- Введение в глубокое обучение

Содержание
- 2. План лекции Ограничения линейных моделей Модель глубокого обучения Вычислительные возможности нейросетей Слои моделей Функция активации Обратное
- 3. Ограничения линейных моделей Работают только с линейными зависимостями Сами не конструируют высокоабстрактные признаки текстовые данные графические
- 4. Задача «исключающего ИЛИ»
- 5. Задача «исключающего ИЛИ»
- 6. Задача «исключающего ИЛИ»
- 7. Задача «исключающего ИЛИ»
- 8. Задача «исключающего ИЛИ» Таким образом два решения: конструирование нового признака на основе исходных (сложно) построение композиции
- 9. Новый подход
- 10. Новый подход перцептрон (МакКаллок и Питтс, 1943 год) искусственный нейрон
- 11. Модель глубокого обучения (нейросеть)
- 12. Модель глубокого обучения (нейросеть)
- 13. Модель глубокого обучения (нейросеть)
- 14. Вычислительные возможности нейросетей Теорема Вейерштрасса – Стоуна Теорема Колмогорова – Арнольда (13 проблема Гильберта) Универсальная теорема
- 15. Вычислительные возможности нейросетей Несколько замечаний: двух слоёв достаточно для аппроксимации практически всех «математических» функций нейросети обучаются
- 16. Слои модели
- 17. Слои модели
- 18. Слои модели модель состоит из взаимосвязанных слоёв (Layers) самый простой и распространённый слой – плотный (Dense),
- 19. Функция активации функция активации
- 20. Функция активации Несколько замечаний: применяется после линейного преобразования признаков отвечает за нелинейность главное требование – дифференцируемость
- 21. Обучение модели
- 22. Обучение модели Напоминание: функция потерь численно определяет, на сколько решена задача оптимизатор корректирует параметры модели в
- 23. Обучение модели Каким методом будем обучать нейросеть? Стохастическим градиентным спуском
- 24. Обратное распространение ошибки Он же: backpropagation цепное правило производная сложной функции
- 25. Обратное распространение ошибки
- 26. Обратное распространение ошибки
- 27. Алгоритм обратного распространения ошибки
- 28. Обратное распространение ошибки Плюсы метода: вычисляется, практически рекурсивно, что даёт скорость работает с любой шириной, глубиной
- 29. Модель глубокого обучения Предварительные выводы: модели глубокого обучения состоят из взаимосвязанных слоёв слои хранят параметры модели
- 30. Функция активации: сигмоида Минусы: на плечах производная ноль ОДЗ не центрирована вычисление экспоненты
- 31. Функция активации: гиперболический тангенс Плюсы: центрирован Минусы: на плечах производная ноль ОДЗ не центрирована вычисление экспоненты
- 32. Функция активации: ReLU Плюсы: центрирована нелинейная быстрая дифференцируемая Минусы: не центрирована
- 33. Функция активации: Leaky ReLU Плюсы: центрирована нелинейная быстрая дифференцируемая «центрирована»
- 34. Различные функции активации
- 35. Различные функции активации Замечание: ReLU – отправная точка изменяйте аккуратно скорость обучения попробуйте Leaky ReLU или
- 36. Недостатки SGD застревание в локальных экстремумах «медленная» сходимость
- 37. Эвристики SGD: Momentum
- 38. Эвристики SGD: Momentum
- 39. Эвристики SGD: Momentum
- 40. Эвристики SGD: AdaGrad и RMSProp
- 41. Эвристики SGD: Adam Включает в себя все перечисленные подходы
- 42. Эвристики SGD
- 43. Эвристики SGD: подбор скорости обучения
- 44. Эвристики SGD Замечание: чем навороченней эвристика, тем больше требуется памяти для хранения кэшей, моментов и т.д.
- 45. Эвристики SGD
- 46. Нормировка признаков
- 47. Нормировка признаков Замечание: модель, обученная на нормированных признаках, менее чувствительна к изменениям в данных градиентный спуск
- 48. Нормализация батча
- 49. Нормализация батча Замечание: позволяет решить проблему метода обратного распространения ошибки: параметры модели оптимизируются «несогласовано» намного ускоряет
- 50. Регуляризация Прореживание (Dropout)
- 51. Регуляризация: прореживание прореживание (dropout) – приравнивание к нулю случайно выбираемых признаков на этапе обучения на этапе
- 53. Скачать презентацию

