- Классификация данных. Лекция 5

Содержание
- 2. Определение Классификация – это процесс определения принадлежности объектов к определенным классам. классификация относится к типу задач
- 3. Применение задач классификации Существует много практических задач классификации. В промышленности при оценке качества продукции возникает задача
- 4. Два этапа Применение классификации производится в два этапа. 1 – выполняется обучение классификатора на некотором наборе
- 5. Виды классификации Различают бинарную и множественную классификацию. Бинарная классификация предполагает наличие двух классов, множественная – трех
- 6. Бинарная классификация определение принадлежности некоего объекта к одному из двух возможных классов.
- 7. Примеры бинарной классификации - является ли сообщение электронной почты «нормальным» или представляет собой спам; - здоров
- 8. Методы бинарной классификации - логистическая регрессия (Logistic Regression); - «наивный» байесовский классификатор (Naive Bayes Classifier); -
- 9. Логистическая регрессия – один из методов бинарной классификации данных. Алгоритм применения логистической регрессии: 1 Подготовка обучающей
- 10. Численное решение логистической регрессии (1) (2) (3)
- 11. Другой вариант решения В ряде случаев использование численных методов может приводить к ошибкам вычислений, поэтому иногда
- 12. Оптимизационная задача Оптимизационная задача по-прежнему формулируется как задача минимизации функции штрафа:
- 13. Численное решение задачи логистической регрессии с помощью Microsoft Excel Шаг 1 В соответствии с предложенным выше
- 14. Логистическая регрессия в Excel (режим формул)
- 15. Шаг 2-3 2 Выполним численное решение с помощью инструмента «Поиск решения» 3 В результате численного решения
- 16. Визуальное представление классов
- 17. Проблема линейной разделимости Зачастую в реальных задачах бинарной классификации данные не могут быть разделены на два
- 18. Способы решения проблемы Возможны следующие способы решения этой проблемы: - применение нелинейной функции гипотезы; - принципиальная
- 19. Качество классификации Очевидно, что при бинарной классификации возможны четыре сочетания реального класса каждого из объектов выборки
- 20. Последствия ошибок классификации Реальные алгоритмы допускают ошибки классификации двух видов: ошибки I рода; ошибки II рода.
- 21. Методы оценки качества классификации
- 22. Пример Предположим, что в электронный почтовый ящик пришло 10 сообщений, часть из которых является нормальными, а
- 23. Возможные варианты Рассчитаем количество всех четырех сочетаний В соответствии с формулами из слайда 21 Для идеального
- 24. Множественная классификация Задачей множественной классификации является определение принадлежности некоего объекта к одному из нескольких (трех или
- 25. методами множественной классификации Наиболее известными методами множественной классификации являются: - метод «один против всех» (One vs
- 26. Искусственная нейронная сеть (ИНС) – математическая модель нервной системы живого организма. Было обнаружено, что свойства ИНС
- 27. Модель нейронной сети ИНС можно рассматривать как векторную функцию векторного аргумента:
- 28. Структура нейронной сети Нейронная сеть состоит из элементов – нейронов, связанных друг с другом нейроны объединяются
- 29. Модель нейрона В общем случае нейрон имеет несколько входов и один выход Нейрон можно рассматривать как
- 30. Структура нейрона Значения на входе нейрона можно представить в виде вектора а весовые коэффициенты – в
- 31. Вычисление значения Вычисление значения на выходе нейрона осуществляется в два этапа. На первом этапе рассчитывается взвешенная
- 32. Свойства функции Свойства функции нейронной сети определяются: - структурой нейронной сети, то есть характером взаимосвязей между
- 33. Обучение ИНС Как и логистическая регрессия, нейронная сеть приобретает свои свойства в результате так называемого «обучения».
- 34. Взвешенная сумма квадратов отклонений Показателем качества обучения является значение функции штрафа, определяемой взвешенной суммой квадратов отклонений:
- 35. Обучение сети В процессе обучения весовые коэффициенты нейронов ИНС изменяются согласно определенным правилам. Обучение производится шагами
- 36. Алгоритмы обучение сети Обучение сети производится с помощью специальных алгоритмов. В основе большинства алгоритмов лежат градиентные
- 37. Функция штрафа при недообученности Эффект недообученности, как в регрессионном анализе, проявляется в виде недостаточного качества классификации
- 38. Избежания эффекта недообученности Для избежания эффекта недообученности можно использовать следующие способы: 1) увеличение числа нейронов в
- 39. Эффект переобученности Можно выделить три признака переобучения: 1) относительно быстрое убывание функции штрафа в процессе обучения;
- 40. Функция штрафа при переобучении Одним из признаков переобученности является нулевое значение функции штрафа после обучения ИНС
- 41. Избежания эффекта переобученности Переобучение приводит к потере классификатором способности к обобщению. Для избежания эффекта переобученности можно
- 42. Заключение В лекции были рассмотрены вопросы классификации Виды классификации как бинарная и множественная Также рассмотрены алгоритмы
- 44. Скачать презентацию

