- Нелинейные структуры данных

Содержание
- 2. Дерево состоит из элементов, называемых узлами (вершинами). Узлы соединены между собой дугами. В случае X →
- 3. Внутренний – это узел, не являющийся ни листом, ни корнем. Порядок узла равен количеству его узлов-сыновей.
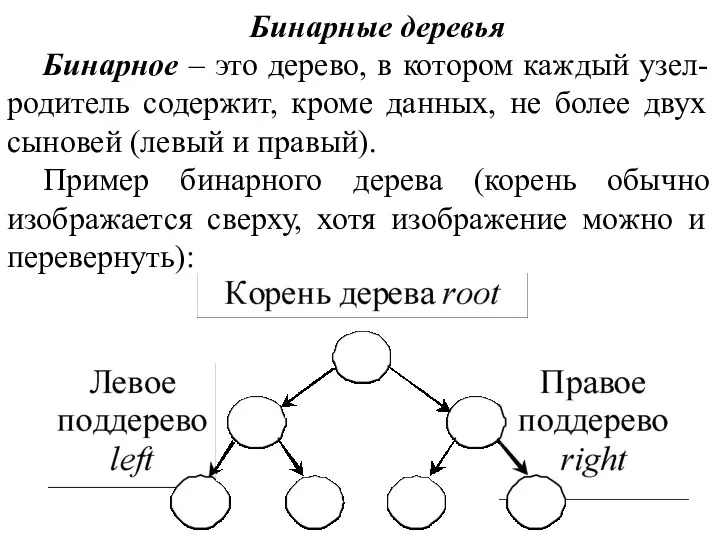
- 4. Бинарные деревья Бинарное – это дерево, в котором каждый узел-родитель содержит, кроме данных, не более двух
- 5. Для работы с бинарными деревьями объ-является структурный тип (шаблон) следующего вида: struct Tree { Информационная Часть
- 6. Такая структура данных организуется следую-щим образом (N – NULL):
- 7. Высота дерева определяется количеством уровней, на которых располагаются его узлы. Если дерево организовано таким образом, что
- 8. Сбалансированными называются деревья, для каждого узла которых количество узлов в его левом и правом поддеревьях различаются
- 9. Основные алгоритмы При работе с деревьями необходимо уметь: – создать дерево; – добавить новый элемент; –
- 10. Все алгоритмы работы с деревьями будем рассматривать для данных, информационной частью которых являются целые числа (ключи).
- 11. Создание дерева Сначала создаем КОРЕНЬ (лист). Далее для того чтобы добавить новый элемент, необходимо найти для
- 12. Пример создания дерева Построим дерево поиска для следующих ключей 17, 18, 6, 5, 9, 23, 12,
- 13. Поиск места для узла 11 в построенном дереве:
- 14. Рассмотрим функцию List для создания нового элемента ЛИСТА (i – информационная часть (ИЧ), в нашем случае
- 15. В результате выполнения функции List создается новый элемент-лист (N – NULL):
- 16. Функция создания дерева из N ключей с добавлением: Tree* Create (Tree *root) { Tree *Prev, *t;
- 17. //---------- Добавление элементов ----------- for (int i=1; i cout cin >> b; // Текущий указатель установили
- 18. while ( t && ! find) { Prev = t; if( b == t->info) { find
- 19. // Если нашли место с адресом Prev if ( ! find ) { // if (find
- 20. Участок кода с обращением к функции Create будет иметь вид: … Tree *root = NULL; //
- 21. Рассмотрим функцию добавления одного листа в уже созданное дерево: void Add_List (Tree *root, int key) {
- 22. else if ( key info ) t = t -> left; else t = t ->
- 23. Участок кода с обращением к функции Add_List может иметь вид: . . . cout cin >>
- 24. Удаление узла Удаление узла из дерева зависит от того, сколько сыновей (потомков) имеет удаляемый узел. Возможны
