- Алгоритмы кластеризации в машинном обучении

Содержание
- 2. О кластеризации Кластеризация (или кластерный анализ) — это задача разбиения множества объектов на группы, называемые кластерами.
- 3. K-means K-means - самый популярный алгоритм кластеризации. Выделяется благодаря простоте реализации и скорости выполнения. Принцип работы
- 4. Affinity Propagation Вводится матрица схожести S = NxN, S(k,k) Вводятся матрицы ответственности R = NxN и
- 5. Обязательные оптимизации и параметры Affinity Propagation В начале к матрице сходства добавляется немного шума, т.к. когда
- 6. DBSCAN На вход подается матрица близости (S=NxN) и два загаочных параметра: Радиус ε-окресности - радиус, в
- 7. Spectral clustering Данные представляются в виде графа. Связи проходят в заданной окресности от точки к другим
- 8. Spectral clustering После построения матрицы L, находим ее собственные вектора u и собственные значения λ. Оптимальное
- 9. Алгоритмы в действии
- 10. Еще больше алгоритмов
- 12. Скачать презентацию
О кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов
О кластеризации
Кластеризация (или кластерный анализ) — это задача разбиения множества объектов

K-means
K-means - самый популярный алгоритм кластеризации.
Выделяется благодаря простоте реализации и скорости
K-means
K-means - самый популярный алгоритм кластеризации.
Выделяется благодаря простоте реализации и скорости

Affinity Propagation
Вводится матрица схожести S = NxN, S(k,k)<0 (за схожесть 2-х
Affinity Propagation
Вводится матрица схожести S = NxN, S(k,k)<0 (за схожесть 2-х

Обязательные оптимизации и параметры Affinity Propagation
В начале к матрице сходства добавляется
Обязательные оптимизации и параметры Affinity Propagation
В начале к матрице сходства добавляется

DBSCAN
На вход подается матрица близости (S=NxN) и два загаочных параметра:
Радиус ε-окресности
DBSCAN
На вход подается матрица близости (S=NxN) и два загаочных параметра:
Радиус ε-окресности
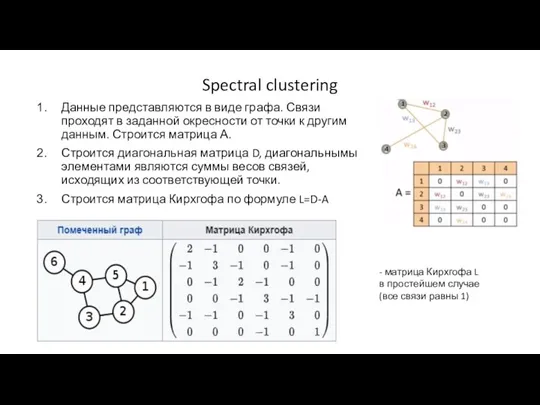
Spectral clustering
Данные представляются в виде графа. Связи проходят в заданной окресности
Spectral clustering
Данные представляются в виде графа. Связи проходят в заданной окресности
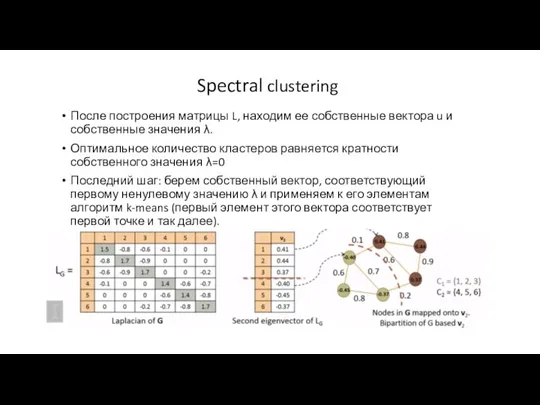
Spectral clustering
После построения матрицы L, находим ее собственные вектора u и
Spectral clustering
После построения матрицы L, находим ее собственные вектора u и

