- Пользовательские типы данных (C++). Лекция 7 по основам программирования

Содержание
- 2. ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ Пользовательские типы данных можно создать с помощью: структуры — группы переменных, имеющей одно
- 3. ОПЕРАТОР TYPEDEF Оператор typedef определяет новое имя для уже существующего типа. Общий вид декларации: typedef type1
- 4. СТРУКТУРЫ Структура — это совокупность переменных, объединенных под одним именем. Объявление структуры создает шаблон, который можно
- 5. STRUCT struct тег { тип имя-члена; тип имя-члена; тип имя-члена; . . . } переменные-структуры; тег
- 6. СТРУКТУРЫ struct addr { char name[30]; char street[40]; char city[20]; char state[3]; unsigned long int zip;
- 7. СТРУКТУРЫ Доступ к отдельным элементам структуры осуществляется с помощью оператора . (точка) имя-объекта-структуры.имя-элемента addr_info.zip = 191002;
- 8. АНАЛИЗ ПРОГРАММЫ int main() { struct { int a; int b; } x, y, *z; x.a
- 9. АНАЛИЗ ПРОГРАММЫ // объявление массива структур struct addr addr_list[100]; // объявление указателя на структуру struct addr
- 10. АНАЛИЗ ПРОГРАММЫ struct Phone { char* name; long phoneNumber; }; Phone *somePhone = new Phone; somePhone->name
- 11. БИТОВЫЕ ПОЛЯ Битовые поля — это особый вид полей структуры. Они используются для плотной упаковки данных,
- 12. БИТОВЫЕ ПОЛЯ struct Options { bool centerX:1; bool centerY:1; unsigned int shadow:2; unsigned int palette:4; };
- 13. ОБЪЕДИНЕНИЯ Объединение (union) представляет собой частный случай структуры, все поля которой располагаются по одному и тому
- 14. ОБЪЕДИНЕНИЯ struct Options { bool centerX:1; bool centerY:1; unsigned int shadow:2; unsigned int palette:4; }; union
- 15. ОБЪЕДИНЕНИЯ Ограничения объединений (по сравнению со структурами): объединение может инициализироваться только значением его первого элемента; объединение
- 16. ПЕРЕЧИСЛЕНИЯ Перечисление — это набор именованных целых констант. enum тег {список перечисления} список переменных; тег или
- 17. ПЕРЕЧИСЛЕНИЯ /* penny (пенни, монета в один цент) nickel (никель, монета в пять центов) dime (монета
- 18. ПЕРЕЧИСЛЕНИЯ enum Err {ERR_READ, ERR_WRITE, ERR_CONVERT}; Err error; // ... switch (error) { case ERR_READ: /*
- 19. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ Если до начала работы с данными невозможно определить, сколько памяти потребуется для их
- 20. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ Механизм доступа (data engine) к данным –механизм сохранения и получения информации. Очередь (queue)
- 21. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ Динамические структуры данных (списки, стеки, очереди, деревья) различаются способами связи отдельных элементов и
- 22. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ Элемент любой динамической структуры данных представляет собой структуру (struct), содержащую по крайней мере
- 23. ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ Описание простейшего элемента (компоненты, узла) динамической структуры: struct Node { /* тип данных
- 24. СПИСКИ Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения.
- 25. СПИСКИ Самый простой способ связать множество элементов — сделать так, чтобы каждый элемент содержал ссылку на
- 26. СПИСКИ Каждый элемент списка содержит ключ, идентифицирующий этот элемент. Ключ обычно бывает либо целым числом, либо
- 27. СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ INF - информационное поле, данные NEXT - указатель на следующий элемент списка nil
- 28. СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ Линейный двусвязный список: Наличие двух указателей в каждом элементе усложняет список и приводит
- 29. СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ Кольцевой список (может быть организован на основе как односвязного, так и двухсвязного)
- 30. ОПЕРАЦИИ НАД СПИСКАМИ начальное формирование списка (создание первого элемента); добавление элемента в конец списка; чтение элемента
- 31. РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ Вставка элемента в середину 1-связного списка Вставка элемента в начало 1-связного
- 32. РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ Вставка элемента в середину 2-связного списка
- 33. РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ Удаление элемента из 1-связного списка Удаление элемента из 2-связного списка
- 34. РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ Перестановка элементов 1-связного списка Изменчивость динамических структур данных предполагает не только
- 35. ВОЗМОЖНЫЕ ОПЕРАЦИИ НАД ТИПОМ ДАННЫХ «СПИСОК» end(l) — вернуть позицию, следующую за последним элементом списка l.
- 36. АНАЛИЗ ПРОГРАММЫ //Описание структуры элемента списка struct Node { int d; Node *next; Node *prev; };
- 37. АНАЛИЗ ПРОГРАММЫ // Формирование первого элемента Node * first(int d) { Node *pv = new Node;
- 38. АНАЛИЗ ПРОГРАММЫ // Добавление в конец списка void add(Node **pend, int d) { Node *pv =
- 39. АНАЛИЗ ПРОГРАММЫ // Поиск элемента по ключу Node * find(Node * const pbeg, int d) {
- 40. АНАЛИЗ ПРОГРАММЫ // Вставка элемента Node * insert(Node * const pbeg, Node **pend, int key, int
- 41. АНАЛИЗ ПРОГРАММЫ // Удаление элемента bool remove(Node **pbeg, Node **pend, int key) { if (Node *pkey
- 42. СРАВНЕНИЕ ОПЕРАЦИЙ НАД СТРУКТУРАМИ ДАННЫХ Сравнение операций над статическими массивами, динамическими массивами и связными списками:
- 43. ДОСТОИНСТВА СПИСКОВ лёгкость добавления и удаления элементов размер ограничен только объёмом памяти компьютера и разрядностью указателей
- 44. НЕДОСТАТКИ СПИСКОВ сложность определения адреса элемента по его индексу (номеру) в списке на поля-указатели (указатели на
- 45. АБСТРАКТНЫЕ ПРИНЦИПЫ ОБРАБОТКИ СПИСКОВ FIFO (First In, First Out) «первым пришёл — первым ушёл» FIFO (First
- 46. ОЧЕРЕДИ Очередь — это частный случай линейного 1-связного списка, добавление элементов в который выполняется в один
- 47. ОЧЕРЕДИ Типичные операции: void push(const value_type&) - добавить элемент void pop() - удалить первый элемент size_type
- 48. СТЕКИ Стек — это частный случай линейного 1-связного списка, добавление элементов в который и извлечение из
- 49. СТЕКИ Типичные операции: void push(const value_type&) - добавить элемент void pop() - удалить верхний элемент value_type&
- 50. ЗАДАЧИ (СПИСКИ) 1) Написать программу, выводящую элемент списка по его номеру. 2) Определить длину списка (вывести
- 52. Скачать презентацию

ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ
Пользовательские типы данных можно создать с помощью:
структуры — группы
ПОЛЬЗОВАТЕЛЬСКИЕ ТИПЫ ДАННЫХ
Пользовательские типы данных можно создать с помощью:
структуры — группы

ОПЕРАТОР TYPEDEF
Оператор typedef определяет новое имя для уже существующего типа.
Общий
ОПЕРАТОР TYPEDEF
Оператор typedef определяет новое имя для уже существующего типа.
Общий

СТРУКТУРЫ
Структура — это совокупность переменных, объединенных под одним именем.
Объявление структуры
СТРУКТУРЫ
Структура — это совокупность переменных, объединенных под одним именем.
Объявление структуры

STRUCT
struct тег {
тип имя-члена;
тип имя-члена;
тип имя-члена;
.
.
STRUCT
struct тег {
тип имя-члена;
тип имя-члена;
тип имя-члена;
.
.
![СТРУКТУРЫ struct addr { char name[30]; char street[40]; char city[20];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7377/slide-5.jpg)
СТРУКТУРЫ
struct addr
{
char name[30];
char street[40];
char city[20];
char state[3];
unsigned
СТРУКТУРЫ
struct addr
{
char name[30];
char street[40];
char city[20];
char state[3];
unsigned

СТРУКТУРЫ
Доступ к отдельным элементам структуры осуществляется с помощью оператора . (точка)
имя-объекта-структуры.имя-элемента
addr_info.zip
СТРУКТУРЫ
Доступ к отдельным элементам структуры осуществляется с помощью оператора . (точка)
имя-объекта-структуры.имя-элемента
addr_info.zip