План лекции
Ограничения линейных моделей
Модель глубокого обучения
Вычислительные возможности нейросетей
Слои моделей
Функция активации
Обратное распространение
План лекции
Ограничения линейных моделей
Модель глубокого обучения
Вычислительные возможности нейросетей
Слои моделей
Функция активации
Обратное распространение

Ограничения линейных моделей
Работают только с линейными зависимостями
Сами не конструируют высокоабстрактные признаки
текстовые
Ограничения линейных моделей
Работают только с линейными зависимостями
Сами не конструируют высокоабстрактные признаки
текстовые

Задача «исключающего ИЛИ»
Задача «исключающего ИЛИ»

Задача «исключающего ИЛИ»
Задача «исключающего ИЛИ»

Задача «исключающего ИЛИ»
Задача «исключающего ИЛИ»

Задача «исключающего ИЛИ»
Задача «исключающего ИЛИ»

Задача «исключающего ИЛИ»
Таким образом два решения:
конструирование нового признака на основе исходных
Задача «исключающего ИЛИ»
Таким образом два решения:
конструирование нового признака на основе исходных

Новый подход
Новый подход
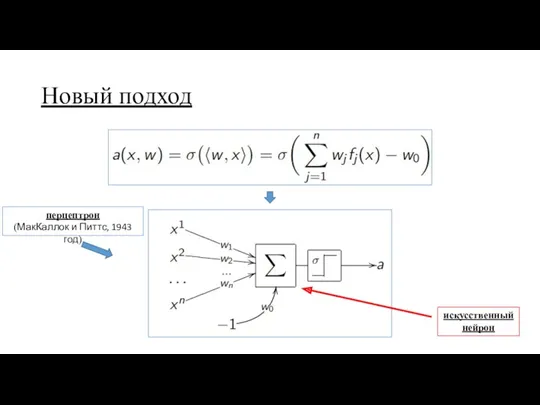
Новый подход
перцептрон
(МакКаллок и Питтс, 1943 год)
искусственный
нейрон
Новый подход
перцептрон
(МакКаллок и Питтс, 1943 год)
искусственный
нейрон

Модель глубокого обучения (нейросеть)
Модель глубокого обучения (нейросеть)

Модель глубокого обучения (нейросеть)
Модель глубокого обучения (нейросеть)
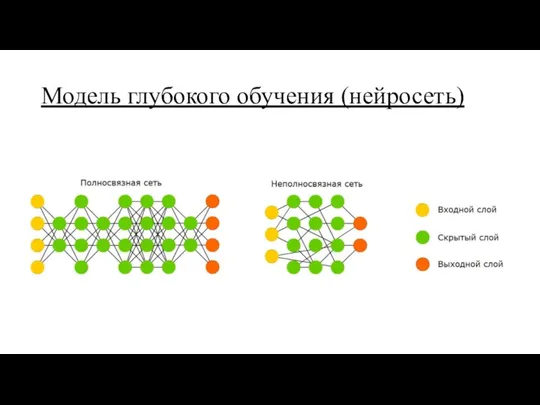
Модель глубокого обучения (нейросеть)
Модель глубокого обучения (нейросеть)

Вычислительные возможности нейросетей
Теорема Вейерштрасса – Стоуна
Теорема Колмогорова – Арнольда (13 проблема
Вычислительные возможности нейросетей
Теорема Вейерштрасса – Стоуна
Теорема Колмогорова – Арнольда (13 проблема

