- Операция объединения merge. Категории итераторов. (Лекция 3)

Содержание
- 2. Алгоритм merge (объединение) Рассмотрим операцию объединения a и b в c : Алгоритм merge можно использовать
- 3. Объединение вектора и массива в список #include #include #include #include #include using namespace std; int merge()
- 4. Замечания Здесь также нужно использовать итератор вставки, если хотим писать в с в режиме вставки. В
- 5. Типы, определенные пользователем Кроме стандартных типов, таких как int, в контейнерах STL можно хранить типы, определенные
- 6. Типы, определенные пользователем // merge2.срр: Объединяем записи, используя // имена в качестве ключей. #include #include #include
- 7. В качестве ключей используются имена int merge2() { entry a[3] = {{10, "Betty"}, {11, "James"}, {80,
- 8. В качестве ключей используются числа Чтобы числа шли в порядке возрастания, их нужно было бы перечислить
- 9. В качестве ключей используются числа Результат: 10 Betty 11 James 16 Fred 20 William Jim Функция
- 10. Категории итераторов Мы можем использовать алгоритм sort (произвольный доступ) для массивов, векторов и двусторонних очередей, но
- 11. Предположим, что i и j - итераторы одного вида. Тогда, основные операции, выполняемые с любым итератором:
- 12. Пусть i – итератор; просмотр элементов контейнера записывается так: for (i = first; i != last;
- 13. Таблица операций, применимых к итераторам х - переменная того же типа, что и элементы рассматриваемого контейнера,
- 14. Категории итераторов Входные (input) итераторы используются для чтения значений из контейнера, аналогично вводу данных из потока
- 15. Категории итераторов Итераторы произвольного доступа (random access) получили, добавив к двунаправленному итератору операции +, -, +=,
- 16. Демонстрация итераторов произвольного доступа: int а[3] = {5, 8, 2}; vector v(a, a+3); vector :: iterator
- 17. Категории итераторов и алгоритмы Алгоритм find требует исключительно тех операций над итераторами, которые определены для входных
- 18. Категории итераторов и алгоритмы Итераторы двунаправленного доступа возвращаются несколькими контейнерами STL: list, set, multiset, map и
- 19. Потоковые итераторы Можно применить алгоритм сору для вывода: #include const int N = 4; int a[N]
- 20. Потоковые итераторы Программа читает из стандартного потока cin числа, вводимые пользователем и дублирует их на экране.
- 21. Операции с итераторами К итераторам произвольного доступа можно применять арифметические операции: int n, dist; // i
- 22. Алгоритм replace replace позволяет найти все элементы с определенным значением в заданном контейнере и заменить их
- 23. Алгоритм reverse reverse позволяет заменить последовательность на обратную ей. Этот алгоритм требует двунаправленных итераторов, которые предоставляют
- 24. Краткие итоги Рассмотрели алгоритмы: 1. merge() – объединение элементов различных контейнеров. merge(a.begin(), a.end(), b, b+6, inserter(c,
- 25. Краткие итоги 2. replace() – замена одних элементов на другие replace (str, str+n, 'b', ‘q'); 3.
- 27. Скачать презентацию
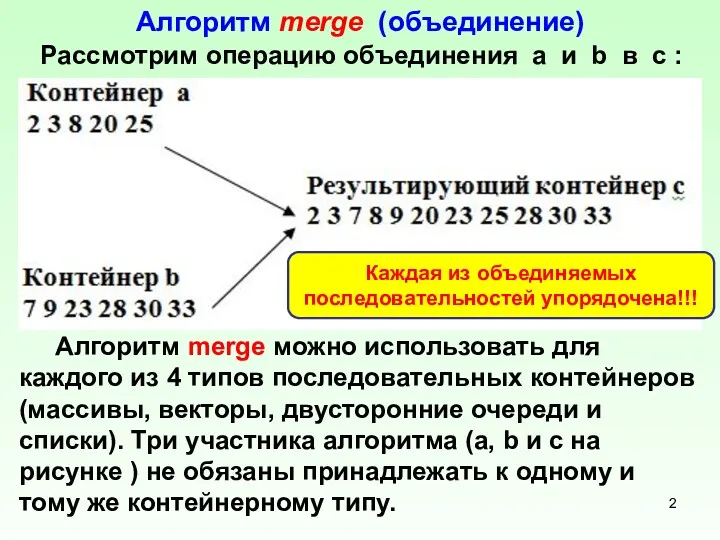
Алгоритм merge (объединение)
Рассмотрим операцию объединения a и b в c
Алгоритм merge (объединение)
Рассмотрим операцию объединения a и b в c

Объединение вектора и массива в список
#include
#include
#include
#include
Объединение вектора и массива в список
#include
#include
#include
#include

Замечания
Здесь также нужно использовать итератор вставки, если хотим писать в
Замечания
Здесь также нужно использовать итератор вставки, если хотим писать в

Типы, определенные пользователем
Кроме стандартных типов, таких как int, в контейнерах
Типы, определенные пользователем
Кроме стандартных типов, таких как int, в контейнерах

Типы, определенные пользователем
// merge2.срр: Объединяем записи, используя // имена в качестве
Типы, определенные пользователем
// merge2.срр: Объединяем записи, используя // имена в качестве
![В качестве ключей используются имена int merge2() { entry a[3]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167696/slide-6.jpg)
В качестве ключей используются имена
int merge2()
{ entry a[3] = {{10, "Betty"},
В качестве ключей используются имена
int merge2()
{ entry a[3] = {{10, "Betty"},

В качестве ключей используются числа
Чтобы числа шли в порядке возрастания,
В качестве ключей используются числа
Чтобы числа шли в порядке возрастания,

