- Распознавание образов. Классификация

Содержание
- 2. Определения Предмет распознавания образов (классификация) объединяет ряд научных дисциплин. Их связывает поиск решения общей задачи -
- 3. Основные методы классификация с помощью деревьев решений; байесовская (наивная) классификация; классификация при помощи нейронных сетей; классификация
- 4. Простой примерчик Распознавание больных гриппом: Х- температура; Y-число лейкоцитов Пространство признаков – решающее правило
- 5. Общие принципы распознавания Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие
- 6. Гипотеза компактности Классификация, распознавание, кластеризация - неявно опираются на одно важное предположение, называемое гипотезой компактности: если
- 7. Проблема выбора метрики_1 В практических задачах классификации редко встречаются такие «идеальные случаи», когда заранее известна хорошая
- 8. Проблема выбора метрики_2 Однако и нормировка является весьма сомнительной эвристикой, так как остаётся вопрос: «неужели все
- 9. Об информативности признаков Если признаков слишком много, а расстояние вычисляется как сумма отклонений по отдельным признакам,
- 10. Методологии распознавания Статистический подход: непараметрические методы. Распознавание по образцу Статистический подход: основан на теории принятия решений.
- 11. Непараметрические (эвристические) методы Метод ближайшего соседа. Метод к-ближайших соседей. Метод потенциальных функций. Метод «парзеновских» окон.
- 12. Идеи эвристик распознавания_1 Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации. Классифицируемый объект относится к
- 13. Примеры задач классификации
- 14. Способы определения классов объектов Перечисление. Каждый класс задаётся путём прямого указания его членов. Такой подход используется
- 15. Пример перечисления классов объектов Пример. Распознавание машинопечатного шрифта. Все символы имеют чётко заданное шрифтом начертание. Следовательно,
- 16. Способы определения классов объектов Задание общих свойств. Класс задаётся указанием некоторых признаков, присущих всем его членам.
- 17. Пример задания общих свойств классов объектов Пример. Распознавание цифр почтовых индексов. Рассматривается набор из 10-ти цифр
- 18. Способы определения классов объектов x1 x2 x3 x4 0 4 2 0 1 1 2 0
- 19. Статистический подход Основу статистического подхода к задаче распознавания образов, составляет Байесовская теория принятия решений. Подход основан
- 20. Априорная вероятность В байесовском статистическом выводе априорное распределение вероятностей ( prior probability distribution) неопределённой величины p
- 21. Апостериорная вероятность Априорное распределение часто задается субъективно опытным экспертом или по известной выборке. Апостерио́рная вероя́тность —
- 22. Обозначения Ω - множество состояний природы. А – множество из а возможных действий. λij (αi |
- 23. Правило Байеса Ƥ (Ω j | z ) = p ( z | Ω j )
- 24. Классификация для 2-х классов Апостериорная вероятность Ожидаемые потери – риск – R. Найти min R. Классификация
- 25. Что есть в теории ? Вероятности ошибок. Нормальный закон распределения. Разделяющие функции – разделяющие плоскости. Случай
- 26. Структурно-лингвистический подход Основан на теории формальных грамматик. ( Kifg-Sun Fu ). К Фу. Доктор Кинг-Сан Фу
- 27. Структурно-лингвистический подход Буква(символ) — простой неделимый знак. Алфавит — множество букв (символов) A={a, b, c}. Конкатенация
- 28. Структурно-лингвистический подход_2 Слово (строка) — упорядоченная совокупность букв из алфавита. Множество всех строк (включая пустую), которые
- 29. Классификация грамматик Иерархия Хомского — классификация формальных языков и формальных грамматик, согласно которой они делятся на
- 30. Обозначения VT — множество (словарь) терминальных символов – неизменяемый элемент (буква) алфавита. VN — множество (словарь)
- 31. «Простенький примерчик» a b c d Цепочки (слова ): aaabbcccdd aaaabbbccccddd aabbbbccdddd
- 32. Грамматика для «примерчика» V N = { S, A, B, C, D } – словарь нетерминалов
- 33. Продолжение примерчика abcd – слово ( образ ) – «четырехугольник». a(3)b(5)c(3)d(5) – с атрибутами Что за
- 34. Алгоритм распознавания Виолы-Джонса (Viola-Jones 2001 год Изначально для распознавания лиц, но можно распознавать и другие объекты.
- 35. Благодарность По материалам Д.Азарова https://oxozle.com/2015/04/11/metod-raspoznavaniya-lic-violy-dzhonsa-viola-jones
- 36. Общая схема алгоритма Виолы-Джонса Два этапа: алгоритм обучения и алгоритм распознавания.
- 37. Обобщенная схема алгоритма Обобщенная схема алгоритма: перед началом распознавания алгоритм обучения на основе тестовых изображений обучает
- 38. Признаки В качестве признаков для алгоритма распознавания авторами были предложены признаки разложения Хаара, на основе вейвлетов
- 39. Виды масок (морфология) Признаки Хаара дают точечное значение перепада яркости по оси X и Y соответственно.
- 40. Пример изображений для обучения Размер тестовой выборки около 10 000 изображений. Алгоритм обучения работает с изображениями
- 41. Обучение При размере тестового изображения 24 на 24 пикселя количество конфигураций одного признака около 40 000
- 42. Обучение_2 Для алгоритма необходимо заранее подготовить тестовую выборку из l изображений, содержащих искомый объект и n
- 43. Интегральное представление изображений Интегральное представление можно представить в виде матрицы, размеры которой совпадают с размерами исходного
- 44. Распознавание После обучения на тестовой выборке имеется обученная база знаний из T слабых классификаторов. Для каждого
- 45. Введение в нейронные сети: персептрон Смещение f - Функция активации x - Входы (Сенсоры) w -
- 46. Основные архитектуры нейронных сетей Персептрон (P) НС прямого распространения (FF) Сверточная НС (CNN) Реккурентная НС (RNN)
- 47. Библиотеки машинного обучения
- 48. Революция глубокого обучения Сенсорный интеллект Речь, зрение, тексты … На уровне человека Игровой интеллект Шахматы, Go,
- 49. Глубокое обучение - подражание мозгу Google Brain: «Сегодня нейросети могут все, что мозг делает за первые
- 50. Искусственные нейронные сети Искусственный нейрон:
- 51. Глубокие нейронные сети: лучше, чем широкие
- 52. III. Элементы искусственной психики Машинное зрение Распознавание речи, рабочая память Понимание речи, управление вниманием Понимание отношений
- 53. Благодарность На основе материалов С.А.Шумского
- 54. Благодарности - литература Р. Дуда, П. Харт. Распознавание образов и анализ сцен. Пер. с англ., М.,
- 56. Скачать презентацию

