- Python 01. Beautiful Soup

Содержание
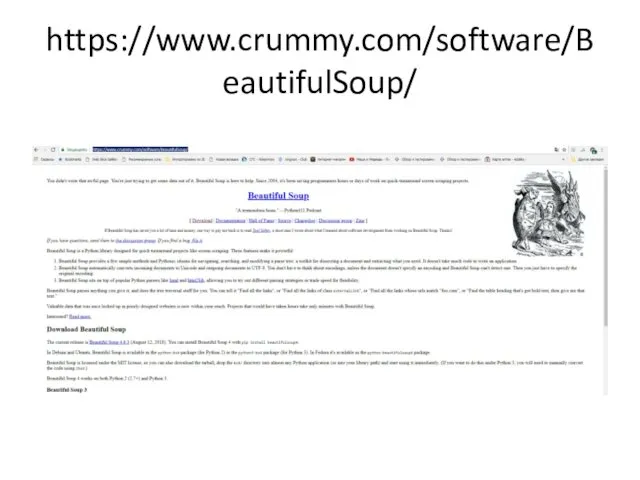
- 2. https://www.crummy.com/software/BeautifulSoup/
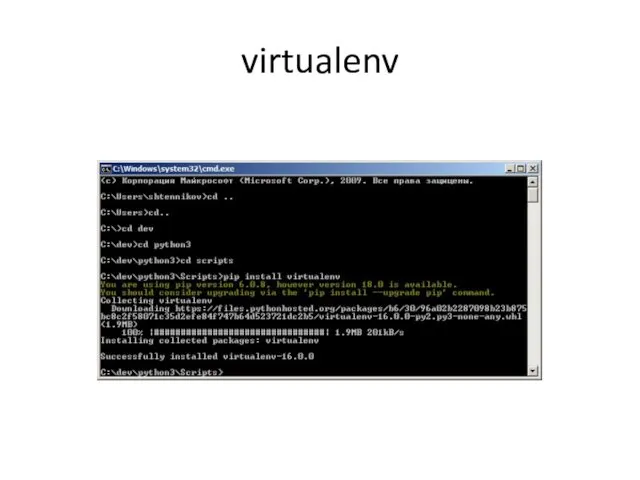
- 3. virtualenv
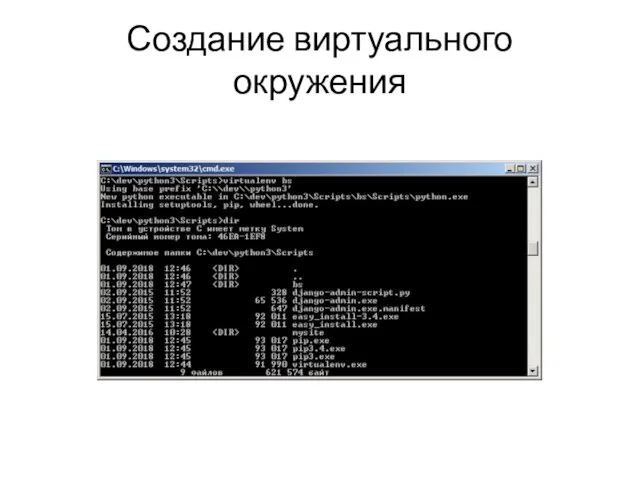
- 4. Создание виртуального окружения
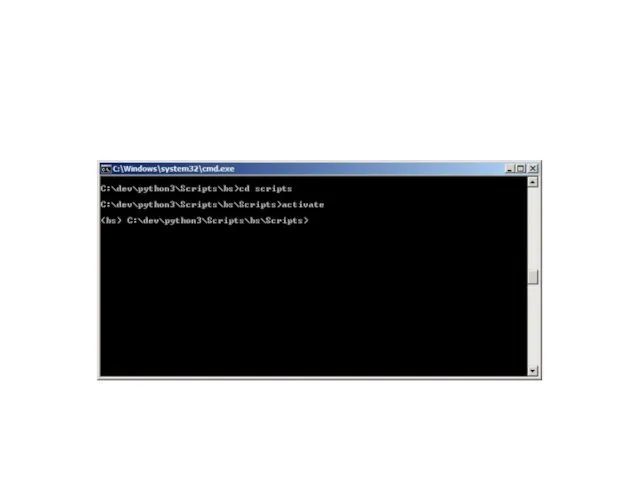
- 6. pip install beautifulsoup4 pip3 install beautifulsoup4 pip3 freeze
- 7. >>> from bs4 import BeautifulSoup as bs >>> import re >>> f_html=open('01re.html','r') >>> f_str=f_html.read() >>> #bs_str=BeautifulSoup(f_str)
- 8. prettify()
- 9. Обращение к элементам >>> soup.contents[0].name 'html' >>> soup.contents[0].contents[0].name 'head' >>> soup.contents[0].contents[0].contents[0].name 'title' >>> soup.title Page title
- 10. find() >>> bs_str.find('td') row 1 col 1 >>> bs_str.find('tr') row 1 col 1 row 1 col
- 11. >>> soup.p This is paragraph one . This is paragraph two . >>> soup.p['align'] 'center' >>>
- 12. Чтение информации из URL >>> from urllib.request import urlopen >>> from bs4 import BeautifulSoup >>> html1=urlopen('https://www.djangoproject.com/download/')
- 13. html_str1
- 14. Удобство вывода >>> bs1_str=BeautifulSoup(html1_str) >>> bs1_str
- 15. Обращение по тегам >>> bs1_str.h1 Download >>> bs1_str.title Download Django | Django >>> bs1_str.div >>> bs1_str.body
- 16. Идентичность вывода >>> bs1_str.body.h1 Download >>> bs1_str.html.body.h1 Download >>> bs1_str.html.h1 Download >>> bs1_str.h1 Download
- 17. Поиск всех элементов на странице >>> from urllib.request import urlopen >>> from bs4 import BeautifulSoup as
- 18. >>> nameList=bs_str1.findAll('div') >>> nameList
- 19. Введение ограничения на поиск >>> nameList2=bs_str1.findAll('div', {'class':'footer-logo'}) >>> nameList2 [ Django ]
- 20. >>> allTags=bs_str.findAll('p',{'id':'fst'}) >>> allTags [ ]
- 21. Использование регулярок для поиска >>> nameList3=bs_str1.findAll('div', {'class':re.compile('^footer')}) >>> nameList3 [
- 22. Получение текста get_text() >>> for i in nameList4: print(i.get_text())
- 23. Посиск по нескольким тегам >>> nameList5=bs_str1.findAll(['h1','h2']) nameList5=bs_str1.findAll({'h1':True,'h2':True})
- 24. Вывод всего текста или список тегов nameList6=bs_str1.findAll(True) [i.name for i in nameList6]
