- Нелинейные структуры данных. Лекция 1

Содержание
- 2. Учебный план дисциплины Лекции 16 часов (8 лекций) Практические занятия 32 часа (16 занятий) Отчетность: экзамен
- 3. 1. Кормен Т.Х., Лейзерсон Ч.И., Ривест Р.Л.Алгоритмы: построение и анализ. - Вильямс, 2019 2. Дональд Э.
- 4. Лекция 1 Введение в нелинейные структуры Иерархическая структура – k-арное дерево
- 5. Повторим!!!!
- 6. Структуры данных Структура данных - совокупность логически связанных элементов данных между которыми существуют некоторые отношения, при
- 7. От задачи к программе Абстрактный тип данных – это математическая модель данных с совокупностью операций, определенных
- 8. Три уровня представления данных Структура данных задачи Структура данных языка программирования Структура хранения данных
- 9. Структуры хранения Векторное хранение Размещение элементов структуры в последовательно организованной памяти. Элемент хранит только данные, отношения
- 10. Сложность алгоритма Эффективный алгоритм должен удовлетворять требованиям: приемлемое время исполнения разумной объем оперативной памяти. Совокупность этих
- 11. Пример 1. Определение теоретической вычислительной сложности алгоритма Вычислить среднее арифметическое всех положительных чисел массива A из
- 12. Асимптотический анализ и асимптотические обозначения вычислительной сложности алгоритма Асимптотический анализ – упрощенный способ оценки сложности алгоритма
- 13. Часто встречающиеся асимптотические обозначения
- 14. Нелинейные структуры данных Позволяют хранить более сложные отношения между элементами структуры данных, по сравнению с линейными
- 15. Нелинейные структуры данных Иерархическая структура (Дерево) Граф ( Сеть) Лес
- 16. Классификация структур данных в зависимости от отношений между элементами
- 17. Примеры структур данных с нелинейными отношениями 1) Оглавление в книге Раздел 1. Глава 1 Название темы
- 18. 3) Организационная диаграмма выполнения строительных работ при строительстве здания
- 19. Примеры структур данных с нелинейными отношениями (продолжение) 4) Карта автомобильных дорог, карта авиационных перевозок, карта метро
- 20. Иерархические структуры данных (деревья) В иерархической структуре данных, элементы подчинены отношению: у каждого потомка есть только
- 21. Модель иерархической структуры Рис.1. Дерево – иерархическая структура данных
- 22. Основные термины иерархической структуры В виде кружков представлены элементы данных (вершины дерева/узлы), линии, их соединяющие, указывают
- 23. Основные термины иерархической структуры (продолжение) В деревьях действует отношение: у каждого потомка только один предок. 2.
- 24. Основные термины иерархической структуры (продолжение) 8. Путь в дереве – последовательность узлов от корня к указанному
- 25. Основные термины иерархической структуры (продолжение) 13. Упорядоченные и неупорядоченные деревья Дерево считается упорядоченным, если существует порядок
- 26. Определение иерархической структуры ( дерева) Дерево - это совокупность узлов, один из которых корень, и отношений,
- 27. Определение k – ароного дерева Арность дерева определяется степенью дерева. Пусть T1 T2 T3…Tk деревья с
- 28. Рекурсивное определение дерева Из приведенных определений видно, что структура определена с помощью рекурсии, поэтому можно ввести
- 29. Виды деревьев Сильно ветвящиеся деревья (степень дерева >2). Двоичное (бинарное) дерево (степень дерева Двоичное идеально сбалансированное
