- Строковые алгоритмы

Содержание
- 2. Полиномиальное хеширование Хеш-функция сопоставляет объекту некоторое число. Для вычисления хеша последовательности вида a1a2a3…an нужно выбрать значение
- 3. Полиномиальное хеширование Прямой полиномиальный хеш можно вычислить следующим образом: h = (a1 + a2* p +
- 4. Полиномиальное хеширование Учитывая, что хеш является значением многочлена, мы можем быстро пересчитывать значение хеша от результата
- 5. Полиномиальное хеширование Пример. Дана последовательность a1a2a3a4a5. Получить значение хеша подстроки a3a4a5. Обратный полиномиальный хеш: h[1:5] -
- 6. Полиномиальное хеширование Общая формула для вычисления значения хеша на подотрезке (i, j), h(i, j) = pr[
- 7. Полиномиальное хеширование Прямой полиномиальный хеш: (a1 + a2* p + a3* p2 + a4* p3 +
- 8. Полиномиальное хеширование В общем виде (h[ j + 1] - h[ i ]) * p-i) Для
- 9. Полиномиальное хеширование Либо мы можем фиксировать не младшую степень, а старшую. Тогда (h[ j + 1]
- 10. Полиномиальное хеширование. Проверка на равенство s = abcde → hs t = abcde → ht if
- 11. Полиномиальное хеширование. Сравнение на больше/меньше Для сравнения на больше/меньше требуется найти первый несовпадающий элемент слева, то
- 12. Полиномиальное хеширование. Уменьшение вероятности коллизий. P = n2 / (2 * mod) Чтобы решение работало как
- 13. Полиномиальное хеширование. Строка Туэ-Морса. При хешированию по модулю 264 строки вида abbabaabbaababba… В общем виде: Si
- 14. Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше. Дана последовательность s1…si…sl…sk…sj…sn Требуется вычислить хеш на
- 15. Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше. Учитывая, что у нас были предпосчитаны хеши
- 16. Полиномиальное хеширование. Применение Поиск всех вхождений одной строки длины n в другую длины m за O(n
- 17. Полиномиальное хеширование. Полезные ссылки https://codeforces.com/blog/entry/65819 - вычисление по модулю 261 - 1 https://pastebin.com/5Run2F5y - реализация хеша
- 18. Z-функция строки Z-функция - массив длины n, i-ый элемент которого равен наибольшему числу символов, начиная с
- 19. Z-функция. Тривиальный алгоритм Простая реализация выполняется за O(N2), где N - длина строки. Для каждой позиции
- 20. Z-функция. Эффективный алгоритм Назовём Z-блоком подстроку с началом в позиции i и длиной Z[ i ].
- 21. Z-функция. Ссылки https://e-maxx.ru/algo/z_function - тут есть доказательство линейности алгоритма https://neerc.ifmo.ru/wiki/index.php?title=Z-функция
- 22. Префикс-функция Дана строка s[0…n-1]. Требуется вычислить для неё префикс-функцию, т.е. массив чисел π[0…n-1], где π[ i
- 23. Префикс-функция. Эффективный алгоритм Заметим, что p[i+1] Избавимся от явных сравнений строк. Пусть мы вычислили p[i], тогда,
- 24. Алгоритм Кнута-Морриса-Пратта КМП предназначен для поиска шаблона (подстроки) в строке. https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/
- 25. Префикс-функция → Z-функция & V/V ~ O(N) Префикс-функция и Z-функция взаимозаменяемы и могут быть представлены друг
- 27. Скачать презентацию

Полиномиальное хеширование
Хеш-функция сопоставляет объекту некоторое число.
Для вычисления хеша последовательности вида
Полиномиальное хеширование
Хеш-функция сопоставляет объекту некоторое число.
Для вычисления хеша последовательности вида

Полиномиальное хеширование
Прямой полиномиальный хеш можно вычислить следующим образом:
h = (a1 +
Полиномиальное хеширование
Прямой полиномиальный хеш можно вычислить следующим образом:
h = (a1 +

Полиномиальное хеширование
Учитывая, что хеш является значением многочлена, мы можем быстро пересчитывать
Полиномиальное хеширование
Учитывая, что хеш является значением многочлена, мы можем быстро пересчитывать

Полиномиальное хеширование
Пример. Дана последовательность a1a2a3a4a5. Получить значение хеша подстроки a3a4a5.
Обратный полиномиальный
Полиномиальное хеширование
Пример. Дана последовательность a1a2a3a4a5. Получить значение хеша подстроки a3a4a5.
Обратный полиномиальный

Полиномиальное хеширование
Общая формула для вычисления значения хеша на подотрезке (i, j),
Полиномиальное хеширование
Общая формула для вычисления значения хеша на подотрезке (i, j),

Полиномиальное хеширование
Прямой полиномиальный хеш:
(a1 + a2* p + a3* p2 +
Полиномиальное хеширование
Прямой полиномиальный хеш:
(a1 + a2* p + a3* p2 +
![Полиномиальное хеширование В общем виде (h[ j + 1] -](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581163/slide-7.jpg)
Полиномиальное хеширование
В общем виде
(h[ j + 1] - h[ i ])
Полиномиальное хеширование
В общем виде
(h[ j + 1] - h[ i ])

