- Database Management Systems. Lecture 4

Содержание
- 2. Content: Joining Multiple Tables
- 3. JOINS PostgreSQL JOIN is used to combine columns from one or more tables based on the
- 4. INNER JOIN The INNER JOIN keyword selects all rows from both the tables if the condition
- 5. Example: Suppose you have two tables called basket_a and basket_b and that store fruits: CREATE TABLE
- 6. Example: The inner join examines each row in the first table (basket_a). It compares the value
- 7. LEFT JOIN This join returns all the rows of the table on the left side of
- 8. Example: The left join starts selecting data from the left table. It compares values in the
- 9. RIGHT JOIN RIGHT JOIN is similar to LEFT JOIN. This join returns all the rows of
- 10. Example: The right join is a reversed version of the left join. The right join starts
- 11. FULL JOIN FULL JOIN creates the result-set by combining result of both LEFT JOIN and RIGHT
- 12. Example: The full outer join or full join returns a result set that contains all rows
- 13. CROSS JOIN A CROSS JOIN clause allows you to produce a Cartesian Product of rows in
- 14. Example: In this case CROSS JOIN works like INNER JOIN
- 15. NATURAL JOIN A NATURAL JOIN is a join that creates an implicit join based on the
- 16. Example:
- 17. Example:
- 18. SELF JOIN A self-join is a regular join that joins a table to itself. In practice,
- 19. Example:
- 20. UPDATE JOIN Sometimes, you need to update data in a table based on values in another
- 21. Example:
- 22. DELETE JOIN PostgreSQL doesn’t support the DELETE JOIN statement. However, it does support the USING clause
- 23. Example:
- 24. SEQUENCE By definition, a sequence is an ordered list of integers. The orders of numbers in
- 25. SEQUENCE By definition, a sequence is an ordered list of integers. The orders of numbers in
- 26. Specify the name of the sequence after the CREATE SEQUENCE clause. The sequence name must be
- 28. Скачать презентацию

Content:
Joining Multiple Tables
Content:
Joining Multiple Tables

JOINS
PostgreSQL JOIN is used to combine columns from one or more
JOINS
PostgreSQL JOIN is used to combine columns from one or more

INNER JOIN
The INNER JOIN keyword selects all rows from both the
INNER JOIN
The INNER JOIN keyword selects all rows from both the

Example:
Suppose you have two tables called basket_a and basket_b and that
Example:
Suppose you have two tables called basket_a and basket_b and that

Example:
The inner join examines each row in the first table (basket_a).
Example:
The inner join examines each row in the first table (basket_a).

LEFT JOIN
This join returns all the rows of the table on
LEFT JOIN
This join returns all the rows of the table on
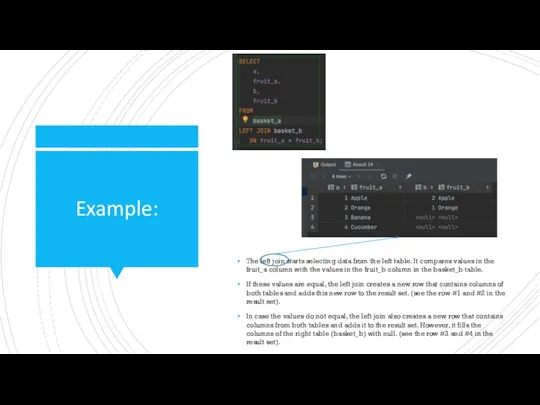
Example:
The left join starts selecting data from the left table. It
Example:
The left join starts selecting data from the left table. It

RIGHT JOIN
RIGHT JOIN is similar to LEFT JOIN.
This join returns
RIGHT JOIN
RIGHT JOIN is similar to LEFT JOIN.
This join returns
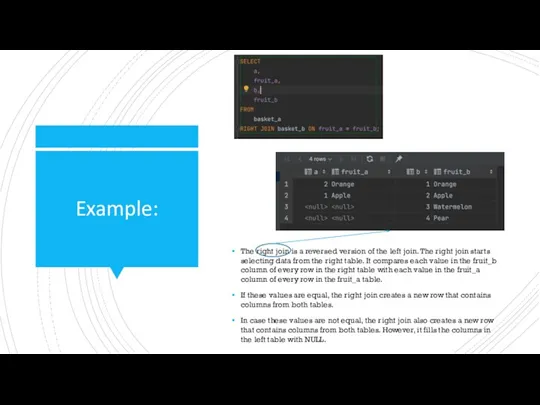
Example:
The right join is a reversed version of the left join. The
Example:
The right join is a reversed version of the left join. The