- 25. 2. Удаляемый узел имеет одного потомка, т.е. из удаляемого узла выходит ровно одна ветвь. Пример схемы
- 26. 3. Удаление узла, имеющего двух сыновей, сложнее рассмотренных выше. Если key – удаляемый узел, то его
- 27. Используя первое условие, находим узел R, который является самым правым узлом поддерева узла key, у него
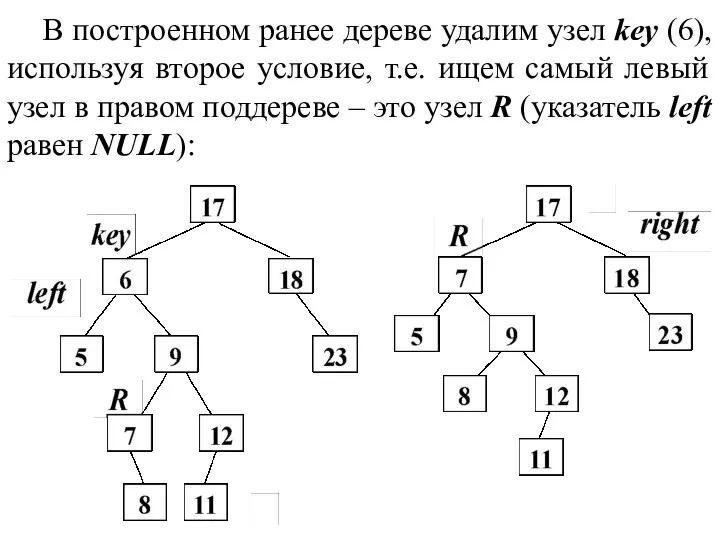
- 28. В построенном ранее дереве удалим узел key (6), используя второе условие, т.е. ищем самый левый узел
- 29. Функция удаления узла по заданному ключу key может иметь вид: Tree* Del (Tree *root, int key)
- 30. // Поиск удаляемого элемента и его родителя while (Del != NULL && Del -> info !=
- 31. // --------- Поиск элемента R для замены --------- if (Del -> right == NULL) R =
- 32. /* Нашли элемент для замены R и его родителя Prev_R */ if( Prev_R == Del) R
- 33. if (Del == root) root = R; // Удаляя корень, заменяем его на R else /*
- 34. Участок программы с обращением к данной функции будет иметь вид … cout cin >> key; root
- 35. Функция просмотра Рекурсивная функция вывода узлов дерева: void View ( Tree *t, int level ) {
- 36. Обращение к функции View будет иметь вид View ( root, 0 ); Второй параметр определяет уровень
- 37. Для ключей 10 (корень), 25, 20, 6, 21, 8, 1, 30, построенное дерево будет выведено на
- 38. Освобождение памяти Функция освобождения памяти может быть реализована аналогично функции View : void Del_All (Tree *t)
- 39. Поиск узла с минимальным (макс.) ключом Tree* Min_Key (Tree *p) { // Max_Key while (p ->
- 40. Для построения сбалансированного дерева поиска из ключей необходимо сформировать массив (динамический), отсортировать его в порядке возрастания
- 41. void Make_Blns (Tree **p, int n, int k, int *a) { if (n == k) {
- 42. Алгоритмы обхода дерева Существуют три алгоритма обхода деревьев, которые естественно следуют из самой структуры дерева. 1.
- 43. Рассмотрим результаты этих обходов на примере записи формулы в виде дерева, т.к. они и позволяют получить
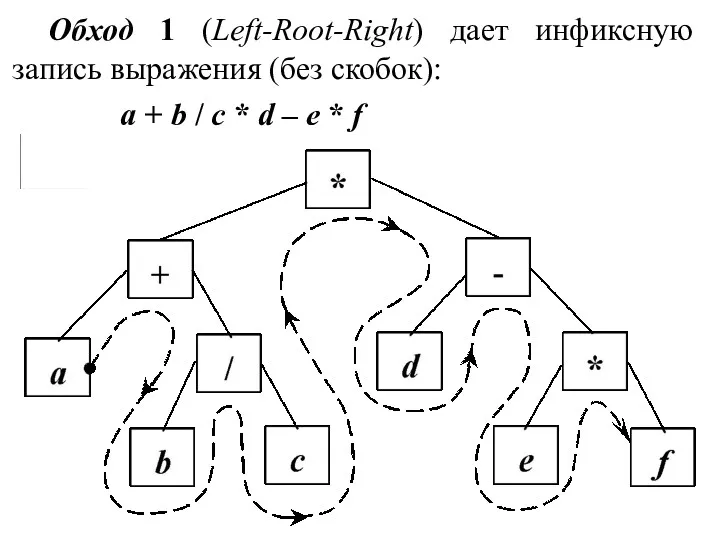
- 44. Рассмотрим обходы дерева на примере формулы: (a + b / c) * (d – e *
- 45. Обход 1 (Left-Root-Right) дает инфиксную запись выражения (без скобок): a + b / c * d
- 46. Обход 2 (Root-Left-Right) дает префиксную запись выражения (без скобок): * + a / b c –
- 48. Скачать презентацию
Дерево состоит из элементов, называемых узлами (вершинами). Узлы соединены между собой дугами. В
Дерево состоит из элементов, называемых узлами (вершинами). Узлы соединены между собой дугами. В