Вычислительные возможности нейросетей
Несколько замечаний:
двух слоёв достаточно для аппроксимации практически всех «математических»
Вычислительные возможности нейросетей
Несколько замечаний:
двух слоёв достаточно для аппроксимации практически всех «математических»
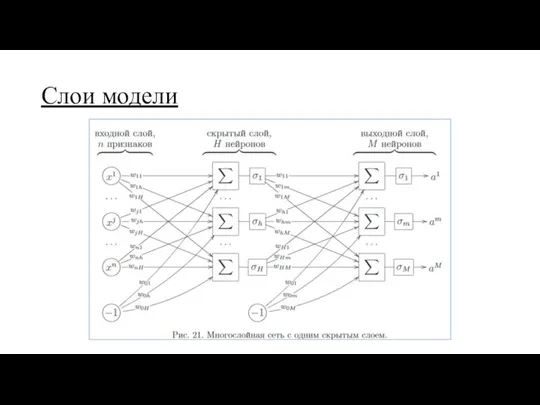
Слои модели
Слои модели
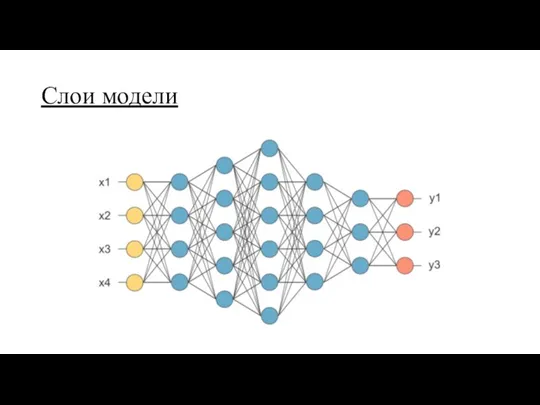
Слои модели
Слои модели

Слои модели
модель состоит из взаимосвязанных слоёв (Layers)
самый простой и распространённый слой
Слои модели
модель состоит из взаимосвязанных слоёв (Layers)
самый простой и распространённый слой
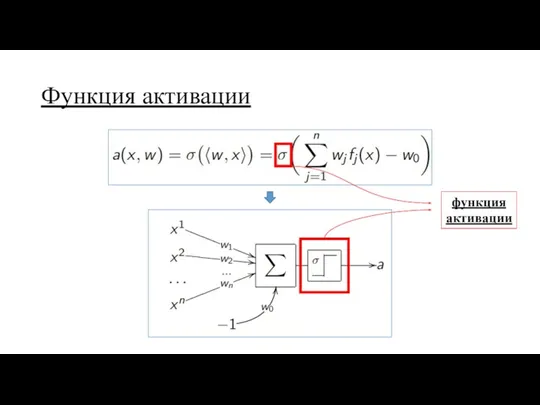
Функция активации
функция
активации
Функция активации
функция
активации

Функция активации
Несколько замечаний:
применяется после линейного преобразования признаков
отвечает за нелинейность
главное требование –
Функция активации
Несколько замечаний:
применяется после линейного преобразования признаков
отвечает за нелинейность
главное требование –
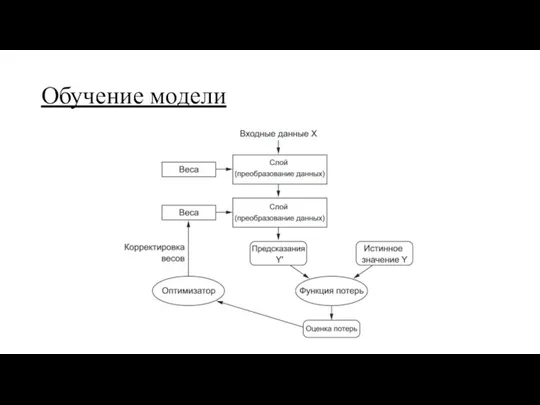
Обучение модели
Обучение модели

Обучение модели
Напоминание:
функция потерь численно определяет, на сколько решена задача
оптимизатор корректирует параметры
Обучение модели
Напоминание:
функция потерь численно определяет, на сколько решена задача
оптимизатор корректирует параметры

Обучение модели
Каким методом будем обучать нейросеть?
Стохастическим градиентным спуском
Обучение модели
Каким методом будем обучать нейросеть?
Стохастическим градиентным спуском

