- Хранение данных и доступ к ним

Содержание
- 2. Цели лекции Будут рассмотрены структуры хранения данных, доступ к данным, их буферирование, индексы, представления таблиц в
- 3. Часть 1. Структуры хранения (1/4) Замечание: терминология, применяемая в различных базах данных, различается существенно. Наша терминосистема
- 4. Структуры хранения (2/4) Табличные пространства состоят из сегментов, содержащих хранимые объекты базы, например, таблицы, индексы. Каждому
- 5. Замечание: Это структура данных для СУБД Oracle. © Бессарабов Н.В.2014 Структуры хранения (3/4)
- 6. Структуры хранения (4/4) Блок базы, в другой терминологии страница памяти, это минимальная единица хранения, которой база
- 7. Часть 2. Индексы Индексы могут ускорить доступ к данным, но не всегда это делают, зато могут
- 8. Иерархическая структура в таблице EMP В таблице emp хранится следующая иерархия: Пример запроса сверху вниз начиная
- 9. Пример работы B*-индекса (1/2) Выборка из EMP по условию ENAME=BLAKE. Работает индекс на ENAME ROWID для
- 10. Пример работы B*-индекса (2/2) Как работает индекс в примере выше? Сначала просматривается корневой блок и по
- 11. О работе B*-индекса (1/2) В общем случае при поиске по значению ключа или по диапазону значений
- 12. О работе B*-индекса (2/2) Если строки индекса постоянно удаляются и добавляются, то через какое-то время индекс
- 13. Когда B*-индекс ускоряет запрос? В материалах Oracle 80-х -90-х годов можно было найти “золотое правило”, в
- 14. Индексы битовой карты (1/2) Побитовые (BitMapped) индексы это разновидность не уникальных индексов. Побитовые индексы эффективны при
- 15. Операции с такими индексами могут выполняться очень быстро, так как логические операции над битовыми матрицами транслируются
- 16. Часть 3. Доступ к данным Кэш буферов данных, реализующий алгоритм LRU Логическая схема: 1. Физическое чтение.
- 17. Доступ к единственной таблице Существует два варианта доступа к одной таблице: Полное сканирование таблицы. Индексный доступ
- 18. Соединения Рассмотренные ранее (воображаемые!) алгоритмы выполнения запросов SQL к нескольким таблицам, основаны на создании декартового произведения,
- 19. Соединение при помощи вложенных циклов Внешний цикл выполняет фактически однотабличный запрос к ведущей таблице, используя только
- 20. Соединение хешированием Два цикла выполняют фактически независимые оптимизированные однотаб- личные запросы к исходным таблицам, используя для
- 21. Соединение с сортировкой слиянием Таблицы считываются независимо. Оба результирующих набора предварительно сортируются по ключу соединения и
- 22. Сравнения соединений Соединение при помощи вложенных циклов каждый раз формирует в оперативной памяти единственную строку результата.
- 23. Часть 4. Планы исполнения Создавая запрос SQL пользователь указывает какими свойствами обладают нужные ему данные, но
- 24. Оптимизация по правилам и по стоимости Два основных способа: Оптимизация по правилам (RULE BASED). Учитываются только
- 25. Ранжирование методов доступа © Бессарабов Н.В.2014
- 26. Статистики для оптимизатора по стоимости CBO-оптимизатор использует для определения стоимости пути доступа статистики: число элементов таблицы,
- 27. Подсказки Управлять планом исполнения можно размещая после слова SELECT подсказки в виде комментариев специального вида (hints).
- 28. Примеры планов исполнения (1/5) Освоение SQL-настройки требует знания массы сведений об используемой СУБД, её физической организации
- 29. Примеры планов исполнения (2/5) Примеры планов: 1. Простейший запрос SELECT * FROM emp; План исполнения: SELECT
- 30. Примеры планов исполнения (3/5) 4. Тот же запрос SELECT * FROM emp ORDER BY ename; но
- 31. Примеры планов исполнения (4/5) 6. Доступ по значению ROWID. Запрос: SELECT * FROM emp WHERE rowid=‘00004F2A00A2000C’;
- 32. Примеры планов исполнения (5/5) 9. Сортировка слиянием SELECT * FROM emp, dept WHERE emp.deptno=dept.deptno; План исполнения:
- 34. Скачать презентацию

Цели лекции
Будут рассмотрены структуры хранения данных, доступ к данным,
их
Цели лекции
Будут рассмотрены структуры хранения данных, доступ к данным,
их

