- Понятия о MDS. Аналитические службы MS SQL Server

Содержание
- 2. Содержание 1. Цель использования аналитических служб 2. Модели добычи данных 2. Модели добычи данных (DataMining) 3.
- 3. 1. Цель использования аналитических служб Информация, которую вы ищете, уже находится в вашей базе данных. Но
- 4. Аналитические модели в SQL Server 2005
- 5. 2. Модели добычи данных (DataMining) Модель добычи данных представляет собой виртуальную структуру, хранящую данные, используемые при
- 6. 3. Алгоритмы добычи данных Microsoft Association Rules. Правила ассоциаций ищут элементы, которые наиболее вероятно появляются вместе
- 7. 3.1. Метод деревья решений Деревья решений применяются уже довольно долгое время для поиска набора определенных характеристик
- 8. Задача о грибах. Data Mining, будет состоять из двух процессов: обучение модели (которое выполняется однократно и
- 9. Исходные данные В качестве исходных данных для обучения модели мы воспользуемся набором данных в 8416 грибов,
- 10. Исходные данные к определению признаков съедобности грибов
- 11. Выбор полей для исследования
- 12. Пример отчета дерева решений
- 13. Правила классификации данных выглядят так: если запах гриба миндальный или анисовый (Odor = ALMOND или Odor
- 14. Второй уровень иерархии Второй уровень иерархии доступен только для ветви, содержащей данные о грибах без запаха,
- 15. Третий уровень иерархии Третий уровень иерархии - поверхность ножки под кольцом (Stalk Surface Below Ring), далее
- 16. Область применения Таким образом, алгоритм построения деревьев решений позволяет определить набор значений характеристик, позволяющих отделить одну
- 17. 3.2. Кластеризация При помощи кластеризации информация группируется по схожим признакам. В результате применения данной методики мы
- 18. Рассмотрим многофакторную модель анализа индекса РТС Задачи, решаемые в процессе кластеризации выглядят следующим образом: 1. построить
- 19. Пример кластеризации
- 20. Перемещая движок All Links вверх или вниз, можно просмотреть наличие сильных и слабых связей между кластерами
- 21. Панель Cluster Discrimination
- 22. 4. Построение модели добычи данных
- 23. Выбор команды «Новая модель данных»
- 24. Выбор способа хранения исходных данных
- 25. Выбор куба для дальнейшего анализа
- 26. Выбор алгоритма DataMining
- 27. Выбор уровня измерения для многомерной модели
- 28. Выбор атрибутов
- 29. Разделение атрибутов
- 30. Ввод имени модели
- 31. Список моделей Data Mining
- 32. Расчет модели В панели MS_Solution Explorer щелкните правой кнопкой мыши на имени модели и из контекстного
- 33. Сообщение об окончании процессинга
- 34. Запуск на иллюстрацию результатов построения модели
- 35. Вид модели Naive Bayes в виде графа
- 36. 5. Анализ модели Microsoft Naive Bayes Появление первой связи между кластерами
- 37. Во вторую очередь появляется влияние уровня средней зарплаты (WAG_R_M)
- 38. В-третьих, появляется влияние добычи полезных ископаемых (в % к январю 1995 года) IMQ C
- 39. В-четвертых, появляется влияние временного роста и инвестиций в основной капитал в млрд. руб. (Date, INFC M)
- 40. Влияние показателя «Добыча сырой нефти и газа»
- 41. Влияние показателя «Индекс промышленности».
- 43. Скачать презентацию

Содержание
1. Цель использования аналитических служб
2. Модели добычи данных 2. Модели добычи
Содержание
1. Цель использования аналитических служб
2. Модели добычи данных 2. Модели добычи

1. Цель использования аналитических служб
Информация, которую вы ищете, уже находится в
1. Цель использования аналитических служб
Информация, которую вы ищете, уже находится в
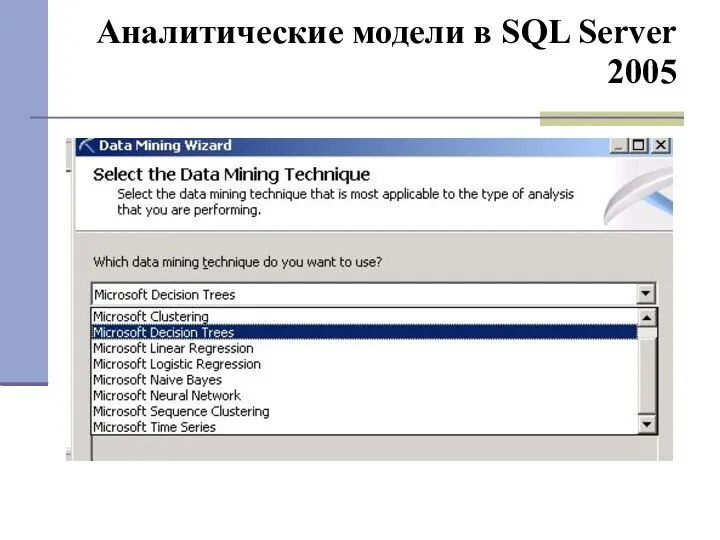
Аналитические модели в SQL Server 2005
Аналитические модели в SQL Server 2005

