- Методы анализа данных

Содержание
- 2. Раздел 1. Введение в анализ данных 1.1 Информация. Данные. Знания 1.2 Шкалы измерений 1.3 Классификация данных
- 3. Раздел 1. Введение в анализ данных 2.1 MS Excel как инструмент статистического анализа 2.2 Корреляционный анализ
- 4. Раздел 1. Введение в анализ данных 3.1 Технология баз данных 3.2 OLTP-системы. Требования к OLTP-системам 3.3
- 5. Раздел 2. Интеллектуальный анализ данных 1.1 Сравнение Data Mining с другими методами анализа данных 1.2 Сфера
- 6. Раздел 2. Интеллектуальный анализ данных 2.1 Задача классификации 2.2 Задача прогнозирования 2.3 Метод k-ближайших соседей 2.4
- 7. Раздел 2. Интеллектуальный анализ данных 3.1 Задача кластеризации 3.2 Кластеризация методом k-средних 3.3 Метод главных компонент
- 8. Раздел 2. Интеллектуальный анализ данных 4.1 Ассоциативные правила 4.2 Методы поиска ассоциативных правил 4.3 Приложения с
- 9. Раздел 2. Интеллектуальный анализ данных 5.1 Задачи, которые ставятся перед нейронными сетями 5.2 Как работает нейронная
- 10. Раздел 2. Интеллектуальный анализ данных 6.1 Характеристики Big Data 6.2 Источники больших данных 6.3 Методы и
- 11. Раздел 2. Интеллектуальный анализ данных 7.1 Лабораторная работа 1.Знакомство с аналитической платформой Deductor Studio (2 часа)
- 12. 1.1. Информация. Данные. Знания Каждое из этих понятий имеет свое собственное определение Информация – это любые
- 13. 1.2 Шкалы измерений Данные получаются в результате измерений. Существует пять типов шкал измерений: номинальная, порядковая, интервальная,
- 14. 1.2 Шкалы измерений Данные получаются в результате измерений. Существует пять типов шкал измерений: номинальная, порядковая, интервальная,
- 15. 1.3 Классификация данных Данные могут являться числовыми либо символьными. Числовые данные, в свою очередь, могут быть
- 16. 1.3 Классификация данных По критерию постоянства своих значений в ходе решения задачи данные могут быть: •
- 17. 1.3 Классификация данных Следует различать данные за период и точечные данные. Эти различия важны при проектировании
- 18. 1.3 Классификация данных Данные бывают первичными и вторичными. Вторичные данные - это данные, которые являются результатом
- 19. 1.4 Подготовка данных Если качество данных низкое, то результаты даже самого изощренного анализа окажутся не очень-то
- 20. 1.4 Подготовка данных Типы переменных Есть 4 главных типа переменных: Бинарная. Это простейший тип переменных только
- 21. 1.4 Подготовка данных Выбор переменных В нашем первоначальном наборе данных (генеральная совокупность) может быть много разных
- 22. 1.4 Подготовка данных Конструирование признаков Иногда хорошие переменные требуется сконструировать. Например, если мы хотим предсказать, кто
- 23. 1.4 Подготовка данных Неполные данные Мы не всегда располагаем полными данными. Иногда значения каких-то признаков бывает
- 24. 1.4 Подготовка данных Подготовка данных является первым шагом в исследовании Data Science. Следующие шаги: 2) –
- 25. 3.1 Технология баз данных Для решения задач анализа данных и поиска решений необходимо накопление и хранение
- 26. 3.1 Технология баз данных Транзакция – это последовательность операций над БД, которую СУБД рассматривает как единое
- 27. 3.1 Технология баз данных Общая идея хранилищ данных заключается в разделении БД для OLTP-систем и для
- 28. 3.1 Технология баз данных Для анализа информации наиболее удобной является многомерная модель или гиперкуб, ребрами которых
- 29. 3.1 Технология баз данных С концепцией многомерного анализа тесно связан оперативный анализ, который выполняется средствами OLAP-систем.
- 30. 1.1. Сравнение Data Mining с другими методами анализа данных Data Mining - это процесс обнаружения в
- 31. 1.2 Сфера применения Data Mining Data Mining представляет большую ценность для руководителей и аналитиков в их
- 32. 1.3 Перспективы технологии Data Mining Потенциал Data Mining дает "зеленый свет" для расширения границ применения технологии.
- 33. 1.4 Задачи Data Mining Методы Data Mining помогают решить многие задачи, с которыми сталкивается аналитик. Задача
- 34. 1.4 Задачи Data Mining Методы Data Mining помогают решить многие задачи, с которыми сталкивается аналитик. При
- 35. 1.4 Задачи Data Mining По способам решения задачи разделяют на supervised learning (обучение с учителем) и
- 36. 2.1 Задача классификации В Data Mining задачу классификации рассматривают как задачу определения значения одного из параметров
- 37. 2.1 Задача классификации Для получения максимально точной функции к обучающей выборке предъявляются такие требования: . -
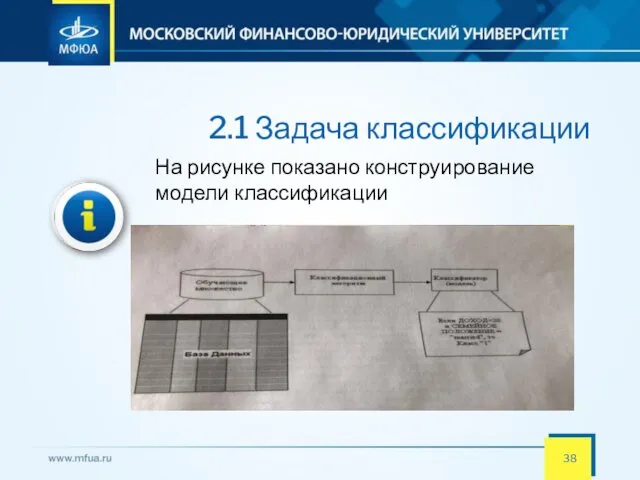
- 38. 2.1 Задача классификации На рисунке показано конструирование модели классификации
- 39. 2.1 Задача классификации На втором этапе построенную модель применяют к анализируемым объектам. Использование модели на рисунке:
- 40. 2.1 Задача классификации Оценивание классификационных методов следует проводить, исходя из следующих характеристик:. Скорость характеризует время, которое
