- Линейные блоковые коды

Содержание
- 2. 7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 7.1. Базовые определения 7.1.1. Конечные поля 7.1.2. Векторное пространство 7.2. Основные свойства
- 3. 7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ Все канальные коды могут быть разделены на два класса: блоковые коды (block codes)
- 4. 7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ Свёрточные коды определяются с помощью конечных автоматов (finite-state machines). Для этих кодов в
- 5. 7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ Кодовая скорость (code rate) как блочного, так и свёрточного кодов определяется отношением Предположим,
- 6. 7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ Следовательно: Пусть средняя энергия сигнального созвездия Eav, тогда энергия кодового слова и энергия
- 7. 7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 7.1. Базовые определения 7.2. Основные свойства линейных блоковых кодов 7.2.1. Порождающая и
- 8. 7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ Блоковый код называется q-ичным, если символы (элементы) его кодовых
- 9. 7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ Помимо кодовой скорости важным параметром для кодового слова является его
- 10. 7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ Для ЛБК (n, k) алгоритм формирования n-битового кодового слова cm на
- 11. 7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ Если порождающая матрица имеет форму где Ik – единичная матрица k
- 12. 7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ Учитывая, что ЛБК (n, k) является k-мерным подпространством n-мерного пространства,
- 13. 7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ Учитывая ортогональность строк G и H, имеем Для систематических БЛК G
- 14. 7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ Вес кодового слова c2 – число ненулевых элементов –
- 15. 7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ Минимальным расстоянием (minimum distance) кода является минимальное расстояние между всеми возможными
- 16. 7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ Для некоторых типов модуляции возможно установить простое соотношение между Хемминговым и
- 17. 7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ Полином распределения весов (функция-счётчик кодовых слов с заданным весом) (weight distribution polynomial,
- 18. 7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ Ещё один вариант полинома указывает количество кодовых слов с весом i, соответствующих
- 19. 7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ Вероятность блоковой ошибки (Block Error Probability) Для ЛБК набор расстояний от
- 20. 7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ Вероятность битовой ошибки (Bit Error Probability) Среднее число ожидаемых битовых ошибок:
- 21. 7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 7.1. Базовые определения 7.2. Основные свойства линейных блоковых кодов 7.3. Примеры характерных
- 22. 7.3.1. КОДЫ С ПОВТОРЕНИЕМ Двоичный код с повторениями (repetition code) (n, 1) состоит из двух возможных
- 23. 7.3.2. КОДЫ ХЕММИНГА Коды Хемминга (Hamming codes) – одни из первых предложенных кодов, являются линейными кодами
- 24. 7.3.3. КОДЫ МАКСИМАЛЬНОЙ ДЛИНЫ Коды максимальной длины (maximum-length codes) являются дуальными к кодам Хемминга, т.е. это
- 25. 7.3.4. КОДЫ РИДА-МАЛЛЕРА Коды Рида-Маллера (Reed-Muller codes) известны благодаря существованию простого алгоритма их декодирования. Для длины
- 26. 7.3.5. КОДЫ АДАМАРА Кодовые слова кода Адамара (Hadamard code) – это строки матрицы Адамара. Свойством строк
- 27. 7.3.6. КОДЫ ГОЛЕЯ (Совершенный) код Голея (the Golay code) – двоичный линейный код (23, 12) с
- 28. 7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 7.1. Базовые определения 7.2. Основные свойства линейных блоковых кодов 7.3. Примеры характерных
- 29. 7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ Большинство хорошо изученных кодов эффективно работают в условиях каналов
- 30. 7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ Перед подачей на модулятор можно перемешивать модуляционные символы так,
- 31. 7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ Блочные перемежители записывают поступающие биты по строкам в таблицу
- 32. 7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ 7.1. Базовые определения 7.2. Основные свойства линейных блоковых кодов 7.3. Примеры характерных
- 33. 7.13. КОМБИНИРОВАНИЕ КОДОВ Эффективность блокового кода определяется его исправляющей способностью, т.е. количеством ошибок, которые он может
- 34. 7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES) Пусть имеются два систематических линейных блоковых i кода (ni, ki) с
- 35. 7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES) Исправляющая способность каждого кода: Таким образом, при использовании простого последовательного двух-шагового
- 36. 7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES) Пример Код БЧХ (255, 123), для которого dmin,1 = 39, t1
- 37. 7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES) Обычно при каскадном кодировании на основе двух кодов используются двоичный и
- 38. 7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES) Декодирование с жёсткими решениями: Внутренний декодер выполняет МП декодирование с жёсткими
- 39. 7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES) Последовательное и параллельное соединение с перемежителями (Serial and Parallel Concatenation with
- 41. Скачать презентацию