Определения
Предмет распознавания образов (классификация) объединяет ряд научных дисциплин. Их связывает поиск
Определения
Предмет распознавания образов (классификация) объединяет ряд научных дисциплин. Их связывает поиск

Основные методы
классификация с помощью деревьев решений;
байесовская (наивная) классификация;
классификация при
Основные методы
классификация с помощью деревьев решений;
байесовская (наивная) классификация;
классификация при
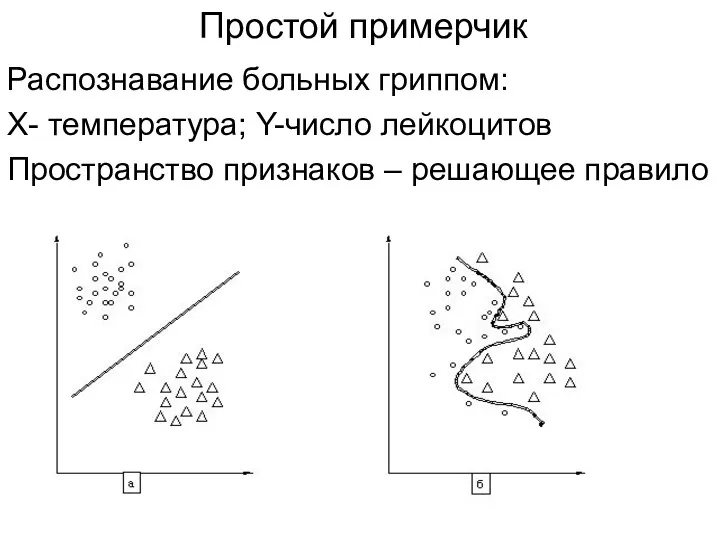
Простой примерчик
Распознавание больных гриппом:
Х- температура; Y-число лейкоцитов
Пространство признаков – решающее правило
Простой примерчик
Распознавание больных гриппом:
Х- температура; Y-число лейкоцитов
Пространство признаков – решающее правило

Общие принципы распознавания
Методика отнесения элемента к какому-либо образу называется решающим правилом.
Общие принципы распознавания
Методика отнесения элемента к какому-либо образу называется решающим правилом.

