- Елементи теорії формальних мов

Содержание
- 2. 1. Означення формальних мов. Ланцюжки Позначимо – множину всіх слів, крім е (ε). Припустимо, що ми
- 3. 1.1. Приклади формальних мов
- 4. 1.2. Задача належності. Способи визначення мов
- 5. 1.3. Регулярні операції над мовами
- 6. 2. Метамова БНФ має структуру ::= БНФ оператора присвоєння: ::= ':=' ::= Приклад 1. ::= ':='
- 7. 3. Розширені БНФ Означення: Метавирази з символами "(", ")", "[", "]", "{", "}" нази-ваються розширеними, а
- 9. Ітераційні дужки “{“ , “}” Якщо X – довільний метавираз, то метавираз {X} позначає всі послідовності
- 10. The syntax of C in Backus-Naur Form (fragment 1) ::= | , ::= = | *=
- 11. The syntax of C in Backus-Naur Form (fragment 2) ::= if ( ) | if (
- 12. 4. Граматики Хомського. Основні поняття Означення: Граматикою Хомського називається четвірка G = (N, T, P, S),
- 13. How a grammar generates sentences G = (N, T, P, S), Example: consider the grammar: P:
- 14. How a grammar generates sentences Summary of the derivation: S => NP VP NP John VP
- 15. G = (N, T, P, S) Можна вважати P – скінченною підмножиною такої множини: ( T
- 16. Приклади граматик Хомського Приклад . G0 =(N, T, P, S) N: { A, S } T:
- 17. Визначимо ряд понять: Приклад . G1 =({ A, B, C, D },{ a, 1, 2 },
- 18. Приклад .Слова A, BC, aC, a1 вивідні в граматиці G1. 2. На множині (T∪N)* означається відношення
- 19. 4. Вивідні слова в алфавіті T називаються породжуваними, а множина їх усіх – мовою, що задається
- 20. 5. Вивідний ланцюжок граматики , що не містить нетермінальних символів називається термінальним ланцюжком, що породжується граматикою
- 21. Введемо позначення: 1. Будемо позначати a,b, …,0,1, …9 – термінали. 2. A, B, C, D, E,
- 22. 5. Класифікація граматик Хомського. Приклади
- 23. Приклад контекстно-вільної граматики: G4 = ({ E, T,F},{ a, *, +,(,)} ,P,E) P: E→E+T|T T→T*F|F F→(E)|a
- 24. S=>aSBC=>aabCBC=> aabBCC=> aabbCC => aabbcC => aabbcc Приклад контекстно-залежної граматики: G5 = ({ B,С,S},{ a, b,
- 25. Приклад необмеженої граматики: G6 = ({ A,B,С,D,S},{ a, b} ,P,S) 1) S→CD 6) Aa→aA 2) C→aCA
- 26. 1) S→CD 2) C→aCA 3) C→bCB 4) AD→aD 5) BD→bD 6) Aa→aA 7) Ab→bA 8) Ba→aB
- 27. Означення 5. Праволінійна граматика G = (Т, N, P, S) називається регулярною (автоматною), якщо кожне правило
- 28. Означення 6. Граматика G називається розширеною граматикою, якщо вона задається списком пар Ai → ri, де
- 29. Адреса://fpm.chnu Гіперпосилання “Системне програмування”, Вкладинка “Програмний супровід”
- 30. 5. Розпізнавачі Розпізнавач складається з трьох частин: вхідна стрічка; керуючий пристрій із скінченню пам’яттю; робоча (допоміжна)
- 31. Означення 1. Керуючий пристрій називається детермінованим, якщо для кожної конфігурації існує не більше одного наступного детермінованого
- 33. Скачать презентацию

1. Означення формальних мов. Ланцюжки
Позначимо – множину всіх слів,
1. Означення формальних мов. Ланцюжки
Позначимо – множину всіх слів,

1.1. Приклади формальних мов
1.1. Приклади формальних мов
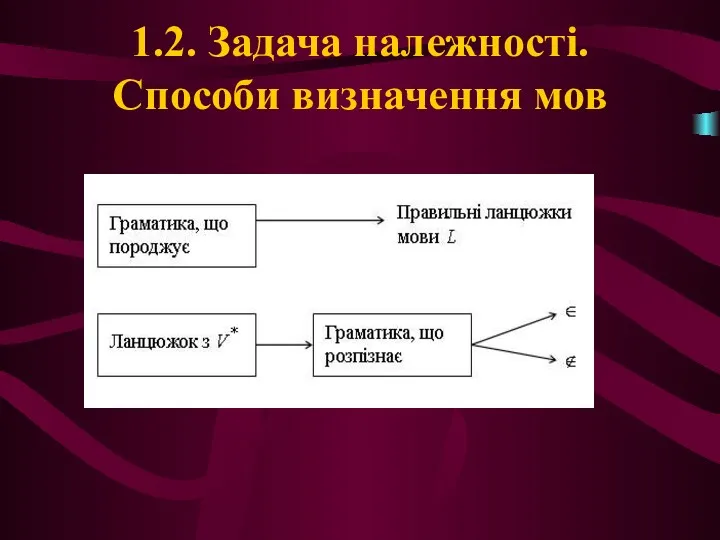
1.2. Задача належності. Способи визначення мов
1.2. Задача належності. Способи визначення мов