2. Модели добычи данных (DataMining)
Модель добычи данных представляет собой виртуальную
2. Модели добычи данных (DataMining)
Модель добычи данных представляет собой виртуальную

3. Алгоритмы добычи данных
Microsoft Association Rules. Правила ассоциаций ищут
3. Алгоритмы добычи данных
Microsoft Association Rules. Правила ассоциаций ищут

3.1. Метод деревья решений
Деревья решений применяются уже довольно долгое время
3.1. Метод деревья решений
Деревья решений применяются уже довольно долгое время

Задача о грибах. Data Mining, будет состоять из двух процессов:
обучение модели
Задача о грибах. Data Mining, будет состоять из двух процессов:
обучение модели

Исходные данные
В качестве исходных данных для обучения модели мы воспользуемся
Исходные данные
В качестве исходных данных для обучения модели мы воспользуемся
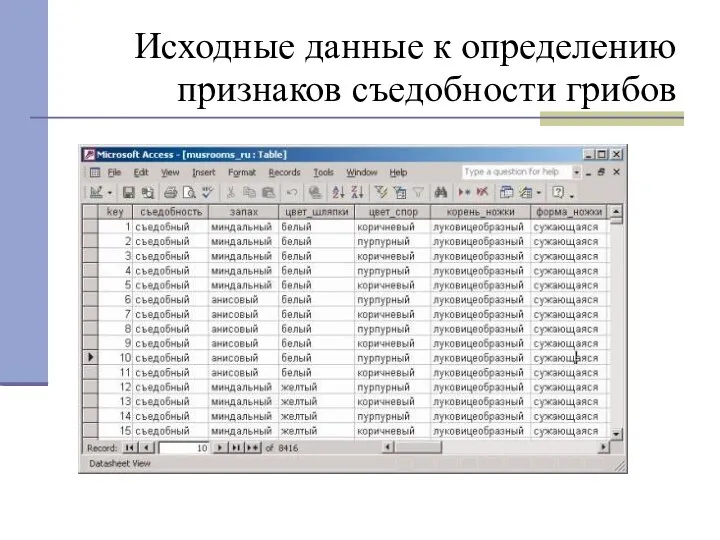
Исходные данные к определению признаков съедобности грибов
Исходные данные к определению признаков съедобности грибов

Выбор полей для исследования
Выбор полей для исследования

Пример отчета дерева решений
Пример отчета дерева решений

Правила классификации данных выглядят так:
если запах гриба миндальный или анисовый
Правила классификации данных выглядят так:
если запах гриба миндальный или анисовый

Второй уровень иерархии
Второй уровень иерархии доступен только для ветви, содержащей
Второй уровень иерархии
Второй уровень иерархии доступен только для ветви, содержащей

Третий уровень иерархии
Третий уровень иерархии - поверхность ножки под кольцом
Третий уровень иерархии
Третий уровень иерархии - поверхность ножки под кольцом

Область применения
Таким образом, алгоритм построения деревьев решений позволяет определить набор значений
Область применения
Таким образом, алгоритм построения деревьев решений позволяет определить набор значений

3.2. Кластеризация
При помощи кластеризации информация группируется по схожим признакам. В
3.2. Кластеризация
При помощи кластеризации информация группируется по схожим признакам. В

