- JDBC

Содержание
- 2. My SQL – установка Шаг-1
- 3. My SQL – установка Шаг-2
- 4. My SQL – установка Шаг-3
- 5. My SQL – установка Шаг-4
- 6. My SQL – установка Шаг-5
- 7. My SQL – установка Шаг-6
- 8. My SQL – установка Шаг-7
- 9. My SQL – установка Шаг-8
- 10. My SQL – установка Шаг-9
- 11. My SQL – установка Шаг-10
- 12. My SQL – установка Шаг-10
- 13. My SQL – установка Шаг-11
- 14. My SQL – установка Шаг-12
- 15. My SQL – установка Шаг-13
- 16. My SQL – установка Шаг-14
- 17. My SQL – установка Шаг-15
- 18. My SQL – установка Шаг-16
- 19. My SQL – установка Шаг-17
- 20. My SQL – установка Шаг-18
- 21. My SQL – установка Шаг-19
- 22. My SQL – установка Шаг-20
- 23. MySQL Workbench Стартовая страница.
- 24. MySQL Workbench Авторизация.
- 25. MySQL Workbench Рабочее окно.
- 26. Итак, что нужно установить? Основные программы (https://dev.mysql.com/downloads/mysql) MySQL Server MySQL Workbench MySQL Connector/J Дополнительные программы: DbVisualizer
- 27. Предпосылки проблемы Любое приложение так или иначе будет обслуживать данные (информацию), которые необходимы пользователям приложения. Приложение
- 28. Предпосылки проблемы Под «обслуживанием» можно понимать: Сохранение данных в персистентном (постоянном) хранилище. Извлечение данных из хранилища.
- 29. Предпосылки проблемы Следовательно, для любого приложения программист создаст: Алгоритмы для бизнес процессов приложения. Модель, хранящую все
- 30. Проблема С точки зрения человека. Алгоритмы для обслуживания данных всегда будут сложнее алгоритмов бизнес логики. Они
- 31. Проблема С точки зрения машины. Хранилище может предоставить данные, но оно не всегда предоставляет описание хранимых
- 32. Возможное решение проблемы С каждым новым приложением программист работает над алгоритмами по обслуживанию данных. Со временем
- 33. Возможное решение проблемы Таким образом, программист понимает, что хорошо бы иметь в своем арсенале: Теорию, которая
- 34. И наконец – решение База Данных: Теория, фундаментальные вопросы по описанию данных и доступу к ним.
- 35. Термины, сокращения, переводы
- 36. Таблица в БД Таблица – Основной элемент базы данных. Одна таблица хранит данные всех сущностей (объектов)
- 37. Таблица в БД
- 38. Столбец в таблице Один столбец описывает одно свойство сущности. Каждый столбец должен иметь имя. Имя столбца
- 39. Типы данных в MySQL Numeric Types (Числа) Date and Time Types (Дата и время) String Types
- 40. Служебные столбцы Любая таблица может иметь столбцы, которые «не интересны» пользователю, но необходимы для функционирования БД.
- 41. Первичный ключ Primary Key Одна из главных задач СУБД – обеспечить уникальность записей в таблице. За
- 42. Виды первичных ключей AUTO_INCREMENT наиболее популярный Natural Primary Key натуральный первичный ключ. любой столбец, с уникальными
- 43. Внешний ключ Foreign Key Внешний ключ – это специальный столбец, который хранит значения первичных ключей из
- 44. Отношения таблиц Рассматривать внешний ключ тяжело без понятия «отношения между таблицами» Давайте по рассуждаем: Любое приложение
- 45. Отношения таблиц Но приложению «не интересно», знать данные только из одной таблицы Например, «не интересно» знать,
- 46. Таким образом Кроме самих таблиц, в БД большое значение имеют Отношения между таблицами Все таблицы находятся
- 47. Как создать внешний ключ?
- 48. Какие бывают отношения? One-To-Many – Один ко многим Many-To-One – Многие к одному Many-To-Many – Многие
- 49. One-To-Many Самое популярное отношение Означает, что Одна сущность главной таблицы может владеть множеством сущностей из подчиненной
- 50. One-To-Many - пример
- 51. Many-To-One Это такая же связь, как и One-To-Many Реализуется она точно так же: Добавлением внешнего ключа
- 52. Many-To-Many Означает, что: Одна сущность главной таблицы может владеть множеством сущностей из подчиненной таблицы, но и
- 53. Many-To-Many - пример
- 54. One-To-One Довольно редкая связь Означает, что: Одна сущность из главной таблицей может владеть только одной сущностью
- 55. One-To-One - пример
- 56. BD SCHEMA
- 57. Что насупился весь И сидишь как буржуй? Раз возникла проблема Ты сопли не жуй!!! Не станет
- 58. SQL – Условное деление
- 59. Команда CREATE При помощи команды CREATE можно создать следующие элементы Базы Данных: Базу данных (Схему БД)
- 60. CREATE для Базы Данных CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] `db_name` [CHARACTER SET charset_name] [COLLATE
- 61. CREATE для Базы Данных. Пояснения. Character set – кодировка, в которой СУБД будет представлять символы, хранящиеся
- 62. CREATE для Базы Данных. Пояснения. Каждая СУБД имеет некоторую кодировку по умолчанию. Она указывается при установке
- 63. СУБД не поддерживает UTF-8. Логическая задача. Условие: Java-программист работает под СУБД, которая не поддерживает кодировку UTF-8.
- 64. CREATE для таблицы CREATE TABLE [IF NOT EXISTS] `db_name` .`tbl_name` ( create_definition ); Здесь create_definition –
- 65. CREATE для таблицы. Пример. CREATE TABLE ` TRAINING_DB `.`STUDENTS` ( `PK_STUDENT_ID` INTEGER NOT NULL AUTO_INCREMENT, `FIRST_NAME`
- 66. CREATE для индекса CREATE INDEX index_name ON tbl_name
- 67. Синтаксис команды DROP DROP {DATABASE | SCHEMA} [IF EXISTS] db_name DROP TABLE [IF EXISTS] tbl_name-1, tbl_name-1,
- 68. SQL - DDL
- 69. SQL - DML INSERT UPDATE DELETE SELECT
- 70. Синтаксис команды INSERT INSERT INTO tbl_name (col-1, col-2, ...) VALUES (val-1, val-1, ...); Примеры: INSERT INTO
- 71. Синтаксис команды UPDATE UPDATE tbl_name SET col-1 = expr-1, col-2 = expr-2, ... [WHERE where_condition]; Примеры:
- 72. Синтаксис команды DELETE DELETE FROM tbl_name [WHERE where_condition]; Примеры: DELETE FROM ACCOUNTS; DELETE FROM ACCOUNTS WHERE
- 73. Синтаксис команды SELECT SELECT [DISTINCT] select_expr, ... FROM table_references [WHERE where_condition] [ORDER BY col_name [ASC |
- 74. Пример SELECT Выбрать все записи из ACCOUNTS SELECT `login`, `password` FROM ACCOUNTS SELECT * FROM ACCOUNTS
- 75. Пример SELECT Выбрать всех админов SELECT * FROM ACCOUNTS WHERE `login` = ‘Admin’
- 76. Пример SELECT Выбрать всех умных админов ☺ SELECT * FROM ACCOUNTS WHERE `login` = ‘Admin’ AND
- 77. Архитектура JDBC
- 78. Архитектура JDBC JDBC API – поставляется компанией SUN. JDBC API служит для соединения с любой базой
- 79. Архитектура JDBC Ответ – они не написали ни строки кода для работы с определенной СУБД. JDBC
- 80. Работа с БД на Java Последовательность шагов Подключить JDBC драйвер для СУБД. Соединиться с Базой Данных.
- 81. Шаг 1 – JDBC Драйвер для СУБД
- 82. Шаг 1 – JDBC Драйвер для СУБД Как уже говорили JDBC – это всего лишь интерфейсы.
- 83. Шаг 1 – JDBC Драйвер для СУБД Подключение драйвера проходит в два этапа: Загрузка JAR-файла драйвера
- 84. Шаг 1.1 – Загрузка JAR-файла в CLASS_PATH.
- 85. Шаг 1. 2 – загрузка драйвера в коде 1. Когда драйвер грузится плохо!
- 86. Шаг 1. 2 – загрузка драйвера в коде 2. Когда драйвер грузится хорошо ☺
- 87. Шаг 2 – Соединение с БД
- 88. Шаг 3 Выполнение SQL запросов Объект Statement
- 89. Шаг 4 – обработка результатов. Объект ResultSet.
- 90. Шаг 5 – закрытие ресурсов.
- 91. All in One
- 92. Connection Pool Connection к БД – это «ресурс», который нужно получить. Мы говорили, что после обработки
- 93. Tomcat Connection Pool Step 1 – server.xml
- 94. Tomcat Connection Pool Step 2 – context.xml
- 95. Tomcat Connection Pool Step 3 – web.xml
- 97. Скачать презентацию

