- Алгоритмы поиска. Лекция 12

Содержание
- 2. План лекции Поиск в массивах и списках Линейный поиск Бинарный поиск Поиск подстроки Наивный поиск подстроки
- 3. Поиск в массивах и списках Значения элементов массива (списка) делятся на ключ и произвольные данные struct
- 4. Последовательный просмотр ячеек Останов, если найден нужный ключ или кончились ячейки Число сравнений в худшем случае
- 5. place_t linear_search (list_t L, K key) { place_t p; for (p = begin(L); p != end();
- 6. Бинарный поиск в упорядоченном массиве На каждом шаге делим массив пополам и на следующем шаге продолжаем
- 7. Бинарный поиск в упорядоченном массиве int binary_search(const struct KeyData A[], int N, K key) { int
- 8. 4 10 17 19 20 28 25 2 33 45 40 42 39 35 46 64
- 9. План лекции Поиск в массивах и списках Линейный поиск Бинарный поиск Поиск подстроки Наивный поиск подстроки
- 10. abcdaaccbbssacbaszzzaaa cbbss s q Поиск подстроки Даны строка s из N элементов (текст) и строка q
- 11. Наивный (прямой) поиск подстроки Шаг 1 «Прикладываем» левый край образца к левому краю текста, К =
- 12. Прямой поиск подстроки int naive_substring_search( const char s[], int N, const char q[], int M) {
- 13. Алгоритм Рабина-Карпа Майкл Рабин р. 1932 Ричард Карп р. 1935 Karp, Richard M. Rabin, Michael O.
- 14. Алгоритм Рабина-Карпа Быстрый поиск нескольких образцов в одном тексте Уменьшение числа сравнений в наивном поиске подстроки
- 15. Алгоритм Рабина-Карпа Шаг 1 Прикладываем левый край образца к левому краю текста, К = 0 Вычисляем
- 16. Алгоритм Рабина-Карпа int rk_substring_search( const char s[], int N, const char q[], int M) { int
- 17. Простая хэш-функция // hs = s[0]+s[1]+…+s[M-1] // чем плоха такая хэш-функция? int rk_hash(const char s[], int
- 18. Улучшенная хэш-функция static const int rk_hash_p = "хорошее" простое число; static const int rk_hash_n = 256;
- 19. Анализ алгоритма Рабина-Карпа Число сравнений зависит от сочетания хэш-функции, текста и образца В худшем случае О((N
- 20. Алгоритм Бойера—Мура Robert Stephen Boyer Роберт Стивен Бойер р. ? J Strother Moore Джей Стротер Мур
- 21. Алгоритм Бойера—Мура Улучшение наивного поиска Сравнение текста и образца, начиная с q[М – 1] и s[k
- 22. Алгоритм Бойера-Мура со сдвигом по стоп-символам Шаг 1 Прикладываем левый край образца к левому краю текста,
- 23. Алгоритм Бойера-Мура без сдвига по суффиксам int bm_substring_search( const char s[], int N, const char q[],
- 24. Заполнение таблицы сдвигов по стоп-символам Для каждого символа x из образца Если q[M-1] != х (не
- 25. Пример заполнения таблицы сдвигов по стоп-символам Для образца q=“аbсаbеаbсе” (М = 10) d['a'] = 3 d['b']
- 26. а friend in need is a friend indeed indeed М = 6 d['i'] = 5 d['n']
- 27. Анализ алгоритма Бойера-Мура В лучшем случае O(N/M) сравнений Если последний символ образца всегда попадает на символ
- 28. Алгоритм Кнута-Морриса- Пратта Donald Knuth Дональд Кнут р. 1938 Воган Пратт р. 1944 Джеймс Моррис р.
- 29. Алгоритм Кнута-Морриса-Пратта Улучшение наивного поиска Каждый символ текста участвует в сравнении Сдвиг выбирается с учётом того,
