- Лабораторная работа № 2. Анализ главных компонент

Содержание
- 2. Основные приложения Dimensionality reduction Снижение размерности данных при сохранении всей или большей части информации Feature extraction
- 3. Анализ заемщиков банка Задача : Проанализировать заемщиков банка на основе различных данных
- 4. Личные данные Семейное положение Образование Финансовое состояние Имущество Кредитная история … Данные могут быть:
- 5. Пример: Give Me Some Credit* * https://www.kaggle.com/c/GiveMeSomeCredit
- 6. Пример: Give Me Some Credit* * https://www.kaggle.com/c/GiveMeSomeCredit
- 7. Задача снижения размерности Представить набор данных меньшим числом признаков таким образом, чтобы потеря информации, содержащейся в
- 8. Principal Component Analysis Данные заданы матрицей размерности n×m, где и , n – число наблюдений (объектов),
- 9. Principal Component Analysis Обозначим за C (m×m) матрицу ковариаций признаков матрицы X: В матричном виде:
- 10. Principal Component Analysis Вариация i-го признака: Общая вариация данных: Задача: найти ортогональные векторы такие, что т.е.
- 11. Матрица C симметричная и положительно определена. Имеет место равенство: Principal Component Analysis
- 12. Principal Component Analysis Главные компоненты: Доля объясненной вариации:
- 13. Решение в R Подготовка R-сессии # Изменение опций по умолчанию options(digits = 10, "scipen" = 10)
- 14. Решение в R Для выполнения PCA воспользуемся функцией princomp из пакета stats (встроен в базовый дистрибутив
- 15. Доля объясненной вариации # Доля объясненной вариации e_var sapply(1:(length(Y_pca$sdev^2)), function(x, y) {sum(y[1:x])/sum(y)}, y = Y_pca$sdev^2)) ggplot(mapping
- 16. Интерпретация главных факторов # Число главных компонент k # Матрица нагрузок L t(diag(Y_pca$sdev[1:k])) %>% as.data.frame rownames(L)
- 17. Интерпретация главных факторов Исходя из структуры матрицы корреляций, можно предложить следующую интерпретацию: U1: История просроченных выплат
- 18. Решение в pyDAAL ## Размерность данных ## 201669 10 ## Вклад каждой компоненты в объяснение вариации
- 19. Singular value decomposition Данные заданы матрицей размерности n×m, где и , n – число наблюдений (объектов),
- 20. Singular value decomposition Решение зависит от матричной нормы Наиболее подходящие: Евклидова норма и норма Фробениуса Евклидова
- 21. Singular value decomposition Существуют такие матрицы U и V, что выполняется равенство где U – матрица
- 22. Singular value decomposition Запишем матрицы U и V в векторном виде: Тогда SVD разложение можно представить
- 23. Singular value decomposition Теорема Шмидта-Мирского: Решением матричной задачи наилучшей аппроксимации в норме Евклида и в норме
- 24. Выбор числа k главных факторов Общая вариация данных: Доля объясненной вариации: Хорошим значением считается доля объясненной
- 25. Для выполнения SVD разложения воспользуемся функцией svd() из пакета stats (встроен в базовый дистрибутив R) Функция
- 26. Доля объясненной вариации e_var sapply(1:(length(Y_svd$d^2)), function(x, y) {sum(y[1:x])/sum(y)}, y = Y_svd$d^2)) ggplot(mapping = aes(x = 0:(length(e_var)-1),
- 27. Ошибки аппроксимации ## Ошибка аппроксимации в норме Евклида err2 ggplot(mapping = aes(x = 1:length(err2), y =
- 28. Интерпретация главных факторов # Матрица нагрузок L # Переход к матрице корреляций L % as.data.frame rownames(L)
- 29. Решение в scikit-learn %matplotlib inline import numpy as np import scipy as sp from sklearn.decomposition import
- 30. Решение в scikit-learn # Выполняем метод главных компонент pca = PCA(svd_solver='full') pca.fit(data) # Вклад каждого фактора
- 31. Решение в pyDAAL ## Размерность данных ## 201669 10 ## Вклад каждого фактора в объяснение вариации
- 32. Latent Semantic Analysis Document-term matrix X: строки – документы, столбцы – слова (после предобработки, нормализации, удаления
- 33. Latent Semantic Analysis Задача: представить документы в пространстве k признаков, где k много меньше размера словаря,
- 34. Latent Semantic Analysis Применяя SVD к document-term матрице, мы одновременной находим представление в k-мерном пространстве как
- 35. Пример: 20 Newsgroups Набор новостных статей «20 Newsgroups» 18000 новостных статей из 20 различных рубрик. URL:
- 36. Решение в scikit-learn # Загрузка данных from sklearn.datasets import fetch_20newsgroups_vectorized newsgroups = fetch_20newsgroups_vectorized(subset='train', remove = ('headers',
- 37. Решение в pyDAAL # Транспонируем матрицу данных и переводим из sparse в dense nwsd = newsgroups.data
- 38. Пример: 20 Newsgroups k = 3000 главных факторов дает долю объясненной вариации ~ 90% k =
- 39. Скорость вычислений Скорость выполнения метода главных компонент в R, Scikit-learn и pyDAAL для набора данных Give
- 40. Задания Воспроизведите вычисления, представленные в лекционных материалах. Подтвердите выводы. Рассмотрите набор данных Turkiye Student Evaluation: Опишите
- 42. Скачать презентацию