- 30. Способы реализации деревьев Для представления упорядоченных деревьев в памяти компьютера можно использовать: линейные структуры данных (массив,
- 31. Способы реализации деревьев: Массив родителей Пусть есть дерево, представленное на рисунке, создадим его массив родителей
- 32. Способы программной реализации массива родителей Способ 1. Определение количества максимально возможных узлов Maxlen. Определение массива для
- 33. Способы программной реализации массива родителей Способ 2. Определение всех параметров дерева в одной структуре struct Tree
- 34. Применение представления дерева на массиве родителей Задача. Найти левого сына заданного узла и его правого брата.
- 35. Задача 1.Найти левого сына заданного узла Для поиска левого сына узла 2 в дереве А ,
- 36. Задача 2.Найти правого брата заданного узла При решении задачи по поиску правого брата узла достаточно найти
- 37. Способы реализации деревьев: Списки сыновей Представление дерева основано на массиве линейных списков. Каждый список хранит метки
- 38. Реализация дерева на списках сыновей Структура элемента списка struct Tnode{ Tinfo info; //данные элемента Tnode *next;
- 39. Способы реализации деревьев: список левых сыновей и правых братьев Такой подход по реализации списков на массивах,
- 40. Способы реализации деревьев: Список левых сыновей и правых братьев в таблице
- 41. Реализация дерева в таблице Структура элемента таблицы struct TNode{ int Left; //левое поддерево char Nod; //метка
- 42. Способы реализации деревьев: связанное размещение узлов дерева в динамической памяти
- 43. Реализация структуры узла динамически размещаемого узла дерева и самого дерева struct Tnode{ Tdata data; //поле для
- 44. Способы реализации деревьев: связанное размещение узлов со ссылкой на сыновей и родителя В некоторых алгоритмах удобно
- 45. Алгоритмы обхода K– арного дерева K-арное дерево типа T это: Пустая структура или Состоит из 1-го
- 46. Методы обхода дерева Требование. Обход дерева возможен, если дерево упорядочено. обход методом в глубину - это
- 47. Схемы обхода дерева методом в глубину Существует три алгоритма обхода в глубину: прямой, обратный, симметричный. Рассмотрим
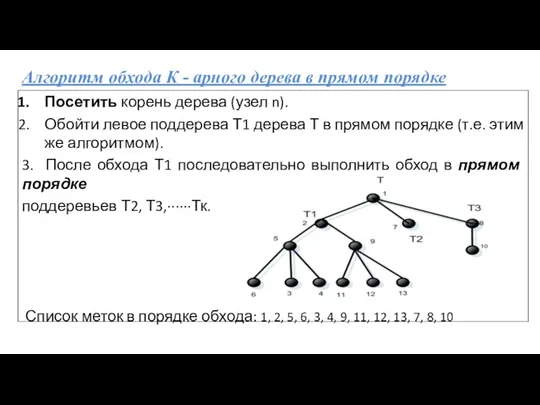
- 48. Алгоритм обхода К - арного дерева в прямом порядке Посетить корень дерева (узел n). Обойти левое
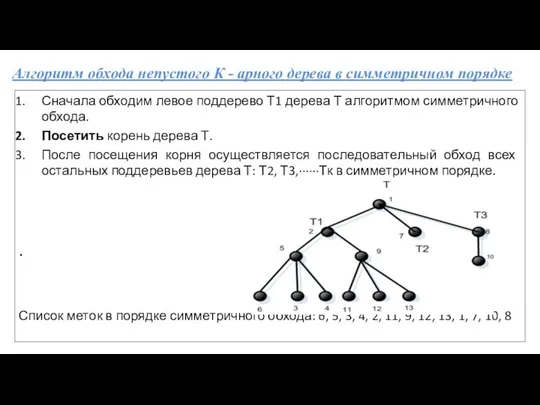
- 49. Алгоритм обхода непустого К - арного дерева в симметричном порядке Сначала обходим левое поддерево Т1 дерева
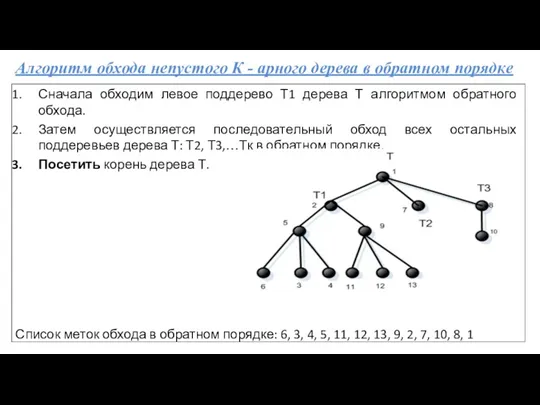
- 50. Алгоритм обхода непустого К - арного дерева в обратном порядке Сначала обходим левое поддерево Т1 дерева
- 51. Выводы по алгоритмам Так как дерево является рекурсивно определяемой структурой, то алгоритмы обхода методом в глубину
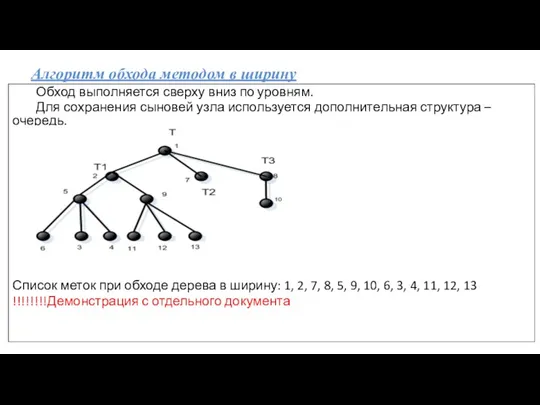
- 52. Алгоритм обхода методом в ширину Обход выполняется сверху вниз по уровням. Для сохранения сыновей узла используется
- 53. Абстрактный тип данных – дерево и определим в нем данные (дерево) и операции над деревом АТД
- 54. Алгоритм обхода k – арного дерева рекурсивно Если дерево является пустым, то при обходе в список
- 55. Алгоритм обхода в прямом порядке на псевдокоде Посетить корень – n (занести в список посещенных) Затем
- 56. Алгоритм обхода в симметричном порядке на псевдокоде Обход поддерева Т1 в симметричном порядке Посетить корень n
- 57. Алгоритм обхода в обратном порядке на псевдокоде Посещаем все узлы поддерева Т1 в обратном порядке Далее
- 59. Скачать презентацию

