- Load Balancing and Termination Detection

Содержание
- 2. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 3. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 4. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 5. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 6. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 7. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 8. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 9. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 10. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 11. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 12. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 13. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 14. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 15. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 16. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 17. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 18. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 19. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 20. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 21. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 22. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 23. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 24. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 25. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 26. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 27. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 28. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 29. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 30. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 31. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 32. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 33. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 34. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 35. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 36. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 37. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 38. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 39. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 40. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 41. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 42. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 43. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 44. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 45. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 46. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 47. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 48. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
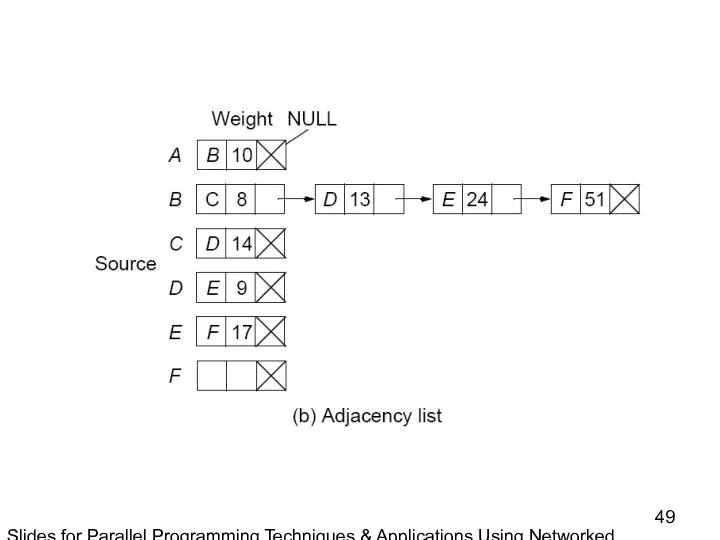
- 49. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 50. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 51. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
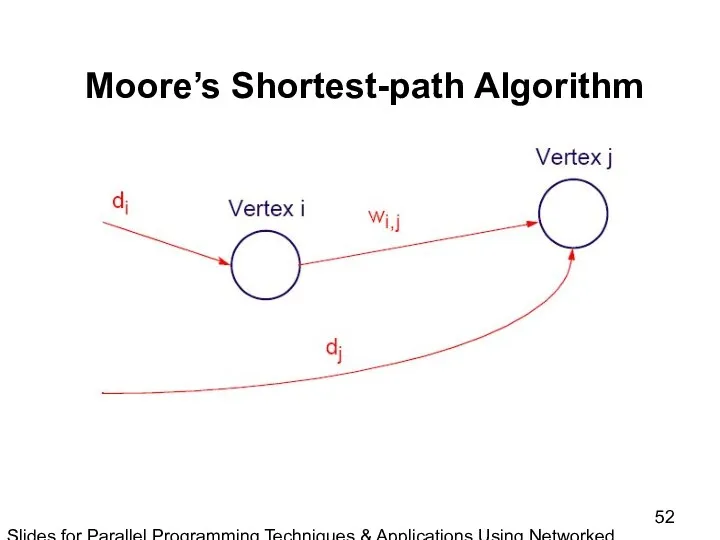
- 52. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 53. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 54. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 55. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 56. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 57. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
