- Архитектура IA-32. Формат команды IA-32

Содержание
- 2. Формат команды IA-32. Типы префиксов: командные префиксы (префиксы повторения) REP, REPE/REPZ, REPNE/REPNZ; префикс блокировки шины LOCK;
- 3. Новая архитектура - новые возможности при указании адреса для операнда в памяти. Как процессор будет считать
- 4. Для получения операнда из памяти процессору необходимо знать: селектор сегмента, смещение в сегменте. В некоторых командах
- 5. Функциональная классификация машинных команд. Группы внутри всего набора машинных команд: команды общего назначения, исполняемые целочисленным устройством,
- 6. Исключения составляют следующие команды: Цепочечные — могут перемещать данные из памяти в память Работа со стеком
- 7. 6) операнд — порт ввода/вывода Примеры: in al, 48h ; взять байт из порта 48h mov
- 8. Абсолютная прямая адресация: Эффективный адрес операнда формируется из поля смещения команды. mov eax, DWORD PTR [0h]
- 9. Косвенная индексная адресация со смещением: Предназначена для доступа к данным с известным смещением относительно базового адреса,
- 10. ММХ-технология В основе технологии ММХ лежит расширение набора команд (57 новых команд) для эффективного выполнения типичных
- 11. Большинство SPFP-команд имеют два операнда. Данные, содержащиеся в первом операнде, после выполнения команды, как правило, замещаются
- 12. Кроме ХММ-регистров в микропроцессоре Pentium III появился новый регистр состояния и управления MXCSR. Для работы с
- 13. Расширение SSE3, включает 5 новых операций с комплексными числами, 5 потоковых операций над числами с плавающей
- 15. Скачать презентацию

Формат команды IA-32.
Типы префиксов:
командные префиксы (префиксы повторения) REP, REPE/REPZ, REPNE/REPNZ;
префикс блокировки шины
Формат команды IA-32.
Типы префиксов:
командные префиксы (префиксы повторения) REP, REPE/REPZ, REPNE/REPNZ;
префикс блокировки шины

Новая архитектура - новые возможности при указании адреса для операнда в памяти.
Как процессор
Новая архитектура - новые возможности при указании адреса для операнда в памяти.
Как процессор

Для получения операнда из памяти процессору необходимо знать:
селектор сегмента,
смещение в сегменте.
В
Для получения операнда из памяти процессору необходимо знать:
селектор сегмента,
смещение в сегменте.
В
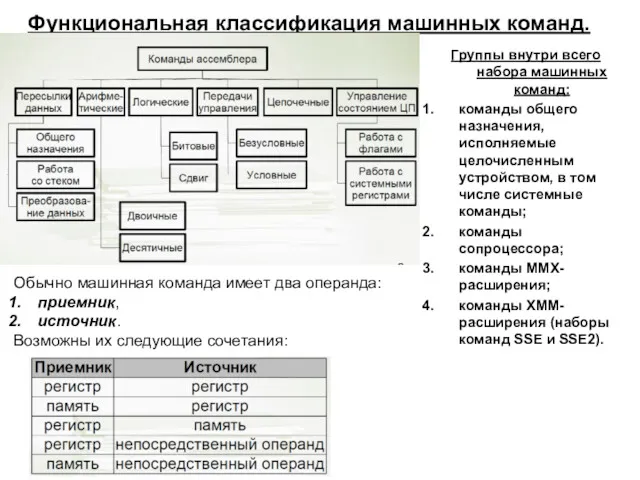
Функциональная классификация машинных команд.
Группы внутри всего набора машинных команд:
команды общего назначения,
Функциональная классификация машинных команд.
Группы внутри всего набора машинных команд:
команды общего назначения,

Исключения составляют следующие команды:
Цепочечные — могут перемещать данные из памяти в
Исключения составляют следующие команды:
Цепочечные — могут перемещать данные из памяти в

6) операнд — порт ввода/вывода
Примеры:
in al, 48h ; взять байт из
6) операнд — порт ввода/вывода
Примеры:
in al, 48h ; взять байт из

Абсолютная прямая адресация:
Эффективный адрес операнда формируется из поля смещения команды.
mov eax,
Абсолютная прямая адресация:
Эффективный адрес операнда формируется из поля смещения команды.
mov eax,

Косвенная индексная адресация со смещением:
Предназначена для доступа к данным с известным
Косвенная индексная адресация со смещением:
Предназначена для доступа к данным с известным

ММХ-технология
В основе технологии ММХ лежит расширение набора команд (57 новых команд) для
ММХ-технология
В основе технологии ММХ лежит расширение набора команд (57 новых команд) для

Большинство SPFP-команд имеют два операнда. Данные, содержащиеся в первом операнде, после
Большинство SPFP-команд имеют два операнда. Данные, содержащиеся в первом операнде, после

Кроме ХММ-регистров в микропроцессоре Pentium III появился новый регистр состояния и
Кроме ХММ-регистров в микропроцессоре Pentium III появился новый регистр состояния и

Расширение SSE3, включает 5 новых операций с комплексными числами, 5 потоковых
Расширение SSE3, включает 5 новых операций с комплексными числами, 5 потоковых
 Лекція 8. База даних Access
Лекція 8. База даних Access Автоматизированная система Музей-3
Автоматизированная система Музей-3 Информационные системы
Информационные системы Ошибки в безопасности. SQL Injection
Ошибки в безопасности. SQL Injection Структура курсового проекта
Структура курсового проекта Практикум: создание простого интерактивного приложения
Практикум: создание простого интерактивного приложения Telegram бот с информацией о погоде
Telegram бот с информацией о погоде Библиографическое оформление рефератов, курсовых, дипломных работ, диссертаций
Библиографическое оформление рефератов, курсовых, дипломных работ, диссертаций Лекция 2. Основы компьютерных сетей. Назначение и структура
Лекция 2. Основы компьютерных сетей. Назначение и структура Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации
Примеры применения пакета STATISTICA 5.5 для статистического анализа медицинской информации Интернет. Правила безопасности в сети Интернет
Интернет. Правила безопасности в сети Интернет Flight controls
Flight controls Форматирование символов. MS WORD 1
Форматирование символов. MS WORD 1 1C-Администратор. Новый сервис для продвинутых пользователей
1C-Администратор. Новый сервис для продвинутых пользователей Электронно-библиотечные системы (ЭБС)
Электронно-библиотечные системы (ЭБС) Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Второй уровень информационного взаимодействия. Вторичные информационные процессы
Второй уровень информационного взаимодействия. Вторичные информационные процессы Настройка контекстной рекламы Яндекс Директ
Настройка контекстной рекламы Яндекс Директ Информационная глобальная компьютерная сеть интернет. (Лекция 3)
Информационная глобальная компьютерная сеть интернет. (Лекция 3) Право и этика в интернете
Право и этика в интернете Высокопроизводительные вычисления
Высокопроизводительные вычисления Складання алгоритмів
Складання алгоритмів Управление эксплуатацией вооружения и военной техники Космических войск. Лекция №02
Управление эксплуатацией вооружения и военной техники Космических войск. Лекция №02 ПРЕЗЕНТАЦИЯ
ПРЕЗЕНТАЦИЯ Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (Аккумуляторная)
Расчетные методики ПП ЭкоСфера-предприятие. Расчет выбросов от автотранспорта (Аккумуляторная) 3D-Blender
3D-Blender Кластерлер сипаттамасы
Кластерлер сипаттамасы Интернет безопасность
Интернет безопасность