Учебный план дисциплины
Лекции 16 часов (8 лекций)
Практические занятия 32 часа (16
Учебный план дисциплины
Лекции 16 часов (8 лекций)
Практические занятия 32 часа (16

1. Кормен Т.Х., Лейзерсон Ч.И., Ривест Р.Л.Алгоритмы: построение и анализ. -
1. Кормен Т.Х., Лейзерсон Ч.И., Ривест Р.Л.Алгоритмы: построение и анализ. -

Лекция 1
Введение в нелинейные структуры
Иерархическая структура – k-арное дерево
Лекция 1
Введение в нелинейные структуры
Иерархическая структура – k-арное дерево

Повторим!!!!
Повторим!!!!

Структуры данных
Структура данных - совокупность логически связанных элементов данных между
Структуры данных
Структура данных - совокупность логически связанных элементов данных между

От задачи к программе
Абстрактный тип данных – это математическая модель данных
От задачи к программе
Абстрактный тип данных – это математическая модель данных

Три уровня представления данных
Структура данных задачи
Структура данных языка программирования
Структура хранения
Три уровня представления данных
Структура данных задачи
Структура данных языка программирования
Структура хранения

Структуры хранения
Векторное хранение
Размещение элементов структуры в последовательно организованной памяти. Элемент хранит
Структуры хранения
Векторное хранение
Размещение элементов структуры в последовательно организованной памяти. Элемент хранит

Сложность алгоритма
Эффективный алгоритм должен удовлетворять требованиям:
приемлемое время исполнения
разумной объем
Сложность алгоритма
Эффективный алгоритм должен удовлетворять требованиям:
приемлемое время исполнения
разумной объем