Алгоритмы в действии
Алгоритмы в действии

Еще больше алгоритмов
Еще больше алгоритмов
 Сравнительный анализ СЭД на основе пользовательских оценок
Сравнительный анализ СЭД на основе пользовательских оценок Модельдер және оның тұрлері
Модельдер және оның тұрлері ЕАС ОПС. Задачи системы и роль ключевых пользователей
ЕАС ОПС. Задачи системы и роль ключевых пользователей Очередность работ при последовательной схеме технологического процесса
Очередность работ при последовательной схеме технологического процесса Електропостачання електровозної відкатки. Електровози
Електропостачання електровозної відкатки. Електровози Промышленные сети
Промышленные сети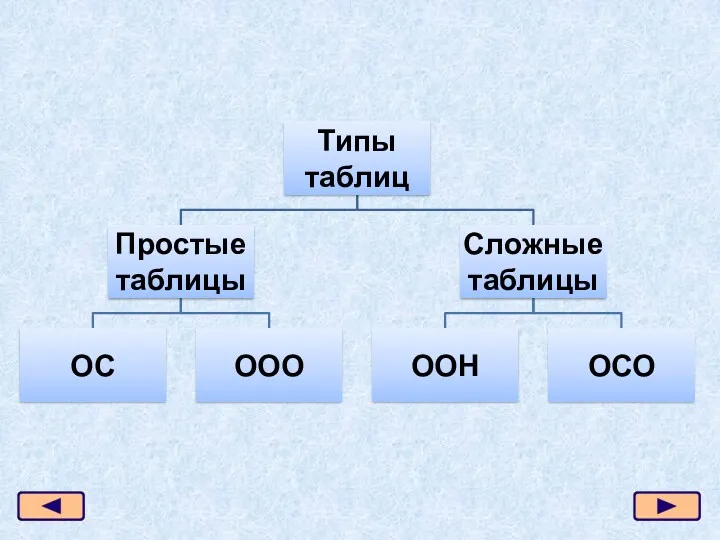 Типы таблиц
Типы таблиц Обработка информации в системах управления базами данных
Обработка информации в системах управления базами данных Регистрация на сайте Научной библиотеки МГУ (для первокурсников)
Регистрация на сайте Научной библиотеки МГУ (для первокурсников) Эволюция телефонов Nokia
Эволюция телефонов Nokia Поиск информации в базе данных. ОГЭ по информатике, задача 12
Поиск информации в базе данных. ОГЭ по информатике, задача 12 Возможности динамических, электронных таблиц. Математическая обработка числовых данных
Возможности динамических, электронных таблиц. Математическая обработка числовых данных Знакомство с графическими редакторами. Растровые рисунки
Знакомство с графическими редакторами. Растровые рисунки Язык программирования Паскаль
Язык программирования Паскаль Яка небезпека очікує дітей в інтернеті
Яка небезпека очікує дітей в інтернеті Поняття електронної таблиці. Засоби опрацювання електронних таблиць. Запуск на виконання табличного процесора
Поняття електронної таблиці. Засоби опрацювання електронних таблиць. Запуск на виконання табличного процесора Фільтрація та сортування
Фільтрація та сортування Высокопроизводительные вычисления
Высокопроизводительные вычисления Қолданбалы бағдарламалық қамсыздандыру
Қолданбалы бағдарламалық қамсыздандыру Разработка внеклассного мероприятия по информатике Путешествие в страну компьютерная графика
Разработка внеклассного мероприятия по информатике Путешествие в страну компьютерная графика Пример слайда. Sydney Opera House is Australia’s
Пример слайда. Sydney Opera House is Australia’s Программирование разветвляющихся алгоритмов. Начала программирования. Условный алгоритм
Программирование разветвляющихся алгоритмов. Начала программирования. Условный алгоритм Коммуникации в соцсетях
Коммуникации в соцсетях Строки. Работа со строками. Лекция 7
Строки. Работа со строками. Лекция 7 Учебный центр. Введение в компанию 2ГИС. Продукты
Учебный центр. Введение в компанию 2ГИС. Продукты Модуль 5. Массивы. Способы их описания, формирования и обработки
Модуль 5. Массивы. Способы их описания, формирования и обработки Configuring Backup Settings (3)
Configuring Backup Settings (3) Устройство компьютера
Устройство компьютера