- 30. Алгоритм Кнута-Морриса-Пратта На сколько позиций можно сдвинуть q относительно s, не пропустив вхождений q в s,
- 31. Префикс-функция КМП Префикс-функция prefix(q, j) строки q prefix(q,j) = max { x | q[0..x] = q[j-x..j],
- 32. Префикс-функция КМП Пример 1 j 0 1 2 3 4 5 6 q[j] a b a
- 33. Алгоритм Кнута-Морриса-Пратта Шаг 1 Прикладываем левый край образца к левому краю окна просмотра, К = 0,
- 34. Алгоритм Кнута-Морриса-Пратта int kmp_substring_search( const char s[], int N, const char q[], int M) { int
- 35. Алгоритм Кнута-Морриса-Пратта В худшем случае О(N) сравнений без учета построения префикс-функции Почему каждый символ текста участвует
- 36. Заключение Поиск в массивах и списках Линейный поиск списки, массивы, линейная сложность Бинарный поиск упорядоч. массивы,
- 37. При первом входе в цикл индексы указывают на начала строк и Eq(i,j) = Eq(1, 1), очевидно,
- 38. При несовпадении очередных символов надо сдвинуть образец так, чтобы некоторый dj-префикс q продолжал совпадать с dj-суффиксом
- 39. До сдвига pref (q, j–1) совпадает с suff (pref (s ,i—1), dj — 1). Чтобы сдвиг
- 40. Добавив теперь условие максимальности длины префикса dj, выразим зависимость dj от j cледующей префикс-функцией: d [j]
- 41. Выбором подходящего dj, с учетом всего сказанного, занимается внутренний цикл КМП-алгоритма. Ниже приведены значения префикс-функции и
- 42. - Eq(i,j): j = 6,d[j] = 4 pref(q,3) = suff(pref(s,i-1),3) d-1 = 3 – длина совпадения
- 43. Допустим, что для всех позиций k образеца, предшествующих и включая i, d[k] уже вычислены и d[i]
- 44. int seek_substring_KMP (char s[], char q[]){ int i, j, N, M; N = strlen(s); M =
- 45. Алгоритм Рабина -- Карпа поиска подстроки Майкл Рабин, Ричард Карп 1987 Уменьшение числа сравнений в наивном
- 46. По схеме Горнера значения tq и t1 можно вычислить за время, пропорциональное М Временно забудем о
- 47. Чтобы получить t[k+1] из t[k], надо удалить последнее слагаемое из формулы (10) ( т. е. вычесть
- 48. Вычислив все tk, мы можем по очереди сравнить их с tq, определив тем самым совпадение или
- 49. Рекуррентная формула (11) приобретает вид: где . Из равенства tq ≡ tk(mod p) еще не следует,
- 50. Алгоритм А5: • вход: q - образец, s - строка, М - длина образеца, N -
- 51. int Robin_Carp_Matcher(char s[], char q[], int d, int p) { int i, h, k, M, N,
- 52. вхождение образца холостое срабатывание … … … (б) mod 13 Цифра старшего разряда Цифра младшего разряда
- 53. Реализация алгоритма Бойера-Мура int seek_substring_BM(unsigned char s[], unsigned char q[]) { int d[256]; int i, j,
- 54. Алгоритм Бойера-Мура Будем последовательно сравнивать образец q с подстроками s[i – М + 1..i] (в начале
- 55. Здесь j = 6 символов строки, следующих за позицией k, уже известны, поэтому можно, не выполняя
- 56. КМП-алгоритм (Кнут, Моррис, Пратт) Алгоритм А4: • вход: q - образец, s - строка, М -
- 57. Индекс-указатель i пробегает строку s без возвратов (что обеспечивает линейность времени работы алгоритма). Индекс j синхронно
- 59. Скачать презентацию

