- Докинг. Hadoop

Содержание
- 2. Определение Молекулярный докинг – это расчет взаимодействия низкомолекулярного вещества с активным центром белка и предсказание энергетически
- 3. Типы программ
- 4. Типы программ Prieto-Martínez FD, Arciniega M, Medina-Franco JL. Molecular docking: current advances and challenges. TIP Rev
- 5. Типы докинга
- 6. Типы докинга
- 7. Как найти нужную конформацию? Как понять, что она лучшая?
- 8. Алгоритмы Сравнивают по так называемой оценивающей функции
- 9. НО КАК ПРЕДСТАВИТЬ БЕЛОК ТАК, ЧТОБЫ КОМПЬЮТЕР ПОНЯЛ, ЧТО ЭТО БЕЛОК? ДА И ЕЩЁ НАМ ЧТО-ТО
- 10. Как вообще расшифровывают структуру белков? Рентгеновская кристаллография Ядерно-магнитный резонанс
- 11. Форматы представления Protein Data Bank (PDB). Формат файла представляет собой формат текстового файла описание трехмерных структур
- 12. Пример pdbqt файла Как описывается атом в pdb
- 13. Где брать? www.rcsb.org Состояние на 24.09.2020 21:50 UTC+3
- 14. AutoDock
- 15. Определение Кластер — группа компьютеров, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя единый аппаратный
- 16. Что хочется Что есть Оглянитесь вокруг ☹ Техники работают с большим Linux кластером в Хемницком техническом
- 17. Hadoop Hadoop — проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и фреймворк для
- 18. MapReduce
- 19. Архитектура кластера Hadoop https://data-flair.training/blogs/hadoop-architecture/
- 20. Как я организовал процесс Вход Выход
- 22. Скачать презентацию

Определение
Молекулярный докинг – это расчет взаимодействия низкомолекулярного вещества с активным центром
Определение
Молекулярный докинг – это расчет взаимодействия низкомолекулярного вещества с активным центром
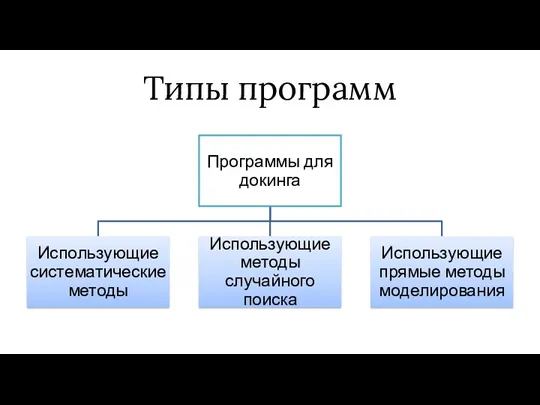
Типы программ
Типы программ

Типы программ
Prieto-Martínez FD, Arciniega M, Medina-Franco JL. Molecular docking: current advances
Типы программ
Prieto-Martínez FD, Arciniega M, Medina-Franco JL. Molecular docking: current advances
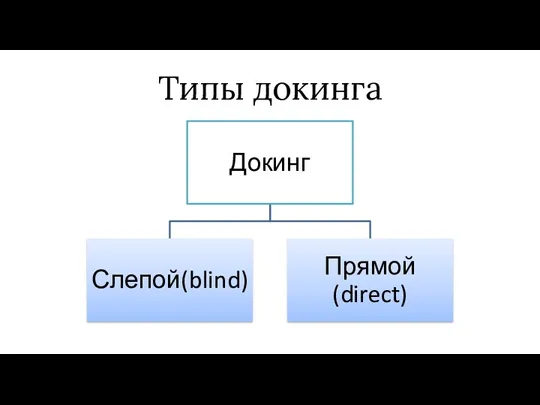
Типы докинга
Типы докинга
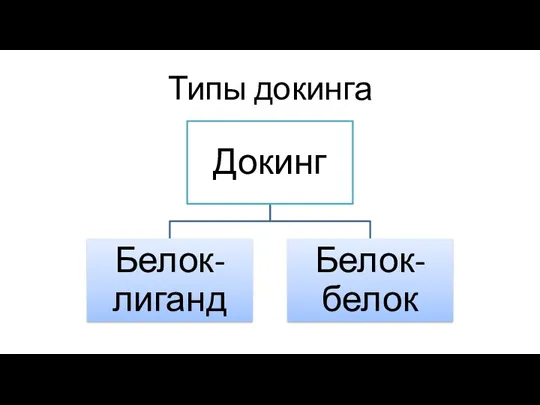
Типы докинга
Типы докинга

Как найти нужную конформацию?
Как понять, что она лучшая?
Как найти нужную конформацию?
Как понять, что она лучшая?