Определение
Классификация – это процесс определения принадлежности объектов к определенным классам.
классификация
Определение
Классификация – это процесс определения принадлежности объектов к определенным классам.
классификация

Применение задач классификации
Существует много практических задач классификации.
В промышленности при оценке
Применение задач классификации
Существует много практических задач классификации.
В промышленности при оценке
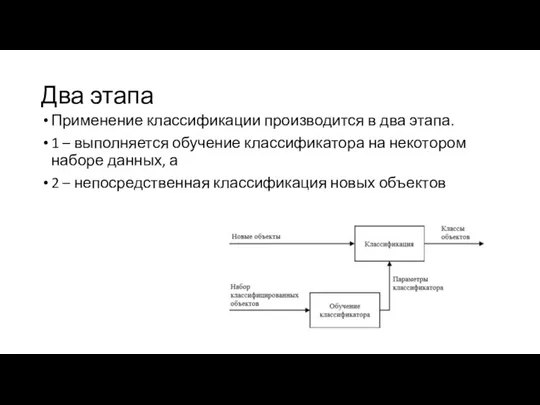
Два этапа
Применение классификации производится в два этапа.
1 – выполняется обучение
Два этапа
Применение классификации производится в два этапа.
1 – выполняется обучение

Виды классификации
Различают бинарную и множественную классификацию.
Бинарная классификация предполагает наличие двух
Виды классификации
Различают бинарную и множественную классификацию.
Бинарная классификация предполагает наличие двух
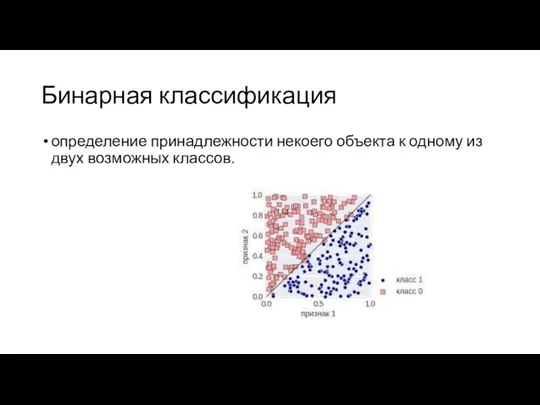
Бинарная классификация
определение принадлежности некоего объекта к одному из двух возможных классов.
Бинарная классификация
определение принадлежности некоего объекта к одному из двух возможных классов.