План лекции
Поиск в массивах и списках
Линейный поиск
Бинарный поиск
Поиск подстроки
Наивный поиск подстроки
Алгоритм
План лекции
Поиск в массивах и списках
Линейный поиск
Бинарный поиск
Поиск подстроки
Наивный поиск подстроки
Алгоритм

Поиск в массивах и списках
Значения элементов массива (списка) делятся на ключ
Поиск в массивах и списках
Значения элементов массива (списка) делятся на ключ

Последовательный просмотр ячеек
Останов, если найден нужный ключ или кончились ячейки
Число сравнений
Последовательный просмотр ячеек
Останов, если найден нужный ключ или кончились ячейки
Число сравнений

place_t linear_search (list_t L, K key)
{
place_t p;
for (p = begin(L); p
place_t linear_search (list_t L, K key) { place_t p; for (p = begin(L); p

Бинарный поиск в упорядоченном массиве
На каждом шаге делим массив пополам
Бинарный поиск в упорядоченном массиве
На каждом шаге делим массив пополам
![Бинарный поиск в упорядоченном массиве int binary_search(const struct KeyData A[],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-6.jpg)
Бинарный поиск в упорядоченном массиве
int binary_search(const struct KeyData A[], int N,
Бинарный поиск в упорядоченном массиве
int binary_search(const struct KeyData A[], int N,

4
10
17
19
20
28
25
2
33
45
40
42
39
35
46
64
71
77
85
89
99
X = 33
[
]
0 1 2 3 4 5 6 7
4
10
17
19
20
28
25
2
33
45
40
42
39
35
46
64
71
77
85
89
99
X = 33
[
]
0 1 2 3 4 5 6 7

План лекции
Поиск в массивах и списках
Линейный поиск
Бинарный поиск
Поиск подстроки
Наивный поиск подстроки
Алгоритм
План лекции
Поиск в массивах и списках
Линейный поиск
Бинарный поиск
Поиск подстроки
Наивный поиск подстроки
Алгоритм

abcdaaccbbssacbaszzzaaa
cbbss
s
q
Поиск подстроки
Даны строка s из N элементов (текст) и строка
abcdaaccbbssacbaszzzaaa
cbbss
s
q
Поиск подстроки
Даны строка s из N элементов (текст) и строка

Наивный (прямой) поиск подстроки
Шаг 1
«Прикладываем» левый край образца к левому краю
Наивный (прямой) поиск подстроки
Шаг 1
«Прикладываем» левый край образца к левому краю
![Прямой поиск подстроки int naive_substring_search( const char s[], int N,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-11.jpg)
Прямой поиск подстроки
int naive_substring_search(
const char s[], int N, const char
Прямой поиск подстроки
int naive_substring_search(
const char s[], int N, const char

Алгоритм Рабина-Карпа
Майкл Рабин р. 1932
Ричард Карп р. 1935
Karp, Richard M.
Rabin, Michael
Алгоритм Рабина-Карпа
Майкл Рабин р. 1932
Ричард Карп р. 1935
Karp, Richard M.
Rabin, Michael

Алгоритм Рабина-Карпа
Быстрый поиск нескольких образцов в одном тексте
Уменьшение числа сравнений в
Алгоритм Рабина-Карпа
Быстрый поиск нескольких образцов в одном тексте
Уменьшение числа сравнений в

Алгоритм Рабина-Карпа
Шаг 1
Прикладываем левый край образца к левому краю текста, К
Алгоритм Рабина-Карпа
Шаг 1
Прикладываем левый край образца к левому краю текста, К
![Алгоритм Рабина-Карпа int rk_substring_search( const char s[], int N, const](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-15.jpg)
Алгоритм Рабина-Карпа
int rk_substring_search(
const char s[], int N, const char q[], int
Алгоритм Рабина-Карпа
int rk_substring_search(
const char s[], int N, const char q[], int
![Простая хэш-функция // hs = s[0]+s[1]+…+s[M-1] // чем плоха такая](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-16.jpg)
Простая хэш-функция
// hs = s[0]+s[1]+…+s[M-1]
// чем плоха такая хэш-функция?
int rk_hash(const char
Простая хэш-функция
// hs = s[0]+s[1]+…+s[M-1]
// чем плоха такая хэш-функция?
int rk_hash(const char

Улучшенная хэш-функция
static const int rk_hash_p = "хорошее" простое число;
static const int
Улучшенная хэш-функция
static const int rk_hash_p = "хорошее" простое число;
static const int

Анализ алгоритма Рабина-Карпа
Число сравнений зависит от сочетания хэш-функции, текста и образца
В
Анализ алгоритма Рабина-Карпа
Число сравнений зависит от сочетания хэш-функции, текста и образца
В

Алгоритм Бойера—Мура
Robert Stephen Boyer Роберт Стивен Бойер
р. ?
J Strother Moore
Алгоритм Бойера—Мура
Robert Stephen Boyer Роберт Стивен Бойер
р. ?
J Strother Moore

