Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 3 презентация
- Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 3

Содержание
- 2. Лекция № 3
- 3. Физический факультет МГУ им М.В.Ломоносова Содержание лекции Структура, области применения, этапы разработки и характеристики производительности параллельной
- 4. Параллельная программа Физический факультет МГУ им М.В.Ломоносова процесс Последовательная программа один поток управления несколько потоков управления
- 5. Взаимодействие процессов Физический факультет МГУ им М.В.Ломоносова Разделяемые переменные один процесс осуществляет запись в переменную, считываемую
- 6. Классы приложений Физический факультет МГУ им М.В.Ломоносова Многопоточные системы Распределенные системы Синхронные параллельные вычисления
- 7. Многопоточные системы Физический факультет МГУ им М.В.Ломоносова Примеры приложений оконные системы на персональных компьютерах или рабочих
- 8. Распределенные системы Физический факультет МГУ им М.В.Ломоносова Примеры приложений файловые серверы в сети системы баз данных
- 9. Синхронные параллельные вычисления Физический факультет МГУ им М.В.Ломоносова Примеры приложений научные вычисления, которые моделируют и имитируют
- 10. Основные классы научных приложений Сеточные вычисления для приближенных решений дифференциальных уравнений в частных производных Точечные вычисления
- 11. Этапы разработки параллельной программы Последовательная программа выбор наилучшего алгоритма оптимизация Параллельная программа коррекция алгоритма (наилучший параллельный
- 12. Закон Амдала – время выполнения последовательной программы – время выполнения параллельной программы на n процессорах –
- 13. Закон Амдала Физический факультет МГУ им М.В.Ломоносова
- 14. Сетевой закон Амдала – время затрачиваемое на создание процессов и их диспетчеризацию взаимодействие процессов синхронизацию –
- 15. OpenMP Физический факультет МГУ им М.В.Ломоносова
- 16. SMP – архитектура SMP ccNUMA – архитектура Обмен данными между процессами через обмен сообщениями (Message Passing
- 17. Основные принципы OpenMP OpenMP – это интерфейс прикладного программирования для создания многопоточных приложений в вычислительных системах
- 18. Стандарт OpenMP директивы процедуры переменные среды OpenMP ARB (ARchitecture Board) www.openmp.org для языков Fortran и C/C++
- 19. Стандарт OpenMP Версии 1.0-2.5 (1997 – 2005) внедрение и развитие потокового распараллеливания циклов Версии 3.0, 3.1
- 20. Достоинства OpenMP инкрементальное распараллеливание гибкость контроля и единственность разрабатываемого кода эффективность стандартизованность Single Program Multiple Data
- 21. Модель с разделяемой (общей) памятью Физический факультет МГУ им М.В.Ломоносова
- 22. Начала программирования в OpenMP В моделях с общей памятью для обмена данными между потоками следует использовать
- 23. Структура параллельной программы Набор директив компилятора определение параллельной области разделение работы синхронизация Библиотека функций Набор переменных
- 24. Формат записи директив Формат C/C++ #pragma omp имя_директивы [clause,…] FORTRAN c$omp имя_директивы [clause,…] !$omp имя_директивы [clause,…]
- 25. Основные конструкции OpenMP Большинство директив OpenMP применяется к структурным блокам. Структурные блоки – это последовательность операторов
- 26. Порождение нитей PARALLEL [clause,…] ... END PARALLEL (основная директива OpenMP) создается набор (team) из N потоков
- 27. Порождение нитей FORTRAN C/C++ Физический факультет МГУ им М.В.Ломоносова
- 28. Определение параллельной области Количество потоков определяется переменной окружения OMP_NUM_THREADS функцией omp_set_num_threads() Каждый поток имеет свой номер
- 29. Модель выполнения Физический факультет МГУ им М.В.Ломоносова
- 30. Определение параллельной области Режимы выполнения (Execution Mode) параллельных блоков динамический (Dynamic Mode) – количество потоков определяется
- 31. Модель памяти Физический факультет МГУ им М.В.Ломоносова *Технология параллельного программирования OpenMP. © Бахтин В.А
- 32. Директивные предложения (clauses) OpenMP shared(var1, var2, …) переменные var1,… являются общими для всех потоков и относятся
- 33. Примеры реализации предложений Каждый поток имеет свою собственную копию переменных “x” и “myid” Значение “x” будет
- 34. Пример реализации предложения firstprivate В каждом параллельном потоке используется своя переменная “c”, но значение этой переменной
- 35. Пример реализации предложения lastprivate В этом случае переменная “i” определена для каждого потока в параллельном блоке
- 36. Пример реализации предложения if В этом примере цикл распараллеливается только в том случае ( n>2000 ),
- 37. Разделение работы (work-sharing constructs) Do/for - распараллеливание циклов (параллелизм данных) Sections - функциональное распараллеливание Single -
- 38. Конструкции разделения работы to be continued Физический факультет МГУ им М.В.Ломоносова
- 39. Переменные окружения OpenMP OMP_NUM_THREADS - определяет число нитей для исполнения параллельных областей приложения. OMP_SCHEDULE - определяет
- 40. Некоторые функции OpenMP (void) omp_set_num_threads(int num_threads) – задает число потоков в области параллельных вычислений int omp_get_num_threads()
- 41. Пример разделения работы Физический факультет МГУ им М.В.Ломоносова int sum_openmp (int *data, int n) { int
- 43. Скачать презентацию

