольших множеств ключей. Требуется задать динамическое множество, каждый элемент которого имеет ключ
- 5. Прямая адресация Операция поиска по ключу занимает время Ο(1)
- 6. Недостатки прямой адресации : если пространство ключей U велико, хранение таблицы Т размером |U| непрактично, а
- 7. Хеш-функция – такая функция h, которая определяет местоположение элементов множества U в таблице T. Хеш-функция
- 8. При хешировании элемент с ключом k хранится в ячейке h(k), хеш-функция h используется для вычисления ячейки
- 9. Хеширование
- 10. Коллизия – ситуация, когда два ключа отображаются в одну и ту же ячейку . Например, h(43)
- 11. Коллизии
- 12. Идея: Хранить элементы множества с одинаковым значением хэш-функции в виде списка. h(51) = h(49) = h(63)
- 13. Наихудший случай: если хэш-функция для всех элементов множества выдает одно и то же значение. Время доступа
- 14. Пусть дана таблица T[0..m - 1], и в ней хранится n ключей. Тогда, α = n/m
- 15. Выбор хэш-функции Ключи должны равномерно распределятся по всем ячейкам таблицы. Закономерность распределения ключей хэш-функции не должна
- 16. Метод деления h (k) = k mod m Проблема маленького делителя m Пример №1. m =
- 17. Метод деления: хорошая эвристика Выбирать для m простое число не близкое к степеням 2 и 10.
- 18. Метод умножения Пусть m = 2r, ключи являются w-битными словами. h(k) = (A • k mod
- 19. Метод умножения: пример m = 8 = 23, w = 7 ignore by mod 2w 1001010
- 20. Разрешение коллизий: открытая адресация Не нужно хранить ссылки Будем последовательно проверять ячейки таблиц, пока не найдем
- 21. Открытая адресация: пример вставки Пусть дана таблица A: 2 3 4 5 6 7 8 9
- 22. Открытая адресация: поиск Поиск – также последовательное исследование Успех, когда нашли значение Неудача, когда нашли пустую
- 23. Стратегии исследования Линейная - h(k, i) = (h′(k) + i) mod m где h′(k) – обычная
- 24. Двойное хеширование Этот метод даёт отличные результаты, но h2(k) должен быть взаимно простым с m. Этого
- 25. Открытая адресация: пример вставки Пусть дана таблица A: Двойное хеширование h(k,i) = (h1(k) + i •
- 26. Открытая адресация: пример вставки
- 28. Скорость работы поиска в хэш-таблице при открытой адресации а Как же себя ведет а: Таблица заполнена
- 30. Скачать презентацию

Для многих приложений необходимо и достаточно реализовывать динамические множества, поддерживающие только
Для многих приложений необходимо и достаточно реализовывать динамические множества, поддерживающие только

Скорость поиска
Линейный поиск - Tprepare = О(n),Tfind = O(n)
Скорость поиска
Линейный поиск - Tprepare = О(n),Tfind = O(n)

Прямая адресация применяется для небольших множеств ключей. Требуется задать динамическое множество,
Прямая адресация применяется для небольших множеств ключей. Требуется задать динамическое множество,
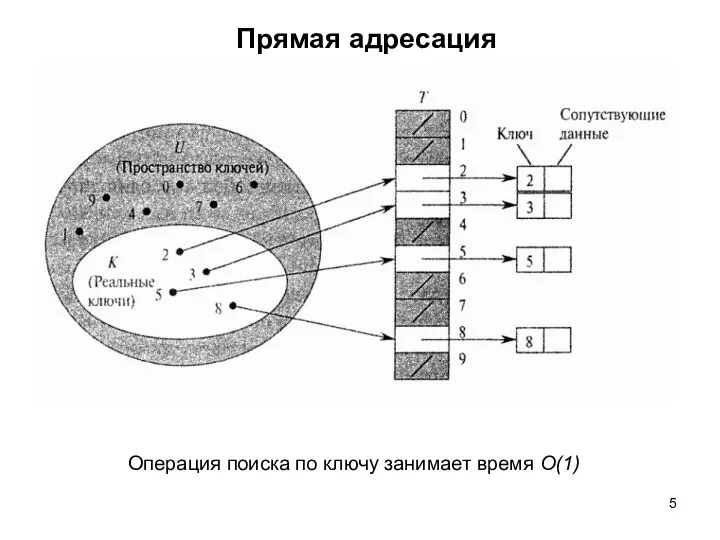
Прямая адресация
Операция поиска по ключу занимает время Ο(1)
Прямая адресация
Операция поиска по ключу занимает время Ο(1)