My SQL – установка
Шаг-1
My SQL – установка
Шаг-1
My SQL – установка
Шаг-2
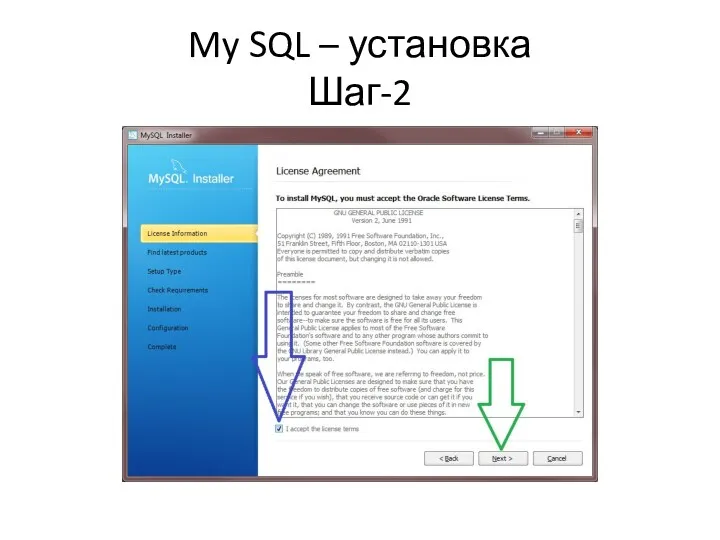
My SQL – установка
Шаг-2
My SQL – установка
Шаг-3
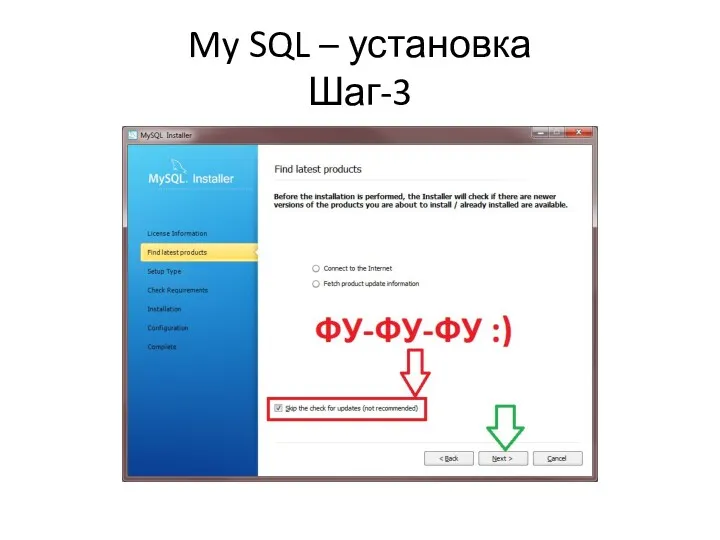
My SQL – установка
Шаг-3
My SQL – установка
Шаг-4
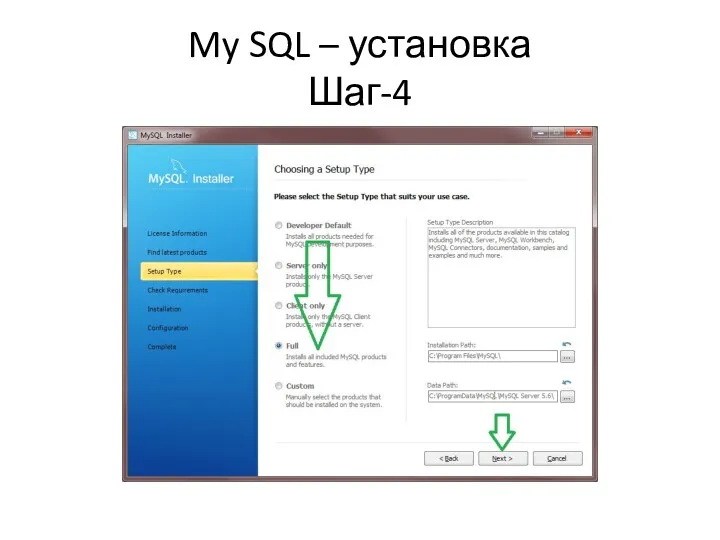
My SQL – установка
Шаг-4
My SQL – установка
Шаг-5
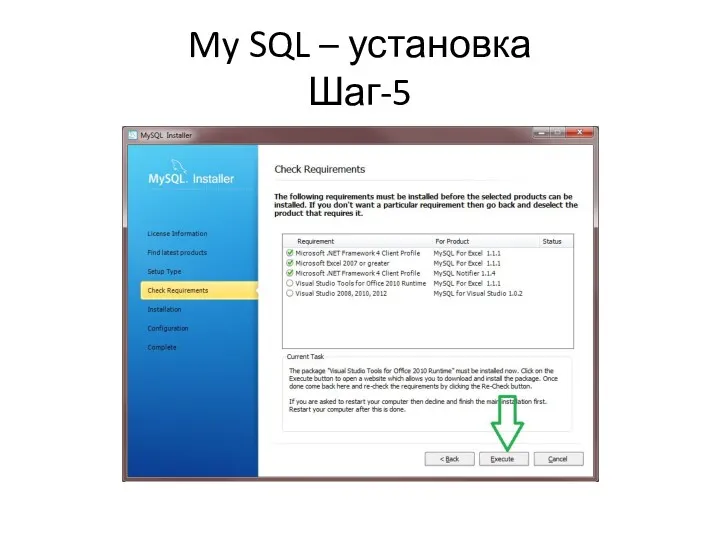
My SQL – установка
Шаг-5
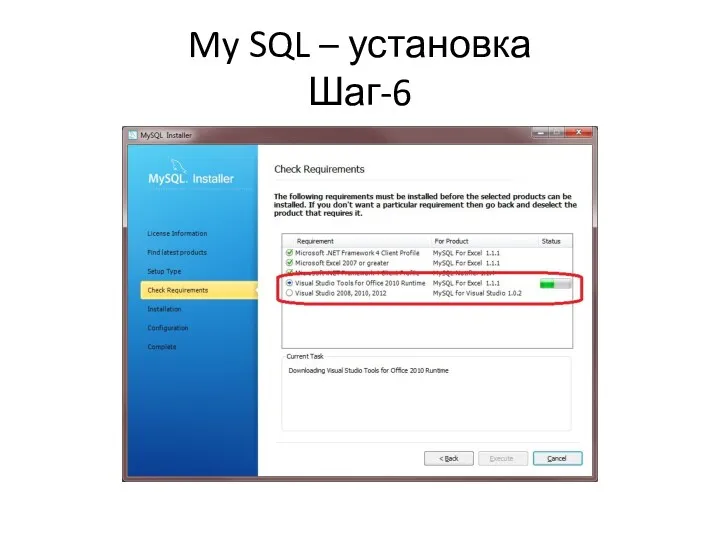
My SQL – установка
Шаг-6
My SQL – установка
Шаг-6
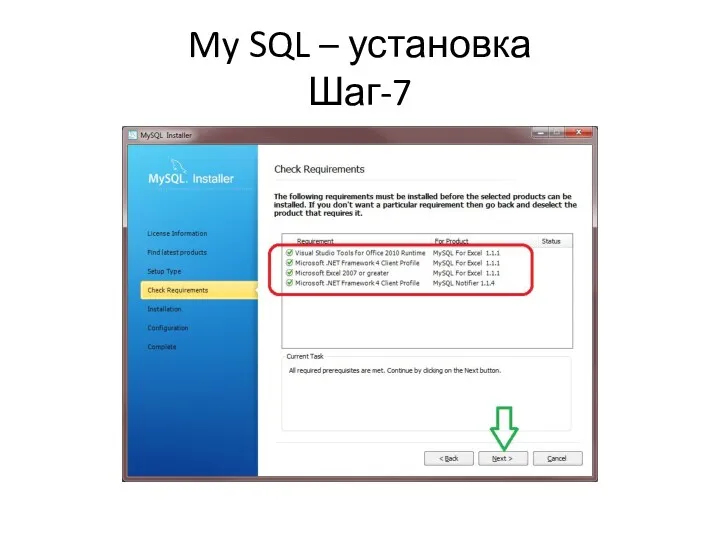
My SQL – установка
Шаг-7
My SQL – установка
Шаг-7
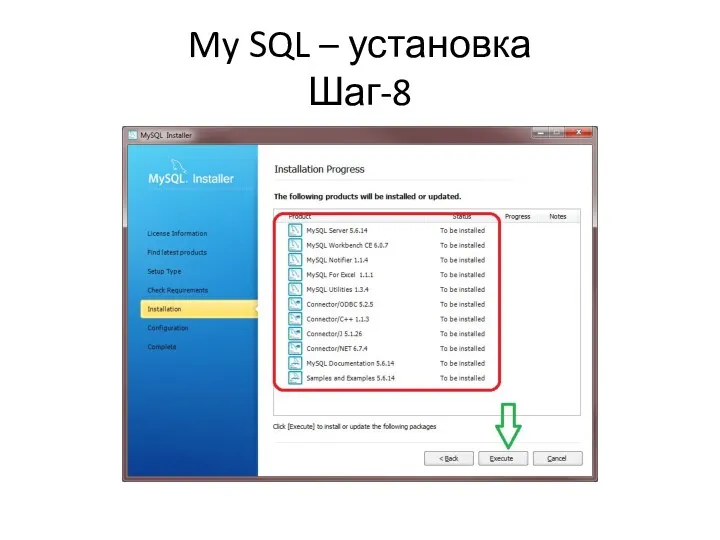
My SQL – установка
Шаг-8
My SQL – установка
Шаг-8
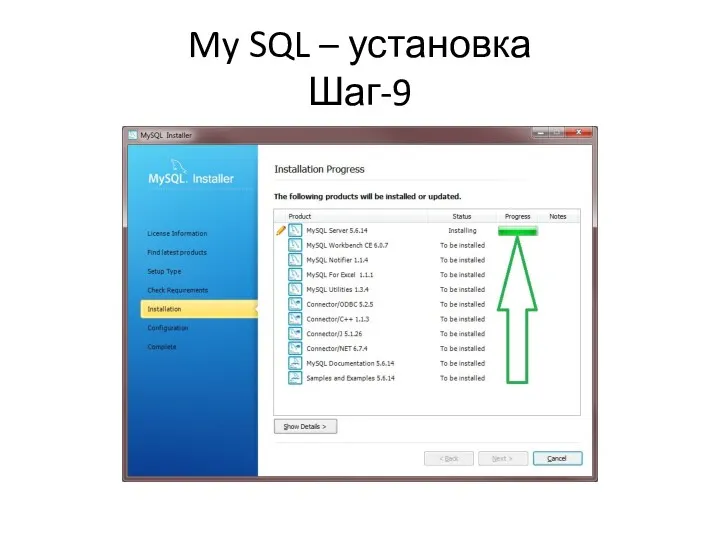
