- Программирование многоядерных архитектур

Содержание
- 2. План презентации кратко о параллельных ЭВМ; введение в многопоточность; интерфейсы работы с потоками; OpenMP: организация многопоточности,
- 3. Кратко о параллельных ЭВМ
- 4. Основные классы параллельных ЭВМ SMP MPP PVP COW GPGPU FPGA NOW Xilinx, Altera NVIDIA, ATI, S3
- 5. Основные виды параллельных ЭВМ Мультикомпьютеры Мультипроцессоры
- 6. Многоядерность
- 7. Примеры многоядерных процессоров Intel XEON Phi 60 ядер Tilera TILE-Gx8072 72 ядра GreenArrays GA144A12 144 ядра
- 8. Процессор Tilera TILE-Gx8072
- 9. Введение в многопоточность процесс, поток, многозадачность, многопоточная программа.
- 10. Процесс Процесс - экземпляр запущенной на исполнение программы. Имеет собственные: состояние, код возврата, переменные окружения, идентификаторы
- 11. Поток Разделяет общие: адресное пространство/ память, данные в памяти, исполняемый код. Имеет собственные: ID, приоритет; Регистры:
- 12. Многозадачность Формы многозадачности: разделение времени; параллельное исполнение. Виды планирования многозадачности: вытесняющая (Win32, Win64, Linux); кооперативная (Win16).
- 13. Интерфейсы по работе с потоками
- 14. OpenMP организация многопоточности; синхронизация; что замедляет вычисления.
- 15. Что такое OpenMP? Стандарт OpenMP определяет: интерфейс (API); набор прагм компилятора; переменные окружения для построения многопоточных
- 16. Архитектура OpenMP
- 17. Модель исполнения Fork-join
- 18. OpenMP программа 1 Напишем многопоточную программу, в которой: каждый поток печатает свой номер, один поток печатает
- 19. Шаги создания OpenMP программы Подключение заголовочного файла: #include 2. Создание параллельно исполняемого блока в функции main():
- 20. Шаги создания OpenMP программы 3. Декларация переменной, собственную копию которой имеет каждый поток: #include void main(){
- 21. Шаги создания OpenMP программы 3. Получение и печать номера потока: void main(){ int tid; #pragma omp
- 22. Шаги создания OpenMP программы 4. Декларация переменной, общей для всех потоков. 5. Получение и печать количества
- 23. Шаги создания OpenMP программы 6. Исполнение кода только одним потоком: #pragma omp parallel private(tid) { tid
- 24. Шаги создания OpenMP программы 7. Компиляция OpenMP программы: В Windows + Microsoft Visual C++: cl.exe myprog.c
- 25. OpenMP программа 2 Напишем многопоточную программу, для поэлементного суммирования двух векторов способами: используя конструкцию распределения работы,
- 26. OpenMP программа 2 1. Пишем общую часть #include void main () { int i; float a[N],
- 27. Способ 1. Распределение работы между потоками 2. Добавляем параллельную часть #pragma omp parallel shared(a,b,c) private(i) {
- 28. Ограничения в for число итераций известно до входа в цикл, итерации независимы Индекс меняется только следующим
- 29. Способ 2. С использованием секций 2. Добавляем параллельную часть #pragma omp parallel shared(a,b,c) private(i) { #pragma
- 30. OpenMP программа 3 Напишем многопоточную программу вычисления скалярного произведения векторов.
- 31. OpenMP программа 3 1. Напишем последовательную часть. #include #define N 1000 void main() { int i;
- 32. OpenMP программа 3 1. Напишем параллельную часть. #pragma omp parallel for \ default(shared) private(i) \ schedule(static,
- 33. OpenMP программа 4 Напишем многопоточную программу, для увеличения счетчика на единицу: наивно; с синхронизацией.
- 34. Вариант 1. Наивный #include void main(){ int x; x = 0; #pragma omp parallel for shared(x)
- 35. Вариант 1. Наивный $ ./plus1 x=977177 $ ./plus1 x=975883 $ ./plus1 x=980608 $ ./plus1 x=979246 Получился
- 36. Вариант 1. Наивный
- 37. Вариант 2. С синхронизацией #include void main() { int x; x = 0; #pragma omp parallel
- 38. Вариант 2. С синхронизацией $ ./plus2 x=1000000
- 39. Вариант 2. С синхронизацией
- 40. Что замедляет вычисления? избыточное число порождений потока -> если можно, выносим параллельный блок из цикла; одновременный
- 41. Цель работы Написание многопоточного приложения с использованием интерфейса OpenMP.
- 43. Скачать презентацию