Рассмотрим многофакторную модель анализа индекса РТС
Задачи, решаемые в процессе кластеризации выглядят
Рассмотрим многофакторную модель анализа индекса РТС
Задачи, решаемые в процессе кластеризации выглядят
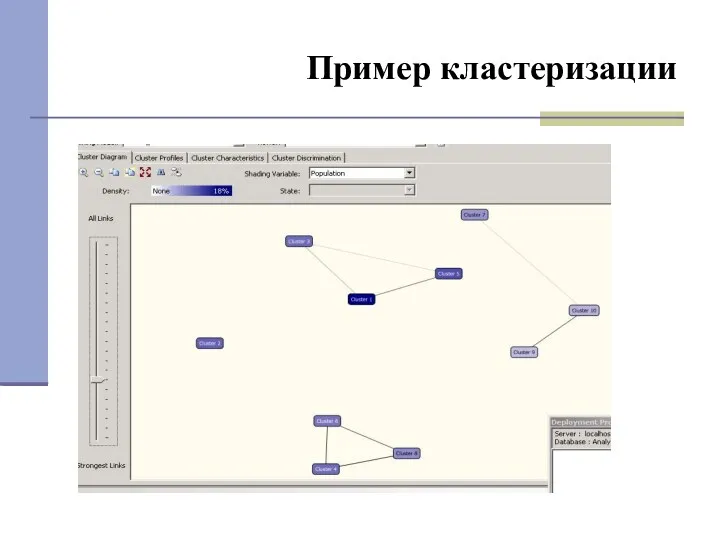
Пример кластеризации
Пример кластеризации
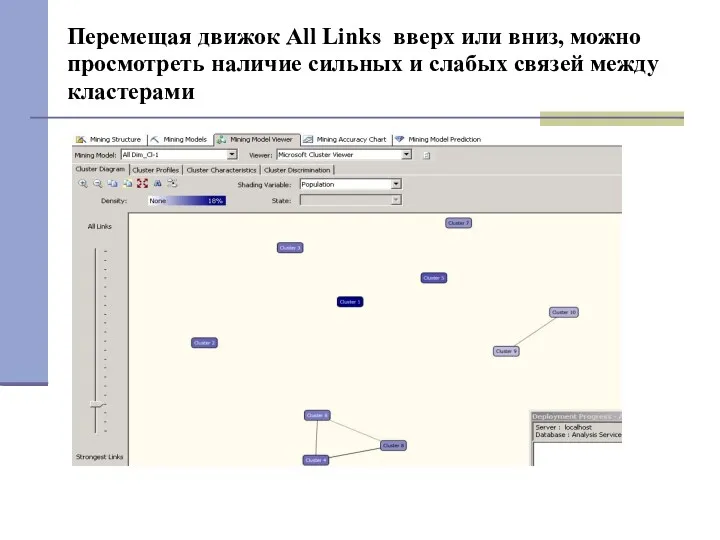
Перемещая движок All Links вверх или вниз, можно просмотреть наличие сильных
Перемещая движок All Links вверх или вниз, можно просмотреть наличие сильных

