- Распределенные системы. Технологии параллельного программирования

Содержание
- 2. План 2008 Средства автоматического распараллеливания программ MPI Настройка рабочего места для выполнения практических заданий. Выполнение первой
- 3. СРЕДСТВА АВТОМАТИЧЕСКОГО РАСПАРАЛЛЕЛИВАНИЯ ПРОГРАММ
- 4. Варианты архитектур Чтобы процессоры могли считаться автономными, они должны, по меньшей мере, обладать собственным независимым управлением.
- 5. Средства автоматического распараллеливания Средства автоматического распараллеливания – наиболее быстрый способ получить параллельную программу из последовательной, но
- 6. Некоторые программные инструменты параллелизма OpenMP — стандарт интерфейса приложений для параллельных систем с общей памятью. POSIX
- 7. MPI
- 8. MPI MPI (Message Passing Interface) — интерфейс обмена сообщениями (информацией) между одновременно работающими вычислительными процессами. Он
- 9. MPI Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком запускается указываемое количество экземпляров
- 10. Стандарт MPI Коммуникатор (communicator) – множество процессов, образующих логическую область для выполнения коллективных операций (обменов информацией
- 11. MPI Все ветви запускаются загрузчиком одновременно как процессы Unix. Количество ветвей фиксировано - в ходе работы
- 12. MPI (проблемы при использовании) во-первых, перед запуском приложения необходимо копирование приложения на все компьютеры кластера; во-вторых,
- 13. MPI (этапы разработки программы) Создание параллельной программы можно разбить на следующие этапы: последовательный алгоритм подвергается декомпозиции
- 14. Сравнение MPI с другими средствами
- 15. Версии MPI Версия MPI-1 вышла в 1994 году Версия MPI-2 вышла в 1998 году, первая реализация
- 16. Спецификации MPI Спецификация MPI-1 Содержит описание стандарта программного интерфейса обмена сообщениями. Спецификация учитывает опыт предшествующих разработок
- 17. Спецификации MPI Спецификация MPI-2 Является дальнейшим развитием MPI. Новое в MPI-2: возможность создания новых процессов во
- 18. MPICH2 (Open source, Argone NL) http://www.mcs.anl.gov/research/projects/mpich2 MVAPICH2 IBM MPI Cray MPI Intel MPI HP MPI SiCortex
- 19. Реализации MPI MPI CHameleon (MPICH) является свободно распространяемой “opensource” реализацией MPI. Этот пакет доступен в исходных
- 20. Реализации MPI «Производные» от MPICH LAM/MPI (Университет шт. Индиана.) MPICH GM (Myricom) - MPICH с поддержкой
- 21. Реализации MPI LAM (Local Area Multicomputer) MPI - “opensource” реализация MPI, соответствующая спецификации MPI-1 и, в
- 22. Реализации MPI OpenMPI - “opensource” реализация MPI-2, разрабатываемая консорциумом представителей академических, научных и индустриальных кругов. Полное
- 23. Реализации MPI Microsoft MPI (MS-MPI v7.1) входит в состав Compute Cluster Pack SDK. Ориентирован на работу
- 24. Реализации MPJ Most of those early projects are no longer active. mpiJava is still used and
- 25. Реализации MPJ Один из ранних и наиболее живучих проектов - mpiJava все еще поддерживается и широко
- 26. НАСТРОЙКА РАБОЧЕГО МЕСТА
- 27. Установка MS-MPI https://www.microsoft.com/en-us/download/details.aspx?id=49926 скачиваем msi-файл (размер около 2 Мбайт): Для установки потребуются права Администратора системы (запуск
- 28. Установка MS-MPI Запускаем скачанный файл, он нам устанавливает MPI SDK: Можно попробовать эту инструкцию для дальнейшей
