- Алгоритмы поиска подстроки в строке. Лекция 6

Содержание
- 2. ПРЯМОЙ ПОИСК самый простой и не эффективный поиск. не проводит анализа подстроки наиболее эффективно работает при
- 3. ПРЯМОЙ ПОИСК
- 4. ПРЯМОЙ ПОИСК
- 5. S – текст, n – количество символов текста O – образ, m – количество символов образа
- 6. если f==m то УСПЕХ, вернуть i; i++; кц ПРЯМОЙ ПОИСК
- 7. ПРЯМОЙ ПОИСК Самый неэффективный случай: Оценка времени работы алгоритма O(n*m)
- 8. Описан Кнутом и Праттом и независимо от них Моррисом Результаты опубликованы совместно в 1977 г. Алгоритм
- 9. Алгоритм Кнута, Морриса и Пратта для повышения эффективности алгоритма необходимо, чтобы сдвиг на каждом шаге алгоритма
- 10. обозначим j - количество совпадений, текущего сравнения (j = 3) значение j зависит только от вида
- 11. Для образа строится таблица сдвигов d[m] d[0] = -1, d[1] = 0 d[j] – длина самой
- 12. Примеры таблиц сдвигов для различных образов: КМП – АЛГОРИТМ. Предварительная обработка образа
- 13. m = длина образа о; j = 1, k=0 d[0] = -1; d[1] = 0; Пока
- 14. Если j==m-1 то закончить выполнение цикла k++; d[j+1]=k; j++; кц КМП – АЛГОРИТМ. Предварительная обработка образа
- 15. КМП – АЛГОРИТМ. Пример сдвиг на j – d[j]
- 16. КМП – АЛГОРИТМ. Пример Чем больше совпадений по тексту и меньше совпадений по строке
- 17. Алгоритм Боуэра-Мура Предложен в 1977
- 18. Сравнение символов образа с символами текста осуществляется с конца образа Если несовпадение произошло на символе, не
- 19. Алгоритм Боуэра-Мура Если несовпадение произошло на символе, встречающемся в образе, то выполняется сдвиг на величину, равную
- 20. Алгоритм Боуэра-Мура Перед работой создается массив d, размерность которого равна размеру использованного алфавита
- 21. Алгоритм Боуэра-Мура. Пример
- 22. Алгоритм Боуэра-Мура. Пример Чем меньше совпадений, тем быстрее
- 23. ПОИСК ПОДСТРОКИ В СТРОКЕ Определить таблицы сдвигов для КМП-алгоритма и алгоритма Боуэра – Мура На каждом
- 24. ПОИСК В МАССИВЕ Неупорядоченный массив – прямой поиск (O(n)) Упорядоченный массив – бинарный поиск (О(log2 n))
- 25. Вход – X[n], a 1. F = 0, L = n-1 2. Если F>L то вернуть
- 26. M =1/2* (F+L) ? F + 1/2*(L-F) Если искомый элемент S: 1/2 ? (S-X[F])/(X[L] – X[F])
- 27. BST - деревья Binary Search Tree - деревья двоичного поиска. Родитель Правый потомок Левый потомок
- 28. Правила организации элементов: BST - деревья Родитель Правый потомок Левый потомок Родитель Родитель >
- 29. BST - деревья Реализация описания узла дерева в Си typedef struct node{ int data; struct node
- 30. BST - деревья 7
- 31. BST - деревья 7 9
- 32. BST - деревья 7 9 8
- 33. BST - деревья 7 9 8 6
- 34. BST - деревья 7 9 8 6 3
- 35. BST - деревья 7 9 8 6 3 5
- 36. BST - деревья 7 9 8 6 3 5 20
- 37. BST - деревья 7 9 8 6 3 5 20 15
- 38. BST - деревья 7 9 8 6 3 5 20 15 18
- 39. BST - деревья 7 9 8 6 3 5 20 15 18 1
- 40. BST - деревья 7 9 8 6 3 5 20 15 18 1 2
- 41. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10
- 42. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 43. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 44. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 45. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 46. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 47. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 48. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 49. BST - деревья 7 9 8 6 3 5 20 15 18 1 2 10 19
- 50. Деревья бинарного поиска можно определить таким образом чтобы индексы строились в точности так же… Пример использования
- 51. Пример использования BST-деревьев для поиска слов Д 1 Деревья бинарного поиска можно определить таким образом чтобы
- 52. BST – деревья. Алгоритм вставки элемента Вставка (Node ** Root, int key) Если *Root - пустой,
- 53. BST – деревья. Алгоритм вставки элемента иначе Если key >= *Root->data то Вставка (*Root->right, key) иначе
- 54. Вставка1 (Node ** Root, int key) Если *Root – пустой то выделить память под *Root *Root
- 55. Node *temp = *Root; Пока (temp не пуст) нц Если (key>=temp->data) то Если (temp->right - пуст)
- 57. Скачать презентацию

ПРЯМОЙ ПОИСК
самый простой и не эффективный поиск.
не проводит анализа подстроки
наиболее эффективно
ПРЯМОЙ ПОИСК
самый простой и не эффективный поиск.
не проводит анализа подстроки
наиболее эффективно
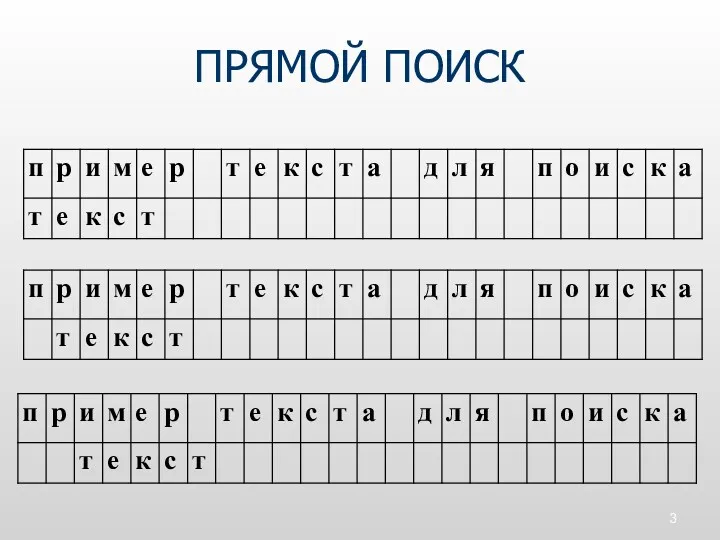
ПРЯМОЙ ПОИСК
ПРЯМОЙ ПОИСК
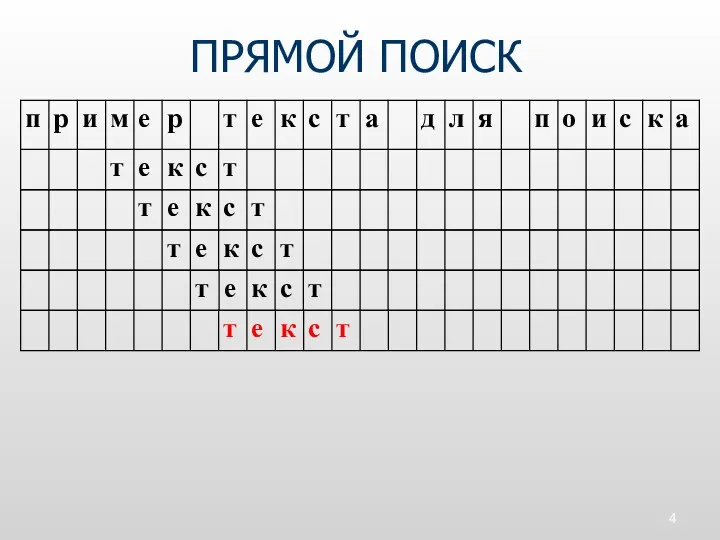
ПРЯМОЙ ПОИСК
ПРЯМОЙ ПОИСК