- 41. 2.2 Задача прогнозирования Задачи прогнозирования решаются в самых разнообразных областях человеческой деятельности, таких как наука, экономика,
- 42. 2.2 Задача прогнозирования Перед началом прогнозирования необходимо ответить на следующие вопросы: Что нужно прогнозировать? Определяем переменные,
- 43. 2.2 Задача прогнозирования Виды прогнозов. Прогноз может быть краткосрочным, среднесрочным и долгосрочным. Краткосрочный прогноз представляет собой
- 44. 2.2 Задача прогнозирования Прогнозирование сходно с задачей классификации. Многие методы Data Mining используются для решения задач
- 45. 2.3 Метод k-ближайших соседей Метод "ближайшего соседа" (“Nearest Neighbour") относится к классу методов, работа которых основывается
- 46. 2.3 Метод k-ближайших соседей При таком подходе используется термин "k-ближайших соседей" ("k-Nearest Neighbors"). Метод k-ближайших соседей
- 47. 2.3 Метод k-ближайших соседей Пример. Пять ближайших соседей (k = 5) Элемент данных в середине будет
- 48. 2.3 Метод k-ближайших соседей Данный метод по своей сути относится к категории "обучение без учителя", то
- 49. 2.3 Метод k-ближайших соседей Пример Сравнение моделей настройки при различных значениях k.
- 50. 2.3 Метод k-ближайших соседей Поскольку не всегда удобно хранить все данные, иногда хранится только множество "типичных"
- 51. 2.3 Метод k-ближайших соседей Подход, основанный на прецедентах, условно можно поделить на следующие этапы: . •
- 52. 2.3 Метод k-ближайших соседей Метод, основанный на прецедентах, представляет собой такой метод анализа данных, который делает
- 53. 2.3 Метод k-ближайших соседей Преимущества метода . • Простота использования полученных результатов. • Решения не уникальны
- 54. 2.3 Метод k-ближайших соседей Недостатки метода "ближайшего соседа" . • Данный метод не создает каких-либо моделей
- 55. 2.3 Метод k-ближайших соседей Недостатки метода "ближайшего соседа" . • При использовании метода возникает необходимость полного
- 56. 2.4 Метод опорных векторов Метод опорных векторов (Support Vector Machine - SVM) относится к группе граничных
- 57. 2.4 Метод опорных векторов В чем же состоит идея метода опорных векторов? Давайте, сначала рассмотрим очень
- 58. 2.4 Метод опорных векторов Рассмотрим упрощенный случай. Пусть точки, принадлежащие разным классам, можно разделить с помощью
- 59. 2.4 Метод опорных векторов Очевидный способ решения задачи: провести прямую так, чтобы все точки одного класса
- 60. 2.4 Метод опорных векторов Какую из прямых выбрать? Интуитивно понятно, что нам бы хотелось прямую где-нибудь
- 61. 2.4 Метод опорных векторов В реальной жизни, к сожалению, данные далеко не всегда можно разделить линейно.
- 62. 2.4 Метод опорных векторов Существенное достоинство метода опорных векторов – способность обнаруживать в данных криволинейные паттерны.
- 63. 2.4 Метод опорных векторов Пример: обнаружение сердечно-сосудистых заболеваний. Пациентов американской клиники попросили делать упражнения, а затем
- 64. 2.4 Метод опорных векторов Метод опорных векторов является адаптивным и быстрым инструментом. Тем не менее, он
- 65. 2.4 Метод опорных векторов Метод опорных векторов является адаптивным и быстрым инструментом. Тем не менее, он
- 66. 2.5 Метод деревьев решений Метод деревьев решений (decision trees) является одним из наиболее популярных методов решения
- 67. 2.5 Метод деревьев решений В наиболее простом виде дерево решений - это способ представления правил в
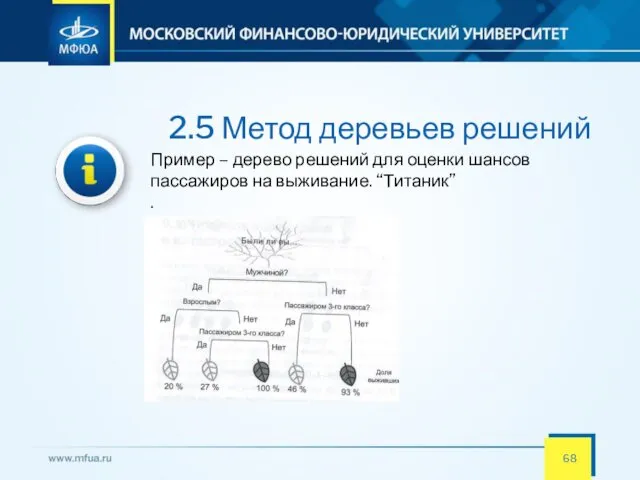
- 68. 2.5 Метод деревьев решений Пример – дерево решений для оценки шансов пассажиров на выживание. “Титаник” .
- 69. 2.5 Метод деревьев решений В обычных деревьях решений есть только два возможных ответа на каждом ветвлении.
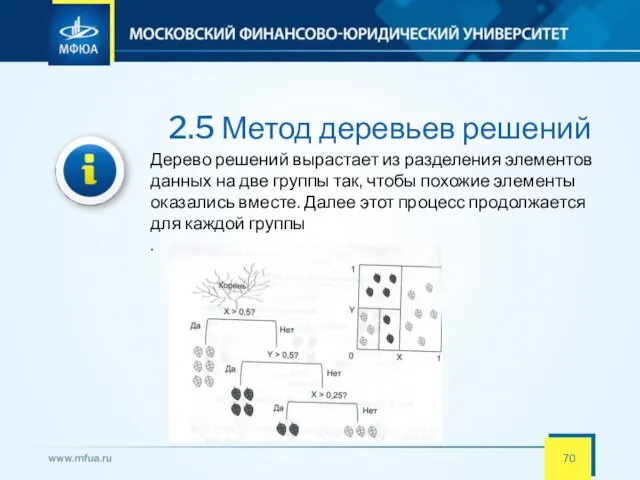
- 70. 2.5 Метод деревьев решений Дерево решений вырастает из разделения элементов данных на две группы так, чтобы
- 71. 2.5 Метод деревьев решений Метод деревьев решений часто называют "наивным" подходом. Но благодаря целому ряду преимуществ,
- 72. 2.5 Метод деревьев решений Метод деревьев решений часто называют "наивным" подходом. Но благодаря целому ряду преимуществ,
- 73. 2.5 Метод деревьев решений Метод деревьев решений часто называют "наивным" подходом. Но благодаря целому ряду преимуществ,
- 74. 2.5 Метод деревьев решений Метод деревьев решений часто называют "наивным" подходом. Но благодаря целому ряду преимуществ,
- 75. 2.5 Метод деревьев решений Несмотря на легкость интерпретации, деревья решений также имеют свои недостатки. Нестабильность. Поскольку
- 76. 2.6 Случайные леса Случайный лес – это ансамбль деревьев решений Ансамблирование – это способ комбинирования моделей
- 77. 2.6 Случайные леса Случайный лес – это ансамбль деревьев решений Ансамблирование – это способ комбинирования моделей
- 78. 2.6 Случайные леса Пример: предсказание криминальной активности Открытая сводка от полицейского управления Сан-Франциско представляет информацию о
