- Основы технологии CUDA. Работа с памятью

Содержание
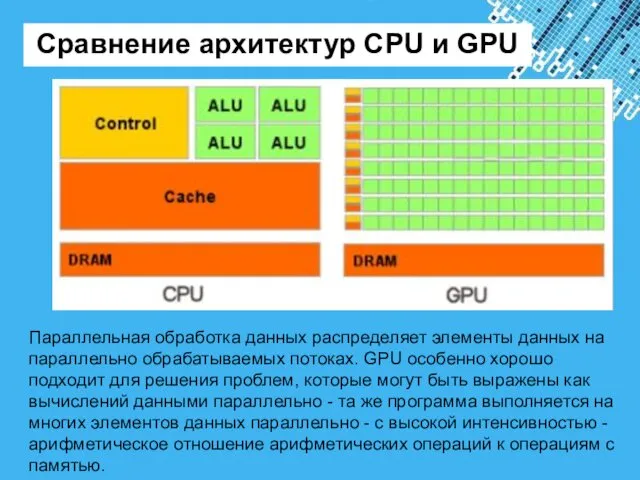
- 2. Сравнение архитектур CPU и GPU Параллельная обработка данных распределяет элементы данных на параллельно обрабатываемых потоках. GPU
- 3. Вычислительная модель GPU Двумерная блочная структура
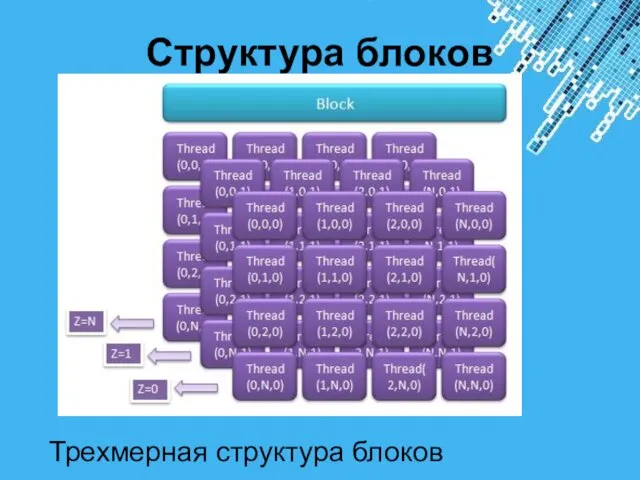
- 4. Структура блоков Трехмерная структура блоков
- 5. Подключаемые библиотеки #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include
- 6. Оценка затраченного на вычисления времени cudaEvent_t start, stop; float gpuTime; cudaEventCreate( &start ); cudaEventCreate( &stop );
- 7. О компоновке нитей и блоков #define DGX 8 #define DGY 32 #define DBX 8 #define DBY
- 8. Отладка программ Функции из CUDA runtime API могут возвращать различные коды ошибок. Можно использовать следующий макрос
- 9. Типы памяти
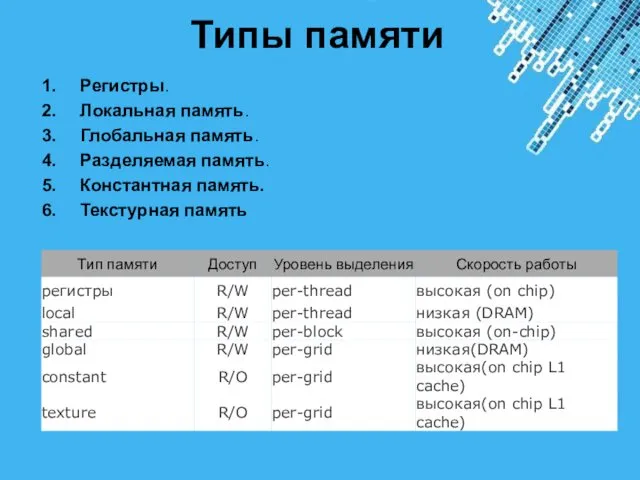
- 10. Типы памяти Регистры. Локальная память. Глобальная память. Разделяемая память. Константная память. Текстурная память
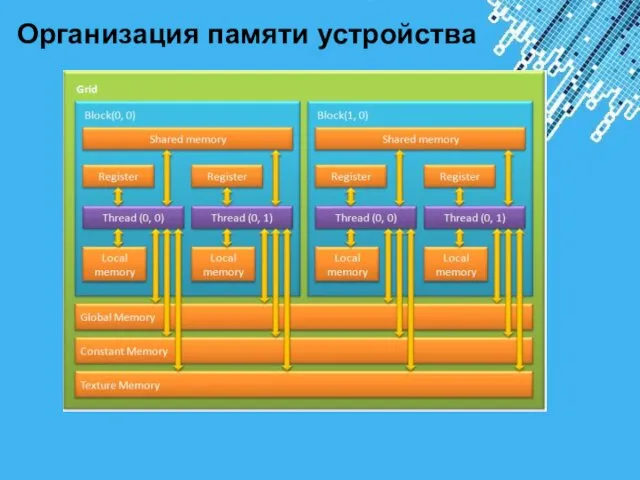
- 11. Организация памяти устройства
- 12. Регистровая память (register) Является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с
- 13. Расчет количества регистров, доступных одной нити GPU При вызове функций ядра myKernelFunc >>(float* param1,float * param2),
- 14. Локальная память Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в
- 15. Глобальная память Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные
- 16. Разделяемая память Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для
- 17. Константная память Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти
- 18. Текстурная память Предназначена главным образом для работы с текстурами. Она оптимизирована под выборку 2D данных и
- 19. Пример использования различных типов памяти При операции транспонирования матрицы
- 20. Транспонирование матрицы на CPU // inputMatrix - указатель на исходную матрицу // outputMatrix - указатель на
- 21. Использование только глобальной памяти. __global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix, int width, int height) { int
- 22. Использование константной памяти. #define N 100 __constant__ float devInputMatrix[N]; __global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix, int
- 23. Использование разделяемой памяти #define BLOCK_DIM 16 __global__ void transposeMatrixFast(float* inputMatrix, float* outputMatrix, int width, int height)
- 24. Результаты вычислений матрица размерностью 2048 * 1536 = 3145728 элементов и 20 итераций в нагрузочных циклах
- 26. Скачать презентацию
Сравнение архитектур CPU и GPU
Параллельная обработка данных распределяет элементы данных на
Сравнение архитектур CPU и GPU
Параллельная обработка данных распределяет элементы данных на