Пример 1. Определение теоретической вычислительной сложности алгоритма Вычислить среднее арифметическое всех
Пример 1. Определение теоретической вычислительной сложности алгоритма Вычислить среднее арифметическое всех
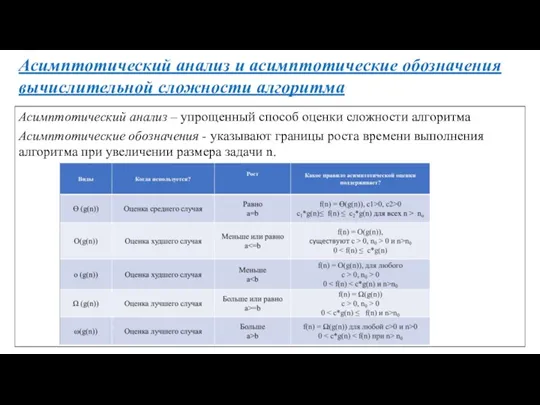
Асимптотический анализ и асимптотические обозначения вычислительной сложности алгоритма
Асимптотический анализ – упрощенный
Асимптотический анализ и асимптотические обозначения вычислительной сложности алгоритма
Асимптотический анализ – упрощенный

Часто встречающиеся асимптотические обозначения
Часто встречающиеся асимптотические обозначения

Нелинейные структуры данных
Позволяют хранить более сложные отношения между элементами структуры данных,
Нелинейные структуры данных
Позволяют хранить более сложные отношения между элементами структуры данных,

Нелинейные структуры данных
Иерархическая структура (Дерево)
Граф ( Сеть)
Лес
Нелинейные структуры данных
Иерархическая структура (Дерево)
Граф ( Сеть)
Лес
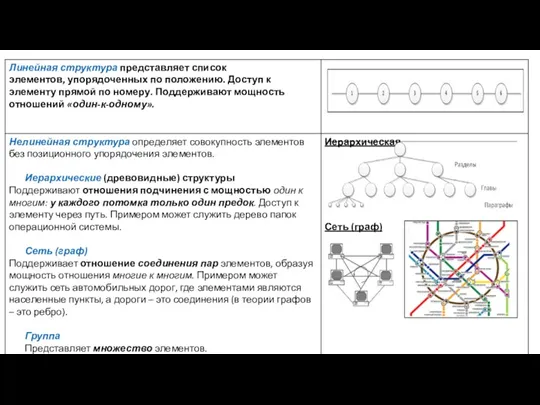
Классификация структур данных в зависимости от отношений между элементами
Классификация структур данных в зависимости от отношений между элементами
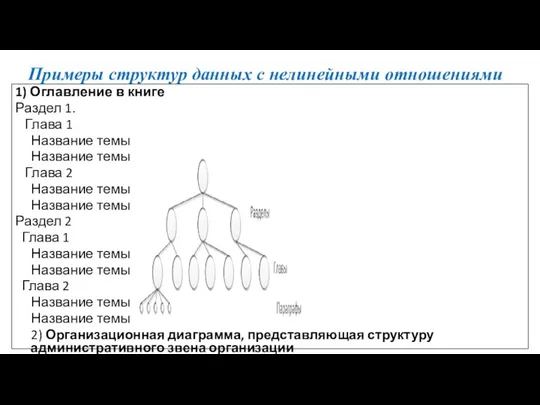
Примеры структур данных с нелинейными отношениями
1) Оглавление в книге
Раздел 1.
Глава
Примеры структур данных с нелинейными отношениями
1) Оглавление в книге
Раздел 1.
Глава
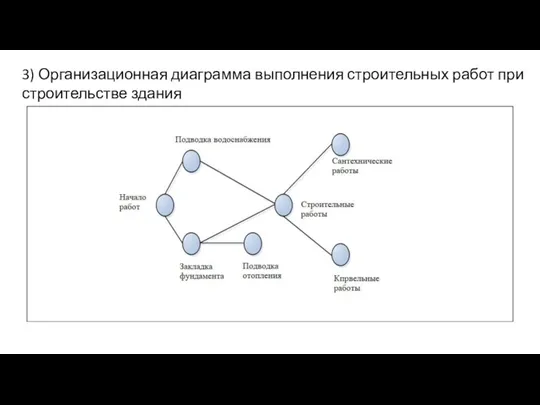
3) Организационная диаграмма выполнения строительных работ при строительстве здания
3) Организационная диаграмма выполнения строительных работ при строительстве здания