Основные приложения
Dimensionality reduction
Снижение размерности данных при сохранении всей или большей части
Основные приложения
Dimensionality reduction Снижение размерности данных при сохранении всей или большей части

Анализ заемщиков банка
Задача : Проанализировать заемщиков банка на основе различных данных
Анализ заемщиков банка
Задача : Проанализировать заемщиков банка на основе различных данных

Личные данные
Семейное положение
Образование
Финансовое состояние
Имущество
Кредитная история
…
Данные могут быть:
Личные данные
Семейное положение
Образование
Финансовое состояние
Имущество
Кредитная история
…
Данные могут быть:

Пример: Give Me Some Credit*
* https://www.kaggle.com/c/GiveMeSomeCredit
Пример: Give Me Some Credit*
* https://www.kaggle.com/c/GiveMeSomeCredit
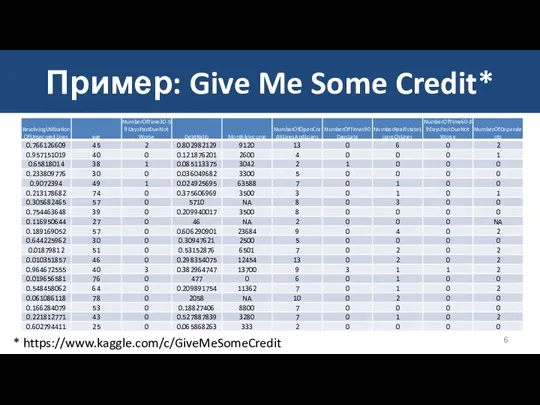
Пример: Give Me Some Credit*
* https://www.kaggle.com/c/GiveMeSomeCredit
Пример: Give Me Some Credit*
* https://www.kaggle.com/c/GiveMeSomeCredit

Задача снижения размерности
Представить набор данных меньшим числом признаков таким образом, чтобы
Задача снижения размерности
Представить набор данных меньшим числом признаков таким образом, чтобы

Principal Component Analysis
Данные заданы матрицей размерности n×m,
где и , n
Principal Component Analysis
Данные заданы матрицей размерности n×m, где и , n

Principal Component Analysis
Обозначим за C (m×m) матрицу ковариаций признаков матрицы X:
В
Principal Component Analysis
Обозначим за C (m×m) матрицу ковариаций признаков матрицы X:
В

Principal Component Analysis
Вариация i-го признака:
Общая вариация данных:
Задача:
Principal Component Analysis
Вариация i-го признака:
Общая вариация данных:
Задача:

Матрица C симметричная и положительно определена. Имеет место равенство:
Principal Component Analysis
Матрица C симметричная и положительно определена. Имеет место равенство:
Principal Component Analysis

Principal Component Analysis
Главные компоненты:
Доля объясненной вариации:
Principal Component Analysis
Главные компоненты:
Доля объясненной вариации:

Решение в R
Подготовка R-сессии
# Изменение опций по умолчанию
options(digits = 10, "scipen"
Решение в R
Подготовка R-сессии
# Изменение опций по умолчанию
options(digits = 10, "scipen"

