- Big data: технологии добычи данных

Содержание
- 2. SFedU Цель исследования повышение эффективности прикладных систем добычи данных на основе развития моделей, методов и алгоритмов
- 3. www.sapr.favt.tsure.ru Объект и предмет исследования
- 4. Инфографика схемы роста объемов информации
- 5. Рост объемов данных
- 6. SFedU Векторная репрезентация слов
- 7. SFedU Векторная репрезентация слов
- 8. SFedU Семантический вектор запроса и текста
- 9. SFedU Постановка задачи семантического поиска
- 10. SFedU Постановка задачи классификации
- 11. SFedU Постановка задачи структуризации
- 12. SFedU Постановка задачи структуризации
- 13. SFedU Абстрактный пример структуризации
- 14. SFedU Постановка задачи интеграции
- 15. SFedU Путь исследования КТО? ГДЕ? ЧТО? КАК? Коалиции интеллектуальных агентов Онтологическая модель информационногопространства знаний Информационные модели
- 16. Модель переходов агента G = B – вершина начала функционирования агента; E – вершина конца функционирования
- 17. Имитационные модели прецедентов
- 18. Выполнение условий достижимости
- 19. Нарушение условий достижимости
- 20. Модели поведения
- 21. Модели поведения
- 22. Абстрактная модель среды поиска данных
- 23. SFedU Модель онтологии Онтология O представляет собой знаковую систему O = , где P – множество
- 24. Модель среды поиска данных 1) акторы (A) – фильтры знаний, представляющие активные элементы (агенты), создающие предметную
- 25. Модель фильтра данных семантического поиска Основными достоинствами предлагаемой модели являются: 1) поддержка семантического поиска релевантных знаний
- 26. Case-модель фильтра данных
- 27. Нечеткая модель структуризации содержательной части данных
- 29. Скачать презентацию

SFedU
Цель исследования
повышение эффективности прикладных систем добычи данных на основе развития моделей,
SFedU
Цель исследования
повышение эффективности прикладных систем добычи данных на основе развития моделей,
www.sapr.favt.tsure.ru
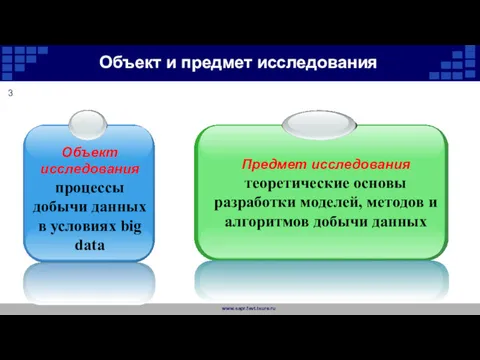
Объект и предмет исследования
www.sapr.favt.tsure.ru
Объект и предмет исследования
Инфографика схемы роста объемов информации
Инфографика схемы роста объемов информации
Рост объемов данных
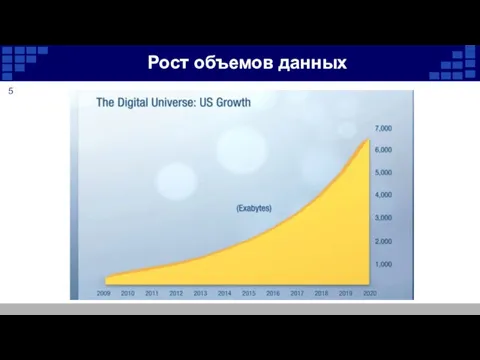
Рост объемов данных

SFedU
Векторная репрезентация слов
SFedU
Векторная репрезентация слов

SFedU
Векторная репрезентация слов
SFedU
Векторная репрезентация слов

SFedU
Семантический вектор запроса и текста
SFedU
Семантический вектор запроса и текста

SFedU
Постановка задачи семантического поиска
SFedU
Постановка задачи семантического поиска