- 25. Поиск по параметрам тега >>> nameList7=bs_str1.findAll(lambda tag: len(tag.name)==2) nameList7=bs_str1.findAll(lambda tag: len(tag.get_text())>20) >>> nameList7=bs_str1.findAll(lambda tag: len(tag.attrs)>2) >>>
- 26. Изменения >>> bs_str.body.insert(0, 'MyPage')
- 27. Доп возможности вывода >>> str(bs_str) >>> bs_str.__str__()
- 28. >>> bs_str.prettify() >>> bs_str.renderContents()
- 29. Вывод содержимого тегов >>> MyTitle=bs_str.title >>> str(MyTitle) ' Table ' >>> MyTitle.renderContents() b'Table'
- 30. Присвоение имен и замена содержимого >>> titleTag=bs_str.html.head.title >>> titleTag Table >>> titleTag.string 'Table' >>> len(bs_str('title')) 1
- 31. Атрибуты тегов >>> fstTag,scndTag=bs_str.findAll('p') >>> fstTag >>> fstTag['id'] 'fst' >>> scndTag['id'] 'scnd'
- 32. >>> pTag=bs_str.p >>> pTag >>> pTag.contents [' '] >>> pTag.contents[0].contents AttributeError: 'NavigableString' object has no attribute
- 33. >>> bs_str1.td 2.1 >>> bs_str1.td.string '2.1' >>> bs_str1.td.contents[0] '2.1' >>> bs_str1.td.get_text() '2.1'
- 34. Вверх и вниз по уровню >>> bs_str.table.nextSibling '\n' >>> bs_str.table.previousSibling '\n'
- 35. Вниз и вверх >>> bs_str.head.next '\n' >>> bs_str.head.next.name >>> bs_str.head.next.next BS Table >>> bs_str.head.next.next.name 'title' >>>
- 36. Поиск следующих по уровню findPreviousSiblings findPreviousSibling >>> bs_str.table.tr >>> rTable=bs_str.table.tr >>> rTable.findNextSiblings('tr') >>> rTable.findNextSiblings('tr', limit=1)
- 37. findAllNext findNext findAllNext(name, attrs, text, limit, **kwargs) findNext(name, attrs, text, **kwargs)
- 38. findAllPrevious findPrevious findAllPrevious(name, attrs, text, limit, **kwargs) findPrevious(name, attrs, text, **kwargs)
- 39. findParents findParent findParents(name, attrs, limit, **kwargs) findParent(name, attrs, **kwargs)
- 41. Скачать презентацию
https://www.crummy.com/software/BeautifulSoup/
https://www.crummy.com/software/BeautifulSoup/
virtualenv
virtualenv
Создание виртуального окружения
Создание виртуального окружения
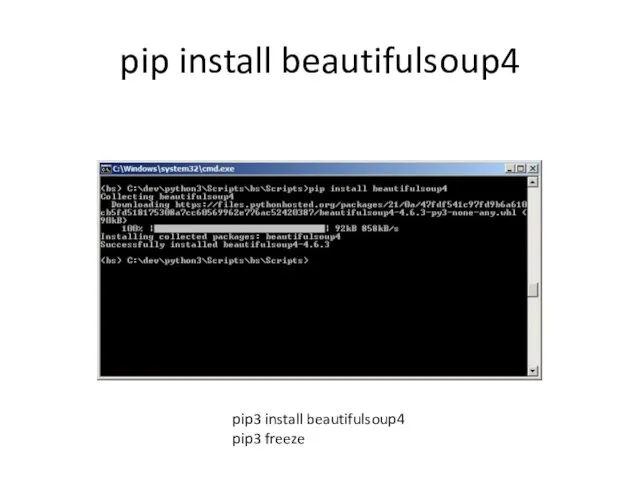
pip install beautifulsoup4
pip3 install beautifulsoup4
pip3 freeze
pip install beautifulsoup4
pip3 install beautifulsoup4
pip3 freeze