7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.1.1. Конечные поля
7.1.2. Векторное пространство
7.2. Основные
7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.1.1. Конечные поля
7.1.2. Векторное пространство
7.2. Основные

7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Все канальные коды могут быть разделены на два класса:
7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Все канальные коды могут быть разделены на два класса:
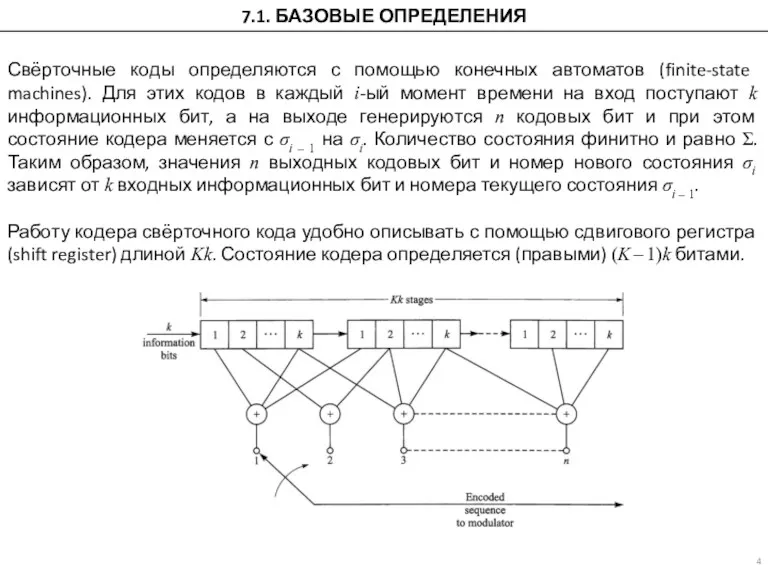
7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Свёрточные коды определяются с помощью конечных автоматов (finite-state machines).
7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Свёрточные коды определяются с помощью конечных автоматов (finite-state machines).

7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Кодовая скорость (code rate) как блочного, так и свёрточного
7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Кодовая скорость (code rate) как блочного, так и свёрточного

7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Следовательно:
Пусть средняя энергия сигнального созвездия Eav, тогда энергия кодового
7.1. БАЗОВЫЕ ОПРЕДЕЛЕНИЯ
Следовательно:
Пусть средняя энергия сигнального созвездия Eav, тогда энергия кодового

7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.2.1.
7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.2.1.

7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Блоковый код называется q-ичным, если
7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Блоковый код называется q-ичным, если

7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Помимо кодовой скорости важным параметром для
7.2. ОСНОВНЫЕ СВОЙСТВА ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Помимо кодовой скорости важным параметром для

7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Для ЛБК (n, k) алгоритм формирования n-битового
7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Для ЛБК (n, k) алгоритм формирования n-битового

7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Если порождающая матрица имеет форму
где Ik –
7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Если порождающая матрица имеет форму
где Ik –

7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Учитывая, что ЛБК (n, k) является
7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Учитывая, что ЛБК (n, k) является

7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Учитывая ортогональность строк G и H, имеем
Для
7.2.1. ПОРОЖДАЮЩАЯ И ПРОВЕРОЧНАЯ МАТРИЦЫ
Учитывая ортогональность строк G и H, имеем
Для

7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Вес кодового слова c2 –
7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Вес кодового слова c2 –

7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Минимальным расстоянием (minimum distance) кода является минимальное
7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Минимальным расстоянием (minimum distance) кода является минимальное

7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Для некоторых типов модуляции возможно установить простое
7.2.2. ПОНЯТИЯ ВЕСА И РАССТОЯНИЯ
Для некоторых типов модуляции возможно установить простое

7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ
Полином распределения весов (функция-счётчик кодовых слов с заданным
7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ
Полином распределения весов (функция-счётчик кодовых слов с заданным

7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ
Ещё один вариант полинома указывает количество кодовых слов
7.2.3. ПОЛИНОМ РАСПРЕДЕЛЕНИЯ ВЕСОВ
Ещё один вариант полинома указывает количество кодовых слов

7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Вероятность блоковой ошибки (Block Error Probability)
Для ЛБК
7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Вероятность блоковой ошибки (Block Error Probability)
Для ЛБК

7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Вероятность битовой ошибки (Bit Error Probability)
Среднее число
7.2.4. ПОМЕХОУСТОЙЧИВОСТЬ ЛИНЕЙНЫХ БЛОКОВЫХ КОДОВ
Вероятность битовой ошибки (Bit Error Probability)
Среднее число

7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.
7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.

