- Обработка больших данных. Python 2 и Python 3

Содержание
- 2. ЛИТЕРАТУРА
- 3. Python 2 и Python 3 Python 3 - более новая версия. Иногда код, написанный на Python
- 4. Скопировать файл affinity_dataset.txt [в папку python (по умолчанию при установке C:\Users\User ), или указывать путь] import
- 5. - Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1 по каждому item. Решить задачу
- 6. Пример реализации для произвольной пары #Составляем правила: если X1=1 и X2=1 – то valid, иначе –
- 7. # Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1 # (т.е. когда X1=1, а
- 8. Визуализация и анализ данных: сортировать по парам по убыванию их совместных реализаций; сортировать по вероятности появления
- 9. Установка свободного дистрибутива Python для научных вычислений, специально предназначенного для Windows, включающего: NumPy, SciPy, matplotlib, pandas,
- 10. Jupyter Notebook, JupyterLab Интерактивная среда для запуска программного кода в браузере. Инструмент для анализа данных, Позволяет
- 11. SciPy Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация, обработка сигналов, статистика. SCIKIT-LEARN использует
- 12. SciPy # Массив NumPy преобразуем в разреженную матрицу SciPy в формате CSR # Compressed Sparse Row
- 13. Matplotlib Основная библиотека для построения графиков. Включает функции для создания высококачественных визуализаций типа линейных диаграмм, гистограмм,
- 14. Pandas Библиотека для обработки и анализа данных. Построена на основе структуры данных DataFrame (таблицы, похожие на
- 15. Вспомнить: class (target, цель) Есть ли на фото тигр? Болен ли пациент таким-то заболеванием? Продается ли
- 16. 2. Задача классификации. OneR (one rule) алгоритм Загрузить файл данных из модуля datasets библиотеки scikit-learn, вызвав
- 17. 2. Задача классификации. OneR (one rule) алгоритм # Массив target содержит сорта уже измеренных цветов, записанные
- 18. 2. Задача классификации. OneR (one rule) алгоритм Для решения задачи классификации с учителем надо иметь 2
- 20. Скачать презентацию

ЛИТЕРАТУРА
ЛИТЕРАТУРА

Python 2 и Python 3
Python 3 - более новая версия.
Иногда
Python 2 и Python 3
Python 3 - более новая версия.
Иногда

Скопировать файл affinity_dataset.txt
[в папку python (по умолчанию при установке C:\Users\User
Скопировать файл affinity_dataset.txt
[в папку python (по умолчанию при установке C:\Users\User

- Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1
- Открыть файл данных в Excel. Посмотреть структуру. Посчитать кол-во 1

Пример реализации для произвольной пары
#Составляем правила: если X1=1 и X2=1 –
Пример реализации для произвольной пары
#Составляем правила: если X1=1 и X2=1 –

# Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1
# Статистика, вероятность совпадений X1=X2=1 относительно общего числа выпаданий только Х1

Визуализация и анализ данных:
сортировать по парам по убыванию их совместных
Визуализация и анализ данных:
сортировать по парам по убыванию их совместных

Установка свободного дистрибутива Python для научных вычислений, специально предназначенного для Windows,
Установка свободного дистрибутива Python для научных вычислений, специально предназначенного для Windows,

Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.
Jupyter Notebook, JupyterLab
Интерактивная среда для запуска программного кода в браузере.

SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,
SciPy
Библиотека для научных вычислений: матричные вычисления, процедуры линейной алгебры, оптимизация,

SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
SciPy
# Массив NumPy преобразуем в разреженную матрицу SciPy в формате
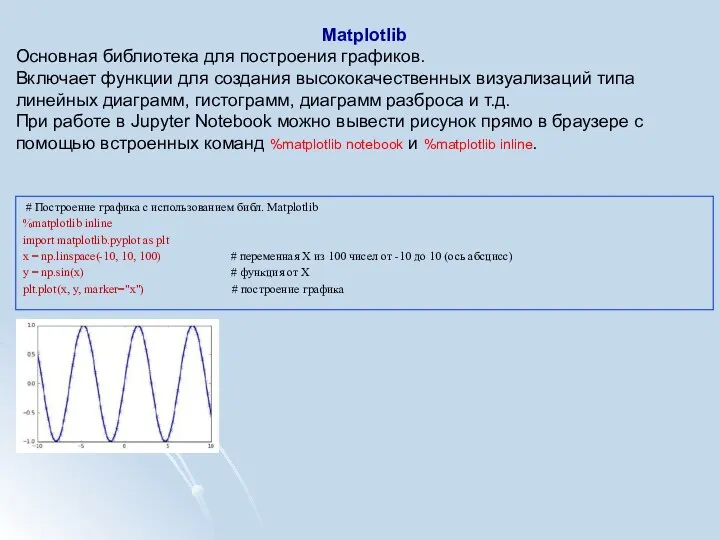
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных
Matplotlib
Основная библиотека для построения графиков.
Включает функции для создания высококачественных

Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры
Pandas
Библиотека для обработки и анализа данных.
Построена на основе структуры

Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент
Вспомнить:
class (target, цель)
Есть ли на фото тигр?
Болен ли пациент

2. Задача классификации. OneR (one rule) алгоритм
Загрузить файл данных из модуля
2. Задача классификации. OneR (one rule) алгоритм
Загрузить файл данных из модуля

2. Задача классификации. OneR (one rule) алгоритм
# Массив target содержит сорта
2. Задача классификации. OneR (one rule) алгоритм
# Массив target содержит сорта

2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
2. Задача классификации. OneR (one rule) алгоритм
Для решения задачи классификации с
 Цветовые модели компьютерной графики
Цветовые модели компьютерной графики Sistem pakar. Definisi Kecerdasan Buatan
Sistem pakar. Definisi Kecerdasan Buatan Призначення й використання логічних функцій табличного процесора. Умовне форматування
Призначення й використання логічних функцій табличного процесора. Умовне форматування Задача о пути торможения автомобиля
Задача о пути торможения автомобиля Алгоритмизация и программирование. Язык C++. (§ 38 - § 45)
Алгоритмизация и программирование. Язык C++. (§ 38 - § 45) Компьютерные сети
Компьютерные сети Разработка урока по информатике Путешествие в компьютерную страну 7 класс
Разработка урока по информатике Путешествие в компьютерную страну 7 класс Массивы. Решение задач. Подготовка к ЕГЭ
Массивы. Решение задач. Подготовка к ЕГЭ Methods of graphical representation of information
Methods of graphical representation of information Поведенческие паттерны
Поведенческие паттерны Основы системного администрирования. Мониторинг производительности и устранение неполадок
Основы системного администрирования. Мониторинг производительности и устранение неполадок Операции, линейный алгоритм. (Семинар 1-3)
Операции, линейный алгоритм. (Семинар 1-3) Тема 4. Занятие 3. Функции
Тема 4. Занятие 3. Функции Технологический слой
Технологический слой Задача о минимальном разрезе на взвешенном бисвязном графе
Задача о минимальном разрезе на взвешенном бисвязном графе Электронный листок нетрудоспособности на территории Ленинградской области
Электронный листок нетрудоспособности на территории Ленинградской области ЕГЭ 2015 по информатике
ЕГЭ 2015 по информатике Массивы. Лабиринт с тупиками
Массивы. Лабиринт с тупиками Створення комп'ютерних презентацій (10 клас)
Створення комп'ютерних презентацій (10 клас) Программное обеспечение
Программное обеспечение История вычислительной техники. Викторина
История вычислительной техники. Викторина Современный образовательный портал MegaCampus
Современный образовательный портал MegaCampus Инструкция по поиску информации в базе данных Astrophysics Data System
Инструкция по поиску информации в базе данных Astrophysics Data System Принципы построения ОС. Основные принципы построения ОС
Принципы построения ОС. Основные принципы построения ОС Защита персональных данных
Защита персональных данных Техническая система. Лекция 4
Техническая система. Лекция 4 Классы. Лекция 8
Классы. Лекция 8 Системы автоматизированного проектирования и производства
Системы автоматизированного проектирования и производства