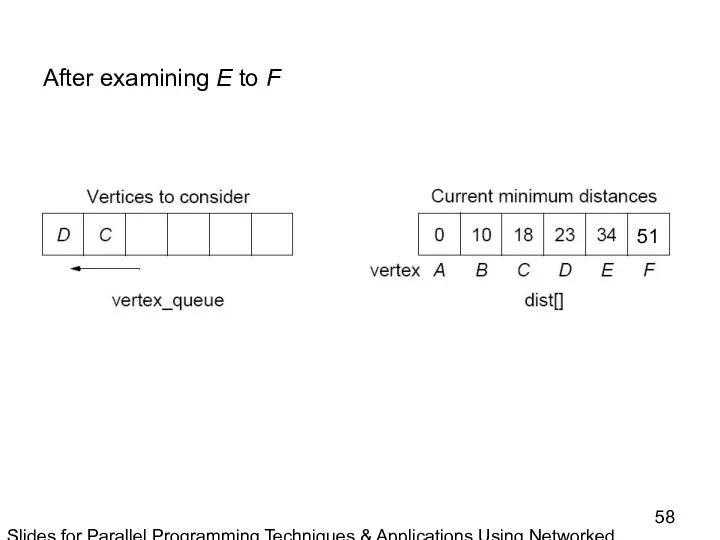
- 58. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 59. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 60. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 61. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 62. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 63. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 64. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 65. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 66. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
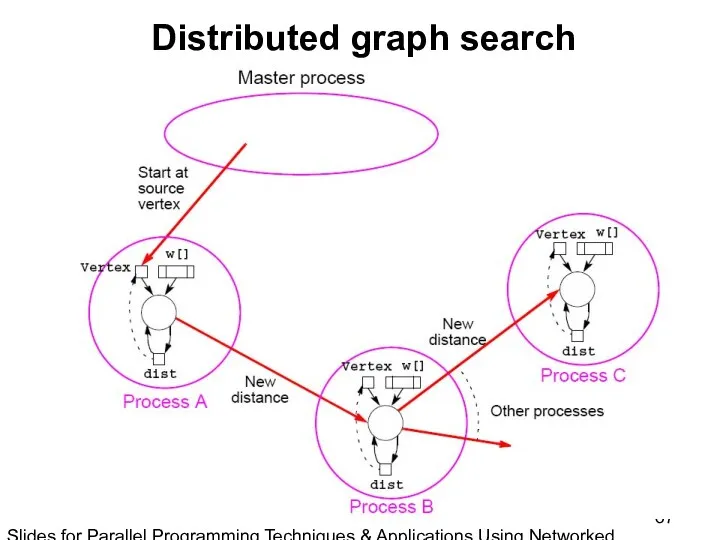
- 67. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 68. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 69. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 70. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 71. Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers 2nd ed., by
- 73. Скачать презентацию
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