Обратное распространение ошибки
Он же:
backpropagation
цепное правило
производная сложной функции
Обратное распространение ошибки
Он же:
backpropagation
цепное правило
производная сложной функции
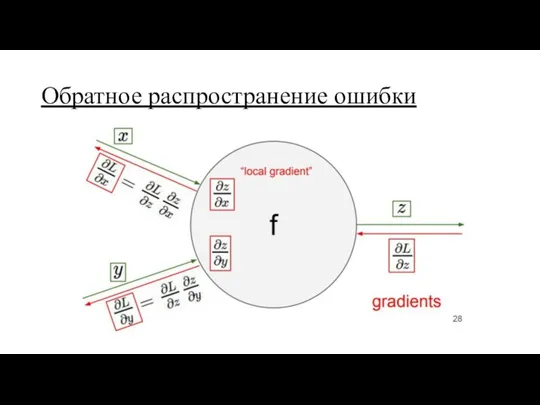
Обратное распространение ошибки
Обратное распространение ошибки
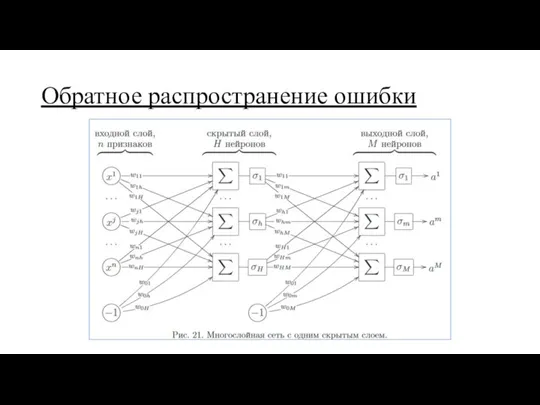
Обратное распространение ошибки
Обратное распространение ошибки

Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки

Обратное распространение ошибки
Плюсы метода:
вычисляется, практически рекурсивно, что даёт скорость
работает
Обратное распространение ошибки
Плюсы метода:
вычисляется, практически рекурсивно, что даёт скорость
работает

Модель глубокого обучения
Предварительные выводы:
модели глубокого обучения состоят из взаимосвязанных слоёв
слои хранят
Модель глубокого обучения
Предварительные выводы:
модели глубокого обучения состоят из взаимосвязанных слоёв
слои хранят
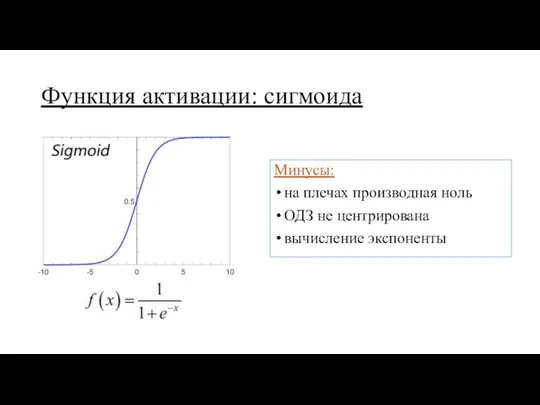
Функция активации: сигмоида
Минусы:
на плечах производная ноль
ОДЗ не центрирована
вычисление экспоненты
Функция активации: сигмоида
Минусы:
на плечах производная ноль
ОДЗ не центрирована
вычисление экспоненты
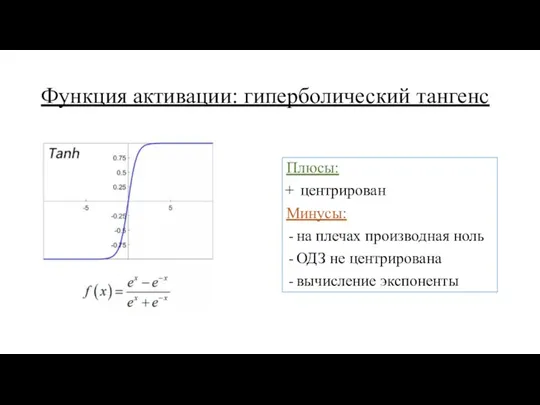
Функция активации: гиперболический тангенс
Плюсы:
центрирован
Минусы:
на плечах производная ноль
ОДЗ не центрирована
вычисление экспоненты
Функция активации: гиперболический тангенс
Плюсы:
центрирован
Минусы:
на плечах производная ноль
ОДЗ не центрирована
вычисление экспоненты
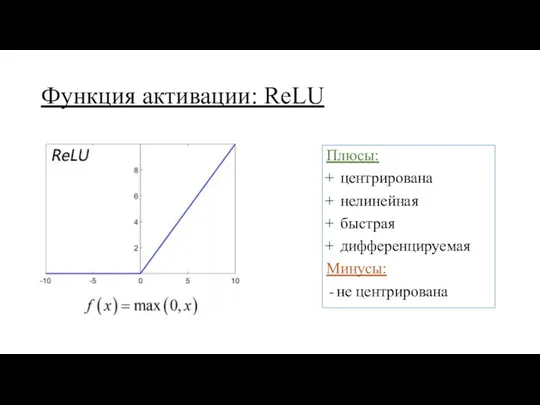
Функция активации: ReLU
Плюсы:
центрирована
нелинейная
быстрая
дифференцируемая
Минусы:
не центрирована
Функция активации: ReLU
Плюсы:
центрирована
нелинейная
быстрая
дифференцируемая
Минусы:
не центрирована
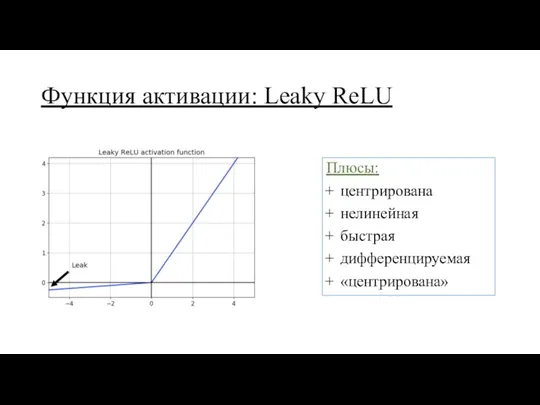
Функция активации: Leaky ReLU
Плюсы:
центрирована
нелинейная
быстрая
дифференцируемая
«центрирована»
Функция активации: Leaky ReLU
Плюсы:
центрирована
нелинейная
быстрая
дифференцируемая
«центрирована»

