- JDBC стандартный прикладной интерфейс (API) языка Java. (Лекция 16)

Содержание
- 2. JDBC JDBC – это стандартный прикладной интерфейс (API) языка Java для организации взаимодействия между приложением и
- 3. Тип 1 – драйвер, использующий другой прикладной интерфейс, в частности ODBC, для работы с СУБД (так
- 4. Предпочтение естественным образом отдается второму типу, однако если приложение выполняется на машине, на которой не предполагается
- 5. JDBC предоставляет интерфейс для разработчиков, использующих различные СУБД. С помощью JDBC отсылаются SQL-запросы только к реляционным
- 6. Эти же действия можно выполнить, импортируя библиотеку и создавая объект явно (например для DB2): import COM.ibm.db2.jdbc.net.DB2Driver;
- 7. В результате будет возвращен объект Connection и будет одно установленное соединение с БД NeuronNetwork. Класс DriverManager
- 8. 4. Создание объекта для передачи запросов Statement st = conn.createStatement(); Объект класса Statement используется для выполнения
- 9. Основные методы класса Statement: public void addBatch(String sql) throws SQLException Добавляет заданную команду SQL к текущему
- 10. Метод executeQuery() используется для выполнения запросов (на извлечение данных). Он возвращает для обработки результирующий набор. Метод
- 11. public void close() throws SQLException Вручную закрывает объект Statement. Обычно этого не требуется, так как Statement
- 12. public boolean absolute(int row) throws SQLException Метод перемещает курсор на заданное число строк от начала, если
- 13. public ResultSetMetaData getMetaData() throws SQLException Предоставляет объект метаданных для данного ResultSet. Класс ResultSetMetaData содержит информацию о
- 14. public boolean next() throws SQLException public boolean previous() throws SQLException Эти методы позволяют переместиться в результирующем
- 15. Рассмотрим пример: package mssql; import java.sql.*; public class Main { private static Connection con = null;
- 16. //Statement позволяет отправлять запросы базе данных Statement st = con.createStatement(); //ResultSet получает результирующую таблицу ResultSet rs
- 17. Интерфейс CallableStatement расширяет возможности интерфейса PreparedStatement и обеспечивает выполнение хранимых процедур. Стоит заметить, что PreparedStatement расширяет
- 18. Интерфейс CallableStatement позволяет исполнять хранимые процедуры, которые находятся непосредственно в БД. Одна из особенностей этого процесса
- 19. Пусть в БД существует хранимая процедура getempname, которая по уникальному для каждой записи в таблице employee
- 20. Тогда для получения имени служащего employee через вызов данной процедуры необходимо исполнить java-код вида: String SQL
- 21. В результате будет выведено, приблизительно следующее: Employee with SSN:822301 is Spiridonov В JDBC также существует механизм
- 22. //выполняем запрос int[] updateCounts = stmt.executeBatch(); В массиве updateCounts содержаться числа: 1.>=0 – означает, что запрос
- 23. Если используется объект PreparedStatement, batch-команда состоит из параметризованного SQL-запроса и ассоциируемого с ним множества параметров. Рассмотрим
- 24. try { Employee[] employees = new Employee[10]; PreparedStatement statement= con.prepareStatement( "INSERT INTO employee VALUES (?,?,?,?,?)"); for
- 25. int [] updateCounts = statement.executeBatch(); } catch (BatchUpdateException e) { e.printStackTrace(); } Транзакции Транзакцию (деловую операцию)
- 26. Согласованность – при возникновении сбоя система возвращается в состояние до начала неудавшейся транзакции. Если транзакция завершается
- 27. Для фиксации результатов работы SQL-операторов, логически выполняемых в рамках некоторой транзакции, используется SQL-оператор COMMIT. В API
- 28. После этого выполнение любого запроса на изменение информации в таблицах базы данных не приведет к необратимым
- 29. try{ Connection cn=…….; cn.setAutoCommit(false); Statement st = cn.createStatement(); String upd = "INSERT INTO student (id, name)
- 30. Для транзакций существует несколько типов чтения: Грязное чтение (dirty reads) происходит, когда транзакциям разрешено видеть несохраненные
- 31. Фантомное чтение (phantom reads) происходит, когда транзакция А считывает все строки, удовлетворяющие WHERE-условию, транзакция B вставляет
- 32. JDBC удовлетворяет четырем уровням изоляции транзакций, определенным в стандарте SQL. Уровни изоляции транзакций определены в виде
- 33. TRANSACTION_READ_COMMITTED – означает, что любое изменение, сделанное в транзакции, не видно вне неё, пока она не
- 34. Метод boolean supportsTransactionIsolationLevel (int level) интерфейса DatabaseMetaData определяет, поддерживается ли заданный уровень изоляции транзакций. В свою
- 35. Точки сохранения Точки сохранения дают дополнительный контроль над транзакциями. Установкой точки сохранения обозначается логическая точка внутри
- 36. Методы setSavepoint(String name) и setSavepoint() (оба возвращают объект Savepoint) интерфейса Connection используются для установки именованной или
- 37. ………………………. Class.forName ("com.mysql.jdbc.Driver") .newInstance(); Connection cn = null; Savepoint savepoint = null; cn = DriverManager.getConnection( "jdbc:mysql://localhost/db3","root","pass");
- 38. //установка точки сохранения savepoint = cn.setSavepoint("savepoint1"); //выполнение некорректного запроса String wrongSQL = "INSERT INTO (id,name,surname,salary) "
- 39. Рассмотрим пример, двухмерный массив на основе базы данных. import java.sql.*; import java.util.*; //здесь хранится имя массива,
- 40. public class DB{ private String name; //имя базы данных private LinkedList tables=new LinkedList();//список имен массивов в
- 41. public void createMas(String name_of_massive, int number_of_rows, int number_of_columns){ try { //добавляем имя массива в список имен
- 42. //создание таблицы String createString="CREATE TABLE "+name_of_massive+ " ( NUMBER int generated by default as identity (START
- 43. for(int j=0;j //добавление строк в таблицу String str_query="insert into “ +name_of_massive+" ( w0 )"+ " values
- 44. public void set(String name_of_massive, int row, int column, double value){ //изменение значения элемента с координатами row