Лекция № 3
Лекция № 3

Физический факультет МГУ им М.В.Ломоносова
Содержание лекции
Структура, области применения, этапы разработки и
Физический факультет МГУ им М.В.Ломоносова
Содержание лекции
Структура, области применения, этапы разработки и
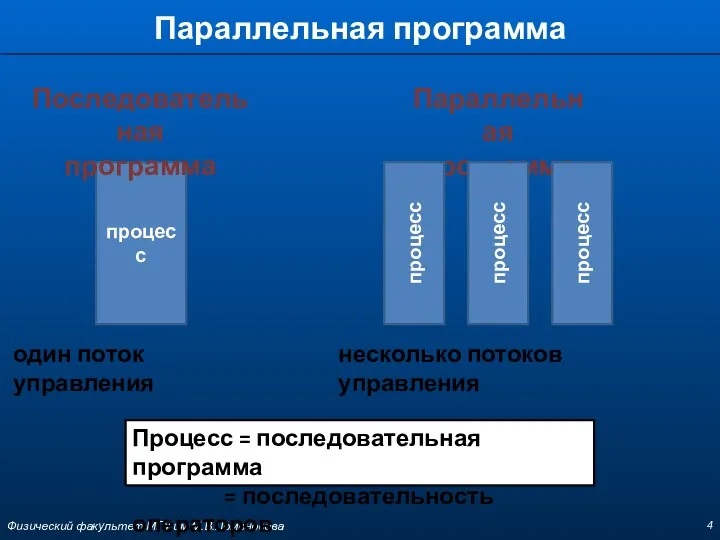
Параллельная программа
Физический факультет МГУ им М.В.Ломоносова
процесс
Последовательная
программа
один поток управления
несколько потоков управления
Процесс =
Параллельная программа
Физический факультет МГУ им М.В.Ломоносова
процесс
Последовательная
программа
один поток управления
несколько потоков управления
Процесс =
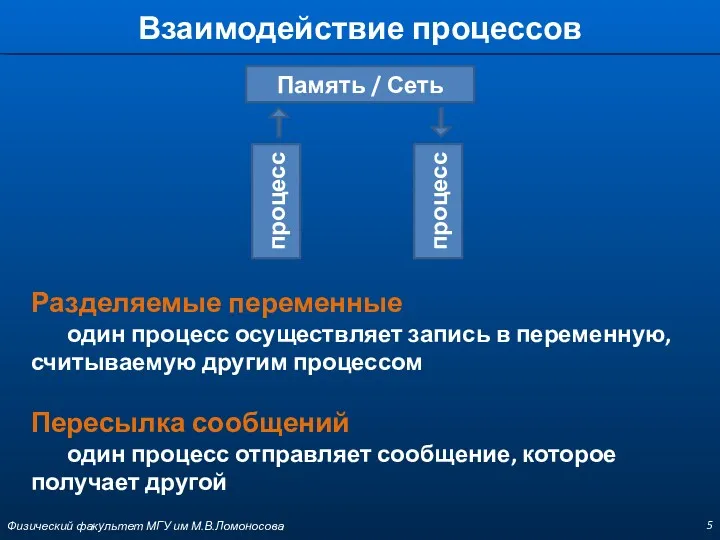
Взаимодействие процессов
Физический факультет МГУ им М.В.Ломоносова
Разделяемые переменные
один процесс осуществляет запись в
Взаимодействие процессов
Физический факультет МГУ им М.В.Ломоносова
Разделяемые переменные
один процесс осуществляет запись в