Часть 1. Структуры хранения (1/4)
Замечание: терминология, применяемая в различных базах данных,
Часть 1. Структуры хранения (1/4)
Замечание: терминология, применяемая в различных базах данных,

Структуры хранения (2/4)
Табличные пространства состоят из сегментов, содержащих
хранимые объекты
Структуры хранения (2/4)
Табличные пространства состоят из сегментов, содержащих
хранимые объекты
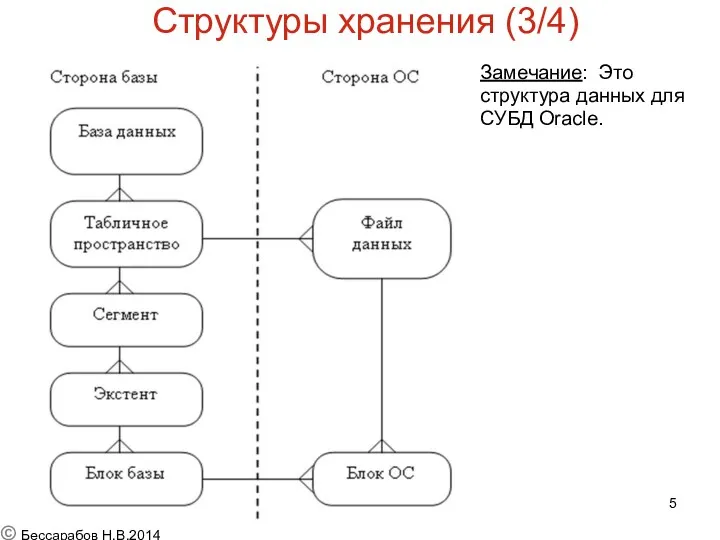
Замечание: Это
структура данных для
СУБД Oracle.
© Бессарабов Н.В.2014
Структуры хранения (3/4)
Замечание: Это
структура данных для
СУБД Oracle.
© Бессарабов Н.В.2014
Структуры хранения (3/4)
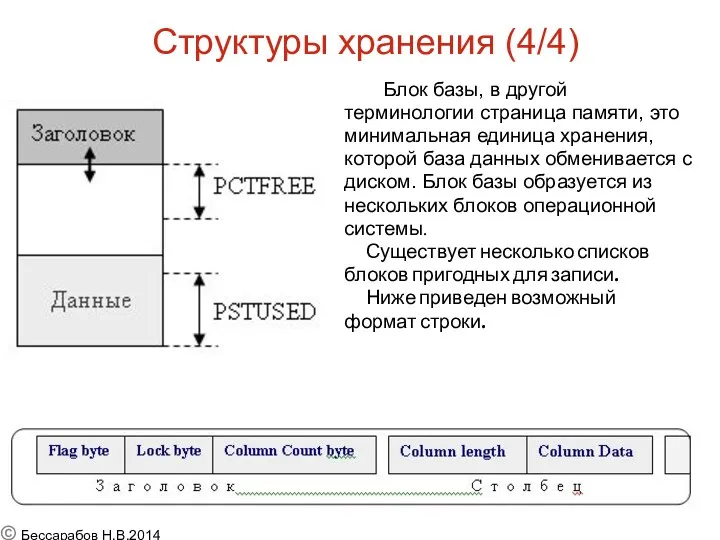
Структуры хранения (4/4)
Блок базы, в другой
терминологии страница памяти, это
Структуры хранения (4/4)
Блок базы, в другой
терминологии страница памяти, это