SFedU
Постановка задачи классификации
SFedU
Постановка задачи классификации

SFedU
Постановка задачи структуризации
SFedU
Постановка задачи структуризации

SFedU
Постановка задачи структуризации
SFedU
Постановка задачи структуризации
SFedU
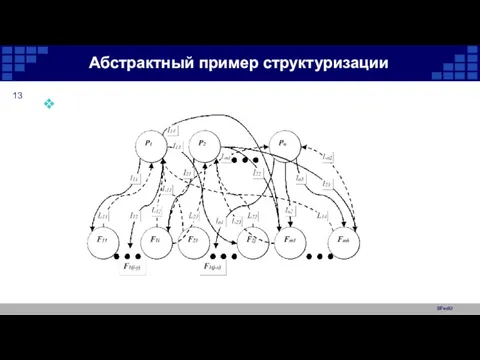
Абстрактный пример структуризации
SFedU
Абстрактный пример структуризации

SFedU
Постановка задачи интеграции
SFedU
Постановка задачи интеграции
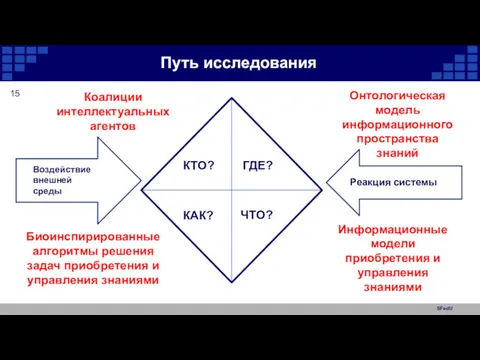
SFedU
Путь исследования
КТО?
ГДЕ?
ЧТО?
КАК?
Коалиции интеллектуальных агентов
Онтологическая модель информационногопространства знаний
Информационные модели приобретения и управления
SFedU
Путь исследования
КТО?
ГДЕ?
ЧТО?
КАК?
Коалиции интеллектуальных агентов
Онтологическая модель информационногопространства знаний
