- Основы MPI

Содержание
- 2. Содержание Введение MPI: Основные понятия и определения Основы MPI Инициализация и завершение программы MPI Определение числа
- 3. ВВЕДЕНИЕ Основы MPI Н. Новгород, 2018
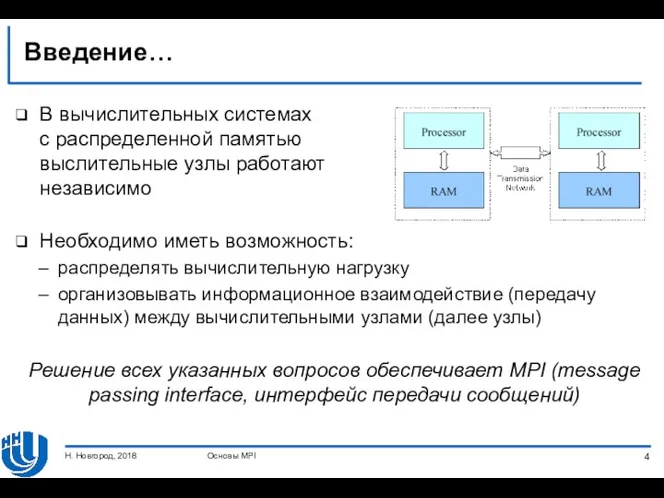
- 4. Введение… В вычислительных системах с распределенной памятью выслительные узлы работают независимо Необходимо иметь возможность: распределять вычислительную
- 5. Введение… При использовании MPI для решения задачи разрабатывается одна программа, которая запускается на выполнение одновременно на
- 6. Введение… В MPI существует множество операций передачи данных: Поддерживаются различные способы пересылки данных, Реализованы практически все
- 7. Введение… Что такое MPI? MPI – это стандарт организации передачи сообщений MPI – это программное обеспечение,
- 8. Введение… Преимущества MPI MPI позволяет в значительной степени уменьшить проблемы переносимости параллельных программ между различными компьютерными
- 9. Введение История MPI (разработка стандарта MPI ведется международным консорциумом MPI Forum) 1992 год Начало исследований по
- 10. MPI: ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ Основы MPI Н. Новгород, 2018
- 11. MPI: основные понятия и определения ... Концепция параллельной программы В рамках MPI под параллельной программой понимается
- 12. MPI: основные понятия и определения ... В основе MPI лежат четыре основные концепции: Тип операций передачи
- 13. MPI: основные понятия и определения ... Операции передачи данных Операции передачи данных составляют основу MPI Среди
- 14. MPI: основные понятия и определения ... Коммуникаторы Коммуникатор в MPI – служебный объект, который объединяет в
- 15. MPI: основные понятия и определения ... Коммуникаторы Во время вычислений могут быть созданы новые коммуникаторы, а
- 16. MPI: основные понятия и определения … Типы данных В любой операции передачи данных MPI необходимо указывать
- 17. MPI: основные понятия и определения Виртуальные топологии Логическая топология линий связи между процессами представляет собой полный
- 18. ОСНОВЫ MPI Основы MPI Н. Новгород, 2018 Инициализация и завершение MPI программы Определение числа и ранга
- 19. Основы MPI… Инициализация и завершение MPI программы Первая вызываемая функция MPI должна быть (служит для инициализации
- 20. Основы MPI… Инициализация и завершение MPI программы Структура параллельной программы на основе MPI должна выглядеть следующим
- 21. Основы MPI… Определение числа и ранга процессов Количество процессов в выполняемой параллельной программе может быть получено
- 22. Основы MPI… Определение числа и ранга процессов Как правило, функции MPI_Comm_size() и MPI_Comm_rank() вызываются сразу после
- 23. Основы MPI… Определение числа и ранга процессов Коммуникатор MPI_COMM_WORLD создается по умолчанию и представляет все процессы
- 24. Основы MPI… Передача сообщений Для передачи данных процесс-отправитель должен выполнить функцию Основы MPI Н. Новгород, 2018
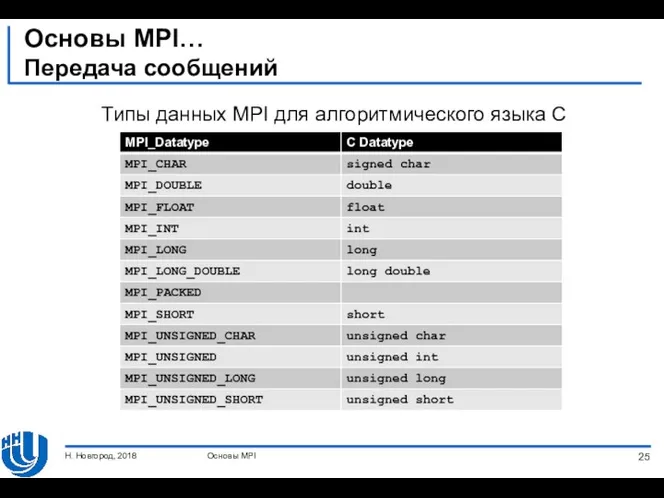
- 25. Основы MPI… Передача сообщений Типы данных MPI для алгоритмического языка C Основы MPI Н. Новгород, 2018
- 26. Основы MPI… Передача сообщений Отправляемое сообщение определяется путем указания на блок памяти (buffer), который содержит сообщение.