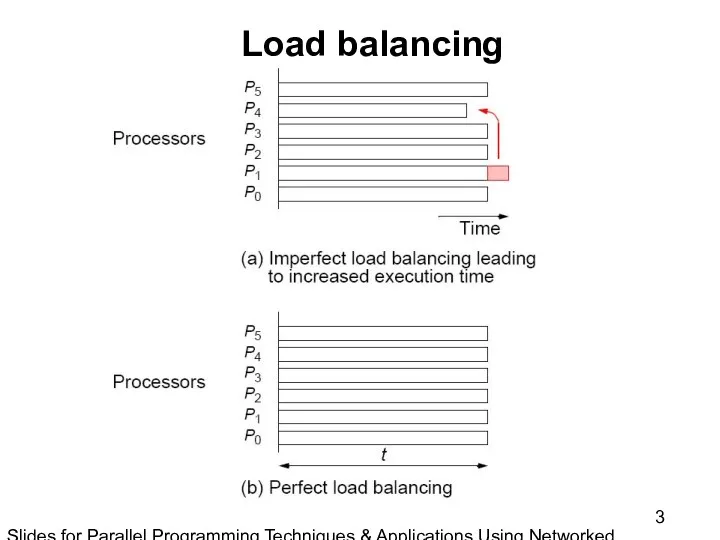
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
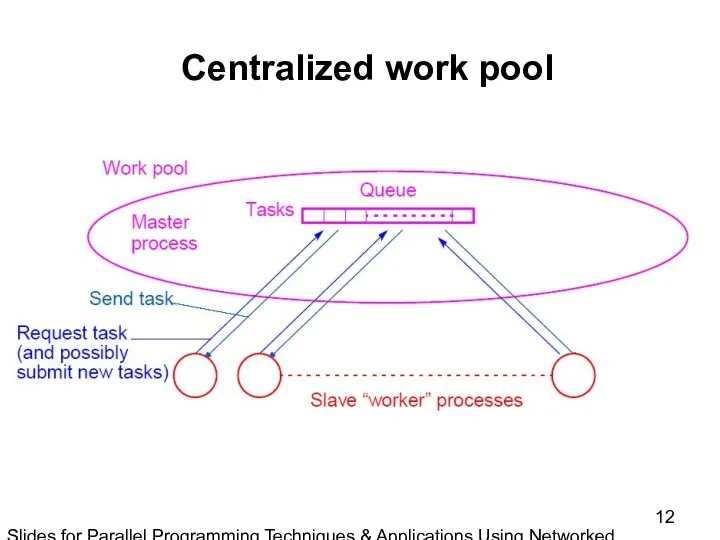
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
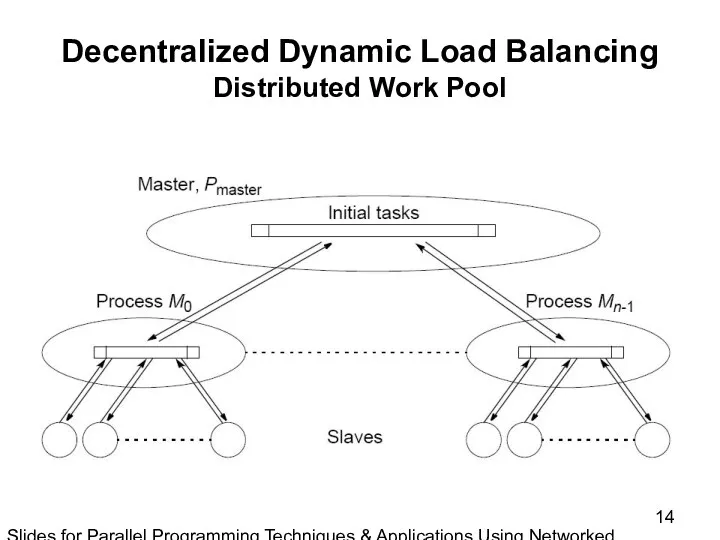
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
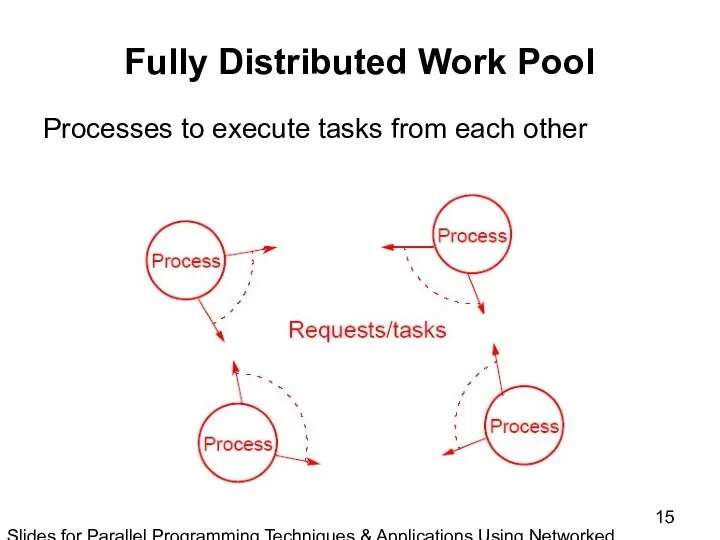
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
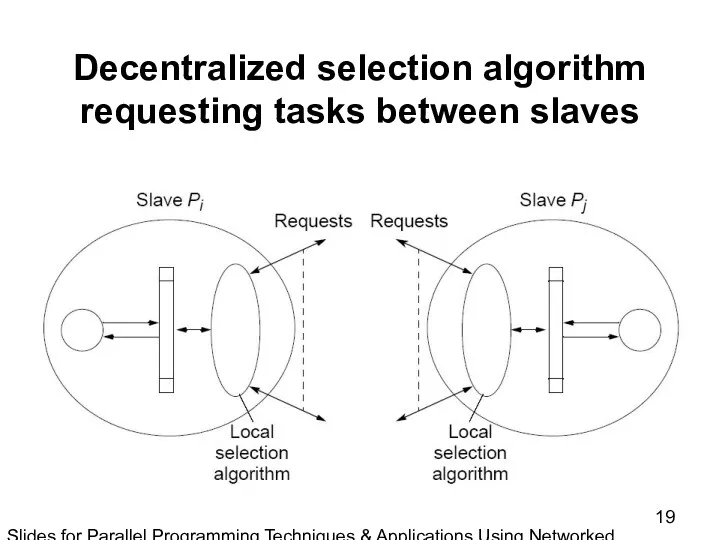
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
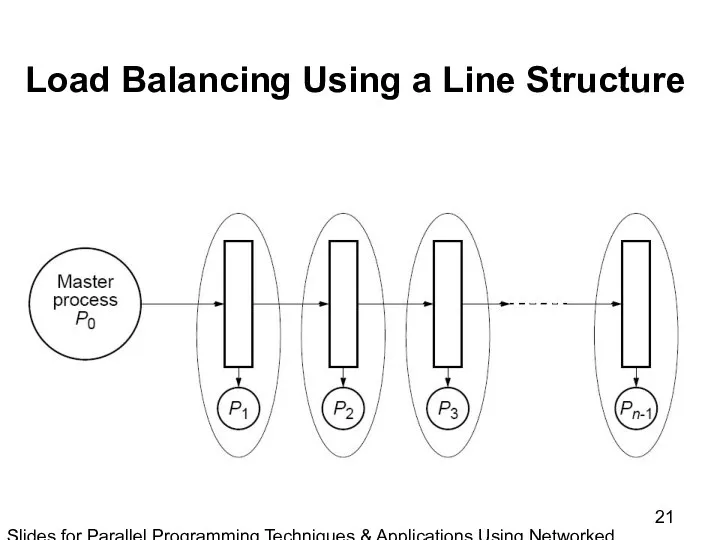
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
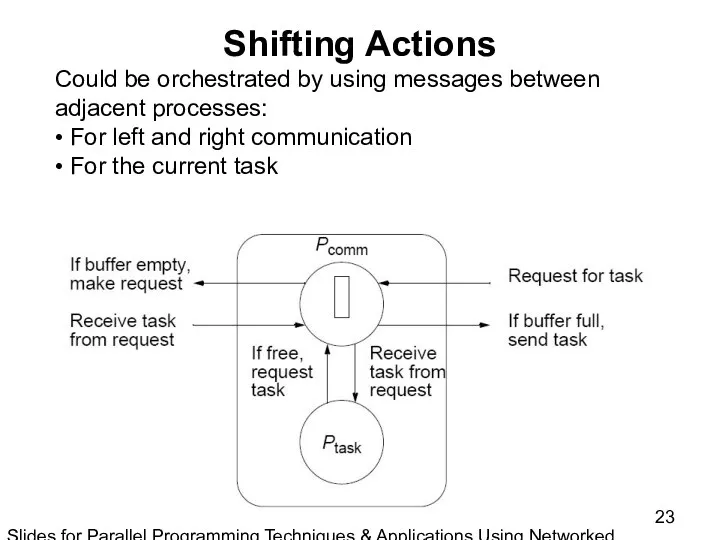
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
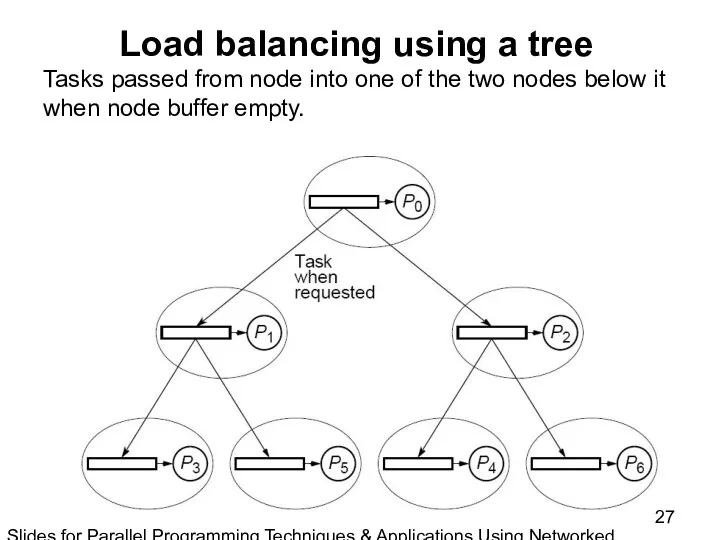
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
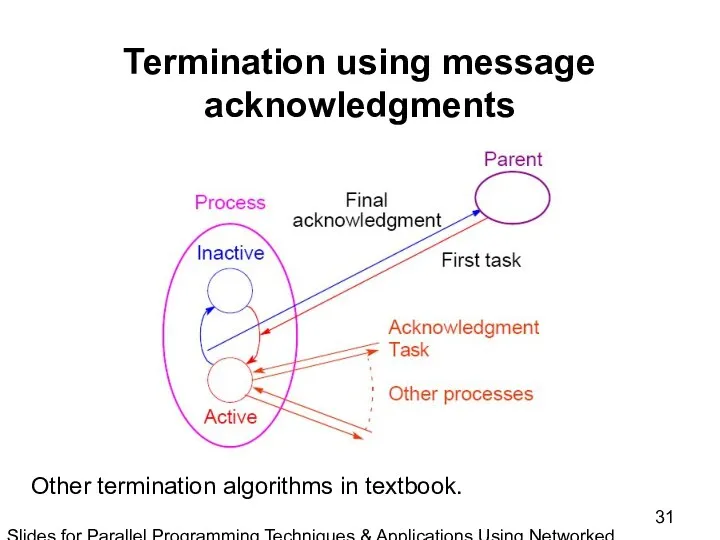
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
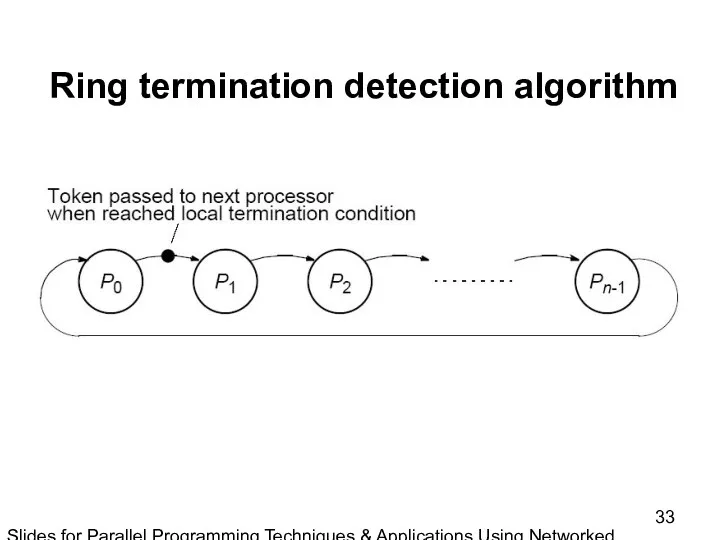
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
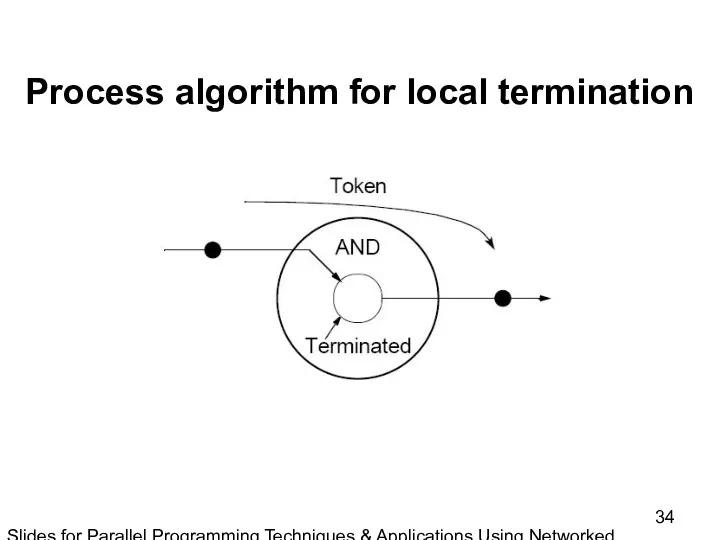
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
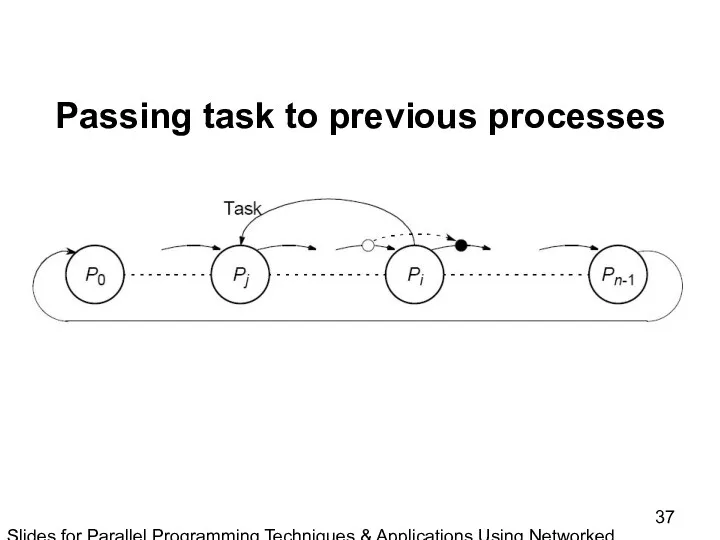