Панель Cluster Discrimination
Панель Cluster Discrimination
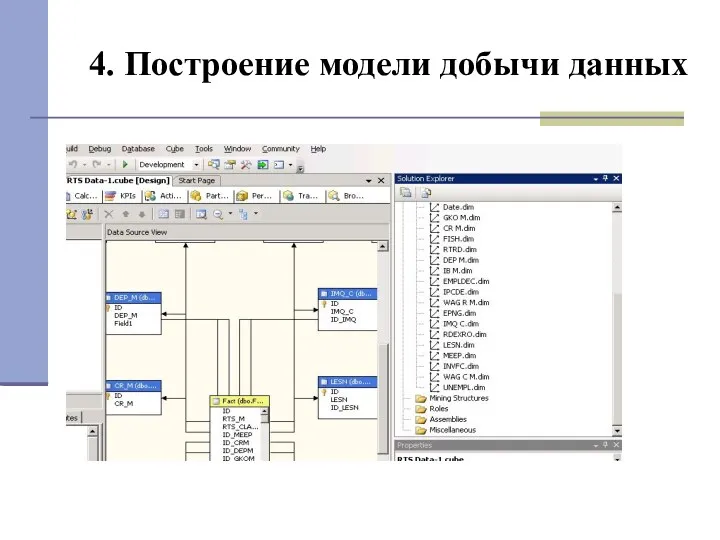
4. Построение модели добычи данных
4. Построение модели добычи данных
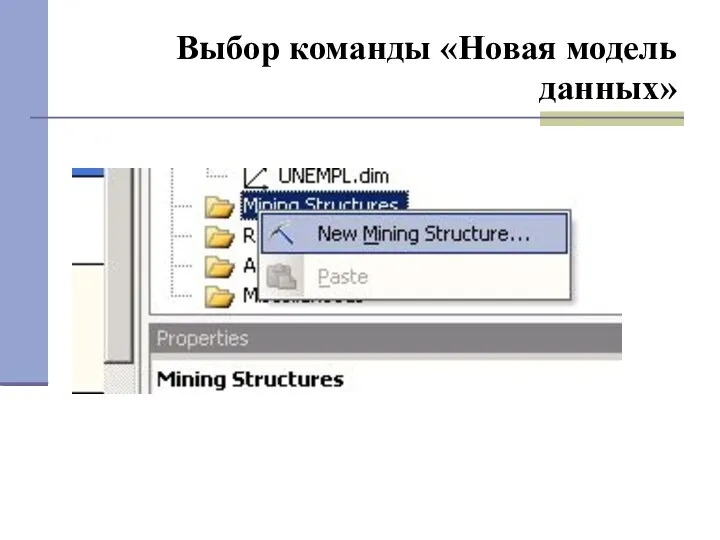
Выбор команды «Новая модель данных»
Выбор команды «Новая модель данных»
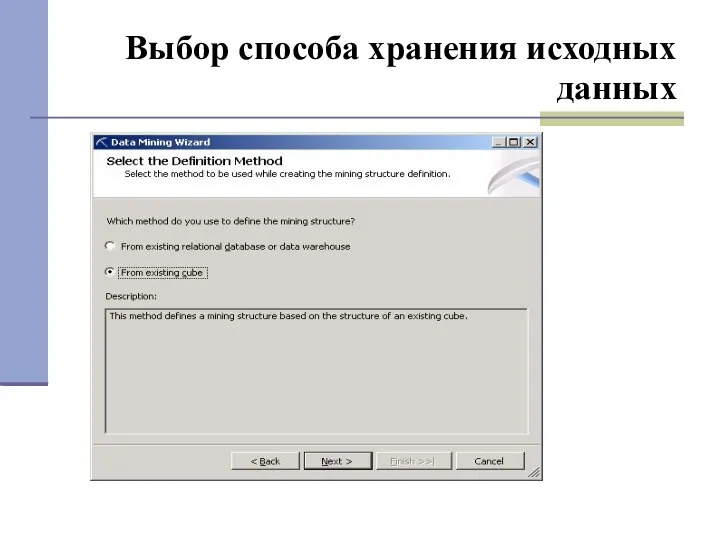
Выбор способа хранения исходных данных
Выбор способа хранения исходных данных
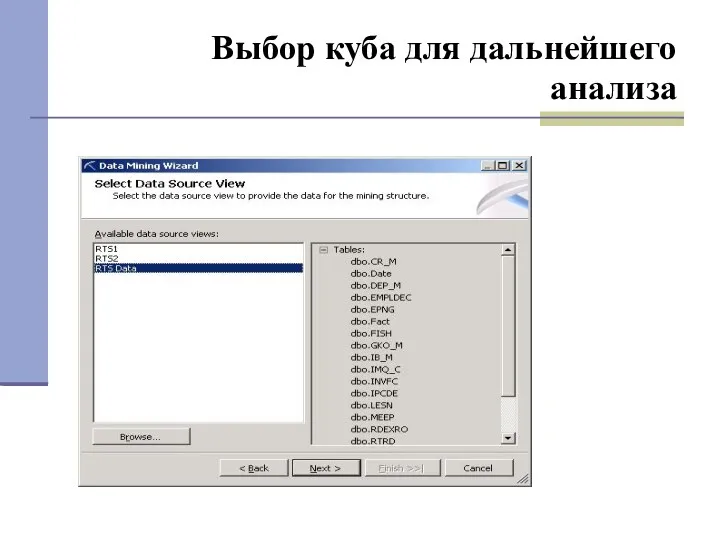
Выбор куба для дальнейшего анализа
Выбор куба для дальнейшего анализа
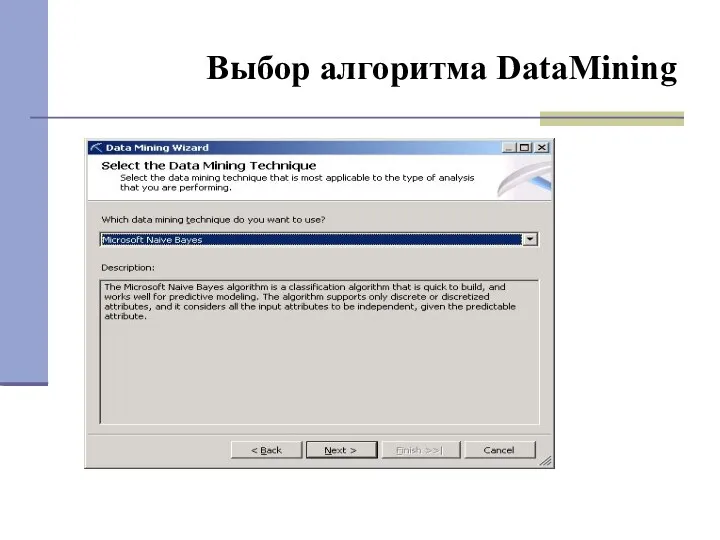
