- Линейные списки

Содержание
- 2. Некоторые задачи требуют введения структур, способных увеличивать или уменьшать свой размер в процессе работы программы. Основу
- 3. Если для связи элементов в структуре задан указатель (адресное поле) на следующий элемент, то такой список
- 4. Для работы с однонаправленными списками шаблон структуры (структурный тип) будет иметь следующий вид: struct TList1 {
- 5. Схема такого списка может иметь вид: begin – адрес первого элемента в списке; Адресная часть последнего
- 6. Для работы с двунаправленными списками шаблон структуры будет иметь следующий вид: struct TList2 { Информационная часть
- 7. Схема такого списка будет иметь вид: begin и end – адреса первого и последнего элементов в
- 8. Над списками обычно выполняются следующие операции: – начальное формирование списка (создание первого элемента); – добавление нового
- 9. Структура данных СТЕК Стек – упорядоченный набор данных, в ко-тором добавление и удаление элементов производится только
- 10. Графически Стек можно изобразить так: Стек получил свое название из-за схожести с обоймой патронов: когда добавляется
- 11. Число элементов стека не ограничивается. При добавлении элементов в стек память должна динамически выделяться и освобождаться
- 12. Кроме этих обязательных операций используется операция top (peek) для чтения информации в вершине стека без извлечения
- 13. Напомним некоторые сведения: 1. Инициализация указателей Stack *begin = NULL; или Stack *begin = 0; Константа
- 14. Объявление структурного типа (шаблон) выполняется в виде, общий формат которого: struct Имя_Типа { Описание полей }
- 15. Обращение к полям структур выполняется с помощью составных имен, которые образуются двумя способами: 1) при помощи
- 16. В нашем случае будут использоваться УКАЗАТЕЛИ на структуру, поэтому обращение к полям структур будет выполняется с
- 17. Алгоритм формирования стека Рассмотрим данный алгоритм для первых двух элементов. 1. Описание типа для структуры, содержащей
- 18. 2. Объявление указателей на структуру (можно объявить в шаблоне глобально): Stack *begin, – Вершина стека (top)
- 19. 5. Ввод информации (обозначим i1); а) формирование информационной части: t -> info = i1; б) формирование
- 20. 6. Вершина стека переносится на созданный первый элемент: begin = t; В результате получается следующее: 7.
- 21. 8. Ввод информации для второго элемента (i2); а) формирование информационной части: t -> info = i2;
- 22. 9. Вершина стека снимается с первого и устана-вливается на новый элемент (A2): begin = t; Получается
- 23. Например: . . . Stack *begin = NULL, *t; int n, i, in; cout > n;
- 24. Функция формирования элемента стека Простейший вид функции (типа push), в которую передаются указатель на вершину (р)
- 25. Участок программы с обращением к функции InStack для добавления n случайных чисел (от -10 до 10)
- 26. Если в функцию InStack указатель на вершину передавать по адресу, то она может иметь следующий вид:
- 27. Просмотр стека (без извлечения) 1. Устанавливаем текущий указатель на вершину t = begin; 2. Проверяем, если
- 28. 4. ИЧ текущего элемента t -> info выводим на экран. 5. Переставляем текущий указатель t на
- 29. Функция, реализующая этот алгоритм: void View (Stack *p) { Stack *t = p; while ( t
- 30. Алгоритм освобождения памяти 1. Начинаем цикл, выполняющийся пока begin не станет равным NULL. 2. Устанавливаем текущий
- 31. Вариант 1. Функция, реализующая этот алго-ритм, может иметь следующий вид: void Del_All ( Stack **p )
- 32. Вершина стека передается в функцию по адресу с помощью указателя для того, чтобы его измененное значение
- 33. Вариант 2: void Del_All ( Stack *&p ) { Stack *t; while ( p != NULL)
- 34. Вершина стека передается в функцию по адресу с помощью ссылки (копии адреса) для того, чтобы его
- 35. Вариант 3: Stack* Del_All ( Stack *p ) { Stack *t; while ( p != NULL)
- 36. В данном случае указатель на вершину стека передаем в функцию по значению, а его измененную величину,
- 37. Алгоритм получения информации из вершины стека c извлечением 1. Устанавливаем текущий указатель t на вершину t
- 38. Вариант 1. Функция, в которую передаются значение указателя на вершину (р) и адрес переменной out для
- 39. Обращение к этой функции и вывод полученной информации на экран: begin = OutStack ( begin, &out
- 40. int OutStack ( Stack **p ) { // Как по ссылке? int out ; Stack *t
- 41. Рассмотрим примеры удаления из стека элементов, кратных 5. Вариант 1. Добавим в вершину любой элемент, удаляем
- 42. Stack* Del_5 ( Stack *b ) { b = InStack (b, 21); // Добавляем любое число
- 43. else { p = t; t = t -> next; } } // Удаление из вершины
- 44. Вариант 2. Удаляем все нужные элементы, начиная со второго, после выполненного в стеке удаления, проверяем информацию
- 45. Stack* Del_5 ( Stack *b ) { Stack *p = b; // предыдущий p = вершине
- 46. else { p = t; t = t -> next; } } // Удаление элемента из
- 47. Cвязь параметра и результата как в Варианте 1. Обращение к функции – аналогично: begin = Del_5
- 48. Stack* Del_5_mas ( Stack *b ) { int n = 0, *a, i, m; Stack *t
- 49. a = new int[n]; // Создаем массив /* Извлекаем в массив все элементы из стека, после
- 50. /* Создаем стек снова, переписывая в него элементы, оставшиеся в массиве: */ for ( i =
- 51. И в этом случае связь параметра и результата, как и в вариантах 1 и 2. Что
- 52. Stack* New_Stack_5 (Stack *b) { int in; Stack *new_b = NULL; while ( b != NULL
- 53. Обращение к функции: begin = New_Stack_5 ( begin ); Что в созданном стеке не совсем корректно
- 54. int Poisk ( Stack *p ) { int k = 0; Stack *t = p; while
- 56. Скачать презентацию
Некоторые задачи требуют введения структур, способных увеличивать или уменьшать свой размер в процессе
Некоторые задачи требуют введения структур, способных увеличивать или уменьшать свой размер в процессе