- 27. Основы MPI… Получение сообщений Для приема данных процесс-получатель должен выполнить функцию Основы MPI Н. Новгород, 2018
- 28. Основы MPI… Получение сообщений Буфер памяти должен быть достаточным для приема данных, а типы элементов отправленного
- 29. Основы MPI… Получение сообщений Параметр status позволяет определить ряд характеристик полученного сообщения Функция возвращает в переменной
- 30. Основы MPI… Получение сообщений Функция MPI_Recv() является блокирующей для процесса-получателя Выполнение процесса приостанавливается до тех пор,
- 31. Основы MPI… Оценка времени выполнения MPI программы Для оценки ускорения параллельной программы необходимо уметь получать время
- 32. ПЕРВАЯ ПРОГРАММА НА MPI Основы MPI Н. Новгород, 2018
- 33. Первая параллельная MPI программа… MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &ProcNum); MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank); if (ProcRank == 0) { printf("Hello
- 34. Первая параллельная MPI программа… Каждый процесс узнает свой ранг, после чего все операции в программе разделяются
- 35. Первая параллельная MPI программа… Следует отметить, что порядок приема сообщений не определен и зависит от условий
- 36. Первая параллельная MPI программа Все функции MPI возвращают код завершения Если функция успешно завершена, код возврата
- 37. Основы MPI ВВЕДЕНИЕ В КОЛЛЕКТИВНУЮ ПЕРЕДАЧУ ДАННЫХ Н. Новгород, 2018
- 38. Введение в коллективную передачу данных… Проблема суммирования Рассмотрим задачу суммирования элементов вектора x Для разработки параллельной
- 39. Введение в коллективную передачу данных… Передача данных Предположим, что мы имеем p процессов и n %
- 40. Введение в коллективную передачу данных… Передача данных Для обеспечения эффективной передачи можно использовать следующую функцию MPI
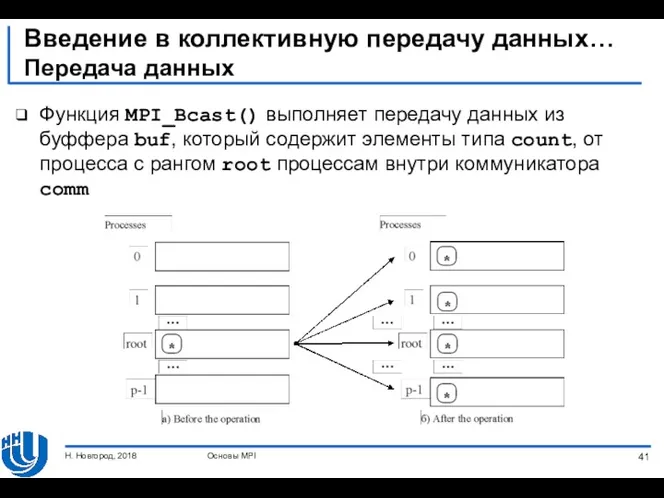
- 41. Введение в коллективную передачу данных… Передача данных Функция MPI_Bcast() выполняет передачу данных из буффера buf, который
- 42. Введение в коллективную передачу данных… Передача данных Функция MPI_Bcast() – это коллективная операция, ее вызов должен
- 43. Введение в коллективную передачу данных… Распределение данных и вычислений Чтобы распределить вектор x среди процессов, мы
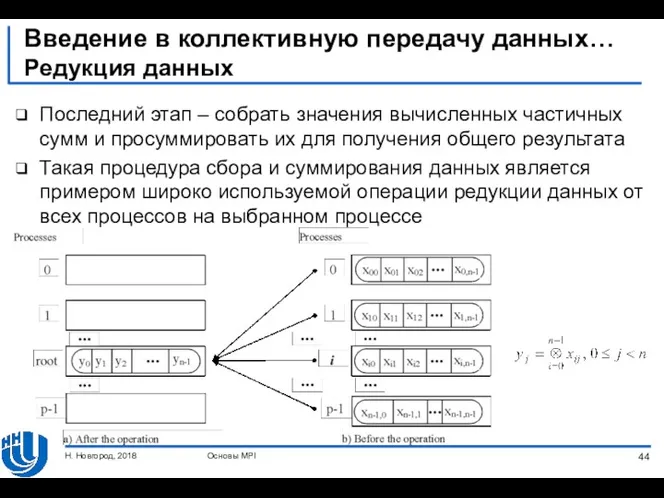
- 44. Введение в коллективную передачу данных… Редукция данных Последний этап – собрать значения вычисленных частичных сумм и
- 45. Введение в коллективную передачу данных… Редукция данных Для «редукции» данных со всех процессов на выбранном может
- 46. Введение в коллективную передачу данных… Редукция данных Основные типы операций MPI для редукции данных Основы MPI
- 47. Введение в коллективную передачу данных… Редукция данных Функция MPI_Reduce() является коллективной операцией, ее вызов должен выполняться
- 48. Введение в коллективную передачу данных… Сжатие данных Пример вычисления суммы значений Основы MPI Н. Новгород, 2018
- 49. Итоги Рассмотрен ряд концепций и определений, которые являются основными для стандарта MPI (параллельная программа, операции передачи
- 50. Упражнения Разработать программу для нахождения минимального (максимального) значения среди элементов вектора Разработать программу вычисления скалярного произведения
- 52. Скачать презентацию