Выбор алгоритма DataMining
Выбор алгоритма DataMining
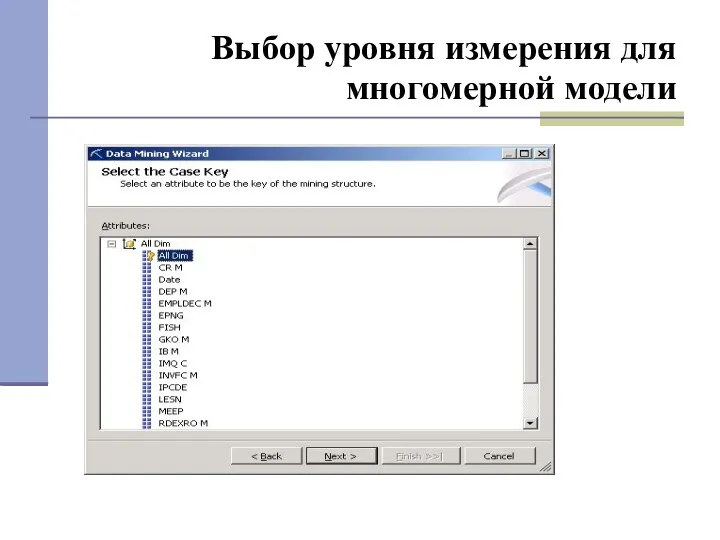
Выбор уровня измерения для многомерной модели
Выбор уровня измерения для многомерной модели
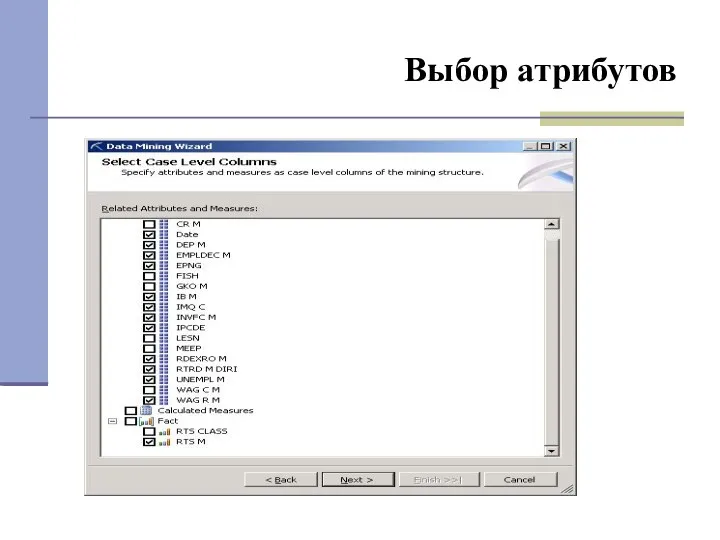
Выбор атрибутов
Выбор атрибутов
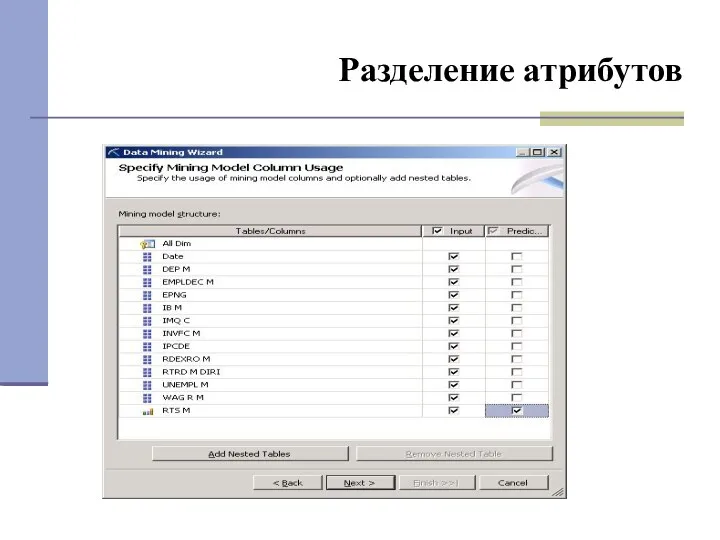
Разделение атрибутов
Разделение атрибутов
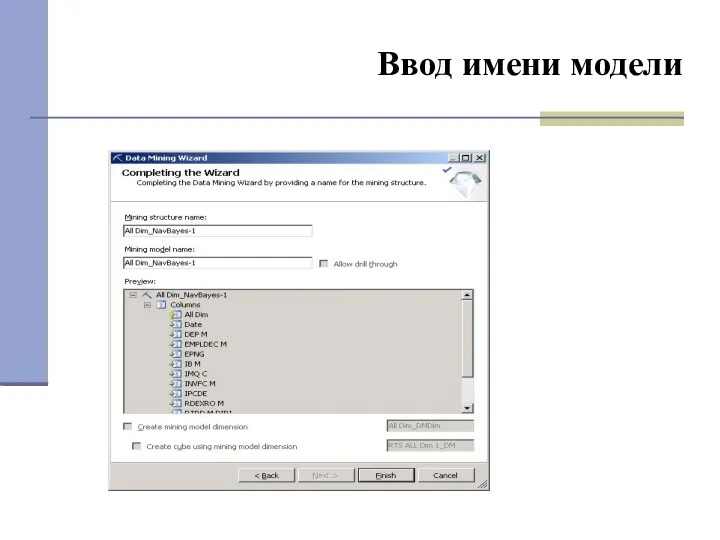
Ввод имени модели
Ввод имени модели
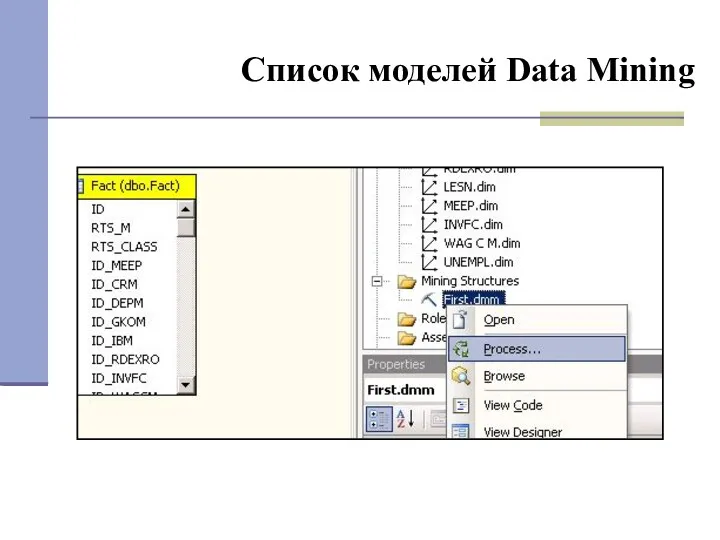
Список моделей Data Mining
Список моделей Data Mining