- 45. String str="update "+name_of_massive+ "set"+"w"+String.valueOf(column)+"=?"+ "where NUMBER="+String.valueOf(row+1); PreparedStatement psInsert = conn.prepareStatement(str); psInsert.setDouble(1,value); psInsert.executeUpdate();} catch(Exception e){ System.out.println("In function
- 46. public double get(String name_of_massive, int row, int column){ //получение элемента массива с координатами row и column
- 47. String str=“select“ +"w"+String.valueOf(column)+”from“ +name_of_massive+ "where NUMBER="+String.valueOf(row+1); Statement stmt2 = conn.createStatement(); ResultSet rs = stmt2.executeQuery(str); rs.next(); double
- 48. public int Ncolumns(String name_of_massive) { //кол-во столбцов в массиве name_of_massive try{ MasSize m=new MasSize(); m.setName(name_of_massive); m.setColumns(0);
- 49. public int Nrows(String name_of_massive){ //кол-во строк в массиве name_of_massiv try{ MasSize m=new MasSize(); m.setName(name_of_massive); m.setColumns(0); m.setRows(0);
- 50. public void delete_mas(String name_of_massive){ //удаление массива name_of_massive из базы данных try{ MasSize m=new MasSize(); m.setName(name_of_massive); m.setColumns(0);
- 51. Использование данного класса может выглядеть следующим образом: class m1{ public static void main(String[] args){ DB data=new
- 52. Метаданные С помощью методов интерфейсов ResultSetMetaData и DatabaseMetaData можно получить список таблиц, определить типы, свойства и
- 53. int getColumnType(int column) – возвращает тип данных указанного столбца объекта ResultSet. Получить объект DatabaseMetaData можно следующим
- 54. catalog - Значение String, содержащее имя каталога. Задание значения NULL для этого параметра указывает на то,
- 55. public static void executeGetTables(Connection con) { try { DatabaseMetaData dbmd = con.getMetaData(); ResultSet rs = dbmd.getTables("AdventureWorks",
- 56. Результирующий набор, возвращаемый методом getTables, включает следующие данные: TABLE_CAT - Имя базы данных, в которой расположена
- 57. Пул соединений При большом количестве клиентов приложения к БД этого приложения выполняется большое количество запросов. Соединение
- 58. Разделяемый доступ к источнику данных можно организовать путем объявления статической переменной типа DataSource из пакета javax.sql.
- 59. Затем созданный объект можно получить с помощью метода lookup() по его имени. Методу lookup() передается имя,
- 60. Пул соединений Tomcat Для организации пула необходимо изменить файл server.xml, который находится в папке conf (в
- 61. username root password pass соединений, которые будут содержаться в пуле.--> maxActive 500 maxIdle 10
- 62. maxWait 10000 removeAbandoned true removeAbandonedTimeout 60 logAbandoned true
- 63. Некоторые производители СУБД для облегчения создания пула соединений определяют собственный класс на основе интерфейса DataSource. В
- 64. Также существует специальный пакет для создания пула соединений с БД DBPool (необходимы пакеты DBPool-5.0 и commons-logging-1.1.1-bin).
- 65. String SQL="{call getmname(?,?)}"; CallableStatement cs = conn.prepareCall(SQL); int ssn=251; cs.setInt(1, ssn); cs.registerOutParameter(2, Types.VARCHAR); cs.execute(); String name=cs.getString(2);
- 66. Паттерн Data Access Object Data Access Object (DAO) используется для абстрагирования и инкапсулирования доступа к источнику
- 67. Диаграмма классов для DAO имеет вид:
- 68. Диаграмма последовательности, показывающая взаимодействия между участниками в данном паттерне имеет вид:
- 69. BusinessObject BusinessObject представляет клиента данных. Это объект, который нуждается в доступе к источнику данных для получения
- 70. DataAccessObject DataAccessObject является первичным объектом данного паттерна. DataAccessObject абстрагирует используемую реализацию доступа к данным для BusinessObject,
- 71. DataSource Представляет реализацию источника данных. Источником данных может быть база данных, XML-репозиторий и др. Источником данных
- 72. TransferObject Представляет собой объект, используемый для передачи данных. DataAccessObject может использовать TransferObject для возврата данных клиенту.
- 73. Стратегии Стратегия Automatic DAO Code Generation Поскольку BusinessObject соответствует конкретному DAO, есть возможность установить взаимоотношения между
- 74. Стратегия Factory for Data Access Objects Паттерн DAO может быть сделан очень гибким при использовании паттернов
- 75. Диаграмма классов этого случая имеет вид:
- 76. Когда используемое хранилище данных может измениться при переходе от одной реализации к другой, данная стратегия может
- 78. Диаграмма последовательности, описывающая взаимодействия для этой стратегии имеет вид:
- 79. Рассмотрим пример кода для паттерна DAO. // DAO Factory public abstract class DAOFactory { // Список
- 80. public class CloudscapeDAOFactory extends DAOFactory { public static final String DRIVER= "COM.cloudscape.core.RmiJdbcDriver"; public static final String
- 81. Интерфейс для CustomerDAO public interface CustomerDAO { public int insertCustomer(...); public boolean deleteCustomer(...); public Customer findCustomer(...);
- 82. Имплементация интерфейса CustomerDAO public class CloudscapeCustomerDAO implements CustomerDAO { public CloudscapeCustomerDAO() {…. } public int insertCustomer(...)
- 83. Customer Transfer Object public class Customer implements java.io.Serializable { int CustomerNumber; String name; String streetAddress; String
- 84. Использование DAO Factory ………………………………… DAOFactory cloudscapeFactory = DAOFactory.getDAOFactory( DAOFactory.DAOCLOUDSCAPE); CustomerDAO custDAO = cloudscapeFactory.getCustomerDAO(); int newCustNo =
- 85. Hibernate Hibernate - это механизм отображения в реляционной базе данных объектов java. На практике наибольшую популярность
- 86. Java разработчикам доступно множество технологий для работы с данными это может быть просто сериализация объектов, JDBC,
- 87. Рассмотрим примеры использования Hibernate. В базе данных создадим таблицу Student с тремя полями: 1) id —
- 88. package logic; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; import javax.persistence.Table; import org.hibernate.annotations.GenericGenerator; @Entity @Table(name="Student")
- 89. @Id @GeneratedValue (generator="increment") @GenericGenerator (name="increment", strategy = "increment") @Column(name="id") public Long getId() { return id; }