S – текст, n – количество символов текста
O – образ, m
S – текст, n – количество символов текста
O – образ, m

если f==m то УСПЕХ, вернуть i;
i++;
кц
ПРЯМОЙ ПОИСК
если f==m то УСПЕХ, вернуть i;
i++;
кц
ПРЯМОЙ ПОИСК

ПРЯМОЙ ПОИСК
Самый неэффективный случай:
Оценка времени работы алгоритма O(n*m)
ПРЯМОЙ ПОИСК
Самый неэффективный случай:
Оценка времени работы алгоритма O(n*m)

Описан Кнутом и Праттом и независимо от них Моррисом
Результаты опубликованы совместно
Описан Кнутом и Праттом и независимо от них Моррисом
Результаты опубликованы совместно

Алгоритм Кнута, Морриса и Пратта
для повышения эффективности алгоритма необходимо, чтобы сдвиг
Алгоритм Кнута, Морриса и Пратта
для повышения эффективности алгоритма необходимо, чтобы сдвиг
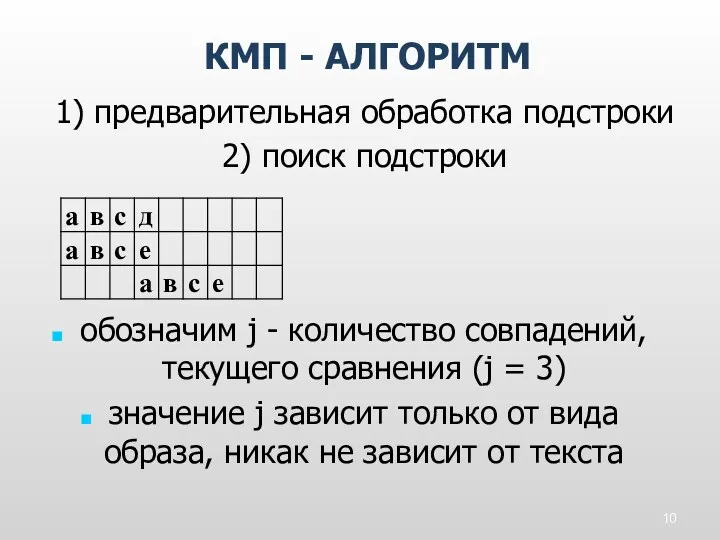
обозначим j - количество совпадений, текущего сравнения (j = 3)
значение j
обозначим j - количество совпадений, текущего сравнения (j = 3)
значение j
![Для образа строится таблица сдвигов d[m] d[0] = -1, d[1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/332003/slide-10.jpg)
Для образа строится таблица сдвигов d[m]
d[0] = -1, d[1] = 0
d[j]
Для образа строится таблица сдвигов d[m]
d[0] = -1, d[1] = 0
d[j]
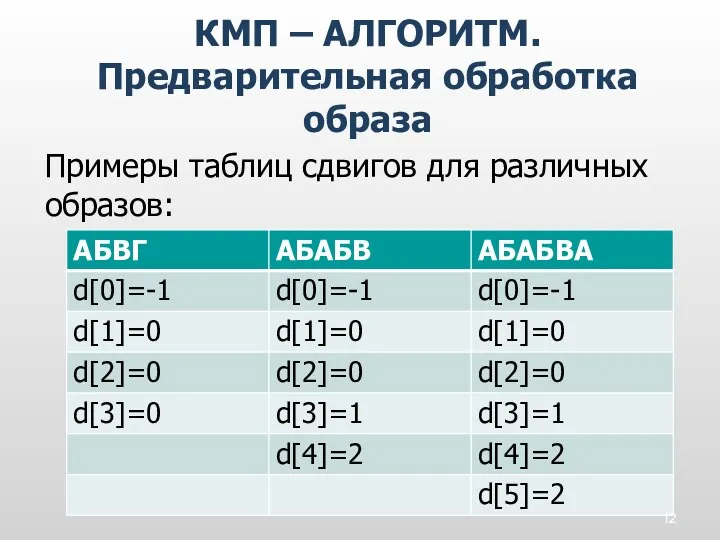
Примеры таблиц сдвигов для различных образов:
КМП – АЛГОРИТМ. Предварительная обработка образа
Примеры таблиц сдвигов для различных образов:
КМП – АЛГОРИТМ. Предварительная обработка образа
![m = длина образа о; j = 1, k=0 d[0]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/332003/slide-12.jpg)
m = длина образа о;
j = 1, k=0
d[0] = -1;
d[1] =
m = длина образа о;
j = 1, k=0
d[0] = -1;
d[1] =
![Если j==m-1 то закончить выполнение цикла k++; d[j+1]=k; j++; кц КМП – АЛГОРИТМ. Предварительная обработка образа](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/332003/slide-13.jpg)
Если j==m-1 то закончить выполнение цикла
k++;
d[j+1]=k;
Если j==m-1 то закончить выполнение цикла
k++;
d[j+1]=k;
![КМП – АЛГОРИТМ. Пример сдвиг на j – d[j]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/332003/slide-14.jpg)
КМП – АЛГОРИТМ.
Пример
сдвиг на j – d[j]
КМП – АЛГОРИТМ.
Пример
сдвиг на j – d[j]
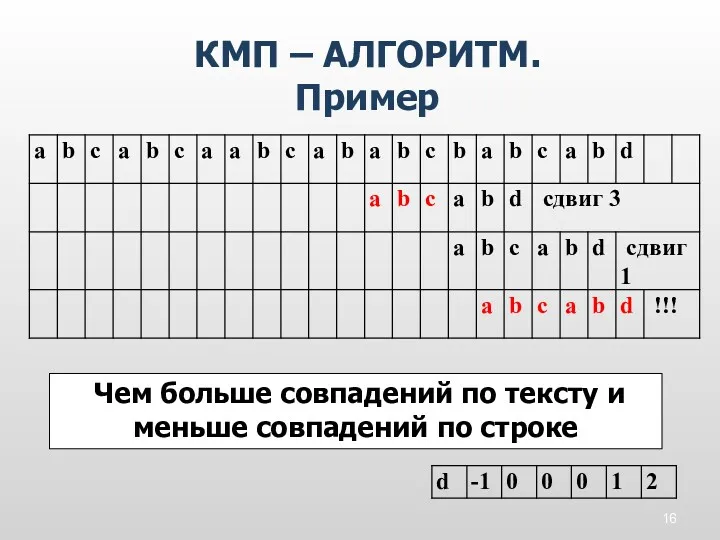
КМП – АЛГОРИТМ.
Пример
Чем больше совпадений по тексту и меньше
КМП – АЛГОРИТМ.
Пример
Чем больше совпадений по тексту и меньше
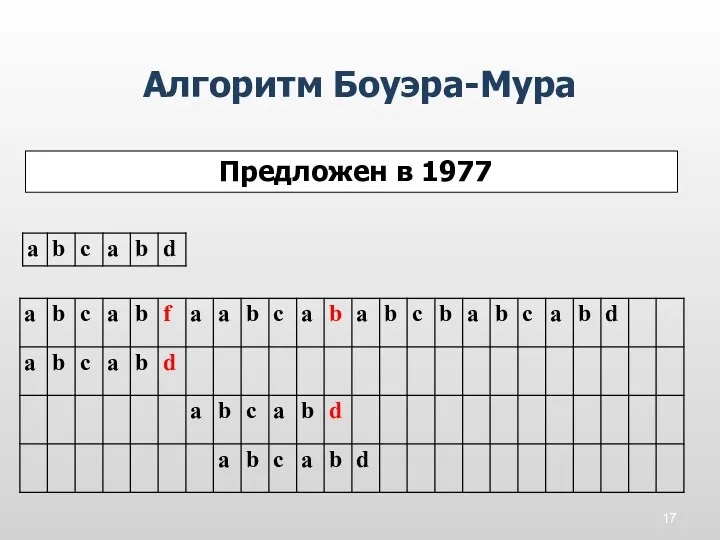
Алгоритм Боуэра-Мура
Предложен в 1977
Алгоритм Боуэра-Мура
Предложен в 1977