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
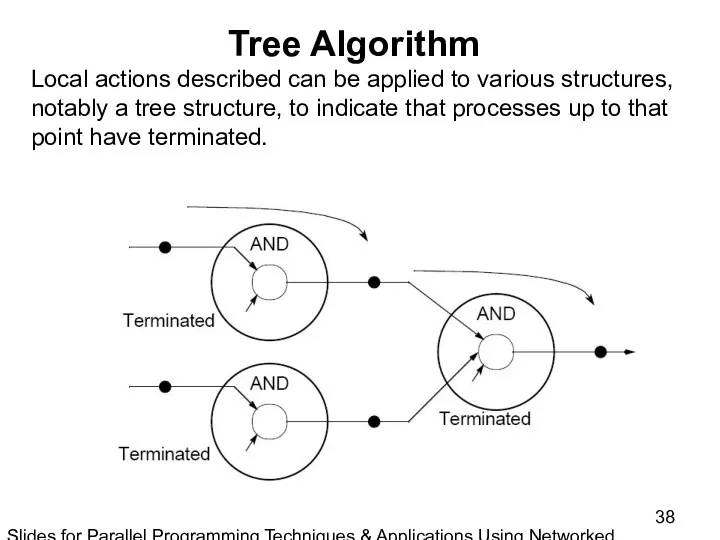
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
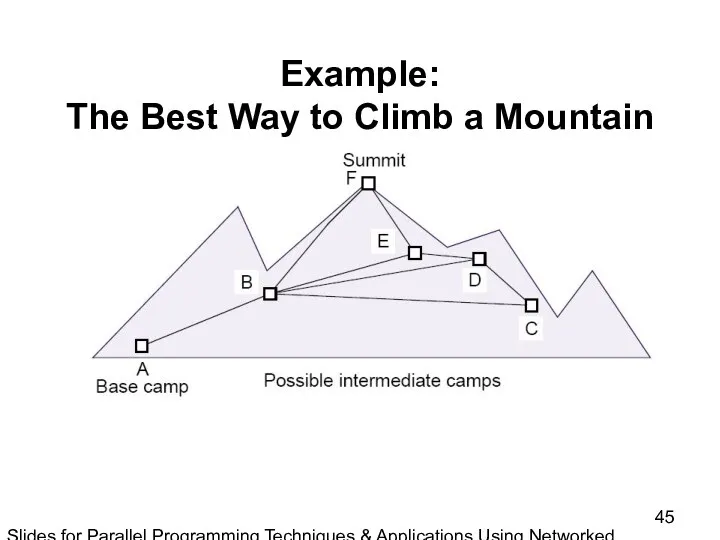
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
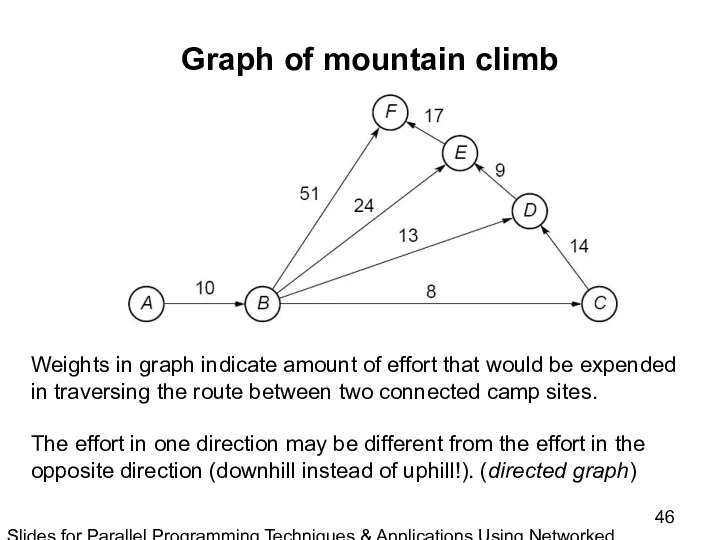
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
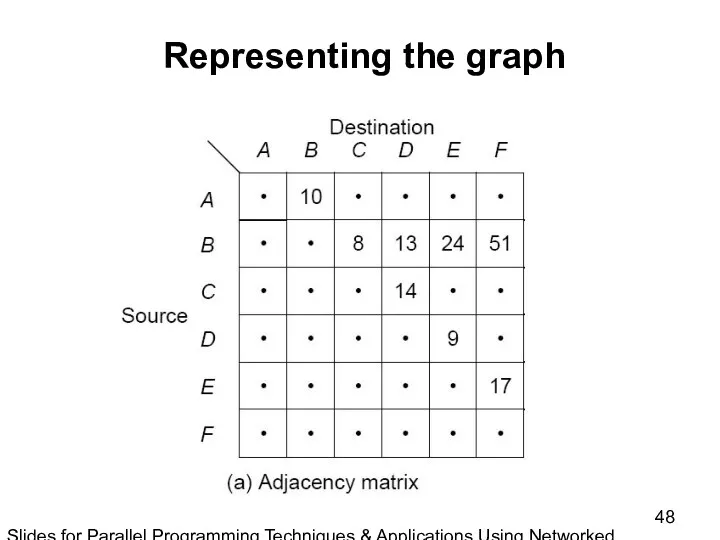
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers
Slides for Parallel Programming Techniques & Applications Using Networked Workstations & Parallel Computers

 Information technology in our daily lives
Information technology in our daily lives Основы языка ассемблера
Основы языка ассемблера Области применения компьютерного информационного моделирования
Области применения компьютерного информационного моделирования Микропроцессор
Микропроцессор Культура научной речи
Культура научной речи Технология создания электронного учебника
Технология создания электронного учебника Хранение информации. 10 лекция
Хранение информации. 10 лекция Моделирование как метод познания
