- Face Recognition: From Scratch to Hatch

Содержание
- 2. Face Recognition in Cloud@Mail.ru Users upload photos to Cloud Backend identifies persons on photos, tags and
- 3. Social networks
- 5. edges object parts (combination of edges) object models
- 7. Face detection
- 8. Auxiliary task: facial landmarks Face alignment: rotation Goal: make it easier for Face Recognition
- 9. Train Datasets Wider 32k images 494k faces Celeba 200k images, 10k persons Landmarks, 40 binary attributes
- 10. Test Dataset: FDDB Face Detection Data Set and Benchmark 2845 images 5171 faces
- 11. Old school: Viola-Jones Haar Feature-based Cascade Classifiers
- 12. Viola-Jones algorithm: training Face or Not
- 13. Viola-Jones algorithm: inference Stages Face Yes Yes Stage 1 Stage 2 Stage N Optimization Features are
- 14. Viola-Jones results OpenCV implementation Fast: ~100ms on CPU Not accurate
- 15. Pre-trained network: extracting features New school: Region-based Convolutional Networks Faster RCNN, algorithm Face ? Region proposal
- 16. Comparison: Viola-Jones vs R-FCN Results 92% accuracy (R-FCN) FDDB results 40ms on GPU (slow)
- 17. Face detection: how fast We need faster solution at the same accuracy! Target:
- 18. Alternative: MTCNN Cascade of 3 CNN Resize to different scales Proposal -> candidates + b-boxes Refine
- 19. Comparison: MTCNN vs R-FCN MTCNN + Faster + Landmarks - Less accurate - No batch processing
- 21. What is TensorRT NVIDIA TensorRT is a high-performance deep learning inference optimizer Features Improves performance for
- 22. TensorRT: layer optimizations Horizontal fusion Concat elision Vertical layer fusion
- 23. TensorRT: downsides Caffe + TensorFlow supported Fixed input/batch size Basic layers support
- 24. Batch processing Problem Image size is fixed, but MTCNN works at different scales Solution Pyramid on
- 25. Batch processing Results Single run Enables batch processing
- 26. TensorRT: layers Problem No PReLU layer => default pre-trained model can’t be used Retrained with ReLU
- 27. Face detection: inference Target: Result: 8.8 ms Ingredients MTCNN Batch processing TensorRT
- 29. Face recognition task Goal – to compare faces How? To learn metric To enable Zero-shot learning
- 30. Training set: MSCeleb Top 100k celebrities 10 Million images, 100 per person Noisy: constructed by leveraging
- 31. Small test dataset: LFW Labeled Faces in the Wild Home 13k images from the web 1680
- 32. Large test dataset: Megaface Identification under up to 1 million “distractors” 530 people to find
- 33. Megaface leaderboard ~83% ~98% cleaned
- 34. Metric Learning
- 35. Classification Train CNN to predict classes Pray for good latent space
- 36. Softmax Learned features only separable but not discriminative The resulting features are not sufficiently effective
- 37. We need metric learning Tightness of the cluster Discriminative features
- 38. Triplet loss Features Identity -> single point Enforces a margin between persons positive + α
- 39. Choosing triplets Crucial problem How to choose triplets ? Useful triplets = hardest errors Solution Hard-mining
- 40. Choosing triplets: trap
- 41. Choosing triplets: trap positive ~ negative
- 42. Choosing triplets: trap Instead
- 43. Choosing triplets: trap Selecting hardest negative may lead to the collapse early in training
- 44. Choosing triplets: semi-hard positive
- 45. Triplet loss: summary Overview Requires large batches, margin tuning Slow convergence Opensource Code Openface (Torch) suboptimal
- 46. Center loss Idea: pull points to class centroids
- 47. Center loss: structure Without classification loss – collapses Softmax Loss Center Loss Final loss = Softmax
- 48. Center Loss: different lambdas λ = 10-7
- 49. Center Loss: different lambdas λ = 10-6
- 50. Center Loss: different lambdas λ = 10-5
- 51. Center loss: summary Overview Intra-class compactness and inter-class separability Good performance at several other tasks Opensource
- 52. Tricks: augmentation Test time augmentation Flip image Average embeddings Compute 2 embeddings
- 53. Tricks: alignment Rotation Kabsch algorithm - the optimal rotation matrix that minimizes the RMSD
- 54. Angular Softmax On sphere Angle discriminates
- 55. Angular Softmax
- 56. Angular Softmax: different «m»
- 57. Angular softmax: summary Overview Works only on small datasets Slight modification of the loss yields 74.2%
- 58. Metric learning: summary Softmax A-Softmax With bells and whistles better than center loss Overall Rule of
- 59. Fighting errors
- 60. Errors after MSCeleb: children Problem Children all look alike Consequence Average embedding ~ single point in
- 61. Errors after MSCeleb: asian Problem Face Recognition’s intolerant to Asians Reason Dataset doesn’t contain enough photos
- 62. How to fix these errors ? It’s all about data, we need diverse dataset! Natural choice
- 63. A way to construct dataset Cleaning algorithm Face detection Face recognition -> embeddings Hierarchical clustering algorithm
- 64. MSCeleb dataset’s errors MSCeleb is constructed by leveraging search engines Joe Eszterhas and Mel Gibson public
- 65. MSCeleb dataset’s errors Female + Male
- 66. MSCeleb dataset’s errors Asia Mix
- 67. MSCeleb dataset’s errors Dataset has been shrinked from 100k to 46k celebrities Random search engine
- 68. Results on new datasets Datasets Train: MSCeleb (46k) VK-train (200k) Test MegaVK Sets for children and
- 69. How to handle big dataset It seems we can add more data infinitely, but no. Problems
- 70. Softmax Approximation Algorithm Perform K-Means clustering using current FR model
- 71. Softmax Approximation Algorithm Perform K-Means clustering using current FR model Two Softmax heads: Predicts cluster label
- 72. Softmax Approximation Pros Prevents fusing of the clusters Does hard-negative mining Clusters can be specified Children
- 73. Fighting errors on production
- 74. Errors: blur Problem Detector yields blurry photos Recognition forms «blurry clusters» Solution Laplacian – 2nd order
- 75. Laplacian in action Low variance High variance
- 76. Errors: body parts Detection mistakes form clusters
- 77. Errors: diagrams & mushrooms
- 78. Fixing trash clusters There is similarity between “no faces”!