Сравнение символов образа с символами текста осуществляется с конца образа
Если несовпадение
Сравнение символов образа с символами текста осуществляется с конца образа
Если несовпадение

Алгоритм Боуэра-Мура
Если несовпадение произошло на символе, встречающемся в образе, то выполняется
Алгоритм Боуэра-Мура
Если несовпадение произошло на символе, встречающемся в образе, то выполняется

Алгоритм Боуэра-Мура
Перед работой создается массив d, размерность которого равна размеру использованного
Алгоритм Боуэра-Мура
Перед работой создается массив d, размерность которого равна размеру использованного
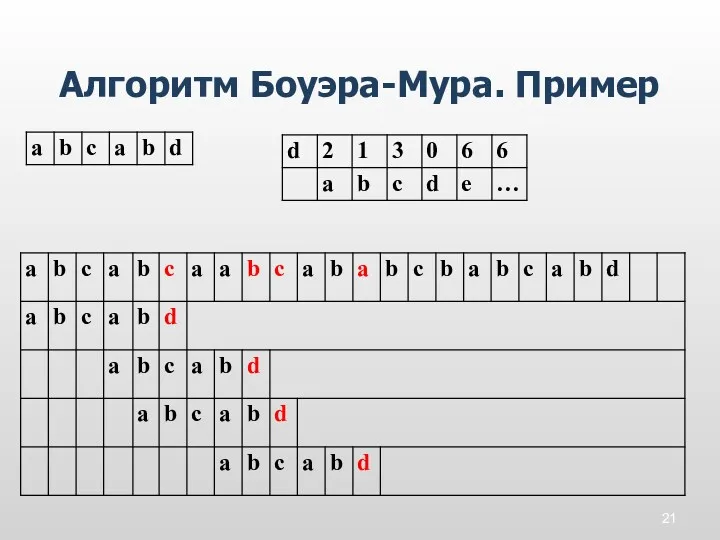
Алгоритм Боуэра-Мура. Пример
Алгоритм Боуэра-Мура. Пример
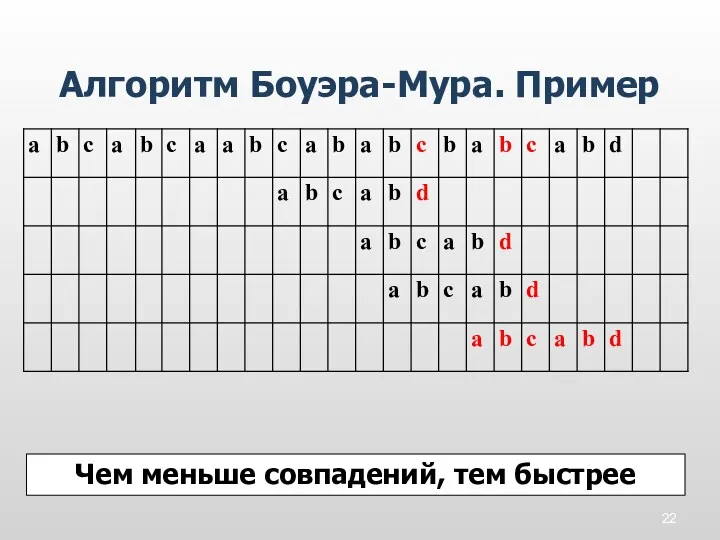
Алгоритм Боуэра-Мура. Пример
Чем меньше совпадений, тем быстрее
Алгоритм Боуэра-Мура. Пример
Чем меньше совпадений, тем быстрее

ПОИСК ПОДСТРОКИ В СТРОКЕ
Определить таблицы сдвигов для КМП-алгоритма и алгоритма Боуэра
ПОИСК ПОДСТРОКИ В СТРОКЕ
Определить таблицы сдвигов для КМП-алгоритма и алгоритма Боуэра