My SQL – установка
Шаг-9
My SQL – установка
Шаг-9
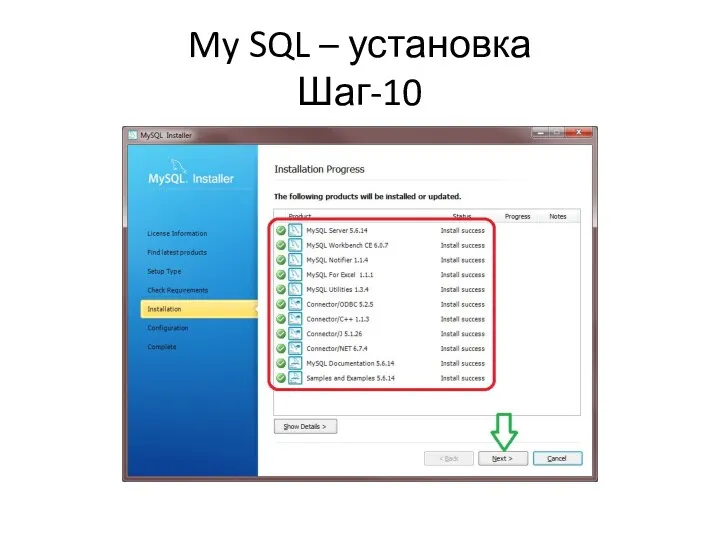
My SQL – установка
Шаг-10
My SQL – установка
Шаг-10
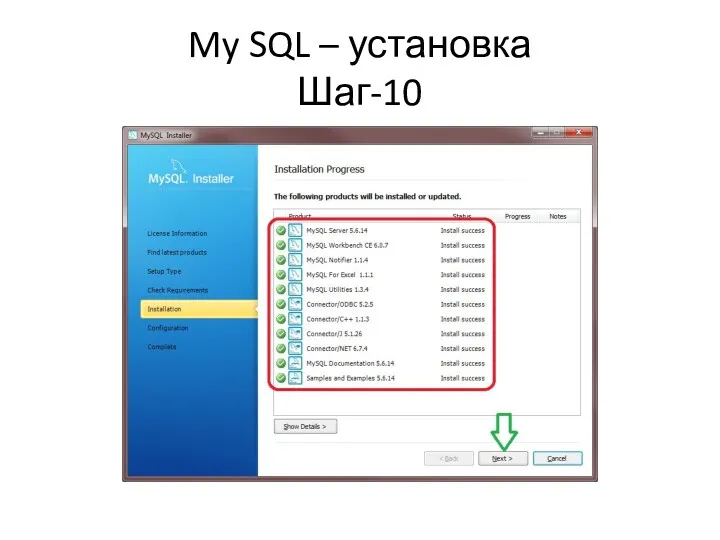
My SQL – установка
Шаг-10
My SQL – установка
Шаг-10
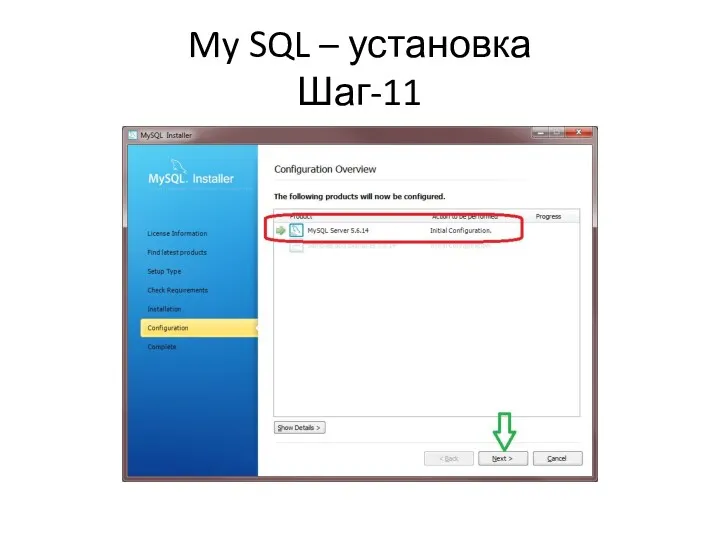
My SQL – установка
Шаг-11
My SQL – установка
Шаг-11
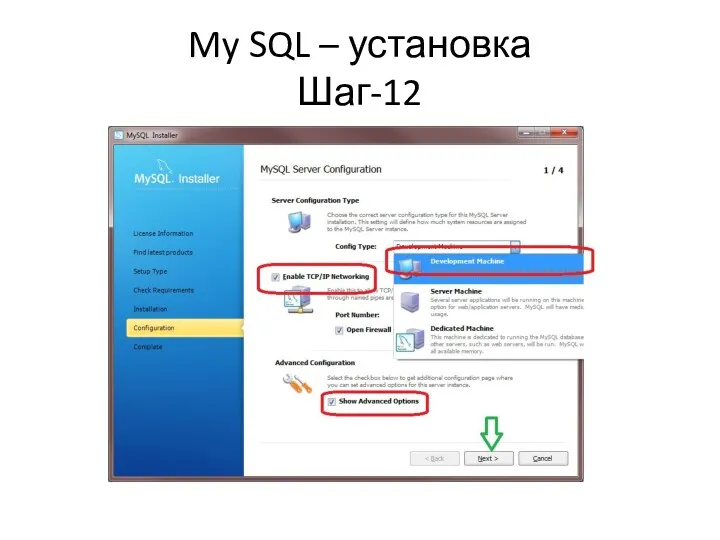
My SQL – установка
Шаг-12
My SQL – установка
Шаг-12
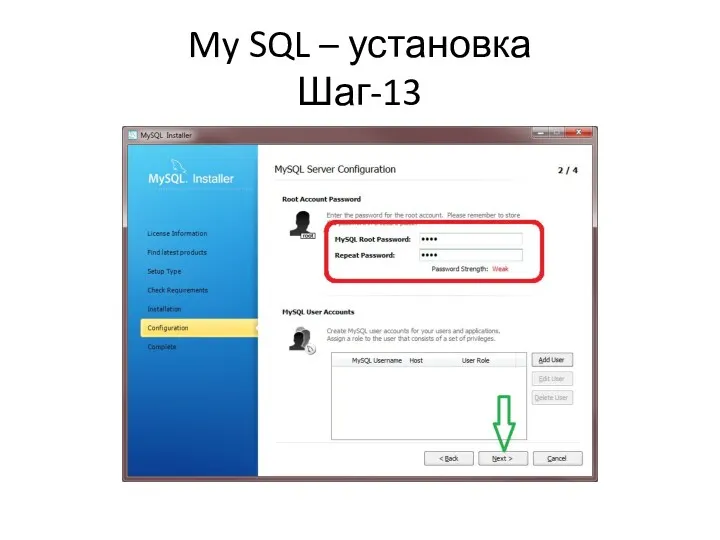
My SQL – установка
Шаг-13
My SQL – установка
Шаг-13
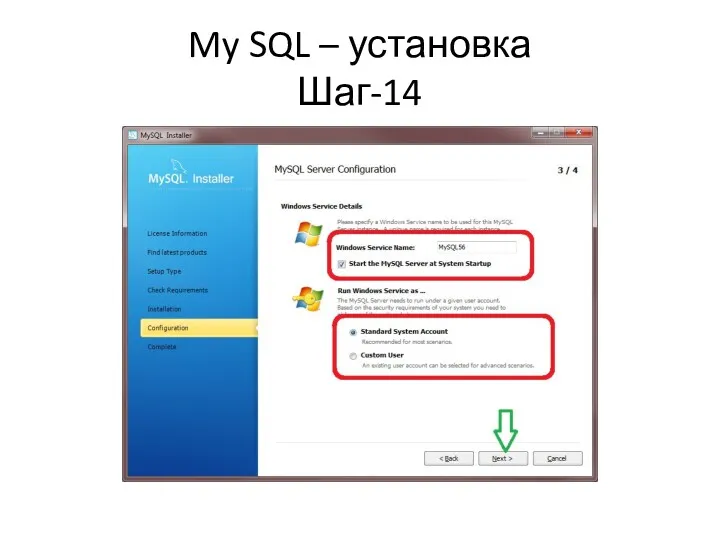
My SQL – установка
Шаг-14
My SQL – установка
Шаг-14
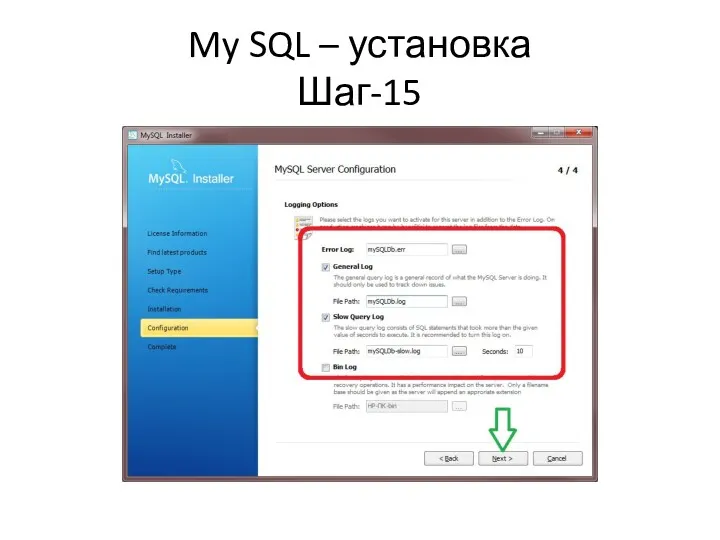
My SQL – установка
Шаг-15
My SQL – установка
Шаг-15
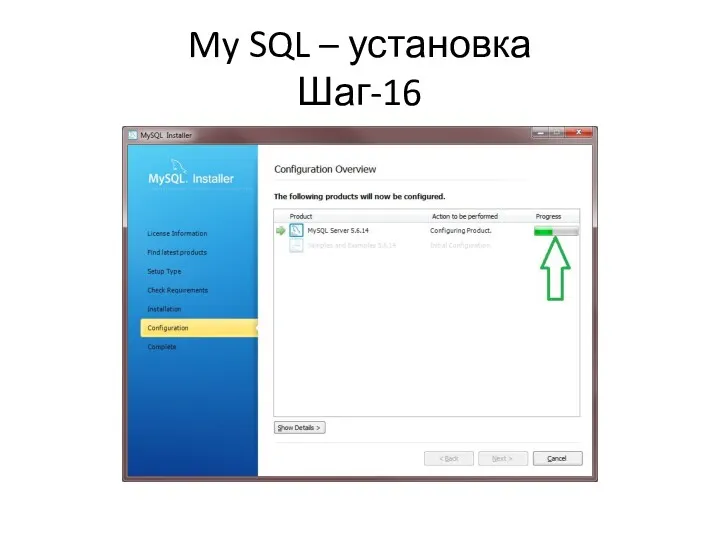