Содержание
Введение
MPI: Основные понятия и определения
Основы MPI
Инициализация и завершение программы MPI
Определение числа
Содержание
Введение
MPI: Основные понятия и определения
Основы MPI
Инициализация и завершение программы MPI
Определение числа

ВВЕДЕНИЕ
Основы MPI
Н. Новгород, 2018
ВВЕДЕНИЕ
Основы MPI
Н. Новгород, 2018
Введение…
В вычислительных системах
с распределенной памятью
выслительные узлы работают
независимо
Необходимо иметь
Введение…
В вычислительных системах
с распределенной памятью
выслительные узлы работают
независимо
Необходимо иметь

Введение…
При использовании MPI для решения задачи разрабатывается одна программа, которая запускается
Введение…
При использовании MPI для решения задачи разрабатывается одна программа, которая запускается

Введение…
В MPI существует множество операций передачи данных:
Поддерживаются различные способы пересылки данных,
Реализованы
Введение…
В MPI существует множество операций передачи данных:
Поддерживаются различные способы пересылки данных,
Реализованы

Введение…
Что такое MPI?
MPI – это стандарт организации передачи сообщений
MPI – это
Введение…
Что такое MPI?
MPI – это стандарт организации передачи сообщений
MPI – это

Введение…
Преимущества MPI
MPI позволяет в значительной степени уменьшить проблемы переносимости параллельных программ
Введение…
Преимущества MPI
MPI позволяет в значительной степени уменьшить проблемы переносимости параллельных программ

Введение
История MPI (разработка стандарта MPI ведется международным консорциумом MPI Forum)
1992 год
Введение
История MPI (разработка стандарта MPI ведется международным консорциумом MPI Forum)
1992 год

MPI: ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Основы MPI
Н. Новгород, 2018
MPI: ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Основы MPI
Н. Новгород, 2018

MPI: основные понятия и определения ...
Концепция параллельной программы
В рамках MPI под
MPI: основные понятия и определения ...
Концепция параллельной программы
В рамках MPI под

MPI: основные понятия и определения ...
В основе MPI лежат четыре основные
MPI: основные понятия и определения ...
В основе MPI лежат четыре основные

MPI: основные понятия и определения ...
Операции передачи данных
Операции передачи данных составляют
MPI: основные понятия и определения ...
Операции передачи данных
Операции передачи данных составляют