- 90. Аннотации здесь используются для Mapping Java классов с таблицами базы данных. Проще говоря для того, чтобы
- 91. 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> oracle.jdbc.driver.OracleDriver name="connection.url">jdbc:oracle:thin:@localhost:1521:MyDB Your_Login Your_Password 10 org.hibernate.dialect.OracleDialect true update false thread
- 92. Создадим пакет util, а в нем класс HibernateUtil, который будет отвечать за обработку данного xml файла
- 93. Теперь осталось разобраться со взаимодействием приложения с базой данных. Тогда для класса-сущности, определим интерфейс StudentDAO из
- 94. Теперь определим реализацию этого интерфейса в классе SudentDAOImpl в пакете DAO.Impl: package DAO.Impl; import java.sql.SQLException; import
- 95. public void updateStudent(Student stud) throws SQLException { Session session = null; try { session = HibernateUtil.getSessionFactory().openSession();
- 96. public Student getStudentById(Long id) throws SQLException { Session session = null; Student stud = null; try
- 97. public List getAllStudents() throws SQLException { Session session = null; List studs = new ArrayList ();
- 98. public void deleteStudent(Student stud) throws SQLException { Session session = null; try { session = HibernateUtil.getSessionFactory().openSession();
- 99. Создадим класс Factory в пакете DAO, к которому будем обращаться за нашими реализациями DAO, от которых
- 100. Метод main будет иметь вид: import DAO.Factory; public class Main { public static void main(String[] args)
- 101. Запросы в Hibernate Запросы возвращают набор данных из базы данных, удовлетворяющих заданному условию. Библиотека Hibernate предлагает
- 102. Запросы с использованием Criteria Объект Criteria создается с помощью метода createCriteria экземпляра класса Session: Criteria crit
- 103. List studs = session.createCriteria(Student.class) .add( Expression.in( "name", new String[] { "Ivanov Ivan", "Petrov Petia", "Zubin Egor"
- 104. Expression.like — указывает шаблон, где ‘_’ — любой один символ, ‘%’ — любое количество символов Expression.isNull
- 105. Поля объекта, имеющие значение null или являющиеся идентификаторами, будут игнорироваться. Example также можно настраивать: Example example
- 106. Запросы с использованием SQL Hibernate позволяет выражать запросы на родном для базы данных диалекте SQL. Выглядеть
- 107. Запросы с использованием HQL Hibernate позволяет производить запросы на HQL(The Hibernate Query Language — Язык запросов
- 108. Отношения в Hibernate Помимо таблицы Student, создадим еще две таблицы Test и Statistics. Они будут связаны
- 109. Создадим эти две таблицы: CREATE TABLE Test(tid NUMBER(10) NOT NULL, tname varchar(100) NOT NULL, CONSTRAINT pk_Test
- 110. Test package logic; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; import javax.persistence.JoinTable; import javax.persistence.Table; import
- 111. public Test(Test s){ tname = s.getTName(); } @Id @GeneratedValue(generator="increment") @GenericGenerator(name="increment", strategy = "increment") @Column(name="tid") public Long
- 112. Statistics package logic; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; import javax.persistence.Table; import org.hibernate.annotations.GenericGenerator; @Entity
- 113. @Id @GeneratedValue(generator="increment") @GenericGenerator(name="increment", strategy = "increment") @Column(name="stid") public Long getStid(){ return stid; } @Column(name="id") public Long
- 114. Классы TestDAO и TestDAOImpl создаются аналогично как для сущности Student. Осталось только показать Hibernate, как эти
- 115. В классе Statistics аннотируем связь один ко многим с классом Student: private Set studs = new
- 116. Так же обозначаем отношение таблицы Test и Statistics, просто добавив в класс Test код: private Statistics
- 117. Поскольку таблица Statistics является не просто таблицей, связанной со Student и Test, а она разбивает нежелательную
- 118. Если бы мы обозначали эту связь в классе Student: private Test test; @ManyToOne @JoinTable(name = "Statistics",
- 119. Другой пример реализации Hibernate JPA Рассмотрим пример работы с базой данный с использованием объектно-ориентированной модели. Пусть
- 120. Создадим класс mytable, который соответствует записи в таблице: import java.io.Serializable; import javax.persistence.*; @Entity @Table(name= “mytable”) public
- 121. public mytable() {}; public mytable(String name,Byte b){ this.age=b; this.name=name; } public Long getId() {return id; }
- 122. Hibernate для своей работы требует специальный файл конфигурации(если точнее, то он используется во время компиляции), который
- 123. value="jdbc:mysql://localhost:3306/mybase" /> value="qwertyui" /> value="com.mysql.jdbc.Driver" /> value="alex" /> value="create-tables" />
- 124. Тогда работа с базой данных будет иметь вид: import javax.persistence.*; public class Main { public static
- 125. Компиляция и запуск Для компиляции удобно воспользоваться утилитой ant(разработка Apache foundation http://ant.apache.org/). Создаем директорию, например base.
- 126. 5. В base помещаем файл build.xml, который имеет вид: default="deploy"> value="C:/Java_Dev/WEB/dev/ejb/ jboss-4.2.3.GA/server/default/deploy" /> value="${basedir}/src" /> value="${basedir}/build"
- 128. "copy-resources"> debug="on" />
- 129. "clean,copy-resources,compile">
- 130. classpathref="libraries">
- 131. 6. Перейти в директорию base и из консоли запустить ant D:\base>ant В результате в папке build
- 132. Пакет JOOQ Данный пакет представляет собой Linq для Java. С помощью данной библиотеки можно строить запросы
- 133. Создаем файл mybase.properties: jdbc.Driver=com.mysql.jdbc.Driver jdbc.URL=jdbc:mysql://localhost:3306/mybase jdbc.Schema=mybase jdbc.User=muser jdbc.Password=qwertyui #The default code generator. You can override this
- 134. #Primary key / foreign key relations should be generated and used. #This will be a prerequisite
- 135. Генерируем классы, соответствующие базе данных java -classpath jooq-1.6.9.jar;jooq-meta-1.6.9.jar; jooq-codegen-1.6.9.jar;mysql-connector-java- 5.1.18-bin.jar;. org.jooq.util.GenerationTool /mybase.properties Тогда получение записей из
- 136. public class Main { public static void main(String[] args) { Connection conn = null; try{ String
- 138. Скачать презентацию