Классы приложений
Физический факультет МГУ им М.В.Ломоносова
Многопоточные системы
Распределенные системы
Синхронные параллельные вычисления
Классы приложений
Физический факультет МГУ им М.В.Ломоносова
Многопоточные системы
Распределенные системы
Синхронные параллельные вычисления

Многопоточные системы
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
оконные системы на персональных компьютерах
Многопоточные системы
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
оконные системы на персональных компьютерах

Распределенные системы
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
файловые серверы в сети
системы баз
Распределенные системы
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
файловые серверы в сети
системы баз

Синхронные параллельные вычисления
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
научные вычисления, которые моделируют
Синхронные параллельные вычисления
Физический факультет МГУ им М.В.Ломоносова
Примеры приложений
научные вычисления, которые моделируют

Основные классы научных приложений
Сеточные вычисления для приближенных решений дифференциальных уравнений в
Основные классы научных приложений
Сеточные вычисления для приближенных решений дифференциальных уравнений в

Этапы разработки параллельной программы
Последовательная программа
выбор наилучшего алгоритма
оптимизация
Параллельная программа
коррекция алгоритма
(наилучший параллельный алгоритм
Этапы разработки параллельной программы
Последовательная программа
выбор наилучшего алгоритма
оптимизация
Параллельная программа
коррекция алгоритма
(наилучший параллельный алгоритм

Закон Амдала
– время выполнения последовательной программы
– время выполнения параллельной программы на
Закон Амдала
– время выполнения последовательной программы
– время выполнения параллельной программы на
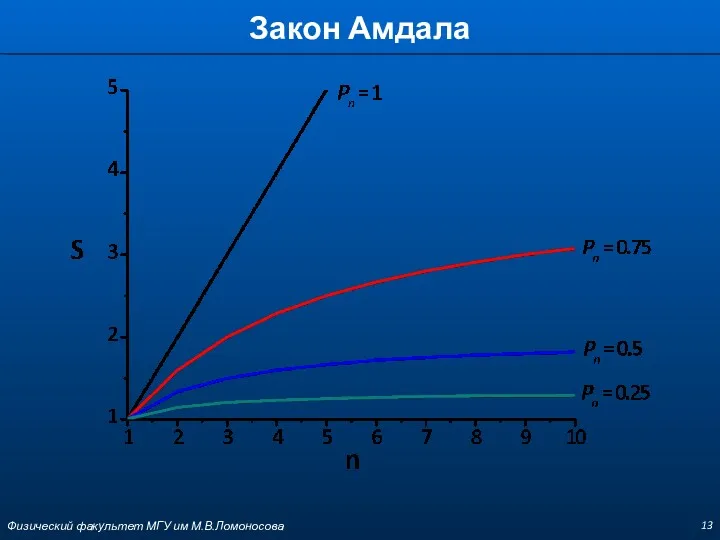
Закон Амдала
Физический факультет МГУ им М.В.Ломоносова
Закон Амдала
Физический факультет МГУ им М.В.Ломоносова