MPI: основные понятия и определения ...
Коммуникаторы
Коммуникатор в MPI – служебный объект,
MPI: основные понятия и определения ...
Коммуникаторы
Коммуникатор в MPI – служебный объект,

MPI: основные понятия и определения ...
Коммуникаторы
Во время вычислений могут быть созданы
MPI: основные понятия и определения ...
Коммуникаторы
Во время вычислений могут быть созданы

MPI: основные понятия и определения …
Типы данных
В любой операции передачи данных
MPI: основные понятия и определения …
Типы данных
В любой операции передачи данных

MPI: основные понятия и определения
Виртуальные топологии
Логическая топология линий связи между процессами
MPI: основные понятия и определения
Виртуальные топологии
Логическая топология линий связи между процессами

ОСНОВЫ MPI
Основы MPI
Н. Новгород, 2018
Инициализация и завершение MPI программы
Определение числа и
ОСНОВЫ MPI
Основы MPI
Н. Новгород, 2018
Инициализация и завершение MPI программы
Определение числа и

Основы MPI…
Инициализация и завершение MPI программы
Первая вызываемая функция MPI должна быть
(служит
Основы MPI…
Инициализация и завершение MPI программы
Первая вызываемая функция MPI должна быть
(служит

Основы MPI…
Инициализация и завершение MPI программы
Структура параллельной программы на основе MPI
Основы MPI…
Инициализация и завершение MPI программы
Структура параллельной программы на основе MPI

Основы MPI…
Определение числа и ранга процессов
Количество процессов в выполняемой параллельной программе
Основы MPI…
Определение числа и ранга процессов
Количество процессов в выполняемой параллельной программе

Основы MPI…
Определение числа и ранга процессов
Как правило, функции MPI_Comm_size() и
Основы MPI…
Определение числа и ранга процессов
Как правило, функции MPI_Comm_size() и

Основы MPI…
Определение числа и ранга процессов
Коммуникатор MPI_COMM_WORLD создается по умолчанию
Основы MPI…
Определение числа и ранга процессов
Коммуникатор MPI_COMM_WORLD создается по умолчанию

Основы MPI…
Передача сообщений
Для передачи данных процесс-отправитель должен выполнить функцию
Основы MPI
Н.
Основы MPI…
Передача сообщений
Для передачи данных процесс-отправитель должен выполнить функцию
Основы MPI
Н.
Основы MPI…
Передача сообщений
Типы данных MPI для алгоритмического языка C
Основы MPI
Н.
Основы MPI…
Передача сообщений
Типы данных MPI для алгоритмического языка C
Основы MPI
Н.

Основы MPI…
Передача сообщений
Отправляемое сообщение определяется путем указания на блок памяти
Основы MPI…
Передача сообщений
Отправляемое сообщение определяется путем указания на блок памяти

Основы MPI…
Получение сообщений
Для приема данных процесс-получатель должен выполнить функцию
Основы MPI
Н.
Основы MPI…
Получение сообщений
Для приема данных процесс-получатель должен выполнить функцию
Основы MPI
Н.

Основы MPI…
Получение сообщений
Буфер памяти должен быть достаточным для приема данных,
Основы MPI…
Получение сообщений
Буфер памяти должен быть достаточным для приема данных,

Основы MPI…
Получение сообщений
Параметр status позволяет определить ряд характеристик полученного сообщения
Функция
возвращает
Основы MPI…
Получение сообщений
Параметр status позволяет определить ряд характеристик полученного сообщения
Функция
возвращает

Основы MPI…
Получение сообщений
Функция MPI_Recv() является блокирующей для процесса-получателя
Выполнение процесса приостанавливается
Основы MPI…
Получение сообщений
Функция MPI_Recv() является блокирующей для процесса-получателя
Выполнение процесса приостанавливается

Основы MPI…
Оценка времени выполнения MPI программы
Для оценки ускорения параллельной программы необходимо
Основы MPI…
Оценка времени выполнения MPI программы
Для оценки ускорения параллельной программы необходимо

ПЕРВАЯ ПРОГРАММА НА MPI
Основы MPI
Н. Новгород, 2018
ПЕРВАЯ ПРОГРАММА НА MPI
Основы MPI
Н. Новгород, 2018

Первая параллельная MPI программа…
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank);
if
Первая параллельная MPI программа…
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &ProcNum);
MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank);
if