Гипотеза компактности
Классификация, распознавание, кластеризация - неявно опираются на одно важное
Гипотеза компактности
Классификация, распознавание, кластеризация - неявно опираются на одно важное

Проблема выбора метрики_1
В практических задачах классификации редко встречаются такие «идеальные случаи»,
Проблема выбора метрики_1
В практических задачах классификации редко встречаются такие «идеальные случаи»,

Проблема выбора метрики_2
Однако и нормировка является весьма сомнительной эвристикой, так как
Проблема выбора метрики_2
Однако и нормировка является весьма сомнительной эвристикой, так как

Об информативности признаков
Если признаков слишком много, а расстояние вычисляется как сумма
Об информативности признаков
Если признаков слишком много, а расстояние вычисляется как сумма

Методологии распознавания
Статистический подход: непараметрические методы.
Распознавание по образцу
Статистический подход: основан на теории
Методологии распознавания
Статистический подход: непараметрические методы.
Распознавание по образцу
Статистический подход: основан на теории

Непараметрические (эвристические) методы
Метод ближайшего соседа.
Метод к-ближайших соседей.
Метод потенциальных функций.
Метод «парзеновских» окон.
Непараметрические (эвристические) методы
Метод ближайшего соседа.
Метод к-ближайших соседей.
Метод потенциальных функций.
Метод «парзеновских» окон.

Идеи эвристик распознавания_1
Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации.
Идеи эвристик распознавания_1
Метод ближайшего соседа является, пожалуй, самым простым алгоритмом классификации.

Примеры задач классификации
Примеры задач классификации

Способы определения классов объектов
Перечисление.
Каждый класс задаётся путём прямого указания его
Способы определения классов объектов
Перечисление.
Каждый класс задаётся путём прямого указания его

Пример перечисления классов объектов
Пример. Распознавание машинопечатного шрифта. Все символы имеют чётко
Пример перечисления классов объектов
Пример. Распознавание машинопечатного шрифта. Все символы имеют чётко

Способы определения классов объектов
Задание общих свойств.
Класс задаётся указанием некоторых признаков,
Способы определения классов объектов
Задание общих свойств.
Класс задаётся указанием некоторых признаков,

Пример задания общих свойств классов объектов
Пример. Распознавание цифр почтовых индексов. Рассматривается
Пример задания общих свойств классов объектов
Пример. Распознавание цифр почтовых индексов. Рассматривается

Способы определения классов объектов
x1 x2 x3 x4
0 4 2 0
Способы определения классов объектов
x1 x2 x3 x4
0 4 2 0

Статистический подход
Основу статистического подхода к задаче распознавания образов, составляет Байесовская теория
Статистический подход
Основу статистического подхода к задаче распознавания образов, составляет Байесовская теория

Априорная вероятность
В байесовском статистическом выводе априорное распределение вероятностей ( prior
Априорная вероятность
В байесовском статистическом выводе априорное распределение вероятностей ( prior

Апостериорная вероятность
Априорное распределение часто задается субъективно опытным экспертом или по известной
Апостериорная вероятность
Априорное распределение часто задается субъективно опытным экспертом или по известной

Обозначения
Ω - множество состояний природы.
А – множество из а возможных действий.
λij
Обозначения
Ω - множество состояний природы.
А – множество из а возможных действий.
λij

Правило Байеса
Ƥ (Ω j | z ) = p (
Правило Байеса
Ƥ (Ω j | z ) = p (

Классификация для 2-х классов
Апостериорная вероятность
Ожидаемые потери – риск – R.
Найти min
Классификация для 2-х классов
Апостериорная вероятность
Ожидаемые потери – риск – R.
Найти min

Что есть в теории ?
Вероятности ошибок.
Нормальный закон распределения.
Разделяющие функции – разделяющие
Что есть в теории ?
Вероятности ошибок.
Нормальный закон распределения.
Разделяющие функции – разделяющие

Структурно-лингвистический подход
Основан на теории формальных грамматик. ( Kifg-Sun Fu ).
К Фу.
Структурно-лингвистический подход
Основан на теории формальных грамматик. ( Kifg-Sun Fu ).
К Фу.