АНАЛИЗ ПРОГРАММЫ
int main()
{
struct {
int a;
int b;
} x,
АНАЛИЗ ПРОГРАММЫ
int main()
{
struct {
int a;
int b;
} x,
![АНАЛИЗ ПРОГРАММЫ // объявление массива структур struct addr addr_list[100]; //](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/7377/slide-8.jpg)
АНАЛИЗ ПРОГРАММЫ
// объявление массива структур
struct addr addr_list[100];
// объявление указателя на структуру
struct
АНАЛИЗ ПРОГРАММЫ
// объявление массива структур
struct addr addr_list[100];
// объявление указателя на структуру
struct

АНАЛИЗ ПРОГРАММЫ
struct Phone
{
char* name;
long phoneNumber;
};
Phone *somePhone = new Phone;
somePhone->name
АНАЛИЗ ПРОГРАММЫ
struct Phone
{
char* name;
long phoneNumber;
};
Phone *somePhone = new Phone;
somePhone->name

БИТОВЫЕ ПОЛЯ
Битовые поля — это особый вид полей структуры. Они используются
БИТОВЫЕ ПОЛЯ
Битовые поля — это особый вид полей структуры. Они используются

БИТОВЫЕ ПОЛЯ
struct Options {
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
БИТОВЫЕ ПОЛЯ
struct Options {
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;

ОБЪЕДИНЕНИЯ
Объединение (union) представляет собой частный случай структуры, все поля которой располагаются
ОБЪЕДИНЕНИЯ
Объединение (union) представляет собой частный случай структуры, все поля которой располагаются

ОБЪЕДИНЕНИЯ
struct Options {
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
unsigned
ОБЪЕДИНЕНИЯ
struct Options {
bool centerX:1;
bool centerY:1;
unsigned int shadow:2;
unsigned

ОБЪЕДИНЕНИЯ
Ограничения объединений (по сравнению со структурами):
объединение может инициализироваться только значением его
ОБЪЕДИНЕНИЯ
Ограничения объединений (по сравнению со структурами):
объединение может инициализироваться только значением его

ПЕРЕЧИСЛЕНИЯ
Перечисление — это набор именованных целых констант.
enum тег {список перечисления}
список
ПЕРЕЧИСЛЕНИЯ
Перечисление — это набор именованных целых констант.
enum тег {список перечисления}
список

ПЕРЕЧИСЛЕНИЯ
/*
penny (пенни, монета в один цент)
nickel (никель, монета в пять центов)
dime
ПЕРЕЧИСЛЕНИЯ
/*
penny (пенни, монета в один цент)
nickel (никель, монета в пять центов)
dime

ПЕРЕЧИСЛЕНИЯ
enum Err {ERR_READ, ERR_WRITE, ERR_CONVERT};
Err error;
// ...
switch (error) {
case ERR_READ:
ПЕРЕЧИСЛЕНИЯ
enum Err {ERR_READ, ERR_WRITE, ERR_CONVERT};
Err error;
// ...
switch (error) {
case ERR_READ:

ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Если до начала работы с данными невозможно определить, сколько
ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Если до начала работы с данными невозможно определить, сколько

ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Механизм доступа (data engine) к данным –механизм сохранения и
ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Механизм доступа (data engine) к данным –механизм сохранения и

ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Динамические структуры данных (списки, стеки, очереди, деревья) различаются способами
ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Динамические структуры данных (списки, стеки, очереди, деревья) различаются способами

ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Элемент любой динамической структуры данных представляет собой структуру (struct),
ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Элемент любой динамической структуры данных представляет собой структуру (struct),

ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Описание простейшего элемента (компоненты, узла) динамической структуры:
struct Node
ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ
Описание простейшего элемента (компоненты, узла) динамической структуры:
struct Node

СПИСКИ
Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым
СПИСКИ
Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым

СПИСКИ
Самый простой способ связать множество элементов — сделать так, чтобы каждый
СПИСКИ
Самый простой способ связать множество элементов — сделать так, чтобы каждый

СПИСКИ
Каждый элемент списка содержит ключ, идентифицирующий этот элемент.
Ключ обычно бывает либо
СПИСКИ
Каждый элемент списка содержит ключ, идентифицирующий этот элемент.
Ключ обычно бывает либо

СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
INF - информационное поле, данные
NEXT - указатель на
СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
INF - информационное поле, данные
NEXT - указатель на
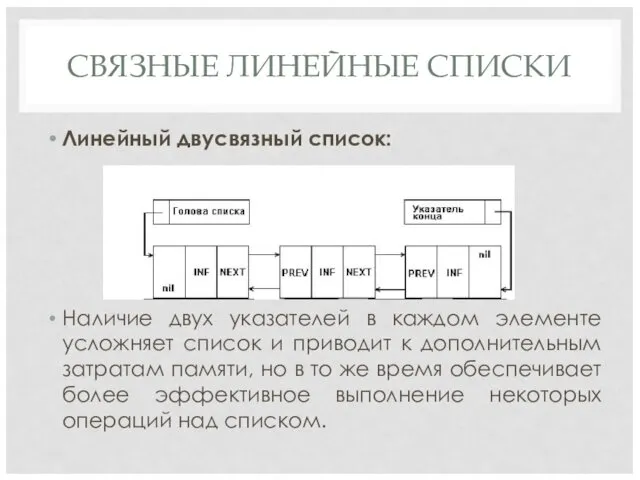
СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
Линейный двусвязный список:
Наличие двух указателей в каждом элементе усложняет
СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
Линейный двусвязный список:
Наличие двух указателей в каждом элементе усложняет
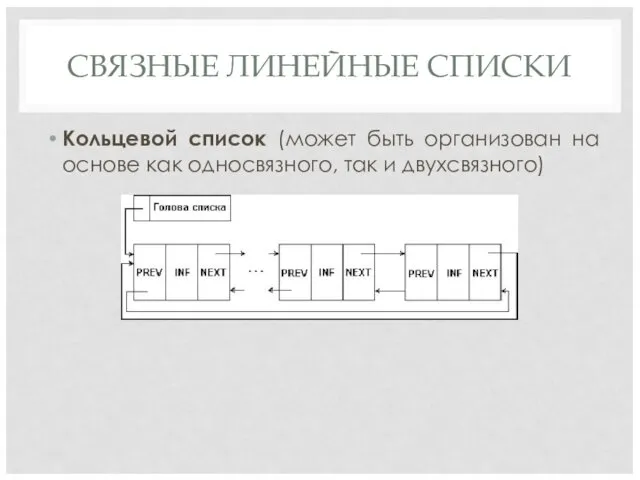
СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
Кольцевой список (может быть организован на основе как односвязного,
СВЯЗНЫЕ ЛИНЕЙНЫЕ СПИСКИ
Кольцевой список (может быть организован на основе как односвязного,

