- Структуры данных

Содержание
- 2. При решении конкретной задачи можно считать, что у нас в наличии имеется «черный ящик» (его мы
- 3. Очередь (queue) Очередь — абстрактный тип данных с дисциплиной доступа к элементам «первый пришёл — первый
- 4. QUEUE-INIT – инициализирует (создает пустую) очередь; ENQUEUE (x) – добавляет в очередь объект x; DEQUEUE –
- 5. Operation QUEUE-INIT Head:= 0; Tail:= 0; End; Operation ENQUEUE (x) Head:= Head+1; Q[Head]:= x; End; Operation
- 6. Опишем реализацию очереди на базе массива. Будем использовать для хранения данных массив Q[0..N], где число N
- 7. СТЕК Стек – список, организованный по принципу LIFO (Last In, First Out – "последним вошел, первым
- 8. STACK-INIT – инициализирует стек; PUSH (x) – добавляет в стек объект x; POP – удаляет из
- 9. Стек будем реализовывать также на базе массива S[1..N]. Данные будем хранить в некотором интервале последовательных ячеек
- 10. Operation STACK-INIT Top:= 0; End; Operation PUSH (x) Top:= Top+1; S[Top]:= x; End; Operation POP Top:=
- 11. Дек (Deque) Дек (deque — double ended queue, «двусторонняя очередь») – структура данных, функционирующая одновременно по
- 12. Базовые операции добавление элемента в начало; добавление элемента в конец; удаление первого элемента; удаление последнего элемента;
- 13. На практике этот список может быть дополнен проверкой дека на пустоту, получением его размера и некоторыми
- 14. СПИСОК Список – структура, в которой данные выписаны в некотором порядке. В отличие от массива, этот
- 15. LIST-INIT – инициализирует список; LIST-FIND (k) – возвращает TRUE, если в списке есть объект с ключом
- 17. Опишем реализацию всех операций для двусвязного некольцевого списка. Каждый элемент списка будем хранить как запись, содержащую
- 18. Operation LIST-INIT Head:= NIL; End; Operation LIST-FIND (k) X:= Head; While X NIL Do Begin If
- 19. При добавлении элемента в список можно вставить его в начало списка, при этом нужно переписать некоторые
- 20. При удалении элемента из списка нужно соединить указателями предыдущий и следующий за ним элементы. При этом
- 21. КУЧА Куча - специализированная структура данных типа дерево, которая удовлетворяет свойству кучи: если B является узлом-потомком
- 22. Свойство 1. Высота полного двоичного дерева из N вершин (то есть максимальное количество ребер на пути
- 23. Функции для работы с кучей а – это массив, где хранится наша куча. size – её
- 24. Пирамидальная сортировка О(n * log n) а – массив, который нужно отсортировать n – размер массива
- 25. Приоритетная очередь Приоритетная очередь — это абстрактная структура данных на подобии стека или очереди, где у
- 27. Скачать презентацию

При решении конкретной задачи можно считать, что у нас в наличии

Очередь (queue)
Очередь — абстрактный тип данных с дисциплиной доступа к элементам
Очередь (queue)
Очередь — абстрактный тип данных с дисциплиной доступа к элементам

QUEUE-INIT – инициализирует (создает пустую) очередь;
ENQUEUE (x) – добавляет в
ENQUEUE (x) – добавляет в

Operation QUEUE-INIT
Head:= 0;
Tail:= 0;
End;
Operation ENQUEUE (x)
Head:=
Head:= 0;
Tail:= 0;
End;
Operation ENQUEUE (x)
Head:=

Опишем реализацию очереди на базе массива. Будем использовать для хранения данных

СТЕК
Стек – список, организованный по принципу LIFO (Last In, First Out
СТЕК
Стек – список, организованный по принципу LIFO (Last In, First Out

STACK-INIT – инициализирует стек;
PUSH (x) – добавляет в стек объект
STACK-INIT – инициализирует стек;
PUSH (x) – добавляет в стек объект
![Стек будем реализовывать также на базе массива S[1..N]. Данные будем](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/108475/slide-8.jpg)
Стек будем реализовывать также на базе массива S[1..N]. Данные будем хранить
Стек будем реализовывать также на базе массива S[1..N]. Данные будем хранить

Operation STACK-INIT
Top:= 0;
End;
Operation PUSH (x)
Top:= Top+1;
S[Top]:=
Operation STACK-INIT
Top:= 0;
End;
Operation PUSH (x)
Top:= Top+1;
S[Top]:=

Дек (Deque)
Дек (deque — double ended queue, «двусторонняя очередь») – структура
Дек (Deque)
Дек (deque — double ended queue, «двусторонняя очередь») – структура