Структурно-лингвистический подход
Буква(символ) — простой неделимый знак.
Алфавит — множество букв (символов) A={a,
Структурно-лингвистический подход
Буква(символ) — простой неделимый знак.
Алфавит — множество букв (символов) A={a,

Структурно-лингвистический подход_2
Слово (строка) — упорядоченная совокупность букв из алфавита.
Множество всех
Структурно-лингвистический подход_2
Слово (строка) — упорядоченная совокупность букв из алфавита.
Множество всех

Классификация грамматик
Иерархия Хомского — классификация формальных языков и формальных грамматик, согласно
Классификация грамматик
Иерархия Хомского — классификация формальных языков и формальных грамматик, согласно

Обозначения
VT — множество (словарь) терминальных символов – неизменяемый элемент (буква) алфавита.
VN
Обозначения
VT — множество (словарь) терминальных символов – неизменяемый элемент (буква) алфавита. VN
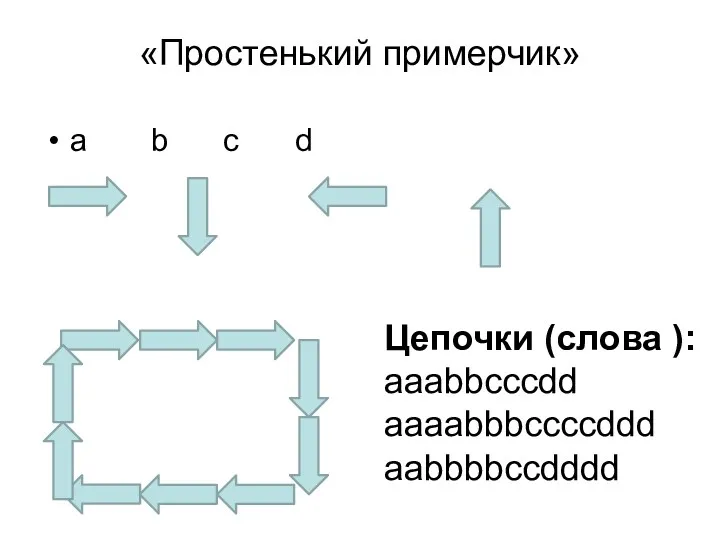
«Простенький примерчик»
a b c d
Цепочки (слова ):
aaabbcccdd
aaaabbbccccddd
aabbbbccdddd
«Простенький примерчик»
a b c d
Цепочки (слова ):
aaabbcccdd
aaaabbbccccddd
aabbbbccdddd

Грамматика для «примерчика»
V N = { S, A, B, C, D
Грамматика для «примерчика»
V N = { S, A, B, C, D

Продолжение примерчика
abcd – слово ( образ ) – «четырехугольник».
a(3)b(5)c(3)d(5) –
Продолжение примерчика
abcd – слово ( образ ) – «четырехугольник».
a(3)b(5)c(3)d(5) –

Алгоритм распознавания Виолы-Джонса (Viola-Jones
2001 год
Изначально для распознавания лиц, но можно распознавать
Алгоритм распознавания Виолы-Джонса (Viola-Jones
2001 год
Изначально для распознавания лиц, но можно распознавать

Благодарность
По материалам Д.Азарова
https://oxozle.com/2015/04/11/metod-raspoznavaniya-lic-violy-dzhonsa-viola-jones
Благодарность
По материалам Д.Азарова
https://oxozle.com/2015/04/11/metod-raspoznavaniya-lic-violy-dzhonsa-viola-jones
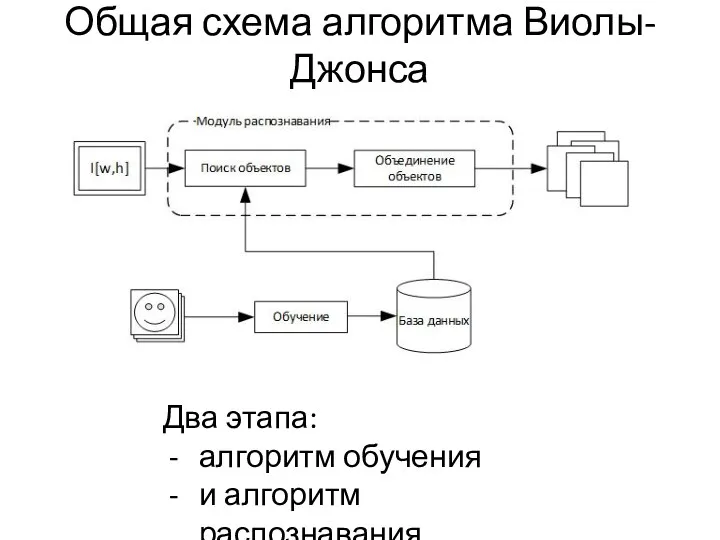
Общая схема алгоритма Виолы-Джонса
Два этапа:
алгоритм обучения
и алгоритм распознавания.
Общая схема алгоритма Виолы-Джонса
Два этапа:
алгоритм обучения
и алгоритм распознавания.