ОПЕРАЦИИ НАД СПИСКАМИ
начальное формирование списка (создание первого элемента);
добавление элемента в конец
ОПЕРАЦИИ НАД СПИСКАМИ
начальное формирование списка (создание первого элемента);
добавление элемента в конец
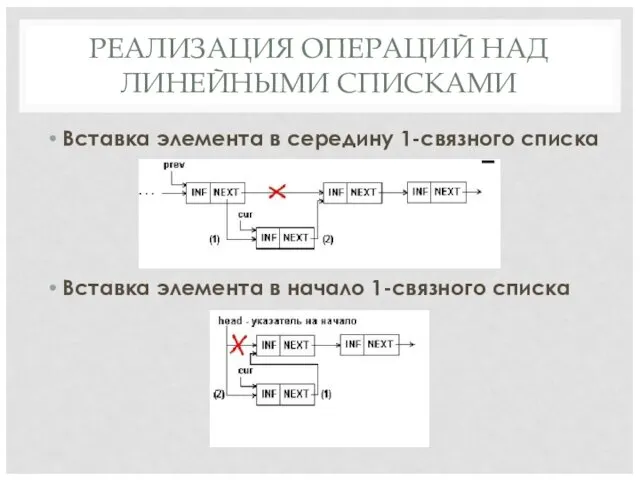
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Вставка элемента в середину 1-связного списка
Вставка элемента
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Вставка элемента в середину 1-связного списка
Вставка элемента
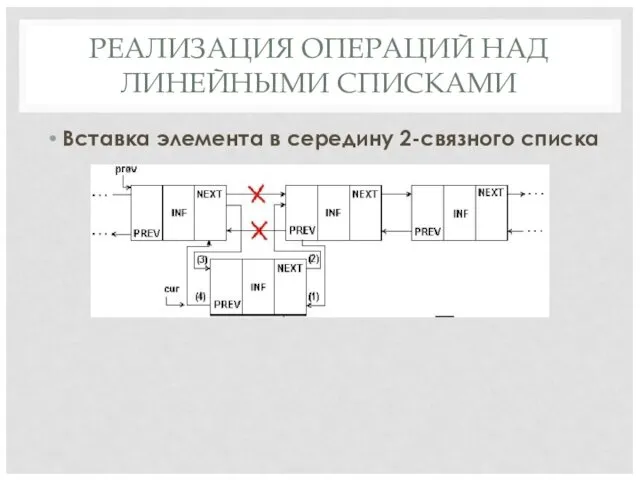
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Вставка элемента в середину 2-связного списка
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Вставка элемента в середину 2-связного списка
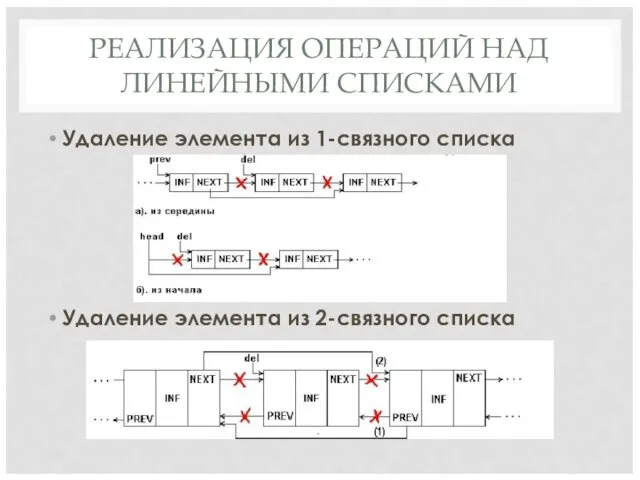
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Удаление элемента из 1-связного списка
Удаление элемента из
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Удаление элемента из 1-связного списка
Удаление элемента из

РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Перестановка элементов 1-связного списка
Изменчивость динамических структур данных
РЕАЛИЗАЦИЯ ОПЕРАЦИЙ НАД ЛИНЕЙНЫМИ СПИСКАМИ
Перестановка элементов 1-связного списка
Изменчивость динамических структур данных

ВОЗМОЖНЫЕ ОПЕРАЦИИ НАД ТИПОМ ДАННЫХ «СПИСОК»
end(l) — вернуть позицию, следующую за
ВОЗМОЖНЫЕ ОПЕРАЦИИ НАД ТИПОМ ДАННЫХ «СПИСОК»
end(l) — вернуть позицию, следующую за

АНАЛИЗ ПРОГРАММЫ
//Описание структуры элемента списка
struct Node
{
int d;
Node *next;
Node *prev;
};
АНАЛИЗ ПРОГРАММЫ
//Описание структуры элемента списка
struct Node
{
int d;
Node *next;
Node *prev;
};

АНАЛИЗ ПРОГРАММЫ
// Формирование первого элемента
Node * first(int d)
{
Node *pv =
АНАЛИЗ ПРОГРАММЫ
// Формирование первого элемента
Node * first(int d)
{
Node *pv =

АНАЛИЗ ПРОГРАММЫ
// Добавление в конец списка
void add(Node **pend, int d)
{
АНАЛИЗ ПРОГРАММЫ
// Добавление в конец списка
void add(Node **pend, int d)
{

АНАЛИЗ ПРОГРАММЫ
// Поиск элемента по ключу
Node * find(Node * const
АНАЛИЗ ПРОГРАММЫ
// Поиск элемента по ключу
Node * find(Node * const

АНАЛИЗ ПРОГРАММЫ
// Вставка элемента
Node * insert(Node * const pbeg, Node
АНАЛИЗ ПРОГРАММЫ
// Вставка элемента
Node * insert(Node * const pbeg, Node