7.3.1. КОДЫ С ПОВТОРЕНИЕМ
Двоичный код с повторениями (repetition code) (n, 1)
7.3.1. КОДЫ С ПОВТОРЕНИЕМ
Двоичный код с повторениями (repetition code) (n, 1)

7.3.2. КОДЫ ХЕММИНГА
Коды Хемминга (Hamming codes) – одни из первых предложенных
7.3.2. КОДЫ ХЕММИНГА
Коды Хемминга (Hamming codes) – одни из первых предложенных

7.3.3. КОДЫ МАКСИМАЛЬНОЙ ДЛИНЫ
Коды максимальной длины (maximum-length codes) являются дуальными к
7.3.3. КОДЫ МАКСИМАЛЬНОЙ ДЛИНЫ
Коды максимальной длины (maximum-length codes) являются дуальными к

7.3.4. КОДЫ РИДА-МАЛЛЕРА
Коды Рида-Маллера (Reed-Muller codes) известны благодаря существованию простого алгоритма
7.3.4. КОДЫ РИДА-МАЛЛЕРА
Коды Рида-Маллера (Reed-Muller codes) известны благодаря существованию простого алгоритма

7.3.5. КОДЫ АДАМАРА
Кодовые слова кода Адамара (Hadamard code) – это строки
7.3.5. КОДЫ АДАМАРА
Кодовые слова кода Адамара (Hadamard code) – это строки

7.3.6. КОДЫ ГОЛЕЯ
(Совершенный) код Голея (the Golay code) – двоичный линейный
7.3.6. КОДЫ ГОЛЕЯ
(Совершенный) код Голея (the Golay code) – двоичный линейный

7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.
7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.

7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Большинство хорошо изученных кодов эффективно
7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Большинство хорошо изученных кодов эффективно
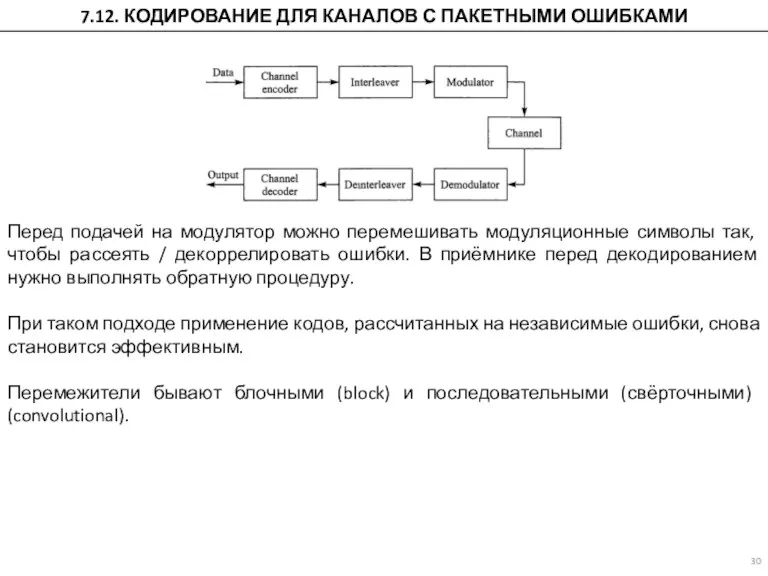
7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Перед подачей на модулятор можно
7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Перед подачей на модулятор можно

7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Блочные перемежители записывают поступающие биты
7.12. КОДИРОВАНИЕ ДЛЯ КАНАЛОВ С ПАКЕТНЫМИ ОШИБКАМИ
Блочные перемежители записывают поступающие биты

7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.
7. ЛИНЕЙНЫЕ БЛОКОВЫЕ КОДЫ
7.1. Базовые определения
7.2. Основные свойства линейных блоковых кодов
7.3.