Внутренний – это узел, не являющийся ни листом, ни корнем.
Порядок узла равен
Внутренний – это узел, не являющийся ни листом, ни корнем.
Порядок узла равен

Бинарные деревья
Бинарное – это дерево, в котором каждый узел-родитель содержит, кроме данных, не
Бинарные деревья
Бинарное – это дерево, в котором каждый узел-родитель содержит, кроме данных, не
Для работы с бинарными деревьями объ-является структурный тип (шаблон) следующего вида:
struct Tree {
Информационная
Для работы с бинарными деревьями объ-является структурный тип (шаблон) следующего вида:
struct Tree {
Информационная

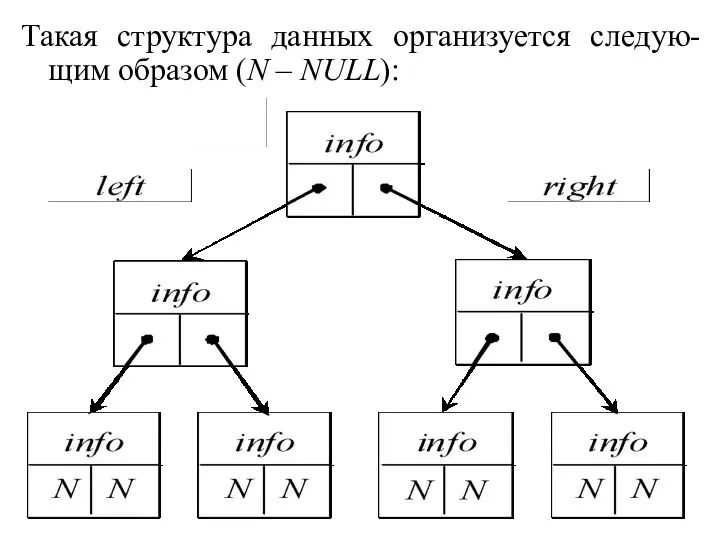
Такая структура данных организуется следую-щим образом (N – NULL):
Такая структура данных организуется следую-щим образом (N – NULL):
Высота дерева определяется количеством уровней, на которых располагаются его узлы.
Если дерево организовано таким
Высота дерева определяется количеством уровней, на которых располагаются его узлы.
Если дерево организовано таким

Сбалансированными называются деревья, для каждого узла которых количество узлов в его левом и
Сбалансированными называются деревья, для каждого узла которых количество узлов в его левом и

Основные алгоритмы
При работе с деревьями необходимо уметь:
– создать дерево;
– добавить новый элемент;
– просмотреть
Основные алгоритмы
При работе с деревьями необходимо уметь:
– создать дерево;
– добавить новый элемент;
– просмотреть

Все алгоритмы работы с деревьями будем рассматривать для данных, информационной частью которых являются
Все алгоритмы работы с деревьями будем рассматривать для данных, информационной частью которых являются

Создание дерева
Сначала создаем КОРЕНЬ (лист). Далее для того чтобы добавить новый элемент, необходимо
Создание дерева
Сначала создаем КОРЕНЬ (лист). Далее для того чтобы добавить новый элемент, необходимо