ПОИСК В МАССИВЕ
Неупорядоченный массив – прямой поиск (O(n))
Упорядоченный массив – бинарный
ПОИСК В МАССИВЕ
Неупорядоченный массив – прямой поиск (O(n))
Упорядоченный массив – бинарный
![Вход – X[n], a 1. F = 0, L =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/332003/slide-24.jpg)
Вход – X[n], a
1. F = 0, L = n-1
2. Если
Вход – X[n], a
1. F = 0, L = n-1
2. Если

M =1/2* (F+L) ? F + 1/2*(L-F)
Если искомый элемент S:
1/2 ?
M =1/2* (F+L) ? F + 1/2*(L-F)
Если искомый элемент S:
1/2 ?
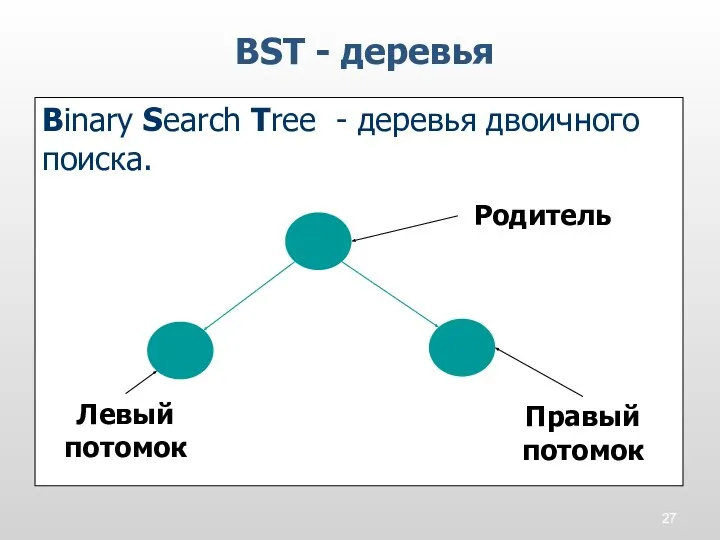
BST - деревья
Binary Search Tree - деревья двоичного поиска.
Родитель
Правый потомок
Левый
BST - деревья
Binary Search Tree - деревья двоичного поиска.
Родитель
Правый потомок
Левый
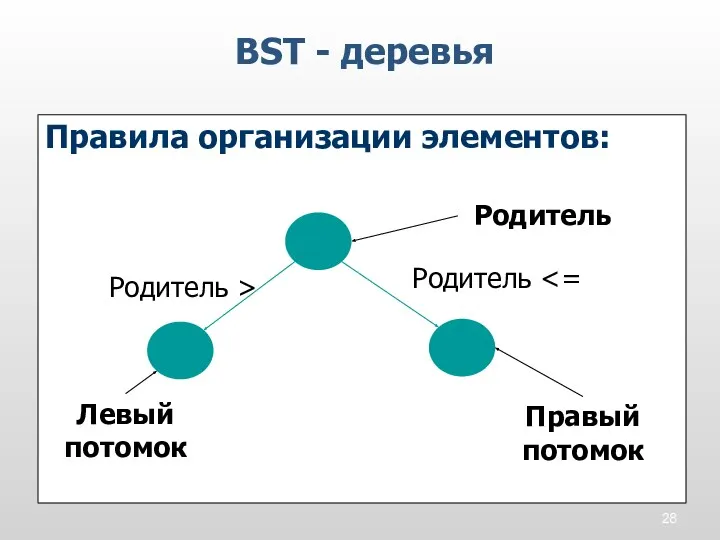
Правила организации элементов:
BST - деревья
Родитель
Правый потомок
Левый потомок
Родитель <=
Родитель >
Правила организации элементов:
BST - деревья
Родитель
Правый потомок
Левый потомок
Родитель <=
Родитель >