План презентации
кратко о параллельных ЭВМ;
введение в многопоточность;
интерфейсы работы с потоками;
OpenMP:
организация многопоточности,
синхронизация,
что
План презентации
кратко о параллельных ЭВМ;
введение в многопоточность;
интерфейсы работы с потоками;
OpenMP:
организация многопоточности,
синхронизация,
что

Кратко о параллельных ЭВМ
Кратко о параллельных ЭВМ
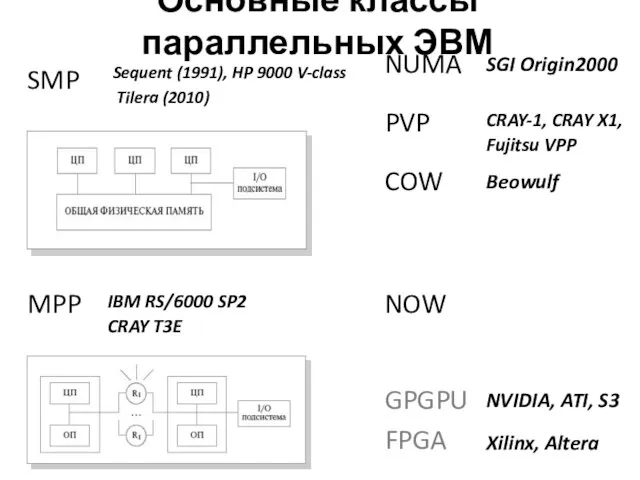
Основные классы параллельных ЭВМ
SMP
MPP
PVP
COW
GPGPU
FPGA
NOW
Xilinx, Altera
NVIDIA, ATI, S3
Sequent (1991), HP 9000 V-class
Основные классы параллельных ЭВМ
SMP
MPP
PVP
COW
GPGPU
FPGA
NOW
Xilinx, Altera
NVIDIA, ATI, S3
Sequent (1991), HP 9000 V-class
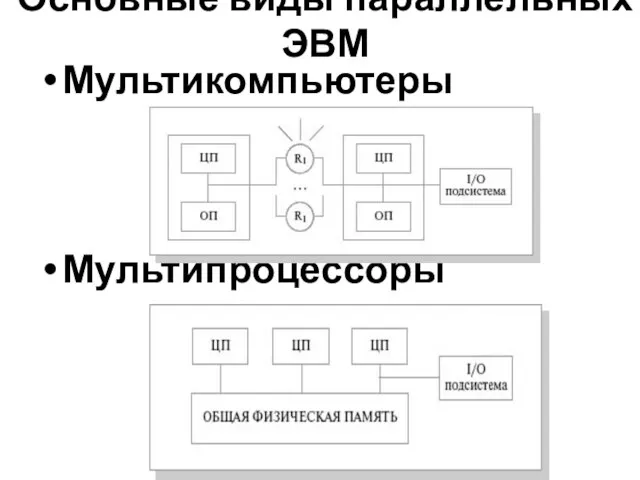
Основные виды параллельных ЭВМ
Мультикомпьютеры
Мультипроцессоры
Основные виды параллельных ЭВМ
Мультикомпьютеры
Мультипроцессоры

Многоядерность
Многоядерность

Примеры многоядерных процессоров
Intel XEON Phi 60 ядер
Tilera TILE-Gx8072 72 ядра
GreenArrays GA144A12
Примеры многоядерных процессоров
Intel XEON Phi 60 ядер
Tilera TILE-Gx8072 72 ядра
GreenArrays GA144A12
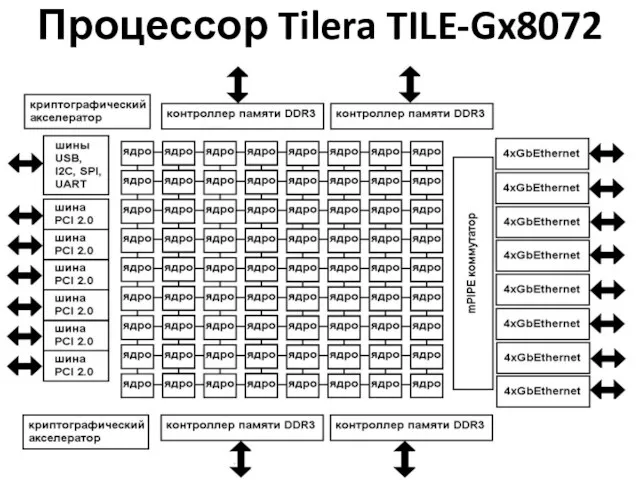
Процессор Tilera TILE-Gx8072
Процессор Tilera TILE-Gx8072

Введение в многопоточность
процесс,
поток,
многозадачность,
многопоточная программа.
Введение в многопоточность
процесс,
поток,
многозадачность,
многопоточная программа.

