- Кодирование. Оптимальный код Хаффмана. Лекция 14

Содержание
- 2. План лекции Алфавит, кодирование, код Типы кодирования, однозначное декодирование Метод кодирования Хафмана Метод кодирования Фано
- 3. Понятие кода Алфавитом называется конечное множество символов Сообщением алфавита А называется конечная последовательность символов алфавита А
- 4. Понятие кода Кодом называется отображение К : Алф1* —> Алф2*, согласованное с конкатенацией, т.е. удовлетворяющее равенству
- 5. Кодирование и декодирование Кодированием сообщения называется вычисление кода сообщения Декодированием (дешифровкой) сообщения называется вычисление его прообраза
- 6. Пример 1 Алф1 = {a,b,c,d} Алф2 = {0,1} К(а) = 0, К(b) = 01, К(с) =
- 7. Пример 2 Алф1 = {a,b,c,d} Алф2 = {0,1} К(а) = 0, К(b) = 10, К(с) =
- 8. Кодовое дерево Кодовым деревом кода К:Алф1 ->Алф2 называется такое дерево Т, с рёбрами помеченными символами из
- 9. Пример кодового дерева Алф1 = {a,b,c,d} Алф2 = {0,1} К(а) = 0, К(b) = 01, К(с)
- 10. Пример кодового дерева Алф1 = {a,b,c,d} Алф2 = {0,1} К(а) = 0, К(b) = 10, К(с)
- 11. Префиксный код Код К называется префиксным, если для любых двух сообщений U и V код К(U)
- 12. Примеры префиксных кодов Пример 1 Алф1 = {a,b,c,d} Алф2 = {0,1} К(a) = 00, K(b) =
- 13. Примеры префиксных кодов Пример 2 Алф1 = {a,b,c,d} Алф2 = {0,1} К(а) = 0, К(b) =
- 14. Однозначная декодируемость префиксного кода Теорема Любой префиксный код однозначно декодируем Доказательство Пусть К – префиксный код.
- 15. Пример Алф1 = {a,b,c,d} Алф2 = {0,1} К(a) = 0, К(b) = 101, К(c) = 110,
- 16. Пример азбука Морзе 1840 Alfred Vail по заказу телеграфной компании Samuel F.B. Morse Двоичный (точка, тире)
- 17. Понятие оптимального кода Обозначим Δ – множество кодов Алф1* -> Алф2* К – какой-то код из
- 18. Оптимальный двочиный префиксный код Как быстро построить оптимальный двоичный префиксный код для данного сообщения? Сжатие данных
- 19. Свойства оптимального двоичного префиксного кода Пусть R -- сообщение в алфавите Алф1={c1,…,cn} сx входит в R
- 20. Свойства оптимального двоичного префиксного кода Символов с кодом длины L(K*,сn) (с самым длинным кодом) не менее
- 21. Свойства оптимального двоичного префиксного кода Оптимальный двоичный префиксный код к* для сообщения r, полученного из сообщения
- 22. Построение дерева оптимального префиксного двоичного кода Вход Кратности p1, …, pn вхождений симолов с1, ..., сn
- 23. Пример кол около колокола o – 7; к – 4; л – 4; пробел – 2;
- 24. пробел пробел о к л а Дерево после шага 1 Дерево после шага 2 л а
- 25. к пробел 0 0 0 1 1 1 1 Дерево после шага 4 0 о л
- 26. Пример построения кода по кодовому дереву Пометим дуги, исходящие из каждой вершины дерева, единицей и нулем
- 27. Для разобранного примера можно построить другое дерево Закодированное сообщение длины L = 39 010010110000100100011001001000010010111
- 28. Теорема Длина кодового слова в оптимальном префиксном двоичном коде ограничена порядковым номером минимального числа Фибоначчи, превосходящего
- 29. Алфавит, кодирование, код Типы кодирования, однозначное декодирование Метод кодирования Хафмана Метод кодирования Фано
- 30. Метод Фано Роберт Марио Фано р. 1917 Один из первых алгоритмов сжатия на основе префиксного кода
- 31. Метод Фано Упорядочим входной алфавит по возрастанию частот p1 Обозначим Sk = p1+p2+…+pk, S0 = 0
- 32. Метод Фано K[i][j] заполняем 0 и 1 по след. правилу Для каждого максимального интервала строк [a,
- 33. Пример А = {a, b, c, d, e} Частоты pa = 0.11, pb = 0.15, pc
- 34. Свойства кода Фано Кодовое дерево для кода Фано обладает следующим свойством Ребра, исходящие из корня, соответствуют
- 35. Свойства кода Фано Код Фано неоптимальный Пример Частоты p1=0.4, p2=p3=p4=p5=0.15 Фано: 00 01 10 110 111
- 36. Метод Шеннона Клод Шеннон 1916 – 2001, основоположник теории информации Упорядочим входные символы по возрастанию частот
- 37. Пример построения кода Шеннона nk разложение Sk код p(a) = 0.08 Sa = 0.08 4 0.0001
- 38. Свойства кода Шеннона Код Шеннона -- префиксный код Почему? Пусть pk – частота вхождения k-го символа
- 40. Скачать презентацию