Решение в R
Для выполнения PCA воспользуемся функцией princomp из пакета stats
Решение в R
Для выполнения PCA воспользуемся функцией princomp из пакета stats
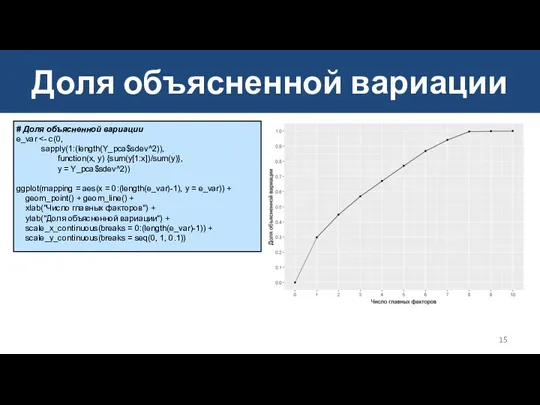
Доля объясненной вариации
# Доля объясненной вариации
e_var <- c(0,
sapply(1:(length(Y_pca$sdev^2)),
Доля объясненной вариации
# Доля объясненной вариации
e_var <- c(0,
sapply(1:(length(Y_pca$sdev^2)),
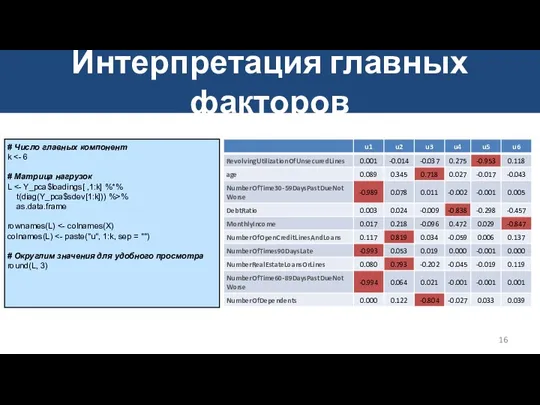
Интерпретация главных факторов
# Число главных компонент
k <- 6
# Матрица нагрузок
L <-
Интерпретация главных факторов
# Число главных компонент
k <- 6
# Матрица нагрузок
L <-

Интерпретация главных факторов
Исходя из структуры матрицы корреляций, можно предложить следующую интерпретацию:
U1:
Интерпретация главных факторов
Исходя из структуры матрицы корреляций, можно предложить следующую интерпретацию:
U1:

Решение в pyDAAL
## Размерность данных
## 201669 10
## Вклад каждой
Решение в pyDAAL
## Размерность данных
## 201669 10
## Вклад каждой

Singular value decomposition
Данные заданы матрицей размерности n×m,
где и , n
Singular value decomposition
Данные заданы матрицей размерности n×m, где и , n

Singular value decomposition
Решение зависит от матричной нормы
Наиболее подходящие: Евклидова норма и
Singular value decomposition
Решение зависит от матричной нормы
Наиболее подходящие: Евклидова норма и

Singular value decomposition
Существуют такие матрицы U и V, что выполняется равенство
где
Singular value decomposition
Существуют такие матрицы U и V, что выполняется равенство
где

Singular value decomposition
Запишем матрицы U и V в векторном виде:
Тогда SVD
Singular value decomposition
Запишем матрицы U и V в векторном виде:
Тогда SVD

Singular value decomposition
Теорема Шмидта-Мирского:
Решением матричной задачи наилучшей аппроксимации в норме
Singular value decomposition
Теорема Шмидта-Мирского:
Решением матричной задачи наилучшей аппроксимации в норме

Выбор числа k главных факторов
Общая вариация данных:
Доля объясненной вариации:
Хорошим значением считается
Выбор числа k главных факторов
Общая вариация данных:
Доля объясненной вариации:
Хорошим значением считается