Вычислительная модель GPU
Двумерная блочная структура
Вычислительная модель GPU
Двумерная блочная структура
Структура блоков
Трехмерная структура блоков
Структура блоков
Трехмерная структура блоков

Подключаемые библиотеки
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
Подключаемые библиотеки
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include

Оценка затраченного на вычисления времени
cudaEvent_t start, stop;
float gpuTime;
cudaEventCreate( &start
Оценка затраченного на вычисления времени
cudaEvent_t start, stop;
float gpuTime;
cudaEventCreate( &start

О компоновке нитей и блоков
#define DGX 8
#define DGY 32
#define
О компоновке нитей и блоков
#define DGX 8
#define DGY 32
#define

Отладка программ
Функции из CUDA runtime API могут возвращать различные коды ошибок.
Отладка программ
Функции из CUDA runtime API могут возвращать различные коды ошибок.

Типы памяти
Типы памяти
Типы памяти
Регистры.
Локальная память.
Глобальная память.
Разделяемая память.
Константная память.
Текстурная память
Типы памяти
Регистры.
Локальная память.
Глобальная память.
Разделяемая память.
Константная память.
Текстурная память
Организация памяти устройства
Организация памяти устройства

Регистровая память (register)
Является самой быстрой из всех видов. Определить количество регистров доступных
Регистровая память (register)
Является самой быстрой из всех видов. Определить количество регистров доступных

Расчет количества регистров, доступных одной нити GPU
При вызове функций ядра
myKernelFunc<<< gridSize, blockSize, sharedMemSize,
cudaStream
Расчет количества регистров, доступных одной нити GPU
При вызове функций ядра
myKernelFunc<<< gridSize, blockSize, sharedMemSize,
cudaStream

Локальная память
Локальная память (local memory) может быть использована компилятором при большом количестве локальных
Локальная память
Локальная память (local memory) может быть использована компилятором при большом количестве локальных

Глобальная память
Глобальная память (global memory) – самый медленный тип памяти, из доступных
Глобальная память
Глобальная память (global memory) – самый медленный тип памяти, из доступных

Разделяемая память
Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память
Разделяемая память
Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память

Константная память
Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной
Константная память
Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной

Текстурная память
Предназначена главным образом для работы с текстурами. Она оптимизирована под
Текстурная память
Предназначена главным образом для работы с текстурами. Она оптимизирована под

Пример использования различных типов памяти
При операции транспонирования матрицы
Пример использования различных типов памяти
При операции транспонирования матрицы

Транспонирование матрицы на CPU
// inputMatrix - указатель на исходную матрицу
//
Транспонирование матрицы на CPU
// inputMatrix - указатель на исходную матрицу
//