Если для связи элементов в структуре задан указатель (адресное поле) на следующий элемент,

Для работы с однонаправленными списками шаблон структуры (структурный тип) будет иметь следующий вид:
struct
Для работы с однонаправленными списками шаблон структуры (структурный тип) будет иметь следующий вид:
struct

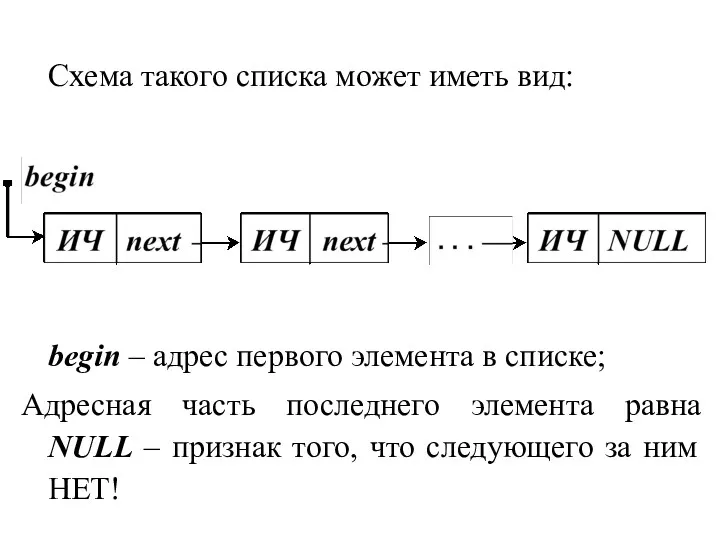
Схема такого списка может иметь вид:
begin – адрес первого элемента в списке;
Адресная часть
begin – адрес первого элемента в списке;
Адресная часть
Для работы с двунаправленными списками шаблон структуры будет иметь следующий вид:
struct TList2 {
Информационная
Для работы с двунаправленными списками шаблон структуры будет иметь следующий вид:
struct TList2 {
Информационная