План лекции
Алфавит, кодирование, код
Типы кодирования, однозначное декодирование
Метод кодирования Хафмана
Метод кодирования Фано
План лекции
Алфавит, кодирование, код
Типы кодирования, однозначное декодирование
Метод кодирования Хафмана
Метод кодирования Фано

Понятие кода
Алфавитом называется конечное множество символов
Сообщением алфавита А называется конечная
Понятие кода
Алфавитом называется конечное множество символов
Сообщением алфавита А называется конечная

Понятие кода
Кодом называется отображение К : Алф1* —> Алф2*, согласованное
Понятие кода
Кодом называется отображение К : Алф1* —> Алф2*, согласованное

Кодирование и декодирование
Кодированием сообщения называется вычисление кода сообщения
Декодированием (дешифровкой) сообщения называется
Кодирование и декодирование
Кодированием сообщения называется вычисление кода сообщения
Декодированием (дешифровкой) сообщения называется

Пример 1
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) = 01,
Пример 1
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) = 01,

Пример 2
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) = 10,
Пример 2
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) = 10,

Кодовое дерево
Кодовым деревом кода К:Алф1 ->Алф2 называется такое дерево Т, с
Кодовое дерево
Кодовым деревом кода К:Алф1 ->Алф2 называется такое дерево Т, с
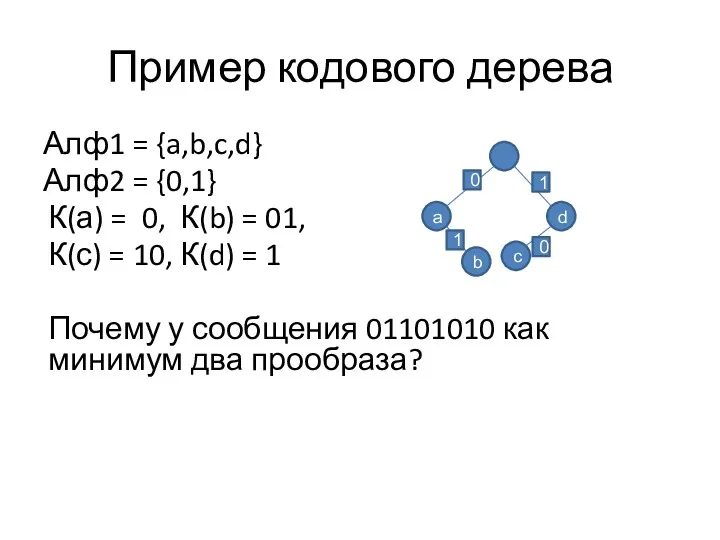
Пример кодового дерева
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) =
Пример кодового дерева
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) =