JDBC
JDBC – это стандартный прикладной интерфейс (API) языка Java для организации
JDBC
JDBC – это стандартный прикладной интерфейс (API) языка Java для организации

Тип 1 – драйвер, использующий другой прикладной интерфейс, в частности ODBC,
Тип 1 – драйвер, использующий другой прикладной интерфейс, в частности ODBC,

Предпочтение естественным образом отдается второму типу, однако если приложение выполняется на
Предпочтение естественным образом отдается второму типу, однако если приложение выполняется на

JDBC предоставляет интерфейс для разработчиков, использующих различные СУБД.
С помощью JDBC
JDBC предоставляет интерфейс для разработчиков, использующих различные СУБД.
С помощью JDBC

Эти же действия можно выполнить, импортируя библиотеку и создавая объект явно
Эти же действия можно выполнить, импортируя библиотеку и создавая объект явно

В результате будет возвращен объект Connection и будет одно установленное соединение
В результате будет возвращен объект Connection и будет одно установленное соединение

4. Создание объекта для передачи запросов
Statement st = conn.createStatement();
Объект класса
4. Создание объекта для передачи запросов
Statement st = conn.createStatement();
Объект класса

Основные методы класса Statement:
public void addBatch(String sql) throws SQLException
Добавляет заданную команду
Основные методы класса Statement:
public void addBatch(String sql) throws SQLException
Добавляет заданную команду

Метод executeQuery() используется для выполнения
запросов (на извлечение данных).
Метод executeQuery() используется для выполнения
запросов (на извлечение данных).

public void close() throws SQLException
Вручную закрывает объект Statement.
Обычно этого
public void close() throws SQLException
Вручную закрывает объект Statement.
Обычно этого

public boolean absolute(int row) throws SQLException
Метод перемещает курсор на заданное число
public boolean absolute(int row) throws SQLException Метод перемещает курсор на заданное число

public ResultSetMetaData getMetaData() throws SQLException
Предоставляет объект метаданных для данного ResultSet.
public ResultSetMetaData getMetaData() throws SQLException
Предоставляет объект метаданных для данного ResultSet.

public boolean next() throws SQLException
public boolean previous() throws SQLException
Эти методы позволяют
public boolean next() throws SQLException public boolean previous() throws SQLException Эти методы позволяют

Рассмотрим пример:
package mssql;
import java.sql.*;
public class Main {
private
Рассмотрим пример:
package mssql;
import java.sql.*;
public class Main {
private

//Statement позволяет отправлять запросы базе данных
Statement st = con.createStatement();
//Statement позволяет отправлять запросы базе данных
Statement st = con.createStatement();

Интерфейс CallableStatement расширяет возможности интерфейса PreparedStatement и обеспечивает выполнение хранимых процедур.
Стоит
Интерфейс CallableStatement расширяет возможности интерфейса PreparedStatement и обеспечивает выполнение хранимых процедур.
Стоит

Интерфейс CallableStatement позволяет исполнять хранимые процедуры, которые находятся непосредственно в БД.
Интерфейс CallableStatement позволяет исполнять хранимые процедуры, которые находятся непосредственно в БД.

Пусть в БД существует хранимая процедура getempname, которая по уникальному для
Пусть в БД существует хранимая процедура getempname, которая по уникальному для

Тогда для получения имени служащего employee через вызов данной процедуры необходимо
Тогда для получения имени служащего employee через вызов данной процедуры необходимо

В результате будет выведено, приблизительно следующее:
Employee with SSN:822301 is Spiridonov
В JDBC
В результате будет выведено, приблизительно следующее:
Employee with SSN:822301 is Spiridonov
В JDBC
![//выполняем запрос int[] updateCounts = stmt.executeBatch(); В массиве updateCounts содержаться](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/17094/slide-21.jpg)
//выполняем запрос
int[] updateCounts = stmt.executeBatch();
В массиве updateCounts содержаться числа:
1.>=0 – означает,
//выполняем запрос
int[] updateCounts = stmt.executeBatch();
В массиве updateCounts содержаться числа:
1.>=0 – означает,

Если используется объект PreparedStatement, batch-команда состоит из параметризованного SQL-запроса и ассоциируемого
Если используется объект PreparedStatement, batch-команда состоит из параметризованного SQL-запроса и ассоциируемого
![try { Employee[] employees = new Employee[10]; PreparedStatement statement= con.prepareStatement(](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/17094/slide-23.jpg)
try {
Employee[] employees = new Employee[10];
PreparedStatement statement=
con.prepareStatement(
"INSERT INTO employee
try {
Employee[] employees = new Employee[10];
PreparedStatement statement=
con.prepareStatement(
"INSERT INTO employee
![int [] updateCounts = statement.executeBatch(); } catch (BatchUpdateException e) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/17094/slide-24.jpg)
int [] updateCounts = statement.executeBatch();
} catch (BatchUpdateException e) {
e.printStackTrace();
int [] updateCounts = statement.executeBatch();
} catch (BatchUpdateException e) {
e.printStackTrace();

Согласованность – при возникновении сбоя система возвращается в состояние до начала
Согласованность – при возникновении сбоя система возвращается в состояние до начала

Для фиксации результатов работы SQL-операторов, логически выполняемых в рамках некоторой транзакции,
Для фиксации результатов работы SQL-операторов, логически выполняемых в рамках некоторой транзакции,

После этого выполнение любого запроса на изменение информации в таблицах базы
После этого выполнение любого запроса на изменение информации в таблицах базы

try{
Connection cn=…….;
cn.setAutoCommit(false);
Statement st = cn.createStatement();
String upd =
try{
Connection cn=…….;
cn.setAutoCommit(false);
Statement st = cn.createStatement();
String upd =

Для транзакций существует несколько типов чтения:
Грязное чтение (dirty reads) происходит, когда
Для транзакций существует несколько типов чтения:
Грязное чтение (dirty reads) происходит, когда

Фантомное чтение (phantom reads) происходит, когда транзакция А считывает все строки,
Фантомное чтение (phantom reads) происходит, когда транзакция А считывает все строки,

JDBC удовлетворяет четырем уровням изоляции транзакций, определенным в стандарте SQL.
Уровни изоляции
JDBC удовлетворяет четырем уровням изоляции транзакций, определенным в стандарте SQL.
Уровни изоляции

TRANSACTION_READ_COMMITTED – означает, что любое изменение, сделанное в транзакции, не видно
TRANSACTION_READ_COMMITTED – означает, что любое изменение, сделанное в транзакции, не видно

Метод
boolean supportsTransactionIsolationLevel
(int level)
интерфейса DatabaseMetaData определяет, поддерживается ли заданный
Метод
boolean supportsTransactionIsolationLevel
(int level)
интерфейса DatabaseMetaData определяет, поддерживается ли заданный

Точки сохранения
Точки сохранения дают дополнительный контроль над транзакциями.
Установкой точки
Точки сохранения
Точки сохранения дают дополнительный контроль над транзакциями.
Установкой точки

Методы setSavepoint(String name) и setSavepoint() (оба возвращают объект Savepoint) интерфейса Connection
Методы setSavepoint(String name) и setSavepoint() (оба возвращают объект Savepoint) интерфейса Connection