В качестве ключей используются числа
Результат:
10 Betty
11 James
16 Fred
20 William
Jim
В качестве ключей используются числа
Результат:
10 Betty
11 James
16 Fred
20 William
Jim

Категории итераторов
Мы можем использовать алгоритм sort (произвольный доступ) для массивов,
Категории итераторов
Мы можем использовать алгоритм sort (произвольный доступ) для массивов,

Предположим, что i и j - итераторы одного вида.
Тогда, основные операции,
Предположим, что i и j - итераторы одного вида.
Тогда, основные операции,

Пусть i – итератор; просмотр элементов контейнера записывается так:
for (i
Пусть i – итератор; просмотр элементов контейнера записывается так:
for (i

Таблица операций, применимых к итераторам
х - переменная того же типа, что
Таблица операций, применимых к итераторам
х - переменная того же типа, что

Категории итераторов
Входные (input) итераторы используются для чтения значений из контейнера, аналогично
Категории итераторов
Входные (input) итераторы используются для чтения значений из контейнера, аналогично

Категории итераторов
Итераторы произвольного доступа (random
access) получили, добавив к двунаправленному
Категории итераторов
Итераторы произвольного доступа (random
access) получили, добавив к двунаправленному
![Демонстрация итераторов произвольного доступа: int а[3] = {5, 8, 2};](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/167696/slide-15.jpg)
Демонстрация итераторов произвольного доступа:
int а[3] = {5, 8, 2}; vector
Демонстрация итераторов произвольного доступа:
int а[3] = {5, 8, 2}; vector

Категории итераторов и алгоритмы
Алгоритм find требует исключительно тех операций над
Категории итераторов и алгоритмы
Алгоритм find требует исключительно тех операций над

Категории итераторов и алгоритмы
Итераторы двунаправленного доступа возвращаются несколькими контейнерами STL:
Категории итераторов и алгоритмы
Итераторы двунаправленного доступа возвращаются несколькими контейнерами STL:

Потоковые итераторы
Можно применить алгоритм сору для вывода:
#include
const int
Потоковые итераторы
Можно применить алгоритм сору для вывода:
#include
const int

Потоковые итераторы
Программа читает из стандартного потока cin числа, вводимые пользователем
Потоковые итераторы
Программа читает из стандартного потока cin числа, вводимые пользователем

Операции с итераторами
К итераторам произвольного доступа можно применять арифметические операции:
int
Операции с итераторами
К итераторам произвольного доступа можно применять арифметические операции:
int

Алгоритм replace
replace позволяет найти все элементы с определенным значением в
Алгоритм replace
replace позволяет найти все элементы с определенным значением в

Алгоритм reverse
reverse позволяет заменить последовательность на обратную ей. Этот алгоритм
Алгоритм reverse
reverse позволяет заменить последовательность на обратную ей. Этот алгоритм

Краткие итоги
Рассмотрели алгоритмы:
1. merge() – объединение элементов различных контейнеров.
merge(a.begin(),
Краткие итоги
Рассмотрели алгоритмы:
1. merge() – объединение элементов различных контейнеров.
merge(a.begin(),

Краткие итоги
2. replace() – замена одних элементов на другие
replace (str,
Краткие итоги
2. replace() – замена одних элементов на другие
replace (str,
 Прямая аренда от собственника!
Прямая аренда от собственника! Системою управління базами даних MS ACCESS
Системою управління базами даних MS ACCESS Введение в объектноориентированное программирование и классы
Введение в объектноориентированное программирование и классы Средства создания презентаций
Средства создания презентаций Основные понятия. Данные: поля и константы. Методы. Параметры методов. Конструкторы. Свойства. Лекция 11-12
Основные понятия. Данные: поля и константы. Методы. Параметры методов. Конструкторы. Свойства. Лекция 11-12 Тестування програмного забезпечення
Тестування програмного забезпечення Основы информационной безопасности критически важных объектов. Базовая терминология
Основы информационной безопасности критически важных объектов. Базовая терминология Безопасный интернет
Безопасный интернет Медиапланирование как основа деятельности пресс-службы
Медиапланирование как основа деятельности пресс-службы Web UI Standards
Web UI Standards Искусственный интеллект
Искусственный интеллект Компьютерная графика и анимация
Компьютерная графика и анимация История развития вычислительной техники
История развития вычислительной техники Ai2 APP Inventor. Переводчик
Ai2 APP Inventor. Переводчик Формы. Построение формы
Формы. Построение формы Алгоритмы внутренней сортировки. (Тема 1.2)
Алгоритмы внутренней сортировки. (Тема 1.2) презентация Моделирование. Введение в теорию графов
презентация Моделирование. Введение в теорию графов Welcome to CAD/CAM services
Welcome to CAD/CAM services Расчет информационного объема
Расчет информационного объема Переход от инфологического моделирования к моделям данных и знаний. Логико-лингвистические модели представления знаний
Переход от инфологического моделирования к моделям данных и знаний. Логико-лингвистические модели представления знаний Программирование на языке Паскаль. Часть II
Программирование на языке Паскаль. Часть II Роль автоматизированных систем в правовой сфере
Роль автоматизированных систем в правовой сфере Python programming
Python programming Microsoft Word 2003
Microsoft Word 2003 Техническое задание для создания сайта. Описание структуры
Техническое задание для создания сайта. Описание структуры Операционная система. Назначение и основные функции
Операционная система. Назначение и основные функции Защита информации. Урок-Игра Счастливый случай
Защита информации. Урок-Игра Счастливый случай Information and communications technology
Information and communications technology