Примеры бинарной классификации
- является ли сообщение электронной почты «нормальным» или
Примеры бинарной классификации
- является ли сообщение электронной почты «нормальным» или

Методы бинарной классификации
- логистическая регрессия (Logistic Regression);
- «наивный» байесовский
Методы бинарной классификации
- логистическая регрессия (Logistic Regression);
- «наивный» байесовский

Логистическая регрессия
– один из методов бинарной классификации данных.
Алгоритм применения
Логистическая регрессия
– один из методов бинарной классификации данных.
Алгоритм применения

Численное решение логистической регрессии
(1)
(2)
(3)
Численное решение логистической регрессии
(1)
(2)
(3)

Другой вариант решения
В ряде случаев использование численных методов может приводить
Другой вариант решения
В ряде случаев использование численных методов может приводить

Оптимизационная задача
Оптимизационная задача по-прежнему формулируется как задача минимизации функции штрафа:
Оптимизационная задача
Оптимизационная задача по-прежнему формулируется как задача минимизации функции штрафа:
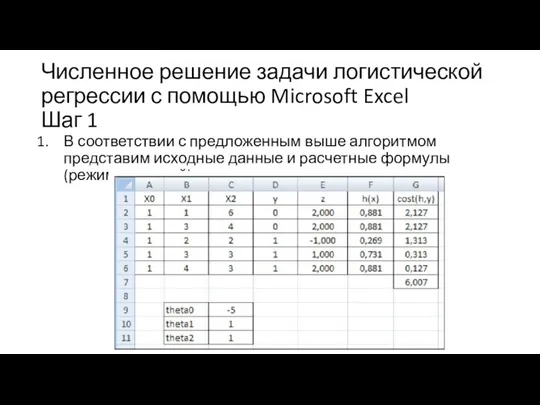
Численное решение задачи логистической регрессии с помощью Microsoft Excel
Шаг 1
В
Численное решение задачи логистической регрессии с помощью Microsoft Excel
Шаг 1
В
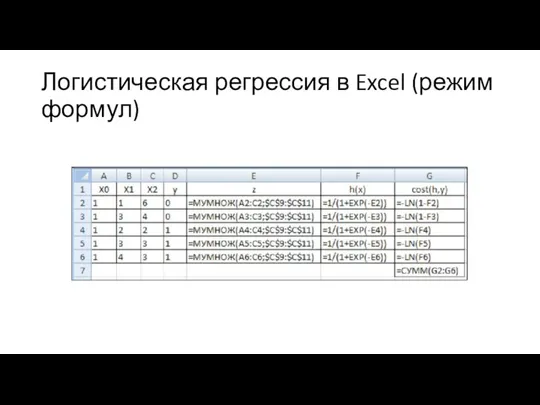
Логистическая регрессия в Excel (режим формул)
Логистическая регрессия в Excel (режим формул)
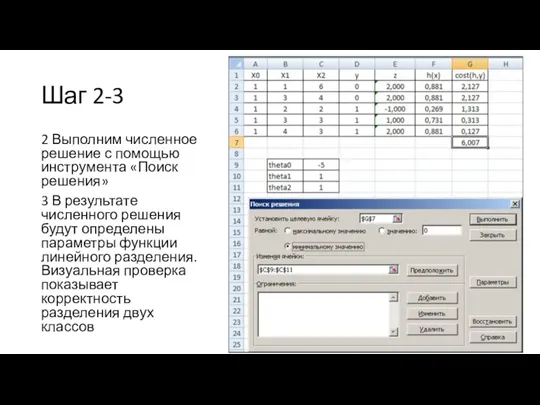
Шаг 2-3
2 Выполним численное решение с помощью инструмента «Поиск решения»
3
Шаг 2-3
2 Выполним численное решение с помощью инструмента «Поиск решения»
3
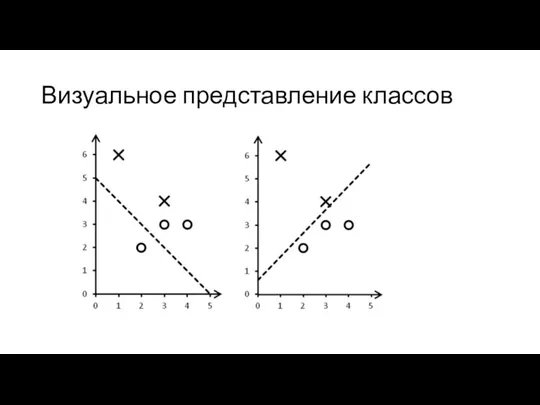
Визуальное представление классов
Визуальное представление классов
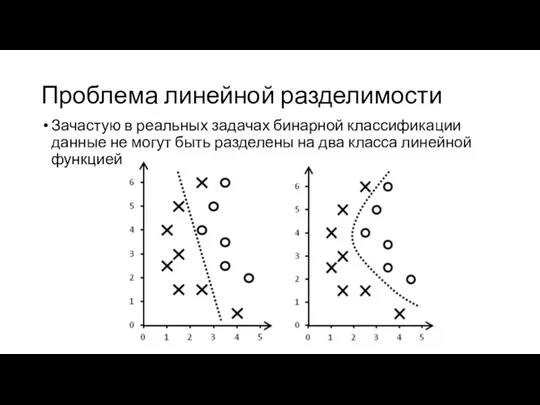
Проблема линейной разделимости
Зачастую в реальных задачах бинарной классификации данные не
Проблема линейной разделимости
Зачастую в реальных задачах бинарной классификации данные не