1.3. Регулярні операції над мовами
1.3. Регулярні операції над мовами

2. Метамова БНФ
<поняття> має структуру <метавираз>
<поняття> ::= <метавираз>
БНФ оператора присвоєння:
<оператор
2. Метамова БНФ
<поняття> має структуру <метавираз>
<поняття> ::= <метавираз>
БНФ оператора присвоєння:
<оператор

3. Розширені БНФ
Означення: Метавирази з символами "(", ")", "[", "]", "{",
3. Розширені БНФ
Означення: Метавирази з символами "(", ")", "[", "]", "{",


Ітераційні дужки “{“ , “}”
Якщо X – довільний метавираз, то метавираз
Ітераційні дужки “{“ , “}”
Якщо X – довільний метавираз, то метавираз

The syntax of C in Backus-Naur Form
(fragment 1)
::=
The syntax of C in Backus-Naur Form
(fragment 1)

The syntax of C in Backus-Naur Form
(fragment 2)
::= if
The syntax of C in Backus-Naur Form
(fragment 2)

4. Граматики Хомського. Основні поняття
Означення: Граматикою Хомського називається четвірка
G
4. Граматики Хомського. Основні поняття
Означення: Граматикою Хомського називається четвірка
G

How a grammar generates sentences
G = (N, T, P, S),
How a grammar generates sentences
G = (N, T, P, S),

How a grammar generates sentences
Summary of the derivation:
S => NP VP
How a grammar generates sentences
Summary of the derivation:
S => NP VP

G = (N, T, P, S)
Можна вважати P – скінченною підмножиною
G = (N, T, P, S)
Можна вважати P – скінченною підмножиною

Приклади граматик Хомського
Приклад . G0 =(N, T, P, S)
N: { A, S
Приклади граматик Хомського
Приклад . G0 =(N, T, P, S)
N: { A, S

Визначимо ряд понять:
Приклад . G1 =({ A, B, C, D
Визначимо ряд понять:
Приклад . G1 =({ A, B, C, D

Приклад .Слова A, BC, aC, a1 вивідні в граматиці G1.
2. На
Приклад .Слова A, BC, aC, a1 вивідні в граматиці G1.
2. На

4. Вивідні слова в алфавіті T називаються породжуваними, а множина їх
4. Вивідні слова в алфавіті T називаються породжуваними, а множина їх

5. Вивідний ланцюжок граматики , що не містить нетермінальних символів
5. Вивідний ланцюжок граматики , що не містить нетермінальних символів

Введемо позначення:
1. Будемо позначати a,b, …,0,1, …9 – термінали.
2. A,
Введемо позначення:
1. Будемо позначати a,b, …,0,1, …9 – термінали.
2. A,

5. Класифікація граматик
Хомського. Приклади
5. Класифікація граматик
Хомського. Приклади
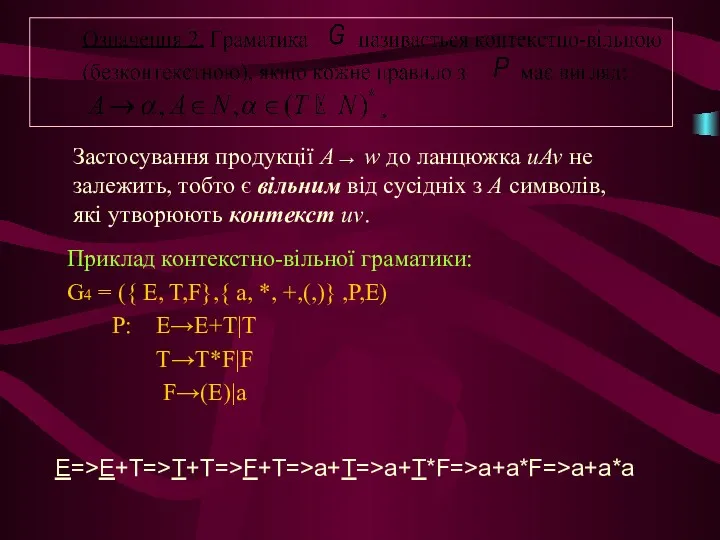
Приклад контекстно-вільної граматики:
G4 = ({ E, T,F},{ a, *, +,(,)}
Приклад контекстно-вільної граматики:
G4 = ({ E, T,F},{ a, *, +,(,)}

S=>aSBC=>aabCBC=> aabBCC=> aabbCC => aabbcC => aabbcc
Приклад контекстно-залежної граматики:
G5 = ({
S=>aSBC=>aabCBC=> aabBCC=> aabbCC => aabbcC => aabbcc
Приклад контекстно-залежної граматики:
G5 = ({

Приклад необмеженої граматики:
G6 = ({ A,B,С,D,S},{ a, b} ,P,S)
1) S→CD
Приклад необмеженої граматики:
G6 = ({ A,B,С,D,S},{ a, b} ,P,S)
1) S→CD