АНАЛИЗ ПРОГРАММЫ
// Удаление элемента
bool remove(Node **pbeg, Node **pend, int key)
{ if
АНАЛИЗ ПРОГРАММЫ
// Удаление элемента
bool remove(Node **pbeg, Node **pend, int key)
{ if
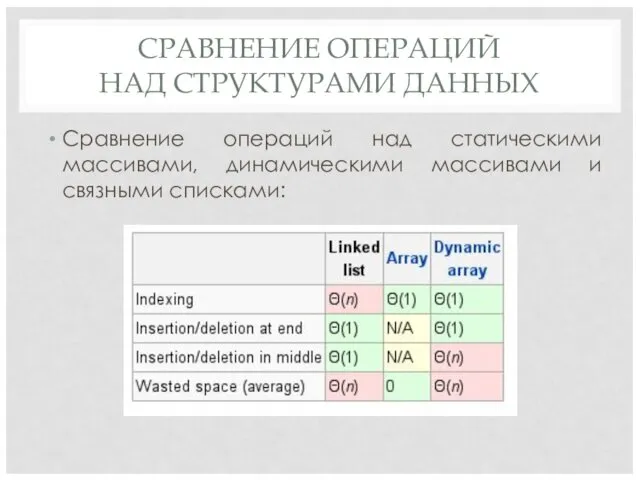
СРАВНЕНИЕ ОПЕРАЦИЙ
НАД СТРУКТУРАМИ ДАННЫХ
Сравнение операций над статическими массивами, динамическими массивами
СРАВНЕНИЕ ОПЕРАЦИЙ
НАД СТРУКТУРАМИ ДАННЫХ
Сравнение операций над статическими массивами, динамическими массивами

ДОСТОИНСТВА СПИСКОВ
лёгкость добавления и удаления элементов
размер ограничен только объёмом памяти компьютера
ДОСТОИНСТВА СПИСКОВ
лёгкость добавления и удаления элементов
размер ограничен только объёмом памяти компьютера

НЕДОСТАТКИ СПИСКОВ
сложность определения адреса элемента по его индексу (номеру) в списке
на
НЕДОСТАТКИ СПИСКОВ
сложность определения адреса элемента по его индексу (номеру) в списке
на
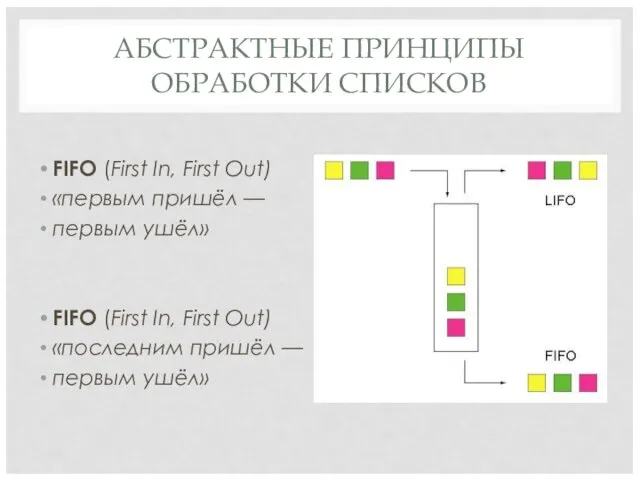
АБСТРАКТНЫЕ ПРИНЦИПЫ ОБРАБОТКИ СПИСКОВ
FIFO (First In, First Out)
«первым пришёл
АБСТРАКТНЫЕ ПРИНЦИПЫ ОБРАБОТКИ СПИСКОВ
FIFO (First In, First Out)
«первым пришёл
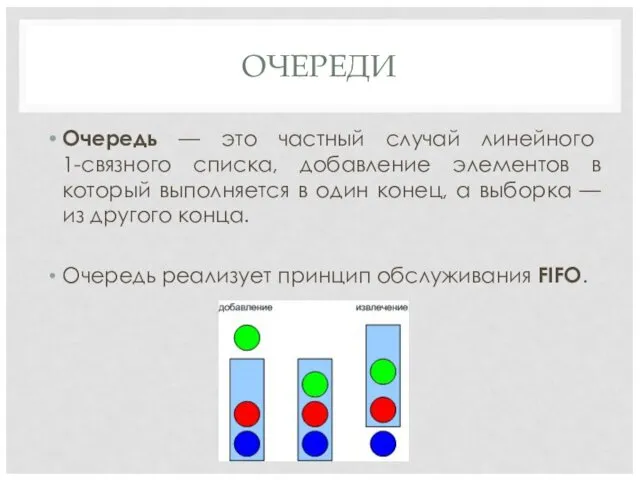
ОЧЕРЕДИ
Очередь — это частный случай линейного
1-связного списка, добавление элементов в
ОЧЕРЕДИ
Очередь — это частный случай линейного 1-связного списка, добавление элементов в