Сетевой закон Амдала
– время затрачиваемое на
создание процессов и их диспетчеризацию
Сетевой закон Амдала
– время затрачиваемое на
создание процессов и их диспетчеризацию

OpenMP
Физический факультет МГУ им М.В.Ломоносова
OpenMP
Физический факультет МГУ им М.В.Ломоносова
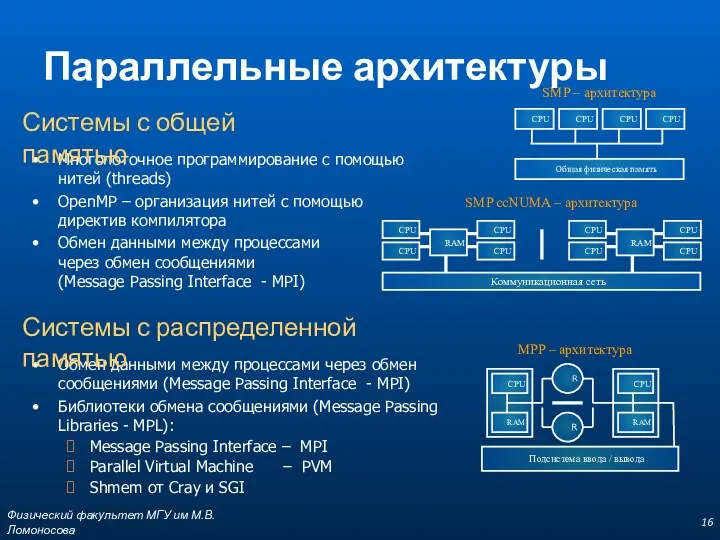
SMP – архитектура
SMP ccNUMA – архитектура
Обмен данными между процессами через обмен
SMP – архитектура
SMP ccNUMA – архитектура
Обмен данными между процессами через обмен

Основные принципы OpenMP
OpenMP – это интерфейс прикладного программирования для создания многопоточных
Основные принципы OpenMP
OpenMP – это интерфейс прикладного программирования для создания многопоточных

Стандарт OpenMP
директивы
процедуры
переменные среды
OpenMP ARB (ARchitecture Board)
www.openmp.org
для языков Fortran и C/C++
Стандарт OpenMP
директивы
процедуры
переменные среды
OpenMP ARB (ARchitecture Board)
www.openmp.org
для языков Fortran и C/C++

Стандарт OpenMP
Версии 1.0-2.5 (1997 – 2005)
внедрение и развитие потокового распараллеливания циклов
Версии
Стандарт OpenMP
Версии 1.0-2.5 (1997 – 2005)
внедрение и развитие потокового распараллеливания циклов
Версии

Достоинства OpenMP
инкрементальное распараллеливание
гибкость контроля и
единственность разрабатываемого кода
эффективность
стандартизованность
Single Program Multiple
Достоинства OpenMP
инкрементальное распараллеливание
гибкость контроля и
единственность разрабатываемого кода
эффективность
стандартизованность
Single Program Multiple
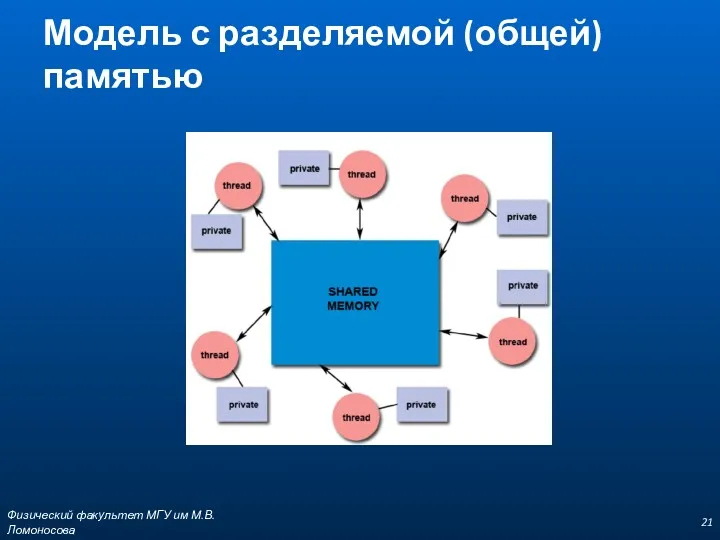
Модель с разделяемой (общей) памятью
Физический факультет МГУ им М.В.Ломоносова
Модель с разделяемой (общей) памятью
Физический факультет МГУ им М.В.Ломоносова