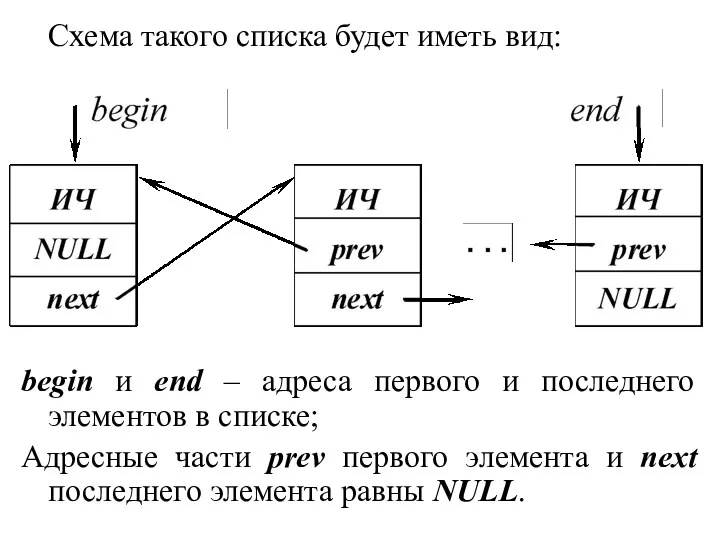
Схема такого списка будет иметь вид:
begin и end – адреса первого и последнего
Схема такого списка будет иметь вид:
begin и end – адреса первого и последнего
Над списками обычно выполняются следующие операции:
– начальное формирование списка (создание первого элемента);
– добавление
Над списками обычно выполняются следующие операции:
– начальное формирование списка (создание первого элемента);
– добавление

Структура данных СТЕК
Стек – упорядоченный набор данных, в ко-тором добавление и удаление элементов
Структура данных СТЕК
Стек – упорядоченный набор данных, в ко-тором добавление и удаление элементов

Графически Стек можно изобразить так:
Стек получил свое название из-за схожести с обоймой патронов:
Графически Стек можно изобразить так:
Стек получил свое название из-за схожести с обоймой патронов:

Число элементов стека не ограничивается. При добавлении элементов в стек память должна динамически
Число элементов стека не ограничивается. При добавлении элементов в стек память должна динамически

Кроме этих обязательных операций используется операция top (peek) для чтения информации в вершине
Кроме этих обязательных операций используется операция top (peek) для чтения информации в вершине

Напомним некоторые сведения:
1. Инициализация указателей
Stack *begin = NULL; или Stack *begin =
Напомним некоторые сведения:
1. Инициализация указателей
Stack *begin = NULL; или Stack *begin =

Объявление структурного типа (шаблон) выполняется в виде, общий формат которого:
struct Имя_Типа {
Описание
Объявление структурного типа (шаблон) выполняется в виде, общий формат которого:
struct Имя_Типа {
Описание

Обращение к полям структур выполняется с помощью составных имен, которые образуются двумя способами:
1)
Обращение к полям структур выполняется с помощью составных имен, которые образуются двумя способами:
1)

В нашем случае будут использоваться УКАЗАТЕЛИ на структуру, поэтому обращение к полям структур
В нашем случае будут использоваться УКАЗАТЕЛИ на структуру, поэтому обращение к полям структур

Алгоритм формирования стека
Рассмотрим данный алгоритм для первых двух элементов.
1. Описание типа для структуры,
Алгоритм формирования стека
Рассмотрим данный алгоритм для первых двух элементов.
1. Описание типа для структуры,

2. Объявление указателей на структуру (можно объявить в шаблоне глобально):
Stack *begin, – Вершина
2. Объявление указателей на структуру (можно объявить в шаблоне глобально):
Stack *begin, – Вершина

5. Ввод информации (обозначим i1);
а) формирование информационной части:
t -> info = i1;
б)
5. Ввод информации (обозначим i1);
а) формирование информационной части:
t -> info = i1;
б)

6. Вершина стека переносится на созданный первый элемент:
begin = t;
В результате получается следующее:
7.
6. Вершина стека переносится на созданный первый элемент:
begin = t;
В результате получается следующее:
7.