Способы решения проблемы
Возможны следующие способы решения этой проблемы:
- применение
Способы решения проблемы
Возможны следующие способы решения этой проблемы:
- применение

Качество классификации
Очевидно, что при бинарной классификации возможны четыре сочетания реального
Качество классификации
Очевидно, что при бинарной классификации возможны четыре сочетания реального

Последствия ошибок классификации
Реальные алгоритмы допускают ошибки классификации двух видов:
ошибки
Последствия ошибок классификации
Реальные алгоритмы допускают ошибки классификации двух видов:
ошибки

Методы оценки качества классификации
Методы оценки качества классификации

Пример
Предположим, что в электронный почтовый ящик пришло 10 сообщений, часть из
Пример
Предположим, что в электронный почтовый ящик пришло 10 сообщений, часть из

Возможные варианты
Рассчитаем количество всех четырех сочетаний
В соответствии с формулами из
Возможные варианты
Рассчитаем количество всех четырех сочетаний
В соответствии с формулами из

Множественная классификация
Задачей множественной классификации является определение принадлежности некоего объекта к
Множественная классификация
Задачей множественной классификации является определение принадлежности некоего объекта к

методами множественной классификации
Наиболее известными методами множественной классификации являются:
- метод «один
методами множественной классификации
Наиболее известными методами множественной классификации являются:
- метод «один

Искусственная нейронная сеть (ИНС)
– математическая модель нервной системы живого организма.
Искусственная нейронная сеть (ИНС)
– математическая модель нервной системы живого организма.

Модель нейронной сети
ИНС можно рассматривать как векторную функцию векторного аргумента:
Модель нейронной сети
ИНС можно рассматривать как векторную функцию векторного аргумента:
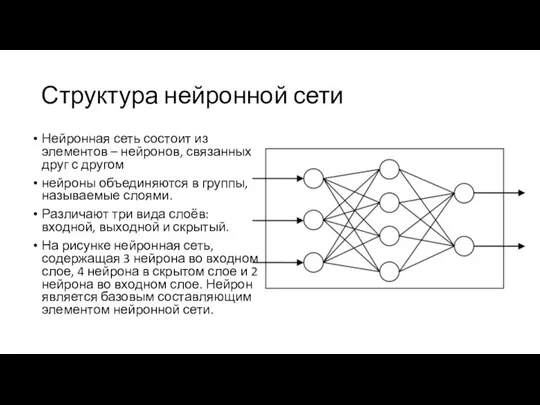
Структура нейронной сети
Нейронная сеть состоит из элементов – нейронов, связанных друг
Структура нейронной сети
Нейронная сеть состоит из элементов – нейронов, связанных друг

