- Машинное обучение с подкреплением

Содержание
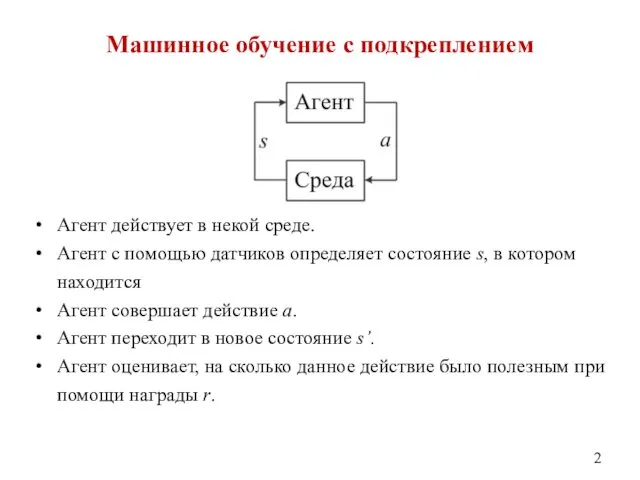
- 2. Машинное обучение с подкреплением Агент действует в некой среде. Агент с помощью датчиков определяет состояние s,
- 3. Развёрнутая схема обучения с подкреплением
- 4. Наглядная схема
- 5. Опыт За счёт совершения различных действий в среде агент набирается опыта. Опыт – в каком состоянии
- 6. Награда Агент оценивает ситуацию – пару «состояние-действие» при помощи скалярной награды (действительного числа). Награда показывает, насколько
- 7. Стратегия Агент руководствуется некоторой стратегией действий. Стратегия определяет в каком состоянии будет совершено какое действие.
- 8. Обучение За счёт использования полученного опыта обновляется стратегия поведения агента. После завершения обучения агент может действовать,
- 9. Этапы рабочего процесса при использовании обучения с подкреплением
- 10. Пример: Обучение беспилотного автомобиля Бортовой компьютер обучается вождению... (агент) с помощью данных с датчиков (камеры и
- 11. Популярный пример: обучение ходьбе роботов
- 12. Q-обучение Самый простой популярный алгоритм обучения с подкреплением. В основе лежит определение оценки функции полезности (Q-функции)
- 13. Функция полезности действия Каждое действие в каждом состоянии можно оценить при помощи функцией полезности Qπ(s, a)
- 14. Функция полезности показывает, насколько большую награду можно получить за определённое действие, а также насколько данное действие
- 15. Стратегия действий агента при Q-обучении Стратегия действий – выбор действия с максимальной текущей оценкой полезности.
- 16. Хранение оценок полезности действий в таблице
- 17. Глубокое Q-обучение Для аппроксимации функции полезности в непрерывном пространстве состояний используется нейронная сеть. Т.е. если состояний
- 18. Более сложный алгоритм, чем Q-обучение. Нет ограничений на количество действий (например, действие - угол поворота руля
- 19. Системы адаптивной критики Критик – блок системы управления, который оценивает качество её работы. Задачей критика является
- 20. Формулы Определение функции полезности: Формула вычисления целевых значений для обучения критика:
- 21. Задача о перевёрнутом маятнике Простая задача для апробации методов обучения с подкреплением. Целевое состояние маятника: стабилизация
- 22. Используемый инструментарий
- 23. До обучения
- 24. Результаты обучения маятника Время обучения – порядка 5 – 10 минут
- 25. Результаты обучения маятника
- 26. Мультиагентное обучение с подкреплением Наиболее актуальная на настоящее время область исследований.
- 27. Задача перемещения твёрдого тела группой роботов (отсутствие прямой информационной связи)
- 28. Постановка задачи В разных точках вдоль периметра цилиндра находятся роботы, давящие на него с разной силой.
- 29. Подход к решению задачи В каждом роботе используется независимая система адаптивной критики. Обучение происходит полностью за
- 30. Робот измеряет скорость движения и угол отклонения направления движения от направления к цели. Эти данные характеризуют
- 31. Структура актора и критика
- 32. Вычислительный эксперимент – траектория перемещения тела
- 33. Визуализация работы трёх роботов
- 34. Визуализация работы трёх роботов
- 36. Скачать презентацию
Машинное обучение с подкреплением
Агент действует в некой среде.
Агент с помощью датчиков
Машинное обучение с подкреплением
Агент действует в некой среде.
Агент с помощью датчиков
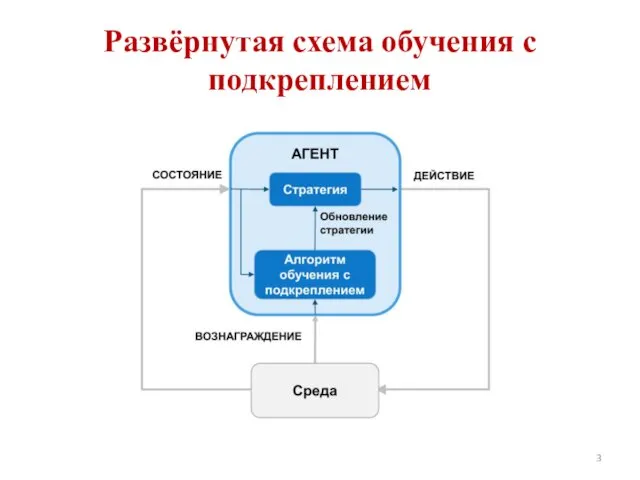
Развёрнутая схема обучения с подкреплением
Развёрнутая схема обучения с подкреплением
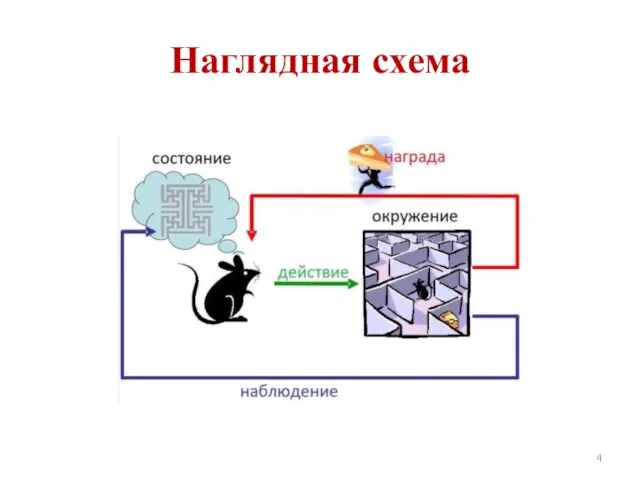
Наглядная схема
Наглядная схема