Часть 2. Индексы
Индексы могут ускорить доступ к данным, но не всегда
Часть 2. Индексы
Индексы могут ускорить доступ к данным, но не всегда
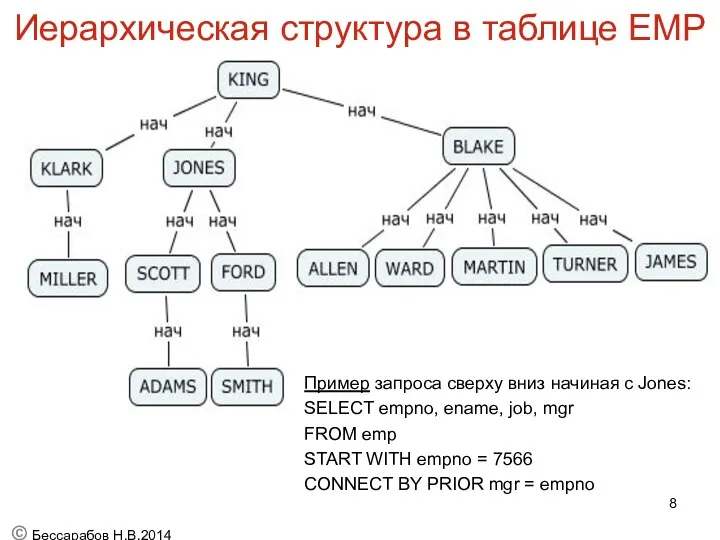
Иерархическая структура в таблице EMP
В таблице emp хранится следующая иерархия:
Пример
Иерархическая структура в таблице EMP
В таблице emp хранится следующая иерархия:
Пример
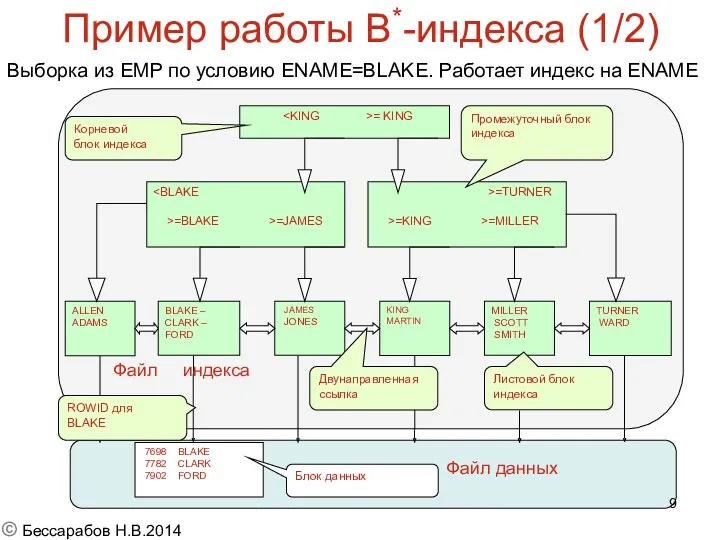
Пример работы B*-индекса (1/2)
Выборка из EMP по условию ENAME=BLAKE. Работает индекс
Пример работы B*-индекса (1/2)
Выборка из EMP по условию ENAME=BLAKE. Работает индекс

Пример работы B*-индекса (2/2)
Как работает индекс в примере выше?
Сначала просматривается корневой
Пример работы B*-индекса (2/2)
Как работает индекс в примере выше?
Сначала просматривается корневой

О работе B*-индекса (1/2)
В общем случае при поиске по значению ключа
О работе B*-индекса (1/2)
В общем случае при поиске по значению ключа

О работе B*-индекса (2/2)
Если строки индекса постоянно удаляются и добавляются, то
О работе B*-индекса (2/2)
Если строки индекса постоянно удаляются и добавляются, то

Когда B*-индекс ускоряет запрос?
В материалах Oracle 80-х -90-х годов
Когда B*-индекс ускоряет запрос?
В материалах Oracle 80-х -90-х годов