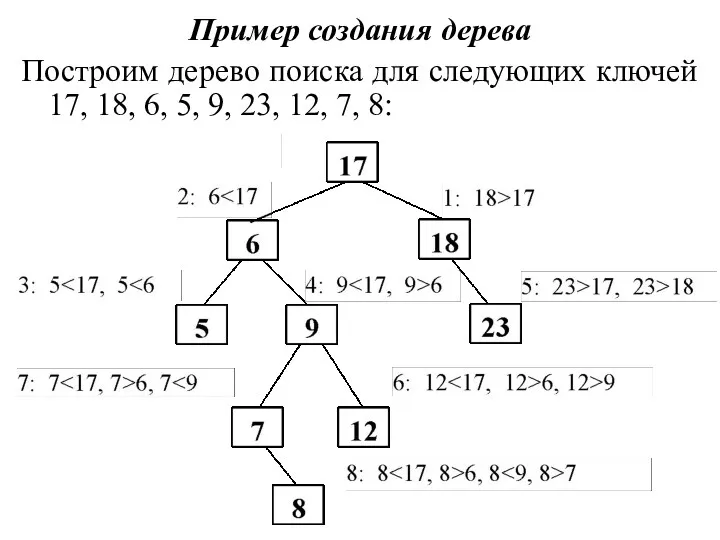
Пример создания дерева
Построим дерево поиска для следующих ключей 17, 18, 6, 5, 9,
Пример создания дерева
Построим дерево поиска для следующих ключей 17, 18, 6, 5, 9,
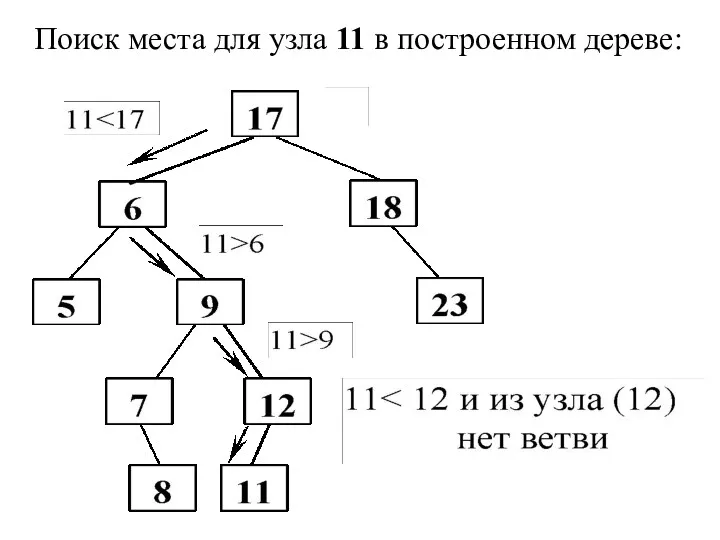
Поиск места для узла 11 в построенном дереве:
Поиск места для узла 11 в построенном дереве:
Рассмотрим функцию List для создания нового элемента ЛИСТА (i – информационная часть (ИЧ),
Рассмотрим функцию List для создания нового элемента ЛИСТА (i – информационная часть (ИЧ),

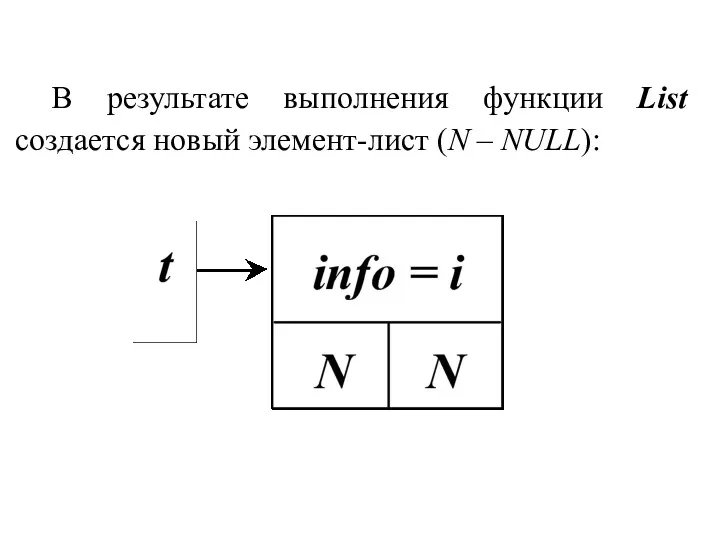
В результате выполнения функции List создается новый элемент-лист (N – NULL):
В результате выполнения функции List создается новый элемент-лист (N – NULL):
Функция создания дерева из N ключей с добавлением:
Tree* Create (Tree *root) {
Tree *Prev,
Функция создания дерева из N ключей с добавлением:
Tree* Create (Tree *root) {
Tree *Prev,