Начала программирования в OpenMP
В моделях с общей памятью для обмена данными
Начала программирования в OpenMP
В моделях с общей памятью для обмена данными

Структура параллельной программы
Набор директив компилятора
определение параллельной области
разделение работы
синхронизация
Библиотека функций
Набор переменных окружения
Физический
Структура параллельной программы
Набор директив компилятора
определение параллельной области
разделение работы
синхронизация
Библиотека функций
Набор переменных окружения
Физический
![Формат записи директив Формат C/C++ #pragma omp имя_директивы [clause,…] FORTRAN](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/256697/slide-23.jpg)
Формат записи директив
Формат
C/C++
#pragma omp имя_директивы [clause,…]
FORTRAN
c$omp имя_директивы [clause,…]
!$omp имя_директивы [clause,…]
*$omp имя_директивы
Формат записи директив
Формат
C/C++
#pragma omp имя_директивы [clause,…]
FORTRAN
c$omp имя_директивы [clause,…]
!$omp имя_директивы [clause,…]
*$omp имя_директивы

Основные конструкции OpenMP
Большинство директив OpenMP применяется к структурным блокам. Структурные блоки
Основные конструкции OpenMP
Большинство директив OpenMP применяется к структурным блокам. Структурные блоки
![Порождение нитей PARALLEL [clause,…] ... END PARALLEL (основная директива OpenMP)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/256697/slide-25.jpg)
Порождение нитей
PARALLEL [clause,…] ... END PARALLEL
(основная директива OpenMP)
создается набор
Порождение нитей
PARALLEL [clause,…] ... END PARALLEL
(основная директива OpenMP)
создается набор

Порождение нитей
FORTRAN
C/C++
Физический факультет МГУ им М.В.Ломоносова
Порождение нитей
FORTRAN
C/C++
Физический факультет МГУ им М.В.Ломоносова

Определение параллельной области
Количество потоков определяется
переменной окружения OMP_NUM_THREADS
функцией omp_set_num_threads()
Каждый поток имеет
Определение параллельной области
Количество потоков определяется
переменной окружения OMP_NUM_THREADS
функцией omp_set_num_threads()
Каждый поток имеет
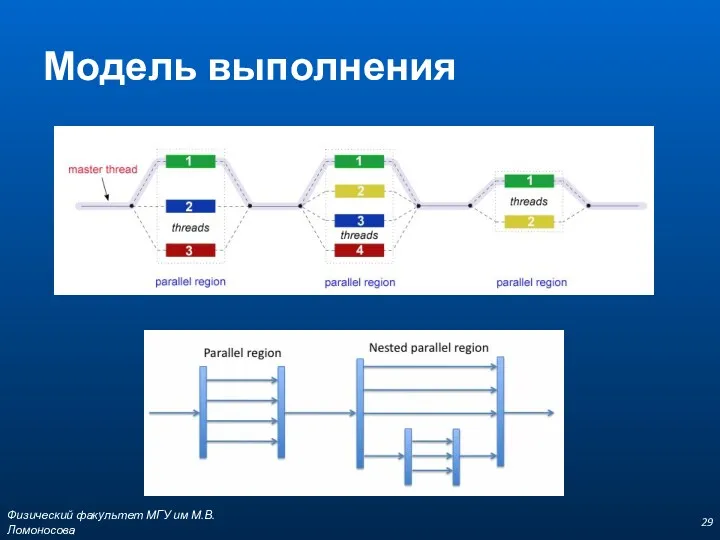
Модель выполнения
Физический факультет МГУ им М.В.Ломоносова
Модель выполнения
Физический факультет МГУ им М.В.Ломоносова