Индексы битовой карты (1/2)
Побитовые (BitMapped) индексы это разновидность не
уникальных
Индексы битовой карты (1/2)
Побитовые (BitMapped) индексы это разновидность не
уникальных
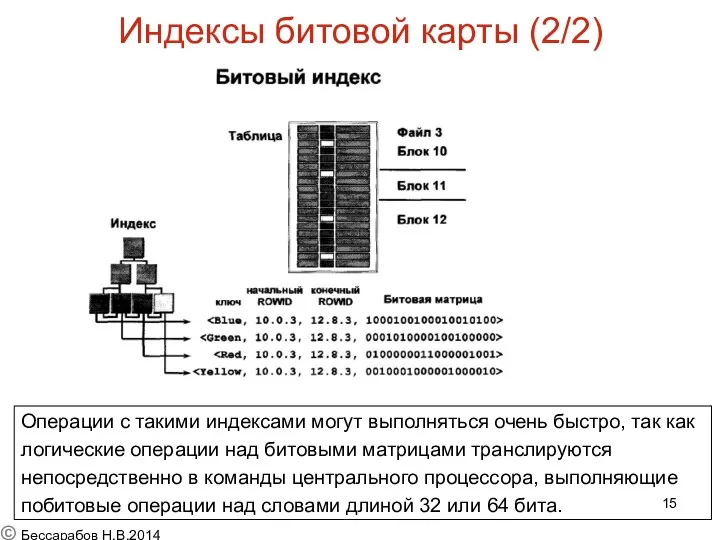
Операции с такими индексами могут выполняться очень быстро, так как
логические
Операции с такими индексами могут выполняться очень быстро, так как
логические
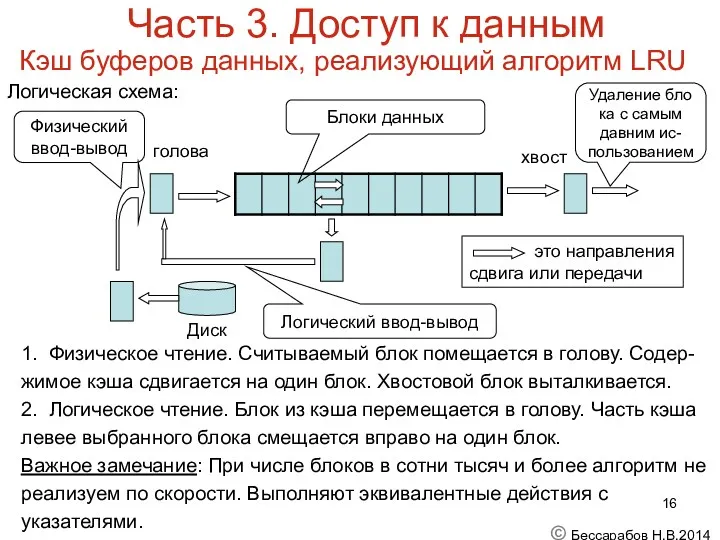
Часть 3. Доступ к данным
Кэш буферов данных, реализующий алгоритм LRU
Логическая
Часть 3. Доступ к данным
Кэш буферов данных, реализующий алгоритм LRU
Логическая

Доступ к единственной таблице
Существует два варианта доступа к одной таблице:
Полное сканирование
Доступ к единственной таблице
Существует два варианта доступа к одной таблице:
Полное сканирование