Расчет модели
В панели MS_Solution Explorer щелкните правой кнопкой мыши на имени
Расчет модели
В панели MS_Solution Explorer щелкните правой кнопкой мыши на имени
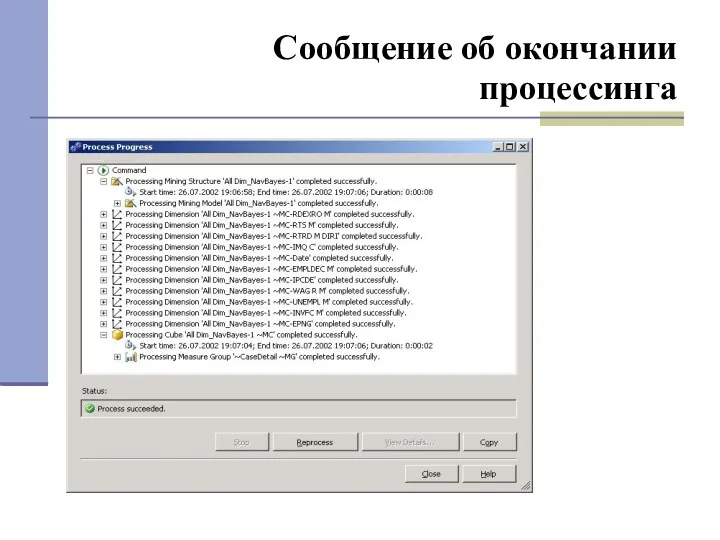
Сообщение об окончании процессинга
Сообщение об окончании процессинга
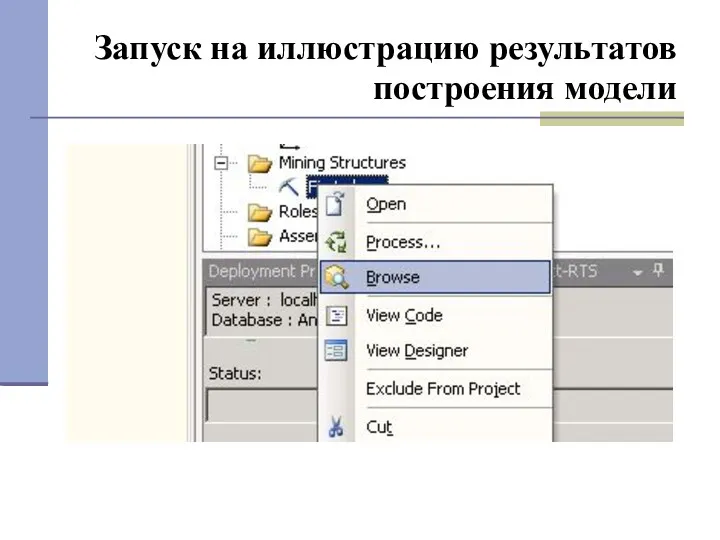
Запуск на иллюстрацию результатов построения модели
Запуск на иллюстрацию результатов построения модели
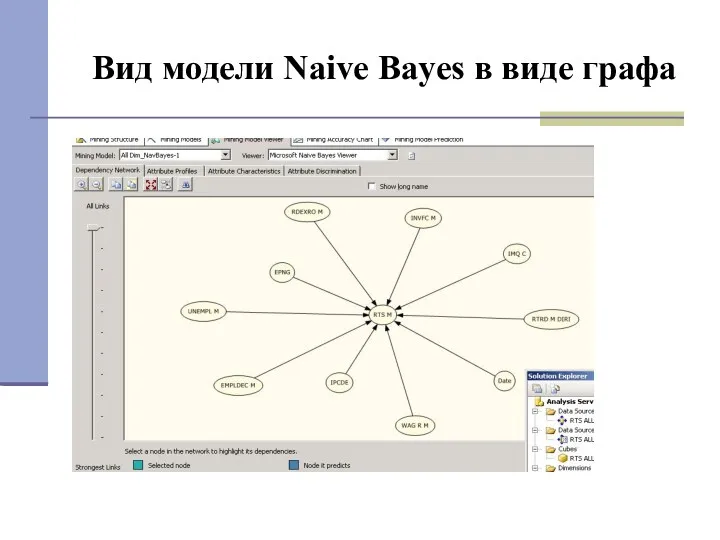
Вид модели Naive Bayes в виде графа
Вид модели Naive Bayes в виде графа