Первая параллельная MPI программа…
Каждый процесс узнает свой ранг, после чего все
Первая параллельная MPI программа…
Каждый процесс узнает свой ранг, после чего все

Первая параллельная MPI программа…
Следует отметить, что порядок приема сообщений не определен
Первая параллельная MPI программа…
Следует отметить, что порядок приема сообщений не определен

Первая параллельная MPI программа
Все функции MPI возвращают код завершения
Если функция успешно
Первая параллельная MPI программа
Все функции MPI возвращают код завершения
Если функция успешно

Основы MPI
ВВЕДЕНИЕ В КОЛЛЕКТИВНУЮ ПЕРЕДАЧУ ДАННЫХ
Н. Новгород, 2018
Основы MPI
ВВЕДЕНИЕ В КОЛЛЕКТИВНУЮ ПЕРЕДАЧУ ДАННЫХ
Н. Новгород, 2018

Введение в коллективную передачу данных…
Проблема суммирования
Рассмотрим задачу суммирования элементов вектора x
Для
Введение в коллективную передачу данных…
Проблема суммирования
Рассмотрим задачу суммирования элементов вектора x
Для

Введение в коллективную передачу данных…
Передача данных
Предположим, что мы имеем p процессов
Введение в коллективную передачу данных…
Передача данных
Предположим, что мы имеем p процессов

Введение в коллективную передачу данных…
Передача данных
Для обеспечения эффективной передачи можно использовать
Введение в коллективную передачу данных…
Передача данных
Для обеспечения эффективной передачи можно использовать
Введение в коллективную передачу данных…
Передача данных
Функция MPI_Bcast() выполняет передачу данных из
Введение в коллективную передачу данных…
Передача данных
Функция MPI_Bcast() выполняет передачу данных из

Введение в коллективную передачу данных…
Передача данных
Функция MPI_Bcast() – это коллективная операция,
Введение в коллективную передачу данных…
Передача данных
Функция MPI_Bcast() – это коллективная операция,

Введение в коллективную передачу данных…
Распределение данных и вычислений
Чтобы распределить вектор x
Введение в коллективную передачу данных…
Распределение данных и вычислений
Чтобы распределить вектор x
Введение в коллективную передачу данных…
Редукция данных
Последний этап – собрать значения вычисленных
Введение в коллективную передачу данных…
Редукция данных
Последний этап – собрать значения вычисленных

Введение в коллективную передачу данных…
Редукция данных
Для «редукции» данных со всех процессов
Введение в коллективную передачу данных…
Редукция данных
Для «редукции» данных со всех процессов
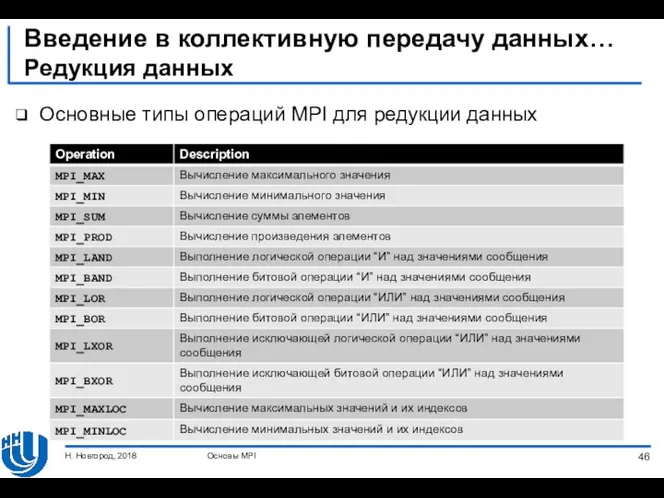
Введение в коллективную передачу данных…
Редукция данных
Основные типы операций MPI для редукции
Введение в коллективную передачу данных…
Редукция данных
Основные типы операций MPI для редукции