Модель нейрона
В общем случае нейрон имеет несколько входов и один
Модель нейрона
В общем случае нейрон имеет несколько входов и один
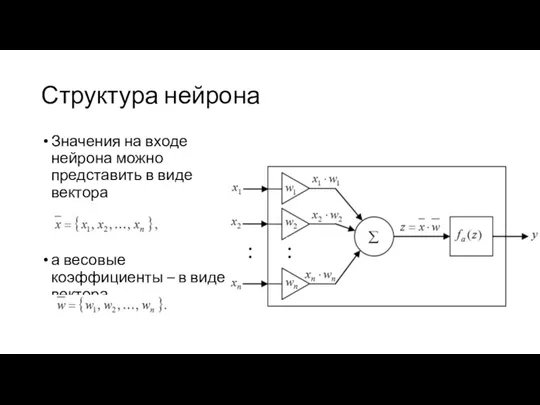
Структура нейрона
Значения на входе нейрона можно представить в виде вектора
а
Структура нейрона
Значения на входе нейрона можно представить в виде вектора
а

Вычисление значения
Вычисление значения на выходе нейрона осуществляется в два этапа. На
Вычисление значения
Вычисление значения на выходе нейрона осуществляется в два этапа. На

Свойства функции
Свойства функции нейронной сети определяются:
- структурой нейронной сети,
Свойства функции
Свойства функции нейронной сети определяются:
- структурой нейронной сети,

Обучение ИНС
Как и логистическая регрессия, нейронная сеть приобретает свои свойства в
Обучение ИНС
Как и логистическая регрессия, нейронная сеть приобретает свои свойства в

Взвешенная сумма квадратов отклонений
Показателем качества обучения является значение функции штрафа, определяемой
Взвешенная сумма квадратов отклонений
Показателем качества обучения является значение функции штрафа, определяемой

Обучение сети
В процессе обучения весовые коэффициенты нейронов ИНС изменяются согласно определенным
Обучение сети
В процессе обучения весовые коэффициенты нейронов ИНС изменяются согласно определенным

Алгоритмы обучение сети
Обучение сети производится с помощью специальных алгоритмов.
В
Алгоритмы обучение сети
Обучение сети производится с помощью специальных алгоритмов.
В
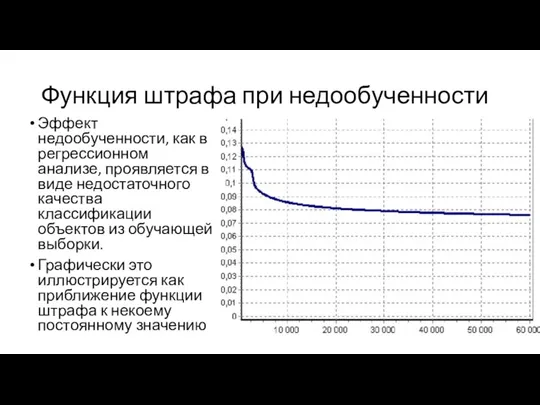
Функция штрафа при недообученности
Эффект недообученности, как в регрессионном анализе, проявляется в
Функция штрафа при недообученности
Эффект недообученности, как в регрессионном анализе, проявляется в

Избежания эффекта недообученности
Для избежания эффекта недообученности можно использовать следующие способы:
1)
Избежания эффекта недообученности
Для избежания эффекта недообученности можно использовать следующие способы:
1)