Примеры структур данных с нелинейными отношениями (продолжение)
4) Карта автомобильных дорог, карта
Примеры структур данных с нелинейными отношениями (продолжение)
4) Карта автомобильных дорог, карта

Иерархические структуры данных (деревья)
В иерархической структуре данных, элементы подчинены отношению:
у
Иерархические структуры данных (деревья)
В иерархической структуре данных, элементы подчинены отношению:
у
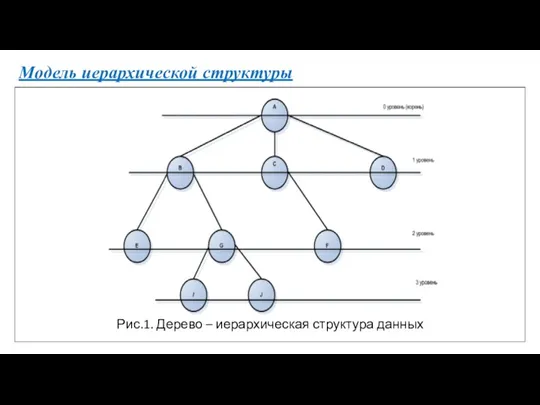
Модель иерархической структуры
Рис.1. Дерево – иерархическая структура данных
Модель иерархической структуры
Рис.1. Дерево – иерархическая структура данных

Основные термины иерархической структуры
В виде кружков представлены элементы данных (вершины дерева/узлы),
Основные термины иерархической структуры
В виде кружков представлены элементы данных (вершины дерева/узлы),

Основные термины иерархической структуры (продолжение)
В деревьях действует отношение: у каждого
потомка
Основные термины иерархической структуры (продолжение)
В деревьях действует отношение: у каждого
потомка
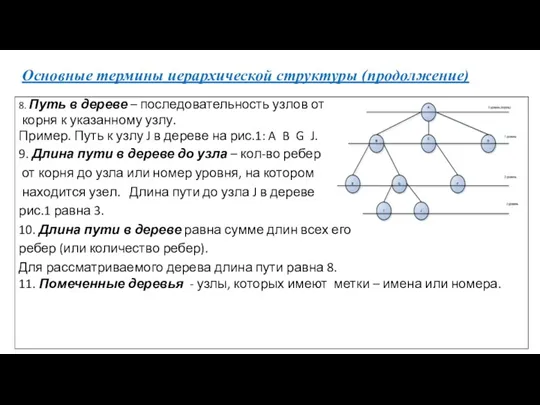
Основные термины иерархической структуры (продолжение)
8. Путь в дереве – последовательность узлов
Основные термины иерархической структуры (продолжение)
8. Путь в дереве – последовательность узлов