Алгоритм Бойера—Мура
Улучшение наивного поиска
Сравнение текста и образца, начиная с q[М
Алгоритм Бойера—Мура
Улучшение наивного поиска
Сравнение текста и образца, начиная с q[М

Алгоритм Бойера-Мура со сдвигом по стоп-символам
Шаг 1
Прикладываем левый край образца к
Алгоритм Бойера-Мура со сдвигом по стоп-символам
Шаг 1
Прикладываем левый край образца к

Алгоритм Бойера-Мура без сдвига по суффиксам
int bm_substring_search(
const char s[], int N,
Алгоритм Бойера-Мура без сдвига по суффиксам
int bm_substring_search(
const char s[], int N,

Заполнение таблицы сдвигов по стоп-символам
Для каждого символа x из образца
Если q[M-1]
Заполнение таблицы сдвигов по стоп-символам
Для каждого символа x из образца
Если q[M-1]

Пример заполнения таблицы сдвигов по стоп-символам
Для образца q=“аbсаbеаbсе” (М = 10)
Пример заполнения таблицы сдвигов по стоп-символам
Для образца q=“аbсаbеаbсе” (М = 10)

а friend in need is a friend indeed
indeed
М = 6
d['i'] =
а friend in need is a friend indeed
indeed
М = 6
d['i'] =

Анализ алгоритма Бойера-Мура
В лучшем случае O(N/M) сравнений
Если последний символ образца всегда
Анализ алгоритма Бойера-Мура
В лучшем случае O(N/M) сравнений
Если последний символ образца всегда

Алгоритм Кнута-Морриса-
Пратта
Donald Knuth Дональд Кнут р. 1938
Воган Пратт р. 1944
Джеймс
Алгоритм Кнута-Морриса-
Пратта
Donald Knuth Дональд Кнут р. 1938
Воган Пратт р. 1944
Джеймс

Алгоритм Кнута-Морриса-Пратта
Улучшение наивного поиска
Каждый символ текста участвует в сравнении <=
Алгоритм Кнута-Морриса-Пратта
Улучшение наивного поиска
Каждый символ текста участвует в сравнении <=

Алгоритм Кнута-Морриса-Пратта
На сколько позиций можно сдвинуть q относительно s, не
Алгоритм Кнута-Морриса-Пратта
На сколько позиций можно сдвинуть q относительно s, не

Префикс-функция КМП
Префикс-функция prefix(q, j) строки q
prefix(q,j) = max { x |
Префикс-функция КМП
Префикс-функция prefix(q, j) строки q prefix(q,j) = max { x |

Префикс-функция КМП
Пример 1
j 0 1 2 3 4 5 6
q[j] a b a
Префикс-функция КМП
Пример 1
j 0 1 2 3 4 5 6
q[j] a b a

Алгоритм Кнута-Морриса-Пратта
Шаг 1
Прикладываем левый край образца к левому краю окна просмотра,
Алгоритм Кнута-Морриса-Пратта
Шаг 1
Прикладываем левый край образца к левому краю окна просмотра,
![Алгоритм Кнута-Морриса-Пратта int kmp_substring_search( const char s[], int N, const](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-33.jpg)
Алгоритм Кнута-Морриса-Пратта
int kmp_substring_search(
const char s[], int N, const char q[], int
Алгоритм Кнута-Морриса-Пратта
int kmp_substring_search(
const char s[], int N, const char q[], int

Алгоритм Кнута-Морриса-Пратта
В худшем случае О(N) сравнений без учета построения префикс-функции
Почему каждый
Алгоритм Кнута-Морриса-Пратта
В худшем случае О(N) сравнений без учета построения префикс-функции
Почему каждый

Заключение
Поиск в массивах и списках
Линейный поиск
списки, массивы, линейная сложность
Бинарный поиск
упорядоч. массивы,
Заключение
Поиск в массивах и списках
Линейный поиск
списки, массивы, линейная сложность
Бинарный поиск
упорядоч. массивы,

При первом входе в цикл индексы указывают на начала строк и
При первом входе в цикл индексы указывают на начала строк и