Определение параллельной области
Режимы выполнения (Execution Mode) параллельных блоков
динамический (Dynamic Mode) –
Определение параллельной области
Режимы выполнения (Execution Mode) параллельных блоков
динамический (Dynamic Mode) –
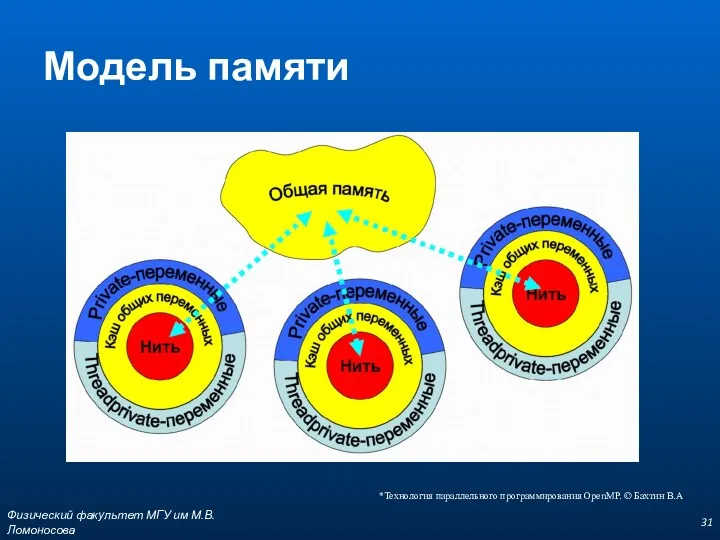
Модель памяти
Физический факультет МГУ им М.В.Ломоносова
*Технология параллельного программирования OpenMP. © Бахтин В.А
Модель памяти
Физический факультет МГУ им М.В.Ломоносова
*Технология параллельного программирования OpenMP. © Бахтин В.А

Директивные предложения (clauses) OpenMP
shared(var1, var2, …)
переменные var1,… являются общими для всех
Директивные предложения (clauses) OpenMP
shared(var1, var2, …)
переменные var1,… являются общими для всех

Примеры реализации предложений
Каждый поток имеет свою собственную копию переменных “x” и
Примеры реализации предложений
Каждый поток имеет свою собственную копию переменных “x” и

Пример реализации предложения firstprivate
В каждом параллельном потоке используется своя переменная “c”,
Пример реализации предложения firstprivate
В каждом параллельном потоке используется своя переменная “c”,

Пример реализации предложения lastprivate
В этом случае переменная “i” определена для каждого
Пример реализации предложения lastprivate
В этом случае переменная “i” определена для каждого

Пример реализации предложения if
В этом примере цикл распараллеливается только в том
Пример реализации предложения if
В этом примере цикл распараллеливается только в том
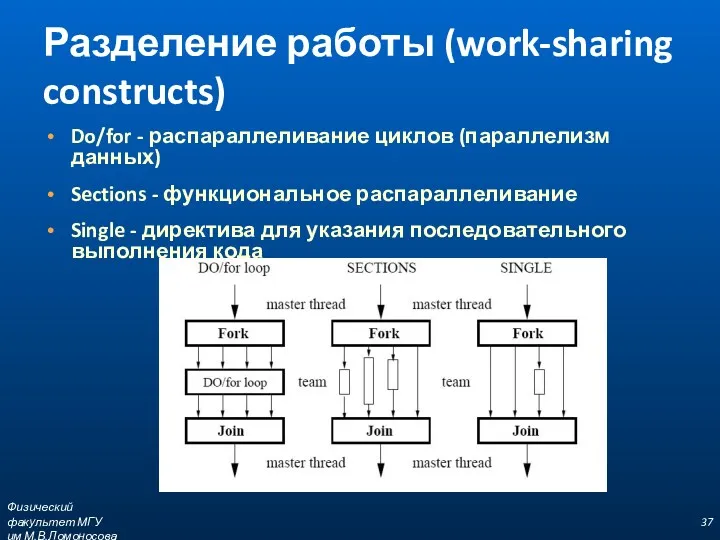
Разделение работы (work-sharing constructs)
Do/for - распараллеливание циклов (параллелизм данных)
Sections -
Разделение работы (work-sharing constructs)
Do/for - распараллеливание циклов (параллелизм данных)
Sections -