BST - деревья
Реализация описания узла дерева в Си
typedef struct node{
int
BST - деревья
Реализация описания узла дерева в Си
typedef struct node{
int
BST - деревья
7
BST - деревья
7
BST - деревья
7
9
BST - деревья
7
9
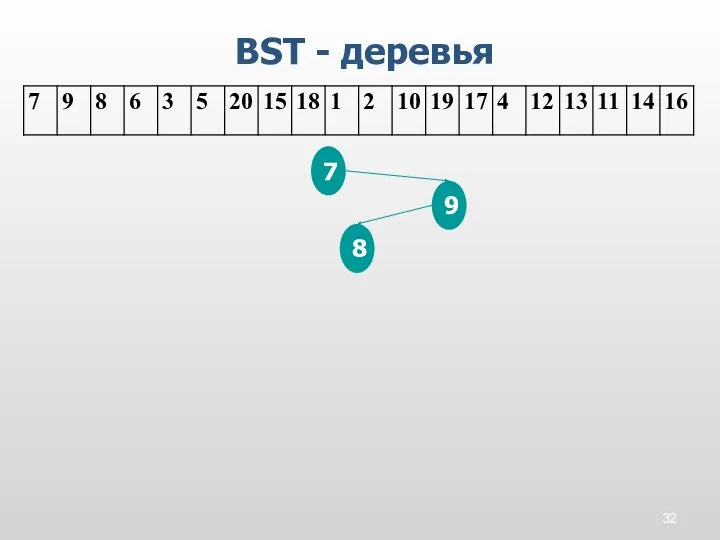
BST - деревья
7
9
8
BST - деревья
7
9
8
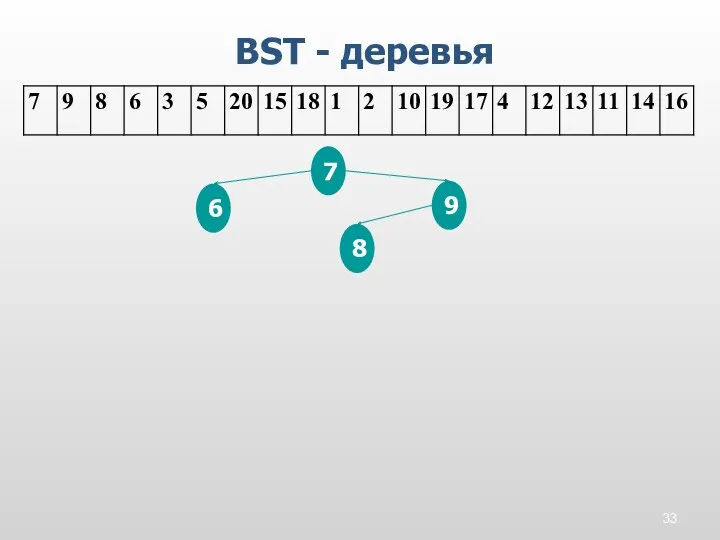
BST - деревья
7
9
8
6
BST - деревья
7
9
8
6
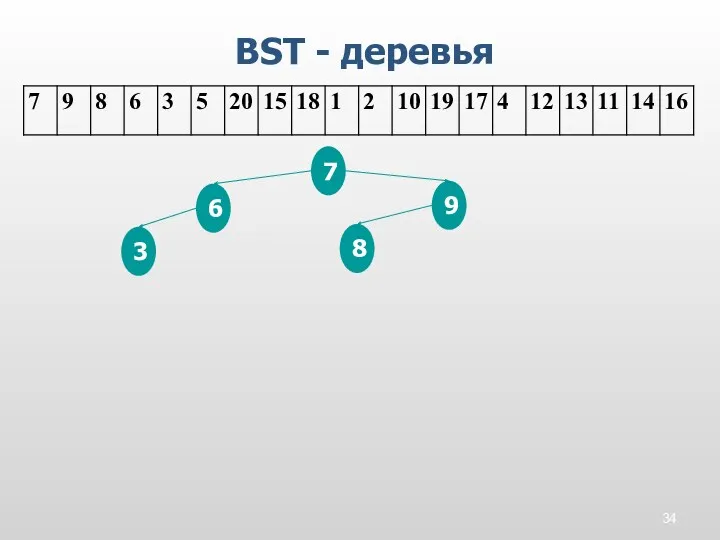
BST - деревья
7
9
8
6
3
BST - деревья
7
9
8
6
3
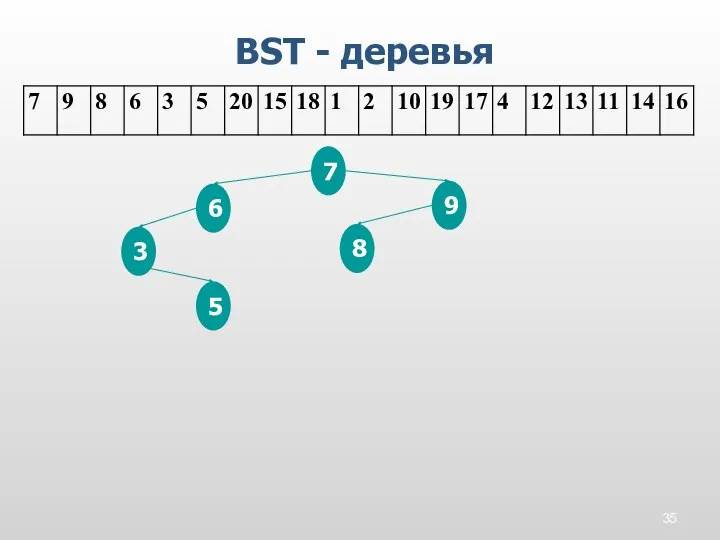
BST - деревья
7
9
8
6
3
5
BST - деревья
7
9
8
6
3
5
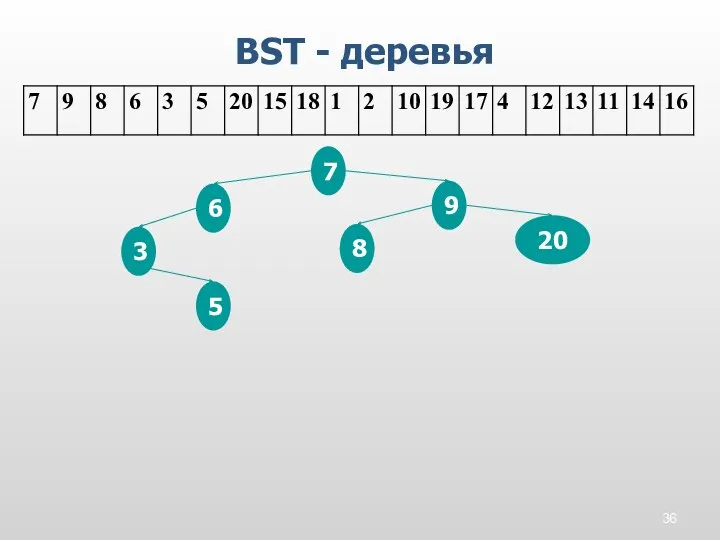
BST - деревья
7
9
8
6
3
5
20
BST - деревья
7
9
8
6
3
5
20
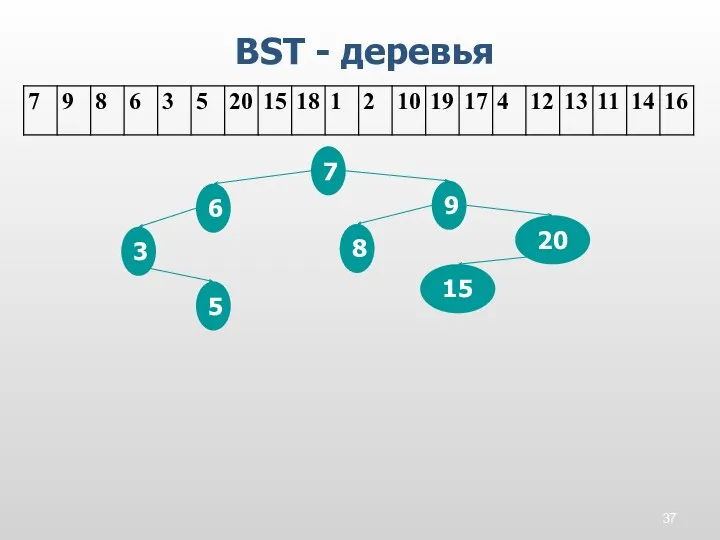
BST - деревья
7
9
8
6
3
5
20
15
BST - деревья
7
9
8
6
3
5
20
15
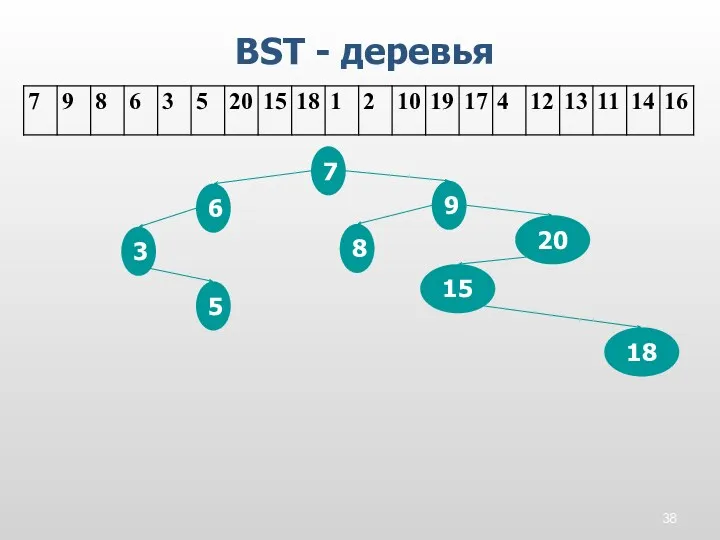
BST - деревья
7
9
8
6
3
5
20
15
18
BST - деревья
7
9
8
6
3
5
20
15
18
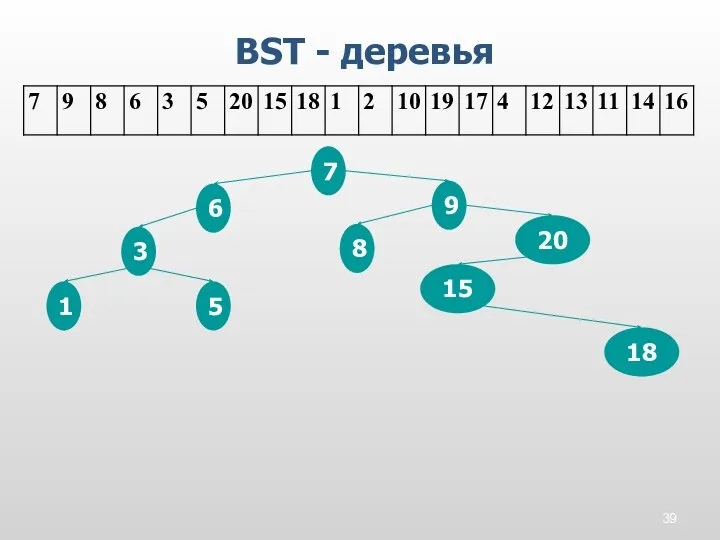
BST - деревья
7
9
8
6
3
5
20
15
18
1
BST - деревья
7
9
8
6
3
5
20
15
18
1
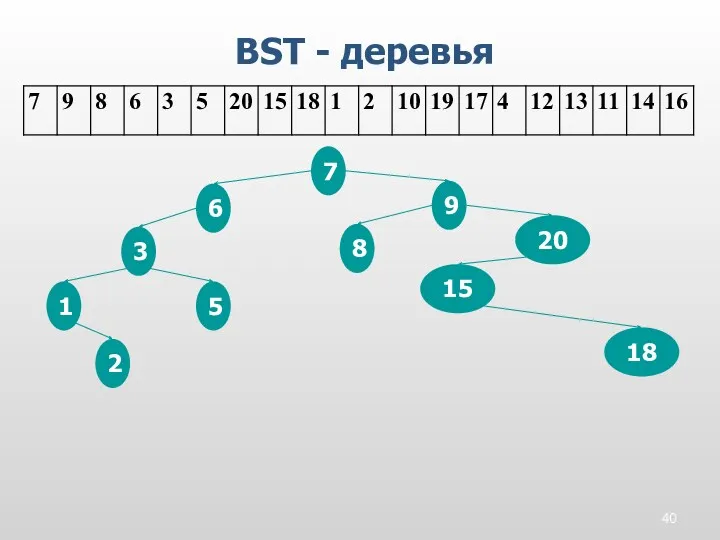