- 29. Установка MPJ Загружаем MPJ Express в виде zip – файла отсюда: http://sourceforge.net/projects/mpjexpress/files/releases и распаковываем.
- 30. Настройка системных переменных Входим в «Дополнительные параметры системы»
- 31. Установка MPJ 2. Извлекаем архив в выбранную вами директорию (мы назовем ее условно "mpj directory" ).
- 32. (2.2) Добавляем MPJ bin директорию к переменной окружения PATH: Path=$PATH:$MPJ_HOME/bin Установка MPJ %MPJ_HOME%/bin
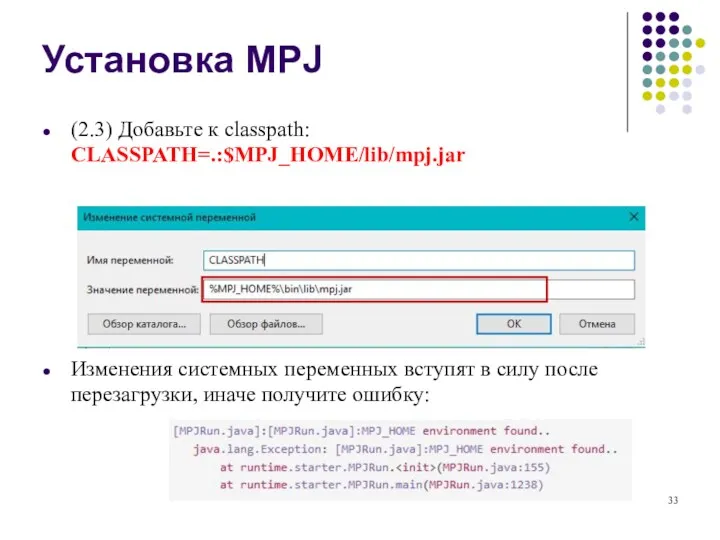
- 33. Установка MPJ (2.3) Добавьте к classpath: CLASSPATH=.:$MPJ_HOME/lib/mpj.jar Изменения системных переменных вступят в силу после перезагрузки, иначе
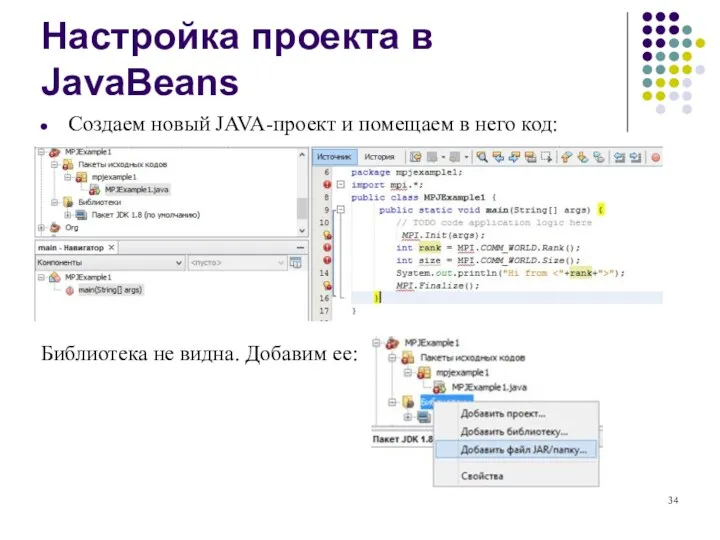
- 34. Настройка проекта в JavaBeans Создаем новый JAVA-проект и помещаем в него код: Библиотека не видна. Добавим
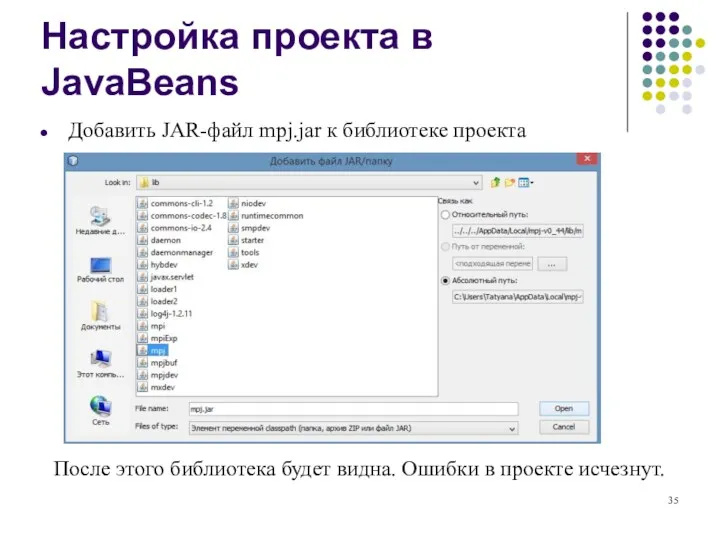
- 35. Настройка проекта в JavaBeans Добавить JAR-файл mpj.jar к библиотеке проекта После этого библиотека будет видна. Ошибки
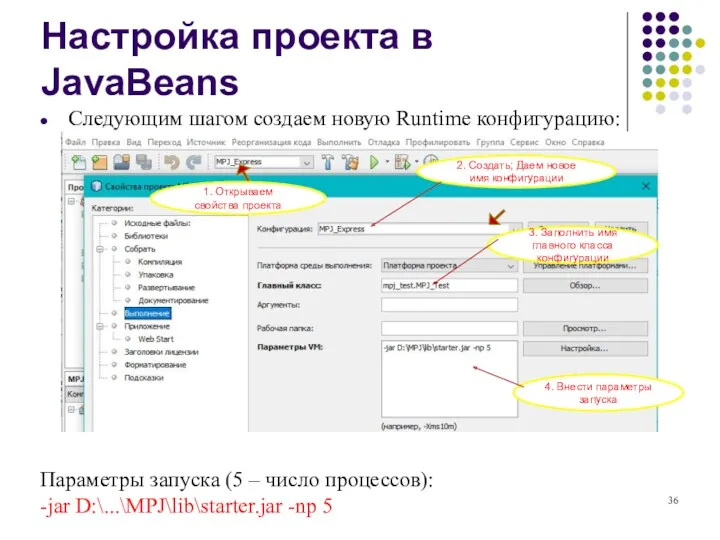
- 36. Настройка проекта в JavaBeans Следующим шагом создаем новую Runtime конфигурацию: Параметры запуска (5 – число процессов):
- 37. MPJ “Hello, World” Запускаем: Получаем:
- 38. MPJ Режим отладки Вводим дополнительные параметры настройки конфигурации: “-gentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000” Отладчик подключится к порту, указанному в этой
- 39. MPJ Режим отладки Устанавливаем точку останова и запускаем: Видим, что идет прослушивание сокета и порта 8000.
- 40. MPJ Режим отладки Подключаем отладчик: Настраиваем параметры:
- 41. MPJ Режим отладки Процесс отладки: Нажимая на кнопки отладки можем контролировать каждый процесс отдельно Выбор контролируемого
- 42. MPJ Режим отладки Процесс отладки: Отработали 3 из 5 процессов
- 43. MPJ “Hello, World” Можно скомпилировать из командной строки: javac -cp .:$MPJ_HOME/lib/mpj.jar MPJExample1.java И запустить: mpjrun -np
- 44. MPJ “Hello, World” import mpi.*; public class MPIAPP { public static void main(String[] args) throws Exception{
- 45. Функции инициализации и завершения работы int MPI_Init(int* argc, char*** argv) argc – указатель на счетчик аргументов
- 46. Структура программы на MPI Структура параллельной программы, разработанная с использованием MPI, должна иметь следующий вид: #include
- 47. Полезные ссылки: MPJ Express: An Implementation of MPI in Java Windows User Guide 18th July 2014:
- 48. Все задачи по курсу
- 49. В исходном тексте программы на языке C (след. слайд) предусмотрена некая схема обмена сообщениями между процессами
- 50. 2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int myrank, size, message; int TAG =
- 51. Задание 2 — Пересылка данных по кольцу Init 0 1 3 Каждый процессор помещает свой ранг
- 52. Неблокирующие обмены Задание 3 Реализовать так называемую задачу фильтрации, используя неблокирующие обмены+Waitall(), например: Вариант: к-во потоков
- 53. Задание 4 Дополнить программу с пробниками, выполнить ее. Неблокирующие обмены (пробники) int data[] = new int[1];
- 54. Задание 4 (окончание) Неблокирующие обмены (пробники) else if(rank == 2){ st = MPI.COMM_WORLD.Probe(…); count = st.Get_count(MPI.INT);
- 55. Два вектора a и b размерности N представлены двумя одномерными массивами, содержащими каждый по N элементов.
- 56. Два вектора a и b размерности N представлены двумя одномерными массивами, содержащими каждый по N элементов.
- 57. 7,8. Задачи с графами. Задание выполняется по вариантам: N mod 4, где N – номер по
- 59. Скачать презентацию