Различные функции активации
Различные функции активации

Различные функции активации
Замечание:
ReLU – отправная точка
изменяйте аккуратно скорость обучения
попробуйте Leaky ReLU
Различные функции активации
Замечание:
ReLU – отправная точка
изменяйте аккуратно скорость обучения
попробуйте Leaky ReLU
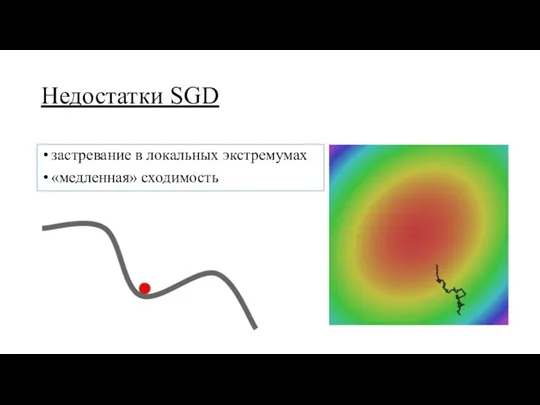
Недостатки SGD
застревание в локальных экстремумах
«медленная» сходимость
Недостатки SGD
застревание в локальных экстремумах
«медленная» сходимость
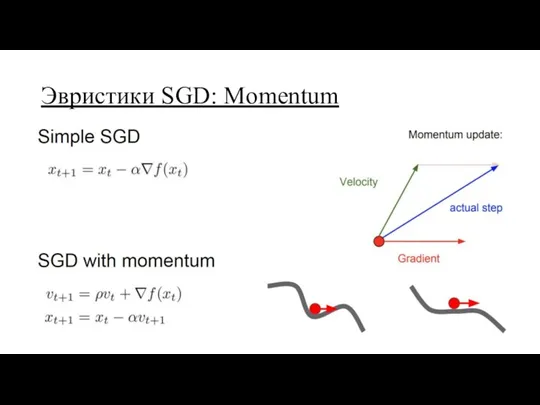
Эвристики SGD: Momentum
Эвристики SGD: Momentum
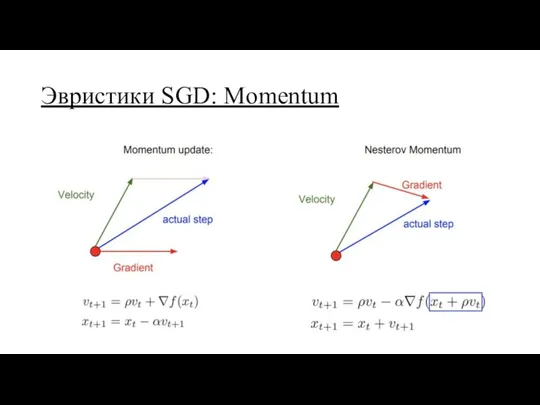
Эвристики SGD: Momentum
Эвристики SGD: Momentum
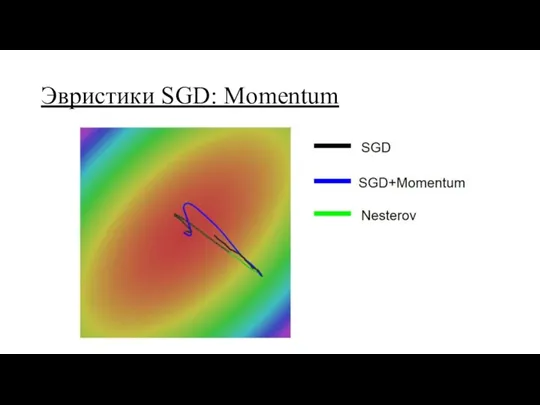
Эвристики SGD: Momentum
Эвристики SGD: Momentum