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
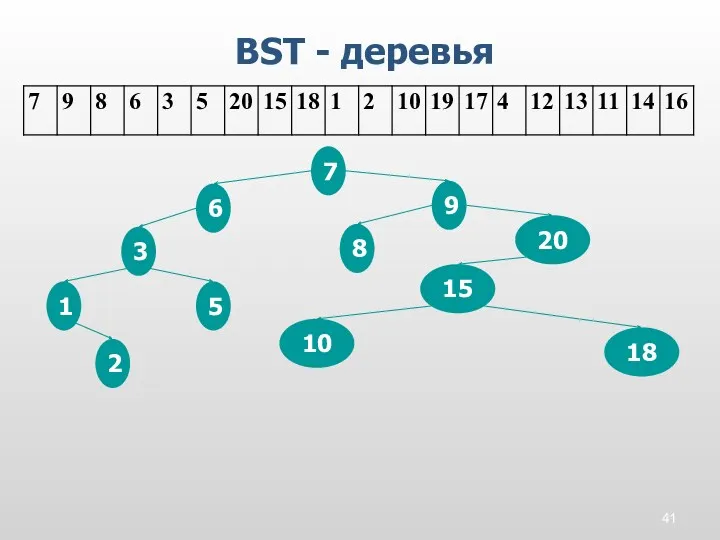
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
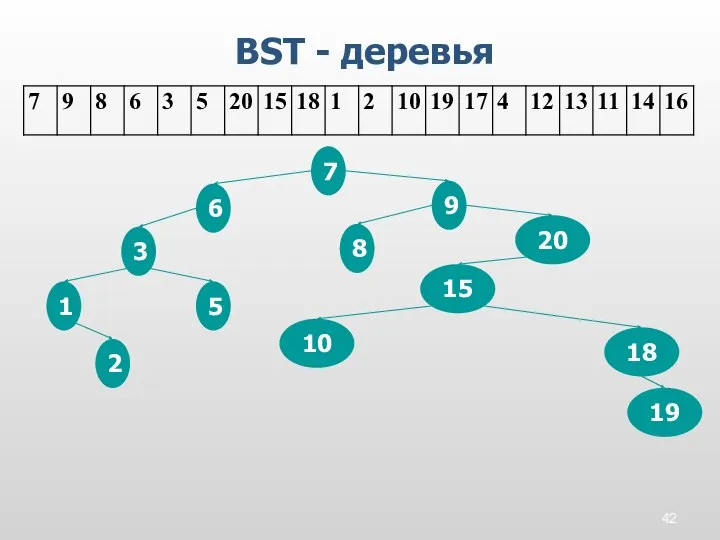
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
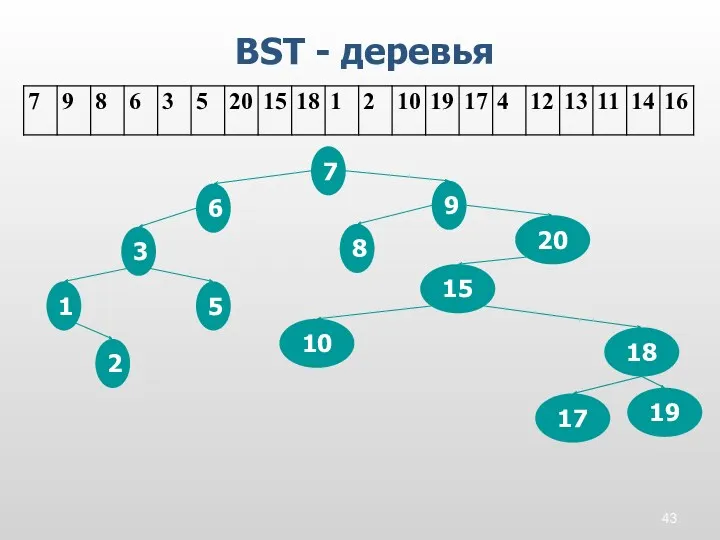
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
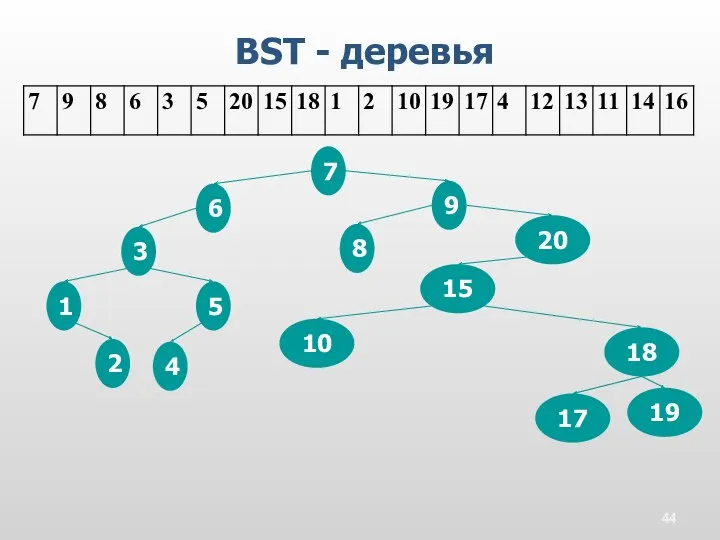
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
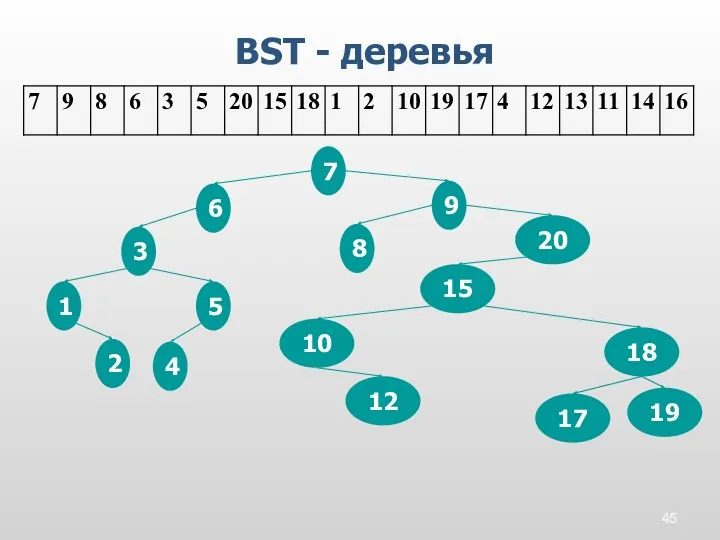
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
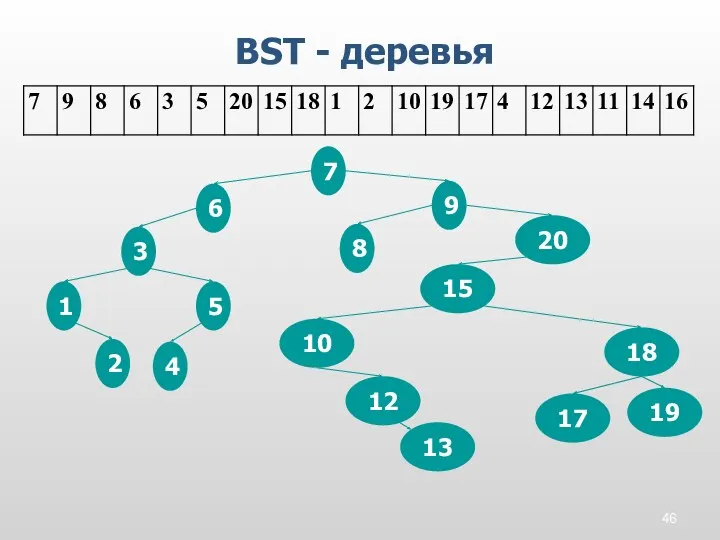
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
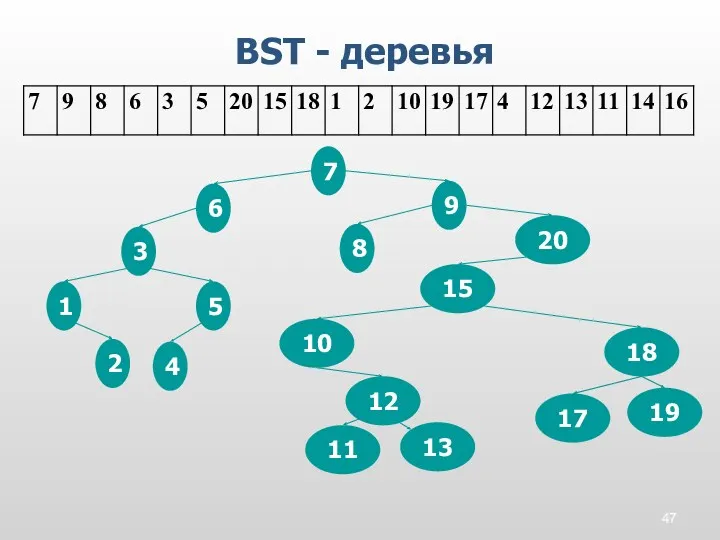
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
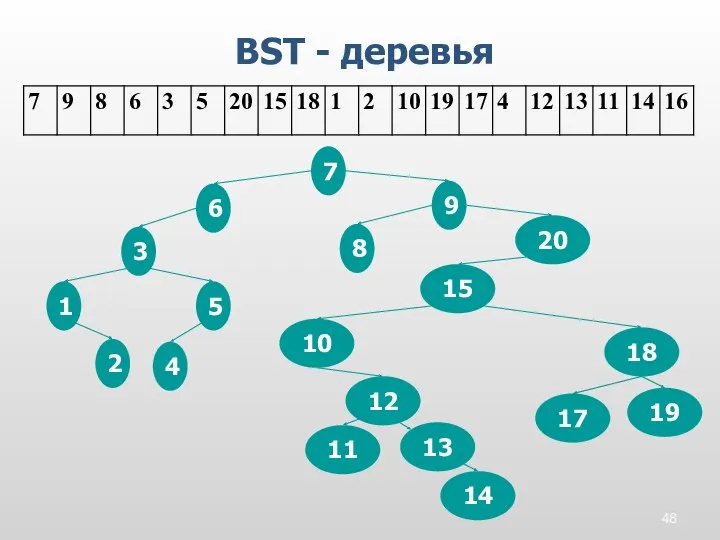
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
14
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
14
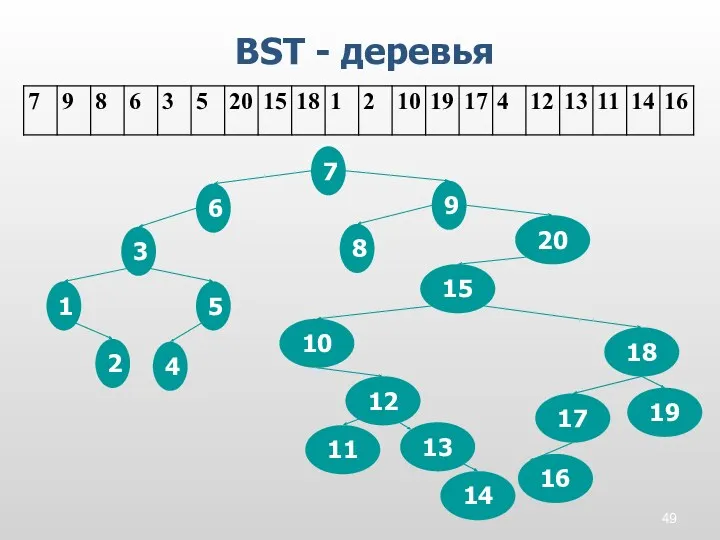
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
14
16
BST - деревья
7
9
8
6
3
5
20
15
18
1
2
10
19
17
4
12
13
11
14
16