Пример кодового дерева
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) =
Пример кодового дерева
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b) =

Префиксный код
Код К называется префиксным, если для любых двух сообщений U
Префиксный код
Код К называется префиксным, если для любых двух сообщений U

Примеры префиксных кодов
Пример 1
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(a) = 00, K(b)
Примеры префиксных кодов
Пример 1
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(a) = 00, K(b)

Примеры префиксных кодов
Пример 2
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b)
Примеры префиксных кодов
Пример 2
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(а) = 0, К(b)

Однозначная декодируемость префиксного кода
Теорема Любой префиксный код однозначно декодируем
Доказательство
Пусть К –
Однозначная декодируемость префиксного кода
Теорема Любой префиксный код однозначно декодируем
Доказательство
Пусть К –

Пример
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(a) = 0, К(b) = 101, К(c)
Пример
Алф1 = {a,b,c,d}
Алф2 = {0,1}
К(a) = 0, К(b) = 101, К(c)
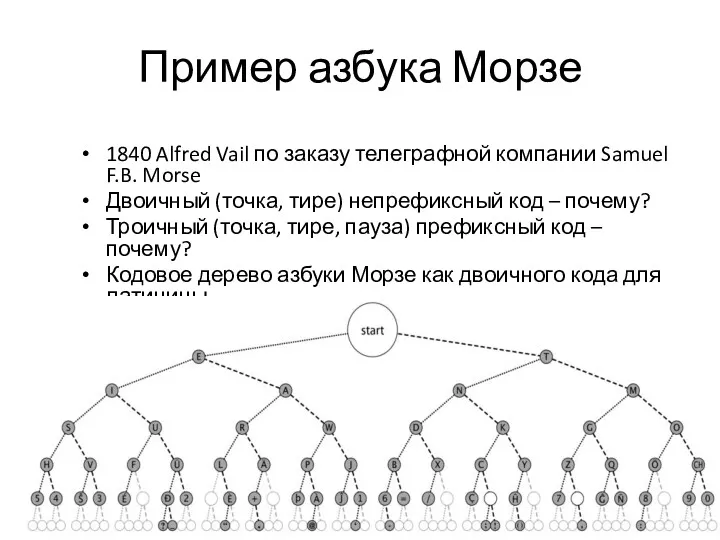
Пример азбука Морзе
1840 Alfred Vail по заказу телеграфной компании Samuel F.B.
Пример азбука Морзе
1840 Alfred Vail по заказу телеграфной компании Samuel F.B.

Понятие оптимального кода
Обозначим
Δ – множество кодов Алф1* -> Алф2*
К – какой-то
Понятие оптимального кода
Обозначим
Δ – множество кодов Алф1* -> Алф2*
К – какой-то

Оптимальный двочиный префиксный код
Как быстро построить оптимальный
двоичный префиксный код для
данного сообщения?
Сжатие
Оптимальный двочиный префиксный код
Как быстро построить оптимальный
двоичный префиксный код для
данного сообщения?
Сжатие

Свойства оптимального двоичного префиксного кода
Пусть R -- сообщение в алфавите Алф1={c1,…,cn}
сx
Свойства оптимального двоичного префиксного кода
Пусть R -- сообщение в алфавите Алф1={c1,…,cn}
сx

Свойства оптимального двоичного префиксного кода
Символов с кодом длины L(K*,сn) (с самым
Свойства оптимального двоичного префиксного кода
Символов с кодом длины L(K*,сn) (с самым

Свойства оптимального двоичного префиксного кода
Оптимальный двоичный префиксный код к* для сообщения
Свойства оптимального двоичного префиксного кода
Оптимальный двоичный префиксный код к* для сообщения

Построение дерева оптимального префиксного двоичного кода
Вход
Кратности p1, …, pn вхождений симолов
Построение дерева оптимального префиксного двоичного кода
Вход
Кратности p1, …, pn вхождений симолов