- 79. Workaround Algorithm Construct «trash» dataset Compute average embedding Every point inside the sphere – trash Results
- 80. Spectacular results
- 81. Fun: new governors Recently appointed governors are almost twins, but FR distinguishes them
- 82. Over years Face recognition algorithm captures similarity across years Although we didn’t focus on the problem
- 83. Over years
- 84. Summary Use TensorRT to speed up inference Metric learning: use Center loss by default Clean your
- 86. Auxiliary
- 87. Best avatar Problem How to pick an avatar for a person ? Solution Train model to
- 88. Predicting awesomeness: how to approach Social networks – not only photos, but likes too
- 89. Predicting awesomeness: dataset Awesomeness (A) = likes/audience A=18% A=27% A=75%
- 90. Results Mean Aveage Precision @5: 25% Data and metric are noisy => human evaluation Predicting awesomeness:
- 92. Скачать презентацию
 Таргетированная реклама Вконтакте. Вводный курс
Таргетированная реклама Вконтакте. Вводный курс Информатика в играх и задачах, 2 класс, Горячев
Информатика в играх и задачах, 2 класс, Горячев Мошенничество в интернете
Мошенничество в интернете Разработка настольной игры
Разработка настольной игры Алгоритмы. Линейный алгоритм
Алгоритмы. Линейный алгоритм Совершенствование управления деятельностью кредитной организации на основе применения технологии искусственного интеллекта
Совершенствование управления деятельностью кредитной организации на основе применения технологии искусственного интеллекта История развития ЭВМ
История развития ЭВМ Универсальное устройство для работы с информацией?
Универсальное устройство для работы с информацией?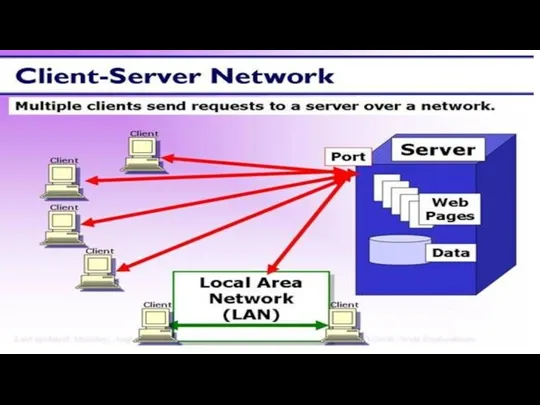 Client-server network
Client-server network Устройство ПК. Программное обеспечение ПК. Информация
Устройство ПК. Программное обеспечение ПК. Информация Сұрыптаудың көбікті әдісі. Cұрыптау әдістері
Сұрыптаудың көбікті әдісі. Cұрыптау әдістері Концепция электронного правительства
Концепция электронного правительства Правовая защита коммерческой тайны. Сведения, составляющие коммерческую тайну (ОПОИБ, лекция 4.1)
Правовая защита коммерческой тайны. Сведения, составляющие коммерческую тайну (ОПОИБ, лекция 4.1) Методологические основы общей теории систем. (Лекция 1)
Методологические основы общей теории систем. (Лекция 1) Скриншоты для составления отчетов ООО Тилипад
Скриншоты для составления отчетов ООО Тилипад Устройства ввода-вывода
Устройства ввода-вывода Архитектура ядра
Архитектура ядра Игровое пространство
Игровое пространство Ai2 APP Inventor. Переводчик
Ai2 APP Inventor. Переводчик Raqamli iqtisodiyotning rivojlanish bosqichlari
Raqamli iqtisodiyotning rivojlanish bosqichlari San Andreas Multiplayer. История. Возможности SA-MP
San Andreas Multiplayer. История. Возможности SA-MP Условные конструкции
Условные конструкции Әдеби мәліметтер көздерінің критикалық анализі. Плагиат және антиплагиат
Әдеби мәліметтер көздерінің критикалық анализі. Плагиат және антиплагиат IP – адреса и маски подсети
IP – адреса и маски подсети Нейронные сети и нейросетевое управление. Лекция 12
Нейронные сети и нейросетевое управление. Лекция 12 Гражданская журналистика и блоги
Гражданская журналистика и блоги Численное интегрирование
Численное интегрирование Источники информации
Источники информации