План
2008
Средства автоматического распараллеливания программ
MPI
Настройка рабочего места для выполнения практических заданий.
Выполнение
План
2008
Средства автоматического распараллеливания программ
MPI
Настройка рабочего места для выполнения практических заданий.
Выполнение

СРЕДСТВА АВТОМАТИЧЕСКОГО РАСПАРАЛЛЕЛИВАНИЯ ПРОГРАММ
СРЕДСТВА АВТОМАТИЧЕСКОГО РАСПАРАЛЛЕЛИВАНИЯ ПРОГРАММ
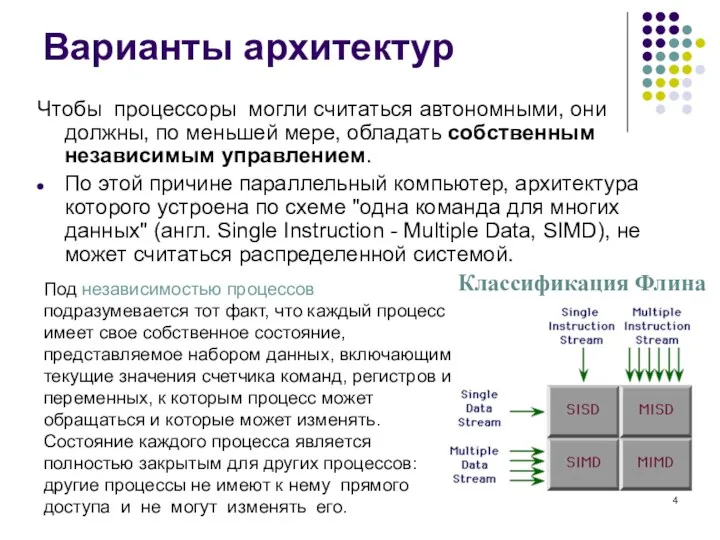
Варианты архитектур
Чтобы процессоры могли считаться автономными, они должны, по меньшей мере,
Варианты архитектур
Чтобы процессоры могли считаться автономными, они должны, по меньшей мере,

Средства автоматического распараллеливания
Средства автоматического распараллеливания – наиболее быстрый способ получить параллельную
Средства автоматического распараллеливания
Средства автоматического распараллеливания – наиболее быстрый способ получить параллельную

Некоторые программные инструменты параллелизма
OpenMP — стандарт интерфейса приложений для параллельных систем с
Некоторые программные инструменты параллелизма
OpenMP — стандарт интерфейса приложений для параллельных систем с

MPI
MPI

MPI
MPI (Message Passing Interface) — интерфейс обмена сообщениями (информацией) между одновременно работающими вычислительными
MPI
MPI (Message Passing Interface) — интерфейс обмена сообщениями (информацией) между одновременно работающими вычислительными

MPI
Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком
MPI
Для MPI принято писать программу, содержащую код всех ветвей сразу. MPI-загрузчиком
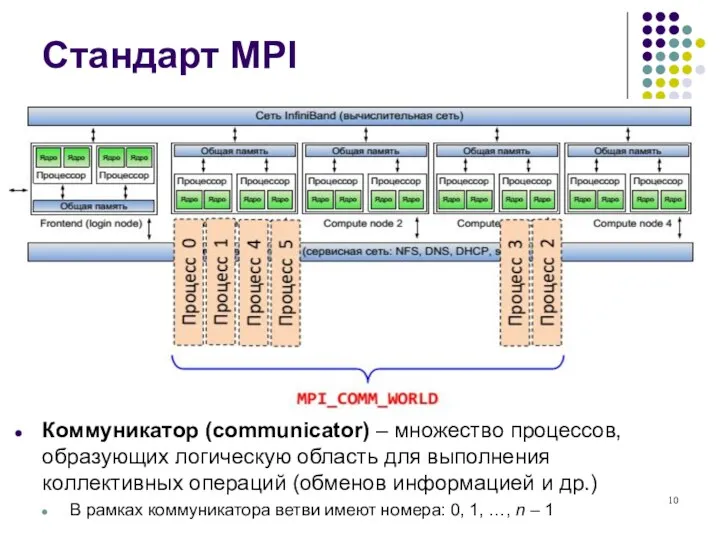
Стандарт MPI
Коммуникатор (communicator) – множество процессов,
образующих логическую область для выполнения
коллективных операций
Стандарт MPI
Коммуникатор (communicator) – множество процессов, образующих логическую область для выполнения коллективных операций