Недостатки прямой адресации :
если пространство ключей U велико, хранение таблицы
Недостатки прямой адресации :
если пространство ключей U велико, хранение таблицы
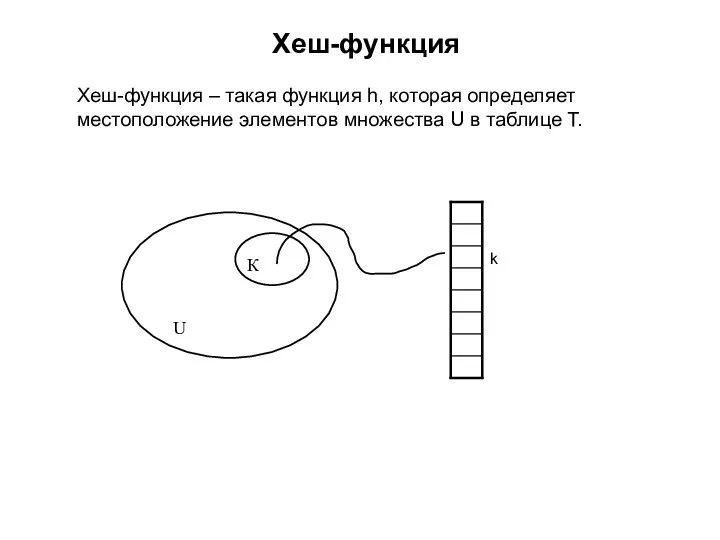
Хеш-функция – такая функция h, которая определяет
местоположение элементов множества U в
Хеш-функция – такая функция h, которая определяет
местоположение элементов множества U в

При хешировании элемент с ключом k хранится в ячейке h(k), хеш-функция
При хешировании элемент с ключом k хранится в ячейке h(k), хеш-функция
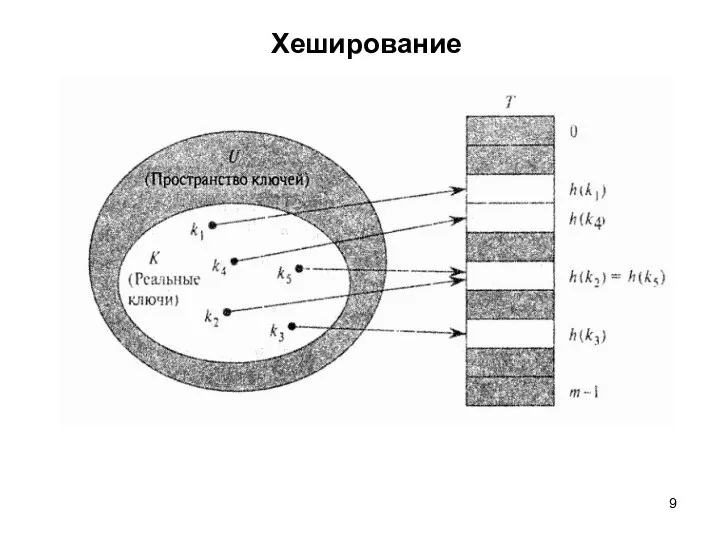
Хеширование
Хеширование

Коллизия – ситуация, когда два ключа отображаются в одну и ту
Коллизия – ситуация, когда два ключа отображаются в одну и ту
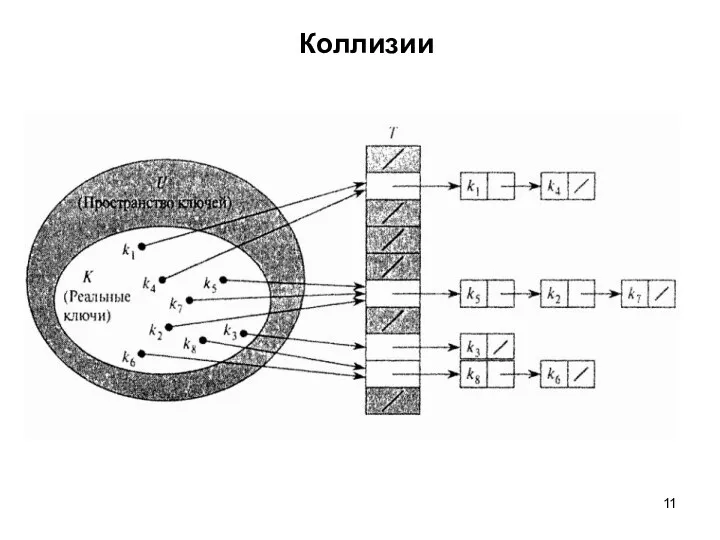
Коллизии
Коллизии
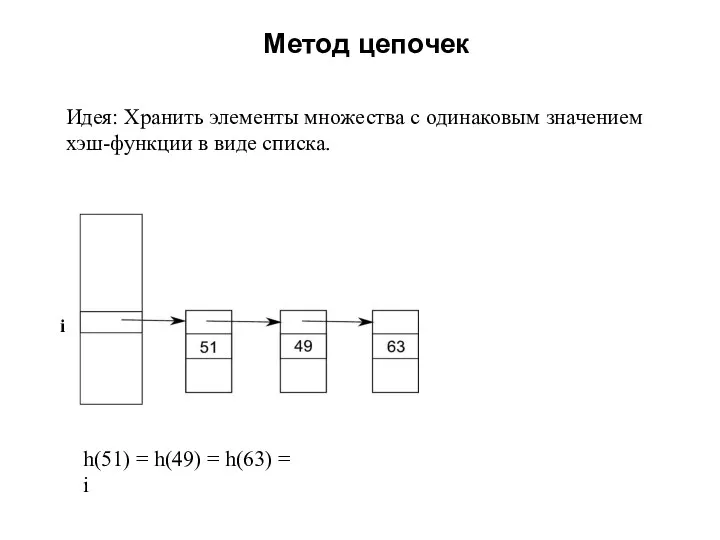
Идея: Хранить элементы множества с одинаковым значением
хэш-функции в виде списка.
h(51) =
Идея: Хранить элементы множества с одинаковым значением
хэш-функции в виде списка.
h(51) =