Основные термины иерархической структуры (продолжение)
13. Упорядоченные и неупорядоченные деревья
Дерево считается упорядоченным,
Основные термины иерархической структуры (продолжение)
13. Упорядоченные и неупорядоченные деревья
Дерево считается упорядоченным,
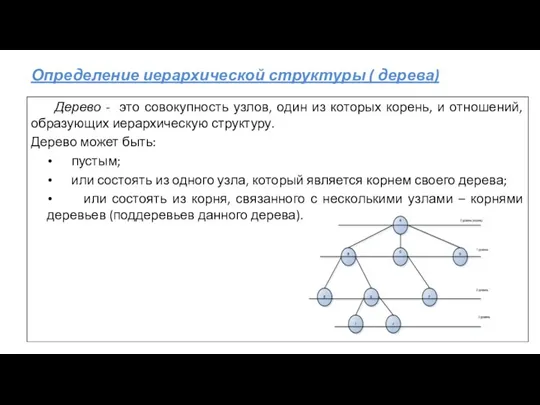
Определение иерархической структуры ( дерева)
Дерево - это совокупность узлов, один из
Определение иерархической структуры ( дерева)
Дерево - это совокупность узлов, один из
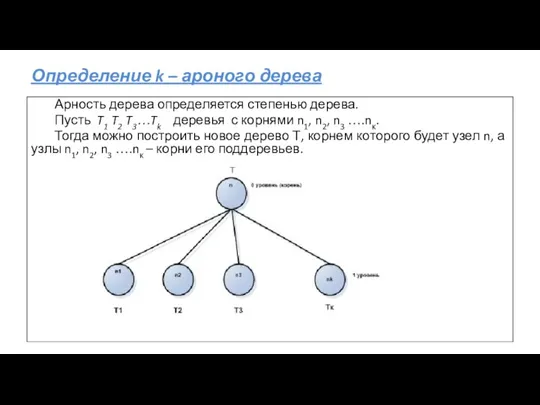
Определение k – ароного дерева
Арность дерева определяется степенью дерева.
Пусть T1
Определение k – ароного дерева
Арность дерева определяется степенью дерева.
Пусть T1

Рекурсивное определение дерева
Из приведенных определений видно, что структура определена с помощью
Рекурсивное определение дерева
Из приведенных определений видно, что структура определена с помощью

Виды деревьев
Сильно ветвящиеся деревья (степень дерева >2).
Двоичное (бинарное) дерево (степень дерева
Виды деревьев
Сильно ветвящиеся деревья (степень дерева >2).
Двоичное (бинарное) дерево (степень дерева

Способы реализации деревьев
Для представления упорядоченных деревьев в памяти компьютера можно использовать:
Способы реализации деревьев
Для представления упорядоченных деревьев в памяти компьютера можно использовать:

Способы реализации деревьев: Массив родителей
Пусть есть дерево, представленное на рисунке, создадим
Способы реализации деревьев: Массив родителей
Пусть есть дерево, представленное на рисунке, создадим

Способы программной реализации массива родителей
Способ 1.
Определение количества максимально возможных узлов
Способы программной реализации массива родителей
Способ 1.
Определение количества максимально возможных узлов

Способы программной реализации массива родителей
Способ 2. Определение всех параметров дерева в
Способы программной реализации массива родителей
Способ 2. Определение всех параметров дерева в
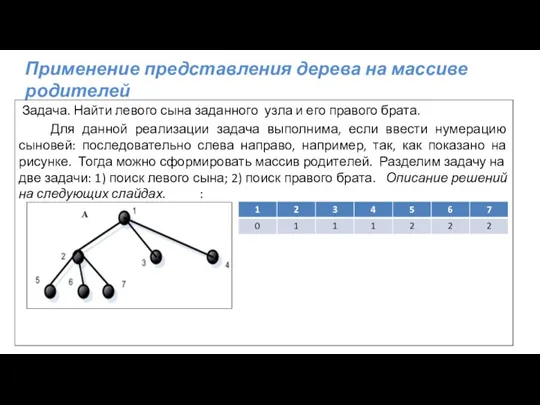
Применение представления дерева на массиве родителей
Задача. Найти левого сына заданного
Применение представления дерева на массиве родителей
Задача. Найти левого сына заданного

Задача 1.Найти левого сына заданного узла
Для поиска левого сына узла 2
Задача 1.Найти левого сына заданного узла
Для поиска левого сына узла 2