1) S→CD
2) C→aCA
3) C→bCB
4) AD→aD
5) BD→bD
1) S→CD
2) C→aCA
3) C→bCB
4) AD→aD
5) BD→bD

Означення 5. Праволінійна граматика G = (Т, N, P, S) називається
Означення 5. Праволінійна граматика G = (Т, N, P, S) називається

Означення 6. Граматика G називається розширеною граматикою, якщо вона задається списком
Означення 6. Граматика G називається розширеною граматикою, якщо вона задається списком

Адреса://fpm.chnu
Гіперпосилання “Системне програмування”,
Вкладинка “Програмний супровід”
Адреса://fpm.chnu
Гіперпосилання “Системне програмування”,
Вкладинка “Програмний супровід”
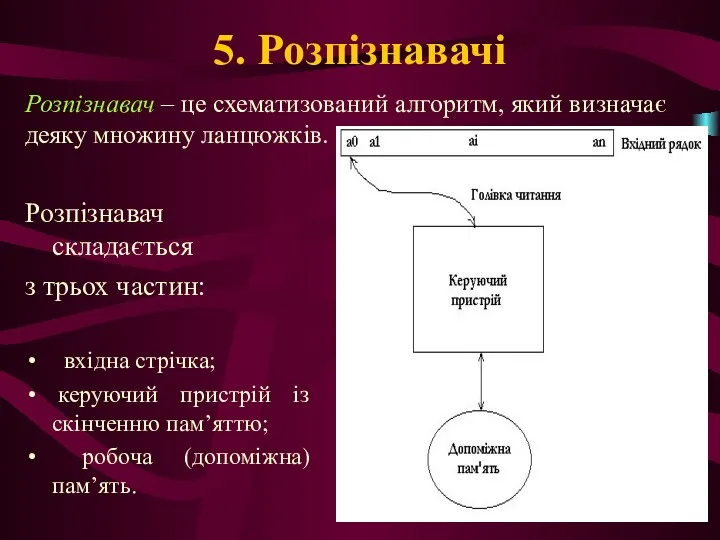
5. Розпізнавачі
Розпізнавач складається
з трьох частин:
вхідна стрічка;
керуючий пристрій із скінченню пам’яттю;
5. Розпізнавачі
Розпізнавач складається
з трьох частин:
вхідна стрічка;
керуючий пристрій із скінченню пам’яттю;

Означення 1. Керуючий пристрій називається детермінованим, якщо для кожної конфігурації існує
Означення 1. Керуючий пристрій називається детермінованим, якщо для кожної конфігурації існує
 Порядок действий для перехода на КЭДО
Порядок действий для перехода на КЭДО Образовательные сайты для педагогов
Образовательные сайты для педагогов Основы программирования: ТЕМА 07. АЛГОРИТМЫ ОБРАБОТКИ ТАБЛИЦ.
Основы программирования: ТЕМА 07. АЛГОРИТМЫ ОБРАБОТКИ ТАБЛИЦ. Sega Mega Drive/Sega Genesis и выходившие на неё игры
Sega Mega Drive/Sega Genesis и выходившие на неё игры Презентация GTA
Презентация GTA Медиапространство России: карта цифровизации
Медиапространство России: карта цифровизации Використання системи Anti-Plagiarism
Використання системи Anti-Plagiarism Canvas
Canvas Нейронные сети
Нейронные сети Презентация опыта Формирование мотивации учения
Презентация опыта Формирование мотивации учения презентация к уроку по информатике Множества 3 класс
презентация к уроку по информатике Множества 3 класс Введение в Интернет-технологии
Введение в Интернет-технологии Короткий текст. Структура новости
Короткий текст. Структура новости Поняття мови розмітки гіпертекстового документа
Поняття мови розмітки гіпертекстового документа Состав и структура, функциональные и обеспечивающие подсистемы, жизненный цикл КИС
Состав и структура, функциональные и обеспечивающие подсистемы, жизненный цикл КИС Архивация данных. Обзор пакетов для архивации данных
Архивация данных. Обзор пакетов для архивации данных Basics of time series forecasting. Lecture 9
Basics of time series forecasting. Lecture 9 Пользовательский интерфейс. (7 класс)
Пользовательский интерфейс. (7 класс) История развития глобальных сетей
История развития глобальных сетей Ветвление. Язык Python. Лекция 4
Ветвление. Язык Python. Лекция 4 Представление числовой информации с помощью систем счисления (1). 8 класс
Представление числовой информации с помощью систем счисления (1). 8 класс Язык GPSS. Синхронизация транзактов. Работа с потоками данных. Лекция 4
Язык GPSS. Синхронизация транзактов. Работа с потоками данных. Лекция 4 Первое знакомство с компьютером
Первое знакомство с компьютером Чем мы можем дорабатывать Revit? DisignScript, Python C#. Что такое Dynamo?
Чем мы можем дорабатывать Revit? DisignScript, Python C#. Что такое Dynamo? Условный оператор в Паскале
Условный оператор в Паскале Урок медиабезопасности
Урок медиабезопасности Презентация и защита проекта
Презентация и защита проекта Объемно-пространсвеннная композиция
Объемно-пространсвеннная композиция