- Основы алгоритмизации и программирования. Лекция 15. Динамические структуры данных

Содержание
- 2. Линейные списки Некоторые задачи исключают использование структур данных фиксированного размера и требуют введения структур, способных увеличивать
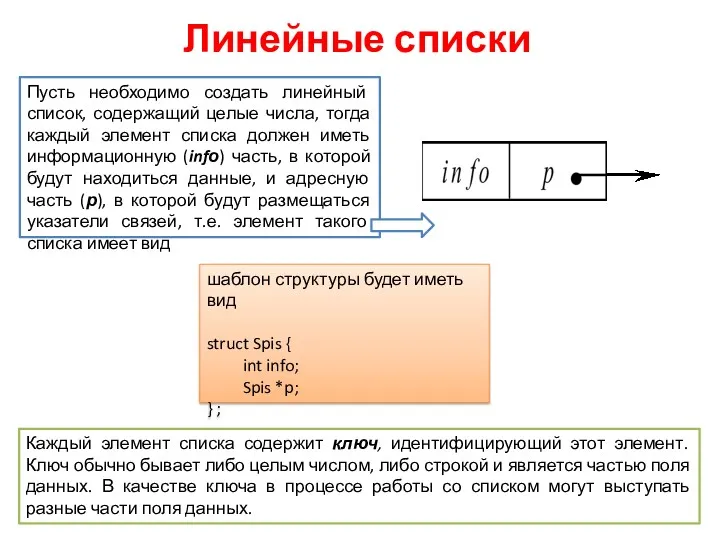
- 3. Линейные списки Пусть необходимо создать линейный список, содержащий целые числа, тогда каждый элемент списка должен иметь
- 4. Линейные списки Например, если создается линейный список из записей, содержащих фамилию, год рождения, стаж работы и
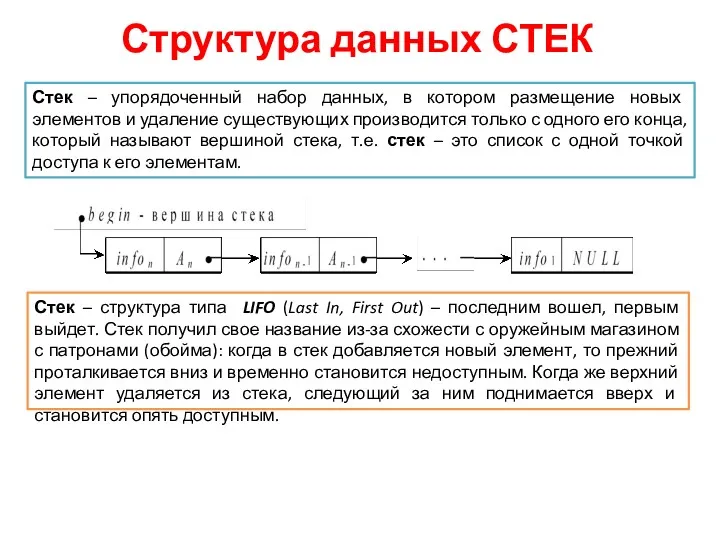
- 5. Структура данных СТЕК Стек – упорядоченный набор данных, в котором размещение новых элементов и удаление существующих
- 6. Структура данных СТЕК Максимальное число элементов стека ограничивается, т.е. по мере вталкивания в стек новых элементов
- 7. Структура данных ОЧЕРЕДЬ Очередь – упорядоченный набор данных (структура данных), в котором в отличие от стека
- 8. Структура данных ОЧЕРЕДЬ При работе с очередью обычно помимо текущего указателя используют еще два указателя, первый
- 9. Двунаправленный линейный список Более универсальным является двунаправленный (двухсвязный) список, в каждый элемент которого кроме указателя на
- 10. Нелинейные структуры данных Введение в динамическую переменную двух и более полей-указателей позволяет получить нелинейные структуры данных.
- 12. Скачать презентацию

Линейные списки
Некоторые задачи исключают использование структур данных фиксированного размера и требуют
Линейные списки
Некоторые задачи исключают использование структур данных фиксированного размера и требуют
Линейные списки
Пусть необходимо создать линейный список, содержащий целые числа, тогда каждый
Линейные списки
Пусть необходимо создать линейный список, содержащий целые числа, тогда каждый
Линейные списки
Например, если создается линейный список из записей, содержащих фамилию, год
Линейные списки
Например, если создается линейный список из записей, содержащих фамилию, год
Структура данных СТЕК
Стек – упорядоченный набор данных, в котором размещение новых
Структура данных СТЕК
Стек – упорядоченный набор данных, в котором размещение новых
Структура данных СТЕК
Максимальное число элементов стека ограничивается, т.е. по мере вталкивания
Структура данных СТЕК
Максимальное число элементов стека ограничивается, т.е. по мере вталкивания