Конструкции разделения работы
to be continued
Физический факультет МГУ им М.В.Ломоносова
Конструкции разделения работы
to be continued
Физический факультет МГУ им М.В.Ломоносова

Переменные окружения OpenMP
OMP_NUM_THREADS - определяет число нитей для исполнения параллельных областей
Переменные окружения OpenMP
OMP_NUM_THREADS - определяет число нитей для исполнения параллельных областей

Некоторые функции OpenMP
(void) omp_set_num_threads(int num_threads) – задает число потоков в области
Некоторые функции OpenMP
(void) omp_set_num_threads(int num_threads) – задает число потоков в области

Пример разделения работы
Физический факультет МГУ им М.В.Ломоносова
int sum_openmp (int *data, int
Пример разделения работы
Физический факультет МГУ им М.В.Ломоносова
int sum_openmp (int *data, int
 Организация файлового сервера в сети предприятия АО САЗ и его администрирование
Организация файлового сервера в сети предприятия АО САЗ и его администрирование Информационные технологии. Лекция 1. Введение
Информационные технологии. Лекция 1. Введение Информационные технологии в юридической деятельности
Информационные технологии в юридической деятельности Браузеры. Наиболее популярные браузеры
Браузеры. Наиболее популярные браузеры Упрощенный приём отправлений (инструкция v.1)
Упрощенный приём отправлений (инструкция v.1) Positive and negative effects of computers
Positive and negative effects of computers Социальные сети и их возможности
Социальные сети и их возможности Поколение - Z. Школа Блогеров
Поколение - Z. Школа Блогеров Разработка информационной системы многоуровневой поддержки отделом информационных технологий
Разработка информационной системы многоуровневой поддержки отделом информационных технологий Строковые алгоритмы
Строковые алгоритмы Файлы и файловая система
Файлы и файловая система Лекция 1. Основы компьютерных сетей. История развития
Лекция 1. Основы компьютерных сетей. История развития Компьютерные технологии интеллектуальной поддержки управленческих решений
Компьютерные технологии интеллектуальной поддержки управленческих решений Управление доступом к ресурсам. Лекция 4
Управление доступом к ресурсам. Лекция 4 Основы трехмерного моделирования в Компас 3D
Основы трехмерного моделирования в Компас 3D How to Update Norton Antivirus
How to Update Norton Antivirus Проблемы с реализацией ФГИС
Проблемы с реализацией ФГИС Глобальная сеть - Интернет
Глобальная сеть - Интернет Автоматизация рабочего места секретаря директора школы
Автоматизация рабочего места секретаря директора школы Информационная картина мира.
Информационная картина мира. Технология поиска информации в сети Интернет
Технология поиска информации в сети Интернет Занимательные задачки
Занимательные задачки Основы SQL. Практическое применение
Основы SQL. Практическое применение Носители информации (5 класс)
Носители информации (5 класс) Основи інформаційної безпеки. Основи захисту даних в комп’ютерних системах. 9 клас
Основи інформаційної безпеки. Основи захисту даних в комп’ютерних системах. 9 клас ВКР: Процесс миграции виртуальных машин в облачных центрах обработки данных с использованием методов машинного обучения
ВКР: Процесс миграции виртуальных машин в облачных центрах обработки данных с использованием методов машинного обучения C# Collections. Generic Collections
C# Collections. Generic Collections Поставки - продаж непродовольчих товарів. База даних
Поставки - продаж непродовольчих товарів. База даних