Эвристики SGD: AdaGrad и RMSProp
Эвристики SGD: AdaGrad и RMSProp

Эвристики SGD: Adam
Включает в себя все перечисленные подходы
Эвристики SGD: Adam
Включает в себя все перечисленные подходы
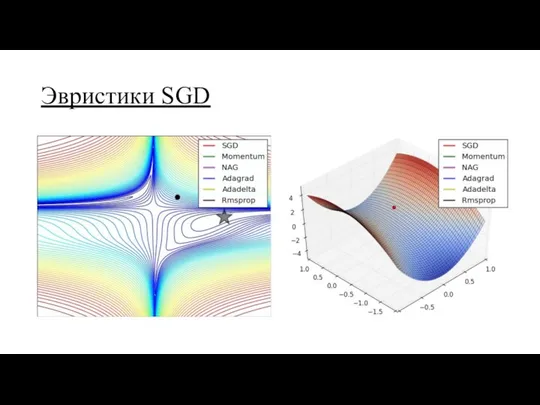
Эвристики SGD
Эвристики SGD
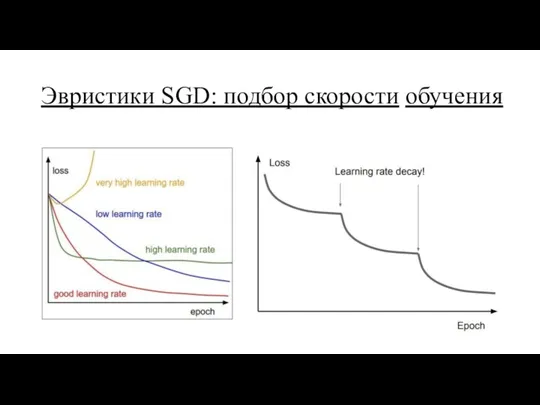
Эвристики SGD: подбор скорости обучения
Эвристики SGD: подбор скорости обучения

Эвристики SGD
Замечание:
чем навороченней эвристика, тем больше требуется памяти для хранения кэшей,
Эвристики SGD
Замечание:
чем навороченней эвристика, тем больше требуется памяти для хранения кэшей,
Эвристики SGD
Эвристики SGD
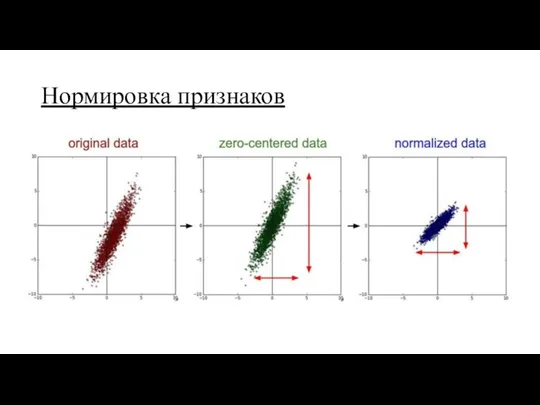
Нормировка признаков
Нормировка признаков

Нормировка признаков
Замечание:
модель, обученная на нормированных признаках, менее чувствительна к изменениям в
Нормировка признаков
Замечание:
модель, обученная на нормированных признаках, менее чувствительна к изменениям в