Процесс
Процесс - экземпляр запущенной на исполнение программы.
Имеет собственные:
состояние, код возврата, переменные
Процесс
Процесс - экземпляр запущенной на исполнение программы.
Имеет собственные:
состояние, код возврата, переменные
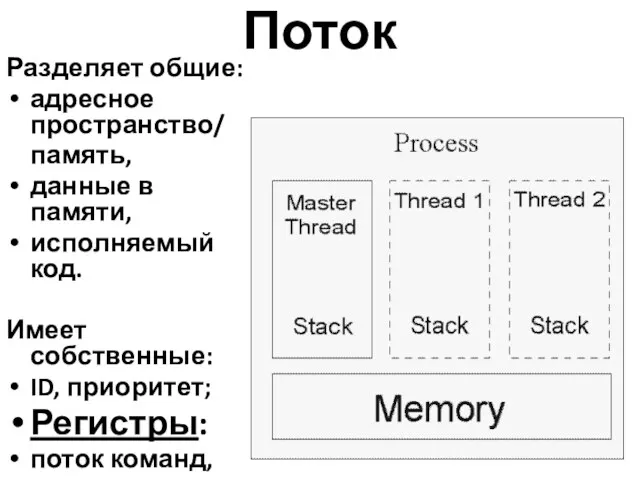
Поток
Разделяет общие:
адресное пространство/
память,
данные в памяти,
исполняемый код.
Имеет собственные:
ID, приоритет;
Регистры:
поток команд,
стек,
TLS.
Поток
Разделяет общие:
адресное пространство/
память,
данные в памяти,
исполняемый код.
Имеет собственные:
ID, приоритет;
Регистры:
поток команд,
стек,
TLS.

Многозадачность
Формы многозадачности:
разделение времени;
параллельное исполнение.
Виды планирования многозадачности:
вытесняющая (Win32, Win64, Linux);
кооперативная (Win16).
Многозадачность
Формы многозадачности:
разделение времени;
параллельное исполнение.
Виды планирования многозадачности:
вытесняющая (Win32, Win64, Linux);
кооперативная (Win16).
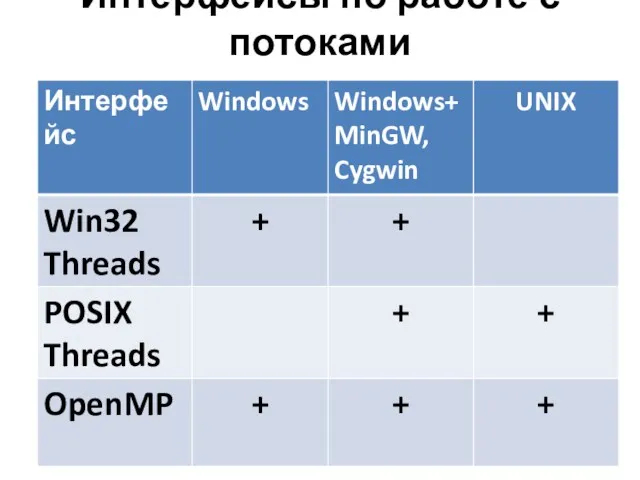
Интерфейсы по работе с потоками
Интерфейсы по работе с потоками

OpenMP
организация многопоточности;
синхронизация;
что замедляет вычисления.
OpenMP
организация многопоточности;
синхронизация;
что замедляет вычисления.