Алгоритмы
Сравнивают по так называемой оценивающей функции
Алгоритмы
Сравнивают по так называемой оценивающей функции

НО КАК ПРЕДСТАВИТЬ БЕЛОК ТАК, ЧТОБЫ КОМПЬЮТЕР ПОНЯЛ, ЧТО ЭТО БЕЛОК?
НО КАК ПРЕДСТАВИТЬ БЕЛОК ТАК, ЧТОБЫ КОМПЬЮТЕР ПОНЯЛ, ЧТО ЭТО БЕЛОК?
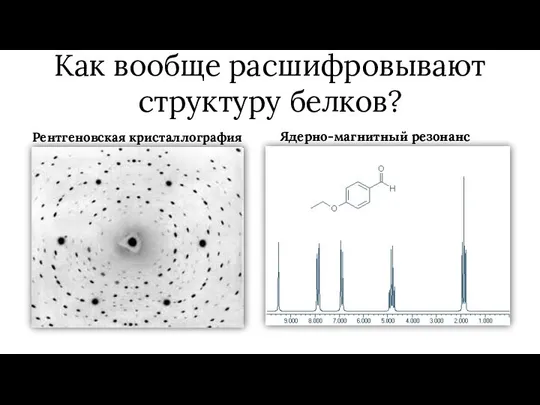
Как вообще расшифровывают структуру белков?
Рентгеновская кристаллография
Ядерно-магнитный резонанс
Как вообще расшифровывают структуру белков?
Рентгеновская кристаллография
Ядерно-магнитный резонанс

Форматы представления
Protein Data Bank (PDB). Формат файла представляет собой формат текстового
Форматы представления
Protein Data Bank (PDB). Формат файла представляет собой формат текстового
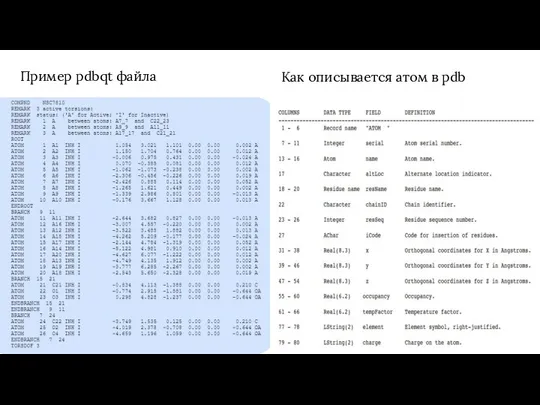
Пример pdbqt файла
Как описывается атом в pdb
Пример pdbqt файла
Как описывается атом в pdb
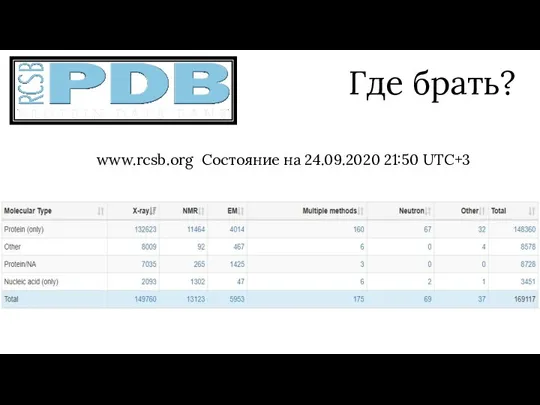
Где брать?
www.rcsb.org Состояние на 24.09.2020 21:50 UTC+3
Где брать?
www.rcsb.org Состояние на 24.09.2020 21:50 UTC+3
AutoDock
AutoDock

Определение
Кластер — группа компьютеров, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя
Определение
Кластер — группа компьютеров, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя

Что хочется
Что есть
Оглянитесь вокруг ☹
Техники работают с большим Linux кластером в Хемницком техническом университете,
Что хочется
Что есть
Оглянитесь вокруг ☹
Техники работают с большим Linux кластером в Хемницком техническом университете,