Соединения
Рассмотренные ранее (воображаемые!) алгоритмы выполнения
запросов SQL к нескольким таблицам,
Соединения
Рассмотренные ранее (воображаемые!) алгоритмы выполнения
запросов SQL к нескольким таблицам,
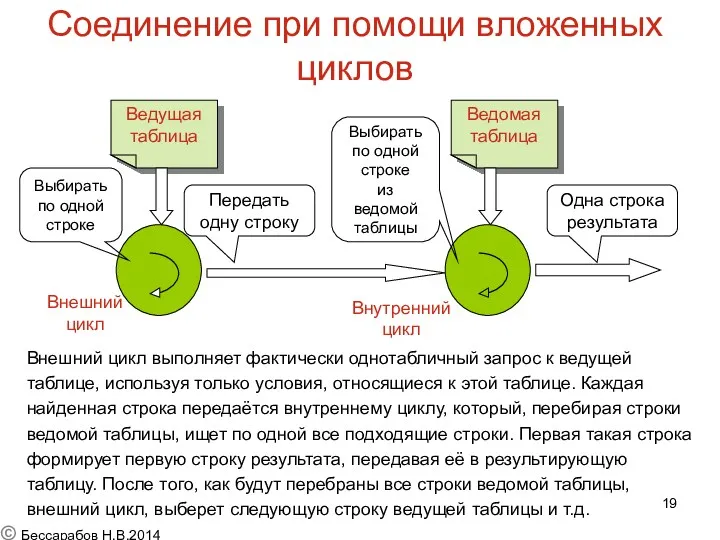
Соединение при помощи вложенных циклов
Внешний цикл выполняет фактически однотабличный запрос к
Соединение при помощи вложенных циклов
Внешний цикл выполняет фактически однотабличный запрос к
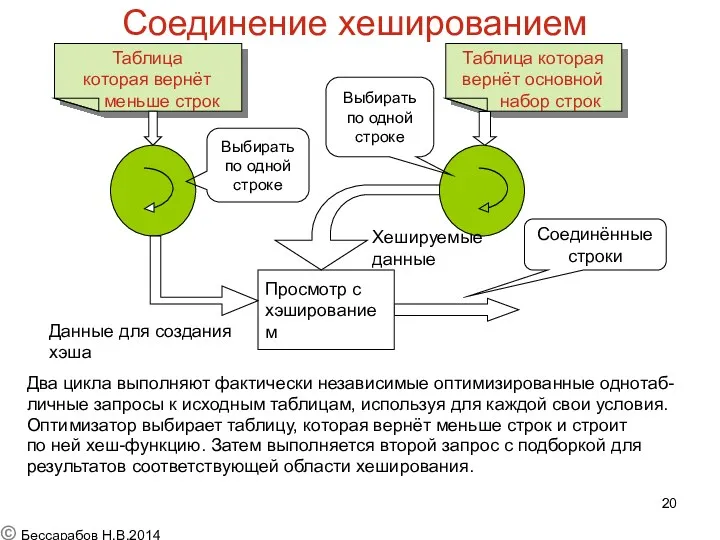
Соединение хешированием
Два цикла выполняют фактически независимые оптимизированные однотаб-
личные запросы к исходным
Соединение хешированием
Два цикла выполняют фактически независимые оптимизированные однотаб-
личные запросы к исходным
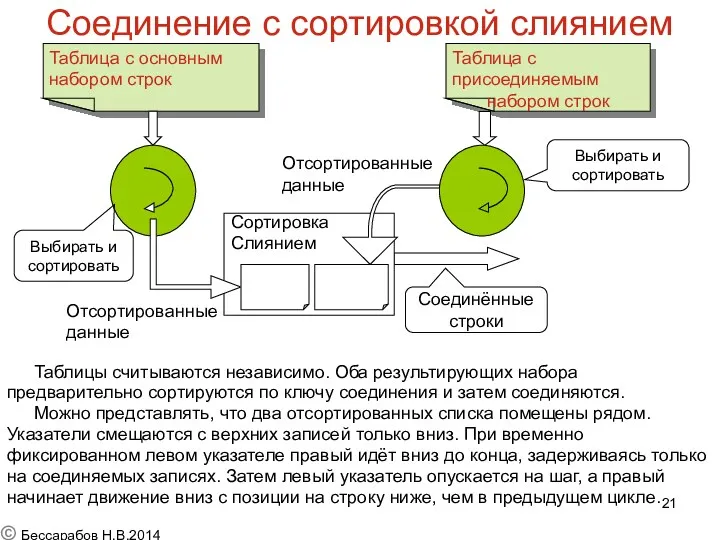
Соединение с сортировкой слиянием
Таблицы считываются независимо. Оба результирующих набора
предварительно сортируются
Соединение с сортировкой слиянием
Таблицы считываются независимо. Оба результирующих набора
предварительно сортируются

Сравнения соединений
Соединение при помощи вложенных циклов каждый раз формирует в
Сравнения соединений
Соединение при помощи вложенных циклов каждый раз формирует в

Часть 4. Планы исполнения
Создавая запрос SQL пользователь указывает какими свойствами
Часть 4. Планы исполнения
Создавая запрос SQL пользователь указывает какими свойствами

Оптимизация по правилам и по стоимости
Два основных способа:
Оптимизация по правилам (RULE
Оптимизация по правилам и по стоимости
Два основных способа:
Оптимизация по правилам (RULE

Ранжирование методов доступа
© Бессарабов Н.В.2014
Ранжирование методов доступа
© Бессарабов Н.В.2014

Статистики для оптимизатора по стоимости
CBO-оптимизатор использует для определения стоимости пути
Статистики для оптимизатора по стоимости
CBO-оптимизатор использует для определения стоимости пути
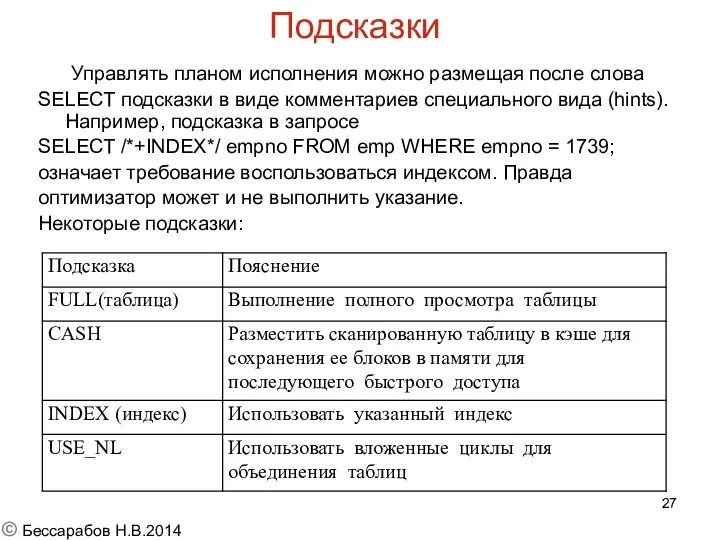
Подсказки
Управлять планом исполнения можно размещая после слова
SELECT подсказки
Подсказки
Управлять планом исполнения можно размещая после слова
SELECT подсказки