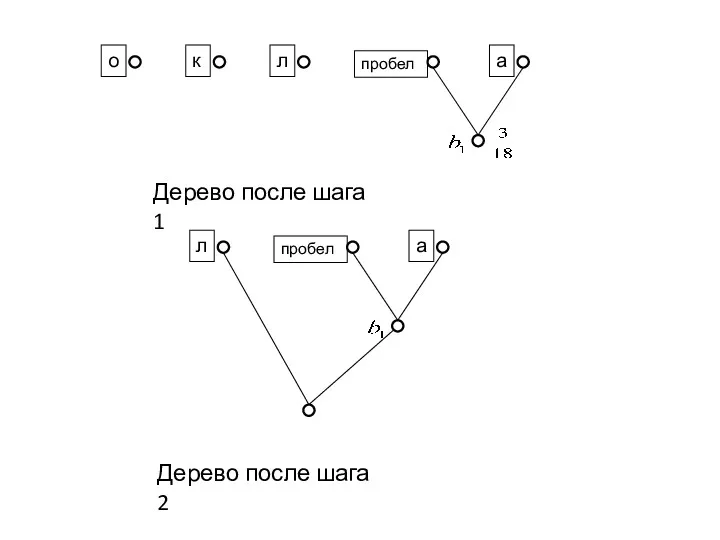
Пример
кол около колокола
o – 7; к – 4; л –
Пример
кол около колокола
o – 7; к – 4; л –
пробел
пробел
о
к
л
а
Дерево после шага 1
Дерево после шага 2
л
а
пробел
пробел
о
к
л
а
Дерево после шага 1
Дерево после шага 2
л
а
к
пробел
0
0
0
1
1
1
1
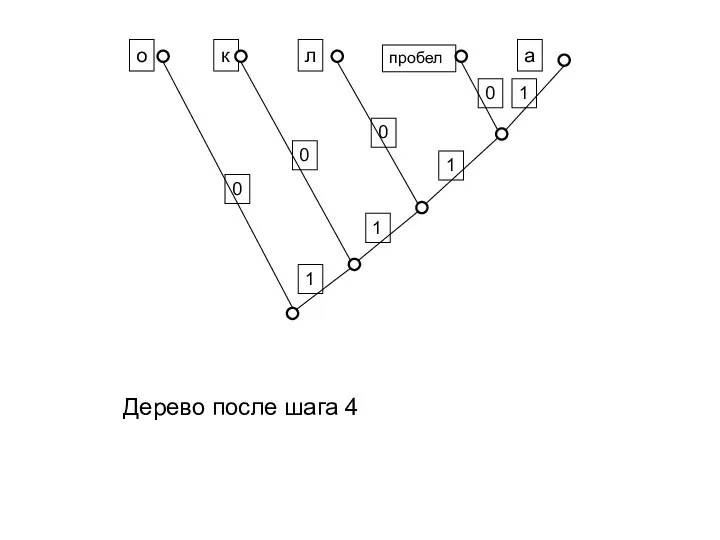
Дерево после шага 4
0
о
л
а
к
пробел
0
0
0
1
1
1
1
Дерево после шага 4
0
о
л
а