Эффект переобученности
Можно выделить три признака переобучения:
1) относительно быстрое убывание функции
Эффект переобученности
Можно выделить три признака переобучения:
1) относительно быстрое убывание функции
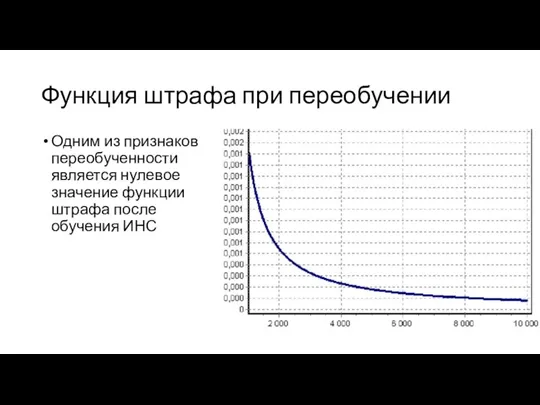
Функция штрафа при переобучении
Одним из признаков переобученности является нулевое значение функции
Функция штрафа при переобучении
Одним из признаков переобученности является нулевое значение функции

Избежания эффекта переобученности
Переобучение приводит к потере классификатором способности к обобщению.
Для
Избежания эффекта переобученности
Переобучение приводит к потере классификатором способности к обобщению.
Для

Заключение
В лекции были рассмотрены вопросы классификации
Виды классификации как бинарная и множественная
Также
Заключение
В лекции были рассмотрены вопросы классификации
Виды классификации как бинарная и множественная
Также
 Wi-Fi роутер ZYXEL Keenetic 4G III
Wi-Fi роутер ZYXEL Keenetic 4G III Работа с файлами. Запись и считывание данных. Лекция 13
Работа с файлами. Запись и считывание данных. Лекция 13 Петербургский научно-практический журнал Дошкольная педагогика
Петербургский научно-практический журнал Дошкольная педагогика Электронная цифровая подпись
Электронная цифровая подпись Working from your Services to Clouds and Cloud Services. Module 4. Exploring Online Scheduling Applications
Working from your Services to Clouds and Cloud Services. Module 4. Exploring Online Scheduling Applications Яндекс.Про. Обучение курьеров
Яндекс.Про. Обучение курьеров Формирование структуры сайта. (Тема 8)
Формирование структуры сайта. (Тема 8) Развитие многоуровневых машин
Развитие многоуровневых машин Прототип. Средства создания прототипа. Технология работы в программе прототипирования
Прототип. Средства создания прототипа. Технология работы в программе прототипирования ЕГЭ информатика, задания А1 и А2
ЕГЭ информатика, задания А1 и А2 Social Networks
Social Networks Презентация Личный сайт. Первые шаги...
Презентация Личный сайт. Первые шаги... Передача информации в древние времена и сегодня
Передача информации в древние времена и сегодня Outside Cloud Storing and Sharing. Module 5. Collaborating via Social Networks and Groupware
Outside Cloud Storing and Sharing. Module 5. Collaborating via Social Networks and Groupware Создание открытки в текстовом редакторе. Работа с графикой.
Создание открытки в текстовом редакторе. Работа с графикой. Среда программирования Scratch. Урок 2
Среда программирования Scratch. Урок 2 Объявление и вызов методов в C#
Объявление и вызов методов в C# Instructions for use. Edit in Google slides edit in PowerPoint®
Instructions for use. Edit in Google slides edit in PowerPoint® Программирование на C#. Часть 2
Программирование на C#. Часть 2 wifi902 Diagnostic Software Installation and Tutorial
wifi902 Diagnostic Software Installation and Tutorial Обучающая презентацияЗвездное небо
Обучающая презентацияЗвездное небо Базы данных Системы управления базами данных
Базы данных Системы управления базами данных Інженерія якості ПЗ
Інженерія якості ПЗ Установка и программирование. Позиционирование систем NEC
Установка и программирование. Позиционирование систем NEC Киберспорт. Курсы администратора киберспортивного клуба
Киберспорт. Курсы администратора киберспортивного клуба Розпізнавання. Загальні алгоритми навчання
Розпізнавання. Загальні алгоритми навчання Типы web-сайтов
Типы web-сайтов Электронные таблицы Ехсel. (Лекция 3)
Электронные таблицы Ехсel. (Лекция 3)