- 79. 2.6 Случайные леса Пример: предсказание криминальной активности Были созданы 1000 возможных деревьев решений, которые учитывали данные
- 80. 2.6 Случайные леса Пример: предсказание криминальной активности Модель случайного леса также позволяет увидеть, какие переменные сыграли
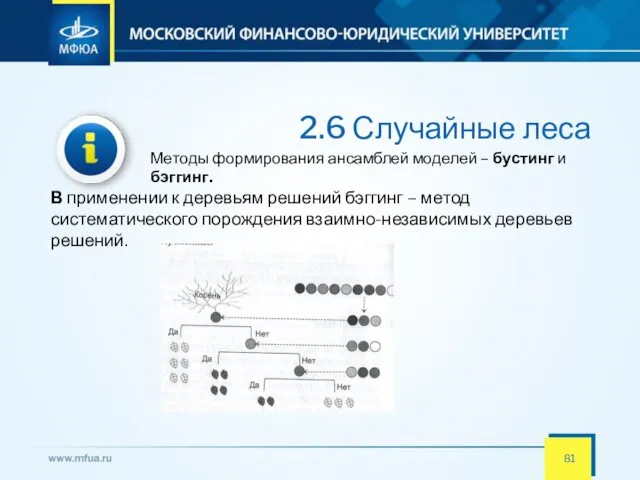
- 81. 2.6 Случайные леса Методы формирования ансамблей моделей – бустинг и бэггинг. В применении к деревьям решений
- 82. 2.6 Случайные леса Ограничения на модель Случайные леса считаются черными ящиками, так как они состоят из
- 83. 3.1 Задача кластеризации Сравним задачи классификации и задачи кластеризации
- 84. 3.1 Задача кластеризации Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и пересекающимися (overlapping) В результате
- 85. 3.1 Задача кластеризации Термин «кластерный анализ» (впервые ввел Tryon в 1939 г.) в действительности включает в
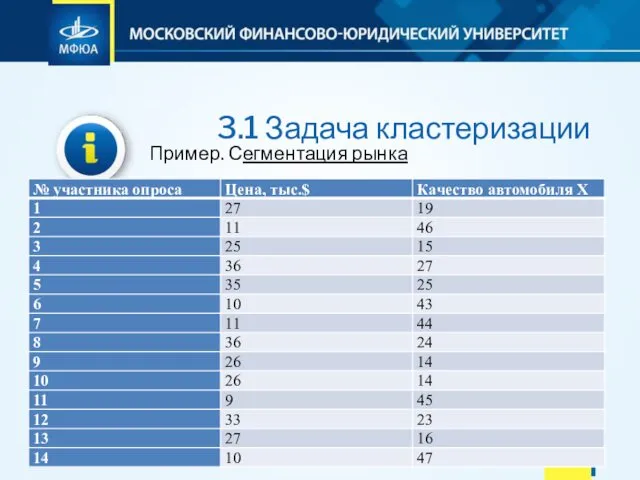
- 86. 3.1 Задача кластеризации Пример. Сегментация рынка Можно кластеризовать потребителей по двум параметрам — цены и качества.
- 87. 3.1 Задача кластеризации Пример. Сегментация рынка
- 88. 3.1 Задача кластеризации Если посмотреть на диаграмму (диаграмма рассеяния) «цена — качество», представленную на рисунке, то
- 89. 3.1 Задача кластеризации В реальной жизни кластеры, различимые глазом, встречаются нечасто, гораздо чаще бывают ситуации, когда
- 90. 3.1 Задача кластеризации Для проведения кластерного анализа, кроме сбора данных, необходимо определить две вещи: на какое
- 91. 3.1 Задача кластеризации Методы кластерного анализа можно разделить на две группы: • иерархические; • неиерархические. Каждая
- 92. 3.1 Задача кластеризации Иерархические методы кластерного анализа Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров
- 93. 3.1 Задача кластеризации Иерархические методы кластерного анализа Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) Эти методы
- 94. 3.1 Задача кластеризации Иерархические методы кластерного анализа Иерархические методы кластеризации различаются правилами построения кластеров. В качестве
- 95. 3.1 Задача кластеризации Неиерархические методы кластерного анализа При большом количестве наблюдений используют неиерархические методы, которые представляют
- 96. 3.2 Кластеризация методом k-средних Наиболее распространен среди неиерархических методов алгоритм k-средних, также называемый быстрым кластерным анализом.
- 97. 3.2 Кластеризация методом k-средних Пример. Кинопредпочтения зрителей Пользователей Facebook пригласили пройти опрос, чтобы распределить их, исходя
- 98. 3.2 Кластеризация методом k-средних Пример. Кинопредпочтения зрителей Суммарные очки черт характера были соотнесы с информацией о
- 99. 3.2 Кластеризация методом k-средних При определении кластеров нужно ответить на два вопроса: Сколько кластеров существует? Что
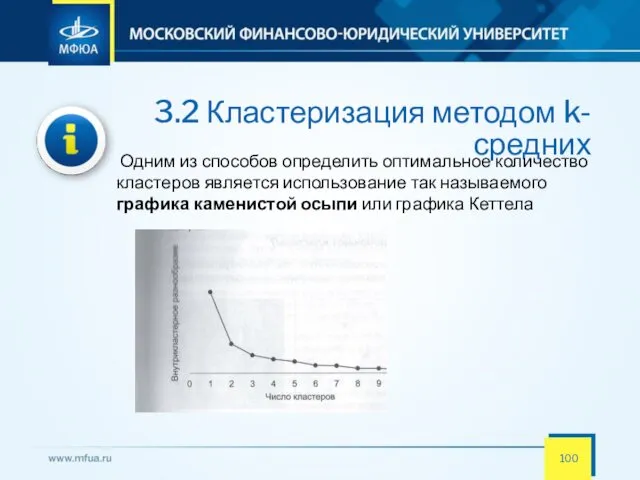
- 100. 3.2 Кластеризация методом k-средних Одним из способов определить оптимальное количество кластеров является использование так называемого графика
- 101. 3.2 Кластеризация методом k-средних Данные распределяются по кластерам в итеративном процессе
- 102. 3.2 Кластеризация методом k-средних Хотя кластеризация методом k-средних очень полезна, у нее есть ограничения Каждый элемент
- 103. 3.3 Метод главных компонент Метод главных компонент – это способ нахождения основополагающих переменных (главные компоненты), которые
- 104. 3.3 Метод главных компонент Пример. Диетология. Как лучше всего дифференцировать пищевые продукты?
- 105. 3.3 Метод главных компонент Пример. Диетология. Как лучше всего дифференцировать пищевые продукты?
- 106. 3.3 Метод главных компонент Пример. Диетология. Как лучше всего дифференцировать пищевые продукты?
- 107. 3.3 Метод главных компонент Пример. Диетология. Как лучше всего дифференцировать пищевые продукты?
- 108. 3.3 Метод главных компонент Метод главных компонент – это полезный способ анализа наборов данных с несколькими
- 109. 4.1 Ассоциативные правила Целью поиска ассоциативных правил (association rule) является нахождение закономерностей между связанными событиями в
- 110. 4.1 Ассоциативные правила Понимание закономерностей рыночной корзины поможет увеличить продажи несколькими способами Например, если пара товаров
- 111. 4.1 Ассоциативные правила Регистрируя все бизнес-операции в течение всего времени своей деятельности, торговые компании накапливают огромные
- 112. 4.1 Ассоциативные правила Пример транзакционной базы данных, состоящей из покупательских транзакций
- 113. 4.1 Ассоциативные правила Существуют три основные меры для определения ассоциаций: поддержка, достоверность и лифт Имеется транзакционная
- 114. 4.1 Ассоциативные правила Поддержкой называют количество или процент транзакций, содержащих определенный набор данных. Поддержка показывает то,
- 115. 4.1 Ассоциативные правила Достоверность показывает, как часто товар Y появляется вместе с товаром X, что выражается