Информационные модели приобретения и управления
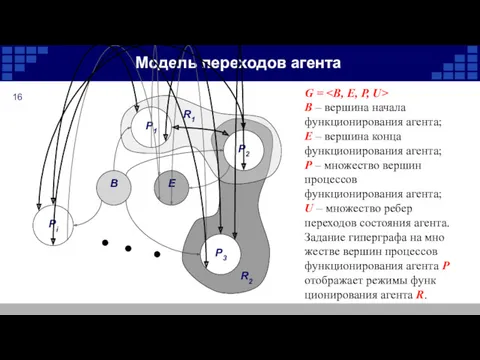
Модель переходов агента
G =
B – вершина
Модель переходов агента
G =
B – вершина
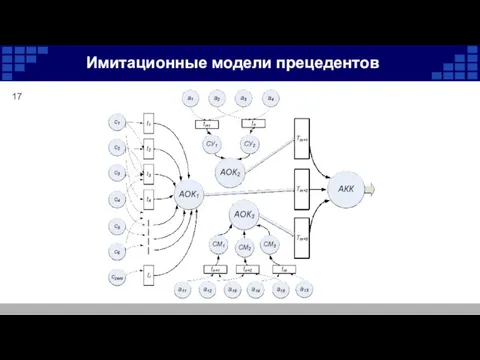
Имитационные модели прецедентов
Имитационные модели прецедентов
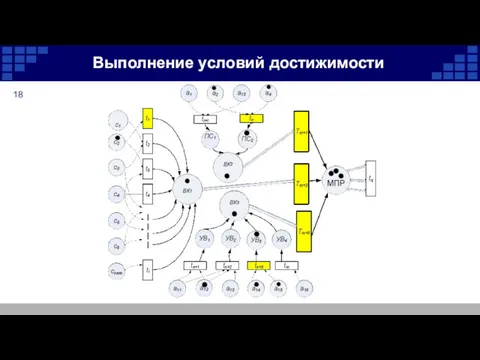
Выполнение условий достижимости
Выполнение условий достижимости
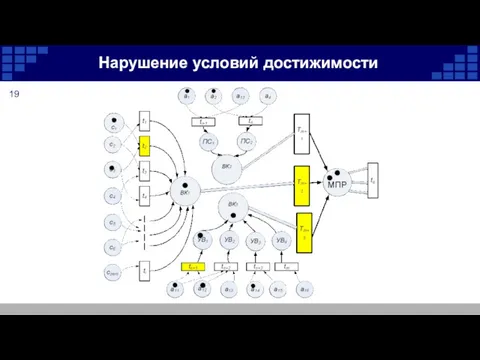
Нарушение условий достижимости
Нарушение условий достижимости
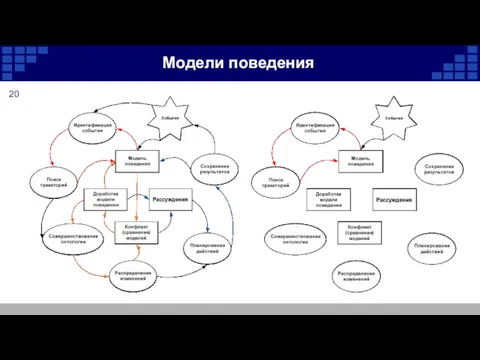
Модели поведения
Модели поведения
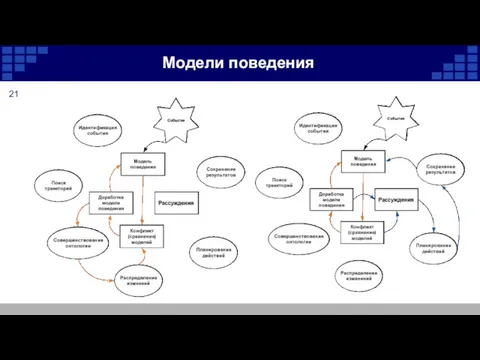
Модели поведения
Модели поведения
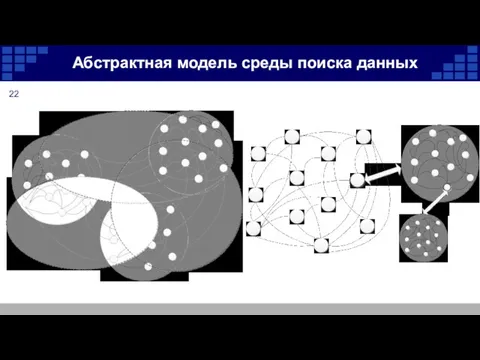
Абстрактная модель среды поиска данных
Абстрактная модель среды поиска данных