Полиномиальное хеширование
Либо мы можем фиксировать не младшую степень, а старшую.
Тогда
Полиномиальное хеширование
Либо мы можем фиксировать не младшую степень, а старшую.
Тогда

Полиномиальное хеширование. Проверка на равенство
s = abcde → hs
t = abcde
Полиномиальное хеширование. Проверка на равенство
s = abcde → hs
t = abcde

Полиномиальное хеширование. Сравнение на больше/меньше
Для сравнения на больше/меньше требуется найти первый
Полиномиальное хеширование. Сравнение на больше/меньше
Для сравнения на больше/меньше требуется найти первый

Полиномиальное хеширование. Уменьшение вероятности коллизий.
P = n2 / (2 * mod)
Чтобы
Полиномиальное хеширование. Уменьшение вероятности коллизий.
P = n2 / (2 * mod)
Чтобы

Полиномиальное хеширование. Строка Туэ-Морса.
При хешированию по модулю 264 строки вида
abbabaabbaababba…
В общем
Полиномиальное хеширование. Строка Туэ-Морса.
При хешированию по модулю 264 строки вида
abbabaabbaababba…
В общем

Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше.
Дана последовательность
s1…si…sl…sk…sj…sn
Требуется
Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше.
Дана последовательность
s1…si…sl…sk…sj…sn
Требуется

Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше.
Учитывая, что у
Полиномиальное хеширование. Обмен местами двух символов в полиномиальном хеше.
Учитывая, что у

Полиномиальное хеширование. Применение
Поиск всех вхождений одной строки длины n в другую
Полиномиальное хеширование. Применение
Поиск всех вхождений одной строки длины n в другую

Полиномиальное хеширование. Полезные ссылки
https://codeforces.com/blog/entry/65819 - вычисление по модулю 261 - 1
https://pastebin.com/5Run2F5y
Полиномиальное хеширование. Полезные ссылки
https://codeforces.com/blog/entry/65819 - вычисление по модулю 261 - 1
https://pastebin.com/5Run2F5y

Z-функция строки
Z-функция - массив длины n, i-ый элемент которого равен наибольшему
Z-функция строки
Z-функция - массив длины n, i-ый элемент которого равен наибольшему

Z-функция. Тривиальный алгоритм
Простая реализация выполняется за O(N2), где N - длина
Z-функция. Тривиальный алгоритм
Простая реализация выполняется за O(N2), где N - длина

Z-функция. Эффективный алгоритм
Назовём Z-блоком подстроку с началом в позиции i и
Z-функция. Эффективный алгоритм
Назовём Z-блоком подстроку с началом в позиции i и

Z-функция. Ссылки
https://e-maxx.ru/algo/z_function - тут есть доказательство линейности алгоритма
https://neerc.ifmo.ru/wiki/index.php?title=Z-функция
Z-функция. Ссылки
https://e-maxx.ru/algo/z_function - тут есть доказательство линейности алгоритма
https://neerc.ifmo.ru/wiki/index.php?title=Z-функция
![Префикс-функция Дана строка s[0…n-1]. Требуется вычислить для неё префикс-функцию, т.е.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581163/slide-21.jpg)
Префикс-функция
Дана строка s[0…n-1]. Требуется вычислить для неё префикс-функцию, т.е. массив чисел
Префикс-функция
Дана строка s[0…n-1]. Требуется вычислить для неё префикс-функцию, т.е. массив чисел
![Префикс-функция. Эффективный алгоритм Заметим, что p[i+1] Избавимся от явных сравнений](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/581163/slide-22.jpg)
Префикс-функция. Эффективный алгоритм
Заметим, что p[i+1] <= p[i]+1. Чтобы показать это, рассмотрим
Префикс-функция. Эффективный алгоритм
Заметим, что p[i+1] <= p[i]+1. Чтобы показать это, рассмотрим

Алгоритм Кнута-Морриса-Пратта
КМП предназначен для поиска шаблона (подстроки) в строке.
https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/
Алгоритм Кнута-Морриса-Пратта
КМП предназначен для поиска шаблона (подстроки) в строке.
https://leetcode.com/problems/find-the-index-of-the-first-occurrence-in-a-string/