Базовые операции
добавление элемента в начало;
добавление элемента в конец;
удаление первого элемента;
удаление последнего
Базовые операции
добавление элемента в начало;
добавление элемента в конец;
удаление первого элемента;
удаление последнего

На практике этот список может быть дополнен проверкой дека на пустоту,
На практике этот список может быть дополнен проверкой дека на пустоту,

СПИСОК
Список – структура, в которой данные выписаны в некотором порядке. В
СПИСОК
Список – структура, в которой данные выписаны в некотором порядке. В

LIST-INIT – инициализирует список;
LIST-FIND (k) – возвращает TRUE, если в
LIST-INIT – инициализирует список;
LIST-FIND (k) – возвращает TRUE, если в
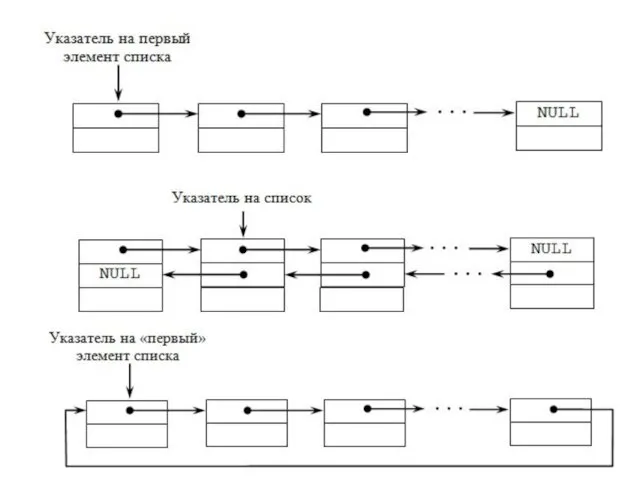

Опишем реализацию всех операций для двусвязного некольцевого списка. Каждый элемент списка
Опишем реализацию всех операций для двусвязного некольцевого списка. Каждый элемент списка

Operation LIST-INIT
Head:= NIL;
End;
Operation LIST-FIND (k)
X:= Head;
While
Operation LIST-INIT
Head:= NIL;
End;
Operation LIST-FIND (k)
X:= Head;
While
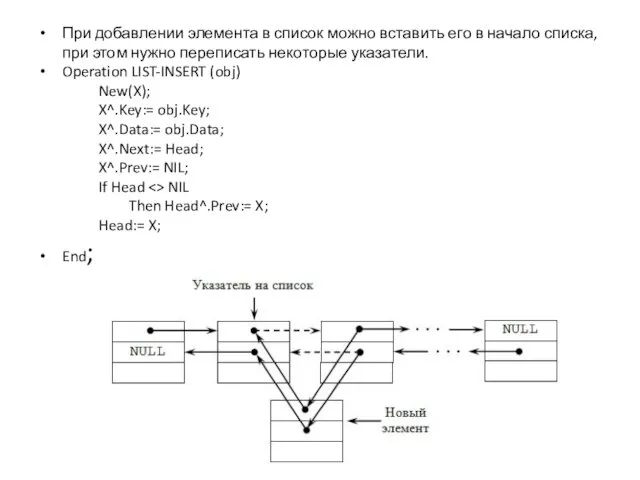
При добавлении элемента в список можно вставить его в начало списка,
При добавлении элемента в список можно вставить его в начало списка,
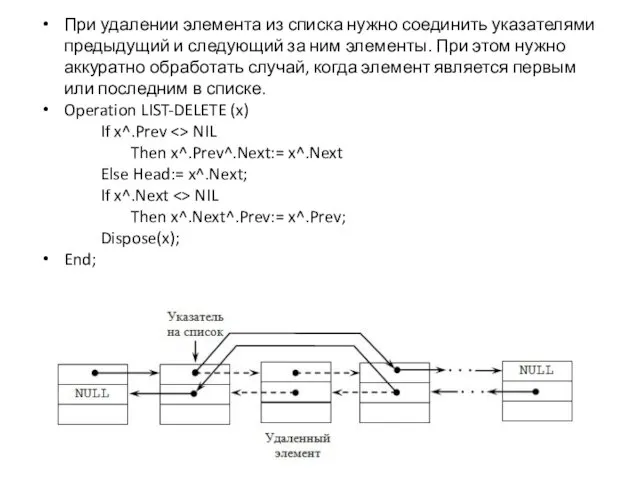
При удалении элемента из списка нужно соединить указателями предыдущий и следующий
При удалении элемента из списка нужно соединить указателями предыдущий и следующий
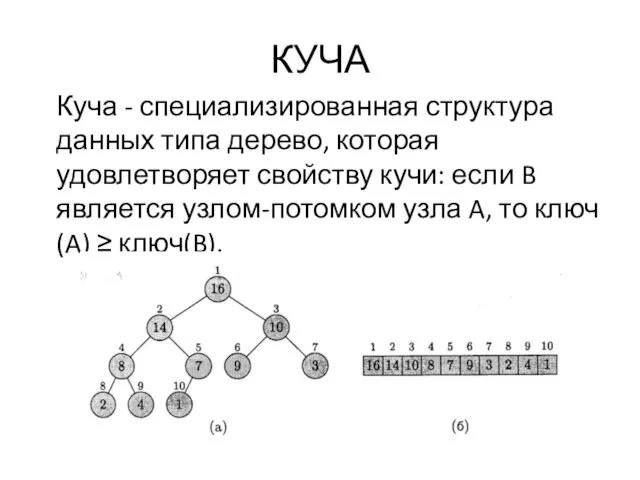
КУЧА
Куча - специализированная структура данных типа дерево, которая удовлетворяет свойству кучи:
КУЧА
Куча - специализированная структура данных типа дерево, которая удовлетворяет свойству кучи:

Свойство 1. Высота полного двоичного дерева из N вершин (то есть
Свойство 1. Высота полного двоичного дерева из N вершин (то есть

Функции для работы с кучей
а – это массив, где хранится наша
Функции для работы с кучей
а – это массив, где хранится наша

Пирамидальная сортировка О(n * log n)
а – массив, который нужно отсортировать
n
Пирамидальная сортировка О(n * log n)
а – массив, который нужно отсортировать
n

Приоритетная очередь
Приоритетная очередь — это абстрактная структура данных на подобии стека
Приоритетная очередь
Приоритетная очередь — это абстрактная структура данных на подобии стека
 Логические принципы проектирования современного компьютера
Логические принципы проектирования современного компьютера Файловые менеджеры
Файловые менеджеры Объединение компьютеров в локальную компьютерную сеть. Организация работы пользователей в локальных компьютерных сетях
Объединение компьютеров в локальную компьютерную сеть. Организация работы пользователей в локальных компьютерных сетях Блоктық шифрлар үшін дифференциалдық криптоталдау тәсілдерімен орнықтылықты зерттеу
Блоктық шифрлар үшін дифференциалдық криптоталдау тәсілдерімен орнықтылықты зерттеу Java database connectivity (JDBC)
Java database connectivity (JDBC) Основы теории информации
Основы теории информации Maple 7 жүйесі мүмкіндіктерімен таныстыру
Maple 7 жүйесі мүмкіндіктерімен таныстыру Типы данных, определяемые пользователем
Типы данных, определяемые пользователем Презентация по дисциплине: Информационные технологии на тему: Поиск информации
Презентация по дисциплине: Информационные технологии на тему: Поиск информации Лекция 8. Основы администрирования Hadoop
Лекция 8. Основы администрирования Hadoop Антивирусные программы
Антивирусные программы Обучение по функционалу 3-9%
Обучение по функционалу 3-9% Разработка собственных правил для SNORT
Разработка собственных правил для SNORT Կոմերցիոն առաջարկ
Կոմերցիոն առաջարկ Итоговый тест по теме Компьютерная графика 5 класс Диск
Итоговый тест по теме Компьютерная графика 5 класс Диск Кодирование графической информации
Кодирование графической информации Структуры и строки в MASM. Префиксы Rep
Структуры и строки в MASM. Префиксы Rep Списки и таблицы в HTML
Списки и таблицы в HTML Регистрация на сайте SPE и получение ID номера
Регистрация на сайте SPE и получение ID номера Сетевой этикет
Сетевой этикет Презентация Крестики ‐ Нолики
Презентация Крестики ‐ Нолики Тексты в компьютерной памяти
Тексты в компьютерной памяти Социальные сети. Инструмент для лучшей организации повседневности или средство развлечения
Социальные сети. Инструмент для лучшей организации повседневности или средство развлечения Презентация и защита проекта
Презентация и защита проекта Сетевые Операционные Системы
Сетевые Операционные Системы Инструкция по участию в торгах на ЭТП ООО Заволжские просторы. Участие в запросе предложений
Инструкция по участию в торгах на ЭТП ООО Заволжские просторы. Участие в запросе предложений Қолданбалы бағдарламалық жасақтама
Қолданбалы бағдарламалық жасақтама Автомобильный светофор
Автомобильный светофор