Примеры планов исполнения (1/5)
Освоение SQL-настройки требует знания массы сведений об
Примеры планов исполнения (1/5)
Освоение SQL-настройки требует знания массы сведений об

Примеры планов исполнения (2/5)
Примеры планов:
1. Простейший запрос
SELECT * FROM emp;
План
Примеры планов исполнения (2/5)
Примеры планов:
1. Простейший запрос
SELECT * FROM emp;
План

Примеры планов исполнения (3/5)
4. Тот же запрос
SELECT * FROM emp
Примеры планов исполнения (3/5)
4. Тот же запрос
SELECT * FROM emp

Примеры планов исполнения (4/5)
6. Доступ по значению ROWID. Запрос:
SELECT *
Примеры планов исполнения (4/5)
6. Доступ по значению ROWID. Запрос:
SELECT *

Примеры планов исполнения (5/5)
9. Сортировка слиянием
SELECT * FROM emp, dept
Примеры планов исполнения (5/5)
9. Сортировка слиянием
SELECT * FROM emp, dept
 Компьютерные технологии интеллектуальной поддержки управленческих решений
Компьютерные технологии интеллектуальной поддержки управленческих решений Задача линейного программирования и способы решения
Задача линейного программирования и способы решения Презентация Необычное кулинарное путешествие
Презентация Необычное кулинарное путешествие Середовище описання і виконання алгоритмів
Середовище описання і виконання алгоритмів Графики и диаграммы
Графики и диаграммы Цифровой офис
Цифровой офис Технологии проектирования компьютерных систем. Методы проектирования цифровых устройств. (Лекция 1)
Технологии проектирования компьютерных систем. Методы проектирования цифровых устройств. (Лекция 1) Основы html/css
Основы html/css Форматирование текста. Обработка текстовой информации. 7 класс
Форматирование текста. Обработка текстовой информации. 7 класс Электронные сервисы Фонда социального страхования РФ (ФСС) - круглый стол
Электронные сервисы Фонда социального страхования РФ (ФСС) - круглый стол Презентация к уроку информатики в 8 классе на тему Измерение информации
Презентация к уроку информатики в 8 классе на тему Измерение информации Облачный сервис 1С:Предприятие 8 через Интернет (1сfresh.com)
Облачный сервис 1С:Предприятие 8 через Интернет (1сfresh.com) Перевод чисел в позиционных системах счисления
Перевод чисел в позиционных системах счисления Виртуальная и дополненная реальность и их отличия. Иммерсивные технологии и здоровье человека
Виртуальная и дополненная реальность и их отличия. Иммерсивные технологии и здоровье человека Возможная архитектура (состав инструментов) электронного правительства
Возможная архитектура (состав инструментов) электронного правительства Сектор удаленного обслуживания центральной городской библиотеки
Сектор удаленного обслуживания центральной городской библиотеки Глобальные сети. Основные понятия и определения
Глобальные сети. Основные понятия и определения Моделирование БП для КИС. Определение КИС.1. Тема 2
Моделирование БП для КИС. Определение КИС.1. Тема 2 Информация и её свойства. Информация и информационные процессы. Информатика. 7 класс
Информация и её свойства. Информация и информационные процессы. Информатика. 7 класс Історія засобів опрацювання інформаційних об’єктів. Технічні характеристики складових комп’ютера. Практична робота №2
Історія засобів опрацювання інформаційних об’єктів. Технічні характеристики складових комп’ютера. Практична робота №2 Системный анализ безопасности
Системный анализ безопасности Организация ввода и вывода данных. Начала программирования
Организация ввода и вывода данных. Начала программирования Обработка массива
Обработка массива Презентация на урок Фрагмент текста и операции с ним
Презентация на урок Фрагмент текста и операции с ним Алгоритми та їх виконавці
Алгоритми та їх виконавці Стохастические модели
Стохастические модели Язык разметки гипертекста
Язык разметки гипертекста Kofax Transformation Modules 5. Introduction to Class Training
Kofax Transformation Modules 5. Introduction to Class Training