//---------- Добавление элементов -----------
for (int i=1; i <= N; ++i) {
cout << "Input
//---------- Добавление элементов -----------
for (int i=1; i <= N; ++i) {
cout << "Input

while ( t && ! find) {
Prev = t;
if( b ==
while ( t && ! find) {
Prev = t;
if( b ==

// Если нашли место с адресом Prev
if ( ! find ) { //
// Если нашли место с адресом Prev
if ( ! find ) { //

Участок кода с обращением к функции Create будет иметь вид:
…
Tree *root = NULL; //
Участок кода с обращением к функции Create будет иметь вид:
…
Tree *root = NULL; //

Рассмотрим функцию добавления одного листа в уже созданное дерево:
void Add_List (Tree *root, int
Рассмотрим функцию добавления одного листа в уже созданное дерево:
void Add_List (Tree *root, int

else
if ( key < t -> info ) t = t ->
else
if ( key < t -> info ) t = t ->

Участок кода с обращением к функции Add_List может иметь вид:
. . .
cout <<
Участок кода с обращением к функции Add_List может иметь вид:
. . .
cout <<

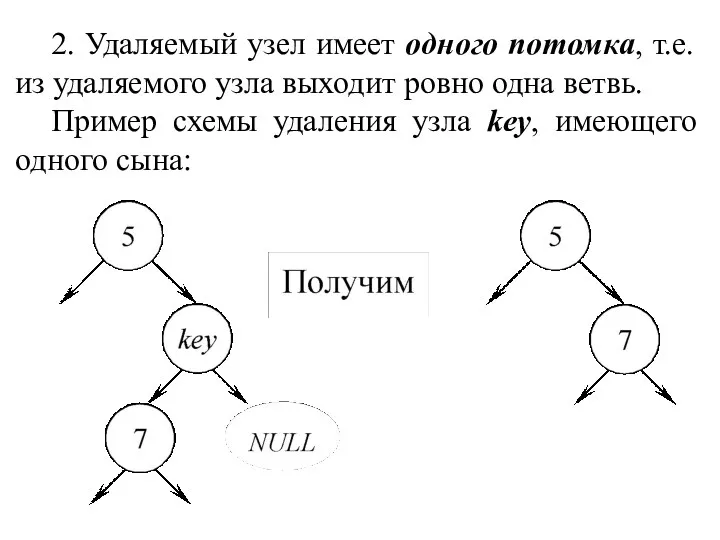
Удаление узла
Удаление узла из дерева зависит от того, сколько сыновей (потомков) имеет удаляемый
Удаление узла
Удаление узла из дерева зависит от того, сколько сыновей (потомков) имеет удаляемый
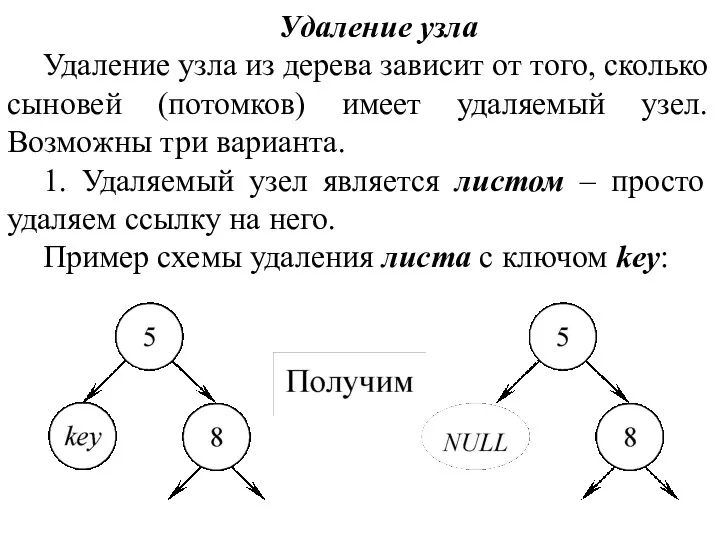
2. Удаляемый узел имеет одного потомка, т.е. из удаляемого узла выходит ровно одна
2. Удаляемый узел имеет одного потомка, т.е. из удаляемого узла выходит ровно одна
3. Удаление узла, имеющего двух сыновей, сложнее рассмотренных выше.
Если key – удаляемый
3. Удаление узла, имеющего двух сыновей, сложнее рассмотренных выше.
Если key – удаляемый

