- Нелинейные структуры данных. Деревья

Содержание
- 2. Тема 7.1. Линейный список Дерево – иерархическая структура некоторой совокупности элементов. Массивы, массивы указателей и списки
- 3. Тема 7.1. Линейный список Определение дерева имеет рекурсивную природу. Элемент этой структуры данных называется вершиной. Дерево
- 4. Тема 7.1. Линейный список Генеалогическое древо. Представьте себе генеалогическое древо отношений между поколениями: бабушки и дедушки,
- 5. Алгоритм не зависит от формы представления дерева. Идея: любое действие, выполняемое над вершиной, должно быть выполнено
- 6. Когда речь идет о древовидных структурах, следует отличать их абстрактное определение от конкретного способа их реализации
- 7. Составными частями физического представления дерева могут быть массивы, списки, массивы указателей. Представление дерева в виде массива
- 8. Это не слишком эффективный способ. Ведь в рекурсивном алгоритме для каждой вершины делается цикл по всему
- 9. Если не искать, как было сделано выше, потомков, то, может быть, их адреса (или индексы) можно
- 10. Получается быстро, а главное, без дополнительной информации, индекс массива однозначно определяет положение вершины. Но за это
- 11. Наиболее близка «по духу» к дереву списковая структура, однако цепочка элементов в данном случае является не
- 12. #include using namespace std; // Представление дерева в виде разветвляющегося списка struct ltree{ string s; ltree
- 13. Определение ltree поразительно напоминает двусвязный список. Ничего удивительного. Ведь определение структуры задает только факт наличия двух
- 14. Можно подобрать способ представления, в котором физическая структура максимально соответствует логической структуре дерева, т.е. ее внешнему
- 15. Можно провести аналогии между парой «деревья - рекурсивные алгоритмы» и «пространство-время». При работе рекурсивной программы происходит
- 16. Для начала рассмотрим простейшие алгоритмы безотносительно к способам организации данных в дереве. Полный рекурсивный обход дерева
- 17. Даже не вдаваясь в подробности организации данных в дереве, можно сделать предварительные выводы, основываясь на известных
- 18. Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить просмотр всех вершин дерева и
- 19. Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить просмотр всех вершин дерева и
- 20. В первом примере в вычислении максимума от потомков участвует значение в текущей вершине, что однозначно определяет
- 21. Рекурсивный обход позволяет получить другие характеристики дерева, например, передавая в качестве формального параметра текущую «глубину» вершины,
- 22. При поиске в дереве вершины, значение в которой удовлетворяет заданному условию, кроме непосредственно обнаружения вершины нужно
- 23. // Поиск свободной вершины с min глубиной. Ссылки на параметры, общие для всех вершин // lmin
- 24. До сих пор мы рассматривали сохранение в последовательном текстовом потоке данных, хранимых в линейных структурах. Для
- 25. //-------------Сохранение в последовательный поток void save(tree *p, ofstream &fd){ fd val n for (int i=0;i n;i++)
- 26. Рекурсивный обход дерева связан со стеком, который используется рекурсивным алгоритмом для сохранения вызовов. В принципе, стек
- 27. Если же вместо стека применить очередь, то обход дерева будет происходить «по горизонтали». Тогда можно естественным
- 28. Аналогичный алгоритм на основе рекурсивного обхода был рассмотрен выше. Забегая вперед, рассмотрим более эффективный (жадный) алгоритм,
- 30. Скачать презентацию

Тема 7.1. Линейный список
Дерево – иерархическая структура некоторой совокупности элементов.
Массивы,
Тема 7.1. Линейный список
Дерево – иерархическая структура некоторой совокупности элементов.
Массивы,

Тема 7.1. Линейный список
Определение дерева имеет рекурсивную природу. Элемент этой структуры
Тема 7.1. Линейный список
Определение дерева имеет рекурсивную природу. Элемент этой структуры

Тема 7.1. Линейный список
Генеалогическое древо. Представьте себе генеалогическое древо отношений между
Тема 7.1. Линейный список
Генеалогическое древо. Представьте себе генеалогическое древо отношений между

Алгоритм не зависит от формы представления дерева.
Идея: любое действие, выполняемое
Алгоритм не зависит от формы представления дерева.
Идея: любое действие, выполняемое

Когда речь идет о древовидных структурах, следует отличать их абстрактное определение
Когда речь идет о древовидных структурах, следует отличать их абстрактное определение

Составными частями физического представления дерева могут быть массивы, списки, массивы указателей.
Составными частями физического представления дерева могут быть массивы, списки, массивы указателей.