Префикс-функция → Z-функция & V/V ~ O(N)
Префикс-функция и Z-функция взаимозаменяемы и
Префикс-функция → Z-функция & V/V ~ O(N)
Префикс-функция и Z-функция взаимозаменяемы и
 Электронные таблицы Excel
Электронные таблицы Excel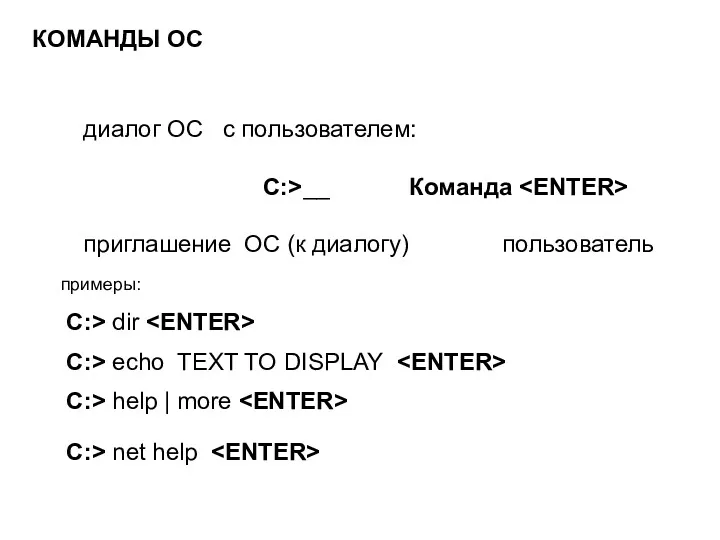 Команды ОС. Диалог ОС с пользователем
Команды ОС. Диалог ОС с пользователем Двоичное кодирование текстовой информации
Двоичное кодирование текстовой информации Функции VBA
Функции VBA Введение в курс информатики и ИКТ. (8 класс)
Введение в курс информатики и ИКТ. (8 класс)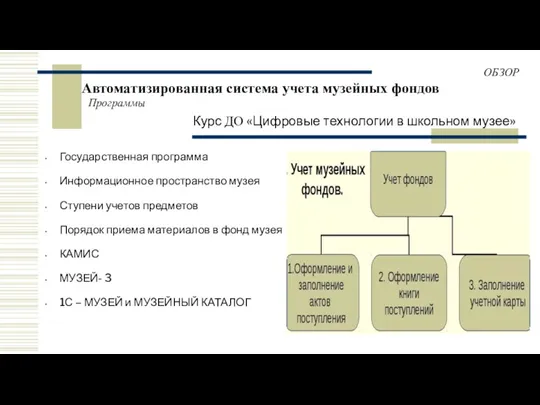 Автоматизированная система учета музейных фондов
Автоматизированная система учета музейных фондов Устройства ввода
Устройства ввода Инновационные технологии в журналистике
Инновационные технологии в журналистике Gadgets or new technologies in our life
Gadgets or new technologies in our life Занимательные задачки по информатике
Занимательные задачки по информатике Сетевые операционные системы
Сетевые операционные системы Файлы и папки
Файлы и папки Процедуры и функции в Паскале
Процедуры и функции в Паскале Мектеп сайтын жасау әдістемесі
Мектеп сайтын жасау әдістемесі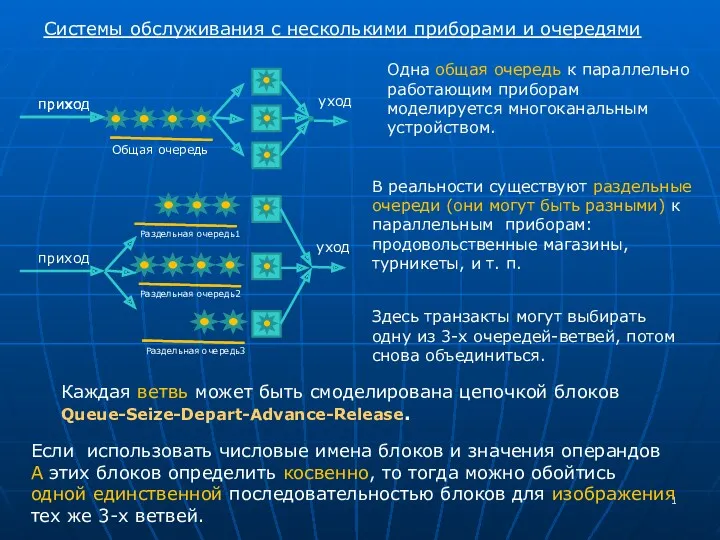 ПрезентацияПоGpss №10
ПрезентацияПоGpss №10 Графический интерфейс в Python
Графический интерфейс в Python Мультимедийнная презентация у уроку информатики на тему Основы логики
Мультимедийнная презентация у уроку информатики на тему Основы логики Кодирование и обработка графической информации
Кодирование и обработка графической информации Объединение компьютеров в локальную сеть Организация работы пользователей в локальных компьютерных сетях
Объединение компьютеров в локальную сеть Организация работы пользователей в локальных компьютерных сетях Конспекты уроков 10 класс (1 четверть)
Конспекты уроков 10 класс (1 четверть) Презентация Использование ЦОР и ЭОР в учебном процессе
Презентация Использование ЦОР и ЭОР в учебном процессе ITK Lecture 6 - The Pipeline
ITK Lecture 6 - The Pipeline Устройства ввода информации. (7класс)
Устройства ввода информации. (7класс) Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка
Анализ современных подходов к разработке мобильных приложений на примере приложения: Дневник стрелка TNS Web Index. Аудитория интернет-проектов. Результаты исследования: Апрель 2016
TNS Web Index. Аудитория интернет-проектов. Результаты исследования: Апрель 2016 Виртуальная реальность
Виртуальная реальность Презентация по информатике для 8 класса Виды информации
Презентация по информатике для 8 класса Виды информации Интернет-банк РНКБ
Интернет-банк РНКБ