My SQL – установка
Шаг-16
My SQL – установка
Шаг-16
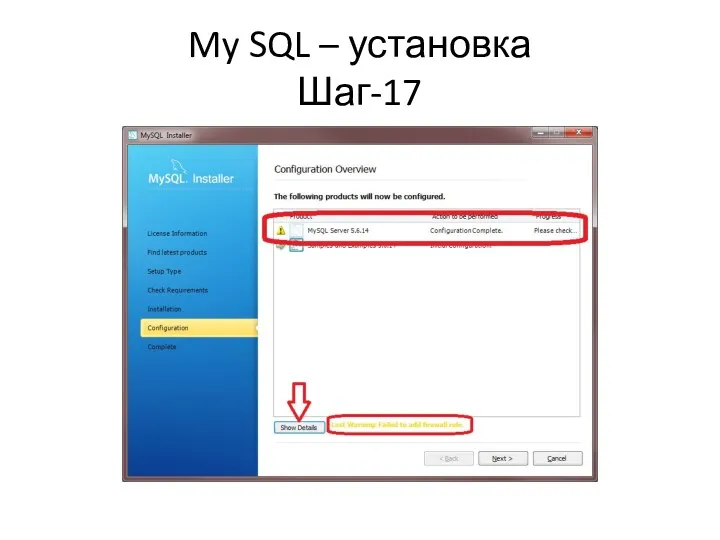
My SQL – установка
Шаг-17
My SQL – установка
Шаг-17
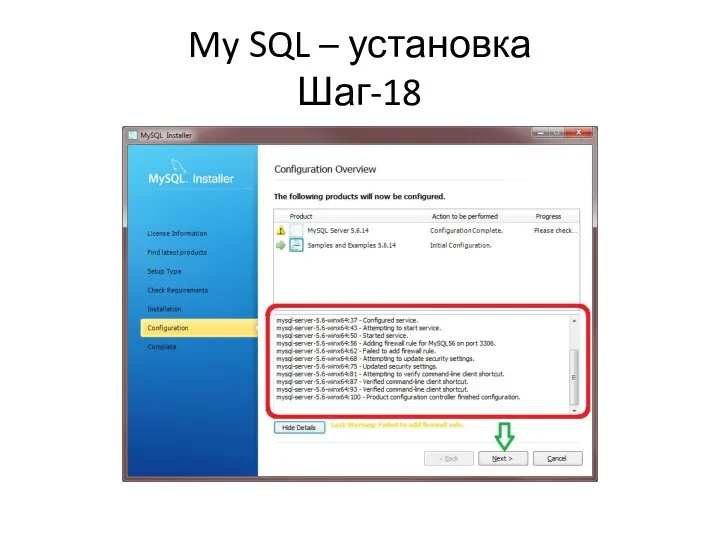
My SQL – установка
Шаг-18
My SQL – установка
Шаг-18
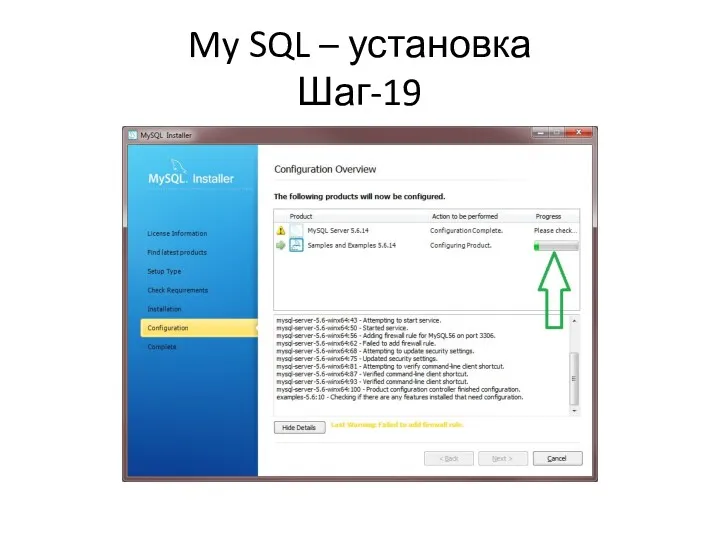
My SQL – установка
Шаг-19
My SQL – установка
Шаг-19
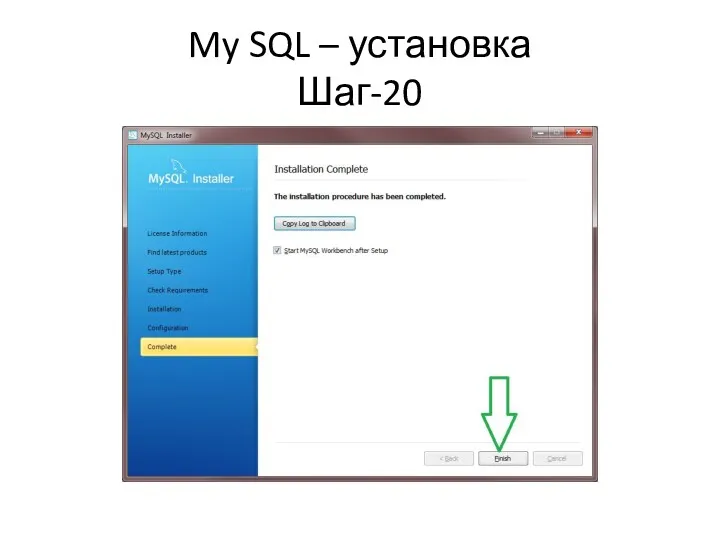
My SQL – установка
Шаг-20
My SQL – установка
Шаг-20
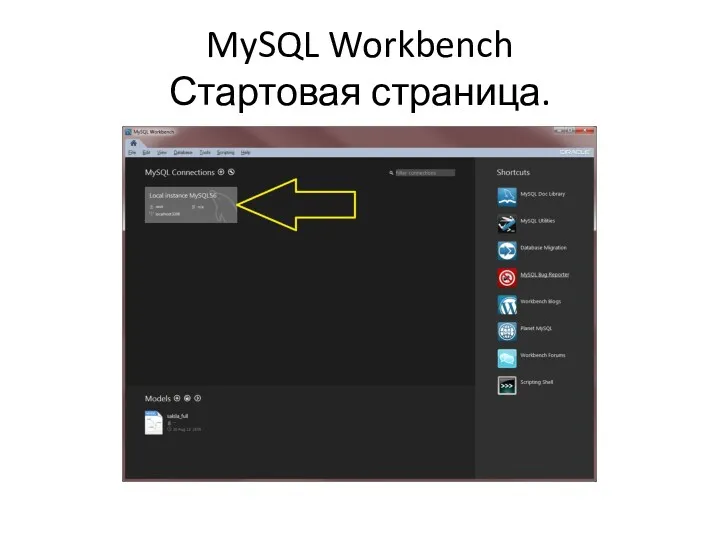
MySQL Workbench
Стартовая страница.
MySQL Workbench
Стартовая страница.
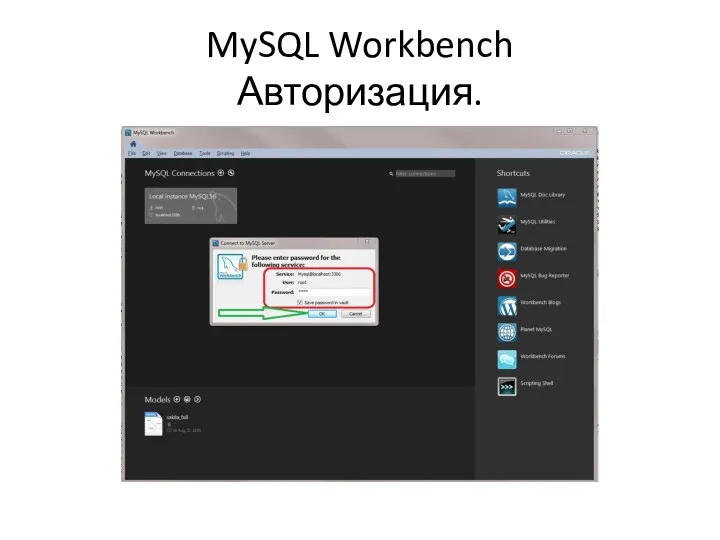
MySQL Workbench
Авторизация.
MySQL Workbench
Авторизация.
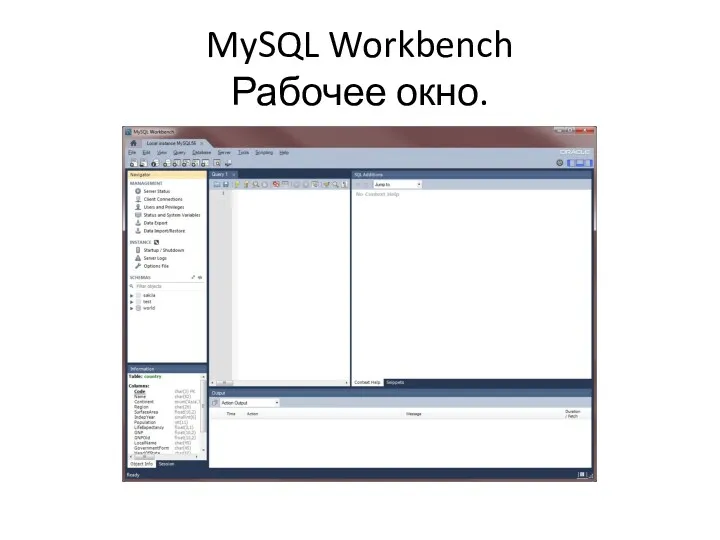
MySQL Workbench
Рабочее окно.
MySQL Workbench
Рабочее окно.