>>> from bs4 import BeautifulSoup as bs
>>> import re
>>> f_html=open('01re.html','r')
>>> f_str=f_html.read()
>>>
>>> from bs4 import BeautifulSoup as bs
>>> import re
>>> f_html=open('01re.html','r')
>>> f_str=f_html.read()
>>>

prettify()
prettify()
![Обращение к элементам >>> soup.contents[0].name 'html' >>> soup.contents[0].contents[0].name 'head' >>>](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-8.jpg)
Обращение к элементам
>>> soup.contents[0].name
'html'
>>> soup.contents[0].contents[0].name
'head'
>>> soup.contents[0].contents[0].contents[0].name
'title'
>>> soup.title
Page title
>>> soup.title.name
'title'
>>> soup.title.string
'Page title'
>>>
Обращение к элементам
>>> soup.contents[0].name
'html'
>>> soup.contents[0].contents[0].name
'head'
>>> soup.contents[0].contents[0].contents[0].name
'title'
>>> soup.title
>>> soup.title.name
'title'
>>> soup.title.string
'Page title'
>>>

find()
>>> bs_str.find('td')
row 1 col 1
>>> bs_str.find('tr')
row 1 col 1
row 1 col
row 1 col 3
find()
>>> bs_str.find('td')
>>> bs_str.find('tr')

>>> soup.p
This is paragraph one.
This is paragraph
>>> soup.p
This is paragraph one.
This is paragraph

Чтение информации из URL
>>> from urllib.request import urlopen
>>> from bs4 import
Чтение информации из URL
>>> from urllib.request import urlopen
>>> from bs4 import

html_str1
html_str1

Удобство вывода
>>> bs1_str=BeautifulSoup(html1_str)
>>> bs1_str
Удобство вывода
>>> bs1_str=BeautifulSoup(html1_str)
>>> bs1_str

Обращение по тегам
>>> bs1_str.h1
Download
>>> bs1_str.title
Download Django | Django >>> bs1_str.div
>>> bs1_str.body
…
Обращение по тегам
>>> bs1_str.h1
Download
>>> bs1_str.title
>>> bs1_str.body
…

Идентичность вывода
>>> bs1_str.body.h1
Download
>>> bs1_str.html.body.h1
Download
>>> bs1_str.html.h1
Download
>>> bs1_str.h1
Download
Идентичность вывода
>>> bs1_str.body.h1
Download
>>> bs1_str.html.body.h1
Download
>>> bs1_str.html.h1
Download
>>> bs1_str.h1
Download