8. Ввод информации для второго элемента (i2);
а) формирование информационной части:
t -> info
8. Ввод информации для второго элемента (i2);
а) формирование информационной части:
t -> info

9. Вершина стека снимается с первого и устана-вливается на новый элемент (A2):
begin =
9. Вершина стека снимается с первого и устана-вливается на новый элемент (A2):
begin =

Например:
. . .
Stack *begin = NULL, *t; int n, i, in;
cout << “ n
Например:
. . .
Stack *begin = NULL, *t; int n, i, in;
cout << “ n

Функция формирования элемента стека
Простейший вид функции (типа push), в которую передаются указатель на
Функция формирования элемента стека
Простейший вид функции (типа push), в которую передаются указатель на

Участок программы с обращением к функции InStack для добавления n случайных чисел (от
Участок программы с обращением к функции InStack для добавления n случайных чисел (от

Если в функцию InStack указатель на вершину передавать по адресу, то она может
Если в функцию InStack указатель на вершину передавать по адресу, то она может

Просмотр стека (без извлечения)
1. Устанавливаем текущий указатель на вершину
t = begin;
2.
Просмотр стека (без извлечения)
1. Устанавливаем текущий указатель на вершину
t = begin;
2.

4. ИЧ текущего элемента t -> info выводим на экран.
5. Переставляем текущий
4. ИЧ текущего элемента t -> info выводим на экран.
5. Переставляем текущий

Функция, реализующая этот алгоритм:
void View (Stack *p) {
Stack *t = p;
while ( t
Функция, реализующая этот алгоритм:
void View (Stack *p) {
Stack *t = p;
while ( t

Алгоритм освобождения памяти
1. Начинаем цикл, выполняющийся пока begin не станет равным NULL.
2. Устанавливаем
Алгоритм освобождения памяти
1. Начинаем цикл, выполняющийся пока begin не станет равным NULL.
2. Устанавливаем

Вариант 1. Функция, реализующая этот алго-ритм, может иметь следующий вид:
void Del_All ( Stack
Вариант 1. Функция, реализующая этот алго-ритм, может иметь следующий вид:
void Del_All ( Stack

Вершина стека передается в функцию по адресу с помощью указателя для того, чтобы
Вершина стека передается в функцию по адресу с помощью указателя для того, чтобы

Вариант 2:
void Del_All ( Stack *&p ) {
Stack *t;
while ( p != NULL)
Вариант 2:
void Del_All ( Stack *&p ) {
Stack *t;
while ( p != NULL)

Вершина стека передается в функцию по адресу с помощью ссылки (копии адреса) для
Вершина стека передается в функцию по адресу с помощью ссылки (копии адреса) для

Вариант 3:
Stack* Del_All ( Stack *p ) {
Stack *t;
while ( p != NULL)
Вариант 3:
Stack* Del_All ( Stack *p ) {
Stack *t;
while ( p != NULL)

В данном случае указатель на вершину стека передаем в функцию по значению, а
В данном случае указатель на вершину стека передаем в функцию по значению, а

Алгоритм получения информации из вершины стека c извлечением
1. Устанавливаем текущий указатель t на
Алгоритм получения информации из вершины стека c извлечением
1. Устанавливаем текущий указатель t на

Вариант 1. Функция, в которую передаются значение указателя на вершину (р) и адрес
Вариант 1. Функция, в которую передаются значение указателя на вершину (р) и адрес

Обращение к этой функции и вывод полученной информации на экран:
begin = OutStack (
Обращение к этой функции и вывод полученной информации на экран:
begin = OutStack (

int OutStack ( Stack **p ) { // Как по ссылке?
int out ;
Stack
int OutStack ( Stack **p ) { // Как по ссылке?
int out ;
Stack