Наихудший случай: если хэш-функция для всех элементов множества выдает одно
Наихудший случай: если хэш-функция для всех элементов множества выдает одно
![Пусть дана таблица T[0..m - 1], и в ней хранится](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/324921/slide-13.jpg)
Пусть дана таблица T[0..m - 1], и в ней хранится n
Пусть дана таблица T[0..m - 1], и в ней хранится n

Выбор хэш-функции
Ключи должны равномерно распределятся по всем ячейкам
таблицы.
Закономерность распределения ключей хэш-функции
Выбор хэш-функции
Ключи должны равномерно распределятся по всем ячейкам
таблицы.
Закономерность распределения ключей хэш-функции

Метод деления
h (k) = k mod m
Проблема маленького делителя m
Пример №1.
Метод деления
h (k) = k mod m
Проблема маленького делителя m
Пример №1.

Метод деления: хорошая эвристика
Выбирать для m простое число не близкое
Метод деления: хорошая эвристика
Выбирать для m простое число не близкое

Метод умножения
Пусть m = 2r, ключи являются w-битными словами.
h(k) =
Метод умножения
Пусть m = 2r, ключи являются w-битными словами.
h(k) =
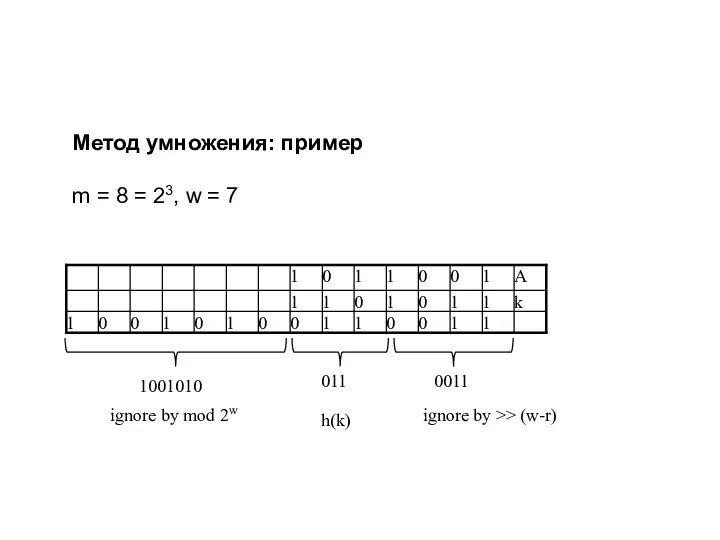
Метод умножения: пример
m = 8 = 23, w = 7
ignore
Метод умножения: пример
m = 8 = 23, w = 7
ignore

Разрешение коллизий: открытая адресация
Не нужно хранить ссылки
Будем последовательно проверять ячейки таблиц,
Разрешение коллизий: открытая адресация
Не нужно хранить ссылки
Будем последовательно проверять ячейки таблиц,

Открытая адресация: пример вставки
Пусть дана таблица A:
2 3 4 5
Открытая адресация: пример вставки
Пусть дана таблица A:
2 3 4 5