Что такое OpenMP?
Стандарт OpenMP определяет:
интерфейс (API);
набор прагм компилятора;
переменные окружения
для построения многопоточных
Что такое OpenMP?
Стандарт OpenMP определяет:
интерфейс (API);
набор прагм компилятора;
переменные окружения
для построения многопоточных
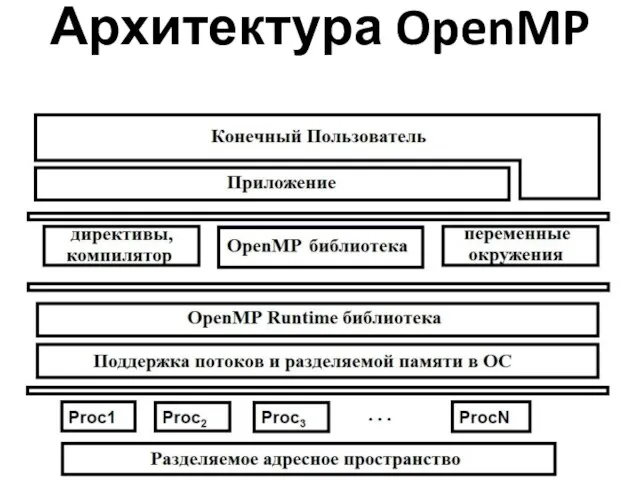
Архитектура OpenMP
Архитектура OpenMP
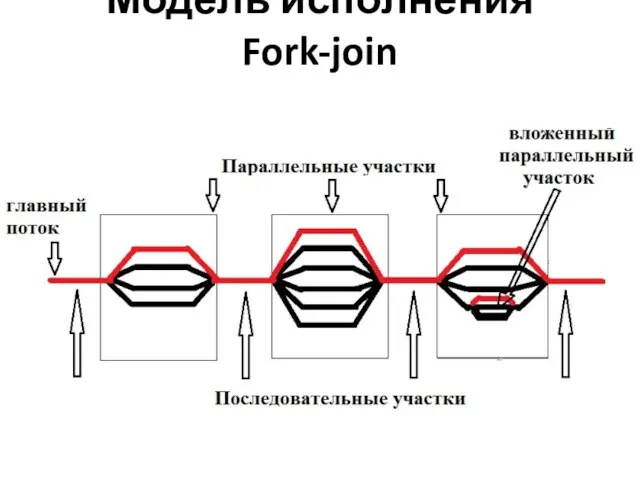
Модель исполнения Fork-join
Модель исполнения Fork-join

OpenMP программа 1
Напишем многопоточную программу, в которой:
каждый поток печатает свой
OpenMP программа 1
Напишем многопоточную программу, в которой:
каждый поток печатает свой

Шаги создания OpenMP программы
Подключение заголовочного файла:
#include
2. Создание параллельно исполняемого блока
Шаги создания OpenMP программы
Подключение заголовочного файла:
#include
2. Создание параллельно исполняемого блока

Шаги создания OpenMP программы
3. Декларация переменной, собственную копию которой имеет каждый
Шаги создания OpenMP программы
3. Декларация переменной, собственную копию которой имеет каждый

Шаги создания OpenMP программы
3. Получение и печать номера потока:
void main(){
int tid;
#pragma
Шаги создания OpenMP программы
3. Получение и печать номера потока:
void main(){
int tid;
#pragma

Шаги создания OpenMP программы
4. Декларация переменной, общей для всех потоков.
5. Получение
Шаги создания OpenMP программы
4. Декларация переменной, общей для всех потоков.
5. Получение

Шаги создания OpenMP программы
6. Исполнение кода только одним потоком:
#pragma omp parallel
Шаги создания OpenMP программы
6. Исполнение кода только одним потоком:
#pragma omp parallel

Шаги создания OpenMP программы
7. Компиляция OpenMP программы:
В Windows + Microsoft Visual
Шаги создания OpenMP программы
7. Компиляция OpenMP программы:
В Windows + Microsoft Visual

OpenMP программа 2
Напишем многопоточную программу, для поэлементного суммирования двух векторов способами:
используя
OpenMP программа 2
Напишем многопоточную программу, для поэлементного суммирования двух векторов способами:
используя

OpenMP программа 2
1. Пишем общую часть
#include
void main ()
{ int i;
float
OpenMP программа 2
1. Пишем общую часть
#include
void main ()
{ int i;
float

Способ 1. Распределение работы между потоками
2. Добавляем параллельную часть
#pragma omp parallel
Способ 1. Распределение работы между потоками
2. Добавляем параллельную часть
#pragma omp parallel

Ограничения в for
число итераций известно до входа в цикл,
итерации независимы
Индекс меняется
Ограничения в for
число итераций известно до входа в цикл,
итерации независимы
Индекс меняется

Способ 2. С использованием секций
2. Добавляем параллельную часть
#pragma omp parallel shared(a,b,c)
Способ 2. С использованием секций
2. Добавляем параллельную часть
#pragma omp parallel shared(a,b,c)

OpenMP программа 3
Напишем многопоточную программу вычисления скалярного произведения векторов.
OpenMP программа 3
Напишем многопоточную программу вычисления скалярного произведения векторов.