Опыт
За счёт совершения различных действий в среде агент набирается опыта.
Опыт –
Опыт
За счёт совершения различных действий в среде агент набирается опыта.
Опыт –

Награда
Агент оценивает ситуацию – пару «состояние-действие» при помощи скалярной награды (действительного
Награда
Агент оценивает ситуацию – пару «состояние-действие» при помощи скалярной награды (действительного

Стратегия
Агент руководствуется некоторой стратегией действий.
Стратегия определяет в каком состоянии будет совершено
Стратегия
Агент руководствуется некоторой стратегией действий.
Стратегия определяет в каком состоянии будет совершено

Обучение
За счёт использования полученного опыта обновляется стратегия поведения агента.
После завершения обучения
Обучение
За счёт использования полученного опыта обновляется стратегия поведения агента.
После завершения обучения

Этапы рабочего процесса при использовании обучения с
подкреплением
Этапы рабочего процесса при использовании обучения с
подкреплением

Пример: Обучение беспилотного автомобиля
Бортовой компьютер обучается вождению...
(агент)
с помощью данных с
Пример: Обучение беспилотного автомобиля
Бортовой компьютер обучается вождению...
(агент)
с помощью данных с

Популярный пример:
обучение ходьбе роботов
Популярный пример:
обучение ходьбе роботов

Q-обучение
Самый простой популярный алгоритм обучения с подкреплением.
В основе лежит определение оценки
Q-обучение
Самый простой популярный алгоритм обучения с подкреплением.
В основе лежит определение оценки

Функция полезности действия
Каждое действие в каждом состоянии можно оценить при помощи
Функция полезности действия
Каждое действие в каждом состоянии можно оценить при помощи

Функция полезности показывает, насколько большую награду можно получить за определённое действие,
Функция полезности показывает, насколько большую награду можно получить за определённое действие,

Стратегия действий агента при
Q-обучении
Стратегия действий – выбор действия с максимальной текущей
Стратегия действий агента при
Q-обучении
Стратегия действий – выбор действия с максимальной текущей

Хранение оценок полезности действий в таблице
Хранение оценок полезности действий в таблице

Глубокое Q-обучение
Для аппроксимации функции полезности в непрерывном пространстве состояний используется нейронная
Глубокое Q-обучение
Для аппроксимации функции полезности в непрерывном пространстве состояний используется нейронная