Итак, что нужно установить?
Основные программы (https://dev.mysql.com/downloads/mysql)
MySQL Server
MySQL Workbench
MySQL Connector/J
Дополнительные программы:
DbVisualizer (https://www.dbvis.com)
Итак, что нужно установить?
Основные программы (https://dev.mysql.com/downloads/mysql)
MySQL Server
MySQL Workbench
MySQL Connector/J
Дополнительные программы:
DbVisualizer (https://www.dbvis.com)

Предпосылки проблемы
Любое приложение так или иначе будет обслуживать данные (информацию), которые
Предпосылки проблемы
Любое приложение так или иначе будет обслуживать данные (информацию), которые

Предпосылки проблемы
Под «обслуживанием» можно понимать:
Сохранение данных в персистентном (постоянном) хранилище.
Извлечение данных
Предпосылки проблемы
Под «обслуживанием» можно понимать:
Сохранение данных в персистентном (постоянном) хранилище.
Извлечение данных

Предпосылки проблемы
Следовательно, для любого приложения программист создаст:
Алгоритмы для бизнес процессов приложения.
Модель,
Предпосылки проблемы
Следовательно, для любого приложения программист создаст:
Алгоритмы для бизнес процессов приложения.
Модель,

Проблема
С точки зрения человека.
Алгоритмы для обслуживания данных всегда будут сложнее алгоритмов
Проблема
С точки зрения человека.
Алгоритмы для обслуживания данных всегда будут сложнее алгоритмов

Проблема
С точки зрения машины.
Хранилище может предоставить данные, но оно не всегда
Проблема
С точки зрения машины.
Хранилище может предоставить данные, но оно не всегда

Возможное решение проблемы
С каждым новым приложением программист работает над алгоритмами по
Возможное решение проблемы
С каждым новым приложением программист работает над алгоритмами по

Возможное решение проблемы
Таким образом, программист понимает, что хорошо бы иметь в
Возможное решение проблемы
Таким образом, программист понимает, что хорошо бы иметь в

И наконец – решение
База Данных:
Теория, фундаментальные вопросы по описанию данных и
И наконец – решение
База Данных:
Теория, фундаментальные вопросы по описанию данных и
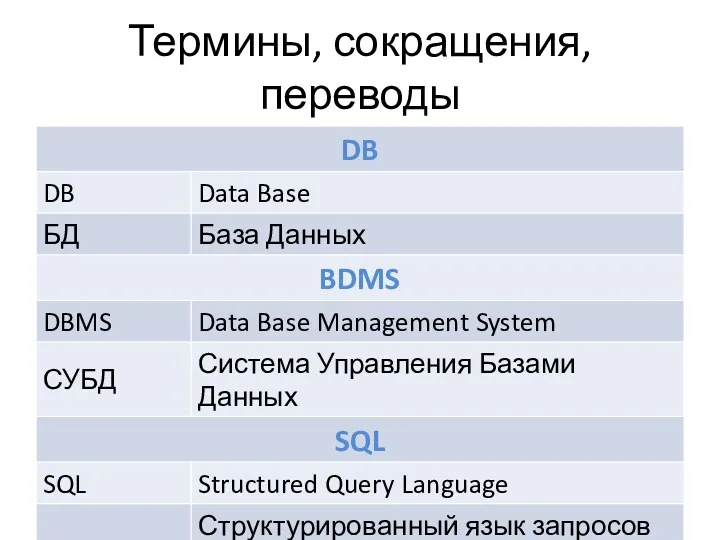
Термины, сокращения, переводы
Термины, сокращения, переводы