FULL JOIN
FULL JOIN creates the result-set by combining result of both
FULL JOIN
FULL JOIN creates the result-set by combining result of both

Example:
The full outer join or full join returns a result set that contains
Example:
The full outer join or full join returns a result set that contains
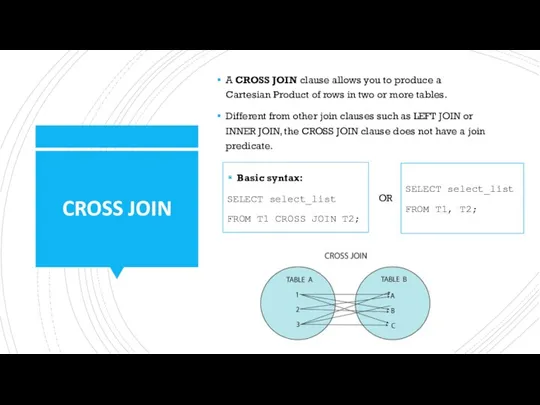
CROSS JOIN
A CROSS JOIN clause allows you to produce a Cartesian Product of
CROSS JOIN
A CROSS JOIN clause allows you to produce a Cartesian Product of
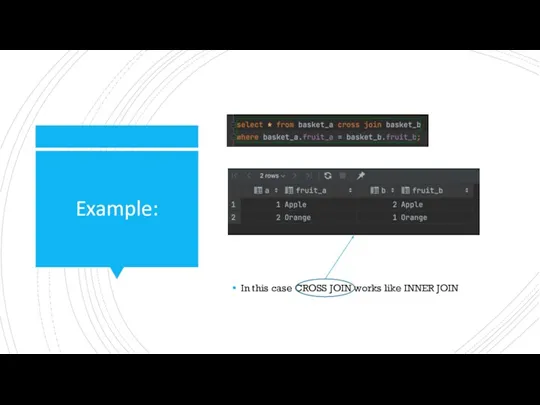
Example:
In this case CROSS JOIN works like INNER JOIN
Example:
In this case CROSS JOIN works like INNER JOIN

NATURAL JOIN
A NATURAL JOIN is a join that creates an implicit
NATURAL JOIN
A NATURAL JOIN is a join that creates an implicit

Example:
Example:

Example:
Example:

SELF JOIN
A self-join is a regular join that joins a table
SELF JOIN
A self-join is a regular join that joins a table
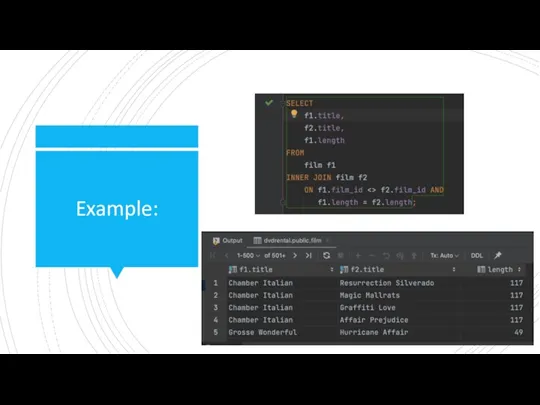
Example:
Example:
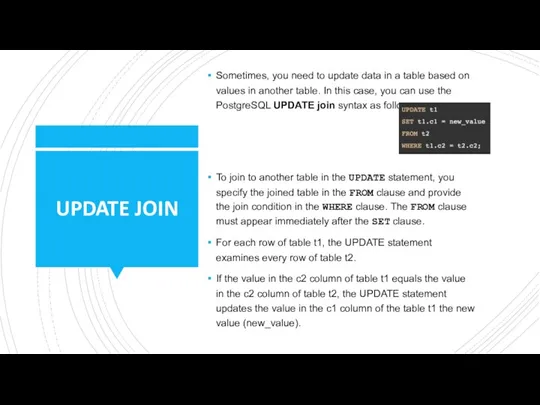
UPDATE JOIN
Sometimes, you need to update data in a table based on
UPDATE JOIN
Sometimes, you need to update data in a table based on