Обобщенная схема алгоритма
Обобщенная схема алгоритма:
перед началом распознавания алгоритм обучения на
Обобщенная схема алгоритма
Обобщенная схема алгоритма:
перед началом распознавания алгоритм обучения на

Признаки
В качестве признаков для алгоритма распознавания авторами были предложены признаки разложения
Признаки
В качестве признаков для алгоритма распознавания авторами были предложены признаки разложения
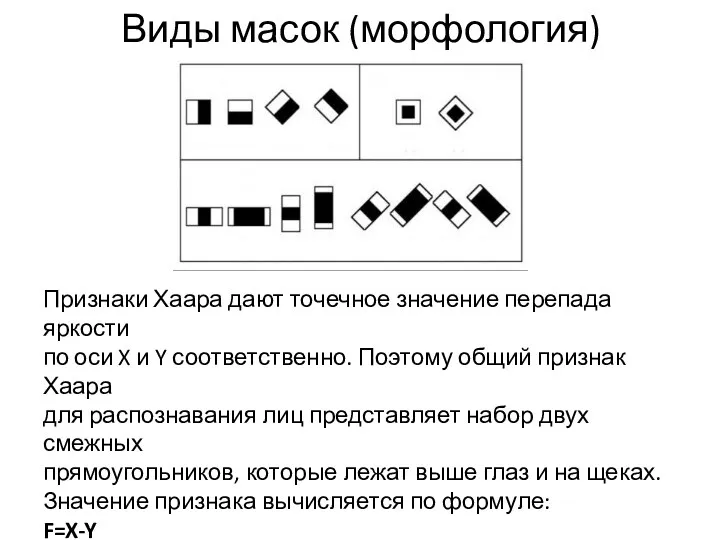
Виды масок (морфология)
Признаки Хаара дают точечное значение перепада яркости
по оси X
Виды масок (морфология)
Признаки Хаара дают точечное значение перепада яркости
по оси X

Пример изображений для обучения
Размер тестовой выборки около 10 000 изображений.
Алгоритм обучения
Пример изображений для обучения
Размер тестовой выборки около 10 000 изображений.
Алгоритм обучения

Обучение
При размере тестового изображения 24 на 24 пикселя количество конфигураций одного
Обучение
При размере тестового изображения 24 на 24 пикселя количество конфигураций одного

Обучение_2
Для алгоритма необходимо заранее подготовить тестовую выборку из l изображений, содержащих
Обучение_2
Для алгоритма необходимо заранее подготовить тестовую выборку из l изображений, содержащих

Интегральное представление изображений
Интегральное представление можно представить в виде матрицы, размеры которой
Интегральное представление изображений
Интегральное представление можно представить в виде матрицы, размеры которой

Распознавание
После обучения на тестовой выборке имеется обученная база знаний из T
Распознавание
После обучения на тестовой выборке имеется обученная база знаний из T
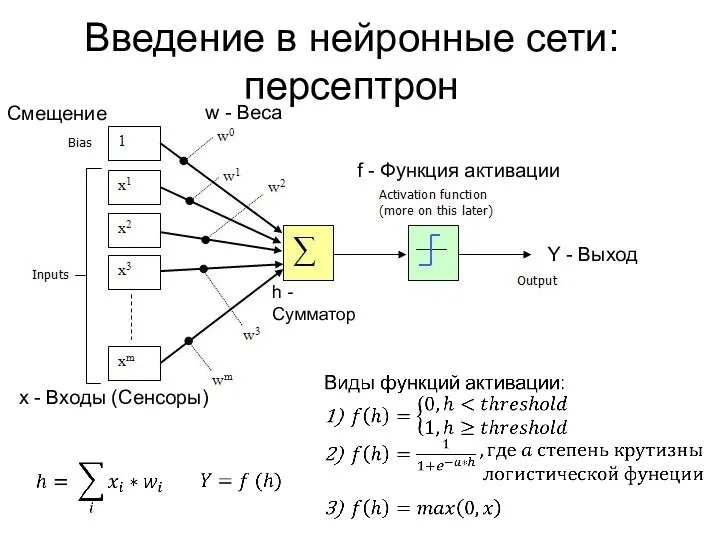
Введение в нейронные сети:
персептрон
Смещение
f - Функция активации
x - Входы (Сенсоры)
w -
Введение в нейронные сети:
персептрон
Смещение
f - Функция активации
x - Входы (Сенсоры)
w -