Нормализация батча
Нормализация батча

Нормализация батча
Замечание:
позволяет решить проблему метода обратного распространения ошибки: параметры модели оптимизируются
Нормализация батча
Замечание:
позволяет решить проблему метода обратного распространения ошибки: параметры модели оптимизируются
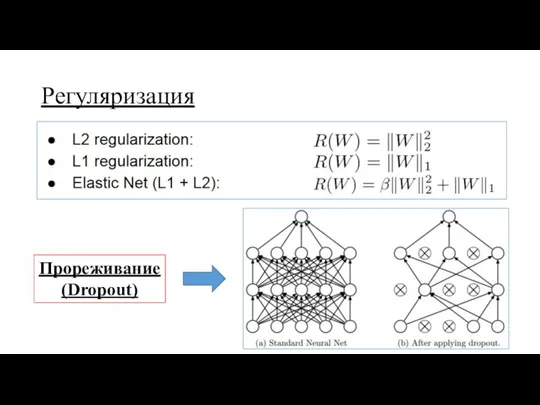
Регуляризация
Прореживание
(Dropout)
Регуляризация
Прореживание
(Dropout)

Регуляризация: прореживание
прореживание (dropout) – приравнивание к нулю случайно выбираемых признаков на
Регуляризация: прореживание
прореживание (dropout) – приравнивание к нулю случайно выбираемых признаков на
 Архитектура ОС MS Windows 2000+. Реестр
Архитектура ОС MS Windows 2000+. Реестр Электронные таблицы Excel
Электронные таблицы Excel История связи. Простейшие средства связи
История связи. Простейшие средства связи Растровая графика
Растровая графика مفاهيم دراسات المستفيدين من المعلومات
مفاهيم دراسات المستفيدين من المعلومات Компьютерные программные продукты для разработки бизнес-планов (Project Expert, COMFAR, Альт-Инвест, PROPSPIN)
Компьютерные программные продукты для разработки бизнес-планов (Project Expert, COMFAR, Альт-Инвест, PROPSPIN) Deep Web – теневой интернет
Deep Web – теневой интернет Программирование на Python
Программирование на Python Работа с диапазонами. Относительная адресация
Работа с диапазонами. Относительная адресация Определение количества информации
Определение количества информации Как создать компьютерный тест-пособие
Как создать компьютерный тест-пособие Система контроля устойчивости бортов. Преимущества выбора радаров MSR (reutech)
Система контроля устойчивости бортов. Преимущества выбора радаров MSR (reutech) Локальные компьютерные сети
Локальные компьютерные сети Создание базы адресов. Слияние
Создание базы адресов. Слияние Системы счисления
Системы счисления Программируемые контроллеры SIEMENS.Simatic S7-200. Программное обеспечение
Программируемые контроллеры SIEMENS.Simatic S7-200. Программное обеспечение Базовый синтаксис CSS в HTML
Базовый синтаксис CSS в HTML Возрастной рейтинг игр
Возрастной рейтинг игр Программирование на языке Python. §54. Алгоритм и его свойства
Программирование на языке Python. §54. Алгоритм и его свойства Составление индивидуальной траектории обучения
Составление индивидуальной траектории обучения Основы синтаксиса. Операции в PHP
Основы синтаксиса. Операции в PHP Администрирование информационных систем. Серверы имен. DNS, WINS
Администрирование информационных систем. Серверы имен. DNS, WINS Урок
Урок Правила безопасного поведения в интернете для детей и подростков
Правила безопасного поведения в интернете для детей и подростков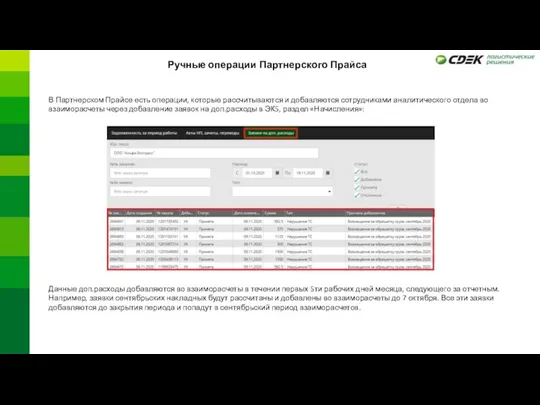 Ручные операции Партнерского Прайса
Ручные операции Партнерского Прайса Информационная культура. Основные понятия
Информационная культура. Основные понятия Урок по информатике в 9 классе на тему Мир электронной почты, телеконференция.
Урок по информатике в 9 классе на тему Мир электронной почты, телеконференция. Функції в Microsoft Excel
Функції в Microsoft Excel