Таблица в БД
Таблица – Основной элемент базы данных.
Одна таблица хранит данные
Таблица в БД
Таблица – Основной элемент базы данных.
Одна таблица хранит данные
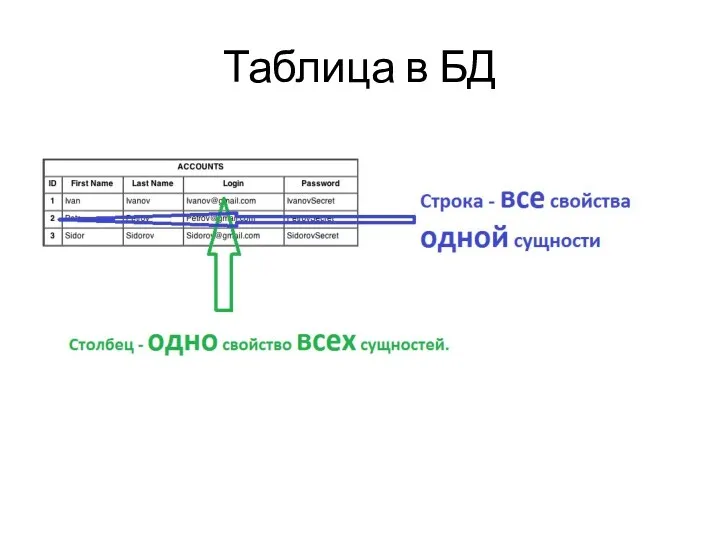
Таблица в БД
Таблица в БД

Столбец в таблице
Один столбец описывает одно свойство сущности.
Каждый столбец должен иметь
Столбец в таблице
Один столбец описывает одно свойство сущности.
Каждый столбец должен иметь

Типы данных в MySQL
Numeric Types (Числа)
Date and Time Types (Дата и
Типы данных в MySQL
Numeric Types (Числа)
Date and Time Types (Дата и

Служебные столбцы
Любая таблица может иметь столбцы, которые «не интересны» пользователю, но
Служебные столбцы
Любая таблица может иметь столбцы, которые «не интересны» пользователю, но

Первичный ключ
Primary Key
Одна из главных задач СУБД – обеспечить уникальность записей
Первичный ключ
Primary Key
Одна из главных задач СУБД – обеспечить уникальность записей

Виды первичных ключей
AUTO_INCREMENT
наиболее популярный
Natural Primary Key
натуральный первичный ключ.
любой столбец, с
Виды первичных ключей
AUTO_INCREMENT
наиболее популярный
Natural Primary Key
натуральный первичный ключ.
любой столбец, с

Внешний ключ
Foreign Key
Внешний ключ – это специальный столбец, который хранит значения
Внешний ключ
Foreign Key
Внешний ключ – это специальный столбец, который хранит значения

Отношения таблиц
Рассматривать внешний ключ тяжело без понятия «отношения между таблицами»
Давайте по
Отношения таблиц
Рассматривать внешний ключ тяжело без понятия «отношения между таблицами»
Давайте по

Отношения таблиц
Но приложению «не интересно», знать данные только из одной таблицы
Например,
Отношения таблиц
Но приложению «не интересно», знать данные только из одной таблицы
Например,

Таким образом
Кроме самих таблиц, в БД большое значение имеют
Отношения между
Таким образом
Кроме самих таблиц, в БД большое значение имеют
Отношения между

Как создать внешний ключ?
Как создать внешний ключ?

Какие бывают отношения?
One-To-Many – Один ко многим
Many-To-One – Многие к одному
Many-To-Many
Какие бывают отношения?
One-To-Many – Один ко многим
Many-To-One – Многие к одному
Many-To-Many

One-To-Many
Самое популярное отношение
Означает, что
Одна сущность главной таблицы может владеть множеством
One-To-Many
Самое популярное отношение
Означает, что
Одна сущность главной таблицы может владеть множеством
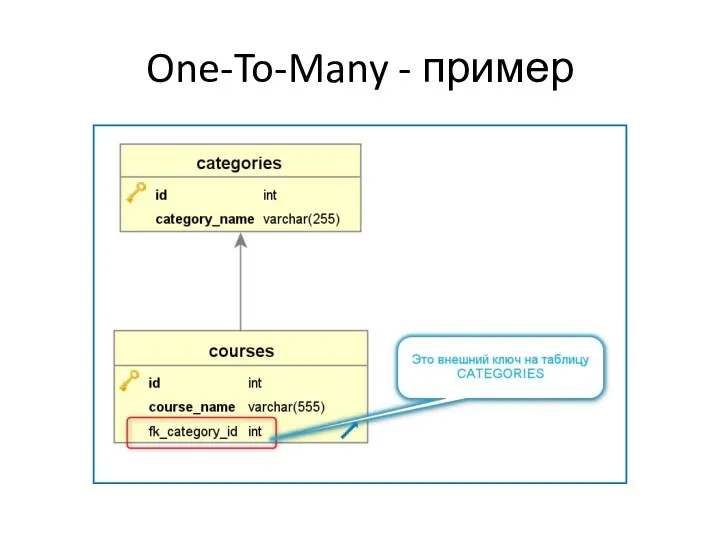
One-To-Many - пример
One-To-Many - пример

Many-To-One
Это такая же связь, как и One-To-Many
Реализуется она точно так же:
Добавлением
Many-To-One
Это такая же связь, как и One-To-Many
Реализуется она точно так же:
Добавлением

Many-To-Many
Означает, что:
Одна сущность главной таблицы может владеть множеством сущностей из
Many-To-Many
Означает, что:
Одна сущность главной таблицы может владеть множеством сущностей из
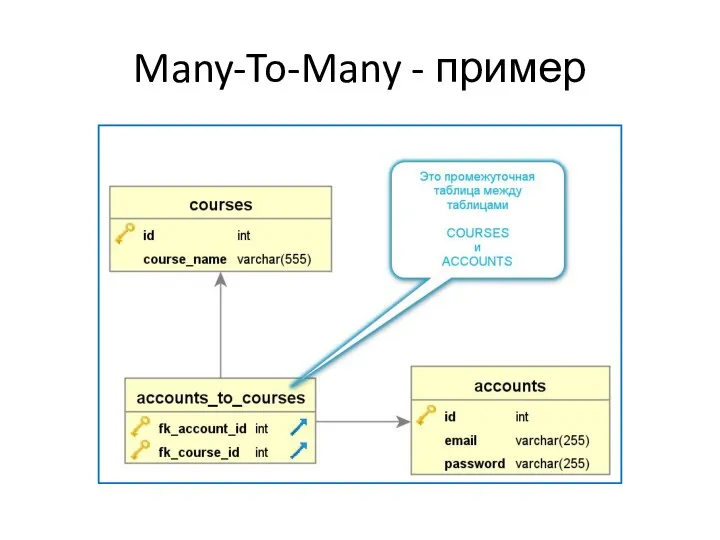
Many-To-Many - пример
Many-To-Many - пример

One-To-One
Довольно редкая связь
Означает, что:
Одна сущность из главной таблицей может владеть только
One-To-One
Довольно редкая связь
Означает, что:
Одна сущность из главной таблицей может владеть только
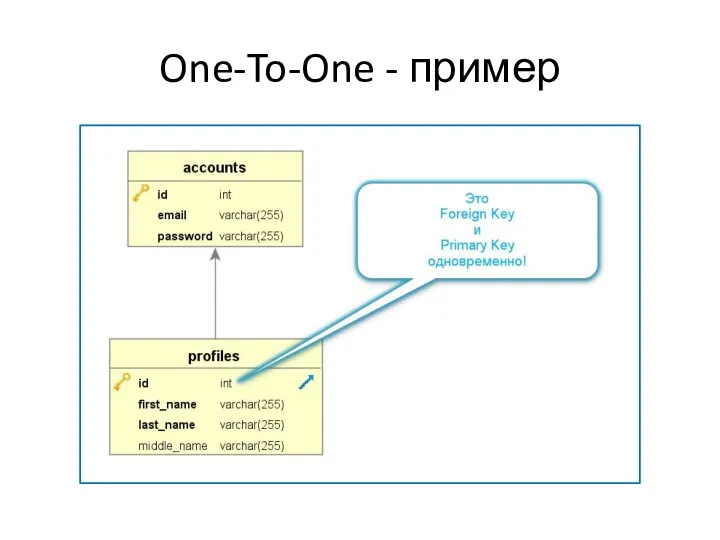
One-To-One - пример
One-To-One - пример
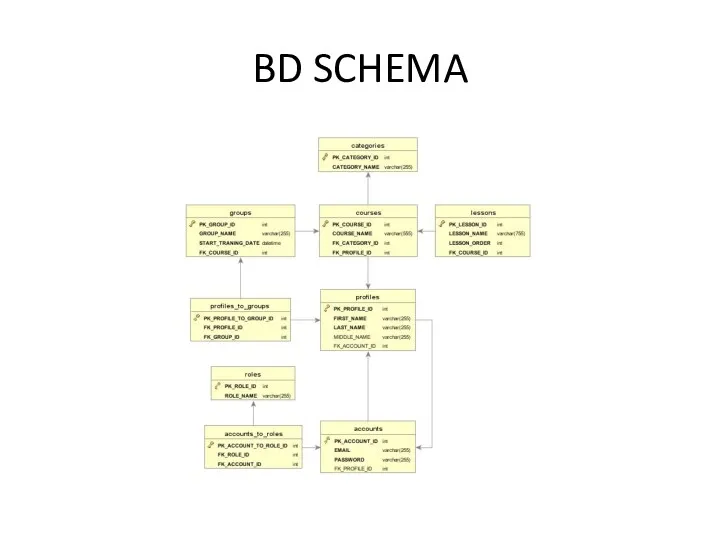
BD SCHEMA
BD SCHEMA