OpenMP программа 3
1. Напишем последовательную часть.
#include
#define N 1000
void main()
{ int i;
float
OpenMP программа 3
1. Напишем последовательную часть.
#include
#define N 1000
void main()
{ int i;
float

OpenMP программа 3
1. Напишем параллельную часть.
#pragma omp parallel for \
default(shared) private(i)
OpenMP программа 3
1. Напишем параллельную часть.
#pragma omp parallel for \
default(shared) private(i)

OpenMP программа 4
Напишем многопоточную программу, для увеличения счетчика на единицу:
наивно;
с синхронизацией.
OpenMP программа 4
Напишем многопоточную программу, для увеличения счетчика на единицу:
наивно;
с синхронизацией.

Вариант 1. Наивный
#include
void main(){
int x; x = 0;
#pragma omp parallel
Вариант 1. Наивный
#include
void main(){
int x; x = 0;
#pragma omp parallel

Вариант 1. Наивный
$ ./plus1
x=977177
$ ./plus1
x=975883
$ ./plus1
x=980608
$ ./plus1
x=979246
Получился
Вариант 1. Наивный
$ ./plus1
x=977177
$ ./plus1
x=975883
$ ./plus1
x=980608
$ ./plus1
x=979246
Получился

Вариант 1. Наивный
Вариант 1. Наивный

Вариант 2. С синхронизацией
#include
void main()
{ int x;
x = 0;
#pragma omp
Вариант 2. С синхронизацией
#include
void main()
{ int x;
x = 0;
#pragma omp

Вариант 2. С синхронизацией
$ ./plus2
x=1000000
Вариант 2. С синхронизацией
$ ./plus2
x=1000000

Вариант 2. С синхронизацией
Вариант 2. С синхронизацией

Что замедляет вычисления?
избыточное число порождений потока -> если можно, выносим параллельный
Что замедляет вычисления?
избыточное число порождений потока -> если можно, выносим параллельный

Цель работы
Написание многопоточного приложения с использованием интерфейса OpenMP.
Цель работы
Написание многопоточного приложения с использованием интерфейса OpenMP.
 Что такое socket.io
Что такое socket.io Object oriented programming. (Lesson 6, part 2)
Object oriented programming. (Lesson 6, part 2) Полезные адреса Интернет-ресурсов
Полезные адреса Интернет-ресурсов Аппаратное и программное обеспечение ЭВМ и сетей
Аппаратное и программное обеспечение ЭВМ и сетей Способы передачи движения. Модель: Мотоцикл с коляской. Занятие №4
Способы передачи движения. Модель: Мотоцикл с коляской. Занятие №4 Запоминающие устройства компьютера. (Лекция 5)
Запоминающие устройства компьютера. (Лекция 5) Значение логического выражения. Решение задания 3. ОГЭ
Значение логического выражения. Решение задания 3. ОГЭ Процесс загрузки и BIOS
Процесс загрузки и BIOS Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет
Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет Установка виртуальной машины. Установка операционной системы
Установка виртуальной машины. Установка операционной системы Управление файловой системой
Управление файловой системой Структуры данных
Структуры данных Условные операторы
Условные операторы Офіційний майданчик державних закупівель. Ваше зручне місце для торгів. Public-Bid
Офіційний майданчик державних закупівель. Ваше зручне місце для торгів. Public-Bid Введение в Matlab
Введение в Matlab Практическая работа в MS PowerPoint-2010
Практическая работа в MS PowerPoint-2010 Порядок оформления заказа
Порядок оформления заказа Я и интернет будущего
Я и интернет будущего Виды компьютерных сетей
Виды компьютерных сетей Принципы построения компьютеров
Принципы построения компьютеров Способы адресации в микропроцессорных системах
Способы адресации в микропроцессорных системах Оценка сложности вычислительных алгоритмов. Лекция 22
Оценка сложности вычислительных алгоритмов. Лекция 22 Парадигмы программирования
Парадигмы программирования Устройства ввода-вывода
Устройства ввода-вывода Презентация к уроку информатики и ИКТ
Презентация к уроку информатики и ИКТ Создание графических изображений. Обработка графической информации. Информатика. 7 класс
Создание графических изображений. Обработка графической информации. Информатика. 7 класс Всероссийская перепись населения 2020
Всероссийская перепись населения 2020 презентация электронного учебника
презентация электронного учебника