Структура данных ОЧЕРЕДЬ
Очередь – упорядоченный набор данных (структура данных), в котором
Структура данных ОЧЕРЕДЬ
Очередь – упорядоченный набор данных (структура данных), в котором
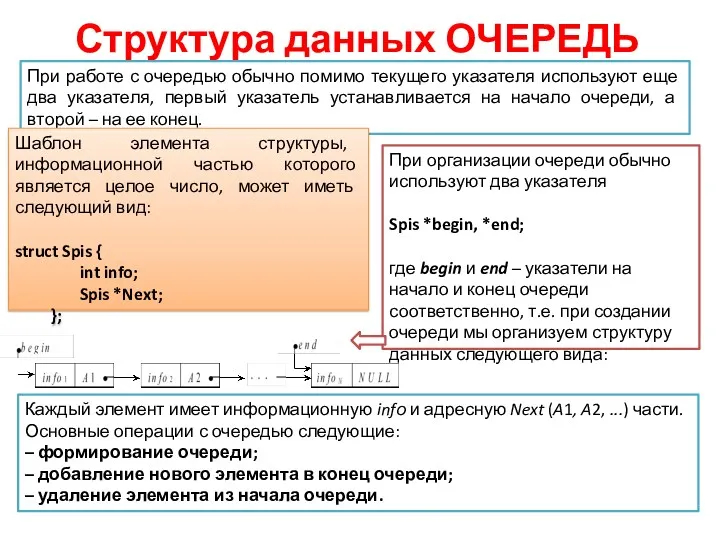
Структура данных ОЧЕРЕДЬ
При работе с очередью обычно помимо текущего указателя используют
Структура данных ОЧЕРЕДЬ
При работе с очередью обычно помимо текущего указателя используют
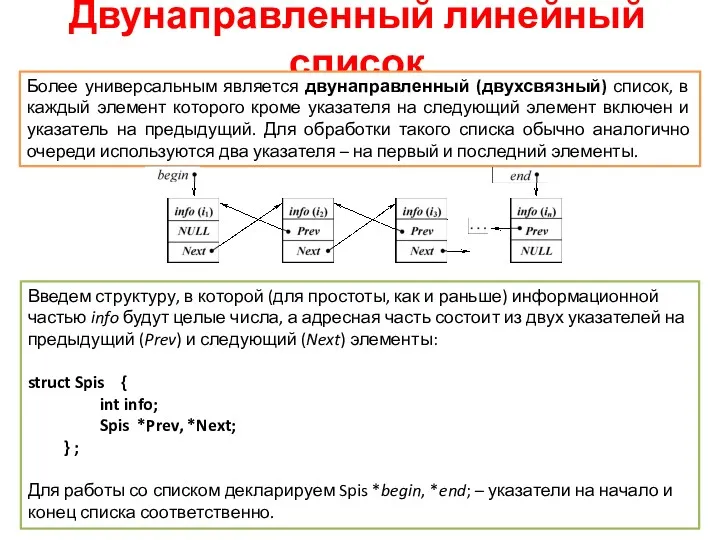
Двунаправленный линейный список
Более универсальным является двунаправленный (двухсвязный) список, в каждый элемент
Двунаправленный линейный список
Более универсальным является двунаправленный (двухсвязный) список, в каждый элемент

Нелинейные структуры данных
Введение в динамическую переменную двух и более полей-указателей позволяет
Нелинейные структуры данных
Введение в динамическую переменную двух и более полей-указателей позволяет
 Занимательное путешествие по персонажам
Занимательное путешествие по персонажам Сервис Интернет. Лекция №3
Сервис Интернет. Лекция №3 Modeling and Solving Constraints. Basic Idea
Modeling and Solving Constraints. Basic Idea Программирование разветвляющихся алгоритмов
Программирование разветвляющихся алгоритмов Графики и диаграммы
Графики и диаграммы Экстремальное программирование. Методология XP
Экстремальное программирование. Методология XP Анализ данных в реляционных БД на примере СУБД MS Access
Анализ данных в реляционных БД на примере СУБД MS Access Chapter 1 Introduction
Chapter 1 Introduction Разработка алгоритмов и программ оперативной аналитической обработки коротких текстов
Разработка алгоритмов и программ оперативной аналитической обработки коротких текстов Информационные технологии
Информационные технологии Приложения Java
Приложения Java Архітектура, розроблення та експлуатація інформаційних систем корпоративного і національного рівнів
Архітектура, розроблення та експлуатація інформаційних систем корпоративного і національного рівнів Intelektual boshqaruv tizimilari. 2-mavzu
Intelektual boshqaruv tizimilari. 2-mavzu Презентация по созданию презентаций
Презентация по созданию презентаций Материалы для проведения уроков технологии 7 класс
Материалы для проведения уроков технологии 7 класс Локальные преобразования
Локальные преобразования Protecting the Network
Protecting the Network Технология обеспечения безопасности информации
Технология обеспечения безопасности информации Sztos. Инструкция оплаты через терминал
Sztos. Инструкция оплаты через терминал Адресация и передача информации в сети Интернет
Адресация и передача информации в сети Интернет Логические элементы
Логические элементы Линейное программирование
Линейное программирование Арбитраж трафика. Gambling
Арбитраж трафика. Gambling Исследование возможности создания электронных документов на основе шаблонов в организации
Исследование возможности создания электронных документов на основе шаблонов в организации Устройство и принцип работы последовательного сумматора
Устройство и принцип работы последовательного сумматора Методология описания бизнес-процессов IDEF3
Методология описания бизнес-процессов IDEF3 Разработка алгоритмов распознавания дефекта изделия с использованием нейронных сетей
Разработка алгоритмов распознавания дефекта изделия с использованием нейронных сетей Метод сортировки пирамидой
Метод сортировки пирамидой