Открытая адресация: поиск
Поиск – также последовательное исследование
Успех, когда нашли значение
Неудача, когда
Открытая адресация: поиск
Поиск – также последовательное исследование
Успех, когда нашли значение
Неудача, когда

Стратегии исследования
Линейная -
h(k, i) = (h′(k) + i) mod m
где
Стратегии исследования
Линейная -
h(k, i) = (h′(k) + i) mod m
где

Двойное хеширование
Этот метод даёт отличные результаты, но h2(k) должен быть взаимно
простым
Этот метод даёт отличные результаты, но h2(k) должен быть взаимно
простым

Открытая адресация: пример вставки
Пусть дана таблица A:
Двойное хеширование
h(k,i) = (h1(k) +
Открытая адресация: пример вставки
Пусть дана таблица A:
Двойное хеширование
h(k,i) = (h1(k) +
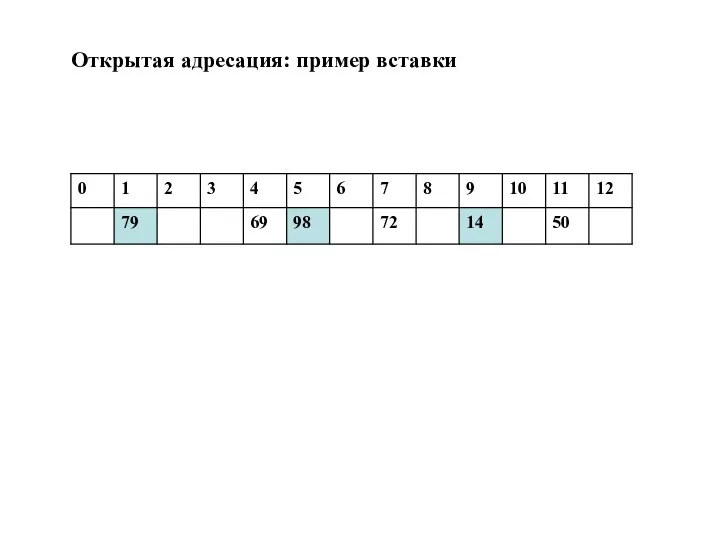
Открытая адресация: пример вставки
Открытая адресация: пример вставки


Скорость работы поиска в хэш-таблице при
открытой адресации
а < 1 — const
Скорость работы поиска в хэш-таблице при
открытой адресации
а < 1 — const
 Что такое socket.io
Что такое socket.io Object oriented programming. (Lesson 6, part 2)
Object oriented programming. (Lesson 6, part 2) Полезные адреса Интернет-ресурсов
Полезные адреса Интернет-ресурсов Аппаратное и программное обеспечение ЭВМ и сетей
Аппаратное и программное обеспечение ЭВМ и сетей Способы передачи движения. Модель: Мотоцикл с коляской. Занятие №4
Способы передачи движения. Модель: Мотоцикл с коляской. Занятие №4 Запоминающие устройства компьютера. (Лекция 5)
Запоминающие устройства компьютера. (Лекция 5) Значение логического выражения. Решение задания 3. ОГЭ
Значение логического выражения. Решение задания 3. ОГЭ Процесс загрузки и BIOS
Процесс загрузки и BIOS Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет
Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет Установка виртуальной машины. Установка операционной системы
Установка виртуальной машины. Установка операционной системы Управление файловой системой
Управление файловой системой Структуры данных
Структуры данных Условные операторы
Условные операторы Офіційний майданчик державних закупівель. Ваше зручне місце для торгів. Public-Bid
Офіційний майданчик державних закупівель. Ваше зручне місце для торгів. Public-Bid Введение в Matlab
Введение в Matlab Практическая работа в MS PowerPoint-2010
Практическая работа в MS PowerPoint-2010 Порядок оформления заказа
Порядок оформления заказа Я и интернет будущего
Я и интернет будущего Виды компьютерных сетей
Виды компьютерных сетей Принципы построения компьютеров
Принципы построения компьютеров Способы адресации в микропроцессорных системах
Способы адресации в микропроцессорных системах Оценка сложности вычислительных алгоритмов. Лекция 22
Оценка сложности вычислительных алгоритмов. Лекция 22 Парадигмы программирования
Парадигмы программирования Устройства ввода-вывода
Устройства ввода-вывода Презентация к уроку информатики и ИКТ
Презентация к уроку информатики и ИКТ Создание графических изображений. Обработка графической информации. Информатика. 7 класс
Создание графических изображений. Обработка графической информации. Информатика. 7 класс Всероссийская перепись населения 2020
Всероссийская перепись населения 2020 презентация электронного учебника
презентация электронного учебника