5. Анализ модели Microsoft Naive Bayes
Появление первой связи между кластерами
5. Анализ модели Microsoft Naive Bayes
Появление первой связи между кластерами
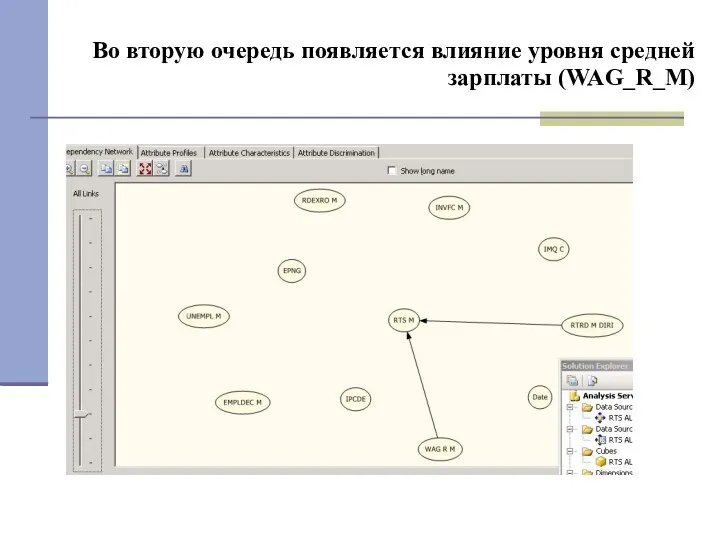
Во вторую очередь появляется влияние уровня средней зарплаты (WAG_R_M)
Во вторую очередь появляется влияние уровня средней зарплаты (WAG_R_M)
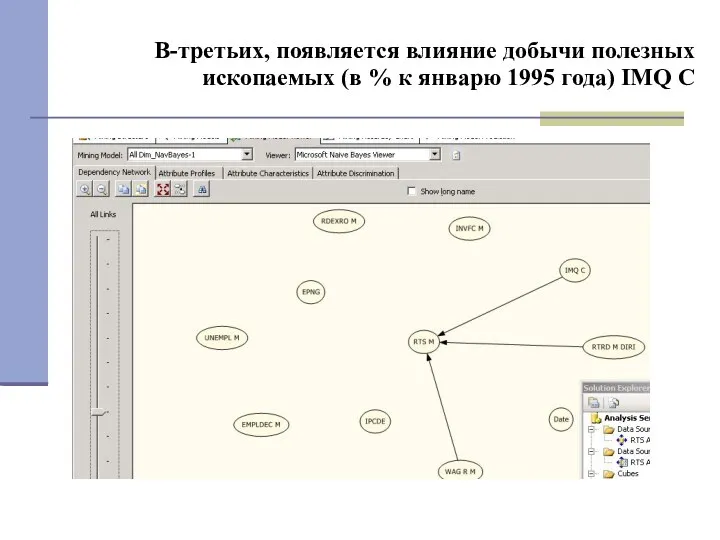
В-третьих, появляется влияние добычи полезных ископаемых (в % к январю 1995
В-третьих, появляется влияние добычи полезных ископаемых (в % к январю 1995
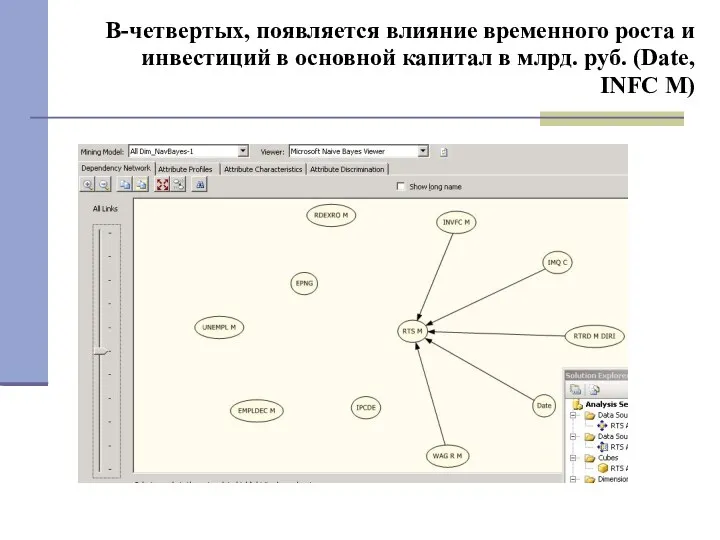
В-четвертых, появляется влияние временного роста и инвестиций в основной капитал в
В-четвертых, появляется влияние временного роста и инвестиций в основной капитал в
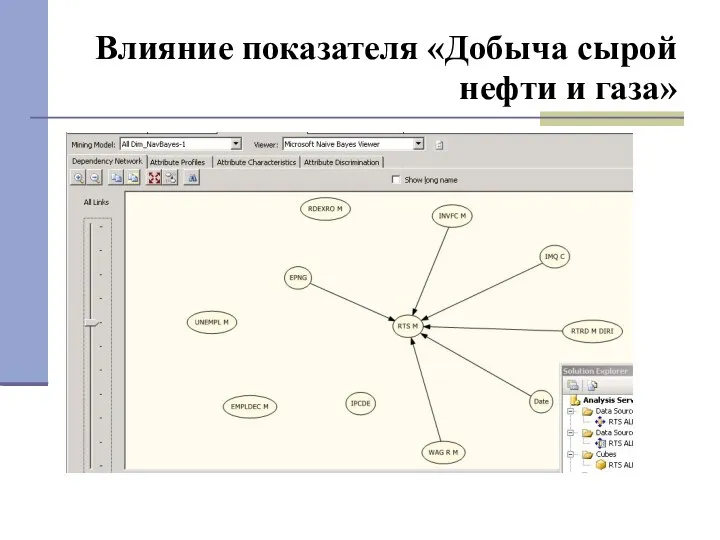
Влияние показателя «Добыча сырой нефти и газа»
Влияние показателя «Добыча сырой нефти и газа»
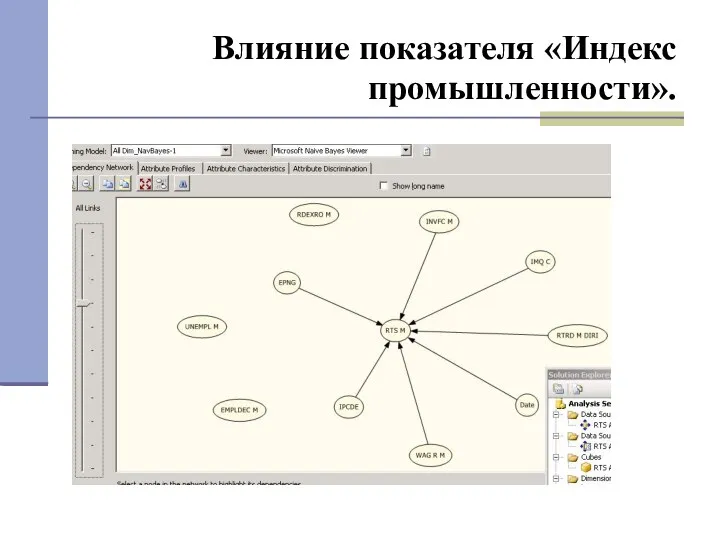
Влияние показателя «Индекс промышленности».
Влияние показателя «Индекс промышленности».
 База данных как модель предметной области
База данных как модель предметной области Оформление информационно-справочных документов. (Лекция 3)
Оформление информационно-справочных документов. (Лекция 3) Робот-спасатель ЯМ-3
Робот-спасатель ЯМ-3 Презентация журнала Работница
Презентация журнала Работница Алгоритмы
Алгоритмы Представление информации в различных системах счисления
Представление информации в различных системах счисления Теоретические основы информатики. Информация