Использование только глобальной памяти.
__global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix, int width,
Использование только глобальной памяти.
__global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix, int width,
![Использование константной памяти. #define N 100 __constant__ float devInputMatrix[N]; __global__](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/111216/slide-21.jpg)
Использование константной памяти.
#define N 100
__constant__ float devInputMatrix[N];
__global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix,
Использование константной памяти.
#define N 100
__constant__ float devInputMatrix[N];
__global__ void transposeMatrixSlow(float* inputMatrix, float* outputMatrix,

Использование разделяемой памяти
#define BLOCK_DIM 16
__global__ void transposeMatrixFast(float* inputMatrix, float* outputMatrix, int
Использование разделяемой памяти
#define BLOCK_DIM 16
__global__ void transposeMatrixFast(float* inputMatrix, float* outputMatrix, int
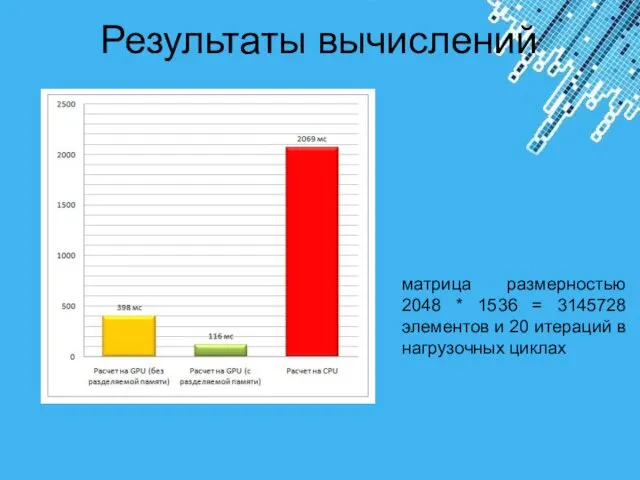
Результаты вычислений
матрица размерностью 2048 * 1536 = 3145728 элементов и 20
Результаты вычислений
матрица размерностью 2048 * 1536 = 3145728 элементов и 20
 Введение в OpenMP. Практика
Введение в OpenMP. Практика АРС 9.9. Автоматизированная рабочая среда проектировщика-сантехника
АРС 9.9. Автоматизированная рабочая среда проектировщика-сантехника Графический интерфейс операционных систем и приложений
Графический интерфейс операционных систем и приложений Безопасный Интернет
Безопасный Интернет Виды базы данных
Виды базы данных Алгоритм Бойера-Мура. Правило плохого символа
Алгоритм Бойера-Мура. Правило плохого символа Базы Данных(БД), Системы Управления Базами Данных(СУБД)
Базы Данных(БД), Системы Управления Базами Данных(СУБД) История развития ЭВМ
История развития ЭВМ Тема 4. Алгоритмічна система рекурсивних функцій
Тема 4. Алгоритмічна система рекурсивних функцій Класифікація та загальна характеристика програмного забезпечення
Класифікація та загальна характеристика програмного забезпечення Технология обработки графической информации
Технология обработки графической информации Міжнародні наукометричні бази даних та індекси цитування наукових праць
Міжнародні наукометричні бази даних та індекси цитування наукових праць Понятия истина и ложь. 2 класс
Понятия истина и ложь. 2 класс Software Architecture and Software Architect T-Systems RUS. JavaSchool
Software Architecture and Software Architect T-Systems RUS. JavaSchool Информатика в играх и задачах
Информатика в играх и задачах Дистанционная подготовка к Всероссийской олимпиаде по информатике
Дистанционная подготовка к Всероссийской олимпиаде по информатике Новые информационные технологии
Новые информационные технологии Дизайн сайта
Дизайн сайта Роль информационной деятельности в современном обществе
Роль информационной деятельности в современном обществе Тренинг по функциональным возможностям Tableau
Тренинг по функциональным возможностям Tableau Інформаційні системи та технології
Інформаційні системи та технології Разработка прототипа мобильного приложения для обмена книгами
Разработка прототипа мобильного приложения для обмена книгами Многомерные массивы. (Лекция 5)
Многомерные массивы. (Лекция 5) Malt Briefing Mockups
Malt Briefing Mockups Мобильное приложение
Мобильное приложение Концепция логического программирования. Программа на языке Пролог. Лекция 1-1
Концепция логического программирования. Программа на языке Пролог. Лекция 1-1 Инструкция по использованию ЛК
Инструкция по использованию ЛК Концепция информационного общества, электронное правительство
Концепция информационного общества, электронное правительство