Поиск всех элементов на странице
>>> from urllib.request import urlopen
>>> from bs4
Поиск всех элементов на странице
>>> from urllib.request import urlopen
>>> from bs4

>>> nameList=bs_str1.findAll('div')
>>> nameList
>>> nameList=bs_str1.findAll('div')
>>> nameList
![Введение ограничения на поиск >>> nameList2=bs_str1.findAll('div', {'class':'footer-logo'}) >>> nameList2 [ Django ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-18.jpg)
Введение ограничения на поиск
>>> nameList2=bs_str1.findAll('div', {'class':'footer-logo'})
>>> nameList2
[
]
Введение ограничения на поиск
>>> nameList2=bs_str1.findAll('div', {'class':'footer-logo'})
>>> nameList2
[
![>>> allTags=bs_str.findAll('p',{'id':'fst'}) >>> allTags [ ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-19.jpg)
>>> allTags=bs_str.findAll('p',{'id':'fst'})
>>> allTags
[
]
>>> allTags=bs_str.findAll('p',{'id':'fst'})
>>> allTags
[
]

Использование регулярок для поиска
>>> nameList3=bs_str1.findAll('div', {'class':re.compile('^footer')})
>>> nameList3
[

Получение текста get_text()
>>> for i in nameList4:
print(i.get_text())
![Посиск по нескольким тегам >>> nameList5=bs_str1.findAll(['h1','h2']) nameList5=bs_str1.findAll({'h1':True,'h2':True})](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-22.jpg)
Посиск по нескольким тегам
>>> nameList5=bs_str1.findAll(['h1','h2'])
nameList5=bs_str1.findAll({'h1':True,'h2':True})
![Вывод всего текста или список тегов nameList6=bs_str1.findAll(True) [i.name for i in nameList6]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-23.jpg)
Вывод всего текста или список тегов
nameList6=bs_str1.findAll(True)
[i.name for i in nameList6]

Поиск по параметрам тега
>>> nameList7=bs_str1.findAll(lambda tag: len(tag.name)==2)
nameList7=bs_str1.findAll(lambda tag: len(tag.get_text())>20)
>>> nameList7=bs_str1.findAll(lambda
tag: len(tag.attrs)>2)
>>> nameList7
[,  ]
]

Изменения
>>> bs_str.body.insert(0, 'MyPage')

Доп возможности вывода
>>> str(bs_str)
>>> bs_str.__str__()

>>> bs_str.prettify()
>>> bs_str.renderContents()

Вывод содержимого тегов
>>> MyTitle=bs_str.title
>>> str(MyTitle)
'
Table '
>>> MyTitle.renderContents()
b'Table'

Присвоение имен и замена содержимого
>>> titleTag=bs_str.html.head.title
>>> titleTag
Table
>>> titleTag.string
'Table'
>>> len(bs_str('title'))
1
>>>
![Атрибуты тегов >>> fstTag,scndTag=bs_str.findAll('p') >>> fstTag >>> fstTag['id'] 'fst' >>> scndTag['id'] 'scnd'](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-30.jpg)
Атрибуты тегов
>>> fstTag,scndTag=bs_str.findAll('p')
>>> fstTag
>>> fstTag['id']
'fst'
>>> scndTag['id']
'scnd'
![>>> pTag=bs_str.p >>> pTag >>> pTag.contents [' '] >>> pTag.contents[0].contents](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-31.jpg)
>>> pTag=bs_str.p
>>> pTag
>>> pTag.contents
[' ']
>>> pTag.contents[0].contents
AttributeError: 'NavigableString' object has
![>>> bs_str1.td 2.1 >>> bs_str1.td.string '2.1' >>> bs_str1.td.contents[0] '2.1' >>> bs_str1.td.get_text() '2.1'](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96376/slide-32.jpg)
>>> bs_str1.td
2.1
>>> bs_str1.td.string
'2.1'
>>> bs_str1.td.contents[0]
'2.1'
>>> bs_str1.td.get_text()
'2.1'

Вверх и вниз по уровню
>>> bs_str.table.nextSibling
'\n'
>>> bs_str.table.previousSibling
'\n'

Вниз и вверх
>>> bs_str.head.next
'\n'
>>> bs_str.head.next.name
>>> bs_str.head.next.next
BS Table
>>> bs_str.head.next.next.name
'title'
>>> bs_str.title.next.name
>>>