- 116. 4.1 Ассоциативные правила Лифт отражает то, как часто товары X и Y появляются вместе, одновременно учитывая,
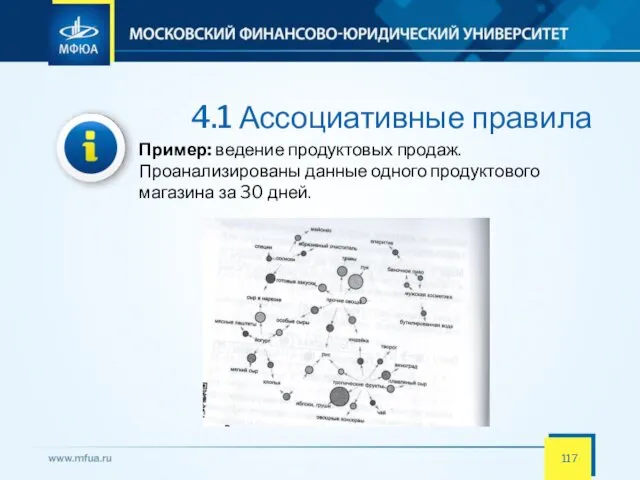
- 117. 4.1 Ассоциативные правила Пример: ведение продуктовых продаж. Проанализированы данные одного продуктового магазина за 30 дней.
- 118. 4.2 Методы поиска ассоциативных правил Перечислим некоторые методы и алгоритмы Алгоритм AIS. Первый алгоритм поиска ассоциативных
- 119. 4.2 Методы поиска ассоциативных правил Для улучшения работы представленных выше алгоритмов был предложен алгоритм Apriori Принцип
- 120. 4.2 Методы поиска ассоциативных правил Пример использования алгоритма Apriori
- 121. 4.3 Приложения с применением ассоциативных правил Часто встречающиеся приложения с применением ассоциативных правил: • розничная торговля:
- 122. 4.4 Ограничение методов поиска ассоциативных правил Ограничения существуют несмотря на большой диапазон использования • требует долгих
- 123. Лабораторная работа. Знакомство с платформой Deductor Целью выполнения данной лабораторной работы является: получение первоначальных сведений о
- 124. Лабораторная работа. Знакомство с платформой Deductor Теоретическая часть АП «Deductor» применима для решения задач распознавания и
- 125. Лабораторная работа. Знакомство с платформой Deductor Задачи, решаемые АП: Системы корпоративной отчетности. Готовое хранилище данных и
- 126. Лабораторная работа. Знакомство с платформой Deductor Задачи, решаемые АП: Анализ тенденций и закономерностей, планирование, ранжирование. Простота
- 127. Лабораторная работа. Знакомство с платформой Deductor Задачи, решаемые АП: Управление рисками. Реализованные в системе алгоритмы дают
- 128. Лабораторная работа. Знакомство с платформой Deductor Задачи, решаемые АП: Диагностика. Механизмы анализа, имеющиеся в системе Deductor,
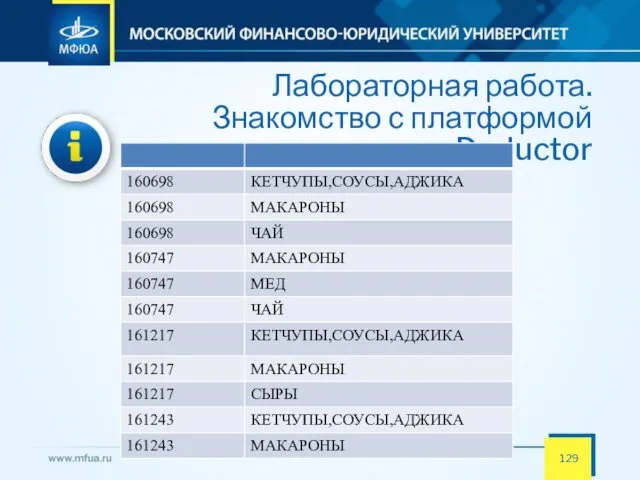
- 129. Лабораторная работа. Знакомство с платформой Deductor Задачи, решаемые АП:
- 130. 5.1 Задачи, которые ставятся перед нейронными сетями Начало нейронным сетям как инструменту анализа данных было положено
- 131. 5.1 Задачи, которые ставятся перед нейронными сетями По мнению Anil K. Jain из Мичиганского государственного университета
- 132. 5.1 Задачи, которые ставятся перед нейронными сетями По мнению Anil K. Jain из Мичиганского государственного университета
- 133. 5.1 Задачи, которые ставятся перед нейронными сетями По мнению Anil K. Jain из Мичиганского государственного университета
- 134. 5.2 Как работает нейронная сеть Предположим, что нам даются наборы чисел (входные векторы), и для каждого
- 135. 5.2 Как работает нейронная сеть Затем нам предъявляют уже новые данные: значения финансовых показателей по сегодняшний
- 136. 5.2 Как работает нейронная сеть Как действует в этой ситуации нейронная сеть? Элементарная операция, которую она
- 137. 5.2 Как работает нейронная сеть Пример распознавания рукописных цифр. Здесь нейронная сеть использует несколько слоев нейронов,
- 138. 5.2 Как работает нейронная сеть Чтобы построить прогноз, нейроны, в свою очередь, должны быть активированы на
- 139. 5.3 Общая схема анализа данных с помощью нейронных сетей Общая схема анализа данных с помощью нейронных
- 140. 5.3 Общая схема анализа данных с помощью нейронных сетей Общая схема анализа данных с помощью нейронных
- 141. 6.1 Характеристики Big Data Big Data — обозначение структурированных и неструктурированных данных огромных объёмов и значительного
- 142. 6.1 Характеристики Big Data В качестве определяющих характеристик для больших данных традиционно выделяют «три V»: Объём
- 143. 6.1 Характеристики Big Data Набор признаков VVV (volume, velocity, variety) изначально выработан Meta Group в 2001
- 144. 6.2 Источники больших данных Есть классические источники данных. Есть источники данных, которые образовались в последнее время
- 145. 6.2 Источники больших данных Есть классические источники данных. Есть источники данных, которые образовались в последнее время
- 146. 6.3 Методы и техники анализа, применимые к большим данным Перечислим эти методы и техники: ► методы
- 147. 6.3 Методы и техники анализа, применимые к большим данным Перечислим эти методы и техники: ► машинное
- 148. 6.3 Методы и техники анализа, применимые к большим данным Перечислим эти методы и техники: ► имитационное
- 149. 6.4 Технологии. Аппаратные решения Существует ряд аппаратно-программных комплексов, предоставляющих предконфигурированные решения для обработки больших данных: Aster
- 150. 6.4 Технологии. Аппаратные решения К решениям из области больших данных иногда относят такие решения, несмотря на
- 151. 6.4 Технологии. Аппаратные решения Иногда к решениям для больших данных относят и аппаратно-программные комплексы на основе
- 152. 6.4 Технологии. Аппаратные решения Аппаратные решения DAS — систем хранения данных, напрямую присоединённых к узлам —
- 154. Скачать презентацию