Это не слишком эффективный способ. Ведь в рекурсивном алгоритме для каждой
Это не слишком эффективный способ. Ведь в рекурсивном алгоритме для каждой

Если не искать, как было сделано выше, потомков, то, может быть,
Если не искать, как было сделано выше, потомков, то, может быть,
Для некоторого вида деревьев, как например, с двумя потомками, принять способ размещения, в котором адреса (индексы) потомков вычисляются через адрес (индекс) предка. Если предок имеет индекс n, то два его потомка - 2n и 2n+1 соответственно. Корневая вершина имеет индекс 1. Отсутствующие потомки должны обозначаться специальным значением, -1.
#include
using namespace std;
void scan_2(int A[], int n, int k,int level){ // k – индекс текущей вершины
if (k>=n) return; if (A[k]==-1) return;
cout<<"l="<

Получается быстро, а главное, без дополнительной информации, индекс массива однозначно определяет
Получается быстро, а главное, без дополнительной информации, индекс массива однозначно определяет

Наиболее близка «по духу» к дереву списковая структура, однако цепочка элементов
Наиболее близка «по духу» к дереву списковая структура, однако цепочка элементов

#include
using namespace std;
// Представление дерева в виде разветвляющегося списка
struct ltree{
#include
using namespace std;
// Представление дерева в виде разветвляющегося списка
struct ltree{
ltree *son,*bro; // Указатели на старшего сына
}; // и младшего брата
ltree A={"aa",NULL,NULL}, // Последняя в списке
B={"bb",NULL,&A},
C={"cc",NULL,&B}, // Список потомков - концевых вершин A,B,C
D={"dd",NULL,NULL}, E={"ee",&C,NULL},
F={"ff",&D,&E}, // Список потомков G - вершин F,E
G={"gg",&F,NULL}, *ph = &G;
void scan_l(ltree *p, int level){
if (p==NULL) return;
cout<<"l="<

Определение ltree поразительно напоминает двусвязный список. Ничего удивительного. Ведь определение структуры
Определение ltree поразительно напоминает двусвязный список. Ничего удивительного. Ведь определение структуры

Можно подобрать способ представления, в котором физическая структура максимально соответствует логической
Можно подобрать способ представления, в котором физическая структура максимально соответствует логической
#include
#define N 4
struct tree{
string s;
int n; // Количество потомков в МУ
tree *ch[N]; };
tree H1={"aa",0}, B1={"bb",0}, C1={"cc",0}, D1={"dd",0},
E1={"ee",3,&C1,&B1,&H1}, F1={"ff",0},
G1={"gg",3,&F1,&E1,&D1}, *ph1 = &G1;
void scan(tree *p, int level){
if (p==NULL) return;
std::cout<<"l="<

Можно провести аналогии между парой «деревья - рекурсивные алгоритмы» и «пространство-время».
Можно провести аналогии между парой «деревья - рекурсивные алгоритмы» и «пространство-время».

Для начала рассмотрим простейшие алгоритмы безотносительно к способам организации данных в
Для начала рассмотрим простейшие алгоритмы безотносительно к способам организации данных в

Даже не вдаваясь в подробности организации данных в дереве, можно сделать
Даже не вдаваясь в подробности организации данных в дереве, можно сделать

Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить
Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить

Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить
Рекурсивное определение дерева и рекурсивный же алгоритм его обхода позволяют выполнить

В первом примере в вычислении максимума от потомков участвует значение в
В первом примере в вычислении максимума от потомков участвует значение в

Рекурсивный обход позволяет получить другие характеристики дерева, например, передавая в качестве
Рекурсивный обход позволяет получить другие характеристики дерева, например, передавая в качестве