Деревья бинарного поиска можно определить таким образом чтобы индексы строились в
Деревья бинарного поиска можно определить таким образом чтобы индексы строились в
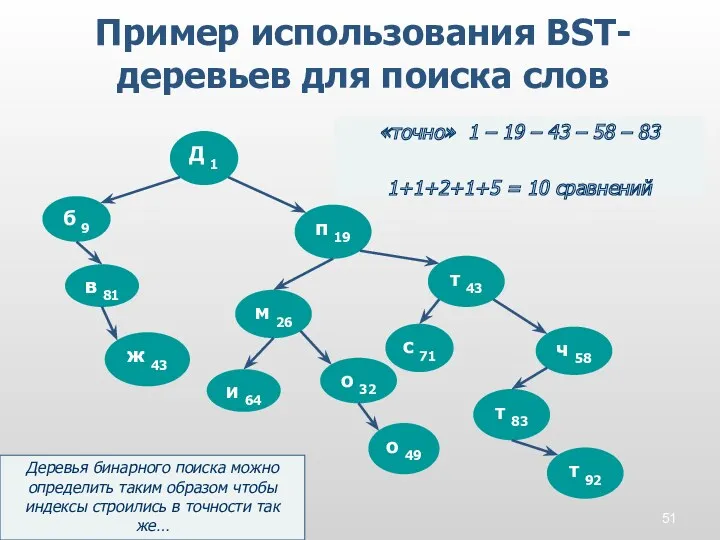
Пример использования BST-деревьев для поиска слов
Д 1
Деревья бинарного поиска можно определить
Пример использования BST-деревьев для поиска слов
Д 1
Деревья бинарного поиска можно определить