……………………….
Class.forName ("com.mysql.jdbc.Driver")
.newInstance();
Connection cn = null;
Savepoint savepoint = null;
cn = DriverManager.getConnection(
……………………….
Class.forName ("com.mysql.jdbc.Driver")
.newInstance();
Connection cn = null;
Savepoint savepoint = null;
cn = DriverManager.getConnection(

//установка точки сохранения
savepoint = cn.setSavepoint("savepoint1");
//выполнение некорректного запроса
String wrongSQL =
"INSERT
//установка точки сохранения
savepoint = cn.setSavepoint("savepoint1");
//выполнение некорректного запроса
String wrongSQL =
"INSERT

Рассмотрим пример, двухмерный массив на основе базы данных.
import java.sql.*;
import java.util.*;
//здесь
Рассмотрим пример, двухмерный массив на основе базы данных.
import java.sql.*;
import java.util.*;
//здесь

public class DB{
private String name; //имя базы данных
private
public class DB{
private String name; //имя базы данных
private

public void createMas(String name_of_massive,
int number_of_rows,
int number_of_columns){
public void createMas(String name_of_massive,
int number_of_rows,
int number_of_columns){

//создание таблицы
String createString="CREATE TABLE
"+name_of_massive+
" ( NUMBER int
//создание таблицы
String createString="CREATE TABLE
"+name_of_massive+
" ( NUMBER int

for(int j=0;j //добавление строк в таблицу
String str_query="insert into “
+name_of_massive+"
for(int j=0;j
String str_query="insert into “
+name_of_massive+"

public void set(String name_of_massive, int row,
int column, double value){
public void set(String name_of_massive, int row,
int column, double value){

String str="update "+name_of_massive+
"set"+"w"+String.valueOf(column)+"=?"+
"where NUMBER="+String.valueOf(row+1);
PreparedStatement psInsert =
conn.prepareStatement(str);
String str="update "+name_of_massive+
"set"+"w"+String.valueOf(column)+"=?"+
"where NUMBER="+String.valueOf(row+1);
PreparedStatement psInsert =
conn.prepareStatement(str);

public double get(String name_of_massive,
int row, int column){
//получение
public double get(String name_of_massive,
int row, int column){
//получение

String str=“select“
+"w"+String.valueOf(column)+”from“
+name_of_massive+
"where NUMBER="+String.valueOf(row+1);
Statement stmt2 = conn.createStatement();
String str=“select“
+"w"+String.valueOf(column)+”from“
+name_of_massive+
"where NUMBER="+String.valueOf(row+1);
Statement stmt2 = conn.createStatement();

public int Ncolumns(String name_of_massive) {
//кол-во столбцов в массиве name_of_massive
public int Ncolumns(String name_of_massive) {
//кол-во столбцов в массиве name_of_massive

public int Nrows(String name_of_massive){
//кол-во строк в массиве name_of_massiv
try{
MasSize
public int Nrows(String name_of_massive){
//кол-во строк в массиве name_of_massiv
try{
MasSize

public void delete_mas(String name_of_massive){
//удаление массива name_of_massive из базы данных
public void delete_mas(String name_of_massive){
//удаление массива name_of_massive из базы данных

Использование данного класса может выглядеть следующим образом:
class m1{
public static void
Использование данного класса может выглядеть следующим образом:
class m1{
public static void

Метаданные
С помощью методов интерфейсов ResultSetMetaData и DatabaseMetaData
можно получить список таблиц, определить
Метаданные
С помощью методов интерфейсов ResultSetMetaData и DatabaseMetaData
можно получить список таблиц, определить

int getColumnType(int column) – возвращает тип данных указанного столбца объекта ResultSet.
Получить
int getColumnType(int column) – возвращает тип данных указанного столбца объекта ResultSet.
Получить

catalog - Значение String, содержащее имя каталога. Задание значения NULL для
catalog - Значение String, содержащее имя каталога. Задание значения NULL для

public static void executeGetTables(Connection con) {
try {
DatabaseMetaData dbmd
public static void executeGetTables(Connection con) {
try {
DatabaseMetaData dbmd

Результирующий набор, возвращаемый методом getTables, включает следующие данные:
TABLE_CAT - Имя базы
Результирующий набор, возвращаемый методом getTables, включает следующие данные:
TABLE_CAT - Имя базы

Пул соединений
При большом количестве клиентов приложения к БД этого приложения выполняется
Пул соединений
При большом количестве клиентов приложения к БД этого приложения выполняется

Разделяемый доступ к источнику данных можно организовать путем объявления статической переменной
Разделяемый доступ к источнику данных можно организовать путем объявления статической переменной

Затем созданный объект можно получить с помощью метода lookup() по его
Затем созданный объект можно получить с помощью метода lookup() по его

Пул соединений Tomcat
Для организации пула необходимо изменить файл server.xml, который находится
Пул соединений Tomcat
Для организации пула необходимо изменить файл server.xml, который находится

username
root
password
pass
maxActive
500
maxIdle
10

maxWait
10000
removeAbandoned
true
removeAbandonedTimeout
60
logAbandoned
true

Некоторые производители СУБД для облегчения создания пула соединений определяют собственный класс
Некоторые производители СУБД для облегчения создания пула соединений определяют собственный класс

Также существует специальный пакет для создания пула соединений с БД DBPool
Также существует специальный пакет для создания пула соединений с БД DBPool

String SQL="{call getmname(?,?)}";
CallableStatement cs = conn.prepareCall(SQL);
int ssn=251;
cs.setInt(1,
String SQL="{call getmname(?,?)}";
CallableStatement cs = conn.prepareCall(SQL);
int ssn=251;
cs.setInt(1,