Раздел 1. Введение в анализ данных
1.1 Информация. Данные. Знания
1.2 Шкалы измерений
1.3
Раздел 1. Введение в анализ данных
1.1 Информация. Данные. Знания
1.2 Шкалы измерений
1.3

Раздел 1. Введение в анализ данных
2.1 MS Excel как инструмент статистического
Раздел 1. Введение в анализ данных
2.1 MS Excel как инструмент статистического

Раздел 1. Введение в анализ данных
3.1 Технология баз данных
3.2 OLTP-системы. Требования
Раздел 1. Введение в анализ данных
3.1 Технология баз данных
3.2 OLTP-системы. Требования

Раздел 2. Интеллектуальный анализ данных
1.1 Сравнение Data Mining с другими методами
Раздел 2. Интеллектуальный анализ данных
1.1 Сравнение Data Mining с другими методами

Раздел 2. Интеллектуальный анализ данных
2.1 Задача классификации
2.2 Задача прогнозирования
2.3 Метод k-ближайших
Раздел 2. Интеллектуальный анализ данных
2.1 Задача классификации
2.2 Задача прогнозирования
2.3 Метод k-ближайших

Раздел 2. Интеллектуальный анализ данных
3.1 Задача кластеризации
3.2 Кластеризация методом k-средних
3.3 Метод
Раздел 2. Интеллектуальный анализ данных
3.1 Задача кластеризации
3.2 Кластеризация методом k-средних
3.3 Метод

Раздел 2. Интеллектуальный анализ данных
4.1 Ассоциативные правила
4.2 Методы поиска ассоциативных правил
4.3
Раздел 2. Интеллектуальный анализ данных
4.1 Ассоциативные правила
4.2 Методы поиска ассоциативных правил
4.3

Раздел 2. Интеллектуальный анализ данных
5.1 Задачи, которые ставятся перед нейронными сетями
5.2
Раздел 2. Интеллектуальный анализ данных
5.1 Задачи, которые ставятся перед нейронными сетями
5.2

Раздел 2. Интеллектуальный анализ данных
6.1 Характеристики Big Data
6.2 Источники больших данных
6.3
Раздел 2. Интеллектуальный анализ данных
6.1 Характеристики Big Data
6.2 Источники больших данных
6.3

Раздел 2. Интеллектуальный анализ данных
7.1 Лабораторная работа 1.Знакомство с аналитической платформой
Раздел 2. Интеллектуальный анализ данных
7.1 Лабораторная работа 1.Знакомство с аналитической платформой

1.1. Информация. Данные. Знания
Каждое из этих понятий имеет свое собственное определение
Информация
1.1. Информация. Данные. Знания
Каждое из этих понятий имеет свое собственное определение
Информация

1.2 Шкалы измерений
Данные получаются в результате измерений.
Существует пять типов шкал
1.2 Шкалы измерений
Данные получаются в результате измерений.
Существует пять типов шкал

1.2 Шкалы измерений
Данные получаются в результате измерений.
Существует пять типов шкал
1.2 Шкалы измерений
Данные получаются в результате измерений.
Существует пять типов шкал

1.3 Классификация данных
Данные могут являться числовыми либо символьными.
Числовые данные, в свою
1.3 Классификация данных
Данные могут являться числовыми либо символьными.
Числовые данные, в свою

1.3 Классификация данных
По критерию постоянства своих значений в ходе решения задачи
1.3 Классификация данных
По критерию постоянства своих значений в ходе решения задачи

1.3 Классификация данных
Следует различать данные за период и точечные данные. Эти
1.3 Классификация данных
Следует различать данные за период и точечные данные. Эти

1.3 Классификация данных
Данные бывают первичными и вторичными.
Вторичные данные - это
1.3 Классификация данных
Данные бывают первичными и вторичными.
Вторичные данные - это

1.4 Подготовка данных
Если качество данных низкое, то результаты даже самого изощренного
1.4 Подготовка данных
Если качество данных низкое, то результаты даже самого изощренного

1.4 Подготовка данных
Типы переменных
Есть 4 главных типа переменных:
Бинарная. Это простейший тип
1.4 Подготовка данных
Типы переменных
Есть 4 главных типа переменных:
Бинарная. Это простейший тип

1.4 Подготовка данных
Выбор переменных
В нашем первоначальном наборе данных (генеральная совокупность) может
1.4 Подготовка данных
Выбор переменных
В нашем первоначальном наборе данных (генеральная совокупность) может

1.4 Подготовка данных
Конструирование признаков
Иногда хорошие переменные требуется сконструировать. Например, если мы
1.4 Подготовка данных
Конструирование признаков
Иногда хорошие переменные требуется сконструировать. Например, если мы

1.4 Подготовка данных
Неполные данные
Мы не всегда располагаем полными данными. Иногда значения
1.4 Подготовка данных
Неполные данные
Мы не всегда располагаем полными данными. Иногда значения

1.4 Подготовка данных
Подготовка данных является первым шагом в исследовании Data Science.
Следующие
1.4 Подготовка данных
Подготовка данных является первым шагом в исследовании Data Science.
Следующие

3.1 Технология баз данных
Для решения задач анализа данных и поиска решений
3.1 Технология баз данных
Для решения задач анализа данных и поиска решений

3.1 Технология баз данных
Транзакция – это последовательность операций над БД, которую
3.1 Технология баз данных
Транзакция – это последовательность операций над БД, которую

3.1 Технология баз данных
Общая идея хранилищ данных заключается в разделении БД
3.1 Технология баз данных
Общая идея хранилищ данных заключается в разделении БД

3.1 Технология баз данных
Для анализа информации наиболее удобной является многомерная модель
3.1 Технология баз данных
Для анализа информации наиболее удобной является многомерная модель

3.1 Технология баз данных
С концепцией многомерного анализа тесно связан оперативный анализ,
3.1 Технология баз данных
С концепцией многомерного анализа тесно связан оперативный анализ,

1.1. Сравнение Data Mining с другими методами анализа данных
Data Mining -
1.1. Сравнение Data Mining с другими методами анализа данных
Data Mining -

1.2 Сфера применения Data Mining
Data Mining представляет большую ценность для руководителей
1.2 Сфера применения Data Mining
Data Mining представляет большую ценность для руководителей

1.3 Перспективы технологии Data Mining
Потенциал Data Mining дает "зеленый свет" для
1.3 Перспективы технологии Data Mining
Потенциал Data Mining дает "зеленый свет" для

1.4 Задачи Data Mining
Методы Data Mining помогают решить многие задачи, с
1.4 Задачи Data Mining
Методы Data Mining помогают решить многие задачи, с

1.4 Задачи Data Mining
Методы Data Mining помогают решить многие задачи, с
1.4 Задачи Data Mining
Методы Data Mining помогают решить многие задачи, с

1.4 Задачи Data Mining
По способам решения задачи разделяют на supervised learning
1.4 Задачи Data Mining
По способам решения задачи разделяют на supervised learning

2.1 Задача классификации
В Data Mining задачу классификации рассматривают как задачу определения
2.1 Задача классификации
В Data Mining задачу классификации рассматривают как задачу определения

2.1 Задача классификации
Для получения максимально точной функции к обучающей выборке предъявляются
2.1 Задача классификации
Для получения максимально точной функции к обучающей выборке предъявляются
2.1 Задача классификации
На рисунке показано конструирование модели классификации
2.1 Задача классификации
На рисунке показано конструирование модели классификации

2.1 Задача классификации
На втором этапе построенную модель применяют к анализируемым объектам.
Использование
2.1 Задача классификации
На втором этапе построенную модель применяют к анализируемым объектам.
Использование

2.1 Задача классификации
Оценивание классификационных методов следует проводить, исходя из следующих характеристик:.
2.1 Задача классификации
Оценивание классификационных методов следует проводить, исходя из следующих характеристик:.