Теоретические основы информатики. Информация Интерактивный плакат
Интерактивный плакат Локальные сети
Локальные сети Page templates and functionality
Page templates and functionality Django. Запись данных. Урок 11
Django. Запись данных. Урок 11 Веб-ресурс для Зимової школи програмування ВоФК НУХТ
Веб-ресурс для Зимової школи програмування ВоФК НУХТ Информатика. Кодирование чисел в ЭВМ
Информатика. Кодирование чисел в ЭВМ Ideas about site. Dental laboratory
Ideas about site. Dental laboratory HTML формы
HTML формы EXCEL Встроенные функции
EXCEL Встроенные функции Графический редактор Adobe Photoshop. История создания
Графический редактор Adobe Photoshop. История создания Инфо-умники и умницы. Викторина
Инфо-умники и умницы. Викторина Вивчення мережі
Вивчення мережі Буква - строка - текст. Искусство шрифта
Буква - строка - текст. Искусство шрифта Современные информационные технологии. Методы информационных технологий
Современные информационные технологии. Методы информационных технологий Опыт внедрения электронного учебника в библиотеке
Опыт внедрения электронного учебника в библиотеке Основы операторского продукта унитарного предприятия Велком
Основы операторского продукта унитарного предприятия Велком Аватар, ЦА, золотые вопросы
Аватар, ЦА, золотые вопросы Мобильное приложение
Мобильное приложение Моделирование в среде табличного процессора
Моделирование в среде табличного процессора Строки. Класс System.String
Строки. Класс System.String Алгоритмы с ветвлениями
Алгоритмы с ветвлениями