Поиск следующих по уровню
findPreviousSiblings findPreviousSibling
>>> bs_str.table.tr
>>> rTable=bs_str.table.tr
>>> rTable.findNextSiblings('tr')
>>> rTable.findNextSiblings('tr', limit=1)

findAllNext
findNext
findAllNext(name, attrs, text, limit, **kwargs)
findNext(name, attrs, text, **kwargs)

findAllPrevious
findPrevious
findAllPrevious(name, attrs, text, limit, **kwargs)
findPrevious(name, attrs, text, **kwargs)

findParents findParent
findParents(name, attrs, limit, **kwargs)
findParent(name, attrs, **kwargs)
Использование регулярок для поиска
>>> nameList3=bs_str1.findAll('div', {'class':re.compile('^footer')})
>>> nameList3
[
Получение текста get_text()
>>> for i in nameList4:
print(i.get_text())
Получение текста get_text()
>>> for i in nameList4:
print(i.get_text())
Посиск по нескольким тегам
>>> nameList5=bs_str1.findAll(['h1','h2'])
nameList5=bs_str1.findAll({'h1':True,'h2':True})
Посиск по нескольким тегам
>>> nameList5=bs_str1.findAll(['h1','h2'])
nameList5=bs_str1.findAll({'h1':True,'h2':True})
Вывод всего текста или список тегов
nameList6=bs_str1.findAll(True)
[i.name for i in nameList6]
Вывод всего текста или список тегов
nameList6=bs_str1.findAll(True)
[i.name for i in nameList6]
Поиск по параметрам тега
>>> nameList7=bs_str1.findAll(lambda tag: len(tag.name)==2)
nameList7=bs_str1.findAll(lambda tag: len(tag.get_text())>20)
>>> nameList7=bs_str1.findAll(lambda
Поиск по параметрам тега
>>> nameList7=bs_str1.findAll(lambda tag: len(tag.name)==2)
nameList7=bs_str1.findAll(lambda tag: len(tag.get_text())>20)
>>> nameList7=bs_str1.findAll(lambda
>>> nameList7
[,
]Изменения
>>> bs_str.body.insert(0, 'MyPage')
Изменения
>>> bs_str.body.insert(0, 'MyPage')
Доп возможности вывода
>>> str(bs_str)
>>> bs_str.__str__()
Доп возможности вывода
>>> str(bs_str)
>>> bs_str.__str__()
>>> bs_str.prettify()
>>> bs_str.renderContents()
>>> bs_str.prettify()
>>> bs_str.renderContents()
Вывод содержимого тегов
>>> MyTitle=bs_str.title
>>> str(MyTitle)
'
Table '
>>> MyTitle.renderContents()
b'Table'
Вывод содержимого тегов
>>> MyTitle=bs_str.title
>>> str(MyTitle)
'
>>> MyTitle.renderContents()
b'Table'
Присвоение имен и замена содержимого
>>> titleTag=bs_str.html.head.title
>>> titleTag
Table
>>> titleTag.string
'Table'
>>> len(bs_str('title'))
1
>>>
Присвоение имен и замена содержимого
>>> titleTag=bs_str.html.head.title
>>> titleTag
>>> titleTag.string
'Table'
>>> len(bs_str('title'))
1
>>>
Атрибуты тегов
>>> fstTag,scndTag=bs_str.findAll('p')
>>> fstTag
>>> fstTag['id']
'fst'
>>> scndTag['id']
'scnd'
Атрибуты тегов
>>> fstTag,scndTag=bs_str.findAll('p')
>>> fstTag
>>> fstTag['id']
'fst'
>>> scndTag['id']
'scnd'
>>> pTag=bs_str.p
>>> pTag
>>> pTag.contents
[' ']
>>> pTag.contents[0].contents
AttributeError: 'NavigableString' object has
>>> pTag=bs_str.p
>>> pTag
>>> pTag.contents
[' ']
>>> pTag.contents[0].contents
AttributeError: 'NavigableString' object has
>>> bs_str1.td
2.1
>>> bs_str1.td.string
'2.1'
>>> bs_str1.td.contents[0]
'2.1'
>>> bs_str1.td.get_text()
'2.1'
>>> bs_str1.td
>>> bs_str1.td.string
'2.1'
>>> bs_str1.td.contents[0]
'2.1'
>>> bs_str1.td.get_text()
'2.1'
Вверх и вниз по уровню
>>> bs_str.table.nextSibling
'\n'
>>> bs_str.table.previousSibling
'\n'
Вверх и вниз по уровню
>>> bs_str.table.nextSibling
'\n'
>>> bs_str.table.previousSibling
'\n'
Вниз и вверх
>>> bs_str.head.next
'\n'
>>> bs_str.head.next.name
>>> bs_str.head.next.next
BS Table
>>> bs_str.head.next.next.name