Задача 2.Найти правого брата заданного узла
При решении задачи по поиску правого
Задача 2.Найти правого брата заданного узла
При решении задачи по поиску правого
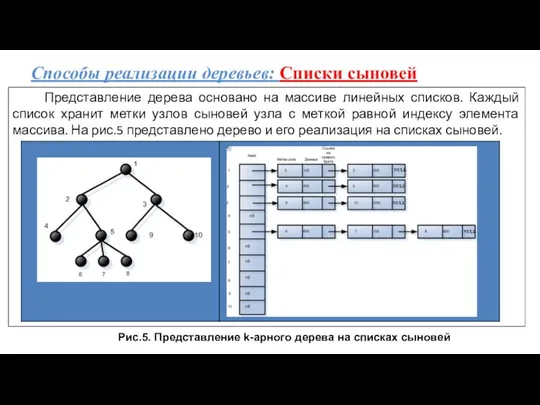
Способы реализации деревьев: Списки сыновей
Представление дерева основано на массиве линейных списков.
Способы реализации деревьев: Списки сыновей
Представление дерева основано на массиве линейных списков.

Реализация дерева на списках сыновей
Структура элемента списка
struct Tnode{
Tinfo info; //данные элемента
Tnode
Реализация дерева на списках сыновей
Структура элемента списка
struct Tnode{
Tinfo info; //данные элемента
Tnode

Способы реализации деревьев: список левых сыновей и правых братьев
Такой подход по
Способы реализации деревьев: список левых сыновей и правых братьев
Такой подход по
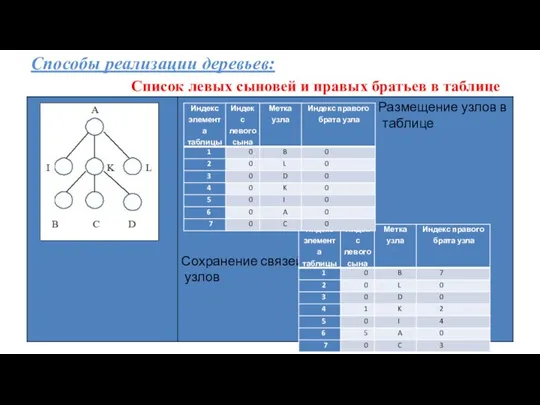
Способы реализации деревьев: Список левых сыновей и правых братьев в таблице
Способы реализации деревьев: Список левых сыновей и правых братьев в таблице

Реализация дерева в таблице
Структура элемента таблицы
struct TNode{
int Left; //левое поддерево
char
Реализация дерева в таблице
Структура элемента таблицы
struct TNode{
int Left; //левое поддерево
char
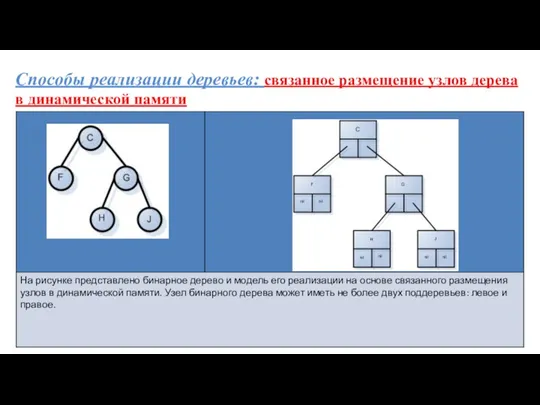
Способы реализации деревьев: связанное размещение узлов дерева в динамической памяти
Способы реализации деревьев: связанное размещение узлов дерева в динамической памяти

Реализация структуры узла динамически размещаемого узла дерева и самого дерева
struct Tnode{
Реализация структуры узла динамически размещаемого узла дерева и самого дерева
struct Tnode{

Способы реализации деревьев: связанное размещение узлов со ссылкой на сыновей и
Способы реализации деревьев: связанное размещение узлов со ссылкой на сыновей и

Алгоритмы обхода K– арного дерева
K-арное дерево типа T это:
Пустая структура или
Состоит
Алгоритмы обхода K– арного дерева
K-арное дерево типа T это:
Пустая структура или
Состоит

Методы обхода дерева
Требование. Обход дерева возможен, если дерево упорядочено.
обход методом в
Методы обхода дерева
Требование. Обход дерева возможен, если дерево упорядочено.
обход методом в