При поиске в дереве вершины, значение в которой удовлетворяет заданному условию,
При поиске в дереве вершины, значение в которой удовлетворяет заданному условию,

// Поиск свободной вершины с min глубиной. Ссылки на параметры, общие
// Поиск свободной вершины с min глубиной. Ссылки на параметры, общие

До сих пор мы рассматривали сохранение в последовательном текстовом потоке данных,
До сих пор мы рассматривали сохранение в последовательном текстовом потоке данных,
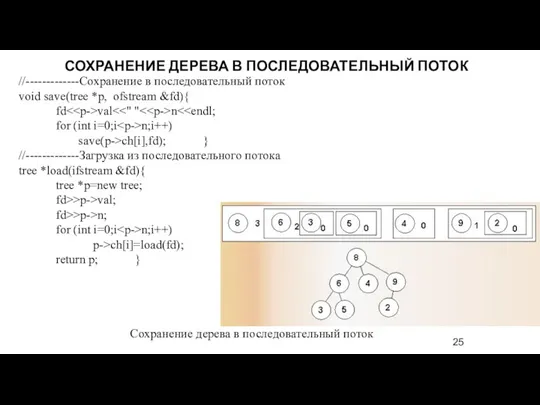
//-------------Сохранение в последовательный поток
void save(tree *p, ofstream &fd){
fd<val<<" "<n< for
//-------------Сохранение в последовательный поток
void save(tree *p, ofstream &fd){
fd<

Рекурсивный обход дерева связан со стеком, который используется рекурсивным алгоритмом для
Рекурсивный обход дерева связан со стеком, который используется рекурсивным алгоритмом для

Если же вместо стека применить очередь, то обход дерева будет происходить
Если же вместо стека применить очередь, то обход дерева будет происходить

Аналогичный алгоритм на основе рекурсивного обхода был рассмотрен выше. Забегая вперед,
Аналогичный алгоритм на основе рекурсивного обхода был рассмотрен выше. Забегая вперед,
 2 февраля 2010 года. Городской конкурс Учитель года. 7 класс. Электронные таблицы. Формулы.
2 февраля 2010 года. Городской конкурс Учитель года. 7 класс. Электронные таблицы. Формулы. Технологии построения web-интерфейсов
Технологии построения web-интерфейсов Библиографическое описание
Библиографическое описание Компьютер и здоровье школьников
Компьютер и здоровье школьников Instagram
Instagram Особливості комп’ютерних програм, як об’єкта авторського права
Особливості комп’ютерних програм, як об’єкта авторського права Модель и моделирование
Модель и моделирование Types and Components of Computer Systems
Types and Components of Computer Systems TopLabs. Introduction to responsive design
TopLabs. Introduction to responsive design Процедуры обработки пиксельной (точечной) графики
Процедуры обработки пиксельной (точечной) графики Systemy informacyjne w zarządzaniu
Systemy informacyjne w zarządzaniu Учителя, родители и дети в цифровом пространстве
Учителя, родители и дети в цифровом пространстве Основы реляционной алгебры
Основы реляционной алгебры Верстальщик сайтов
Верстальщик сайтов Безопасный интернет
Безопасный интернет Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС
Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС Новогодняя открытка
Новогодняя открытка Оценка официальных пабликов Хабаровского края. Экспертное интервью
Оценка официальных пабликов Хабаровского края. Экспертное интервью Дидактические свойства и функции Microsoft Office
Дидактические свойства и функции Microsoft Office Влияние сети Интернет на состояние психологичского здоровья студенческой молодежи
Влияние сети Интернет на состояние психологичского здоровья студенческой молодежи Информация и информационные процессы
Информация и информационные процессы Виды баз данных БД
Виды баз данных БД Кодовые таблицы
Кодовые таблицы Комбинаторика и программирование
Комбинаторика и программирование Источники географической информации
Источники географической информации LDI Plus Presentation EN
LDI Plus Presentation EN Алгоритмы. Свойства алгоритма
Алгоритмы. Свойства алгоритма Сервисы Интернет. Компьютерные телекоммуникации
Сервисы Интернет. Компьютерные телекоммуникации