Example:
Example:

DELETE JOIN
PostgreSQL doesn’t support the DELETE JOIN statement. However, it does support the USING clause
DELETE JOIN
PostgreSQL doesn’t support the DELETE JOIN statement. However, it does support the USING clause

Example:
Example:

SEQUENCE
By definition, a sequence is an ordered list of integers. The
SEQUENCE
By definition, a sequence is an ordered list of integers. The

SEQUENCE
By definition, a sequence is an ordered list of integers. The
SEQUENCE
By definition, a sequence is an ordered list of integers. The
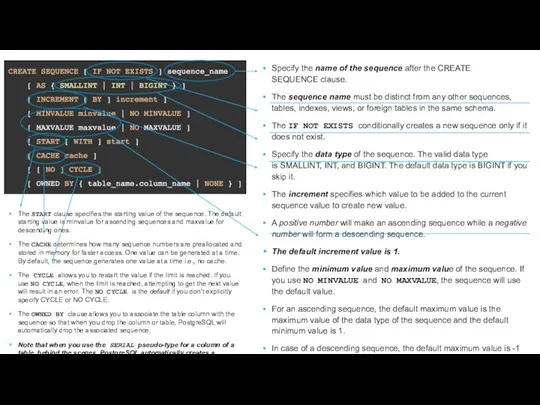
Specify the name of the sequence after the CREATE SEQUENCE clause.
The sequence
Specify the name of the sequence after the CREATE SEQUENCE clause.
The sequence
 Работа с зацепками в системе Youla для МПП
Работа с зацепками в системе Youla для МПП JavaScript. Формы и валидация
JavaScript. Формы и валидация Одномерные массивы целых чисел. Начала программирования. (9 класс)
Одномерные массивы целых чисел. Начала программирования. (9 класс) Табличный процессор Excel. Часть 1
Табличный процессор Excel. Часть 1 WEB – сайты и WEB – страницы
WEB – сайты и WEB – страницы Урок на тему Поиск информации в Интернете 9 класс
Урок на тему Поиск информации в Интернете 9 класс Графика в Python
Графика в Python Использования дистанционных технологий в образовательном процессе
Использования дистанционных технологий в образовательном процессе План-конспект урока В мире алгоритмов
План-конспект урока В мире алгоритмов Принципы работы контекстной рекламы
Принципы работы контекстной рекламы Компьютерные словари и системы перевода текстов
Компьютерные словари и системы перевода текстов Excel: создание таблиц
Excel: создание таблиц Система управления теплицами Агроном
Система управления теплицами Агроном Windows Movie Maker (часть I)
Windows Movie Maker (часть I) Построение базы данных
Построение базы данных Запросы СУБД Microsoft Access
Запросы СУБД Microsoft Access Linux, разновидности Linux и Ubuntu
Linux, разновидности Linux и Ubuntu Virtual reality
Virtual reality Macroscop. Интеграции СКУД
Macroscop. Интеграции СКУД Аналоговая вычислительная машина
Аналоговая вычислительная машина Accelerate Azure migrations with Windows Server & SQL Server 2008 and 2008 R2 end of support
Accelerate Azure migrations with Windows Server & SQL Server 2008 and 2008 R2 end of support Логические законы. Закон тождества
Логические законы. Закон тождества Информационные революции. Информационное общество. Лекция 2
Информационные революции. Информационное общество. Лекция 2 Подпрограммы. Процедуры и функции
Подпрограммы. Процедуры и функции Численные методы решения задач
Численные методы решения задач Материалды сараптауға дайындау
Материалды сараптауға дайындау Анализ систем управления движением
Анализ систем управления движением Инструменты автоматизации форматирования. Создание оглавления
Инструменты автоматизации форматирования. Создание оглавления