MPI
Все ветви запускаются загрузчиком одновременно как процессы Unix. Количество ветвей фиксировано
MPI
Все ветви запускаются загрузчиком одновременно как процессы Unix. Количество ветвей фиксировано

MPI (проблемы при использовании)
во-первых, перед запуском приложения необходимо копирование приложения на
MPI (проблемы при использовании)
во-первых, перед запуском приложения необходимо копирование приложения на

MPI (этапы разработки программы)
Создание параллельной программы можно разбить на следующие этапы:
MPI (этапы разработки программы)
Создание параллельной программы можно разбить на следующие этапы:
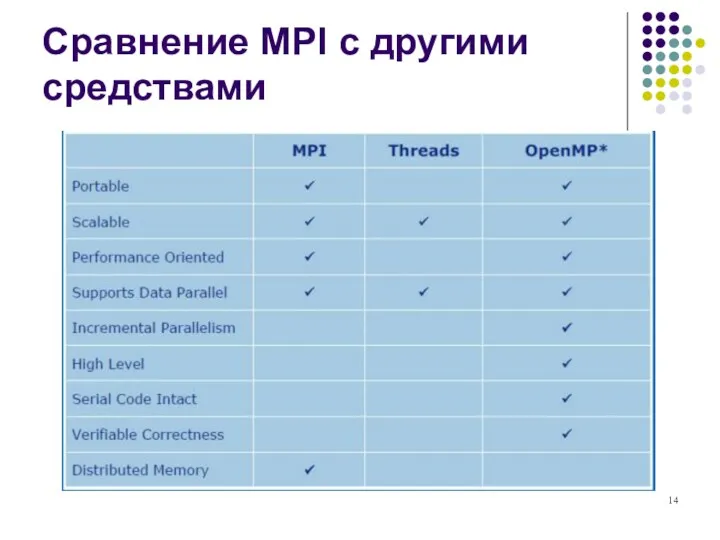
Сравнение MPI с другими средствами
Сравнение MPI с другими средствами

Версии MPI
Версия MPI-1 вышла в 1994 году
Версия MPI-2 вышла в 1998
Версии MPI
Версия MPI-1 вышла в 1994 году
Версия MPI-2 вышла в 1998

Спецификации MPI
Спецификация MPI-1
Содержит описание стандарта программного интерфейса обмена сообщениями. Спецификация учитывает
Спецификации MPI
Спецификация MPI-1
Содержит описание стандарта программного интерфейса обмена сообщениями. Спецификация учитывает

Спецификации MPI
Спецификация MPI-2
Является дальнейшим развитием MPI. Новое в MPI-2:
возможность создания новых
Спецификации MPI
Спецификация MPI-2
Является дальнейшим развитием MPI. Новое в MPI-2:
возможность создания новых

MPICH2 (Open source, Argone NL)
http://www.mcs.anl.gov/research/projects/mpich2
MVAPICH2
IBM MPI
Cray MPI
Intel MPI
HP MPI
SiCortex MPI
Open MPI
MPICH2 (Open source, Argone NL)
http://www.mcs.anl.gov/research/projects/mpich2
MVAPICH2
IBM MPI
Cray MPI
Intel MPI
HP MPI
SiCortex MPI
Open MPI

Реализации MPI
MPI CHameleon (MPICH) является свободно распространяемой “opensource” реализацией MPI. Этот
Реализации MPI
MPI CHameleon (MPICH) является свободно распространяемой “opensource” реализацией MPI. Этот

Реализации MPI
«Производные» от MPICH
LAM/MPI (Университет шт. Индиана.)
MPICH GM (Myricom) - MPICH
Реализации MPI
«Производные» от MPICH
LAM/MPI (Университет шт. Индиана.)
MPICH GM (Myricom) - MPICH

Реализации MPI
LAM (Local Area Multicomputer) MPI - “opensource” реализация MPI, соответствующая
Реализации MPI
LAM (Local Area Multicomputer) MPI - “opensource” реализация MPI, соответствующая

Реализации MPI
OpenMPI - “opensource” реализация MPI-2, разрабатываемая консорциумом представителей академических, научных
Реализации MPI
OpenMPI - “opensource” реализация MPI-2, разрабатываемая консорциумом представителей академических, научных
Реализации MPI
Microsoft MPI (MS-MPI v7.1) входит в состав Compute Cluster Pack
Реализации MPI
Microsoft MPI (MS-MPI v7.1) входит в состав Compute Cluster Pack

Реализации MPJ
Most of those early projects are no longer active. mpiJava
Реализации MPJ
Most of those early projects are no longer active. mpiJava

Реализации MPJ
Один из ранних и наиболее живучих проектов - mpiJava
все
Реализации MPJ
Один из ранних и наиболее живучих проектов - mpiJava
все