При несовпадении очередных символов надо сдвинуть образец так, чтобы некоторый dj-префикс
При несовпадении очередных символов надо сдвинуть образец так, чтобы некоторый dj-префикс

До сдвига pref (q, j–1) совпадает с suff (pref (s ,i—1),
До сдвига pref (q, j–1) совпадает с suff (pref (s ,i—1),

Добавив теперь условие максимальности длины префикса dj,
выразим зависимость dj от j
Добавив теперь условие максимальности длины префикса dj,
выразим зависимость dj от j

Выбором подходящего dj, с учетом всего сказанного,
занимается внутренний цикл КМП-алгоритма.
Ниже
Выбором подходящего dj, с учетом всего сказанного,
занимается внутренний цикл КМП-алгоритма.
Ниже
![- Eq(i,j): j = 6,d[j] = 4 pref(q,3) = suff(pref(s,i-1),3)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-41.jpg)
- Eq(i,j): j = 6,d[j] = 4
pref(q,3) = suff(pref(s,i-1),3)
d-1 =
- Eq(i,j): j = 6,d[j] = 4
pref(q,3) = suff(pref(s,i-1),3)
d-1 =

Допустим, что для всех позиций k образеца, предшествующих и включая i,
Допустим, что для всех позиций k образеца, предшествующих и включая i,
![int seek_substring_KMP (char s[], char q[]){ int i, j, N,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-43.jpg)
int seek_substring_KMP (char s[], char q[]){
int i, j, N, M;
int seek_substring_KMP (char s[], char q[]){
int i, j, N, M;

Алгоритм Рабина -- Карпа поиска подстроки
Майкл Рабин, Ричард Карп 1987
Уменьшение
Алгоритм Рабина -- Карпа поиска подстроки
Майкл Рабин, Ричард Карп 1987
Уменьшение

По схеме Горнера значения tq и t1 можно вычислить за время,
По схеме Горнера значения tq и t1 можно вычислить за время,
![Чтобы получить t[k+1] из t[k], надо удалить последнее слагаемое из](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-46.jpg)
Чтобы получить t[k+1] из t[k], надо удалить последнее слагаемое из формулы
Чтобы получить t[k+1] из t[k], надо удалить последнее слагаемое из формулы

Вычислив все tk, мы можем по очереди сравнить их с tq,
Вычислив все tk, мы можем по очереди сравнить их с tq,

Рекуррентная формула (11) приобретает вид:
где .
Из равенства tq ≡ tk(mod p)
Рекуррентная формула (11) приобретает вид:
где .
Из равенства tq ≡ tk(mod p)

Алгоритм А5:
• вход: q - образец, s - строка, М -
Алгоритм А5:
• вход: q - образец, s - строка, М -
![int Robin_Carp_Matcher(char s[], char q[], int d, int p) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-50.jpg)
int Robin_Carp_Matcher(char s[], char q[], int d, int p) {
int Robin_Carp_Matcher(char s[], char q[], int d, int p) {
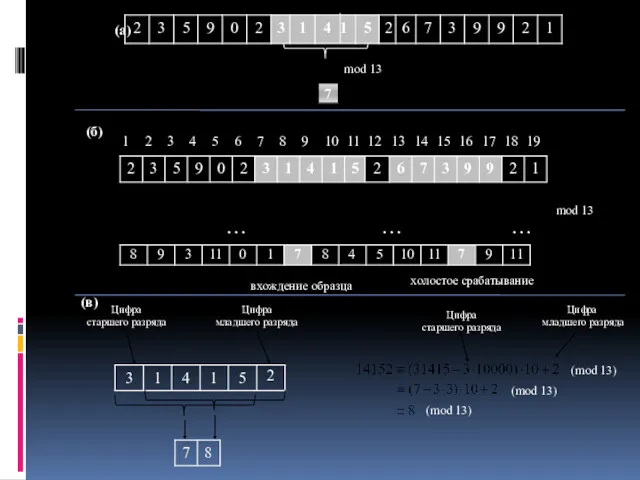
вхождение образца
холостое срабатывание
…
…
…
(б)
mod 13
Цифра
старшего разряда
Цифра
младшего разряда
(в)
(mod 13)
(mod 13)
(mod 13)
Цифра
вхождение образца
холостое срабатывание
…
…
…
(б)
mod 13
Цифра
старшего разряда
Цифра
младшего разряда
(в)
(mod 13)
(mod 13)
(mod 13)
Цифра
![Реализация алгоритма Бойера-Мура int seek_substring_BM(unsigned char s[], unsigned char q[])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/133841/slide-52.jpg)
Реализация алгоритма Бойера-Мура
int seek_substring_BM(unsigned char s[], unsigned char q[])
{ int d[256];
int
Реализация алгоритма Бойера-Мура
int seek_substring_BM(unsigned char s[], unsigned char q[])
{ int d[256];
int