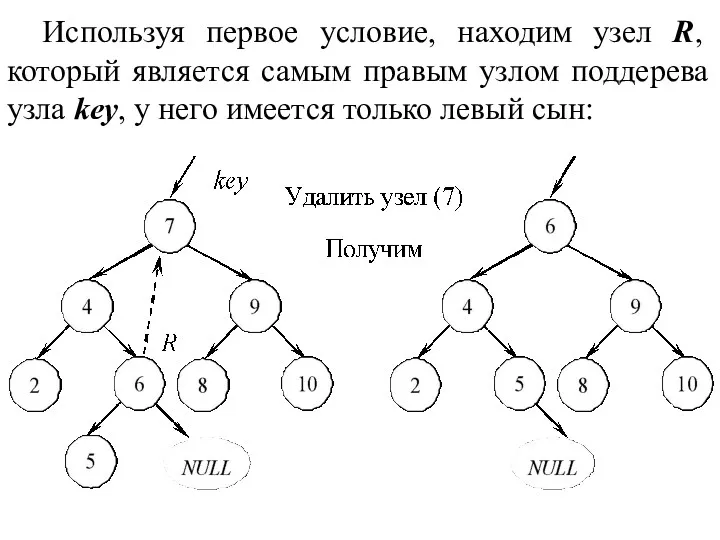
Используя первое условие, находим узел R, который является самым правым узлом поддерева узла
Используя первое условие, находим узел R, который является самым правым узлом поддерева узла
В построенном ранее дереве удалим узел key (6), используя второе условие, т.е. ищем
В построенном ранее дереве удалим узел key (6), используя второе условие, т.е. ищем
Функция удаления узла по заданному ключу key может иметь вид:
Tree* Del (Tree
Функция удаления узла по заданному ключу key может иметь вид:
Tree* Del (Tree

// Поиск удаляемого элемента и его родителя
while (Del != NULL && Del
// Поиск удаляемого элемента и его родителя
while (Del != NULL && Del

// --------- Поиск элемента R для замены ---------
if (Del -> right == NULL)
// --------- Поиск элемента R для замены ---------
if (Del -> right == NULL)

/* Нашли элемент для замены R и его родителя Prev_R */
if( Prev_R ==
/* Нашли элемент для замены R и его родителя Prev_R */
if( Prev_R ==

if (Del == root) root = R;
// Удаляя корень, заменяем его на R
else
/*
if (Del == root) root = R;
// Удаляя корень, заменяем его на R
else
/*

Участок программы с обращением к данной функции будет иметь вид
…
cout << " Input
Участок программы с обращением к данной функции будет иметь вид
…
cout << " Input

Функция просмотра
Рекурсивная функция вывода узлов дерева:
void View ( Tree *t, int level ) {
if
Функция просмотра
Рекурсивная функция вывода узлов дерева:
void View ( Tree *t, int level ) {
if

Обращение к функции View будет иметь вид View ( root, 0 );
Второй параметр
Обращение к функции View будет иметь вид View ( root, 0 );
Второй параметр

Для ключей 10 (корень), 25, 20, 6, 21, 8, 1, 30, построенное дерево
Для ключей 10 (корень), 25, 20, 6, 21, 8, 1, 30, построенное дерево

Освобождение памяти
Функция освобождения памяти может быть реализована аналогично функции View :
void Del_All (Tree
Освобождение памяти
Функция освобождения памяти может быть реализована аналогично функции View :
void Del_All (Tree

Поиск узла с минимальным (макс.) ключом
Tree* Min_Key (Tree *p) { // Max_Key
Поиск узла с минимальным (макс.) ключом
Tree* Min_Key (Tree *p) { // Max_Key

Для построения сбалансированного дерева поиска из ключей необходимо сформировать массив (динамический), отсортировать его
Для построения сбалансированного дерева поиска из ключей необходимо сформировать массив (динамический), отсортировать его

void Make_Blns (Tree **p, int n, int k, int *a)
{
if (n
void Make_Blns (Tree **p, int n, int k, int *a)
{
if (n

Алгоритмы обхода дерева
Существуют три алгоритма обхода деревьев, которые естественно следуют из самой
Алгоритмы обхода дерева
Существуют три алгоритма обхода деревьев, которые естественно следуют из самой

Рассмотрим результаты этих обходов на примере записи формулы в виде дерева, т.к. они
Рассмотрим результаты этих обходов на примере записи формулы в виде дерева, т.к. они