Пример построения кода по кодовому дереву
Пометим дуги, исходящие из каждой вершины
Пример построения кода по кодовому дереву
Пометим дуги, исходящие из каждой вершины
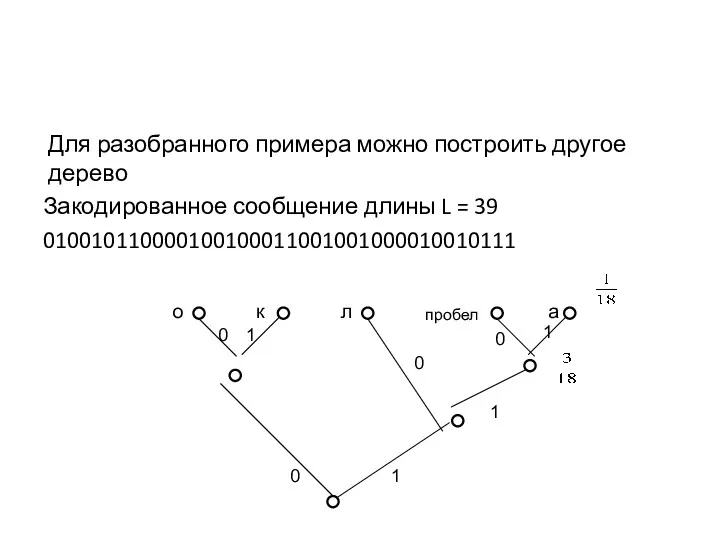
Для разобранного примера можно построить другое дерево
Закодированное сообщение длины L =
Для разобранного примера можно построить другое дерево
Закодированное сообщение длины L =

Теорема
Длина кодового слова в оптимальном префиксном двоичном коде ограничена порядковым номером
Теорема
Длина кодового слова в оптимальном префиксном двоичном коде ограничена порядковым номером

Алфавит, кодирование, код
Типы кодирования, однозначное декодирование
Метод кодирования Хафмана
Метод кодирования Фано
Алфавит, кодирование, код
Типы кодирования, однозначное декодирование
Метод кодирования Хафмана
Метод кодирования Фано

Метод Фано
Роберт Марио Фано р. 1917
Один из первых алгоритмов сжатия на
Метод Фано
Роберт Марио Фано р. 1917
Один из первых алгоритмов сжатия на

Метод Фано
Упорядочим входной алфавит по возрастанию частот p1 <= p2 <=
Метод Фано
Упорядочим входной алфавит по возрастанию частот p1 <= p2 <=
![Метод Фано K[i][j] заполняем 0 и 1 по след. правилу](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/295732/slide-31.jpg)
Метод Фано
K[i][j] заполняем 0 и 1 по след. правилу
Для каждого максимального
Метод Фано
K[i][j] заполняем 0 и 1 по след. правилу
Для каждого максимального
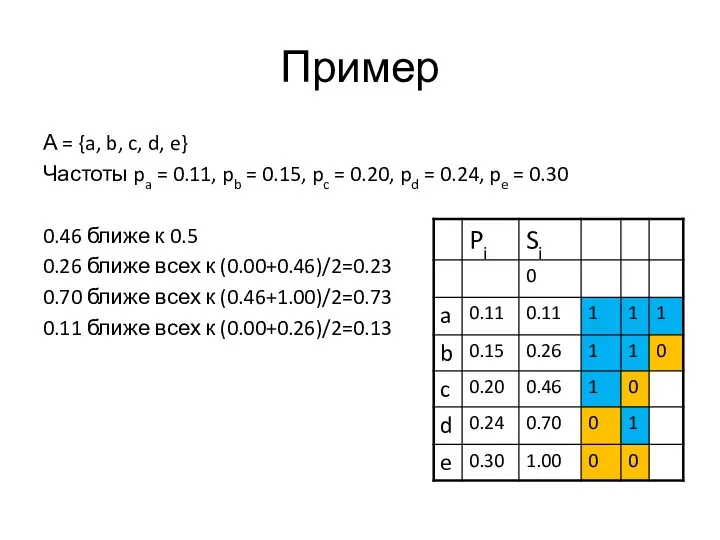
Пример
А = {a, b, c, d, e}
Частоты pa = 0.11, pb
Пример
А = {a, b, c, d, e}
Частоты pa = 0.11, pb

Свойства кода Фано
Кодовое дерево для кода Фано обладает следующим свойством
Ребра, исходящие
Свойства кода Фано
Кодовое дерево для кода Фано обладает следующим свойством
Ребра, исходящие

Свойства кода Фано
Код Фано неоптимальный
Пример
Частоты p1=0.4, p2=p3=p4=p5=0.15
Фано: 00 01 10 110
Свойства кода Фано
Код Фано неоптимальный
Пример
Частоты p1=0.4, p2=p3=p4=p5=0.15
Фано: 00 01 10 110