Алгоритм Бойера-Мура
Будем последовательно сравнивать образец q с подстроками
s[i – М
Алгоритм Бойера-Мура
Будем последовательно сравнивать образец q с подстроками
s[i – М

Здесь j = 6 символов строки, следующих за позицией k, уже
Здесь j = 6 символов строки, следующих за позицией k, уже

КМП-алгоритм
(Кнут, Моррис, Пратт)
Алгоритм А4:
• вход: q - образец, s
КМП-алгоритм
(Кнут, Моррис, Пратт)
Алгоритм А4:
• вход: q - образец, s

Индекс-указатель i пробегает строку s без возвратов
(что обеспечивает линейность
Индекс-указатель i пробегает строку s без возвратов
(что обеспечивает линейность
 Государственная система научно-технической информации
Государственная система научно-технической информации Управление освещением витрины
Управление освещением витрины Контент. SEO текст
Контент. SEO текст Anatomy Lesson for Middle School Internal Organs of the Human Body
Anatomy Lesson for Middle School Internal Organs of the Human Body Таблицы в HTML
Таблицы в HTML Помехоустойчивое кодирование в системах телекоммуникаций (ПКСТ)
Помехоустойчивое кодирование в системах телекоммуникаций (ПКСТ) Решение задания ОГЭ по информатике
Решение задания ОГЭ по информатике Программирование (Python). Введение
Программирование (Python). Введение Кодирование, как изменение формы представления информации
Кодирование, как изменение формы представления информации Понятие информация. Виды информации. Основные информационные процессы
Понятие информация. Виды информации. Основные информационные процессы использование игр на уроке информатики в начальной школе
использование игр на уроке информатики в начальной школе Представление числовой информации в таблицах. Повторение
Представление числовой информации в таблицах. Повторение Каналы. Неименованные каналы
Каналы. Неименованные каналы Файловая система и ввод вывод информации
Файловая система и ввод вывод информации Overview software development methodology Аgile.Вusiness approach
Overview software development methodology Аgile.Вusiness approach Решение задач на компьютере. Алгоритмизация и программирование. 9 класс
Решение задач на компьютере. Алгоритмизация и программирование. 9 класс Интервью (событийное) как жанр журналистики (лекция № 6)
Интервью (событийное) как жанр журналистики (лекция № 6) Программирование. Оператор Mod в Visual Basic
Программирование. Оператор Mod в Visual Basic Перевод чисел из 10СС в 2СС
Перевод чисел из 10СС в 2СС Python NumPy. Установка. Массивы
Python NumPy. Установка. Массивы Декодирование. Построение префиксного кода по набору длин элементарных кодов
Декодирование. Построение префиксного кода по набору длин элементарных кодов Язык программирования C++
Язык программирования C++ Способы передачи данных. (Тема 4)
Способы передачи данных. (Тема 4) Графический дизайн для непрофессионалов
Графический дизайн для непрофессионалов Сущность и значение комплектования государственных архивов. Технотронные документы
Сущность и значение комплектования государственных архивов. Технотронные документы Автоматизированная информационная система Молодежь России. Регистрация в АИС
Автоматизированная информационная система Молодежь России. Регистрация в АИС Персональные данные (для детей 9-11 лет)
Персональные данные (для детей 9-11 лет) Создание комплексной системы непрерывного информационного обеспечения для повышение производительности качества сельхозпродукции
Создание комплексной системы непрерывного информационного обеспечения для повышение производительности качества сельхозпродукции