Паттерн Data Access Object
Data Access Object (DAO) используется для абстрагирования
Паттерн Data Access Object
Data Access Object (DAO) используется для абстрагирования
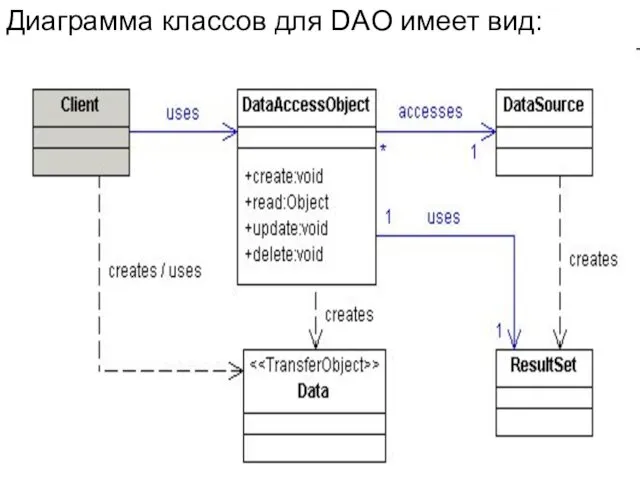
Диаграмма классов для DAO имеет вид:
Диаграмма классов для DAO имеет вид:
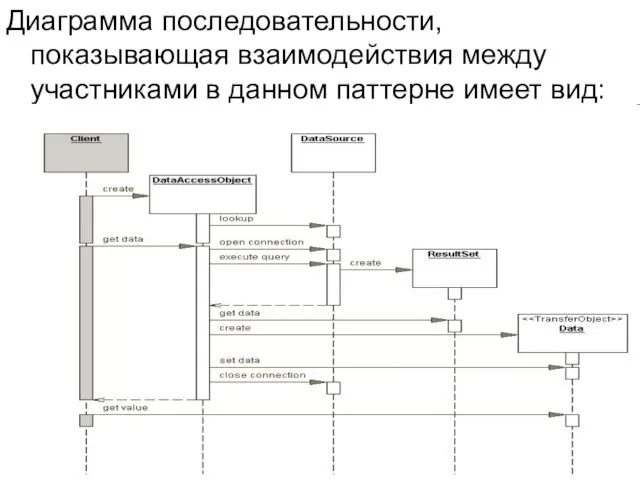
Диаграмма последовательности, показывающая взаимодействия между участниками в данном паттерне имеет вид:
Диаграмма последовательности, показывающая взаимодействия между участниками в данном паттерне имеет вид:

BusinessObject
BusinessObject представляет клиента данных. Это объект, который нуждается в доступе к
BusinessObject
BusinessObject представляет клиента данных. Это объект, который нуждается в доступе к

DataAccessObject
DataAccessObject является первичным объектом данного паттерна.
DataAccessObject абстрагирует используемую реализацию доступа к
DataAccessObject
DataAccessObject является первичным объектом данного паттерна.
DataAccessObject абстрагирует используемую реализацию доступа к

DataSource
Представляет реализацию источника данных.
Источником данных может быть база данных, XML-репозиторий и
DataSource
Представляет реализацию источника данных.
Источником данных может быть база данных, XML-репозиторий и

TransferObject
Представляет собой объект, используемый для передачи данных.
DataAccessObject может использовать
TransferObject
Представляет собой объект, используемый для передачи данных.
DataAccessObject может использовать

Стратегии
Стратегия Automatic DAO Code Generation
Поскольку BusinessObject соответствует конкретному DAO, есть возможность
Стратегии
Стратегия Automatic DAO Code Generation
Поскольку BusinessObject соответствует конкретному DAO, есть возможность

Стратегия Factory for Data Access Objects
Паттерн DAO может быть сделан очень
Стратегия Factory for Data Access Objects
Паттерн DAO может быть сделан очень
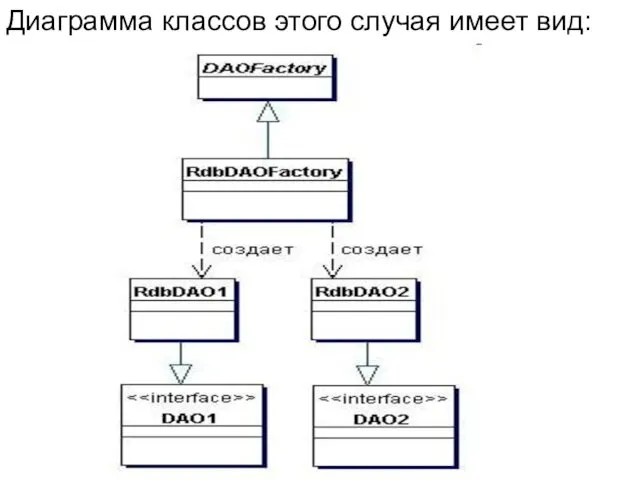
Диаграмма классов этого случая имеет вид:
Диаграмма классов этого случая имеет вид:

Когда используемое хранилище данных может измениться при переходе от одной реализации
Когда используемое хранилище данных может измениться при переходе от одной реализации
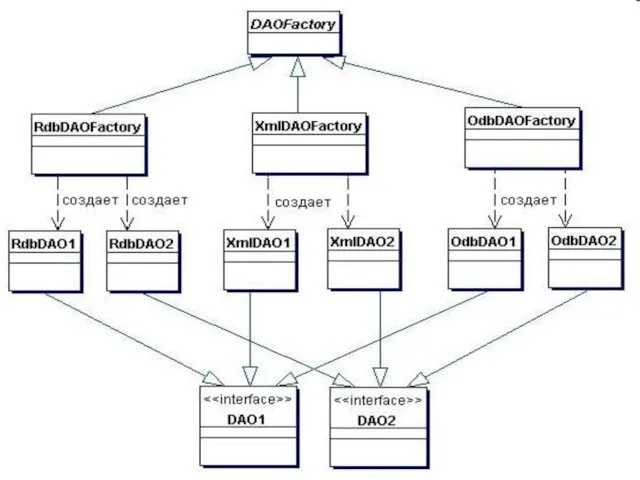
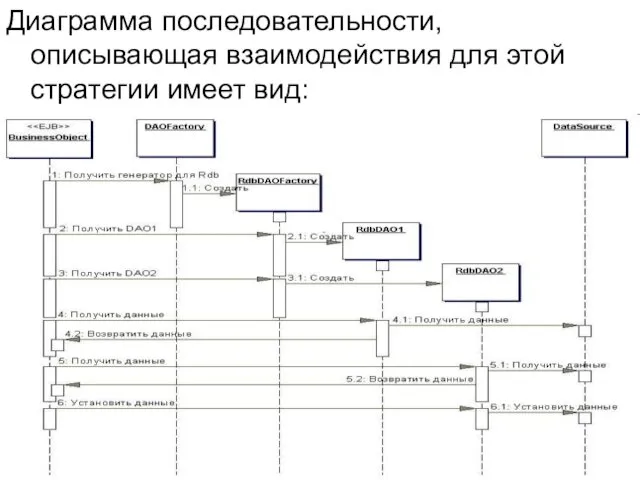
Диаграмма последовательности, описывающая взаимодействия для этой стратегии имеет вид:
Диаграмма последовательности, описывающая взаимодействия для этой стратегии имеет вид:

Рассмотрим пример кода для паттерна DAO.
// DAO Factory
public abstract class
Рассмотрим пример кода для паттерна DAO.
// DAO Factory
public abstract class

public class CloudscapeDAOFactory extends DAOFactory {
public static final String
public class CloudscapeDAOFactory extends DAOFactory {
public static final String

Интерфейс для CustomerDAO
public interface CustomerDAO {
public int insertCustomer(...);
public
Интерфейс для CustomerDAO
public interface CustomerDAO {
public int insertCustomer(...);
public

Имплементация интерфейса CustomerDAO
public class CloudscapeCustomerDAO
implements CustomerDAO {
public CloudscapeCustomerDAO()
Имплементация интерфейса CustomerDAO
public class CloudscapeCustomerDAO
implements CustomerDAO {
public CloudscapeCustomerDAO()

Customer Transfer Object
public class Customer implements
java.io.Serializable {
int
Customer Transfer Object
public class Customer implements
java.io.Serializable {
int

Использование DAO Factory
…………………………………
DAOFactory cloudscapeFactory =
DAOFactory.getDAOFactory(
DAOFactory.DAOCLOUDSCAPE);
CustomerDAO custDAO =
cloudscapeFactory.getCustomerDAO();
int
Использование DAO Factory
…………………………………
DAOFactory cloudscapeFactory =
DAOFactory.getDAOFactory(
DAOFactory.DAOCLOUDSCAPE);
CustomerDAO custDAO =
cloudscapeFactory.getCustomerDAO();
int

Hibernate
Hibernate - это механизм отображения в реляционной базе данных объектов java.
Hibernate
Hibernate - это механизм отображения в реляционной базе данных объектов java.

Java разработчикам доступно множество технологий для работы с данными это может
Java разработчикам доступно множество технологий для работы с данными это может

Рассмотрим примеры использования Hibernate.
В базе данных создадим таблицу Student с
Рассмотрим примеры использования Hibernate.
В базе данных создадим таблицу Student с

package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Student")
public class Student {
package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Student")
public class Student {

@Id
@GeneratedValue (generator="increment")
@GenericGenerator (name="increment", strategy = "increment")
@Column(name="id")
public Long
@Id @GeneratedValue (generator="increment") @GenericGenerator (name="increment", strategy = "increment") @Column(name="id") public Long

Аннотации здесь используются для Mapping Java классов с таблицами базы данных.
Аннотации здесь используются для Mapping Java классов с таблицами базы данных.

3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">

Создадим пакет util, а в нем класс HibernateUtil, который будет отвечать
Создадим пакет util, а в нем класс HibernateUtil, который будет отвечать

Теперь осталось разобраться со взаимодействием приложения с базой данных.
Тогда для
Теперь осталось разобраться со взаимодействием приложения с базой данных.
Тогда для

Теперь определим реализацию этого интерфейса в классе SudentDAOImpl в пакете DAO.Impl:
package
Теперь определим реализацию этого интерфейса в классе SudentDAOImpl в пакете DAO.Impl:
package

public void updateStudent(Student stud) throws SQLException {
Session session = null;
public void updateStudent(Student stud) throws SQLException { Session session = null;

public Student getStudentById(Long id) throws SQLException {
Session session = null;
public Student getStudentById(Long id) throws SQLException { Session session = null;

public List getAllStudents() throws SQLException {
Session session = null;
List
public List

public void deleteStudent(Student stud) throws SQLException {
Session session =
public void deleteStudent(Student stud) throws SQLException { Session session =

Создадим класс Factory в пакете DAO, к которому будем обращаться за
Создадим класс Factory в пакете DAO, к которому будем обращаться за

Метод main будет иметь вид:
import DAO.Factory;
public class Main {
public static
Метод main будет иметь вид:
import DAO.Factory;
public class Main {
public static

Запросы в Hibernate
Запросы возвращают набор данных из базы данных, удовлетворяющих заданному
Запросы в Hibernate
Запросы возвращают набор данных из базы данных, удовлетворяющих заданному

Запросы с использованием Criteria
Объект Criteria создается с помощью метода createCriteria экземпляра
Запросы с использованием Criteria
Объект Criteria создается с помощью метода createCriteria экземпляра
![List studs = session.createCriteria(Student.class) .add( Expression.in( "name", new String[] {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/17094/slide-102.jpg)
List studs = session.createCriteria(Student.class)
.add( Expression.in( "name", new String[] { "Ivanov
List studs = session.createCriteria(Student.class) .add( Expression.in( "name", new String[] { "Ivanov

Expression.like — указывает шаблон, где ‘_’ — любой один символ, ‘%’
Expression.like — указывает шаблон, где ‘_’ — любой один символ, ‘%’

Поля объекта, имеющие значение null или являющиеся идентификаторами, будут игнорироваться.
Example
Поля объекта, имеющие значение null или являющиеся идентификаторами, будут игнорироваться.
Example

Запросы с использованием SQL
Hibernate позволяет выражать запросы на родном для базы
Запросы с использованием SQL
Hibernate позволяет выражать запросы на родном для базы

Запросы с использованием HQL
Hibernate позволяет производить запросы на HQL(The Hibernate Query
Запросы с использованием HQL
Hibernate позволяет производить запросы на HQL(The Hibernate Query

Отношения в Hibernate
Помимо таблицы Student, создадим еще две таблицы Test и
Отношения в Hibernate
Помимо таблицы Student, создадим еще две таблицы Test и

Создадим эти две таблицы:
CREATE TABLE Test(tid NUMBER(10) NOT NULL,
tname varchar(100) NOT
Создадим эти две таблицы:
CREATE TABLE Test(tid NUMBER(10) NOT NULL,
tname varchar(100) NOT

Test
package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.JoinTable;
import javax.persistence.Table;
import javax.persistence.JoinColumn;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Test")
public class
Test
package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.JoinTable;
import javax.persistence.Table;
import javax.persistence.JoinColumn;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Test")
public class

public Test(Test s){
tname = s.getTName();
}
@Id
@GeneratedValue(generator="increment")
@GenericGenerator(name="increment", strategy
public Test(Test s){ tname = s.getTName(); } @Id @GeneratedValue(generator="increment") @GenericGenerator(name="increment", strategy

Statistics
package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Statistics")
public class Statistics {
Statistics
package logic;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.Table;
import org.hibernate.annotations.GenericGenerator;
@Entity
@Table(name="Statistics")
public class Statistics {