Основные архитектуры нейронных сетей
Персептрон (P)
НС прямого распространения (FF)
Сверточная НС (CNN)
Реккурентная НС
Основные архитектуры нейронных сетей
Персептрон (P)
НС прямого распространения (FF)
Сверточная НС (CNN)
Реккурентная НС

Библиотеки машинного обучения
Библиотеки машинного обучения
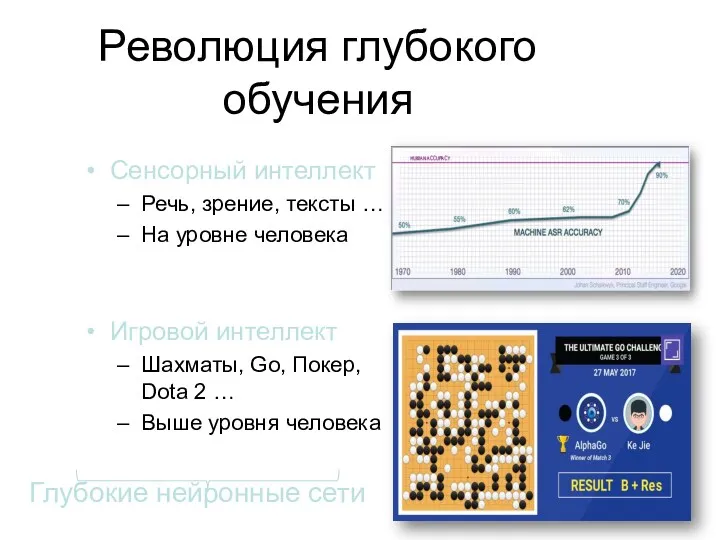
Революция глубокого обучения
Сенсорный интеллект
Речь, зрение, тексты …
На уровне человека
Игровой интеллект
Шахматы, Go,
Революция глубокого обучения
Сенсорный интеллект
Речь, зрение, тексты …
На уровне человека
Игровой интеллект
Шахматы, Go,
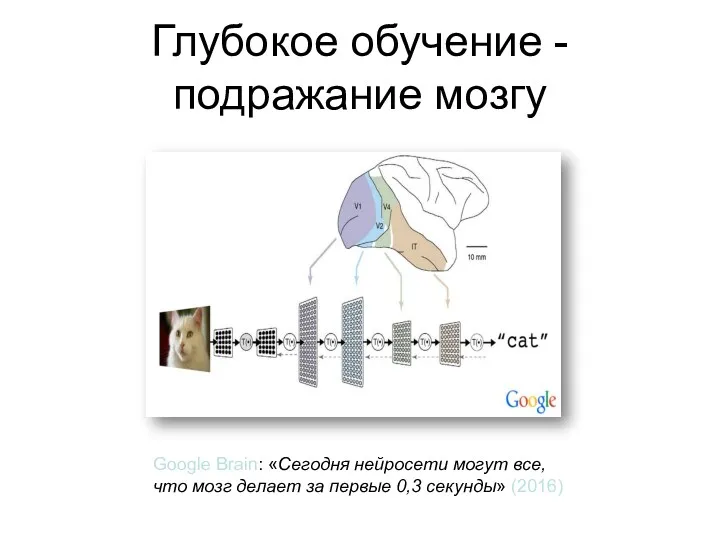
Глубокое обучение - подражание мозгу
Google Brain: «Сегодня нейросети могут все,
что
Глубокое обучение - подражание мозгу
Google Brain: «Сегодня нейросети могут все,
что
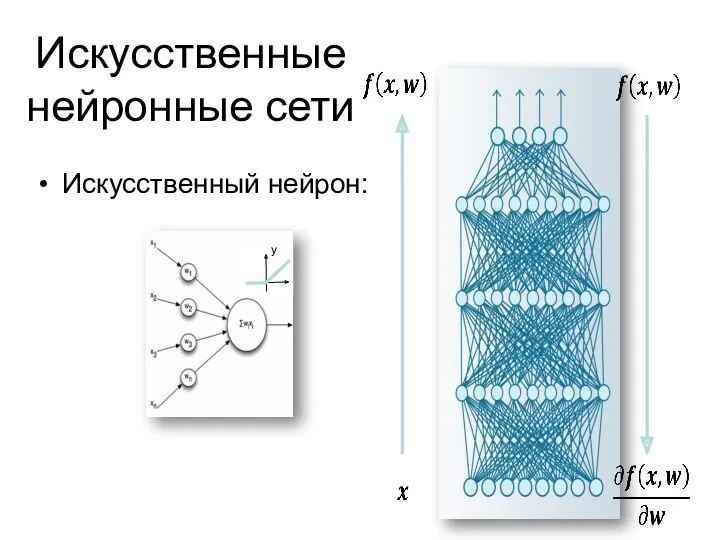
Искусственные нейронные сети
Искусственный нейрон:
Искусственные нейронные сети
Искусственный нейрон:

Глубокие нейронные сети:
лучше, чем широкие
Глубокие нейронные сети:
лучше, чем широкие

III. Элементы искусственной психики
Машинное зрение
Распознавание речи, рабочая память
Понимание речи, управление вниманием
Понимание
III. Элементы искусственной психики
Машинное зрение
Распознавание речи, рабочая память
Понимание речи, управление вниманием
Понимание

Благодарность
На основе материалов С.А.Шумского
Благодарность
На основе материалов С.А.Шумского

Благодарности - литература
Р. Дуда, П. Харт. Распознавание образов и анализ сцен.
Благодарности - литература
Р. Дуда, П. Харт. Распознавание образов и анализ сцен.
 Решаемые задачи для государства
Решаемые задачи для государства Передача и хранение информации
Передача и хранение информации Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Тестирование web-приложений
Тестирование web-приложений Posters NPE
Posters NPE Вставка звука, видео, Flash-анимации
Вставка звука, видео, Flash-анимации Составление линейных программ
Составление линейных программ Эффективный поиск работы
Эффективный поиск работы Введение в язык C#. Лекция 3-4
Введение в язык C#. Лекция 3-4 iSpring Suite 8. Быстрый инструмент для создания электронных курсов и тестов в PowerPoint
iSpring Suite 8. Быстрый инструмент для создания электронных курсов и тестов в PowerPoint NET Windows Forms
NET Windows Forms Глобальная компьютерная сеть Интернет
Глобальная компьютерная сеть Интернет Правила заполнения таблицы
Правила заполнения таблицы Диаграммы взаимодействия в Rose. (Тема 6)
Диаграммы взаимодействия в Rose. (Тема 6) Создание текстовых документов на компьютере. Обработка текстовой информации
Создание текстовых документов на компьютере. Обработка текстовой информации Применение нечеткой логики в ИСУ
Применение нечеткой логики в ИСУ PowerPoint терезесіні
PowerPoint терезесіні Язык C++
Язык C++ Транзакції та блокування
Транзакції та блокування Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №4
Ежемесячная газета МБОУ Красноясыльская средняя общеобразовательная школа Школьная жизнь №4 Программный комплекс для моделирования и анализа динамики ЛА в MATLAB/Simulink
Программный комплекс для моделирования и анализа динамики ЛА в MATLAB/Simulink Интеллектуальная Система Управления Автотранспортом (ИСУА)
Интеллектуальная Система Управления Автотранспортом (ИСУА) Компьютерные сети. Информатика и информационные технологии. (Лекция 6)
Компьютерные сети. Информатика и информационные технологии. (Лекция 6) Регистрация на сайте Госуслуги
Регистрация на сайте Госуслуги презентация к уроку Понятие как форма мышления
презентация к уроку Понятие как форма мышления Pascal. Введение в основы программирования
Pascal. Введение в основы программирования Design patterns. GoF for .Net developers
Design patterns. GoF for .Net developers Интернет. Общие сведения. Адресация в Интернет
Интернет. Общие сведения. Адресация в Интернет