BST – деревья. Алгоритм вставки элемента
Вставка (Node ** Root, int key)
BST – деревья. Алгоритм вставки элемента
Вставка (Node ** Root, int key)

BST – деревья. Алгоритм вставки элемента
иначе
Если key >= *Root->data то
BST – деревья. Алгоритм вставки элемента
иначе
Если key >= *Root->data то

Вставка1 (Node ** Root, int key)
Если *Root – пустой то выделить
Вставка1 (Node ** Root, int key)
Если *Root – пустой то выделить

Node *temp = *Root;
Пока (temp не пуст) нц
Если (key>=temp->data) то
Node *temp = *Root;
Пока (temp не пуст) нц
Если (key>=temp->data) то
 Интеллектуальная игра Хакеры
Интеллектуальная игра Хакеры 3 класс Обработка информации
3 класс Обработка информации 1С-Коннект. Технология продажи и подключения сервиса
1С-Коннект. Технология продажи и подключения сервиса Ассистенты или чат - боты
Ассистенты или чат - боты Волоконно-оптические линии связи
Волоконно-оптические линии связи Представление числовой информации с помощью систем счисления
Представление числовой информации с помощью систем счисления Второй уровень информационного взаимодействия. Вторичные информационные процессы
Второй уровень информационного взаимодействия. Вторичные информационные процессы Робота в середовищі графічного редактора: змінювання зображень з використання функцій обертання, зміна кольору фігур та кольору
Робота в середовищі графічного редактора: змінювання зображень з використання функцій обертання, зміна кольору фігур та кольору Введение в JavaScript. Лекция 16
Введение в JavaScript. Лекция 16 Обработка текстовой информации
Обработка текстовой информации Системы контроля версий
Системы контроля версий Протокол HTTP - это протокол запроса-ответа
Протокол HTTP - это протокол запроса-ответа Учет затрат и расчет себестоимости для МСФО
Учет затрат и расчет себестоимости для МСФО Проектирование ИС
Проектирование ИС Устройство компьютера
Устройство компьютера Тестирование удобства использования
Тестирование удобства использования IMD Vista Industrial Measurement Devices
IMD Vista Industrial Measurement Devices 20231109_tablichnyy_sposob_resh._logich._zadach
20231109_tablichnyy_sposob_resh._logich._zadach Крипке құрылымы әсер ететін жүйелердің моделі ретінде
Крипке құрылымы әсер ететін жүйелердің моделі ретінде Дизайн компьютерных игр и анимационных фильмов с точки зрения их визуального воздействия на человека
Дизайн компьютерных игр и анимационных фильмов с точки зрения их визуального воздействия на человека Архитектура ЭВМ и вычислительных систем
Архитектура ЭВМ и вычислительных систем Инструкция по электронной записи в Муниципальное учреждение Спортивная школа Виктория
Инструкция по электронной записи в Муниципальное учреждение Спортивная школа Виктория Web Technology
Web Technology Интернет-технологии в социальной работе
Интернет-технологии в социальной работе Разработка интеграционного модуля выгрузки данных о продажах фотосепараторов на корпоративный сайт ООО Сисорт
Разработка интеграционного модуля выгрузки данных о продажах фотосепараторов на корпоративный сайт ООО Сисорт Зустріч лідерів
Зустріч лідерів Операторы ввода, вывода в языке Си
Операторы ввода, вывода в языке Си Основы программирования на языке Java
Основы программирования на языке Java