Метод Шеннона
Клод Шеннон 1916 – 2001, основоположник теории информации
Упорядочим входные символы
Метод Шеннона
Клод Шеннон 1916 – 2001, основоположник теории информации
Упорядочим входные символы

Пример построения кода Шеннона
nk разложение Sk код
p(a) = 0.08 Sa = 0.08 4 0.0001
Пример построения кода Шеннона
nk разложение Sk код
p(a) = 0.08 Sa = 0.08 4 0.0001

Свойства кода Шеннона
Код Шеннона -- префиксный код
Почему?
Пусть pk – частота вхождения
Свойства кода Шеннона
Код Шеннона -- префиксный код
Почему?
Пусть pk – частота вхождения
 Салыстыру және логикалық операторларды қолдану
Салыстыру және логикалық операторларды қолдану Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 2
Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 2 Анализ и мониторинг интернет-СМИ. Базы СМИ. Медиаисследования в интернете
Анализ и мониторинг интернет-СМИ. Базы СМИ. Медиаисследования в интернете CSS. Лекция 10
CSS. Лекция 10 Компьютерные словари и системы машинного перевода текстов
Компьютерные словари и системы машинного перевода текстов Інформаційні системи. Інтелектуальна власність та авторське право
Інформаційні системи. Інтелектуальна власність та авторське право Синхронизация в OpenMP
Синхронизация в OpenMP Counter-Strike: Global Offensive. Разработка компьютерных игр
Counter-Strike: Global Offensive. Разработка компьютерных игр Прийоми забезпечення технологічності програмних продуктів. Низхідне та висхідне програмування. Метод покрокової деталізації
Прийоми забезпечення технологічності програмних продуктів. Низхідне та висхідне програмування. Метод покрокової деталізації Z-передаточная функция и весовая последовательность цифрового блока. (Лекция 6)
Z-передаточная функция и весовая последовательность цифрового блока. (Лекция 6) Масиви. Введення даних у масив
Масиви. Введення даних у масив Қатты диск құрылысы. Жинақтауыштың негізгі түйіндері
Қатты диск құрылысы. Жинақтауыштың негізгі түйіндері Разработка модуля CMS Drupal для создания тестов и оценки знаний пользователей
Разработка модуля CMS Drupal для создания тестов и оценки знаний пользователей Засоби UML для моделювання в програмній інженерії
Засоби UML для моделювання в програмній інженерії Грошові перекази та інтернет- магазини
Грошові перекази та інтернет- магазини Интернет Вещей. Умный дом как пример технологии
Интернет Вещей. Умный дом как пример технологии Розвиток інформатики в Україні
Розвиток інформатики в Україні Сетевая журналистика
Сетевая журналистика Текстовый редактор Microsoft office Word
Текстовый редактор Microsoft office Word Welcome To Epson Printer Customer Care Center
Welcome To Epson Printer Customer Care Center Памятка для школьника. Как создать виртуальную экскурсию в программе Microsoft Office PowerPoint
Памятка для школьника. Как создать виртуальную экскурсию в программе Microsoft Office PowerPoint SAP HANA – платформа для бизнеса в реальном времени
SAP HANA – платформа для бизнеса в реальном времени Моделирование памяти. Информационные объекты MATRIX. Организация циклов
Моделирование памяти. Информационные объекты MATRIX. Организация циклов Вычисления в таблицах Excel
Вычисления в таблицах Excel Прототип АИС Путевка. Регистрация
Прототип АИС Путевка. Регистрация Алгоритм построения орграфа Хаффмана (алгоритм сжатия)
Алгоритм построения орграфа Хаффмана (алгоритм сжатия) Поиск и сортировка информации в базах данных. ЕГЭ
Поиск и сортировка информации в базах данных. ЕГЭ Браузеры и поисковые системы
Браузеры и поисковые системы