Более сложный алгоритм, чем Q-обучение.
Нет ограничений на количество действий (например, действие
Более сложный алгоритм, чем Q-обучение.
Нет ограничений на количество действий (например, действие
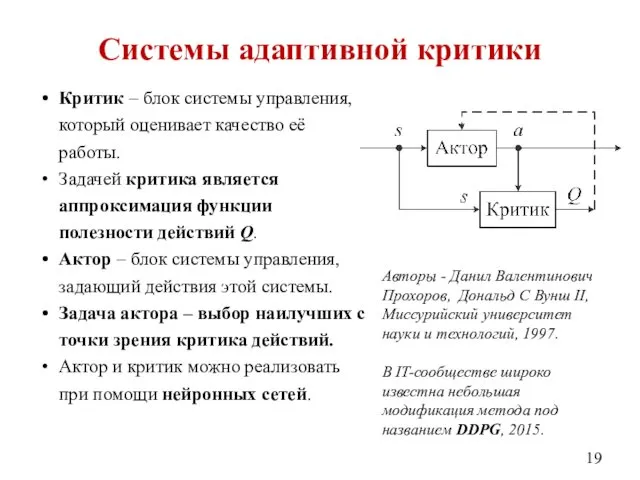
Системы адаптивной критики
Критик – блок системы управления, который оценивает качество её
Системы адаптивной критики
Критик – блок системы управления, который оценивает качество её

Формулы
Определение функции полезности:
Формула вычисления целевых значений для обучения критика:
Формулы
Определение функции полезности:
Формула вычисления целевых значений для обучения критика:

Задача о перевёрнутом маятнике
Простая задача для апробации методов обучения с подкреплением.
Целевое
Задача о перевёрнутом маятнике
Простая задача для апробации методов обучения с подкреплением.
Целевое

Используемый инструментарий
Используемый инструментарий

До обучения
До обучения

Результаты обучения маятника
Время обучения – порядка 5 – 10 минут
Результаты обучения маятника
Время обучения – порядка 5 – 10 минут

Результаты обучения маятника
Результаты обучения маятника
Мультиагентное обучение с подкреплением
Наиболее актуальная на настоящее время область исследований.
Мультиагентное обучение с подкреплением
Наиболее актуальная на настоящее время область исследований.
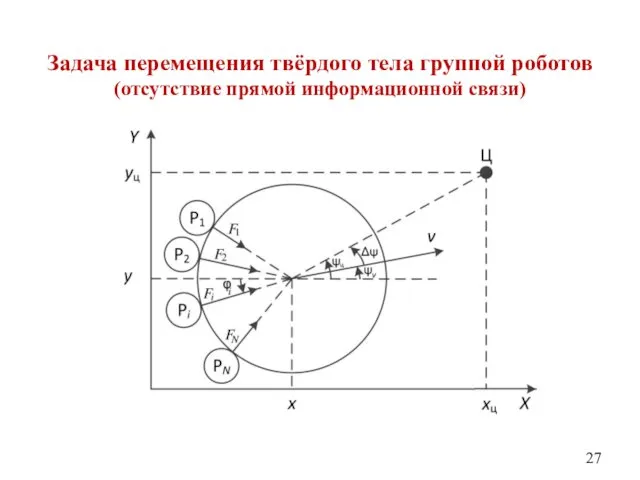
Задача перемещения твёрдого тела группой роботов
(отсутствие прямой информационной связи)
Задача перемещения твёрдого тела группой роботов
(отсутствие прямой информационной связи)

Постановка задачи
В разных точках вдоль периметра цилиндра находятся роботы, давящие на
Постановка задачи
В разных точках вдоль периметра цилиндра находятся роботы, давящие на

Подход к решению задачи
В каждом роботе используется независимая система адаптивной критики.
Обучение
Подход к решению задачи
В каждом роботе используется независимая система адаптивной критики.
Обучение