НАСТРОЙКА РАБОЧЕГО МЕСТА
НАСТРОЙКА РАБОЧЕГО МЕСТА
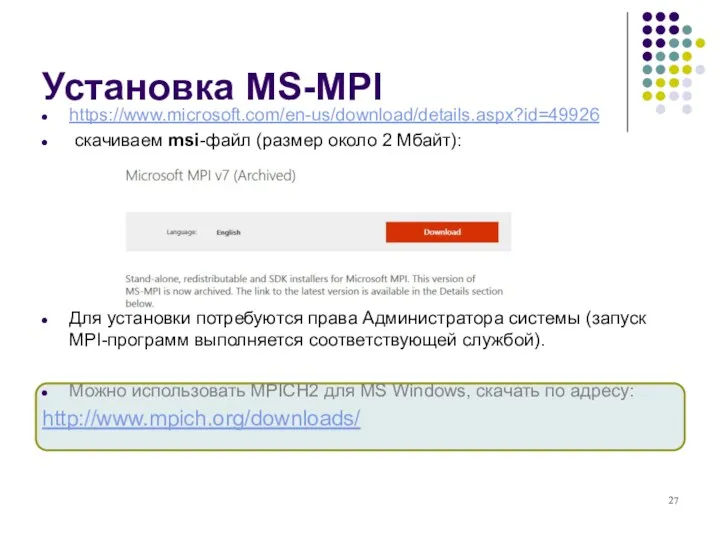
Установка MS-MPI
https://www.microsoft.com/en-us/download/details.aspx?id=49926
скачиваем msi-файл (размер около 2 Мбайт):
Для установки потребуются права
Установка MS-MPI
https://www.microsoft.com/en-us/download/details.aspx?id=49926
скачиваем msi-файл (размер около 2 Мбайт):
Для установки потребуются права

Установка MS-MPI
Запускаем скачанный файл, он нам устанавливает MPI SDK:
Можно попробовать эту
Установка MS-MPI
Запускаем скачанный файл, он нам устанавливает MPI SDK:
Можно попробовать эту
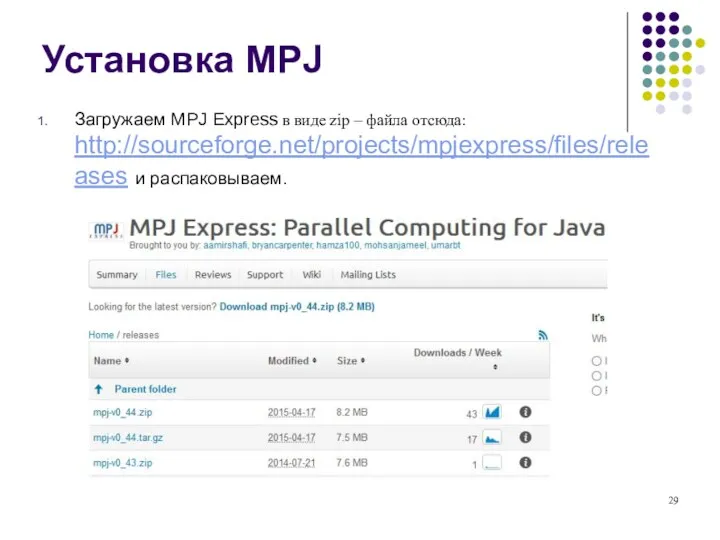
Установка MPJ
Загружаем MPJ Express в виде zip – файла отсюда: http://sourceforge.net/projects/mpjexpress/files/releases
Установка MPJ
Загружаем MPJ Express в виде zip – файла отсюда: http://sourceforge.net/projects/mpjexpress/files/releases

Настройка системных переменных
Входим в «Дополнительные параметры системы»
Настройка системных переменных
Входим в «Дополнительные параметры системы»
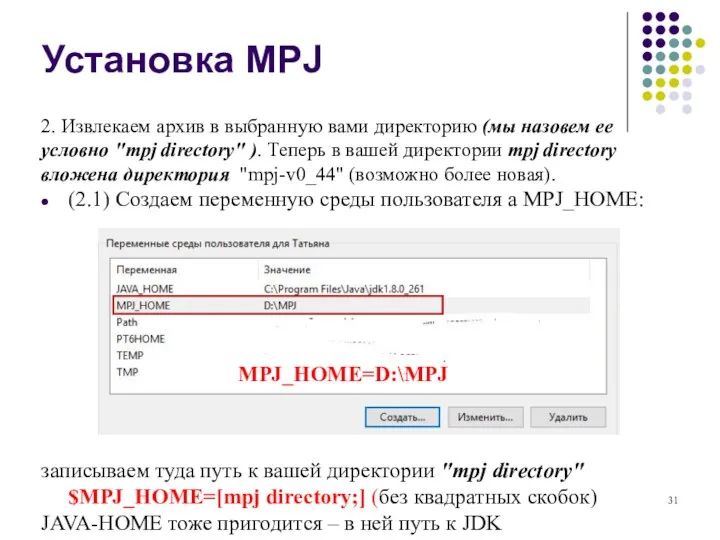
Установка MPJ
2. Извлекаем архив в выбранную вами директорию (мы назовем ее
Установка MPJ
2. Извлекаем архив в выбранную вами директорию (мы назовем ее
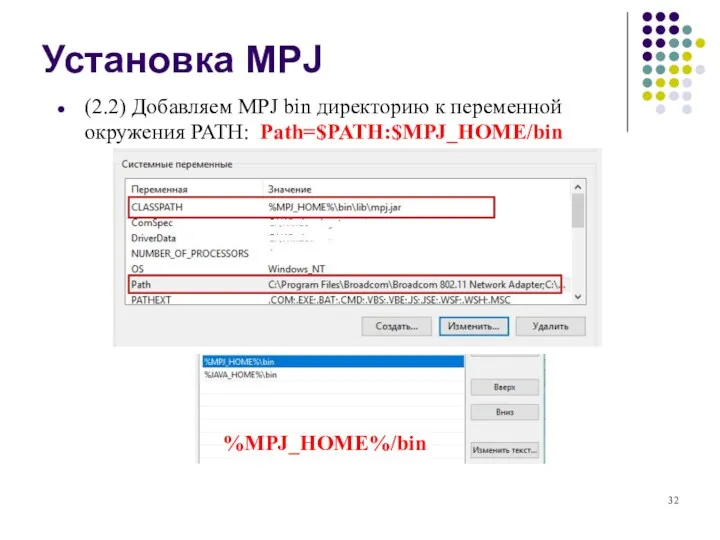
(2.2) Добавляем MPJ bin директорию к переменной окружения PATH: Path=$PATH:$MPJ_HOME/bin
Установка
(2.2) Добавляем MPJ bin директорию к переменной окружения PATH: Path=$PATH:$MPJ_HOME/bin
Установка
Установка MPJ
(2.3) Добавьте к classpath:
CLASSPATH=.:$MPJ_HOME/lib/mpj.jar
Изменения системных переменных вступят в силу после
Установка MPJ
(2.3) Добавьте к classpath:
CLASSPATH=.:$MPJ_HOME/lib/mpj.jar
Изменения системных переменных вступят в силу после
Настройка проекта в JavaBeans
Создаем новый JAVA-проект и помещаем в него код:
Настройка проекта в JavaBeans
Создаем новый JAVA-проект и помещаем в него код:
Настройка проекта в JavaBeans
Добавить JAR-файл mpj.jar к библиотеке проекта
После этого библиотека
Настройка проекта в JavaBeans
Добавить JAR-файл mpj.jar к библиотеке проекта
После этого библиотека
Настройка проекта в JavaBeans
Следующим шагом создаем новую Runtime конфигурацию:
Параметры запуска (5
Настройка проекта в JavaBeans
Следующим шагом создаем новую Runtime конфигурацию:
Параметры запуска (5