SFedU
Модель онтологии
Онтология O представляет собой знаковую систему O = ,
SFedU
Модель онтологии
Онтология O представляет собой знаковую систему O =
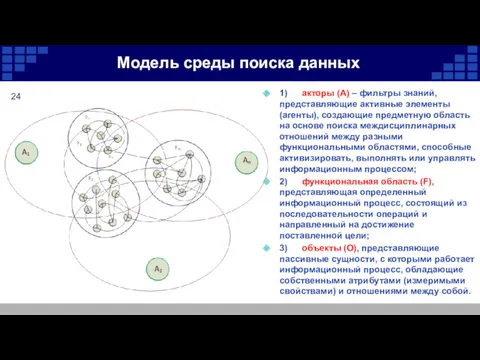
Модель среды поиска данных
1) акторы (A) – фильтры знаний, представляющие активные элементы
Модель среды поиска данных
1) акторы (A) – фильтры знаний, представляющие активные элементы
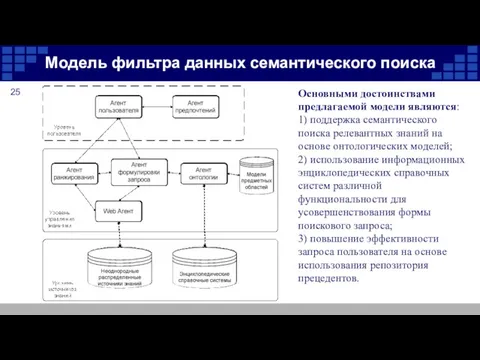
Модель фильтра данных семантического поиска
Основными достоинствами предлагаемой модели являются:
1) поддержка
Модель фильтра данных семантического поиска
Основными достоинствами предлагаемой модели являются:
1) поддержка
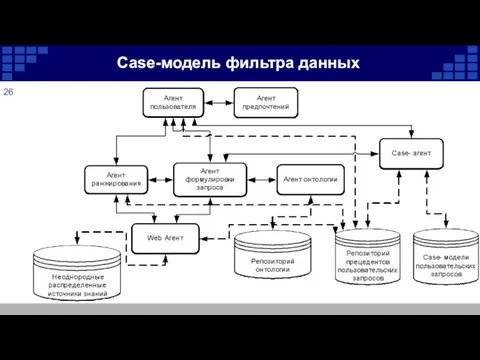
Case-модель фильтра данных
Case-модель фильтра данных
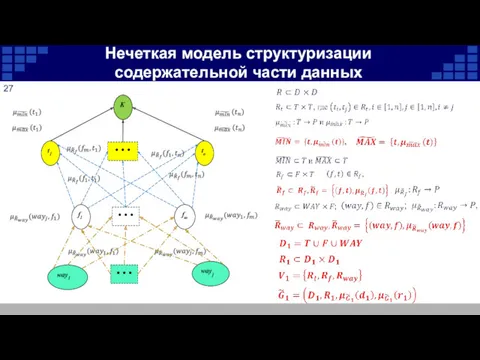
Нечеткая модель структуризации содержательной части данных
Нечеткая модель структуризации содержательной части данных
 Операционная система os/2
Операционная система os/2 Основы SQL
Основы SQL Текстові редактори
Текстові редактори Прикладное программное обеспечение. Электронные таблицы MS Excel 2007
Прикладное программное обеспечение. Электронные таблицы MS Excel 2007 Ищем потерянный трафик
Ищем потерянный трафик Хранение и выборка данных
Хранение и выборка данных Измерение информации. Информация и информационные процессы. Информатика. 7 класс
Измерение информации. Информация и информационные процессы. Информатика. 7 класс Мониторинг сайтов образовательных организаций г.о. Самара
Мониторинг сайтов образовательных организаций г.о. Самара Электронные таблицы. Программа MS Excel
Электронные таблицы. Программа MS Excel Оператор цикла с параметром
Оператор цикла с параметром Знакомство с графическим редактором Adobe Fhotoshop
Знакомство с графическим редактором Adobe Fhotoshop Разработка информационной системы Магазин продуктов. Информационные системы
Разработка информационной системы Магазин продуктов. Информационные системы Системы счисления
Системы счисления Кибербезопасность для младших школьников
Кибербезопасность для младших школьников Создание веб-сайтов
Создание веб-сайтов История развития вычислительной техники
История развития вычислительной техники CCC releases
CCC releases Применение Matlab для обработки данных, полученных от детекторов космических излучений
Применение Matlab для обработки данных, полученных от детекторов космических излучений Система дистанционного обучения УГАТУ
Система дистанционного обучения УГАТУ История вычислительной техники
История вычислительной техники Компьютерная графика
Компьютерная графика Компьютерные сети, Интернет и мультимедиа технологии. Основы сетей передачи данных
Компьютерные сети, Интернет и мультимедиа технологии. Основы сетей передачи данных Информационные технологии и управление образовательной деятельностью
Информационные технологии и управление образовательной деятельностью Культура электронного общения
Культура электронного общения Биометрическая система контроля и управления доступом БиоСКУД Сонда Эксперт
Биометрическая система контроля и управления доступом БиоСКУД Сонда Эксперт Создание формы для базы данных
Создание формы для базы данных Зачем нужны социальные сети
Зачем нужны социальные сети Классификация современных компьютеров
Классификация современных компьютеров