Робот измеряет скорость движения и угол отклонения направления движения от направления
Робот измеряет скорость движения и угол отклонения направления движения от направления
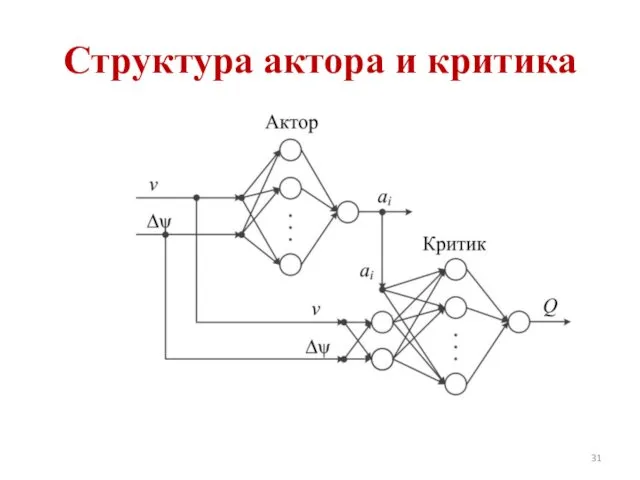
Структура актора и критика
Структура актора и критика
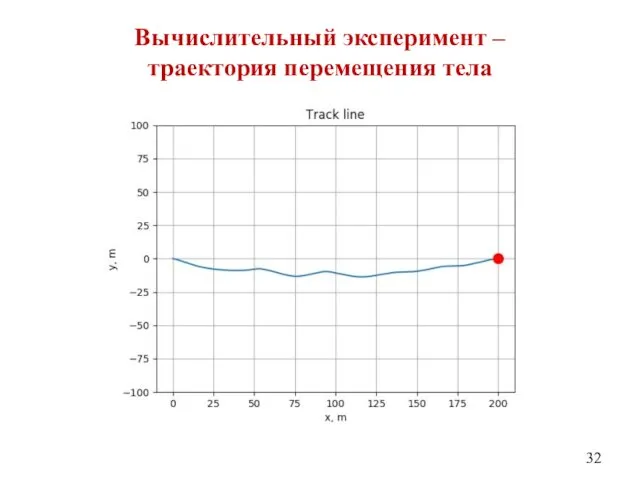
Вычислительный эксперимент –
траектория перемещения тела
Вычислительный эксперимент –
траектория перемещения тела
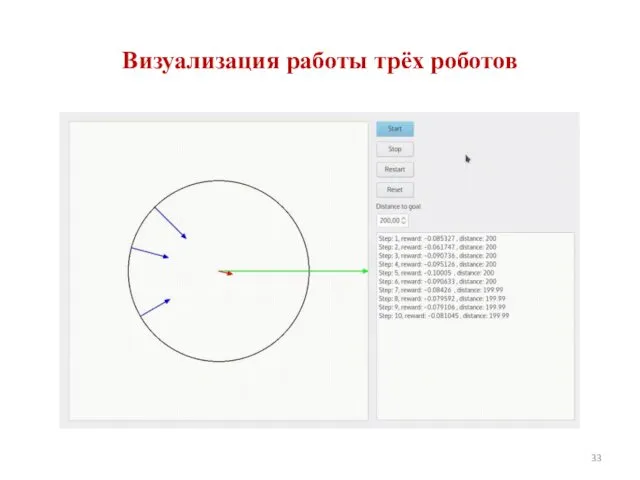
Визуализация работы трёх роботов
Визуализация работы трёх роботов

Визуализация работы трёх роботов
Визуализация работы трёх роботов
 Звуковые карты и мультимедиа
Звуковые карты и мультимедиа Microsoft Word
Microsoft Word Обработка массивов
Обработка массивов Технические средства и системы информатизации. Устройство ПК
Технические средства и системы информатизации. Устройство ПК Константность. Конструктор копирования. Класс массива. ООП. Лекция 5
Константность. Конструктор копирования. Класс массива. ООП. Лекция 5 Архитектура ПК
Архитектура ПК The social media analyst. Position
The social media analyst. Position Инструменты ретуширования в графическом редакторе Photoshop
Инструменты ретуширования в графическом редакторе Photoshop CSS. Источники информации. Подключение CSS к HTML. Таблицы стилей для различных устройств просмотра. Селекторы и комбинаторы
CSS. Источники информации. Подключение CSS к HTML. Таблицы стилей для различных устройств просмотра. Селекторы и комбинаторы Комп'ютерні віруси
Комп'ютерні віруси Кодирование и декодирование информации
Кодирование и декодирование информации Агрегирование каналов
Агрегирование каналов Медиа-карта
Медиа-карта Разработка программного обеспечения
Разработка программного обеспечения Модель данных. I, II и III нормальные формы
Модель данных. I, II и III нормальные формы Vue JS The Progressive JavaScript Framework
Vue JS The Progressive JavaScript Framework Windows Presentation Foundation (WPF) — система для построения клиентских приложений Windows
Windows Presentation Foundation (WPF) — система для построения клиентских приложений Windows Написання програм
Написання програм Модели представления знаний в интеллектуальных системах
Модели представления знаний в интеллектуальных системах Построение и анализ алгоритмов. Минимальное остовное дерево. (Лекция 6.1)
Построение и анализ алгоритмов. Минимальное остовное дерево. (Лекция 6.1) Диаграмма композитной структуры. Диаграмма пакетов. Диаграмма объектов
Диаграмма композитной структуры. Диаграмма пакетов. Диаграмма объектов Линейные алгоритмы обработки целочисленных данных
Линейные алгоритмы обработки целочисленных данных Іскерлік графика
Іскерлік графика Основы технической диагностики
Основы технической диагностики OOP PHP. Class object function construct
OOP PHP. Class object function construct Формула нахождение объема сообщения
Формула нахождение объема сообщения Концептуальное и даталогическое проектирование баз данных
Концептуальное и даталогическое проектирование баз данных Готовим инфографику
Готовим инфографику