MPJ “Hello, World”
Запускаем:
Получаем:
MPJ “Hello, World”
Запускаем:
Получаем:
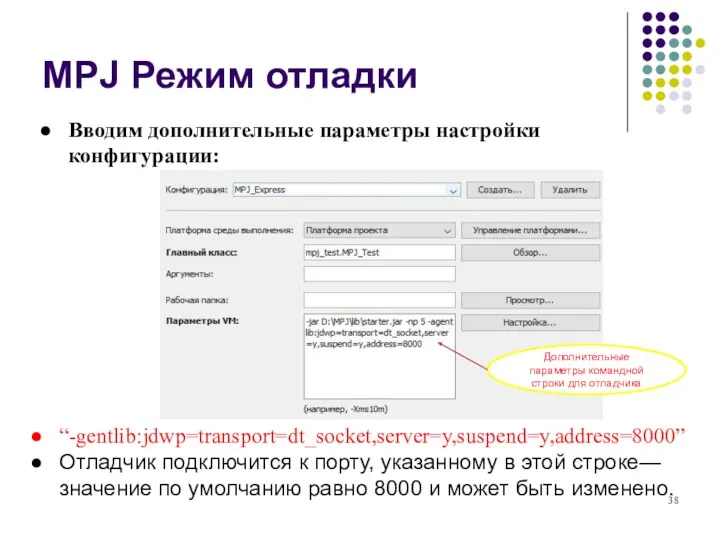
MPJ Режим отладки
Вводим дополнительные параметры настройки конфигурации:
“-gentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000”
Отладчик подключится к порту, указанному
MPJ Режим отладки
Вводим дополнительные параметры настройки конфигурации:
“-gentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000”
Отладчик подключится к порту, указанному