2.2 Задача прогнозирования
Задачи прогнозирования решаются в самых разнообразных областях человеческой деятельности,
2.2 Задача прогнозирования
Задачи прогнозирования решаются в самых разнообразных областях человеческой деятельности,

2.2 Задача прогнозирования
Перед началом прогнозирования необходимо ответить на следующие вопросы:
Что нужно
2.2 Задача прогнозирования
Перед началом прогнозирования необходимо ответить на следующие вопросы:
Что нужно

2.2 Задача прогнозирования
Виды прогнозов. Прогноз может быть краткосрочным, среднесрочным и долгосрочным.
Краткосрочный
2.2 Задача прогнозирования
Виды прогнозов. Прогноз может быть краткосрочным, среднесрочным и долгосрочным.
Краткосрочный

2.2 Задача прогнозирования
Прогнозирование сходно с задачей классификации. Многие методы Data Mining
2.2 Задача прогнозирования
Прогнозирование сходно с задачей классификации. Многие методы Data Mining

2.3 Метод k-ближайших соседей
Метод "ближайшего соседа" (“Nearest Neighbour") относится к классу
2.3 Метод k-ближайших соседей
Метод "ближайшего соседа" (“Nearest Neighbour") относится к классу

2.3 Метод k-ближайших соседей
При таком подходе используется термин "k-ближайших соседей" ("k-Nearest
2.3 Метод k-ближайших соседей
При таком подходе используется термин "k-ближайших соседей" ("k-Nearest

2.3 Метод k-ближайших соседей
Пример. Пять ближайших соседей (k = 5)
Элемент данных
2.3 Метод k-ближайших соседей
Пример. Пять ближайших соседей (k = 5)
Элемент данных

2.3 Метод k-ближайших соседей
Данный метод по своей сути относится к категории
2.3 Метод k-ближайших соседей
Данный метод по своей сути относится к категории

2.3 Метод k-ближайших соседей
Пример
Сравнение моделей настройки при различных значениях k.
2.3 Метод k-ближайших соседей
Пример
Сравнение моделей настройки при различных значениях k.

2.3 Метод k-ближайших соседей
Поскольку не всегда удобно хранить все данные, иногда
2.3 Метод k-ближайших соседей
Поскольку не всегда удобно хранить все данные, иногда

2.3 Метод k-ближайших соседей
Подход, основанный на прецедентах, условно можно поделить на
2.3 Метод k-ближайших соседей
Подход, основанный на прецедентах, условно можно поделить на

2.3 Метод k-ближайших соседей
Метод, основанный на прецедентах, представляет собой такой метод
2.3 Метод k-ближайших соседей
Метод, основанный на прецедентах, представляет собой такой метод

2.3 Метод k-ближайших соседей
Преимущества метода
.
• Простота использования полученных результатов.
•
2.3 Метод k-ближайших соседей
Преимущества метода
.
• Простота использования полученных результатов.
•

2.3 Метод k-ближайших соседей
Недостатки метода "ближайшего соседа"
.
• Данный метод не
2.3 Метод k-ближайших соседей
Недостатки метода "ближайшего соседа"
.
• Данный метод не

2.3 Метод k-ближайших соседей
Недостатки метода "ближайшего соседа"
.
• При использовании метода
2.3 Метод k-ближайших соседей
Недостатки метода "ближайшего соседа"
.
• При использовании метода

2.4 Метод опорных векторов
Метод опорных векторов (Support Vector Machine - SVM)
2.4 Метод опорных векторов
Метод опорных векторов (Support Vector Machine - SVM)

2.4 Метод опорных векторов
В чем же состоит идея метода опорных векторов?
2.4 Метод опорных векторов
В чем же состоит идея метода опорных векторов?

2.4 Метод опорных векторов
Рассмотрим упрощенный случай. Пусть точки, принадлежащие разным классам,
2.4 Метод опорных векторов
Рассмотрим упрощенный случай. Пусть точки, принадлежащие разным классам,

2.4 Метод опорных векторов
Очевидный способ решения задачи: провести прямую так, чтобы
2.4 Метод опорных векторов
Очевидный способ решения задачи: провести прямую так, чтобы

2.4 Метод опорных векторов
Какую из прямых выбрать? Интуитивно понятно, что нам
2.4 Метод опорных векторов
Какую из прямых выбрать? Интуитивно понятно, что нам

2.4 Метод опорных векторов
В реальной жизни, к сожалению, данные далеко не
2.4 Метод опорных векторов
В реальной жизни, к сожалению, данные далеко не

2.4 Метод опорных векторов
Существенное достоинство метода опорных векторов – способность обнаруживать
2.4 Метод опорных векторов
Существенное достоинство метода опорных векторов – способность обнаруживать

2.4 Метод опорных векторов
Пример: обнаружение сердечно-сосудистых заболеваний.
Пациентов американской клиники попросили делать
2.4 Метод опорных векторов
Пример: обнаружение сердечно-сосудистых заболеваний.
Пациентов американской клиники попросили делать

2.4 Метод опорных векторов
Метод опорных векторов является адаптивным и быстрым инструментом.
2.4 Метод опорных векторов
Метод опорных векторов является адаптивным и быстрым инструментом.

2.4 Метод опорных векторов
Метод опорных векторов является адаптивным и быстрым инструментом.
2.4 Метод опорных векторов
Метод опорных векторов является адаптивным и быстрым инструментом.

2.5 Метод деревьев решений
Метод деревьев решений (decision trees) является одним из
2.5 Метод деревьев решений
Метод деревьев решений (decision trees) является одним из

2.5 Метод деревьев решений
В наиболее простом виде дерево решений - это
2.5 Метод деревьев решений
В наиболее простом виде дерево решений - это
2.5 Метод деревьев решений
Пример – дерево решений для оценки шансов пассажиров
2.5 Метод деревьев решений
Пример – дерево решений для оценки шансов пассажиров

2.5 Метод деревьев решений
В обычных деревьях решений есть только два возможных
2.5 Метод деревьев решений
В обычных деревьях решений есть только два возможных
2.5 Метод деревьев решений
Дерево решений вырастает из разделения элементов данных на
2.5 Метод деревьев решений
Дерево решений вырастает из разделения элементов данных на

2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но
2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но

2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но
2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но

2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но
2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но

2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но
2.5 Метод деревьев решений
Метод деревьев решений часто называют "наивным" подходом. Но

2.5 Метод деревьев решений
Несмотря на легкость интерпретации, деревья решений также имеют
2.5 Метод деревьев решений
Несмотря на легкость интерпретации, деревья решений также имеют

2.6 Случайные леса
Случайный лес – это ансамбль деревьев решений
Ансамблирование – это
2.6 Случайные леса
Случайный лес – это ансамбль деревьев решений
Ансамблирование – это

2.6 Случайные леса
Случайный лес – это ансамбль деревьев решений
Ансамблирование – это
2.6 Случайные леса
Случайный лес – это ансамбль деревьев решений
Ансамблирование – это

2.6 Случайные леса
Пример: предсказание криминальной активности
Открытая сводка от полицейского управления Сан-Франциско
2.6 Случайные леса
Пример: предсказание криминальной активности
Открытая сводка от полицейского управления Сан-Франциско

2.6 Случайные леса
Пример: предсказание криминальной активности
Были созданы 1000 возможных деревьев решений,
2.6 Случайные леса
Пример: предсказание криминальной активности
Были созданы 1000 возможных деревьев решений,

2.6 Случайные леса
Пример: предсказание криминальной активности
Модель случайного леса также позволяет увидеть,
2.6 Случайные леса
Пример: предсказание криминальной активности
Модель случайного леса также позволяет увидеть,
2.6 Случайные леса
Методы формирования ансамблей моделей – бустинг и бэггинг.
В применении
2.6 Случайные леса
Методы формирования ансамблей моделей – бустинг и бэггинг.
В применении

2.6 Случайные леса
Ограничения на модель
Случайные леса считаются черными ящиками, так как
2.6 Случайные леса
Ограничения на модель
Случайные леса считаются черными ящиками, так как

3.1 Задача кластеризации
Сравним задачи классификации и задачи кластеризации
3.1 Задача кластеризации
Сравним задачи классификации и задачи кластеризации

3.1 Задача кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и
3.1 Задача кластеризации
Кластеры могут быть непересекающимися, или эксклюзивными (non-overlapping, exclusive), и

3.1 Задача кластеризации
Термин «кластерный анализ» (впервые ввел Tryon в 1939 г.)
3.1 Задача кластеризации
Термин «кластерный анализ» (впервые ввел Tryon в 1939 г.)