Рассмотрим обходы дерева на примере формулы:
(a + b / c) * (d
Рассмотрим обходы дерева на примере формулы:
(a + b / c) * (d

Обход 1 (Left-Root-Right) дает инфиксную запись выражения (без скобок):
a + b / c
Обход 1 (Left-Root-Right) дает инфиксную запись выражения (без скобок):
a + b / c
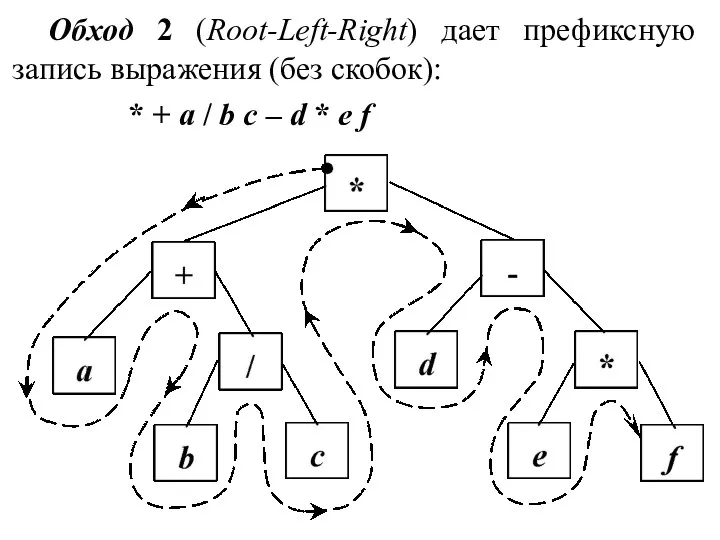
Обход 2 (Root-Left-Right) дает префиксную запись выражения (без скобок):
* + a /
Обход 2 (Root-Left-Right) дает префиксную запись выражения (без скобок):
* + a /
 Information technology in our daily lives
Information technology in our daily lives Основы языка ассемблера
Основы языка ассемблера Области применения компьютерного информационного моделирования
Области применения компьютерного информационного моделирования Микропроцессор
Микропроцессор Культура научной речи
Культура научной речи Технология создания электронного учебника
Технология создания электронного учебника Хранение информации. 10 лекция
Хранение информации. 10 лекция Моделирование как метод познания
Моделирование как метод познания Разработка мобильных приложений. Responsive Web Design
Разработка мобильных приложений. Responsive Web Design Идентификация. Штриховое кодирование
Идентификация. Штриховое кодирование 4 декабря - день информатики в России
4 декабря - день информатики в России Руководство по размещению тестовых заданий в компьютерной программе
Руководство по размещению тестовых заданий в компьютерной программе Позиционирование и продвижение в соцсетях
Позиционирование и продвижение в соцсетях Реформа перехода на новый порядок применения кассовой техники для сферы жилищно-коммунального хозяйства
Реформа перехода на новый порядок применения кассовой техники для сферы жилищно-коммунального хозяйства Создание видеофильма средствами Windows Movie Maker
Создание видеофильма средствами Windows Movie Maker Предмет информатики. Информация, измерение, единицы измерения
Предмет информатики. Информация, измерение, единицы измерения Презентация к уроку по теме: Графический редактор Adobe Photoshop
Презентация к уроку по теме: Графический редактор Adobe Photoshop Создание 3d-модели современного кабинета информатики
Создание 3d-модели современного кабинета информатики Идентификация и установление подлинности
Идентификация и установление подлинности Модельдер және оның тұрлері
Модельдер және оның тұрлері Основные принципы технологии клиент-сервер
Основные принципы технологии клиент-сервер Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile
Создание чат-бота Telegram для обучения мобильной игре PUBG Mobile Презентация Представление чисел в формате с плавающей запятой
Презентация Представление чисел в формате с плавающей запятой Характеристика и оценка возможностей ОС семейства Windows для ПК
Характеристика и оценка возможностей ОС семейства Windows для ПК Информатизация общества. Основы классификации и структурирования информации
Информатизация общества. Основы классификации и структурирования информации Help us find the way to the right
Help us find the way to the right Процесс создания платформы электронной коммерции
Процесс создания платформы электронной коммерции Аддитивные технологии
Аддитивные технологии