Введение в коллективную передачу данных…
Редукция данных
Функция MPI_Reduce() является коллективной операцией, ее
Введение в коллективную передачу данных…
Редукция данных
Функция MPI_Reduce() является коллективной операцией, ее
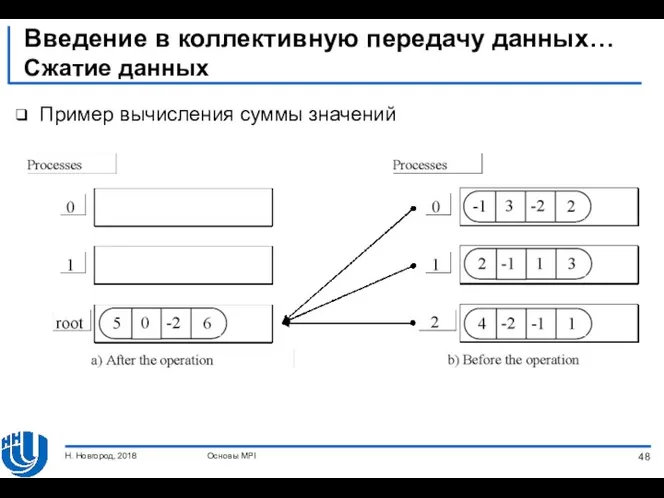
Введение в коллективную передачу данных…
Сжатие данных
Пример вычисления суммы значений
Основы MPI
Н. Новгород,
Введение в коллективную передачу данных…
Сжатие данных
Пример вычисления суммы значений
Основы MPI
Н. Новгород,

Итоги
Рассмотрен ряд концепций и определений, которые являются основными для стандарта MPI
Итоги
Рассмотрен ряд концепций и определений, которые являются основными для стандарта MPI

Упражнения
Разработать программу для нахождения минимального (максимального) значения среди элементов вектора
Разработать программу
Упражнения
Разработать программу для нахождения минимального (максимального) значения среди элементов вектора
Разработать программу
 Chapter 7 - C Pointers
Chapter 7 - C Pointers Introduction to computer systems. Architecture of computer systems. Компьютерлік жүйелерге кіpicne
Introduction to computer systems. Architecture of computer systems. Компьютерлік жүйелерге кіpicne Информационная безопасность
Информационная безопасность Методы и стандарты оценки защищенности компьютерных систем
Методы и стандарты оценки защищенности компьютерных систем Игровая программа для учащихся 7-8 классов Казино безопасности
Игровая программа для учащихся 7-8 классов Казино безопасности Этапы создания программного продукта с нуля на примере разработки мобильного приложения ВДругТакси
Этапы создания программного продукта с нуля на примере разработки мобильного приложения ВДругТакси Прямое и стилевое форматирование текста
Прямое и стилевое форматирование текста Функциональные модули сетей SDH
Функциональные модули сетей SDH Кібербезпека. Поняття кібербезпеки
Кібербезпека. Поняття кібербезпеки Урок по теме: Практическая работаПостроение диаграмм различных типов в табличном процессоре Open Office org Calc
Урок по теме: Практическая работаПостроение диаграмм различных типов в табличном процессоре Open Office org Calc Case – оператор выбора
Case – оператор выбора Презентация тренинга Монтаж по крупности
Презентация тренинга Монтаж по крупности Глобальные сети
Глобальные сети Основные понятия кибернетики и информатики
Основные понятия кибернетики и информатики Intro To AngularJS
Intro To AngularJS Какие бывают чатботы и как можно использовать их для автоматизации
Какие бывают чатботы и как можно использовать их для автоматизации Применение ГИС для целей организации использования земли
Применение ГИС для целей организации использования земли Введение в теорию информации и кодирования
Введение в теорию информации и кодирования Оптимізація топології гетерогенної комп’ютерної мережі навчального закладу
Оптимізація топології гетерогенної комп’ютерної мережі навчального закладу Процесс создания компьютерной техники
Процесс создания компьютерной техники Проектирование метеостанции на микроконтроллере Atmega 328
Проектирование метеостанции на микроконтроллере Atmega 328 Презентация 7 чудес нашего города
Презентация 7 чудес нашего города Операции арифметические, сравнения, логические и поразрядные. Лекция 10
Операции арифметические, сравнения, логические и поразрядные. Лекция 10 Алгебраические структуры: группы, кольца, поля
Алгебраические структуры: группы, кольца, поля Передача информации. Виды информационных процессов
Передача информации. Виды информационных процессов Интеллектуальные информационные системы. Экспертные системы
Интеллектуальные информационные системы. Экспертные системы ИКТ. Перволого. 1 класс.Деревенский пейзаж
ИКТ. Перволого. 1 класс.Деревенский пейзаж Microsoft word 2010. Элементы текста. Форматирование символов. Урок 2
Microsoft word 2010. Элементы текста. Форматирование символов. Урок 2