Схемы обхода дерева методом в глубину
Существует три алгоритма обхода в глубину:
Схемы обхода дерева методом в глубину
Существует три алгоритма обхода в глубину:
Алгоритм обхода К - арного дерева в прямом порядке
Посетить корень дерева
Алгоритм обхода К - арного дерева в прямом порядке
Посетить корень дерева
Алгоритм обхода непустого К - арного дерева в симметричном порядке
Сначала
Алгоритм обхода непустого К - арного дерева в симметричном порядке
Сначала
Алгоритм обхода непустого К - арного дерева в обратном порядке
Сначала обходим
Алгоритм обхода непустого К - арного дерева в обратном порядке
Сначала обходим

Выводы по алгоритмам
Так как дерево является рекурсивно определяемой структурой, то
Выводы по алгоритмам
Так как дерево является рекурсивно определяемой структурой, то
Алгоритм обхода методом в ширину
Обход выполняется сверху вниз по уровням.
Для сохранения
Алгоритм обхода методом в ширину
Обход выполняется сверху вниз по уровням.
Для сохранения

Абстрактный тип данных – дерево
и определим в нем данные (дерево) и
Абстрактный тип данных – дерево
и определим в нем данные (дерево) и

Алгоритм обхода k – арного дерева рекурсивно
Если дерево является пустым, то
Алгоритм обхода k – арного дерева рекурсивно
Если дерево является пустым, то

Алгоритм обхода в прямом порядке на псевдокоде
Посетить корень – n (занести
Алгоритм обхода в прямом порядке на псевдокоде
Посетить корень – n (занести

Алгоритм обхода в симметричном порядке на псевдокоде
Обход поддерева Т1 в симметричном
Алгоритм обхода в симметричном порядке на псевдокоде
Обход поддерева Т1 в симметричном

Алгоритм обхода в обратном порядке на псевдокоде
Посещаем все узлы поддерева Т1
Алгоритм обхода в обратном порядке на псевдокоде
Посещаем все узлы поддерева Т1
 Ideas about site. Dental laboratory
Ideas about site. Dental laboratory Разработка WPF приложений в стиле ViewModel First
Разработка WPF приложений в стиле ViewModel First Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab)
Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab) Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование
Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока
Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока Поиск целевого трафика Вконтакте
Поиск целевого трафика Вконтакте Инфокоммуникационная сеть, как большая и сложная система
Инфокоммуникационная сеть, как большая и сложная система Java.SE.07 Multithreading
Java.SE.07 Multithreading Создание 3D пазл для детей младшего возраста
Создание 3D пазл для детей младшего возраста Dark-Wave
Dark-Wave Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных
Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных MNGT 1710 Course Resources
MNGT 1710 Course Resources Основы журналистики. Пражурналистика и формирование журналистики
Основы журналистики. Пражурналистика и формирование журналистики Создание 3D модели острова в программе Blender
Создание 3D модели острова в программе Blender Использование оборудования фирмы Iskratel для построения мультисервисных сетей
Использование оборудования фирмы Iskratel для построения мультисервисных сетей Язык UML. Диаграммы деятельности. Варианты использования
Язык UML. Диаграммы деятельности. Варианты использования PHP #1.1. Введение. Быстрый старт
PHP #1.1. Введение. Быстрый старт Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор
Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор SWIFT Professional Services I Alliance Lite2 Kick-off
SWIFT Professional Services I Alliance Lite2 Kick-off Операционные системы Windows от XP к 7
Операционные системы Windows от XP к 7 Программаларды өңдеудің аспаптың құралдары (ПӨАҚ)
Программаларды өңдеудің аспаптың құралдары (ПӨАҚ) Інформаційна зброя
Інформаційна зброя Способы кодирования информации
Способы кодирования информации TLS and SSL
TLS and SSL Информационная безопасность. Криптографические средства защиты данных
Информационная безопасность. Криптографические средства защиты данных Доставка терминалов. Собственный процессинг
Доставка терминалов. Собственный процессинг Введение в R
Введение в R Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1
Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1