Рассмотрим примеры удаления из стека элементов, кратных 5.
Вариант 1. Добавим в вершину любой
Рассмотрим примеры удаления из стека элементов, кратных 5.
Вариант 1. Добавим в вершину любой

Stack* Del_5 ( Stack *b )
{
b = InStack (b, 21); //
Stack* Del_5 ( Stack *b )
{
b = InStack (b, 21); //

else {
p = t;
t = t -> next;
}
}
//
else {
p = t;
t = t -> next;
}
}
//

Вариант 2. Удаляем все нужные элементы, начиная со второго, после выполненного в стеке

Stack* Del_5 ( Stack *b )
{
Stack *p = b; // предыдущий
Stack* Del_5 ( Stack *b )
{
Stack *p = b; // предыдущий

else {
p = t;
t = t -> next;
}
}
//
else {
p = t;
t = t -> next;
}
}
//

Cвязь параметра и результата как в Варианте 1.
Обращение к функции – аналогично:
begin
Cвязь параметра и результата как в Варианте 1.
Обращение к функции – аналогично:
begin

Stack* Del_5_mas ( Stack *b )
{
int n = 0, *a, i, m;
Stack* Del_5_mas ( Stack *b )
{
int n = 0, *a, i, m;

a = new int[n]; // Создаем массив
/* Извлекаем в массив все элементы
a = new int[n]; // Создаем массив
/* Извлекаем в массив все элементы
![a = new int[n]; // Создаем массив /* Извлекаем в массив все элементы](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/391397/slide-48.jpg)
/* Создаем стек снова, переписывая в него элементы, оставшиеся в массиве: */
for
/* Создаем стек снова, переписывая в него элементы, оставшиеся в массиве: */
for

И в этом случае связь параметра и результата, как и в вариантах 1
И в этом случае связь параметра и результата, как и в вариантах 1

Stack* New_Stack_5 (Stack *b)
{
int in;
Stack *new_b = NULL;
while ( b !=
Stack* New_Stack_5 (Stack *b)
{
int in;
Stack *new_b = NULL;
while ( b !=

Обращение к функции:
begin = New_Stack_5 ( begin );
Что в созданном стеке не
Обращение к функции:
begin = New_Stack_5 ( begin );
Что в созданном стеке не