@Id
@GeneratedValue(generator="increment")
@GenericGenerator(name="increment", strategy = "increment")
@Column(name="stid")
public Long getStid(){
return
@Id @GeneratedValue(generator="increment") @GenericGenerator(name="increment", strategy = "increment") @Column(name="stid") public Long getStid(){ return

Классы TestDAO и TestDAOImpl создаются аналогично как для сущности Student.
Осталось
Классы TestDAO и TestDAOImpl создаются аналогично как для сущности Student.
Осталось

В классе Statistics аннотируем связь один ко многим с классом Student:
private
В классе Statistics аннотируем связь один ко многим с классом Student:
private

Так же обозначаем отношение таблицы Test и Statistics, просто добавив в
Так же обозначаем отношение таблицы Test и Statistics, просто добавив в

Поскольку таблица Statistics является не просто таблицей, связанной со Student и
Поскольку таблица Statistics является не просто таблицей, связанной со Student и

Если бы мы обозначали эту связь в классе Student:
private Test test;
@ManyToOne
@JoinTable(name
Если бы мы обозначали эту связь в классе Student:
private Test test;
@ManyToOne
@JoinTable(name
Другой пример реализации Hibernate JPA
Рассмотрим пример работы с базой данный с
Другой пример реализации Hibernate JPA
Рассмотрим пример работы с базой данный с

Создадим класс mytable, который соответствует записи в таблице:
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name= “mytable”)
Создадим класс mytable, который соответствует записи в таблице:
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name= “mytable”)

public mytable() {};
public mytable(String name,Byte b){
this.age=b;
this.name=name;
}
public mytable() {};
public mytable(String name,Byte b){
this.age=b;
this.name=name;
}

Hibernate для своей работы требует специальный файл конфигурации(если точнее, то он
Hibernate для своей работы требует специальный файл конфигурации(если точнее, то он

value="jdbc:mysql://localhost:3306/mybase" />

Тогда работа с базой данных будет иметь вид:
import javax.persistence.*;
public class Main
Тогда работа с базой данных будет иметь вид:
import javax.persistence.*;
public class Main

Компиляция и запуск
Для компиляции удобно воспользоваться утилитой ant(разработка Apache foundation http://ant.apache.org/).
Создаем
Компиляция и запуск
Для компиляции удобно воспользоваться утилитой ant(разработка Apache foundation http://ant.apache.org/).
Создаем

5. В base помещаем файл build.xml, который имеет вид:
5. В base помещаем файл build.xml, который имеет вид:


"copy-resources">

"clean,copy-resources,compile">


6. Перейти в директорию base и из консоли запустить ant
D:\base>ant
В результате
6. Перейти в директорию base и из консоли запустить ant
D:\base>ant
В результате

Пакет JOOQ
Данный пакет представляет собой Linq для Java. С помощью данной
Пакет JOOQ
Данный пакет представляет собой Linq для Java. С помощью данной

Создаем файл mybase.properties:
jdbc.Driver=com.mysql.jdbc.Driver
jdbc.URL=jdbc:mysql://localhost:3306/mybase
jdbc.Schema=mybase
jdbc.User=muser
jdbc.Password=qwertyui
#The default code generator. You can override this one,
Создаем файл mybase.properties:
jdbc.Driver=com.mysql.jdbc.Driver
jdbc.URL=jdbc:mysql://localhost:3306/mybase
jdbc.Schema=mybase
jdbc.User=muser
jdbc.Password=qwertyui
#The default code generator. You can override this one,

#Primary key / foreign key relations should be generated and used.
#Primary key / foreign key relations should be generated and used.

Генерируем классы, соответствующие базе данных
java -classpath jooq-1.6.9.jar;jooq-meta-1.6.9.jar;
jooq-codegen-1.6.9.jar;mysql-connector-java-
5.1.18-bin.jar;. org.jooq.util.GenerationTool
/mybase.properties
Тогда
Генерируем классы, соответствующие базе данных
java -classpath jooq-1.6.9.jar;jooq-meta-1.6.9.jar;
jooq-codegen-1.6.9.jar;mysql-connector-java-
5.1.18-bin.jar;. org.jooq.util.GenerationTool
/mybase.properties
Тогда
![public class Main { public static void main(String[] args) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/17094/slide-135.jpg)
public class Main {
public static void main(String[] args) {
Connection
public class Main {
public static void main(String[] args) {
Connection
 Машинный язык и язык высокого уровня
Машинный язык и язык высокого уровня Основные процедуры обработки массивов данных. (Лабораторная работа 6)
Основные процедуры обработки массивов данных. (Лабораторная работа 6) Основы и система обеспечения информационной безопасности хозяйствующего субъекта
Основы и система обеспечения информационной безопасности хозяйствующего субъекта Методы оценивания угроз
Методы оценивания угроз Значение коммуникации в управлении организацией
Значение коммуникации в управлении организацией Нелинейные структуры данных. Лекция 1
Нелинейные структуры данных. Лекция 1 SQL Overview
SQL Overview 3G technology
3G technology Сетевая этика. Культура общения в сети
Сетевая этика. Культура общения в сети Аддитивные технологии
Аддитивные технологии Графический редактор
Графический редактор How to Activate AutoDesk any product for free
How to Activate AutoDesk any product for free Обработка больших данных. Python 2 и Python 3
Обработка больших данных. Python 2 и Python 3 Информация и информационные процессы. Измерение и кодирование информации
Информация и информационные процессы. Измерение и кодирование информации Разработка информационной системы инвентаризации компьютеров в сети для предприятия
Разработка информационной системы инвентаризации компьютеров в сети для предприятия Тестирование безопасности
Тестирование безопасности Создания спецификаций в КА. Пекарня Хлебница
Создания спецификаций в КА. Пекарня Хлебница Типология информационных ресурсов Интернет
Типология информационных ресурсов Интернет Chapter 2. SQL injection
Chapter 2. SQL injection Создание Web-сайтов
Создание Web-сайтов Понятие ресурса ОС
Понятие ресурса ОС Аналіз складних об’єктів і систем. Аналітичні дослідження
Аналіз складних об’єктів і систем. Аналітичні дослідження DTU – Data Transfer Untility Training
DTU – Data Transfer Untility Training Эволюция операционных систем
Эволюция операционных систем Email risk policy
Email risk policy Фишинг. Схема действия фишинга
Фишинг. Схема действия фишинга Графы. Деревья
Графы. Деревья Автоматизована обробка інформації в системі пенсійного забезпечення України
Автоматизована обробка інформації в системі пенсійного забезпечення України