3.1 Задача кластеризации
Пример. Сегментация рынка
Можно кластеризовать потребителей по двум параметрам
3.1 Задача кластеризации
Пример. Сегментация рынка
Можно кластеризовать потребителей по двум параметрам
3.1 Задача кластеризации
Пример. Сегментация рынка
3.1 Задача кластеризации
Пример. Сегментация рынка

3.1 Задача кластеризации
Если посмотреть на диаграмму (диаграмма рассеяния) «цена —
3.1 Задача кластеризации
Если посмотреть на диаграмму (диаграмма рассеяния) «цена —

3.1 Задача кластеризации
В реальной жизни кластеры, различимые глазом, встречаются нечасто,
3.1 Задача кластеризации
В реальной жизни кластеры, различимые глазом, встречаются нечасто,

3.1 Задача кластеризации
Для проведения кластерного анализа, кроме сбора данных, необходимо определить
3.1 Задача кластеризации
Для проведения кластерного анализа, кроме сбора данных, необходимо определить

3.1 Задача кластеризации
Методы кластерного анализа можно разделить на две группы:
•
3.1 Задача кластеризации
Методы кластерного анализа можно разделить на две группы:
•

3.1 Задача кластеризации
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном
3.1 Задача кластеризации
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном

3.1 Задача кластеризации
Иерархические методы кластерного анализа
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis,
3.1 Задача кластеризации
Иерархические методы кластерного анализа
Иерархические дивизимные (делимые) методы (DIvisive ANAlysis,

3.1 Задача кластеризации
Иерархические методы кластерного анализа
Иерархические методы кластеризации различаются правилами построения
3.1 Задача кластеризации
Иерархические методы кластерного анализа
Иерархические методы кластеризации различаются правилами построения

3.1 Задача кластеризации
Неиерархические методы кластерного анализа
При большом количестве наблюдений используют неиерархические
3.1 Задача кластеризации
Неиерархические методы кластерного анализа
При большом количестве наблюдений используют неиерархические

3.2 Кластеризация методом k-средних
Наиболее распространен среди неиерархических методов алгоритм k-средних, также
3.2 Кластеризация методом k-средних
Наиболее распространен среди неиерархических методов алгоритм k-средних, также

3.2 Кластеризация методом k-средних
Пример. Кинопредпочтения зрителей
Пользователей Facebook пригласили пройти опрос, чтобы
3.2 Кластеризация методом k-средних
Пример. Кинопредпочтения зрителей
Пользователей Facebook пригласили пройти опрос, чтобы

3.2 Кластеризация методом k-средних
Пример. Кинопредпочтения зрителей
Суммарные очки черт характера были соотнесы
3.2 Кластеризация методом k-средних
Пример. Кинопредпочтения зрителей
Суммарные очки черт характера были соотнесы

3.2 Кластеризация методом k-средних
При определении кластеров нужно ответить на два вопроса:
Сколько
3.2 Кластеризация методом k-средних
При определении кластеров нужно ответить на два вопроса:
Сколько
3.2 Кластеризация методом k-средних
Одним из способов определить оптимальное количество кластеров
3.2 Кластеризация методом k-средних
Одним из способов определить оптимальное количество кластеров

3.2 Кластеризация методом k-средних
Данные распределяются по кластерам в итеративном процессе
3.2 Кластеризация методом k-средних
Данные распределяются по кластерам в итеративном процессе

3.2 Кластеризация методом k-средних
Хотя кластеризация методом k-средних очень полезна, у нее
3.2 Кластеризация методом k-средних
Хотя кластеризация методом k-средних очень полезна, у нее

3.3 Метод главных компонент
Метод главных компонент – это способ нахождения основополагающих
3.3 Метод главных компонент
Метод главных компонент – это способ нахождения основополагающих

3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?
3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?

3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?
3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?

3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?
3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?

3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?
3.3 Метод главных компонент
Пример. Диетология.
Как лучше всего дифференцировать пищевые продукты?

3.3 Метод главных компонент
Метод главных компонент – это полезный способ анализа
3.3 Метод главных компонент
Метод главных компонент – это полезный способ анализа

4.1 Ассоциативные правила
Целью поиска ассоциативных правил (association rule) является нахождение закономерностей
4.1 Ассоциативные правила
Целью поиска ассоциативных правил (association rule) является нахождение закономерностей

4.1 Ассоциативные правила
Понимание закономерностей рыночной корзины поможет увеличить продажи несколькими способами
4.1 Ассоциативные правила
Понимание закономерностей рыночной корзины поможет увеличить продажи несколькими способами

4.1 Ассоциативные правила
Регистрируя все бизнес-операции в течение всего времени своей деятельности,
4.1 Ассоциативные правила
Регистрируя все бизнес-операции в течение всего времени своей деятельности,

4.1 Ассоциативные правила
Пример транзакционной базы данных, состоящей из покупательских транзакций
4.1 Ассоциативные правила
Пример транзакционной базы данных, состоящей из покупательских транзакций

4.1 Ассоциативные правила
Существуют три основные меры для определения ассоциаций: поддержка, достоверность
4.1 Ассоциативные правила
Существуют три основные меры для определения ассоциаций: поддержка, достоверность

4.1 Ассоциативные правила
Поддержкой называют количество или процент транзакций, содержащих определенный набор
4.1 Ассоциативные правила
Поддержкой называют количество или процент транзакций, содержащих определенный набор

4.1 Ассоциативные правила
Достоверность показывает, как часто товар Y появляется вместе с
4.1 Ассоциативные правила
Достоверность показывает, как часто товар Y появляется вместе с

4.1 Ассоциативные правила
Лифт отражает то, как часто товары X и Y
4.1 Ассоциативные правила
Лифт отражает то, как часто товары X и Y
4.1 Ассоциативные правила
Пример: ведение продуктовых продаж.
Проанализированы данные одного продуктового магазина за
4.1 Ассоциативные правила
Пример: ведение продуктовых продаж.
Проанализированы данные одного продуктового магазина за

4.2 Методы поиска ассоциативных правил
Перечислим некоторые методы и алгоритмы
Алгоритм AIS. Первый
4.2 Методы поиска ассоциативных правил
Перечислим некоторые методы и алгоритмы
Алгоритм AIS. Первый

4.2 Методы поиска ассоциативных правил
Для улучшения работы представленных выше алгоритмов был
4.2 Методы поиска ассоциативных правил
Для улучшения работы представленных выше алгоритмов был

4.2 Методы поиска ассоциативных правил
Пример использования алгоритма Apriori
4.2 Методы поиска ассоциативных правил
Пример использования алгоритма Apriori

4.3 Приложения с применением ассоциативных правил
Часто встречающиеся приложения с применением ассоциативных
4.3 Приложения с применением ассоциативных правил
Часто встречающиеся приложения с применением ассоциативных

4.4 Ограничение методов поиска ассоциативных правил
Ограничения существуют несмотря на большой диапазон
4.4 Ограничение методов поиска ассоциативных правил
Ограничения существуют несмотря на большой диапазон

Лабораторная работа. Знакомство с платформой Deductor
Целью выполнения данной лабораторной работы является:
Лабораторная работа. Знакомство с платформой Deductor
Целью выполнения данной лабораторной работы является:

Лабораторная работа. Знакомство с платформой Deductor
Теоретическая часть
АП «Deductor» применима для
Лабораторная работа. Знакомство с платформой Deductor
Теоретическая часть
АП «Deductor» применима для

Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Системы корпоративной отчетности.
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Системы корпоративной отчетности.

Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Анализ тенденций и
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Анализ тенденций и

Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Управление рисками. Реализованные
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Управление рисками. Реализованные

Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Диагностика. Механизмы анализа,
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Диагностика. Механизмы анализа,
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:
Лабораторная работа. Знакомство с платформой Deductor
Задачи, решаемые АП:

5.1 Задачи, которые ставятся перед нейронными сетями
Начало нейронным сетям как инструменту
5.1 Задачи, которые ставятся перед нейронными сетями
Начало нейронным сетям как инструменту

5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain
5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain

5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain
5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain

5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain
5.1 Задачи, которые ставятся перед нейронными сетями
По мнению Anil K. Jain

5.2 Как работает нейронная сеть
Предположим, что нам даются наборы чисел (входные
5.2 Как работает нейронная сеть
Предположим, что нам даются наборы чисел (входные

5.2 Как работает нейронная сеть
Затем нам предъявляют уже новые данные: значения
5.2 Как работает нейронная сеть
Затем нам предъявляют уже новые данные: значения

5.2 Как работает нейронная сеть
Как действует в этой ситуации нейронная сеть?
5.2 Как работает нейронная сеть
Как действует в этой ситуации нейронная сеть?
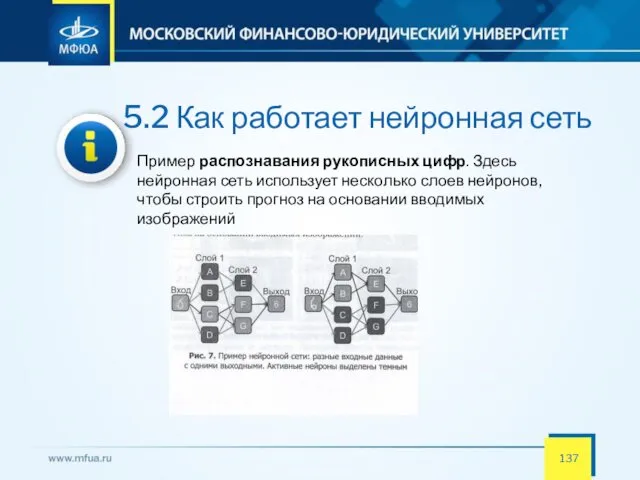
5.2 Как работает нейронная сеть
Пример распознавания рукописных цифр. Здесь нейронная сеть
5.2 Как работает нейронная сеть
Пример распознавания рукописных цифр. Здесь нейронная сеть

5.2 Как работает нейронная сеть
Чтобы построить прогноз, нейроны, в свою очередь,
5.2 Как работает нейронная сеть
Чтобы построить прогноз, нейроны, в свою очередь,

5.3 Общая схема анализа данных с помощью нейронных сетей
Общая схема анализа
5.3 Общая схема анализа данных с помощью нейронных сетей
Общая схема анализа

5.3 Общая схема анализа данных с помощью нейронных сетей
Общая схема анализа
5.3 Общая схема анализа данных с помощью нейронных сетей
Общая схема анализа

6.1 Характеристики Big Data
Big Data — обозначение структурированных и неструктурированных данных
6.1 Характеристики Big Data
Big Data — обозначение структурированных и неструктурированных данных

6.1 Характеристики Big Data
В качестве определяющих характеристик для больших данных традиционно
6.1 Характеристики Big Data
В качестве определяющих характеристик для больших данных традиционно

6.1 Характеристики Big Data
Набор признаков VVV (volume, velocity, variety) изначально выработан
6.1 Характеристики Big Data
Набор признаков VVV (volume, velocity, variety) изначально выработан

6.2 Источники больших данных
Есть классические источники данных. Есть источники данных,
6.2 Источники больших данных
Есть классические источники данных. Есть источники данных,

6.2 Источники больших данных
Есть классические источники данных. Есть источники данных,
6.2 Источники больших данных
Есть классические источники данных. Есть источники данных,

6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы
6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы

6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы
6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы

6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы
6.3 Методы и техники анализа, применимые к большим данным
Перечислим эти методы

6.4 Технологии. Аппаратные решения
Существует ряд аппаратно-программных комплексов, предоставляющих предконфигурированные решения для
6.4 Технологии. Аппаратные решения
Существует ряд аппаратно-программных комплексов, предоставляющих предконфигурированные решения для

6.4 Технологии. Аппаратные решения
К решениям из области больших данных иногда относят
6.4 Технологии. Аппаратные решения
К решениям из области больших данных иногда относят

6.4 Технологии. Аппаратные решения
Иногда к решениям для больших данных относят и
6.4 Технологии. Аппаратные решения
Иногда к решениям для больших данных относят и

6.4 Технологии. Аппаратные решения
Аппаратные решения DAS — систем хранения данных, напрямую
6.4 Технологии. Аппаратные решения
Аппаратные решения DAS — систем хранения данных, напрямую
 Программное обеспечение персонального компьютера
Программное обеспечение персонального компьютера Найпростіша WEB-сторінка
Найпростіша WEB-сторінка Mathematical functions, characters, and strings. Introduction to Java Programming
Mathematical functions, characters, and strings. Introduction to Java Programming S.O.L.I.D. Принципы на практике
S.O.L.I.D. Принципы на практике Кодирование графической информации
Кодирование графической информации Основные процессы жизненного цикла АИС
Основные процессы жизненного цикла АИС Информационные ресурсы сети Интернет
Информационные ресурсы сети Интернет Знакомство с алгоритмическим языком стрелок
Знакомство с алгоритмическим языком стрелок Файловая система. Операционные системы. Лекция 3
Файловая система. Операционные системы. Лекция 3 Информационно-коммуникационные технологии
Информационно-коммуникационные технологии Cooladata. Create the script and look for part of the email
Cooladata. Create the script and look for part of the email Использование UML для проектирования параллельных приложений
Использование UML для проектирования параллельных приложений Инструкция по работе с ресурсами ИЗО
Инструкция по работе с ресурсами ИЗО Введение в глубокое обучение
Введение в глубокое обучение Информационная безопасность
Информационная безопасность Разработка АИС Библиотека
Разработка АИС Библиотека Организация безопасного цифрового пространства учителя и ученика
Организация безопасного цифрового пространства учителя и ученика Программирование на языке Паскаль. 10 класс
Программирование на языке Паскаль. 10 класс Взаимодействие PHP и MySQL
Взаимодействие PHP и MySQL Используем язык программирования Scratch во внеурочной деятельности
Используем язык программирования Scratch во внеурочной деятельности Sportarena. Сайт спортивных новостей
Sportarena. Сайт спортивных новостей Система ввода-вывода и периферийные устройства
Система ввода-вывода и периферийные устройства Основы алгоритмизации и программирования. Лекция 15. Динамические структуры данных
Основы алгоритмизации и программирования. Лекция 15. Динамические структуры данных Транзакции. Понятие транзакции
Транзакции. Понятие транзакции Моделирование систем. Лекция 2
Моделирование систем. Лекция 2 Что такое пост
Что такое пост Работа с текстовым редактором
Работа с текстовым редактором Информатика. Русский язык
Информатика. Русский язык