Моделирование как метод познания Разработка мобильных приложений. Responsive Web Design
Разработка мобильных приложений. Responsive Web Design Идентификация. Штриховое кодирование
Идентификация. Штриховое кодирование 4 декабря - день информатики в России
4 декабря - день информатики в России Руководство по размещению тестовых заданий в компьютерной программе
Руководство по размещению тестовых заданий в компьютерной программе Позиционирование и продвижение в соцсетях
Позиционирование и продвижение в соцсетях Реформа перехода на новый порядок применения кассовой техники для сферы жилищно-коммунального хозяйства
Реформа перехода на новый порядок применения кассовой техники для сферы жилищно-коммунального хозяйства Создание видеофильма средствами Windows Movie Maker
Создание видеофильма средствами Windows Movie Maker Предмет информатики. Информация, измерение, единицы измерения
Предмет информатики. Информация, измерение, единицы измерения Презентация к уроку по теме: Графический редактор Adobe Photoshop
Презентация к уроку по теме: Графический редактор Adobe Photoshop Создание 3d-модели современного кабинета информатики
Создание 3d-модели современного кабинета информатики Идентификация и установление подлинности
Идентификация и установление подлинности Модельдер және оның тұрлері
Модельдер және оның тұрлері Основные принципы технологии клиент-сервер
Основные принципы технологии клиент-сервер Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile
Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile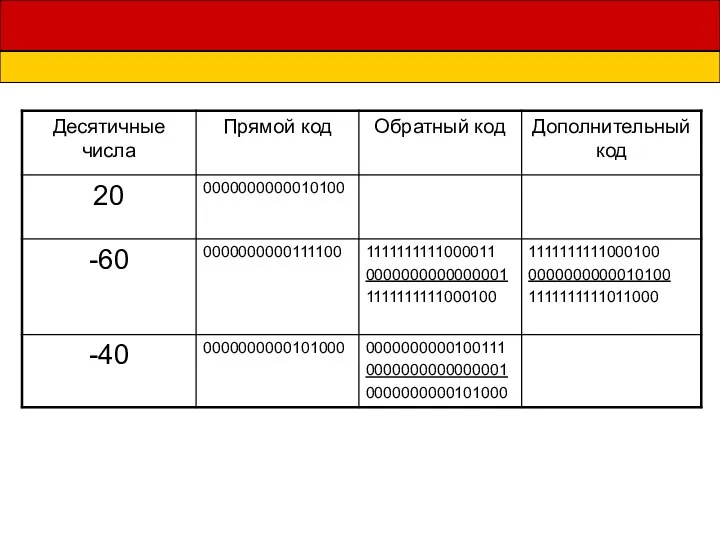 Презентация Представление чисел в формате с плавающей запятой
Презентация Представление чисел в формате с плавающей запятой Характеристика и оценка возможностей ОС семейства Windows для ПК
Характеристика и оценка возможностей ОС семейства Windows для ПК Информатизация общества. Основы классификации и структурирования информации
Информатизация общества. Основы классификации и структурирования информации Help us find the way to the right
Help us find the way to the right Процесс создания платформы электронной коммерции
Процесс создания платформы электронной коммерции Аддитивные технологии
Аддитивные технологии