ОЧЕРЕДИ
Типичные операции:
void push(const value_type&) - добавить элемент
void pop() - удалить первый
ОЧЕРЕДИ
Типичные операции:
void push(const value_type&) - добавить элемент
void pop() - удалить первый
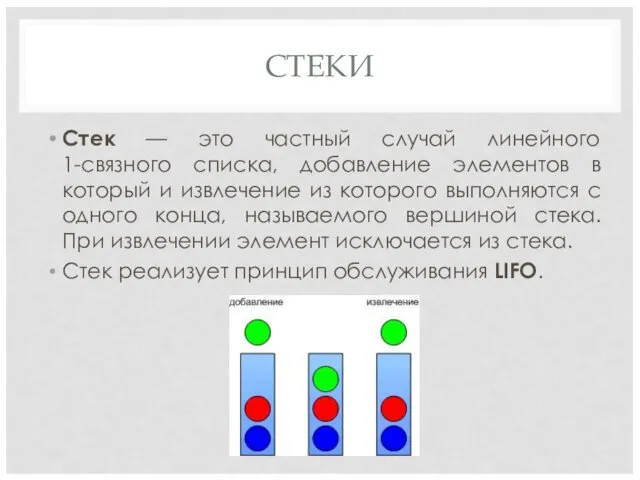
СТЕКИ
Стек — это частный случай линейного
1-связного списка, добавление элементов в
СТЕКИ
Стек — это частный случай линейного 1-связного списка, добавление элементов в

СТЕКИ
Типичные операции:
void push(const value_type&) - добавить элемент
void pop() -
СТЕКИ
Типичные операции:
void push(const value_type&) - добавить элемент
void pop() -

ЗАДАЧИ (СПИСКИ)
1) Написать программу, выводящую элемент списка по его номеру.
2) Определить
ЗАДАЧИ (СПИСКИ)
1) Написать программу, выводящую элемент списка по его номеру.
2) Определить
 Использование интерактивной доски
Использование интерактивной доски Апаратне та програмне забезпечення комп'ютера. Операційні системи
Апаратне та програмне забезпечення комп'ютера. Операційні системи Інструкція
Інструкція Указатели в C++
Указатели в C++ Введение в тестирование программного обеспечения
Введение в тестирование программного обеспечения Информатиканы оқытудың инновациялық технологиялары
Информатиканы оқытудың инновациялық технологиялары Концептуальное проектирование базы данных
Концептуальное проектирование базы данных Системы счисления. Перевод чисел
Системы счисления. Перевод чисел Приложение mywellness cloud
Приложение mywellness cloud Этапы подготовки презентации
Этапы подготовки презентации Глобальные и локальные компьютерные сети
Глобальные и локальные компьютерные сети Документационное обеспечение управления
Документационное обеспечение управления Transmission systems of access networks (TSAN). Lec 1
Transmission systems of access networks (TSAN). Lec 1 Защита информации вчера, сегодня и завтра
Защита информации вчера, сегодня и завтра Методика подготовки учащихся к ЕГЭ по информатике
Методика подготовки учащихся к ЕГЭ по информатике Устройство компьютера
Устройство компьютера Семантическое ядро для статьи, оптимизация и публикация статей
Семантическое ядро для статьи, оптимизация и публикация статей Ethernet
Ethernet Создание сайта книжного магазина Книгомир
Создание сайта книжного магазина Книгомир Программаларды өңдеудің аспаптың құралдары (ПӨАҚ)
Программаларды өңдеудің аспаптың құралдары (ПӨАҚ) Здоровье и аптека
Здоровье и аптека Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Формати даних: числовий, текстовий, формат дати. Табличний процесор
Формати даних: числовий, текстовий, формат дати. Табличний процесор Информация и ее виды
Информация и ее виды Разработка проекта сети для предприятия с введением дополнительного сегмента
Разработка проекта сети для предприятия с введением дополнительного сегмента Человеко машинное взаимодествие. Проектирование пользовательского интерфейса
Человеко машинное взаимодествие. Проектирование пользовательского интерфейса Среда Visual Basic. Основные понятия VB
Среда Visual Basic. Основные понятия VB Чотири обґрунтування для засобів масової інформації
Чотири обґрунтування для засобів масової інформації