Для выполнения SVD разложения воспользуемся функцией svd() из пакета stats (встроен
Для выполнения SVD разложения воспользуемся функцией svd() из пакета stats (встроен
![Доля объясненной вариации e_var sapply(1:(length(Y_svd$d^2)), function(x, y) {sum(y[1:x])/sum(y)}, y =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/329171/slide-25.jpg)
Доля объясненной вариации
e_var <- c(0,
sapply(1:(length(Y_svd$d^2)),
function(x, y) {sum(y[1:x])/sum(y)},
Доля объясненной вариации
e_var <- c(0,
sapply(1:(length(Y_svd$d^2)),
function(x, y) {sum(y[1:x])/sum(y)},
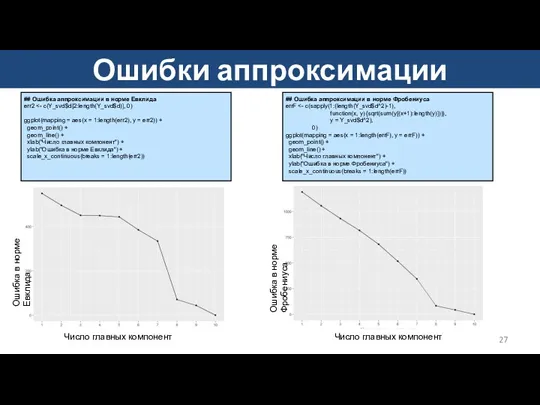
Ошибки аппроксимации
## Ошибка аппроксимации в норме Евклида
err2 <- c(Y_svd$d[2:length(Y_svd$d)], 0)
ggplot(mapping =
Ошибки аппроксимации
## Ошибка аппроксимации в норме Евклида
err2 <- c(Y_svd$d[2:length(Y_svd$d)], 0)
ggplot(mapping =
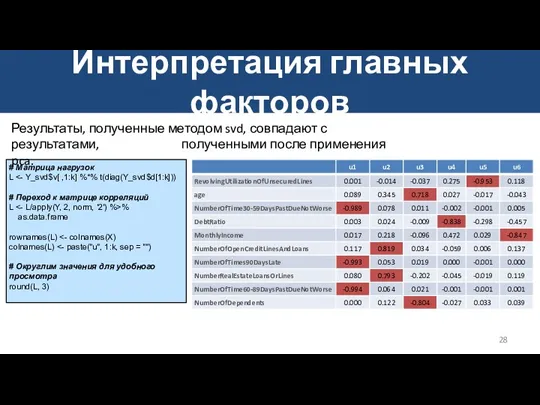
Интерпретация главных факторов
# Матрица нагрузок
L <- Y_svd$v[ ,1:k] %*% t(diag(Y_svd$d[1:k]))
#
Интерпретация главных факторов
# Матрица нагрузок
L <- Y_svd$v[ ,1:k] %*% t(diag(Y_svd$d[1:k]))
#

Решение в scikit-learn
%matplotlib inline
import numpy as np
import scipy as sp
from sklearn.decomposition
Решение в scikit-learn
%matplotlib inline
import numpy as np
import scipy as sp
from sklearn.decomposition

Решение в scikit-learn
# Выполняем метод главных компонент
pca = PCA(svd_solver='full')
pca.fit(data)
Решение в scikit-learn
# Выполняем метод главных компонент
pca = PCA(svd_solver='full')
pca.fit(data)

Решение в pyDAAL
## Размерность данных
## 201669 10
## Вклад каждого
Решение в pyDAAL
## Размерность данных
## 201669 10
## Вклад каждого

Latent Semantic Analysis
Document-term matrix X: строки – документы, столбцы – слова
Latent Semantic Analysis
Document-term matrix X: строки – документы, столбцы – слова

Latent Semantic Analysis
Задача: представить документы в пространстве k признаков, где k
Latent Semantic Analysis
Задача: представить документы в пространстве k признаков, где k
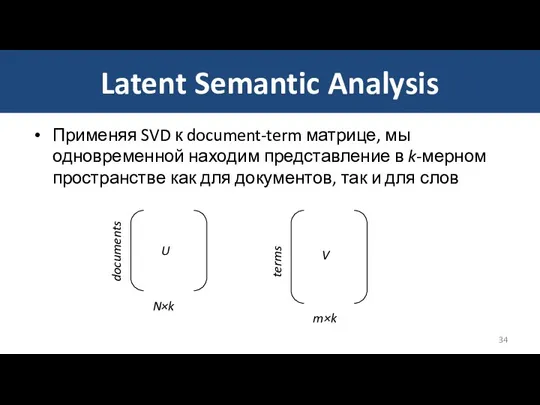
Latent Semantic Analysis
Применяя SVD к document-term матрице, мы одновременной находим представление
Latent Semantic Analysis
Применяя SVD к document-term матрице, мы одновременной находим представление