Что насупился весь
И сидишь как буржуй?
Раз возникла проблема
Что насупился весь
И сидишь как буржуй?
Раз возникла проблема
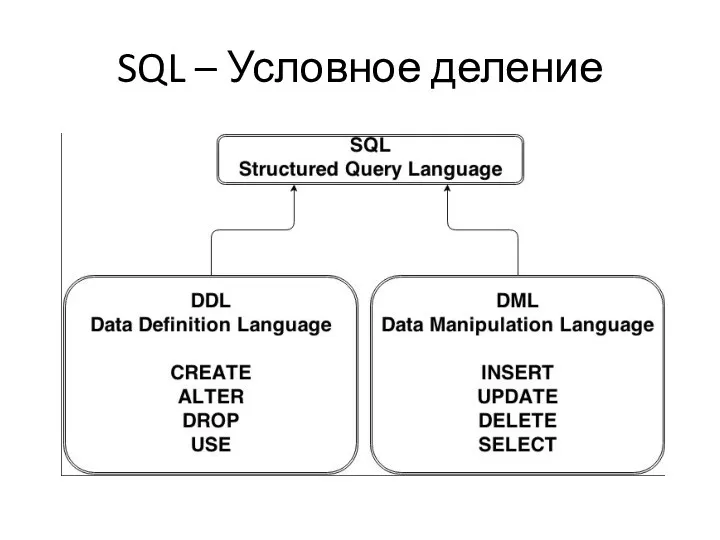
SQL – Условное деление
SQL – Условное деление

Команда CREATE
При помощи команды CREATE можно создать следующие элементы Базы Данных:
Базу
Команда CREATE
При помощи команды CREATE можно создать следующие элементы Базы Данных:
Базу

CREATE для Базы Данных
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] `db_name`
CREATE для Базы Данных
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] `db_name`

CREATE для Базы Данных.
Пояснения.
Character set – кодировка, в которой СУБД будет
CREATE для Базы Данных.
Пояснения.
Character set – кодировка, в которой СУБД будет

CREATE для Базы Данных.
Пояснения.
Каждая СУБД имеет некоторую кодировку по умолчанию.
Она указывается
CREATE для Базы Данных.
Пояснения.
Каждая СУБД имеет некоторую кодировку по умолчанию.
Она указывается

СУБД не поддерживает UTF-8.
Логическая задача.
Условие: Java-программист работает под СУБД, которая не
СУБД не поддерживает UTF-8.
Логическая задача.
Условие: Java-программист работает под СУБД, которая не
![CREATE для таблицы CREATE TABLE [IF NOT EXISTS] `db_name` .`tbl_name`](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/205898/slide-63.jpg)
CREATE для таблицы
CREATE TABLE [IF NOT EXISTS] `db_name` .`tbl_name`
(
create_definition
);
Здесь create_definition –
CREATE для таблицы
CREATE TABLE [IF NOT EXISTS] `db_name` .`tbl_name`
(
create_definition
);
Здесь create_definition –

CREATE для таблицы.
Пример.
CREATE TABLE ` TRAINING_DB `.`STUDENTS` (
`PK_STUDENT_ID` INTEGER NOT
CREATE для таблицы.
Пример.
CREATE TABLE ` TRAINING_DB `.`STUDENTS` (
`PK_STUDENT_ID` INTEGER NOT

CREATE для индекса
CREATE INDEX index_name ON tbl_name
CREATE для индекса
CREATE INDEX index_name ON tbl_name
![Синтаксис команды DROP DROP {DATABASE | SCHEMA} [IF EXISTS] db_name](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/205898/slide-66.jpg)
Синтаксис команды DROP
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
DROP TABLE
Синтаксис команды DROP
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
DROP TABLE

SQL - DDL
SQL - DDL
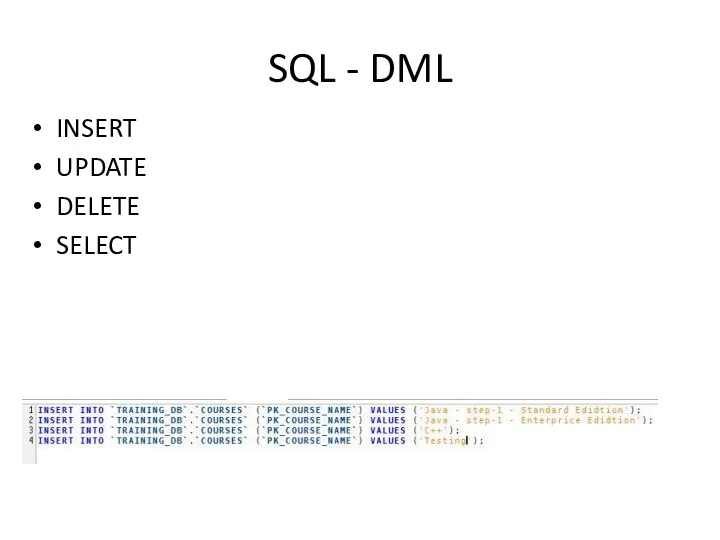
SQL - DML
INSERT
UPDATE
DELETE
SELECT
SQL - DML
INSERT
UPDATE
DELETE
SELECT

Синтаксис команды INSERT
INSERT INTO tbl_name (col-1, col-2, ...)
VALUES (val-1, val-1,
Синтаксис команды INSERT
INSERT INTO tbl_name (col-1, col-2, ...)
VALUES (val-1, val-1,

Синтаксис команды UPDATE
UPDATE tbl_name
SET col-1 = expr-1, col-2 = expr-2,
Синтаксис команды UPDATE
UPDATE tbl_name
SET col-1 = expr-1, col-2 = expr-2,
![Синтаксис команды DELETE DELETE FROM tbl_name [WHERE where_condition]; Примеры: DELETE](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/205898/slide-71.jpg)
Синтаксис команды DELETE
DELETE FROM tbl_name [WHERE where_condition];
Примеры:
DELETE FROM ACCOUNTS;
DELETE FROM ACCOUNTS
Синтаксис команды DELETE
DELETE FROM tbl_name [WHERE where_condition];
Примеры:
DELETE FROM ACCOUNTS;
DELETE FROM ACCOUNTS
![Синтаксис команды SELECT SELECT [DISTINCT] select_expr, ... FROM table_references [WHERE](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/205898/slide-72.jpg)
Синтаксис команды SELECT
SELECT [DISTINCT] select_expr, ...
FROM table_references
[WHERE where_condition]
[ORDER
Синтаксис команды SELECT
SELECT [DISTINCT] select_expr, ...
FROM table_references
[WHERE where_condition]
[ORDER

Пример SELECT
Выбрать все записи из ACCOUNTS
SELECT `login`, `password` FROM ACCOUNTS
SELECT *
Пример SELECT
Выбрать все записи из ACCOUNTS
SELECT `login`, `password` FROM ACCOUNTS
SELECT *

Пример SELECT
Выбрать всех админов
SELECT * FROM ACCOUNTS
WHERE `login` = ‘Admin’
Пример SELECT
Выбрать всех админов
SELECT * FROM ACCOUNTS
WHERE `login` = ‘Admin’

Пример SELECT
Выбрать всех умных админов ☺
SELECT * FROM ACCOUNTS
WHERE `login`
Пример SELECT
Выбрать всех умных админов ☺
SELECT * FROM ACCOUNTS
WHERE `login`
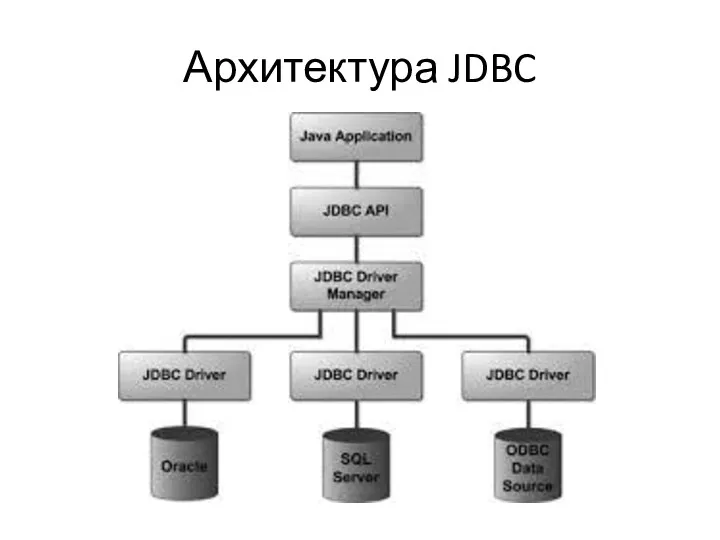
Архитектура JDBC
Архитектура JDBC