7.13. КОМБИНИРОВАНИЕ КОДОВ
Эффективность блокового кода определяется его исправляющей способностью, т.е. количеством
7.13. КОМБИНИРОВАНИЕ КОДОВ
Эффективность блокового кода определяется его исправляющей способностью, т.е. количеством

7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Пусть имеются два систематических линейных блоковых i
7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Пусть имеются два систематических линейных блоковых i

7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Исправляющая способность каждого кода:
Таким образом, при использовании
7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Исправляющая способность каждого кода:
Таким образом, при использовании
7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Пример
Код БЧХ (255, 123), для которого dmin,1
7.13.1. КОДЫ ПРОИЗВЕДЕНИЯ (PRODUCT CODES)
Пример
Код БЧХ (255, 123), для которого dmin,1

7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Обычно при каскадном кодировании на основе двух
7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Обычно при каскадном кодировании на основе двух
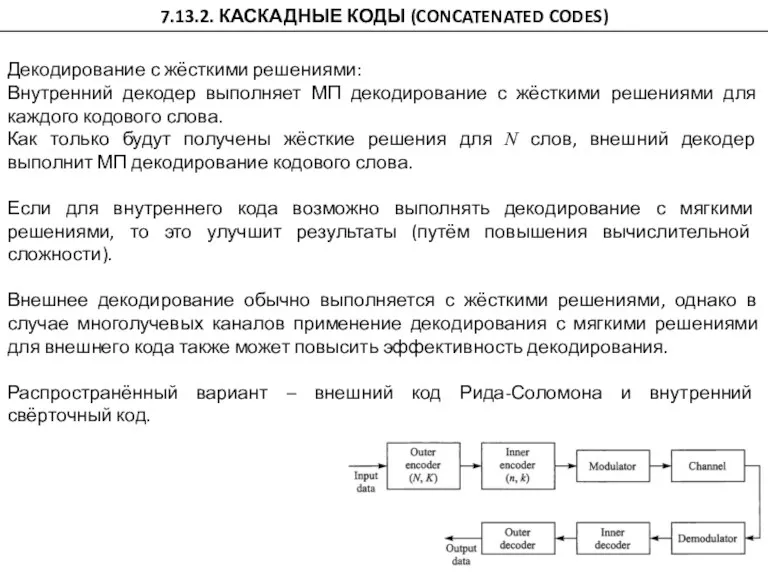
7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Декодирование с жёсткими решениями:
Внутренний декодер выполняет МП
7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Декодирование с жёсткими решениями:
Внутренний декодер выполняет МП

7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Последовательное и параллельное соединение с перемежителями
(Serial and
7.13.2. КАСКАДНЫЕ КОДЫ (CONCATENATED CODES)
Последовательное и параллельное соединение с перемежителями
(Serial and
 Решение задач с использованием файлов
Решение задач с использованием файлов Настройка трансляции сетевых адресов (NAT) в ОС Linux
Настройка трансляции сетевых адресов (NAT) в ОС Linux Как создать свой сайт?
Как создать свой сайт? Табличное представление информации
Табличное представление информации Безопасный интернет
Безопасный интернет КВН-урок
КВН-урок Профессия программист
Профессия программист Network Security. Essentials. Chapter 1
Network Security. Essentials. Chapter 1 Использование 3D для обогащения опыта пользователя в ПО
Использование 3D для обогащения опыта пользователя в ПО Объектно-ориентированное программирование. Практическое занятие №1. Введение в язык С++
Объектно-ориентированное программирование. Практическое занятие №1. Введение в язык С++ Устройство компьютера (кроссворд)
Устройство компьютера (кроссворд) Компьютер. Процессор и память
Компьютер. Процессор и память Базы данных
Базы данных Java Puzzlers
Java Puzzlers Інформаційна система обліку матеріалів складу технічного обладнання Хлібокомбінату
Інформаційна система обліку матеріалів складу технічного обладнання Хлібокомбінату Количество информации
Количество информации Функциональные модули сетей SDH
Функциональные модули сетей SDH Организация ввода и вывода данных. Начала программирования
Организация ввода и вывода данных. Начала программирования Технологии программирования
Технологии программирования Использование информационных технологий на уроках математики
Использование информационных технологий на уроках математики Общие сведения о языке С++. Лекция 2.1
Общие сведения о языке С++. Лекция 2.1 Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10
Основы программирования ФИСТ. Двухмерные массивы. Базовые алгоритмы. Лекция 10 Правила безпечної роботи в Інтернеті
Правила безпечної роботи в Інтернеті Ақпарат. Оның түрлері және қасиеттері
Ақпарат. Оның түрлері және қасиеттері TRACE MODE 5 Интегрированная SCADA/HMI и SoftLogic-система
TRACE MODE 5 Интегрированная SCADA/HMI и SoftLogic-система Развития ПО для автоматизации бизнес - процессов
Развития ПО для автоматизации бизнес - процессов Презентация по теме Технологии программирования
Презентация по теме Технологии программирования Двумерные массивы. Введение.
Двумерные массивы. Введение.