'title'
>>> bs_str.title.next.name
>>>
Вниз и вверх
>>> bs_str.head.next
'\n'
>>> bs_str.head.next.name
>>> bs_str.head.next.next
>>> bs_str.head.next.next.name
'title'
>>> bs_str.title.next.name
>>>
Поиск следующих по уровню
findPreviousSiblings findPreviousSibling
>>> bs_str.table.tr
>>> rTable=bs_str.table.tr
>>> rTable.findNextSiblings('tr')
>>> rTable.findNextSiblings('tr', limit=1)
Поиск следующих по уровню
findPreviousSiblings findPreviousSibling
>>> bs_str.table.tr
>>> rTable=bs_str.table.tr
>>> rTable.findNextSiblings('tr')
>>> rTable.findNextSiblings('tr', limit=1)
findAllNext
findNext
findAllNext(name, attrs, text, limit, **kwargs)
findNext(name, attrs, text, **kwargs)
findAllNext
findNext
findAllNext(name, attrs, text, limit, **kwargs)
findNext(name, attrs, text, **kwargs)
findAllPrevious
findPrevious
findAllPrevious(name, attrs, text, limit, **kwargs)
findPrevious(name, attrs, text, **kwargs)
findAllPrevious
findPrevious
findAllPrevious(name, attrs, text, limit, **kwargs)
findPrevious(name, attrs, text, **kwargs)
findParents findParent
findParents(name, attrs, limit, **kwargs)
findParent(name, attrs, **kwargs)
findParents findParent
findParents(name, attrs, limit, **kwargs)
findParent(name, attrs, **kwargs)
 Компьютерная графика (Autodesk 3ds max). Создание и работа с примитивами. Управление объектами. (Лекция 2.1)
Компьютерная графика (Autodesk 3ds max). Создание и работа с примитивами. Управление объектами. (Лекция 2.1) СМИ нового формата. Журналисты современной информации
СМИ нового формата. Журналисты современной информации Моделирование и его разновидности
Моделирование и его разновидности Развитие детей с помощью курсов робототехники
Развитие детей с помощью курсов робототехники Пользовательские хуки
Пользовательские хуки Электронный учебник по информатике
Электронный учебник по информатике Операционные системы. Введение, основные понятия и термины. (Лекция 1)
Операционные системы. Введение, основные понятия и термины. (Лекция 1) Логические элементы компьютера
Логические элементы компьютера Robots
Robots Introduction to informational and communication technologies
Introduction to informational and communication technologies Операционные системы
Операционные системы Викторина по информатике Инфознайка. 6 класс
Викторина по информатике Инфознайка. 6 класс Игра Удивительный мир информатики
Игра Удивительный мир информатики Структура Web приложений
Структура Web приложений Стандартные функции языка CLIPS. Стандартные арифметические функции
Стандартные функции языка CLIPS. Стандартные арифметические функции Игра Самый умный. Информатика
Игра Самый умный. Информатика Информационные процессы и системы в правовой сфере
Информационные процессы и системы в правовой сфере Основы 3D-моделирования машиностроительных объектов
Основы 3D-моделирования машиностроительных объектов Обзор программных продуктов дистрибутива Линукс Юниор
Обзор программных продуктов дистрибутива Линукс Юниор Применение ИКТ на уроках естествознания
Применение ИКТ на уроках естествознания Час кода в России
Час кода в России Subversion
Subversion Проектирование ПО ИС. Лекция 7
Проектирование ПО ИС. Лекция 7 Computer graphics
Computer graphics Розрахунок функції кутового розподілу
Розрахунок функції кутового розподілу Изучение графического редактора PAINT
Изучение графического редактора PAINT Презентация Ребусы
Презентация Ребусы Declaring PL/SQL Variables. (Lecture 2)
Declaring PL/SQL Variables. (Lecture 2)