Архитектура JDBC
JDBC API – поставляется компанией SUN.
JDBC API служит для соединения
Архитектура JDBC
JDBC API – поставляется компанией SUN.
JDBC API служит для соединения

Архитектура JDBC
Ответ – они не написали ни строки кода для работы
Архитектура JDBC
Ответ – они не написали ни строки кода для работы

Работа с БД на Java
Последовательность шагов
Подключить JDBC драйвер для СУБД.
Соединиться с
Работа с БД на Java
Последовательность шагов
Подключить JDBC драйвер для СУБД.
Соединиться с
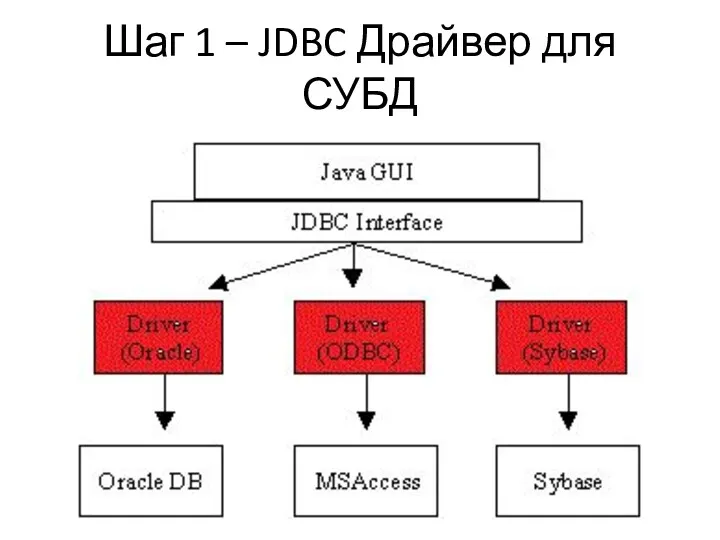
Шаг 1 – JDBC Драйвер для СУБД
Шаг 1 – JDBC Драйвер для СУБД

Шаг 1 – JDBC Драйвер для СУБД
Как уже говорили JDBC –
Шаг 1 – JDBC Драйвер для СУБД
Как уже говорили JDBC –

Шаг 1 – JDBC Драйвер для СУБД
Подключение драйвера проходит в два
Шаг 1 – JDBC Драйвер для СУБД
Подключение драйвера проходит в два
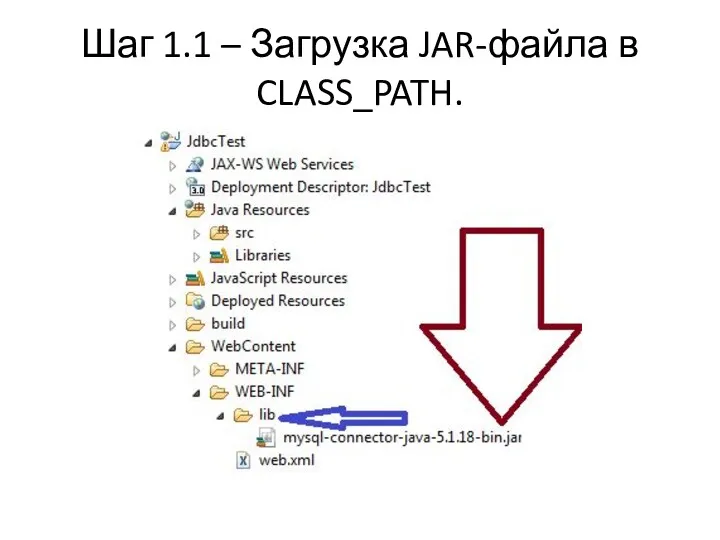
Шаг 1.1 – Загрузка JAR-файла в CLASS_PATH.
Шаг 1.1 – Загрузка JAR-файла в CLASS_PATH.
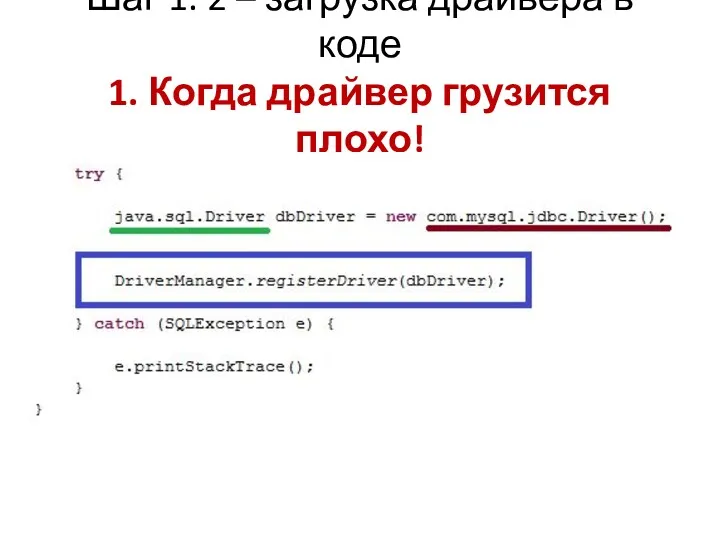
Шаг 1. 2 – загрузка драйвера в коде
1. Когда драйвер грузится
Шаг 1. 2 – загрузка драйвера в коде 1. Когда драйвер грузится

Шаг 1. 2 – загрузка драйвера в коде
2. Когда драйвер грузится
Шаг 1. 2 – загрузка драйвера в коде 2. Когда драйвер грузится

Шаг 2 – Соединение с БД
Шаг 2 – Соединение с БД

Шаг 3 Выполнение SQL запросов
Объект Statement
Шаг 3 Выполнение SQL запросов
Объект Statement

Шаг 4 – обработка результатов.
Объект ResultSet.
Шаг 4 – обработка результатов.
Объект ResultSet.

Шаг 5 – закрытие ресурсов.
Шаг 5 – закрытие ресурсов.

All in One
All in One

Connection Pool
Connection к БД – это «ресурс», который нужно получить.
Мы говорили,
Connection Pool
Connection к БД – это «ресурс», который нужно получить.
Мы говорили,

Tomcat Connection Pool
Step 1 – server.xml
Tomcat Connection Pool
Step 1 – server.xml

Tomcat Connection Pool
Step 2 – context.xml
Tomcat Connection Pool
Step 2 – context.xml

Tomcat Connection Pool
Step 3 – web.xml
Tomcat Connection Pool
Step 3 – web.xml
 Электронные таблицы. (7 класс)
Электронные таблицы. (7 класс) Проект Дом Историй
Проект Дом Историй CAN та CANOpen. Загальне представлення
CAN та CANOpen. Загальне представлення Блок-схема - это графический способ представления алгоритма с помощью геометрических фигур, называемых блоками и стрелок
Блок-схема - это графический способ представления алгоритма с помощью геометрических фигур, называемых блоками и стрелок Разработка программного модуля заказа обратного звонка для сайта компании
Разработка программного модуля заказа обратного звонка для сайта компании Основы программирование на Python
Основы программирование на Python Структуры в С++
Структуры в С++ Руководство оператора АРМ 112. Система 112
Руководство оператора АРМ 112. Система 112 Комп'ютерна графіка на ПЕОМ
Комп'ютерна графіка на ПЕОМ Создание структуры базы данных. Семинар 3. Введение в базы данных
Создание структуры базы данных. Семинар 3. Введение в базы данных Создание презентаций в PowerPoint
Создание презентаций в PowerPoint Моделирование, формализация, визуализация
Моделирование, формализация, визуализация Расчёт стоимости обслуживания и модернизации компьютерной сети в ООО НПФ Пакер
Расчёт стоимости обслуживания и модернизации компьютерной сети в ООО НПФ Пакер Особенности использования криптографии и электронной подписи при защите персональных данных
Особенности использования криптографии и электронной подписи при защите персональных данных Графические программы
Графические программы Презентация к урокам программирования 8-11 класс
Презентация к урокам программирования 8-11 класс Використання та настроювання браузера. Збереження веб-сторінок
Використання та настроювання браузера. Збереження веб-сторінок Программа Защита+
Программа Защита+ Робота з програмою MS Publisher, створення публікації
Робота з програмою MS Publisher, створення публікації Программирование (Python). Символьная строка
Программирование (Python). Символьная строка Учителя, родители и дети в цифровом пространстве
Учителя, родители и дети в цифровом пространстве Програма провідник. Робота з об’єктами
Програма провідник. Робота з об’єктами Информация. Измерение количества информации
Информация. Измерение количества информации История развития компьютерной техники
История развития компьютерной техники Универсальная система управления ООО КЕВ-РУС
Универсальная система управления ООО КЕВ-РУС Робота з запитами на вибірку
Робота з запитами на вибірку Программирование графики с использованием GDI+. (Тема 9)
Программирование графики с использованием GDI+. (Тема 9) Дополненная реальность в видеоиграх
Дополненная реальность в видеоиграх