MPJ Режим отладки
Устанавливаем точку останова и запускаем:
Видим, что идет прослушивание сокета
MPJ Режим отладки
Устанавливаем точку останова и запускаем:
Видим, что идет прослушивание сокета
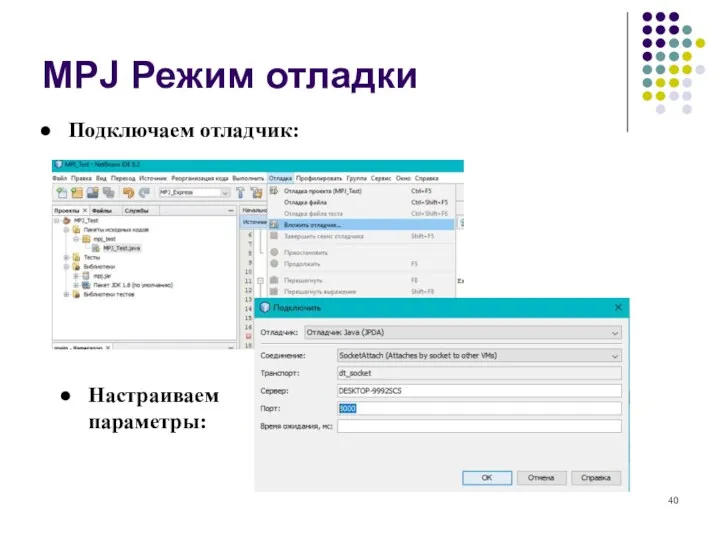
MPJ Режим отладки
Подключаем отладчик:
Настраиваем
параметры:
MPJ Режим отладки
Подключаем отладчик:
Настраиваем
параметры:
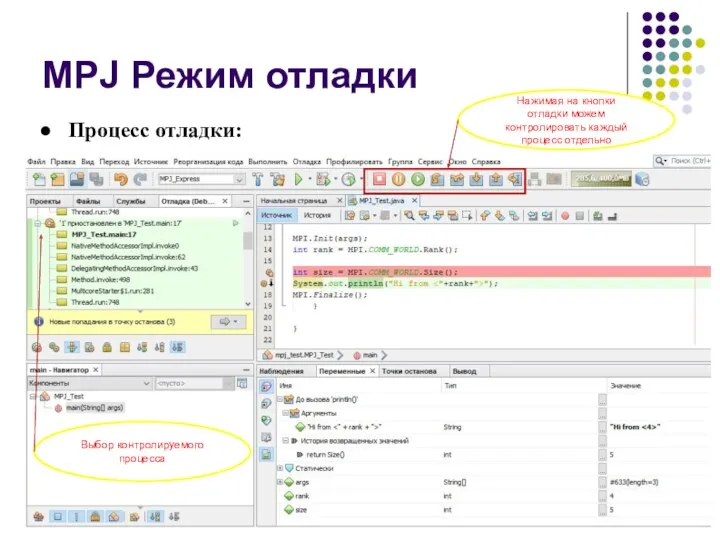
MPJ Режим отладки
Процесс отладки:
Нажимая на кнопки отладки можем контролировать каждый процесс
MPJ Режим отладки
Процесс отладки:
Нажимая на кнопки отладки можем контролировать каждый процесс
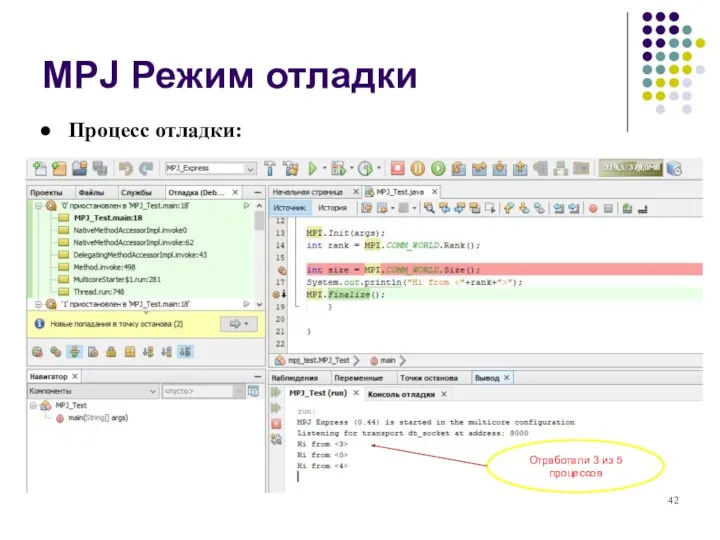
MPJ Режим отладки
Процесс отладки:
Отработали 3 из 5 процессов
MPJ Режим отладки
Процесс отладки:
Отработали 3 из 5 процессов

MPJ “Hello, World”
Можно скомпилировать из командной строки:
javac -cp .:$MPJ_HOME/lib/mpj.jar MPJExample1.java
И
MPJ “Hello, World”
Можно скомпилировать из командной строки:
javac -cp .:$MPJ_HOME/lib/mpj.jar MPJExample1.java
И

MPJ “Hello, World”
import mpi.*;
public class MPIAPP {
public static void main(String[] args)
MPJ “Hello, World”
import mpi.*;
public class MPIAPP {
public static void main(String[] args)

Функции инициализации и завершения работы
int MPI_Init(int* argc, char*** argv)
argc –
Функции инициализации и завершения работы
int MPI_Init(int* argc, char*** argv)
argc –

Структура программы на MPI
Структура параллельной программы, разработанная с использованием MPI, должна
Структура программы на MPI
Структура параллельной программы, разработанная с использованием MPI, должна

Полезные ссылки:
MPJ Express: An Implementation of MPI in Java
Windows User Guide
Полезные ссылки:
MPJ Express: An Implementation of MPI in Java Windows User Guide
Все задачи по курсу
Все задачи по курсу

В исходном тексте программы на языке C (след. слайд) предусмотрена некая
В исходном тексте программы на языке C (след. слайд) предусмотрена некая
![2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/318680/slide-49.jpg)
2008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myrank, size, message;
int TAG =
2008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myrank, size, message;
int TAG =
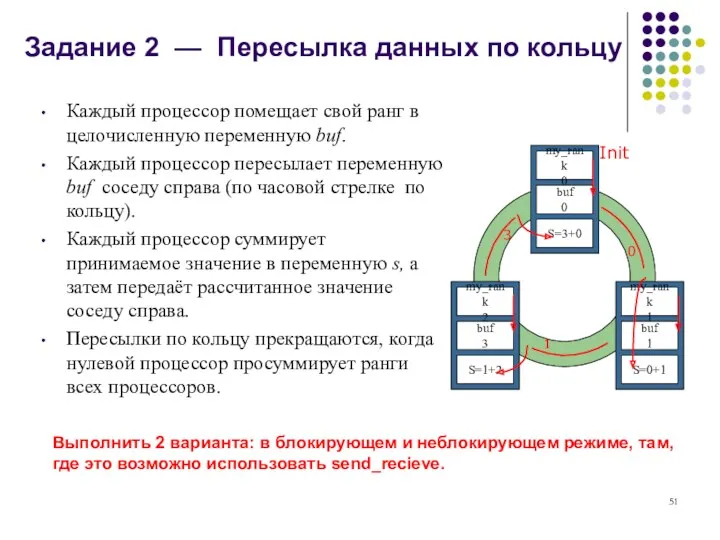
Задание 2 — Пересылка данных по кольцу
Init
0
1
3
Каждый процессор помещает свой ранг
Задание 2 — Пересылка данных по кольцу
Init
0
1
3
Каждый процессор помещает свой ранг
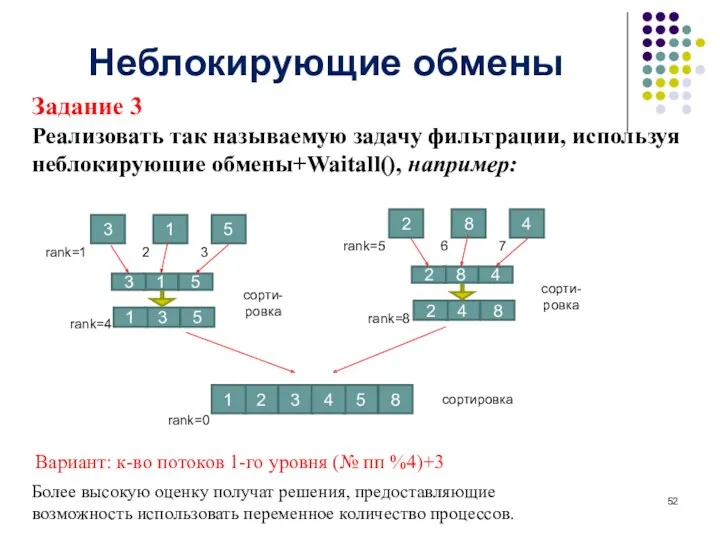
Неблокирующие обмены
Задание 3
Реализовать так называемую задачу фильтрации, используя неблокирующие обмены+Waitall(), например:
Вариант:
Неблокирующие обмены
Задание 3
Реализовать так называемую задачу фильтрации, используя неблокирующие обмены+Waitall(), например:
Вариант:

Задание 4
Дополнить программу с пробниками, выполнить ее.
Неблокирующие обмены
(пробники)
int data[] = new
Задание 4
Дополнить программу с пробниками, выполнить ее.
Неблокирующие обмены
(пробники)
int data[] = new

Задание 4
(окончание)
Неблокирующие обмены
(пробники)
else if(rank == 2){
st = MPI.COMM_WORLD.Probe(…);
Задание 4
(окончание)
Неблокирующие обмены
(пробники)
else if(rank == 2){
st = MPI.COMM_WORLD.Probe(…);

Два вектора a и b размерности N представлены двумя одномерными массивами,
Два вектора a и b размерности N представлены двумя одномерными массивами,

Два вектора a и b размерности N представлены двумя
одномерными массивами, содержащими
Два вектора a и b размерности N представлены двумя одномерными массивами, содержащими

7,8. Задачи с графами.
Задание выполняется по вариантам: N mod 4,
7,8. Задачи с графами.
Задание выполняется по вариантам: N mod 4,
 Передача информации в древние времена и сегодня
Передача информации в древние времена и сегодня Презентация Утилиты. Текстовый редактор
Презентация Утилиты. Текстовый редактор Способы шифрования
Способы шифрования Java input output-library
Java input output-library C++ тілінде бағдарламалау
C++ тілінде бағдарламалау Условный оператор
Условный оператор Кружок по искусственному интеллекту. Семинар 2
Кружок по искусственному интеллекту. Семинар 2 АИС Стационар. Система автоматизации деятельности медицинских учреждений
АИС Стационар. Система автоматизации деятельности медицинских учреждений Создание блога
Создание блога Концепция электронного правительства
Концепция электронного правительства Цвет. Цветовое зрение. Измерение восприятия цвета. Диаграмма цветности. ColorFPM
Цвет. Цветовое зрение. Измерение восприятия цвета. Диаграмма цветности. ColorFPM Електронне урядування та електронна демократія України
Електронне урядування та електронна демократія України Таргетированная реклама ВКонтакте
Таргетированная реклама ВКонтакте Детективное агентство
Детективное агентство Aspects of internal corporate information security policies
Aspects of internal corporate information security policies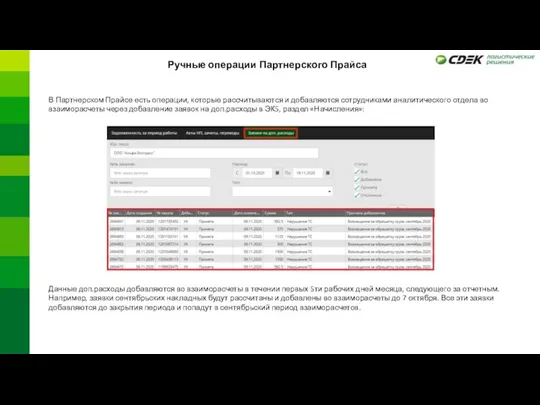 Ручные операции Партнерского Прайса
Ручные операции Партнерского Прайса CiGe Update firmware Using the tutorial
CiGe Update firmware Using the tutorial Презентация к уроку в 9 классе Управление и кибернетика
Презентация к уроку в 9 классе Управление и кибернетика Формування державної політики у сфері кібербезпеки, реалізація Стратегії кібербезпеки України
Формування державної політики у сфері кібербезпеки, реалізація Стратегії кібербезпеки України Практическая работа Служу России
Практическая работа Служу России Поколение - z - школа блогеров
Поколение - z - школа блогеров Технология информационно-справочной работы с документами
Технология информационно-справочной работы с документами Рациональность в инди разработке
Рациональность в инди разработке Классификация ИТ
Классификация ИТ Основы разработки сайтов
Основы разработки сайтов Дизайн приложения и функций. Приложения “Родитель ” или “Ребенок ”
Дизайн приложения и функций. Приложения “Родитель ” или “Ребенок ” Історія виникнення ПК
Історія виникнення ПК Пакеты и модули в Python
Пакеты и модули в Python