Hadoop
Hadoop — проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ,
Hadoop
Hadoop — проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ,
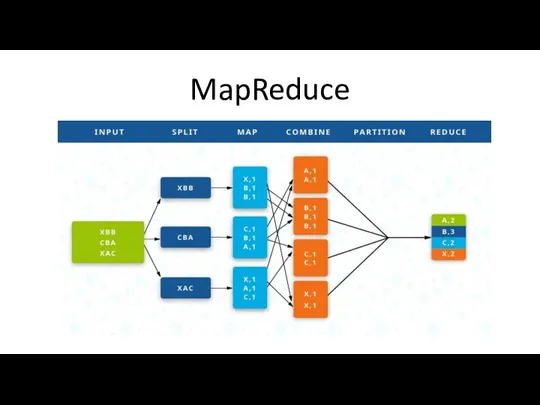
MapReduce
MapReduce
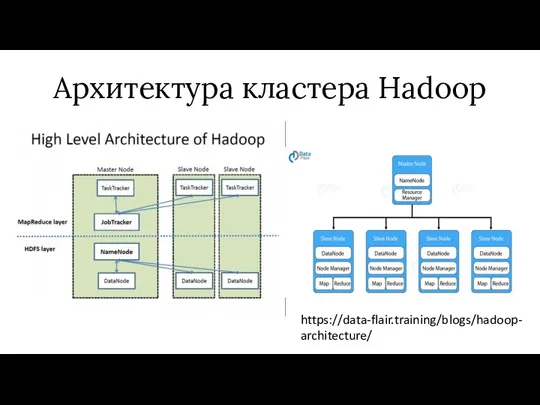
Архитектура кластера Hadoop
https://data-flair.training/blogs/hadoop-architecture/
Архитектура кластера Hadoop
https://data-flair.training/blogs/hadoop-architecture/

Как я организовал процесс
Вход
Выход
Как я организовал процесс
Вход
Выход
 Case Simulation
Case Simulation Использование методов типа ветвей и границ для решения экстремальных задач на графах
Использование методов типа ветвей и границ для решения экстремальных задач на графах Информационные системы
Информационные системы Программирование на языке Python
Программирование на языке Python Технологии баз данных
Технологии баз данных Своя игра. Лабиринт информации
Своя игра. Лабиринт информации Геймінг – це гра у відеоігри на колективних турнірах
Геймінг – це гра у відеоігри на колективних турнірах Дополнительные возможности HTML и CSS. XML-технологии и их применение
Дополнительные возможности HTML и CSS. XML-технологии и их применение Базы данных. Введение в курс баз данных
Базы данных. Введение в курс баз данных Кто играл в PACMAN? Какие правила игры?
Кто играл в PACMAN? Какие правила игры? Сетевые операционные системы
Сетевые операционные системы конспект урока Моделирование
конспект урока Моделирование Решение задач в Mathcad и Excel. Использование функции IF (ЕСЛИ). Лабораторная работа №1
Решение задач в Mathcad и Excel. Использование функции IF (ЕСЛИ). Лабораторная работа №1 Архитектура и система команд процесоров Intel. (Тема 1)
Архитектура и система команд процесоров Intel. (Тема 1) Викторина по информатике (презентация)
Викторина по информатике (презентация) Час кода в России
Час кода в России Обзор периферийных устройств, дополняющих линейку ПЛК ОВЕН
Обзор периферийных устройств, дополняющих линейку ПЛК ОВЕН Язык С++: новые возможности. (Лекция 1)
Язык С++: новые возможности. (Лекция 1) Обзор компьютера
Обзор компьютера This is your presentation title
This is your presentation title Основные компоненты компьютера и их функции
Основные компоненты компьютера и их функции Поняття про мультимедіа. ( 6 клас)
Поняття про мультимедіа. ( 6 клас) Разработка программно-информационного ядра информационной системы на основе СУБД
Разработка программно-информационного ядра информационной системы на основе СУБД Робота з елементами форми
Робота з елементами форми 001 Ancient Greek History - Essential Chronology
001 Ancient Greek History - Essential Chronology Команда Select (лекция 2)
Команда Select (лекция 2) Презентация к уроку Носители информации (3 класс)
Презентация к уроку Носители информации (3 класс) Графическая информация
Графическая информация