int Poisk ( Stack *p )
{
int k = 0;
Stack *t = p;
while
int Poisk ( Stack *p )
{
int k = 0;
Stack *t = p;
while
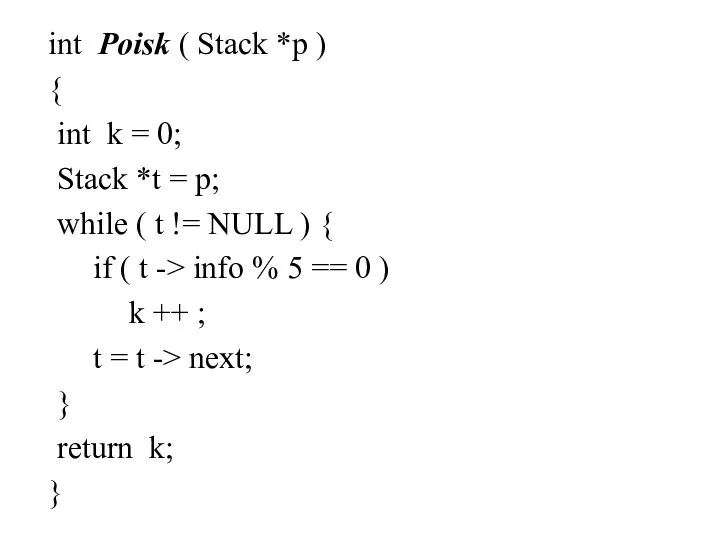
 Электронная почта, телеконференция, обмен файлами и другие услуги сети
Электронная почта, телеконференция, обмен файлами и другие услуги сети Презентация по теме Устойство компьютера
Презентация по теме Устойство компьютера Программное обеспечение
Программное обеспечение Лекция 2. Файлы (текстовые). Массивы
Лекция 2. Файлы (текстовые). Массивы Проектный процесс в дизайне рекламы. Проектирование товарного знака (знака обслуживания) и фирменного стиля
Проектный процесс в дизайне рекламы. Проектирование товарного знака (знака обслуживания) и фирменного стиля Оперативная информация
Оперативная информация Совершенствование управления деятельностью кредитной организации на основе применения технологии искусственного интеллекта
Совершенствование управления деятельностью кредитной организации на основе применения технологии искусственного интеллекта Инструкция подключения учеников к видеоконференции через программу ZOOM
Инструкция подключения учеников к видеоконференции через программу ZOOM Внеклассное мероприятие ФизИкт
Внеклассное мероприятие ФизИкт Интеграционное тестирование. Основные понятия
Интеграционное тестирование. Основные понятия Лексика и концепции языка Си. Лекция 2
Лексика и концепции языка Си. Лекция 2 Учебный проект Паутины компьтерных сетей
Учебный проект Паутины компьтерных сетей Файловая структура компьютера. 8 класс
Файловая структура компьютера. 8 класс Массивы. Решение задач. Подготовка к ЕГЭ
Массивы. Решение задач. Подготовка к ЕГЭ Истинность высказывания со словами и, или
Истинность высказывания со словами и, или Возникновение, развитие и типы журналистики (лекция № 2)
Возникновение, развитие и типы журналистики (лекция № 2) Презентации к урокам
Презентации к урокам Корпоративный документооборот. Документные системы. (Тема 6, продолжение)
Корпоративный документооборот. Документные системы. (Тема 6, продолжение) Проблемы проектирования инфокоммуникационных систем и сетей NGN и пост-NGN. (Лекции 3-6)
Проблемы проектирования инфокоммуникационных систем и сетей NGN и пост-NGN. (Лекции 3-6) Новые профессии в игровой индустрии: Арт-менеджер
Новые профессии в игровой индустрии: Арт-менеджер Доступное дополнительное образование для детей
Доступное дополнительное образование для детей Виды и технологические возможности CAD/CAM/САЕ систем
Виды и технологические возможности CAD/CAM/САЕ систем ER-диаграммы. Связи
ER-диаграммы. Связи Основные методологические аспекты проектирования информационной системы
Основные методологические аспекты проектирования информационной системы Графические редакторы. Программа Paint Tool SAI
Графические редакторы. Программа Paint Tool SAI Применение ГОСТ Р 7.0.100-2018 Библиографическая запись. Библиографическое описание при составлении библиографических списков
Применение ГОСТ Р 7.0.100-2018 Библиографическая запись. Библиографическое описание при составлении библиографических списков Алгоритмы планирования процессов
Алгоритмы планирования процессов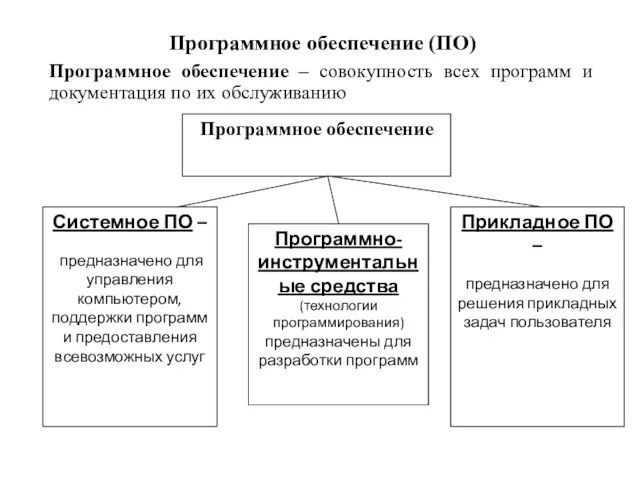 ПО и ОС Windows
ПО и ОС Windows