Пример: 20 Newsgroups
Набор новостных статей «20 Newsgroups»
18000 новостных статей из
Пример: 20 Newsgroups
Набор новостных статей «20 Newsgroups»
18000 новостных статей из
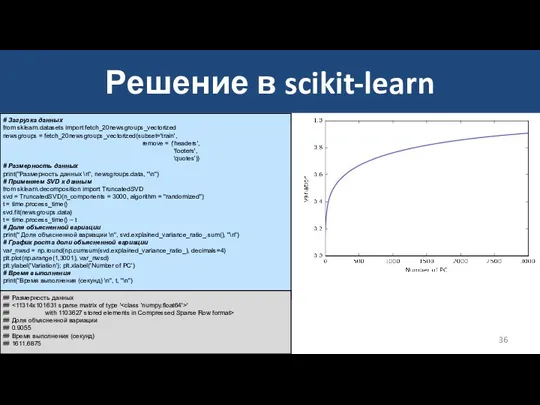
Решение в scikit-learn
# Загрузка данных
from sklearn.datasets import fetch_20newsgroups_vectorized
newsgroups = fetch_20newsgroups_vectorized(subset='train',
Решение в scikit-learn
# Загрузка данных
from sklearn.datasets import fetch_20newsgroups_vectorized
newsgroups = fetch_20newsgroups_vectorized(subset='train',
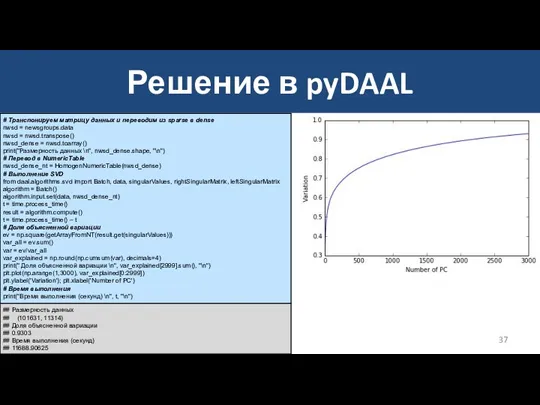
Решение в pyDAAL
# Транспонируем матрицу данных и переводим из sparse в
Решение в pyDAAL
# Транспонируем матрицу данных и переводим из sparse в

Пример: 20 Newsgroups
k = 3000 главных факторов дает долю объясненной
Пример: 20 Newsgroups
k = 3000 главных факторов дает долю объясненной

Скорость вычислений
Скорость выполнения метода главных компонент в R, Scikit-learn и pyDAAL
Скорость вычислений
Скорость выполнения метода главных компонент в R, Scikit-learn и pyDAAL

Задания
Воспроизведите вычисления, представленные в лекционных материалах. Подтвердите выводы.
Рассмотрите набор данных
Задания
Воспроизведите вычисления, представленные в лекционных материалах. Подтвердите выводы.
Рассмотрите набор данных
 2 февраля 2010 года. Городской конкурс Учитель года. 7 класс. Электронные таблицы. Формулы.
2 февраля 2010 года. Городской конкурс Учитель года. 7 класс. Электронные таблицы. Формулы. Технологии построения web-интерфейсов
Технологии построения web-интерфейсов Библиографическое описание
Библиографическое описание Компьютер и здоровье школьников
Компьютер и здоровье школьников Instagram
Instagram Особливості комп’ютерних програм, як об’єкта авторського права
Особливості комп’ютерних програм, як об’єкта авторського права Модель и моделирование
Модель и моделирование Types and Components of Computer Systems
Types and Components of Computer Systems TopLabs. Introduction to responsive design
TopLabs. Introduction to responsive design Процедуры обработки пиксельной (точечной) графики
Процедуры обработки пиксельной (точечной) графики Systemy informacyjne w zarządzaniu
Systemy informacyjne w zarządzaniu Учителя, родители и дети в цифровом пространстве
Учителя, родители и дети в цифровом пространстве Основы реляционной алгебры
Основы реляционной алгебры Верстальщик сайтов
Верстальщик сайтов Безопасный интернет
Безопасный интернет Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС
Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС Новогодняя открытка
Новогодняя открытка Оценка официальных пабликов Хабаровского края. Экспертное интервью
Оценка официальных пабликов Хабаровского края. Экспертное интервью Дидактические свойства и функции Microsoft Office
Дидактические свойства и функции Microsoft Office Влияние сети Интернет на состояние психологичского здоровья студенческой молодежи
Влияние сети Интернет на состояние психологичского здоровья студенческой молодежи Информация и информационные процессы
Информация и информационные процессы Виды баз данных БД
Виды баз данных БД Кодовые таблицы
Кодовые таблицы Комбинаторика и программирование
Комбинаторика и программирование Источники географической информации
Источники географической информации LDI Plus Presentation EN
LDI Plus Presentation EN Алгоритмы. Свойства алгоритма
Алгоритмы. Свойства алгоритма Сервисы Интернет. Компьютерные телекоммуникации
Сервисы Интернет. Компьютерные телекоммуникации